SOLID原則というオブジェクト指向設計原則のDにあたる、依存性逆転の原則について説明します。
まだあまり知識・経験がないという方でもDIPを理解し、GoでDIPを適用した実装までできるようにかなり細かく解説しています。説明・実装に使用する言語はGo言語で、実装の説明が多いです。
オープン・クローズドの原則についての説明記事はこちら。
良い設計とは?
DIPについて説明しても、良いソフトウェアの設計とはどのようなものかについての理解がないと、「・・・、で?」となってしまうかもしれません。良い設計を知るために、どのエンジニアも共感する悪い設計について確認しましょう。
Rigidity(硬直性):
It is hard to change because every change affects too many other parts of the system.
少し変更しようとするだけでシステムの多くの部分に影響が出てしまうため変更することが難しい。
Fragility(変更への脆弱性):
When you make a change, unexpected parts of the system break.
変更を加えると、システムの予想外の部分が動かなくなる。
Immobility(低い移植性):
It is hard to reuse in another application because it cannot be disentangled from the current application.
現在使われているアプリケーションと強く結びついているため、他のアプリケーションで使い回すことが難しい。
誰もが納得する良い設計とはつまりはこの逆、変更に柔軟で変更してもシステムが壊れることなく、使い回しが効く設計です。その設計を実現するためにDIPが役立ちます。
この前提知識を確認した上で、DIPの説明に入ります。
DIP(依存性逆転の原則)とは?
まずは言葉による説明を見てみましょう。Wikipediaでの説明を一部抜粋します。さらっと目を通していただければ構いません。
A. 上位レベルのモジュールは下位レベルのモジュールに依存すべきではない。両方とも抽象(abstractions)に依存すべきである。
B. 抽象は詳細に依存してはならない。詳細が抽象に依存すべきである。
DIPは、モジュール(レイヤー)間を疎結合に保つことで変更に強い柔軟なシステムを作るに役立ちます。それでは、以下にDIP適用前と適用後の実装例を示します。
DIP適用前の悪い実装
よくDIPのメリットを説明する例として使われるのが、データアクセス層とそれに依存する上位層の問題です。
こちらの例では、DBに直接アクセスして社員情報を返すメソッドをハンドラが使用しています。
*本記事での実装例ではORM(gorm)を使っているのでRDBMSをを変更してもデータアクセス層とインフラ層でのDBにアクセスするための定義は使い回しが効きますが、現実ではライブラリに依存したくない場合も往々にしてあります。
import (
"encoding/json"
"net/http"
"github.com/masalennon/test/store"
)
func main() {
http.Handle("/employees/", http.StripPrefix("/employees/", http.HandlerFunc(getEmployee)))
http.ListenAndServe(":8080", nil)
}
func getEmployee(w http.ResponseWriter, r *http.Request) {
id := r.URL.Path
employee, err := store.GetEmployeeByID(id) //詳細への依存がある
if err != nil {
panic(err)
}
json.NewEncoder(w).Encode(employee)
}
func GetEmployeeByID(id string) (*model.Employee, error) {
var e model.Employee
if err := db.GetDB().Where(&model.Employee{ID: id}).First(&e).Error; err != nil {
return nil, nil
}
return &e, nil
}
DIP適用前の悪い実装図
この依存関係を示すと以下のようになるでしょう。
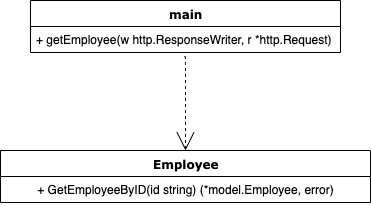
上位のモジュールが下位に依存するのは普通の依存関係です。しかし、ここで問題なのは、ハンドラ側のgetEmployeeメソッドはインフラストラクチャ層のGetEmployeeByIDを直接使用しているため、store/employee.goにあるGetEmployeeByIDに何らかの変更があった場合、もろに影響を受けてしまうということです。例えばgormの使用をやめるなどの変更があった場合、現状だとmain.goにあるgetEmployeeにも変更を加えないといけません。
func getEmployee(w http.ResponseWriter, r *http.Request) {
id := r.URL.Path
employee, err := store.GetEmployeeByID(id) //依存があるこの部分にも変更の影響が及んでしまい改修が必要になる
if err != nil {
panic(err)
}
json.NewEncoder(w).Encode(employee)
}
