本記事について
- クリーンアーキテクチャを理解するのに時間がかかった
- その原因は前提知識が不足していたのが一つの原因だった
- これからクリーンアーキテクチャを学ぶ人がすんなりと理解できるように、クリーンアーキテクチャに登場する用語について前提知識を前提としない解説をする。
注意
本記事の内容がそこまで大きく外れているとは思いませんが、所々自分の理解を元に分かりやすくなるように例えなどを自分で考えて書いています。つまり、本記事はRobert Martinの記事やClean Architectureの本を参照してはいますがその正確な訳などではなく、私の解釈も加わっていることに ー無責任で申し訳ありませんがー 注意してください。しかし、本記事で大まかなイメージを掴んだ後なら分厚い本を読むのもとっつきやすくなると思うので、本記事の果たす役割はあるかと思います。
本記事を一通り読んだら、あとは自分の得意な言語でのクリーンアーキテクチャの実装例を見てみるとなお理解が深まるのでそうすることをオススメします。
クリーンアーキテクチャとは?
クリーンアーキテクチャとは、ロバートマーティンが提唱するソフトウェア構築方式。クリーンアーキテクチャではソフトウェアをその役割ごとにレイヤ分けし、レイヤ間の依存関係を適切にコントロールすることで変更に強くテストしやすいソフトウェア開発を可能にする。
クリーンアーキテクチャの目指すシステム
クリーンアーキテクチャに関連する用語を理解し、クリーンアーキテクチャの要素についてなんとなくイメージがついたところでクリーンアーキテクチャの目指すシステムについて理解しましょう。
- フレームワークから独立していること。クリーンアーキテクチャでは機能満載のライブラリに頼るようなことはせず、そのおかげでフレームワークをまるでツールであるかのように自由に使うことを可能にし、フレームワークの制約に縛られながらシステムを開発するようなことを防ぐ。
- テストが可能であること。ビジネスロジックはUIやDB、Webサーバやその他の要素を使わずにテストをすることができる。これは具体的には依存性逆転の原則を適用して、テスト時にはインターフェースを満たすテスト用のモックを使うことでDBやUIへの依存関係を解決しテスト可能にする。
- UIからの独立。UIを変更する際、システムの他の部分に影響を与えることがない。これもインターフェースを利用してレイヤ間の結合を疎にすることで達成できる。
- データベースから独立している。使用するデータベースをNoSQLでもRDBMSでも自由に取り替えられる。これはRepositoryパターンを使用してインフラストラクチャ層の詳細を隠蔽することで可能になる。
- ビジネスルール(domain層)が外部のレイヤから独立していて、ビジネスルールを表すのに下位のレイヤの詳細(実装)に一切依存しない。
(なお、上記は直訳だとどういう意味かわかりにくいので、Robert Martinの記事にある下記の英文を元に自分の理解を交えて補足を加えわかりやすくしたものです。)
- Independent of Frameworks. The architecture does not depend on the existence of some library of feature laden software. This allows you to use such frameworks as tools, rather than having to cram your system into their limited constraints.
- Testable. The business rules can be tested without the UI, Database, Web Server, or any other external element.
- Independent of UI. The UI can change easily, without changing the rest of the system. A Web UI could be replaced with a console UI, for example, without changing the business rules.
- Independent of Database. You can swap out Oracle or SQL Server, for Mongo, BigTable, CouchDB, or something else. Your business rules are not bound to the database.
- Independent of any external agency. In fact your business rules simply don’t know anything at all about the outside world.
