はじめに
この記事では、OpenShift上でRAGに対応した生成AIチャットボットアプリを起動するまでの手順を説明します。少々長い記事にはなりますが、なるべく簡単に誰でも再現可能な手順を目指していきますので、どうか最後までお付き合いください!
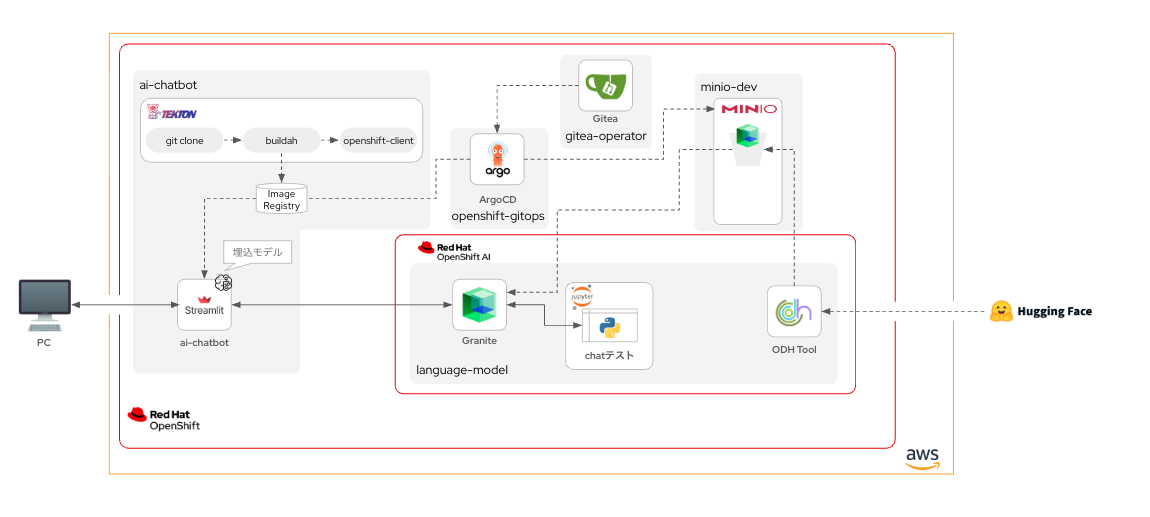
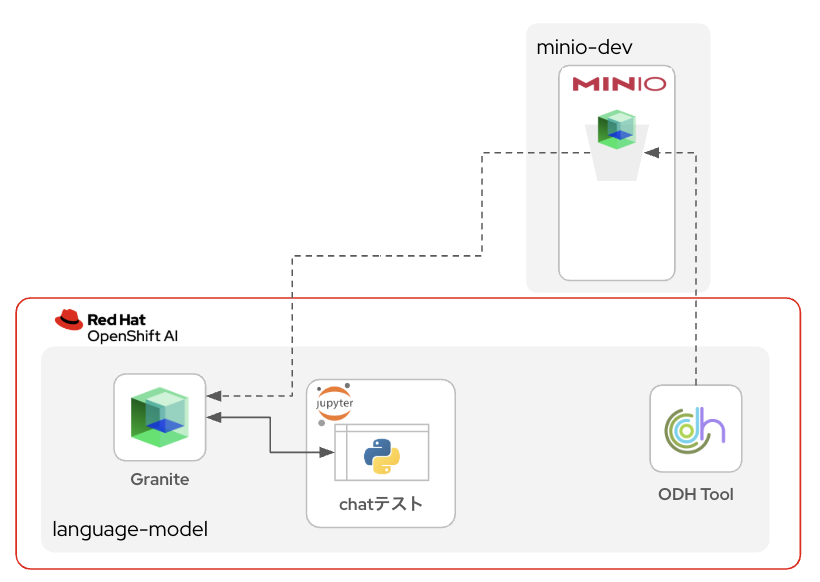
この記事で最終的に作成するチャットボットの構成イメージ
この記事を通して、以下のようなRAG対応のAIチャットボットを作成していきます。
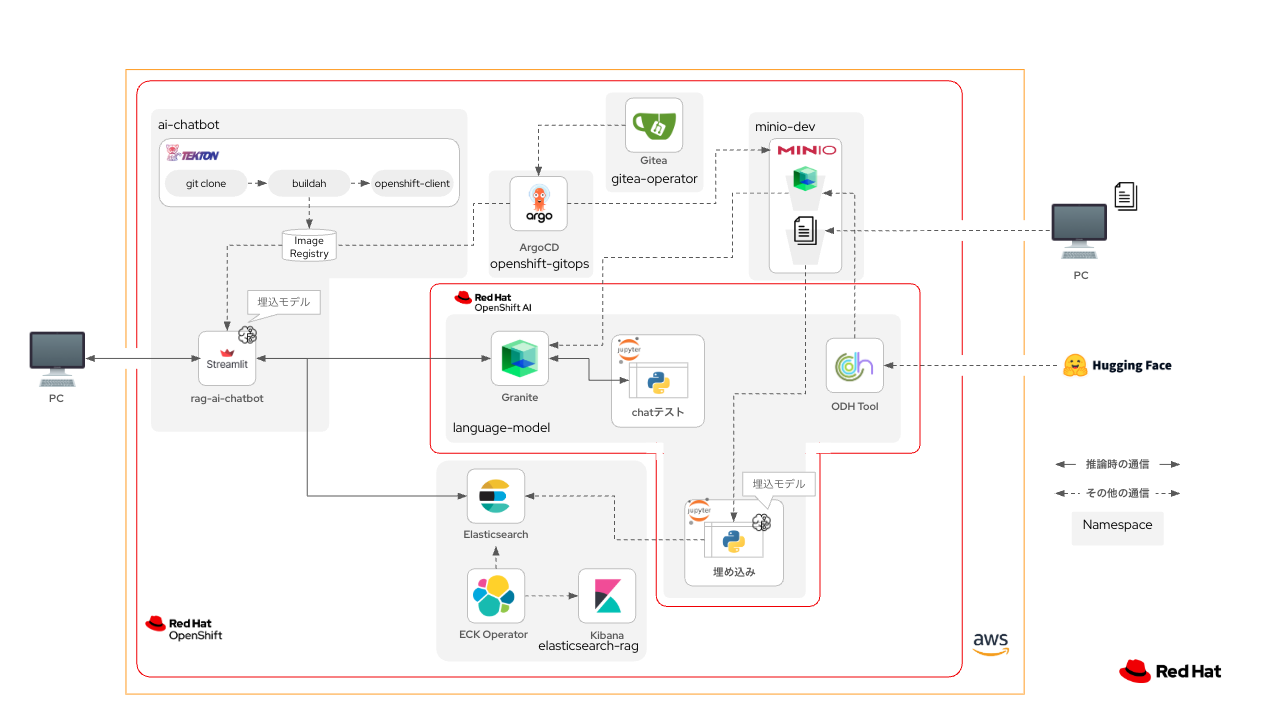
この生成AIチャットボット環境は、それを構成するコンポーネントすべてがOpenShiftの上で動いています。つまり、生成AIが回答を生成(推論)する際に、OpenShiftクラスタの外と通信する必要がありません。これにより、非常にセキュアな環境を実現できます。
チャットボットの画面
このアプリは後述する「Streamlit」というPythonのフレームワークを活用し、簡単なチャットボットインターフェースを作成します。
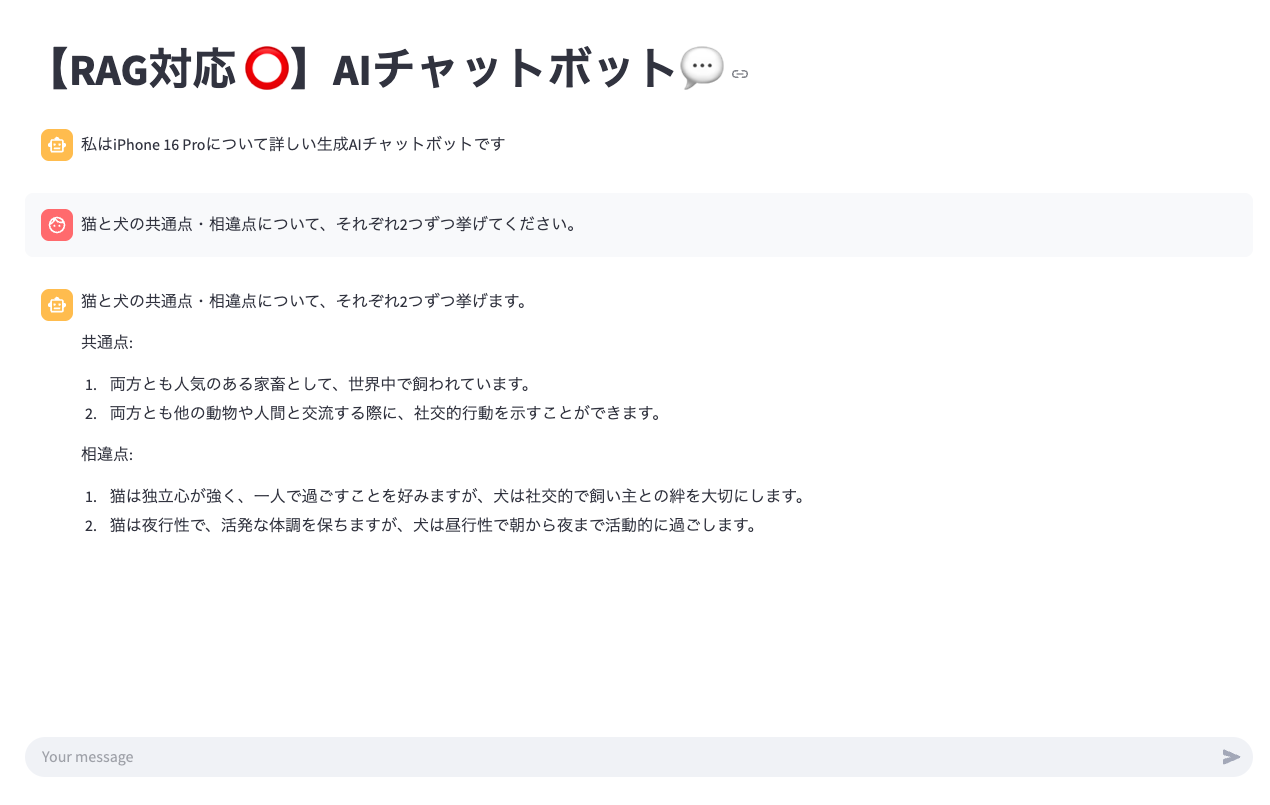
こんな感じで、「よくあるチャットボット」を誰でも簡単に作成することができます。HTMLやCSSなどは不要で、Pythonコードだけでこういったアプリが作成できるのが、Streamlitの特徴です。
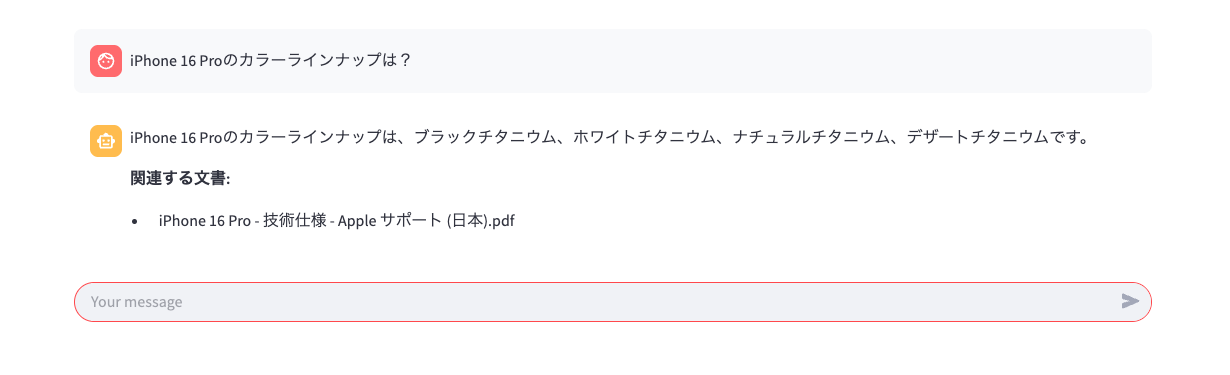
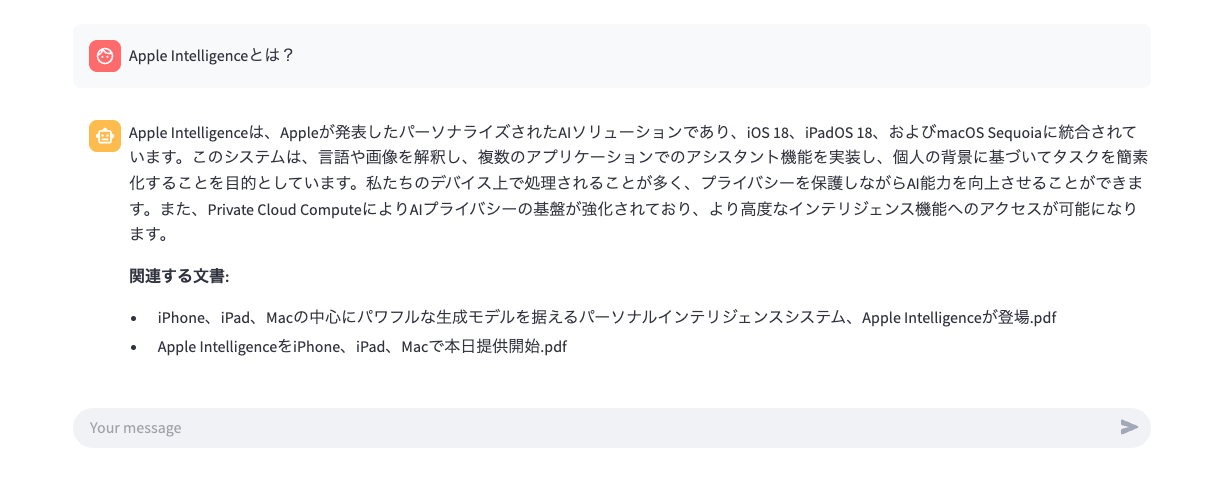
もし言語モデルが事前に学習していない内容に関する質問をした場合、ベクトルストア(ベクトルデータベースともいう)にアップロードしておいたドキュメント情報をもとに回答してくれます。こうした技術をRAG(Retrieval-Augmented Generation、検索拡張生成)といいます。
まずは、この最終系を構成するための技術や各コンポーネントについて簡単に説明していきます。
