この記事は、開発を持続可能にできるようなアーキテクチャとその適用方法を考察するものです。
骨子はできていますが、実装経験をフィードバックして詳細を若干変更するかもしれません。
勉強不足な点もあるので、意見を歓迎します。
開発においてよくある問題点
- ビジネスロジックの本質が何だったか見失う。ソースコードのどこまでが業務上の関心で、どこからがそれを実現するための技術上の関心か分からなくなる。
- 入出力双方向の処理が散在して処理が追い切れなくなる。特にイベント処理でどこに飛ぶかわからないコールバック地獄になる。
- 初期化・つなぎ込み・統合者的オブジェクトが小さな機能単位で生まれて統一感が無くなる。
- 状態を持つ値が大量に散在して副作用を起こしバグを生む。
これらの問題の結果、小さな単位ごとに個人のノウハウで"良い"設計がされ、機能を追加しようとしたときにどういう方針で行えばよいか分からなくなる。
解決策
以下の方針を組み合わせることにより、スケールしやすいアプリケーションを目指す。
- ドメイン駆動開発(DDD) ― 業務的関心事であるドメインモデルをソフトウェア開発の中心にすえ、コードやコミュニケーションを常にドメインモデルに反復的に一体化させながら、より価値の高いアプリケーションを生み出していこうとする考え方。
- ユースケース駆動開発(UCDD) ― 外界の存在であるアクターと我々の作るシステムを意識し、ユースケースをビジネスロジックそのものとしてソースコードに落としこむ。
- クリーンアーキテクチャ ― DDDとUCDDに適したアーキテクチャ。「関心の分離」や「依存関係逆転の原則」を順守しやすくなる。
- **処理やデータの流れを単方向に制限する。**双方向の処理を定義するとコードがどこに飛ぶか分かりづらくなるのでやめる。これは注意深く設計されたMVCパターンやFacebookのFluxアーキテクチャでなされていることだ。
- FRP(Functional Reactive Programming) ― 「時間と共に変化する値」と「振る舞い」同士の関係性を宣言するプログラミングスタイル。
クリーンアーキテクチャを採用する
クリーンアーキテクチャとは、8th Light, Inc.のブログ記事で提案されている、**DDDやUCDDに適したアーキテクチャだ。サーバサイドにもクライアントサイドにも適用できる。(Androidに適用している例もあるが、アーキテクチャを3層に独自改変しているように見える。)
**次のアーキテクチャの影響を受けている。
以下の目的に適している。
- ビジネスロジックを明確にする ― ビジネスロジックそのものであるユースケースと、細かい技術的関心が、分離される。
- フレームワークから独立する ― このアーキテクチャは特定のフレームワークやライブラリに依存しない。
- ストアから独立する ― 永続化するツールがファイルでもDBでも、またRDBMSでもNoSQLでもビジネスロジックに影響が無いようにする。
- UIから独立する ― UIは変わりやすい。ビジネスロジックを変えずにwebUIをコンソールUIに差し替えれるくらいにするべきだ。
- 外部との仲介者から独立する ― ビジネスロジックは外界を知らなくていい。