用語解説
カプセル化
ロバートマーティンの記事を読むと、カプセル化という言葉が出てくる。カプセル化というとオブジェクト指向に出てくる用語なので、オブジェクト指向のカプセル化をイメージするかもしれないが、カプセル化とはデータ(属性)とメソッド(手続き)を一つのオブジェクトにまとめ、その内容を隠蔽することを言う。ビジネスルールをカプセル化する、と言うとビジネスルールを変数とメソッドによってクラスとして表すこと、とでも読み替えて差し支えないだろう。クリーンアーキテクチャではソフトウェアを役割ごとにレイヤ分けし、その依存関係も厳密にコントロールされるので、外部に自由に公開されないと言う点を踏まえてやや比喩的にカプセル化と言う言葉をこのことを表すのに使用している、と思われる。少なくとも、オブジェクト指向のカプセル化をイメージすると混乱するので注意。
エンティティ
ロバートマーティンは、エンティティのことをビジネスルールをカプセル化したものと説明している。カプセル化のところでも説明したが、カプセル化とはデータとメソッドを一つのオブジェクトにまとめその内容を隠蔽することなので、ビジネスルールを変数とメソッドによって表現したものと捉えて良いだろう。ビジネスルールも、それを表現するのに例えばECなら販売者・購買者・商品など実物が存在するものから、セール情報?など実物がないものまで、様々な主体・仕組みが登場する。それらを変数とメソッドを用いて表現したものをエンティティとイメージすれば問題ないはず。
DDD
ドメイン駆動設計(Domain Driven Design)のこと。ユビキタス言語と呼ばれるビジネス側と開発側の人間の間での共通言語を用いてドメインモデル(詳しくは後述)をまず構築し、そのドメインモデルをソフトウェアに落とし込んでいく形で開発を進める。ビジネス側と開発側の認識齟齬をなくすことで、ビジネス側の認識と異なる使い物にならないソフトウェアが出来上がってしまうことを防ぐことができる。ドメイン駆動設計に基づいて実装を行う上でクリーンアーキテクチャが使われることも多いので、クリーンアーキテクチャについて調べていると思ったら、いつの間にかDDDだったということも。そのため、DDDとクリーンアーキテクチャ間の概念を混同しやすい。
ドメイン
ドメインとは、ソフトウェア化する対象のこと。ソフトウェアが作られる時、必ずそのソフトウェアが表現する業務やなんらかの行動(それぞれEC、ToDo管理など)がある。例えばECなら、「出品者が商品をオンラインで出品して購買者がそれを閲覧・購入・決済できる。購入した品物は購買者の住所まで発送される。」などECというサービスを実現するには様々なプレイヤー・処理・工程が存在する。ソフトウェアを作るときはこのドメインを理解し、それをコードに落とし込むことが必要で、そうして完成したソフトウェアを通してドメインのビジネスが成立するようにしなければならない。よって、ドメインについての知識・理解はエンジニアにとっても重要で、ドメインについての知識はそのままドメイン知識と呼ばれる。
ドメインモデル
モデルとは、ある物・概念の細かい部分を削って本質的な部分だけを取り出し抽象化したもののこと。ドメインモデルとはドメインをソフトウェアに落とし込むために使われる、ドメインのモデルで、業務が行われる上で発生するドメイン内でのプレイヤー(ECでいう出品者や購入者など)間のやり取りやデータの流れを抽象化して実際の業務内容を図などで表現する。一般に、ドメイン内の処理をメソッドや属性(RDBでいうテーブルの列、カラムのこと)として洗い出すところも含む。下記画像はWikipediaでドメインモデルの例として使用されている図。
DDDのエンティティとClean Architectureのエンティティ
同じような意味かと思ったら実際には異なるらしい。その違いについての説明は以下のリンクが詳しい。
https://nrslib.com/clean-ddd-entity/
依存