本記事は、すでにRed Hatのホームページで公開されている内容(英語)を元に、日本語での丁寧な解説と、vLLMでの実装のためのソースコード変更や、一部コンポーネントの設定の最適化を行っていきます。元ネタにご興味ある方は、一度ご覧ください。また、チャットボットアプリ(RAG非対応)をデスクトップPCで試したい場合は、ぜひ一度元記事を見てお試しください。
RAGについて
今回のチャットボットで実装するRAG(Retrieval-Augmented Generation、検索拡張生成)とは、言語モデルが回答を生成する前に、外部のデータソース(例:ドキュメントやデータベース)から関連情報を検索し、それをもとに回答を生成する手法です。これにより、モデルが持つ知識の限界を補い、より正確で信頼性の高い応答を追求することができます。今回はRAGを実現するためにベクトルストアを活用します。
ベクトルストア
ベクトルストアは、文書を意味的に表現したベクトルとして保存・検索できるデータベースです。RAGにおいては質問に関連する情報を効率的に検索する役割を担います。つまり、質問に最も近い文脈を取得し、それをもとに言語モデルが回答を生成できるわけです。
ドキュメントをベクトルストアに格納するには、まず参照するドキュメント(今回はPDF文書を利用します)をある一定のまとまりにチャンキング(Chunking、分割)します。
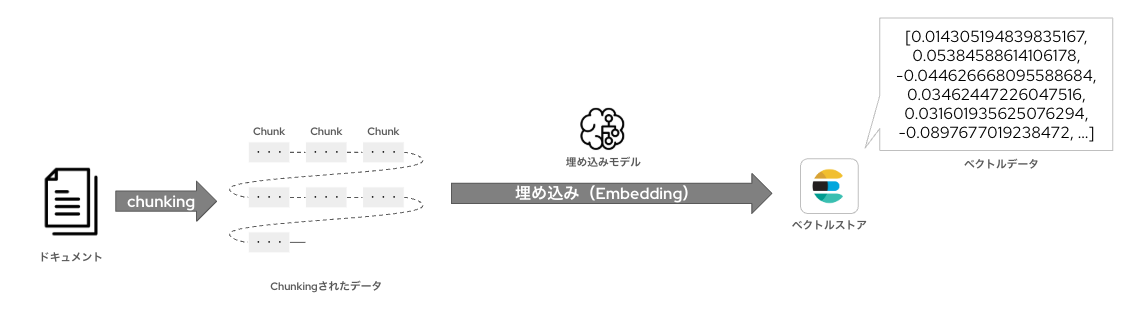
その後、「埋め込みモデル(embedding model)」を使って、各ドキュメントを分割した単位(チャンク)を数値ベクトルに変換します。これにより、テキストの意味や文脈を数学的な特徴量として表現できます。変換されたベクトルは、ベクトルストアに保存されます。
埋め込みモデルは、文章や単語などのテキストを数値ベクトルに変換するためのモデルです。このベクトル表現によって、テキスト同士の意味的な類似度を計算したり、検索や分類などのタスクに活用できるようになります。
RAG(Retrieval-Augmented Generation)では、あらかじめベクトル化されたドキュメント群と、ユーザーからの質問(プロンプト)を同様にベクトル化したものとの間で、意味的な類似度を計算します。