- テストしやすくする - ビジネスロジックはそれ単体でテストできなければならない。
実際には或る程度は妥協して 単機能のライブラリなら依存してしまうのもアリだ。例えば通常のレイヤードアーキテクチャにおいても、「ドメイン層で特定のORマッパライブラリを導入して依存する」と居直れば、ドメイン層とインフラ層で似たような定義を繰り返すことを避けることができる。しかし、フルスタックなフレームワークに完全に依存するべきではない。
また、大きくて複雑なアプリケーションを持続・保守可能にすることに向いているので、小さな使い捨てのアプリケーションではこのアーキテクチャを使わなくても良い。
クリーンアーキテクチャの各層の意味と役割
DDDで使うべきアーキテクチャについて、大まかな区切りと役割を示す記事はあるものの、内部の詳細で使うべきパターンや実際の良い構築方法を示した記事は見当たらなかったので、上記を踏まえて私なりにクリーンアーキテクチャを示す。
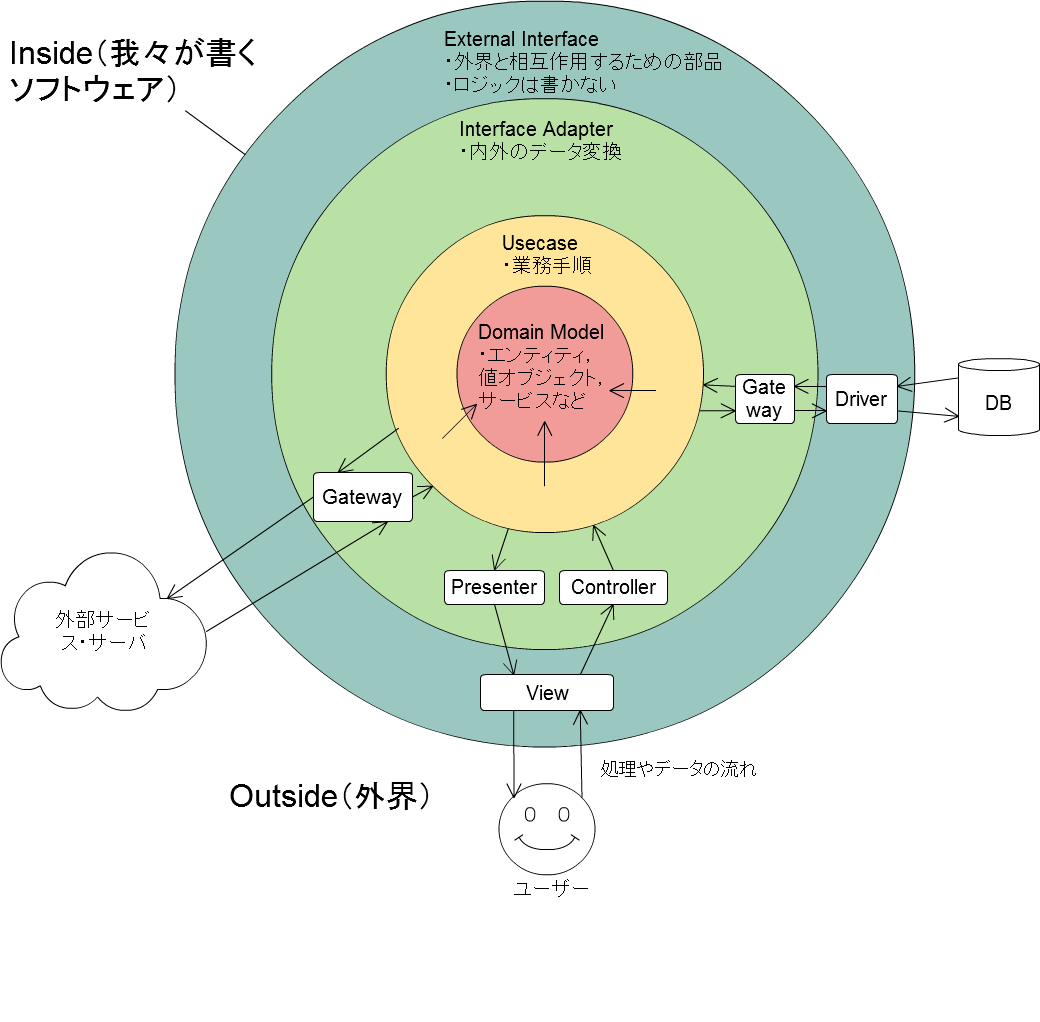
非常に大まかに以下の2つの領域に分けられる。
- Outside ― 外界。ユースケース図のアクターに相当し、我々のソフトウェアは含まないし、書かない。APIを通じてしか干渉できない。(例:ユーザー, DB, サーバー, 外部Webサービス)
- Inside ― 我々が書く領域。Domain Model, Usecase, Interface Adapterを含む。
以下に、主要部であるInsideの中身を内側から説明する。
Domain Model
ユビキタス言語で定義された、ドメイン(アプリケーションが対象とする業務領域)に必要なデータとそれに対するメソッドのセット。
パターン例:ER図,DDDのパターンにおける エンティティ・値オブジェクト・サービス,など
具体例:色相の値オブジェクト,ゲームのAIのアルゴリズムというサービス,など
Usecase
業務の手順を簡潔に記す場所。Input Port, Output Portという抽象を持ち、それらとDomain Modelを用いてビジネスロジックを実現する。各外界への相互作用のハブの役割もする。
パターン例:ユースケース図に書かれた大まかな振る舞い,アクティビティ図やシーケンス図に書かれた手順
具体例:入力フォームからの入力をDBへ出力し、成功・失敗のメッセージをダイアログへ出力する
Input Port
外界からUsecaseへの入力を司る抽象。Outsideからのデータ形式を知らず、Usecase以内で使用可能な形式で返り値をくれる抽象関数を持つ。これは実際にはInterface Adapterで実装される。例えばJavaならinterfaceで定義する。Usecaseが入力を取りに行くPull型と、外界からの変更を検知するPush型がある。
Output Port
Usecaseから外界への出力(副作用)を司る抽象。Domain Modelで使用可能な形式の値を引数に取る関数を持つ。これは実際にはInterface Adapterで実装される。
Interface Adapter
外界との接続や、外界とドメインモデルの間のデータ変換をする場所。外界との相互作用の実装。業務的でない技術的関心事のロジックは全てここに置く。