これは先ほど紹介した悪い設計の一つであるRigidity(少し変更しようとするだけでシステムの多くの部分に影響が出てしまうため変更することが難しい。)に当てはまっていると言えるでしょう。
DIP適用後の実装
DIPはこのような問題を解決し、変更に柔軟で変更してもシステムが壊れることなく、使い回しが効く設計を可能にします。
DIP適用後の実装図
DIPを適用すると、先ほどのクラス図のようなものは次のようになります。
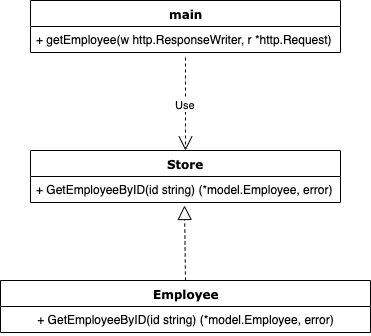
図ではデータアクセス層にあるEmployeeから矢印が伸びており、Employeeがインターフェースに逆に依存している格好となっています。DIP(依存性逆転の原則)というのはこれを指して命名されたようです。
この実装例ではハンドラ(getEmployee)はGetEmployeeByIDを直接使う(依存する)のではなく、Storeというインターフェースに依存し、DBに直接アクセスするemployee.goはStoreインターフェースに依存させます。こうすることでgormを使っていようと使っていなかろうとDBがDynamoDBだろうとPostgresだろうとStoreインターフェースを満たしてやることで、簡単に交換可能になります。
このように、インターフェースをはさむことでハンドラ側のgetEmployeeはデータアクセス層のGetEmployeeByIDの詳細がどうであろうと影響がなくなります。この状態をgetEmployeeはGetEmployeeByIDの詳細を知らないと表現することもあります。
また、それだけでなく単体テストのためにモックを用意する時も、Storeインターフェースを満たすモックを用意すれば良いだけなので単体テストも簡単です。(ここら辺はクリーンアーキテクチャにも繋がってくる話ですが、この記事ではクリーンアーキテクチャまで話を広げず、DIPに留めておきたいと思います。)
DIP適用後の実装例 interface
上記の悪い例として説明した実装にDIPを適用するために、まずはinterfaceを用意します。
package employee
import (
"github.com/masalennon/DIP_sample/model"
)
type Store interface {
GetEmployeeByID(id string) (*model.Employee, error)
}
DIP適用後の実装例 データアクセス層
そうしたら、次はこのStoreインターフェースを満たすようにデータアクセス層を改修します。
type EmployeeGormStore struct {
db *gorm.DB
}
func NewEmployeeGormStore(db *gorm.DB) employee.Store {
return &EmployeeStore{
db: db,
}
}
func (es *EmployeeGormStore) GetEmployeeByID(id string) (*model.Employee, error) {
var e model.Employee
if err := es.db.Where(&model.Employee{ID: id}).First(&e).Error; err != nil {
return nil, nil
}
return &e, nil
}
分かりにくいところ解説
少し長くなるので見やすくするために箇条書きで説明します。
- EmployeeStore構造体を定義し、それにGetEmployeeByIDを定義してStoreインターフェースを満たします(Goはダックタイピングによってインターフェースを実装する)。
-
NewEmployeeGormStore(db *gorm.DB)はgormを使ってDBにアクセスすることを決定するために使います。(この例ではgormしか用意していないですが、例えばstore/employee_sql.goを用意して、gormを使わないNewEmployeeMysqlStore(Conn *sql.DB)にすることもできます。) -
NewEmployeeGormStore(db *gorm.DB)ではemployee.StoreとしてStoreインターフェースを返すようにしています。GetEmployeeByIDを実装しているためEmployeeGormStoreがStoreインターフェースを満たしているので返り値にemployee.Storeを指定できます。そうすることで、このメソッドを呼び出す側でもStoreインターフェースという制約の中で使い回すことができるようになります。 - なぜ
NewEmployeeGormStoreが必要になるかイメージが湧かないかもしれませんが、ひとまずその疑問は置いておいてください。 -
db *gorm.DBが構造体の中に入っていなくても動かせますが、入れておくことで同じdbインスタンスを使いまわせるので便利です。
DIP適用後の実装例 ハンドラ側
ここまででこのクラス図の下半分の部分である、employeeがStoreの実現であるところを実装できました。ここからmain.goのハンドラ側で抽象に依存する部分を実装していきます。
DIPをハンドラ側に適用すると以下のようになるでしょう。
type EmployeeHandler struct {
es employee.Store
}
func NewEmployeeHandler(es employee.Store) *EmployeeHandler {
return &EmployeeHandler{
es: es,
}
}