ソフトウェアの文脈で語られる依存とは、例えばあるメソッドA内で別のクラスのインスタンスを初期化し、初期化したインスタンスBのメソッドを使用しているなど、一つの関数内で別の関数を呼び出している状態を指す。
プログラム内で依存が発生するのはごく当たり前だが、依存関係を適切にコントロールしないと単体テストが難しくなったり、改修を加えたところ思わぬ影響を他に与えてしまうという変更への弱さの原因となるため、クリーンアーキテクチャでは依存関係は厳密にコントロールされる。
import ("path/to/project/answer")
func list() {
a := answer.Get() //answerパッケージ内の関数に依存している
if a == "1" {
//なんらかの処理
}
// answer.Get()に改修が入ると、このcreate()も影響を受ける可能性がある。
// 単体テスト時には、Get()を呼び出す必要がありGet()に結果が左右されてしまうため、真の単体テストでなくなってしまう。
}
依存性注入
メソッド内でクラスをnewするなどしてしまうと、そのメソッドを呼び出す際に必ずそのクラスもnewされるため、そのクラスに固定された依存が発生してしまう。依存すること自体は悪いことではないが、固定された依存は避けるべきで、そのために依存性注入という方法がある。
具体的には、引数でクラスをインスタンスを受け取れるようにしてやることで可能になる。ここでポイントとなるのが、その引数にはインターフェース型を指定することである。そうすることにより、テストの時にはその引数にインターフェースを満たすモック用インスタンスを入れたり、そのメソッドを呼び出す側で場合に応じてどのメソッドを実行するかを引数に受けるインスタンスによって柔軟に切り替えることができる。(ポリモーフィズム)
依存関係逆転の原則
SOLID原則というオブジェクト指向設計原則の一つ。クリーンアーキテクチャでは、レイヤ間の依存関係を疎にしてテストがしやすく変更に強くするためにレイヤ間ではこの依存関係逆転の原則を適用する。依存関係逆転の原則とは、
- 上位レベルのモジュールは下位レベルのモジュールに依存すべきではない。両方とも抽象(abstractions)に依存すべきである。
- 抽象は詳細に依存してはならない。詳細が抽象に依存する。
という二つからなる原則で、
1は、要は上位レベルのモジュールがインターフェースに依存している限り、下位レベルのモジュールはそのインターフェースを満たすという制約の元自由に取り替えられて上位レベルのモジュールに影響を与えなくて済むから変更しやすくなるのでそうしようということ。
2は、抽象は滅多なことで変わらず詳細には変更が起きやすいという前提がまず存在し、頻繁に起きる詳細の変更に抽象が左右されないように抽象をベースにすることで、頻繁に起こる詳細の変更の影響が最小限に抑えられるということ。
依存関係逆転の原則を適用しインターフェースを挟むことで、
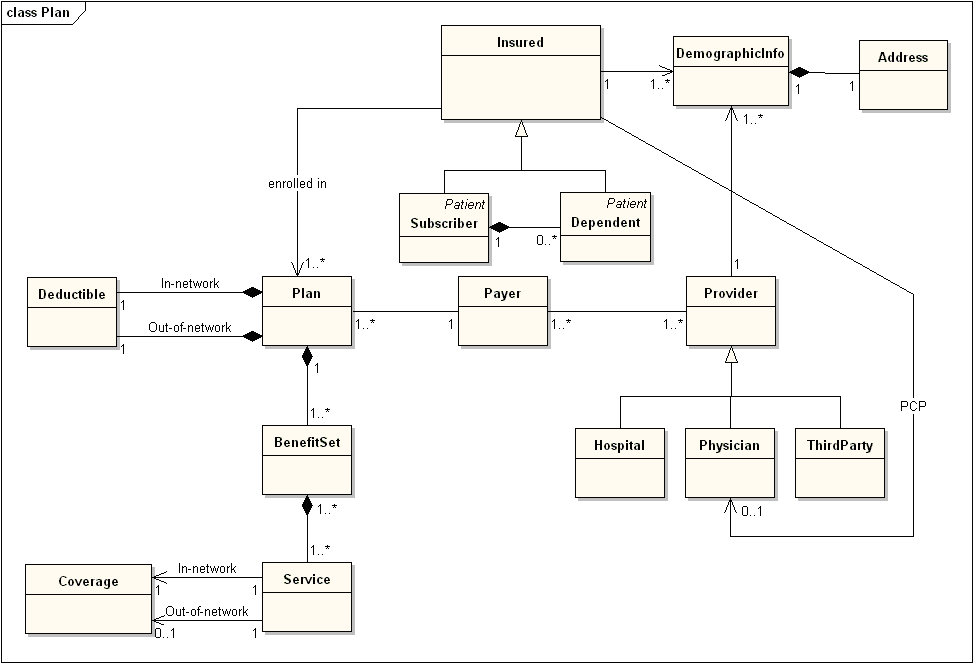
上のような依存関係が
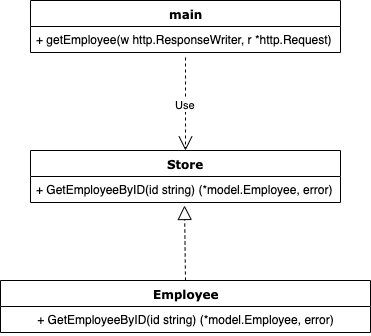
このように変化するためインフラストラクチャー層が依存される側から逆にする格好となり依存関係の逆転関係が起きている。
(インターフェースを満たすという制約の元であるなら自由にインスタンスや構造体を取り替えられるというポリモーフィズムの理解を持っておくとクリーンアーキテクチャの依存関係の制御を理解する上でスムーズであると思います。ポリモーフィズムの記事)
DIPの実装例はこちら
最後にあの図を説明
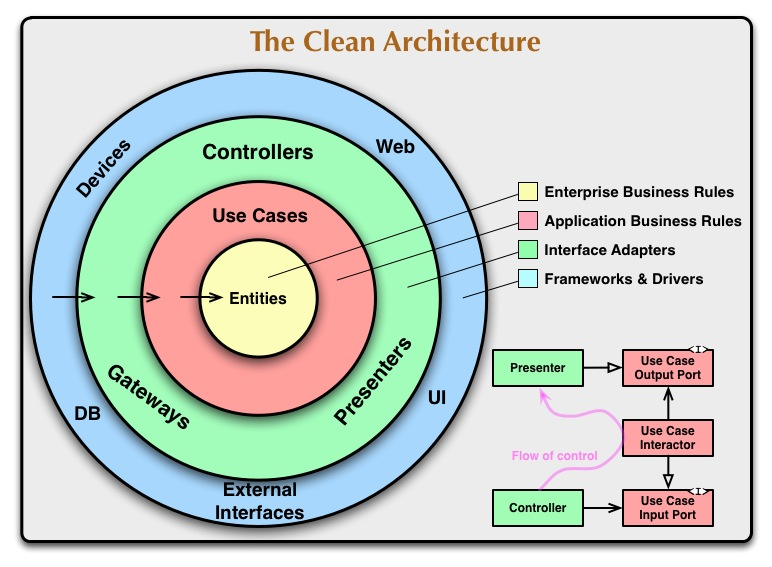
クリーンアーキテクチャについて調べるとよく目にするのがこの図です。何を表しているのかよく分からないこの図ですが、一応説明を試みます。
矢印で表される依存関係の方向