Controller, Presenter, Gatewayを含む。
Controller
外界からの入力をドメインモデルが使える形式に変換する、Input Portの実装。
例:フォームのイベントを検知し入力文字列をDomain Modelが使える数値へ変換する
Presenter
ドメインモデルのデータ形式を(変換して)外界へ出力する。Output Portの実装。
例:DBへの書込、新たなラベルのDOM追加
Gateway
外界との接続を司る。入出力をControllerやPresenterに分離する必要がなければ、それらを統合してもいい。
例:DBとのrepository, websocketとのconnector
External Interface
外界との境界にあり、相互作用するための部品。**ここには多くのロジックを書かない。**不要なら、Gatewayなどに機能をまとめてもよい。
パターン例:API,MVVMのView,FFI,それらの最低限のラッパ
具体例:html, テンプレート, 生のAPI,ドライバ、フレームワークなど
Usecaseで抽象を定義して利用し、Interface Adapterでそれを実装するのは、「依存関係逆転の原則」に従うためだ。相互作用の実装はビジネスロジックの抽象に依存すべきで、逆であるべきではない。つまり、ドメインは外界を知らないようにする。
その他の部分
次の機能はアプリケーションの本質ではないので、先の構造とは独立して置いておく。
- test ― テスト。Insideのディレクトリ階層をそっくり真似したtestモジュールにくくりだす。private関数の単体テストはInsideに含めても良いかもしれない。
- utility ― どの層でも使うようなライブラリなど。例:FRPのライブラリ
依存関係を整理する
内側のビジネスロジックが外界や技術的関心事を知らないようにするために、次のような依存関係にする。
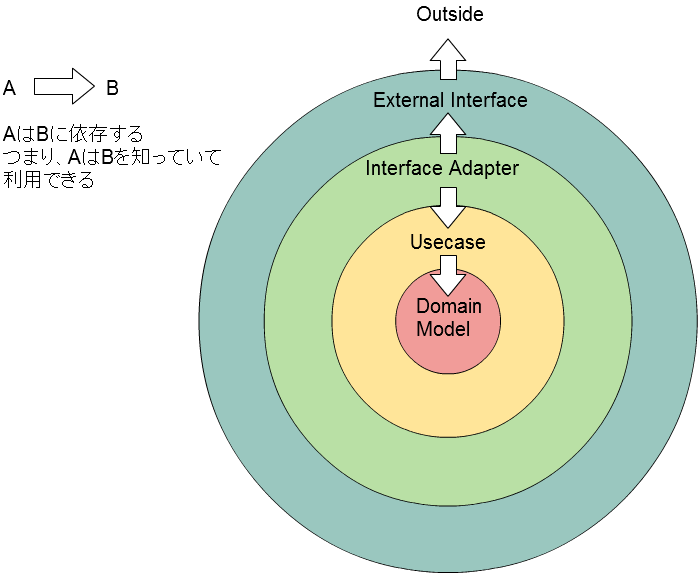
Clean Architectureの元記事には、内側に一方向へ依存するようにすると書いてある。しかし現実には、External InterfaceからDomain Modelまで一方向に依存するのはムリだろう。だから、External Interface(もしくはそれがなければInterface Adapter)は現実の汚さを吸収するために、外界(API)にも依存していいものとする。そもそもデータ変換は内外を知らないと不可能なので、Interface Adapterは内外に依存するしかない。
そして重要なのは、抽象であるInput/Output Portが外界を知らないようにすることだ。そのために、Input/Output Portの関数は**引数も返り値も、Domain Modelで知っている型かvoidにする。**外界のデータ構造を知らなければできないことは、Interface Adapterの細かいprivate関数などで行うべきで、Usecaseは知らなくていい。つまり、継承関係も含めて次のようなクラス図になる:
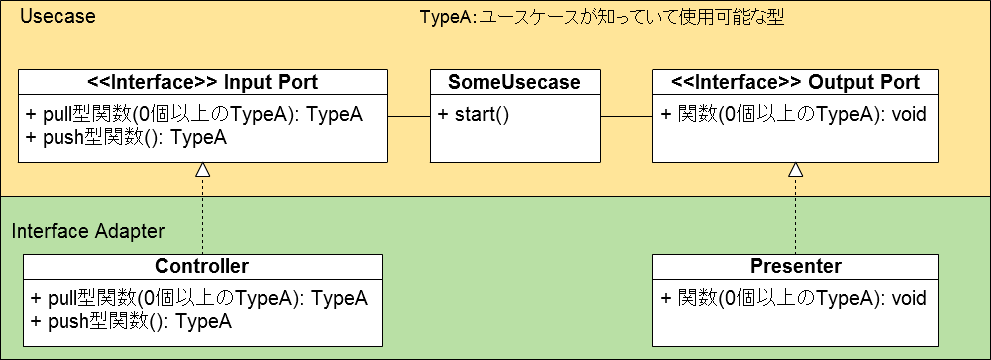