最も類似度が高いドキュメントは「参照情報」として選ばれ、その内容がプロンプトに追加されるかたちで、言語モデルに入力されます。これにより、モデルは外部情報に基づいた、より正確で文脈に沿った回答を生成できます。プロンプトをベクトル化する埋め込みモデルは、今回のケースではチャットボットアプリの内部で動作します。
なお、今回はベクトルストアとして「Elasticsearch」を利用します。
Elasticsearchは、Elastic社が主導して開発している、高速でスケーラブルな全文検索と分析を行うためのオープンソースの検索エンジンです。構造化データやログ、テキストなどをインデックス化し、リアルタイムでの検索や集計が可能です。
なお、RAGの仕組みについて詳しく知りたい方は、Elastic社のホームページを見ていただくことをお勧めします。とても詳細かつわかりやすく書いてくれています。
なお、今回はElasticsearchのGUIとして利用できる「Kibana」もデプロイします。ElasticsearchおよびKibanaは、Elastic社が提供している「Elasticsearch (ECK) Operator」を利用して簡単にデプロイします。
オブジェクトストレージ
RAGで利用するドキュメント一式を一時的に格納しておくために、オブジェクトストレージを利用します。オブジェクトストレージは、ファイルを「オブジェクト」として扱い、メタデータと一緒に保存するストレージ方式です。スケーラビリティに優れ、画像・動画・バックアップデータなど大容量データの保存にも適しています。
今回はオープンソースで利用可能なMinIOを採用します。
MinIOは、Amazon S3と互換性のある高性能なオブジェクトストレージソフトウェアです。軽量でスケーラブルな設計により、クラウド・オンプレミス問わず手軽に分散ストレージ環境を構築できます。OpenShiftの上にデプロイして利用することも可能です。GUIもあるので、非常に直感的なオブジェクトの管理が可能です。
なおオブジェクトストレージは内部に論理空間として「バケット」と呼ばれる単位を設けることができます。今回は「doc」というバケット内に参照するドキュメント(PDFファイル)を格納します。また、詳細は後述しますが、言語モデルのデータも、HugginfaceからMinIO内にダウンロードしてきてから扱います。言語モデルは「models」というバケットに格納します。