func (h EmployeeHandler) getEmployee(w http.ResponseWriter, r *http.Request) {
id := r.URL.Path
employee, err := h.es.GetEmployeeByID(id)
if err != nil {
panic(err)
}
json.NewEncoder(w).Encode(employee)
}
分かりにくいところ解説
まず上記のコードを読んで分かりにくいところは、
-
getEmployeeの中でh.es.GetEmployeeByID(id)というようになっている部分 - なぜ
EmployeeHandlerはes employee.Storeを持っているのか - そもそもなぜ
getEmployeeをEmployeeHandlerに定義しているのか
というところだと思います。
まず、DIPを利用すると言っても結局データアクセス層のメソッドであるGetEmployeeByID(id)は当然ですが使用する必要があるのでgetEmployee内で使います。この時、上位層も抽象であるstore/employee.goにあるStoreインターフェースに依存するのだからemployee.Store.GetEmployeeByIDとなるのでは?と思うでしょうか。
しかし、それでは一体GetEmployeeByID(id)の実装はどれなのか、store/employee_gorm.goなのかstore/employee_mysql.goなのか見分けがつきません。そのため、内部にStoreインターフェース型の変数を持つ構造体(EmployeeHandler)を定義し、getEmployee(w http.ResponseWriter, r *http.Request)をその構造体に実装します。
こうすることで、その構造体を初期化する時に内部にStoreインターフェースを満たす実装クラス(構造体)の変数を持たせることが可能になります(この例ではNewEmployeeGormStore)。一見周りくどいかのように見えるかもしれないですが、柔軟にどのデータアクセス層の実装を使用するかを切り替えられます(その決定部分の説明は後述)。
今回はgormを使うので、NewEmployeeHandler(es employee.Store)の引数にEmployeeGormStore構造体を渡します。Storeインターフェースを引数として受け取るようにすることでStoreインターフェースを満たすものなら何でも引数に受けることができるという点で柔軟さを出すことができています。
ここにNewEmployeeGormStoreだったりNewEmployeeMySQLStoreを指定することでデータアクセスの方法が切り替えられます。
ここまできたらもう後少しです。
func main() {
d := db.Init()
es := store.NewEmployeeGormStore(d)
h := NewEmployeeHandler(es)
http.Handle("/employees/", http.StripPrefix("/employees/", http.HandlerFunc(h.getEmployee)))
http.ListenAndServe(":8080", nil)
}
上記で説明したデータアクセスの方法を決定し、それをハンドラ側に共有し、ハンドラ側では内部的にそのデータアクセスの方法に基づいてデータにアクセスします。もしORMが嫌になりgormではなくsql文を使ってデータアクセスしたいとなっても、インターフェースからハンドラ側のコードには一切手を加える必要がありません。
インターフェースを満たすようにメソッドを定義したら、es := store.NewEmployeeGormStore(d)をes := store.NewEmployeeSQLStore(d)のように改修するだけで良いのです。
「なぜNewEmployeeGormStoreが必要になるかイメージが湧かないかもしれませんが、ひとまずその疑問は置いておいてください。」と言いましたが、このように使います。
DIP適用後では、冒頭で触れたRigidity(少し変更しようとするだけでシステムの多くの部分に影響が出てしまうため変更することが難しい。)という問題が解決されていることが分かると思います。
また、インターフェースを用意し抽象に依存することでFragility(変更への脆弱性):変更を加えると、システムの予想外の部分が動かなくなる。ということもなくなるでしょう。
このように、インターフェースを用意し詳細ではなく抽象に依存することでより柔軟なシステムを構築することができます。それは良いことですが、コードの複雑性は増しますので、無条件でくまなくDIPを適用すれば良いというわけでもなく、そこは判断が必要になってくる部分です。しかし、アーキテクチャに関する知識はバックエンドエンジニアなら言語を問わず必要になってくると思うので、DIPを理解するためにここまで費やした時間は無駄ではなく、この知識を持っていて邪魔になることはないはずです。
サンプルコードはこちらに載せてあります。悪い例のコミットがありますので、そこからDIPを自力で適用してみるのも面白いでしょう。
この記事が何かのお役に立つことがあれば幸いです。
参考
https://www.bilibili.com/video/av78087006/?spm_id_from=trigger_reload
https://qiita.com/Sekky0905/items/2436d669ff5d4491c527
https://en.wikipedia.org/wiki/Dependency_inversion_principle