過度に抽象化して依存性を一方向にすることが重要なのではなく、ビジネスロジックが外界を知らないようにすることが重要なのだ。
データ・処理の流れを単方向にする
データ・処理の流れはなるべく単方向にするべきだ。1つの関数やフローで入出力双方向に処理を始めると、とたんに制御が複雑になってしまう。特に、クライアントサイドのようなイベント駆動の場合は、双方向にすると処理がどこに飛ぶか追いづらくなるので、特別な理由がなければ絶対に単方向にするべきだ。
外界とのデータ入出力は単方向に分離し、ビジネスロジックの実現はユースケースに任せる。
ユースケース単位で処理を単方向にする
まず、1つのユースケース単位で処理を単方向にしたい。ユースケースが利用するインターフェースには、大きく分けて次の方式があると考える(他にもあるかもしれないが):
- UI― ユーザーが見て操作する機能
- Store ― データを永続化し取り出す機能
- Socket ― 外部サーバと通信して利用する機能
これらのインターフェース方式同士の相互作用は、ハブとなるUsecaseで行う。例えば、UIがデータを変更したらUsecaseはStoreのOutput Portの処理を呼んで永続化する。
1個のUsecaseの制約として、どこか1つ以上のインターフェース方式からの入力を、どこかの1つ以上のインターフェース方式へ出力して終わる、というようにすると単方向の処理を保てる:
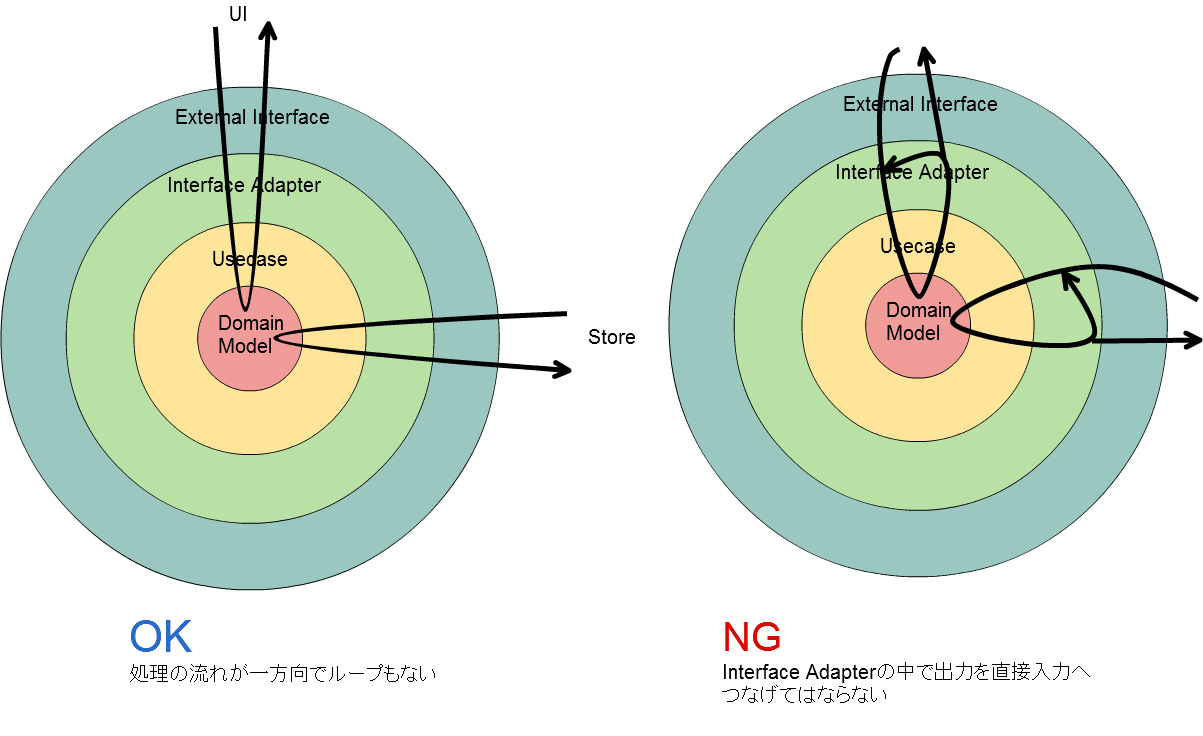
ここで、Input PortとOutput Portは互いに依存してはならない。つまり、Interface Adapterで出力を入力につないでループを作ってはいけない。(リクエストしてレスポンスを受け取るような場合はどうするのかと思うだろうが、それは単一のPull型Input Portなので問題ない。)何を入力に使うかを出力は知ってはいけないし、逆も然りだ。それを許すと、途端にどちらかにビジネスロジックが侵入して肥大化する。何を入力にするかはUsecaseだけが知っていて、そこがハブとなる。
各インターフェース方式を単方向にする
次に、各インターフェース方式の中でどうやって処理を単方向にするか考える。
UIはたいていイベント駆動であり、注意が必要だ。双方向の処理を書くと破綻しやすいので、UIは入力を検知するControllerと出力するPresenterに完全に分離する。
Store, Socketは、よほど複雑でなければ各ユースケースに単一のGatewayなどを作って、接続・入力・出力の関数をまとめて置いておいて良いと思う。
注意しなければいけないのは、入力を非同期処理にしなければ全ての処理がストップしうるということだ。
以上を踏まえると、UIだけの処理をする典型的なユースケースの処理の流れはこうなる(特にFRPなどをしない場合):
- Controllerが、トリガとなるイベントに対し Usecaseの関数をコールバックとして登録しておく。コールバックにはデータをUsecase向けに変換し渡す。
- Usecaseが、Domain Modelを用いて業務処理をした後、Output Portの関数を呼ぶ。