チャットアプリ
チャットアプリはPythonのWebアプリケーションフレームワークである「Streamlit」を活用します。これによりHTMLやCSSが不要で、Pythonファイル(.py)のみから簡単にWebアプリを作成できます。

こんな感じのAIチャットボットが、Pythonコードだけで簡単に作れます。なお、このアプリが言語モデルと通信したり、ベクトルストアを利用してRAGを実行する際には、Pythonのフレームワークである「LangChain」を利用します。
LangChainとは
LangChainは、言語モデルを活用したアプリケーション開発を支援するPythonフレームワークです。外部データ(Web、PDF、データベースなど)との連携や、検索、対話、ツール実行を組み合わせたエージェント的な動作を簡単に構築できます。これを用いることで、ChatGPTのような、言語モデルを業務システムに組み込む際の「つなぎ役」を担わせることが可能です。

上記の絵の様なRAGの仕組みを一から手作業で実装するのは非常に困難です。しかし、LangChainが提供するライブラリを活用すれば、わずかなコードで「拡張生成による回答(Retrieval-Augmented Generation)」を実現できます。LangChainは、埋め込みの作成・ベクトル検索・プロンプトの拡張・言語モデルとの連携といった一連の処理を抽象化しており、RAGの構築を大幅に簡素化してくれます。
CICD
チャットアプリはPythonのコードを含むアプリケーションのソースコードや依存関係一式をコンテナイメージとしてビルドし、マニフェストファイルによってデプロイします。この一連の流れをパイプラインとして管理します。これらにより、Git上に保存されているアプリのソースコード変更を検知し、自動でコンテナイメージの再ビルド、さらにOpenShiftクラスタへの自動デプロイを行います。
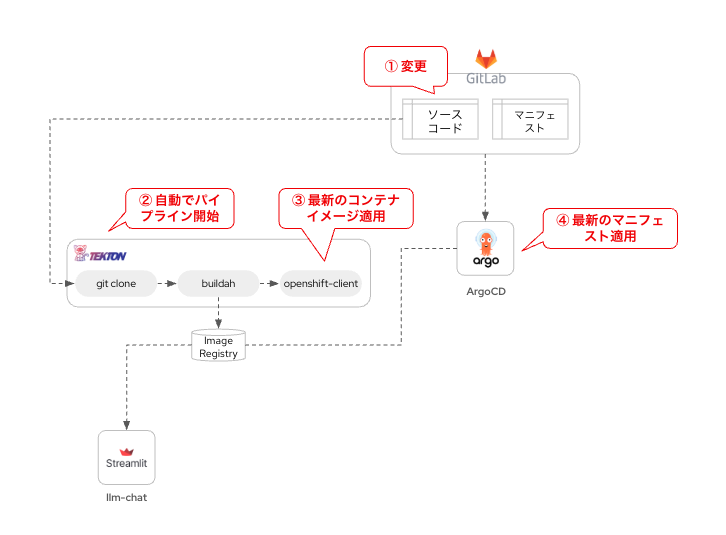
ここでOpenShiftの標準機能として利用可能な2つのOperatorを活用します。
ひとつは「OpenShift Pipelines Operator」です。

これは、OSSのパイプラインマネジメントツールである「Tekton」をRed Hatによるエンタープライズサポート付き機能としてOpenShiftに取り込んだものです。オリジナルのTektonが用意する豊富なTaskテンプレートを活用し、ローコードでパイプライン作成や編集が可能です。また、オリジナルのTektonにGUIが具備され、圧倒的に直感的な操作が可能な点で優れています。
次は「OpenShift Gitops Operator」です。

こちらは、OSSのArgoCDをOpenShiftに組み込んで提供しています。Gitリポジトリに格納したマニフェストファイル(Single Source of Truth)を自動的にKubernetesクラスタに適用してくれる、GitOpsを実現するための要です。
なお、Tekton及びArgoCDを活用したOpenShiftにおけるCICDについては、私が書いた別の記事に詳細を記載しております。今回の内容にも関わるので、一度お目通しいただくことをお勧めします。
環境情報
本記事ではAWSのマネージドサービスとして利用できる「Red Hat OpenShift Service on AWS」、通称”ROSA”を利用して、AIチャットボット構築をしていきます。また、ROSAを含むOpenShiftの有料アドオンとして利用可能な「Red Hat OpenShift AI」を利用し、言語モデルのサービングやJupyterLab環境の構築を行います。
2025年4月から、AWSのMarketplaceから従量課金で利用できるOpenShift AIが提供開始されました。ROSAと組み合わせることで、よりスモールスタートしやすくなっています。1vCPUあたり1時間$0.022から利用可能です。
ROSAの前提条件
今回は以下の環境で実施していきます。
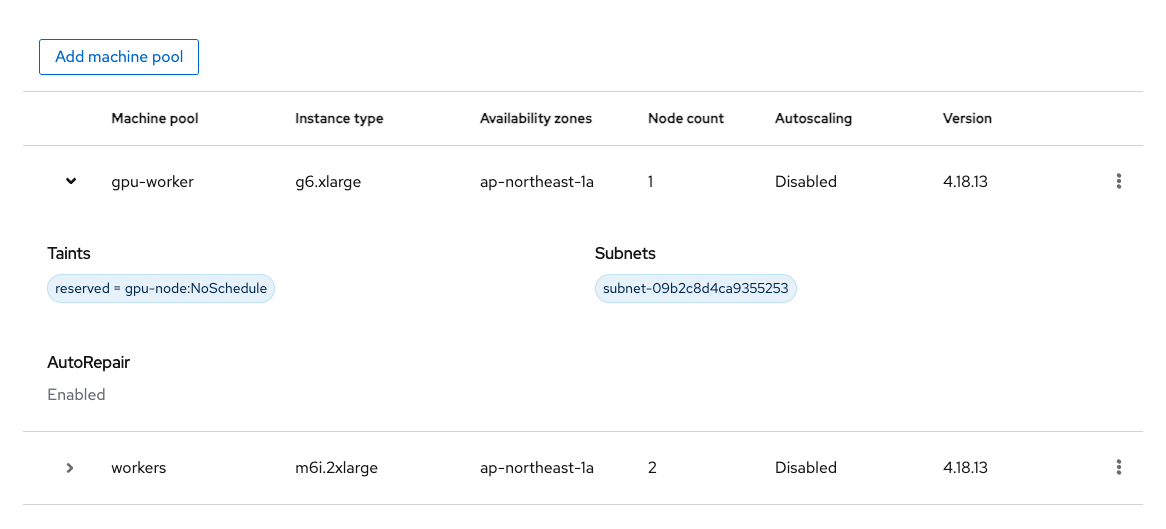
- 通常のComputeノード:m6i.2xlarge × 3台
- GPUノード:g6.xlarge × 1台
- Taintsに以下の設定を行い、許容されたPodのみがスケジュールされるようにする
- Key: reserved
- Value: gpu-node
- Effect: NoSchedule
- Taintsに以下の設定を行い、許容されたPodのみがスケジュールされるようにする