まず、外側から内側にいくほど上位のレイヤになる。Entitiesが一番上位レイヤであり、矢印は依存関係を示しているのでEntitiesはどのレイヤにも依存していない。依存しないというと、内部の円(上位レイヤ)では外部の円(下位レイヤ)の関数や変数、クラスその他プログラムに登場する一切を使用しないということのようだが、しかし実際には、インターフェースを用意することで依存がない形でDBへの永続化処理などを行うので内部の層では外部で定義されているメソッドなどを全く利用しないと思ってしまうと混乱する。また、各層では必要に応じてデータ構造やクラスを定義して各層の間で連携が出来るようにする。クリーンアーキテクチャは依存関係の方向には厳密だが、依存がない形で各層での連携をすることは結構ある。
右下の図
円の図では依存関係はControllers, Presentersが属す円からUse Casesに向かっているのに対し、右下の図ではController→Use Case→Presenterとなっている。これはDIPを適用してこの一見矛盾した関係を解決する。例えば、Presenterの処理をUse Caseで呼び出したい時は、直接呼び出すのではなく必ずPresetnerと共通で持っているInterfaceを呼ぶようにする。そうすることで、Presenterの詳細に依存しなくて済むので依存方向が外側から内側になるように保つことができる。
このように、層をまたがる場合は必ずDIPを適用して依存関係を正しく外側から内側に保つようにしなければならない。
クリーンアーキテクチャの実装例に登場する各レイヤー
インフラストラクチャー層
永続化の処理を行う層。どのDBを使用するか、どのWebフレームワークを使うかなどの技術的な詳細はここに全て記述される。ここでは依存性逆転の原則が適用され、実際にはドメイン層と共通で利用するインターフェースが用意され、インフラストラクチャー層で定義されているメソッドはそのインターフェースの実装になり、その実装の詳細は上位レイヤからは隠蔽される。
この隠蔽のパターンはRepositoryパターンを使っている(必要条件なのかは分からないがそれしか見たことないです)。よくクリーンアーキテクチャの実装例を見るとインターフェースの名前が○○Repositoryとなっているが、それはこのRepositoryパターンを使っているため。 Repositoryパターンについての説明はこちらの記事を読むと良いかと思います。
インターフェースに依存するようにすることで、以下のような利点がある。
- 技術的な詳細に関する変更(DBの変更など)に起因する影響をインターフェースを挟むことで他の層に与えないようにする
- 単体テストをする時に、インフラストラクチャー層のメソッドのモック化が可能になり、DBにアクセスせずに単体テストが行える
なお、「技術的な詳細に関する変更(DBの変更など)に起因する影響をインターフェースを挟むことで他の層に与えないようにする」という文のイメージが湧かない方は、こちらのDIPについての記事を読むと分かるかと思います。
Entities(Domain Model)
Entitiesはドメインを表すのに必要なデータとメソッドを持ったオブジェクトが定義される。ビジネスの根幹となるデータやそのデータに関するメソッドを持ち、ソフトウェアを構築する上で必要となるDBやフレームワークなどその他一切について影響されることはなく、ここにあるものはアプリケーションの中で一番変わる頻度が少ない。ビジネスルールを表現するメソッドを持つが、外部のレイヤに依存してはいけないため、インターフェースを用意してその実装は他のレイヤで行う。
Entityの例を一つ挙げるとすると、ToDoアプリのEntityとして以下のようなものが考えられるだろう。それが持つデータとメソッドはToDoアプリの根幹であることは明らかだと思う。ここではUMLでクラスとして例を示したが、必ずしもクラスである必要はない。

Use Cases
アプリケーションのユースケースを書く。Entitiesで定義したビジネスの根幹となるルールを表すメソッドがいつ、どのような場合に呼ばれるかを定義する。Entityの動きをコントロールするのがUse Casesの役割で、Entitiesで定義されているメソッドを呼ぶ。図からも分かる通り、Entitiesに依存している。