- Presenterが、受け取ったデータをExternal Interface向けに変換し、External Interfaceの中身を書き換える。
FRPを導入する
これまでの制約を守りさえすれば、どこに何を書くべきか分かるので、十分開発しやすくなる思う。ただ、FRPを導入してプログラムを宣言型で書くことでバグを減らせる。複数のアクションが同じ処理のトリガーになることもあるので、ストリームを合成できるFRPを導入することは有用だ。
FRPとは、「時間と共に変化する値」と「振る舞い」同士の関係性を宣言するプログラミングスタイルだ。リアクティブプログラミングとMVVMパターンについて というスライドが分かりやすい。そして、様々な言語でFRPのために使えるReactive Extensionsというライブラリが用意されている。
クリーンアーキテクチャに導入する場合、Input/Output Portでデータ変換ストリームを宣言しておき、Usecaseでそれを合成してビジネスロジックを実現することになる。つまり:
- Input Portが、外界からの入力イベントを検知し変換するストリームを宣言し公開。
- Usecaseが、Input Portを入力に、業務手順のストリームを宣言し公開。
- Output Portが、UsecaseやInput Portを入力してストリーム合成し、Subscribe内でview操作など副作用を起こす。
実案件でRxJSと合わせて使ってみた
Clean Architectureで設計してRxJSを使った話
実際の構築の仕方
ユースケースの処理を開始・登録する順番はどうするべきか?
用いる言語がオブジェクト指向だったら、インスタンスを生成しなければならないだろう。
ソフトウェアにはエントリーポイントがあり、当たり前だが、最低限のインスタンス化や初期化、つまりブート処理をするにはそこしかない。サーバサイドならmain()関数、Webのクライアントサイドならhtmlのscriptタグになるかもしれない。エントリーポイントはどこかの層に完全には含まれず宙に浮いているものと見なしていいと思う。
エントリーポイントが保持すべきは機能は次のものだ:
- Initializer ― 必要なオブジェクトのインスタンスを生成する。UsecaseにInterface Adapterを渡しつつ生成することで、依存性を注入するDIコンテナとして働く。それ以外の初期化はしない。オブジェクト指向でない言語なら要らないかもしれない。
- Starter ― Initializerがオブジェクトを生成した後に、能動的にユースケースを開始する。他のオブジェクトの準備を整えてユースケースを開始する場合に必要となる。例:websocketサーバとの接続
エントリーポイントの周りでは最低限のブート処理だけするべきで、あとは各モジュールに任せるべきだ。
テストのしやすさ
次の理由から、クリーンアーキテクチャをとるとテスト駆動開発(TDD)がしやすいはずだ。
- 1つのユースケース単位でまとまっているので、統合テストしながらユースケースの構築ができる。
- ユースケースが直接利用するのは抽象であり、依存性は注入するので、実装をモックで差し替えてテストするのが容易。
エラー処理はどうする?