「gpu-worker」というMachinePool名で、g6.xlargeを1台プロビジョニングしています。なお、g6.xlargeはNVIDIA L4 Tensor Core GPUを1機搭載し、GPUメモリは24GBが実装されています。ディープラーニング推論およびグラフィックスワークロードにおいて一定のパフォーマンスを提供可能とされています。vCPUは4コア、メモリは16GBであり、今回利用する言語モデル「ibm-granite/granite-3.3-2b-instruct」は動作可能なはずです。
ROSAクラスタに後からGPUノードを追加する場合、「Red Hat Hybrid Cloud Console」のGUIで簡単に実施できます。詳細なやり方については以下に詳しく書かれています。
さて、前置きはこの程度にしておいて、さっそく作業を進めます。とはいえ、いきなりRAGの実装まではやりません。今回は、OpenShift上でAIチャットボットを作成する手法について、Step by stepで進めていきます。そのため、まずは「RAG "非" 対応版AIチャットボット」を作成します。

一旦はここまで構築することを目指しましょう。まずは必要なOperatorをガガっとインストール&設定していきます。なお、以下の操作はすべてcluster-admin権限を持つアカウントで実施しています。それではさっそくやっていきましょう〜!
必要なOperatorをインストール
OperatorHubから以下のOperatorをインストールしてください。インストールするOperatorは以下の通りです。
- OpenShift Gitops
- OpenShift Pipelines
- Node Feature Discovery(NFD)
- NVIDIA GPU Operator
- Red Hat OpenShift Serverless
- Red Hat OpenShift Service Mesh 2
- Red Hat OpenShift AI
- Web Terminal
- Gitea Operator
ちょっとてんこ盛りですが、頑張っていきましょう。なお、一部のOperatorにはインストール時に設定が必要だったり、インストール後にカスタムリソースの作成が求められます。
OpenShift Gitops
OperatorHubで同Operator名を検索&選択し、

「インストール」をクリックし、

次の画面もデフォルト設定のまま「インストール」をクリックします。
インストールが完了し、必要なリソースが自動的にデプロイ完了すると、画面更新を促すポップアップが出ますので、指示に従ってください。

画面を更新してから、OpenShiftコンソール画面右上の「アプリケーションランチャー」をクリックすると、「Cluster Argo CD」というメニューが増えます。

ここからArgoCDのログイン画面に簡単に移動することが可能です。
OpenShift Pipelines
OpenShift Gitops Operatorと同様に、インストールを行い、画面更新指示に従います。

すると、OpenShiftのコンソール画面の右側に「Pipelines」というメニューが増えます。

ここまでで、CICDを実現するために必要なOperatorのインストールが完了しました。
Node Feature Discovery(NFD)
Node Feature Discovery Operator(NFD Operator)は、OpenShiftやKubernetesクラスタ内の各ノードに存在するハードウェアやシステムの特徴(CPU、GPU、NUMA、NIC機能など)を自動的に検出・ラベル付けするためのオペレーターです。これにより、Podのスケジューリング時に「特定の機能を持つノードだけを選ぶ」といった精緻な配置制御が可能になります。これは、この後インストールする「NVIDIA GPU Operator」を利用する際の依存関係として必要なものです。
なお、Oepratorはこれまでと同様、OperatorHubからインストールします。

NFD Operatorは2種類出てきますが、Red Hatが提供する方を選択してください。
インストールが完了したら、「Operatorの表示」をクリックし、カスタムリソース「NodeFeatureDiscovery」を作成します。
デフォルト設定で作成します。

NVIDIA GPU Operator
NVIDIA GPU Operatorは、Kubernetesクラスター上でNVIDIA GPUのドライバ、ランタイム、ツール群(CUDAなど)を自動的にデプロイ・管理するためのオペレーターです。これにより、AIやHPC(High Performance Computing)ワークロードのためのGPU環境を、手作業なしで一貫性のある形で構築できます。NFD Operatorと連携して、GPUを搭載したノードに自動的にラベルを付与し、GPU対応ワークロードが適切なノードにスケジュールされるよう制御できます。
OperatorHubで同Operator名を検索&選択し、「インストール」をクリックします。