例えば、Facebookのユースケースを例に考える。Facebookでは実名サービスであるため登録名の変更には制限が設けられている。
- ユーザに関する情報をInputとして受け付ける
- そのユーザの前回のユーザ名の変更日から〇〇日以上経過していない場合、エラーとする
- 経過している場合、ユーザ名を更新する(Entitiesのメソッドを呼ぶ)
というのがFacebook上での一つのユースケースとなるだろう。ユースケース層でEntityで登録名変更用に用意されているメソッドを呼び出して変更を試みる。実際は登録名の変更には制限がかかっているが、その制限を表現するのがこのUse Casesになる。
Interface Adapters
EntityやUse Caseと、WebやDBの永続化処理などのために双方にとって最も適切な形にデータを変換するための各種アダプターが定義されているのがこの層である。例えばJSONのバインド処理やUse Case, Entitiesで使われるDBにアクセスする処理の具体的な実装、ハンドラの定義はここで行われる。HTTPリクエストを受け取ってHTTPレスポンスを返すハンドラはまさにControllerとPresenterと言える。
また、データの永続化にSQLを使うのか、NoSQLを使うのかという技術的詳細は全てここで記述され、これより内部のレイヤはその詳細について一切知らない。よって、ここでも技術的詳細の実装は内部と共通で使うインターフェースを満たすようにし、内部の層との依存関係を疎に保つ必要がある。
Controller
Use Caseが使用するデータの入力を受け付ける。フォームなどから受け取った入力を、Use Caseにとって適切な形に変換しUse Caseに渡す。外→内。
Presenter
Use Cases, Entitiesのデータを適切に変換し、外側のレイヤに投げる。DBの書き込み、JSONレスポンスの作成、Viewモデルの生成・表示がされる。内→外。
Framework and Drivers
DBに接続したりloggerの設定などはここで行われる。DBやWebフレームワークなど詳細に関する定義は全てここで行われる。ここの層に内部が全く依存しないことで、この層で定義されている技術(MySQL, Postgres, Echo, gin etc...)は容易に交換が可能となる。
実装例紹介
Go言語でのクリーンアーキテクチャの実装例を10個弱ほど見ましたが、その中で個人的にレポジトリ構成など一番クリーンアーキテクチャを忠実に再現していると感じた実装を紹介して終わりたいと思います。Qiitaの解説記事もありましたので、参照してみるとより学びが深まるでしょう。自分でも実装例を作ってみたいと思います。
https://qiita.com/muroon/items/8add8da911341312176d
参考記事
https://engineer.recruit-lifestyle.co.jp/techblog/2018-03-16-go-ddd/
https://blog.j5ik2o.me/entry/2016/03/07/034646
https://qiita.com/gki/items/f601afbfada85fd8624e
https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html
https://qiita.com/kondei/items/41c28674c1bfd4156186
https://qiita.com/muroon/items/8add8da911341312176d
https://qiita.com/guitar_char/items/b01a89bbb1728c94cd9d
Clean Architecture Robert C. Martin