ユースケースレベルのエラーは、そこでキャッチして処理する。例えば、「ユーザーが指定したキーがストアにあれば書き換え、無ければユーザーに"値がありません"というダイアログを見せる」というユースケースがあったとする。その場合はRepositoryの中でエラーを投げて、ユースケースでキャッチし、適切なフローへ切り替えるようにする。
また、成功・失敗を内包した型で鉄道指向的にプログラミングしたい場合も、Input/Output Portの関数でそのような型を扱うようにすれば良い。
○○はどの層に置くべき?
設計の粒度に依ったり、例外はあるかもしれないが、「業務上の関心ならUsecase以内に置く」という原則で判断する。
- 設定ファイル:ビジネスロジックに関する設定ならユースケース単位でUsecaseに置く。データ変換などに関する設定ならInterface Adapter。ビルドなど全体に関わることなら外部に独立して置く。
- 並列処理:ただの高速化手段。ビジネスロジックならDomain ModelやUsecase。変換を並列化したいならInterface Adapter。
- 状態を持つオブジェクト:業務上の関心事ならDomain Model。業務と外界との調整役ならExternal Interfaceか、それがなければInterface Adapter。
- ORマッパによるテーブル定義やエンティティ:どこまで仕事を肩代わりしてくれるかによる。DBへの永続化を完全に隠蔽してくれるなら、Interface Adapterの必要ない高機能なDomain Modelとして扱える。
よくあるレイヤードアーキテクチャではダメだったのか?
私の意見ではダメではないが、オニオン型の方が自然だ。
The Onion Architecture や Hexagonal architecture には、"典型的"なレイヤードアーキテクチャの欠点が書いてあるが、それはわざわざアーキテクチャをオニオン型にしなくても、 Domain-Driven Designのエッセンス 第2回 DDDの基礎と実践 の中に一部書いてあるような 次のことを気をつけるだけで避けれるものだ。
- スマートUIパターンを使わない(UI層にビジネスロジックを書かない)。
- 依存関係はなるべく1方向、下の層にのみ依存するようにする。
クリーンアーキテクチャももちろんそれを順守すべきなので、結局、"良い"レイヤードアーキテクチャに比べた"良い"クリーンアーキテクチャの違いはこうなる:
- UIがDBなどと同様に外層に置かれる
- ユースケースが単一の層として明確に分離されている
これらの何が良いのか?
1点目については、「ユーザ・通信・データベースとのインターフェースを全て統一的に外部との相互作用と見なせる」ことにより、今までのUI層やそれに関連するApp層の部分が他の相互作用と似た観点で書きやすくなり、スマートUIパターンを避けやすくなることだ。
2点目については、ユースケースというビジネスロジックそのものを、設計からコードに簡単に落とし込めるようになることだ。ウォーターフォール、アジャイル問わず、コードから仕様へのフィードバックもしやすい。
あとは、自分のソフトウェアと外界との区分けの意識が高まることも重要だ。(そもそも私は、UIが外部でDBが内部、のような分け方に疑問を持っていた。オニオン型のアーキテクチャは、視点が統一的で自然なのでしっくりくる。)
Fluxアーキテクチャとの違いは?
Fluxアーキテクチャの特徴は次の通りだ。ベストプラクティスとされるパターンに命名して確立しただけで、決して革新的なわけではない。
- 全ての処理をイベント駆動に統一した。
- メッセージングを単方向に制限した。
- イベント同士の依存性を管理するのは、Dispatcherというハブが行う。
全体をイベント駆動にする場合は、Fluxアーキテクチャを参考にできる。また、メッセージングや処理を単方向に制限するのは有用だ。ストアへの処理の時系列を整理するハブについては、クリーンアーキテクチャにはUsecaseがあるし、これの方がビジネスロジックに直結していて分かりやすく、色んなインターフェース方式に対する処理を含む点で汎用的だと思う。