NVIDIA GPU Operatorもカスタムリソースの作成が必要です。また、少し設定変更が必要です。インストールが完了したら、まずは「Operatorの表示」をクリックし、「ClusterPolicy」タブに遷移、「ClusterPolicyを作成」をクリックします。
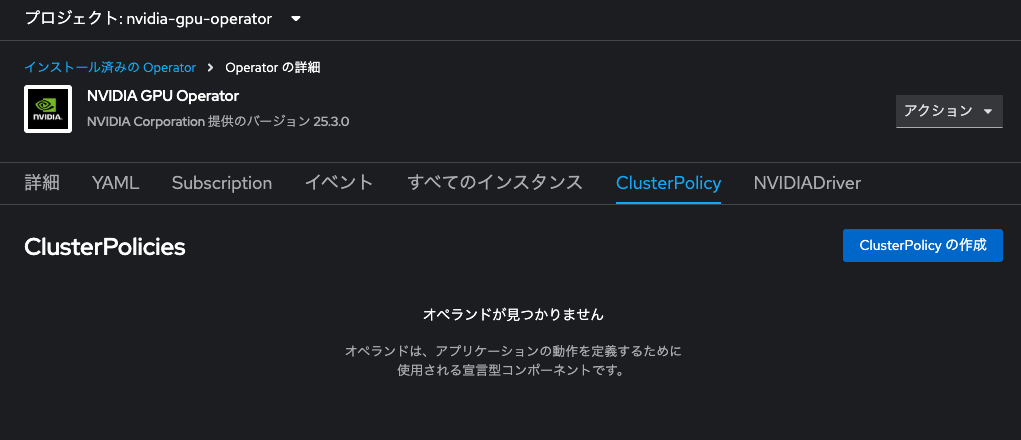
ClusterPolicyを作成すると、GPUノードにDaemonSetがデプロイされます。が、DaemonSet Podのスケジュールを許容するには、先に設定したTaintに対応するtorelationの設定が必要です。設定方法は2通り存在します。
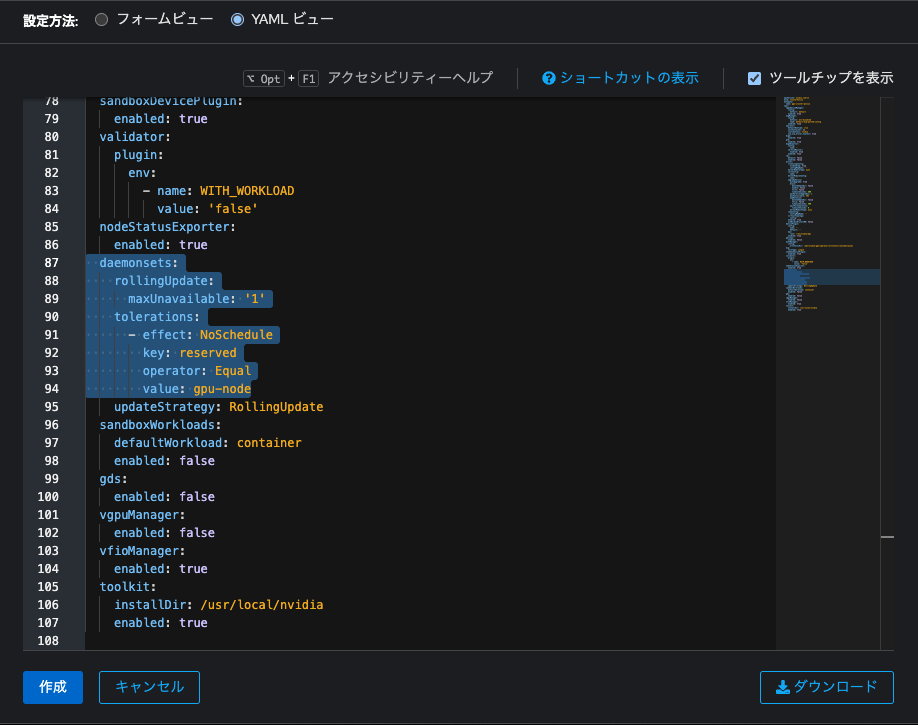
YAMLビューでマニフェストを設定
YAMLビューのspec.daemonsetsを、以下の通り設定します。
spec:
...
daemonsets:
rollingUpdate:
maxUnavailable: '1'
tolerations:
- effect: NoSchedule
key: reserved
operator: Equal
value: gpu-node
...
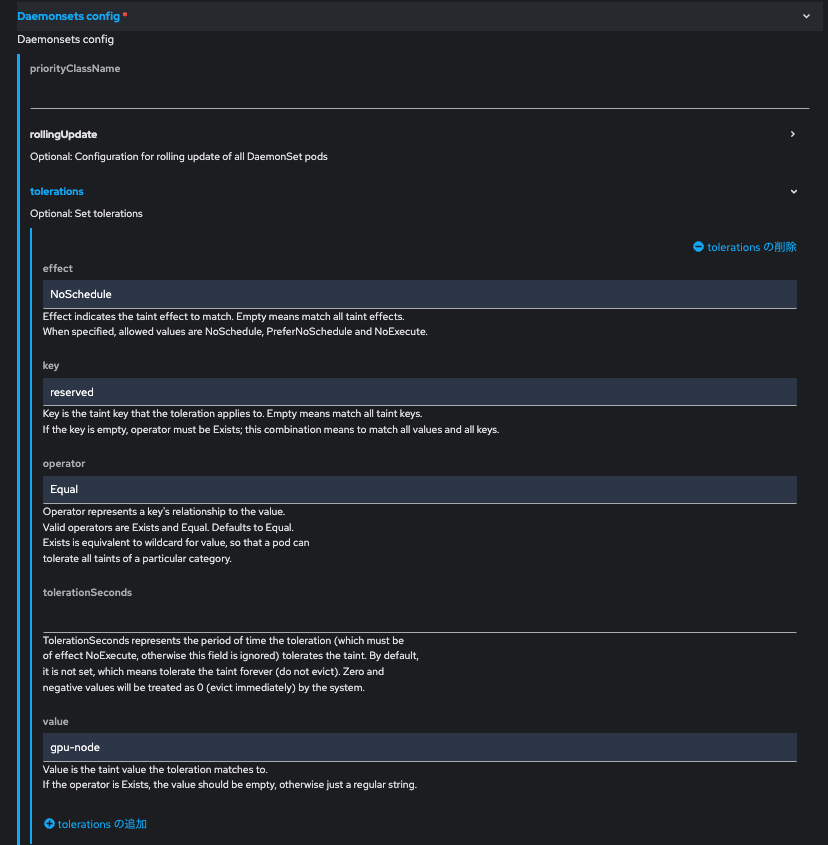
フォームビューで値を設定
以下の通り、Taintに対応したTolerationの設定値を入力します。
いずれかの方法でTolerationの設定ができたら、「作成」をクリックしてClusterPolicyを作成します。OpenShiftのコンソール画面を「開発者向け」パースペクティブに変更し、「トポロジー」メニューでプロジェクトを「nvidia-gpu-operator」に切り替えると、各コンポーネントの起動状況を確認できます。
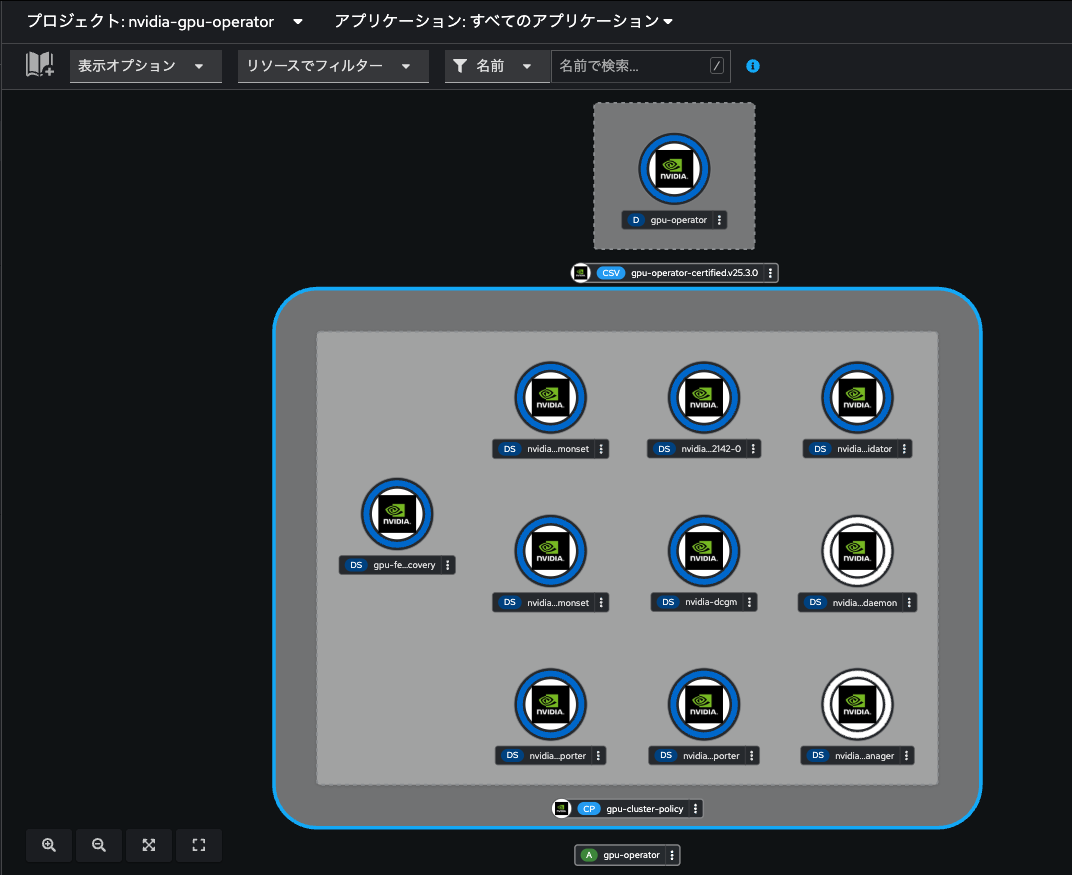
以下を除いて全てがReady(濃い青色のリングが点灯)になったら、ClusterPolicyの作成が完了です。
- nvidia-device-plugin-mps-control-daemon
- nvidia-mig-manager
続いて、OpenShift AI Operatorの依存関係に関わるOperatorを2つインストールします。
Red Hat OpenShift Serverless
これまでと同様、デフォルト設定でインストールを行います。

Red Hat OpenShift Service Mesh 2
やはりこれまでと同様に、インストールを行います。

Red Hat OpenShift Service Meshには「2」と「3」があるのですが、現状は「2」のみ対応です。ご注意ください。

Red Hat OpenShift AI
Red Hat OpenShift AIは、OpenShift上に構築されたエンタープライズ向けの AI/MLプラットフォームで、データサイエンティストや開発者がモデルの学習・推論・運用を一元管理できます。JupyterLabやモデルサービングのための様々なコンポーネント(KServe、vLLMなど)を統合し、セキュアかつスケーラブルな AIワークフローを実現します。「Red Hat OpenShift AI Operator」をインストールし、カスタムリソースを作成することで、OpenShift AIが利用可能になります。
OpenShift AIにおいて言語モデルをサーブする仕組みとして、オープンソースの「Kserve」というコミュニティプロジェクトが活用されています。KServe は、Kubernetes 上で予測および生成 AI モデルを提供するための、クラウドに依存しない標準のモデル推論プラットフォームとされています。
Oepratorはこれまでと同様、OperatorHubからインストールします。

インストールについてはデフォルト設定で構いません。インストールが完了すると、カスタムリソース「DataScienceCluster」の作成を求められますので、「DataScienceClusterの作成」をクリックしてください。
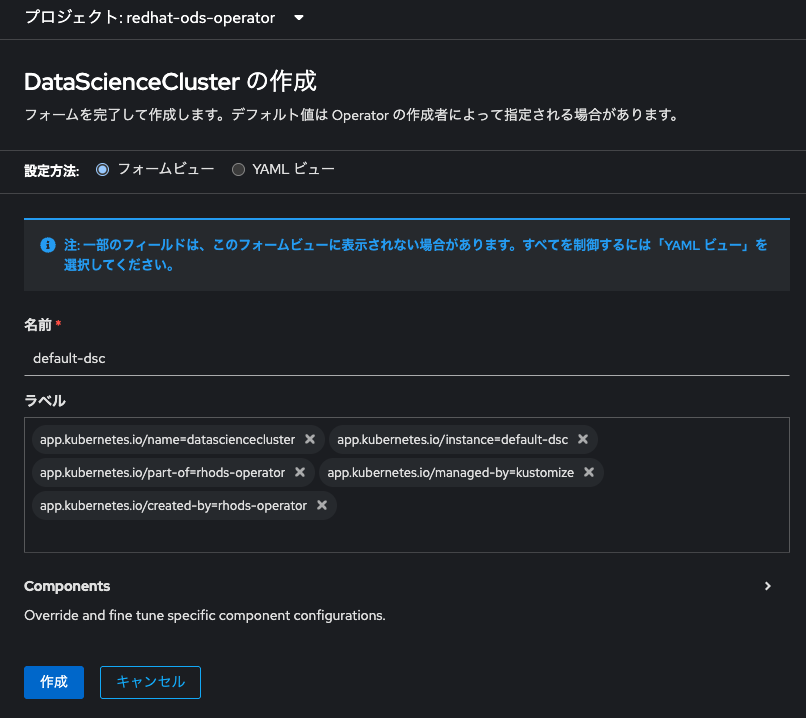
次の画面では、OpenShift AIに含まれる各コンポーネント毎のデプロイ有無を選択することができます。実は今回の「言語モデルのサーブ」だけを考えた場合、デフォルト設定では不要なコンポーネントもデプロイされてしまうのですが、そのまま「作成」をクリックしてください。
OpenShiftのコンソール画面を「開発者向け」パースペクティブに変更し、「トポロジー」メニューでプロジェクトを「redhat-ods-applications」に切り替えると、OpenShift AIを構成するコンポーネントの起動状況を確認できます。
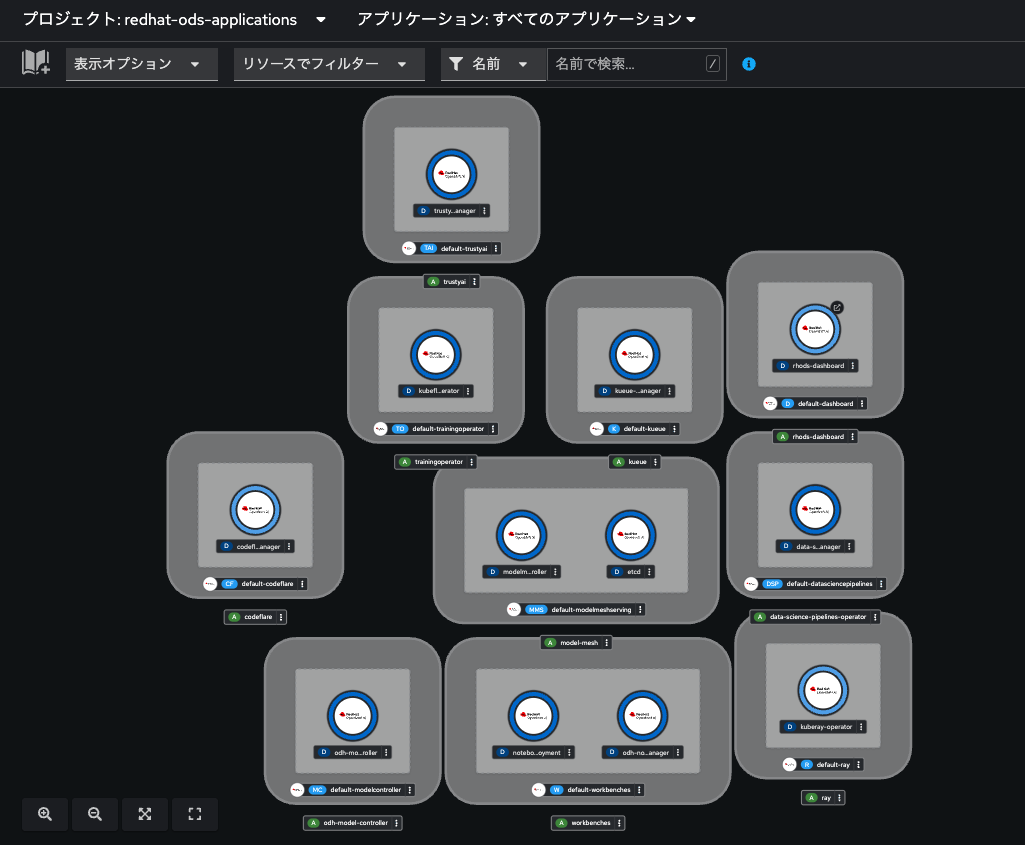
全てがReady(濃い青色のリングが点灯)になったら、「rhods-dashboard」のRoute(インターネットにURLを公開する仕組み)をクリックします。

OpenShiftのログイン画面を介してSingle Sign Onすると、OpenShift AIのコンソール画面にアクセスできます。
後ほどこのコンソール画面でワークベンチの起動や言語モデルのサーブを行いますので、いったんタブを開いたまま、他にも必要なOperatorのインストールを進めます。
Web Terminal
Web Terminal OepratorはOpenShiftのコンソール画面でターミナルがサクッと利用できるためのツールです。今回の環境構築においては、一部コマンド操作を利用するので、こちらを利用できるようにしましょう。

その他のOperatorと同様、デフォルト設定でインストールしてください。こちらはカスタムリソース作成は不要です。インストールが完了したら画面更新してください。

画面更新すると、右上にターミナルボタンが出てきます。これをクリックし、「ターミナルの初期化」メニューで「開始」をクリックします。
これでOpenShiftのコンソール画面でターミナルが利用できる様になりました。
次で最後のOperatorです。
Gitea
Giteaは、軽量でセルフホスト可能なオープンソースのGitサービスです。GitHubのようなWebベースのリポジトリ管理、課題管理、コードレビュー機能を提供し、オンプレミスでの開発環境に適しています。なお、GiteaはGitea Operatorを介してカスタムリソースとして作成することが可能なのですが、同OperatorはOpenShiftのOperatorHubでは公開されていません。そのため、Gitea Operatorのインストール手順を参考にして、セットアップしていきます。
まずは、先程インストールしたWeb Terminalにて、以下のコマンドを実行し、Gitea OperatorをOpenShiftクラスタに追加します。
oc apply -k https://github.com/rhpds/gitea-operator/OLMDeploy
以下のようなログがでます。
namespace/gitea-operator created
operatorgroup.operators.coreos.com/gitea-operator created
catalogsource.operators.coreos.com/redhat-rhpds-gitea created
subscription.operators.coreos.com/gitea-operator created
OpenShiftコンソール画面の管理者表示にて、左メニュー「Operator」から「インストール済みのOperator」をクリックし、プロジェクトをたった今作成された「gitea-operator」に変更してみましょう。
すると、Gitea Operatorが追加されています。このGitea Operatorをクリックし、「インスタンスの作成」クリックします。
「YAML」ビューに切り替え、以下のマニフェストファイルをコピペします。
apiVersion: pfe.rhpds.com/v1
kind: Gitea
metadata:
name: repository
namespace: gitea-operator
spec:
giteaSsl: true
giteaVolumeSize: 4Gi
postgresqlVolumeSize: 4Gi
giteaAdminEmail: gitea-admin@redhat.com #なにか適当なアドミン用メアドを記載
giteaAdminPassword: gitea-admin-pw #Giteaのアドミンアカウントのパスワード
giteaAdminUser: gitea-admin #Giteaのアドミンアカウントのユーザ名
「作成」をクリックして、Giteaインスタンスの起動を待ちます。プロジェクトを「gitea-operator」のままにし、OpenShiftコンソール画面を開発者表示に変えます。左メニュー「トポロジー」を選択すると、Giteaのデプロイ状況を確認できます。デプロイが完了したら、Routeが公開しているURLにアクセスしてみましょう。

Giteaのコンソール画面にアクセスできました。右上「サインイン」をクリックし、先程マニフェストファイルで設定したアドミンアカウントのログイン情報(gitea-admin / gitea-admin-pw)を使ってログインします。

サインインできたら、右上の「+」ボタンをクリックし、「新しい移行」を選択します。
移行元のGitリポジトリサービス一覧が出てきますので、ここでは「GitLab」をクリックします。

「移行 / クローンするURL」にhttps://gitlab.com/masaki-oomura/langchanin-rag-chatbot.gitを入力し、「リポジトリを移行」をクリックします。
ここには事前に今回作成するAIチャットボットに関連するマニフェストファイルやアプリのソースコードを事前に入れてあります。

移行が完了すると、必要なソースコード一式がGiteaの中にインポートされてきます。
お疲れ様でした。これにて必要なOperatorの一式をダウンロードできました。、次からはOpenShift AIを利用してワークベンチを起動したり言語モデルをデプロイします。
OpenShift上に言語モデルをサーブする
まずはOpenShift AIの機能を利用し、OpenShift上に言語モデルをデプロイしましょう。なお、言語モデルも所詮はコンピューティングリソースの上で展開されて動作するデータです。まずはこのデータをOpenShift環境にダウンロードして保存する必要があります。その保存場所からOpenShift AIの機能を使ってデータを取ってきて、モデルをデプロイ、サーブする(推論可能にする)わけです。
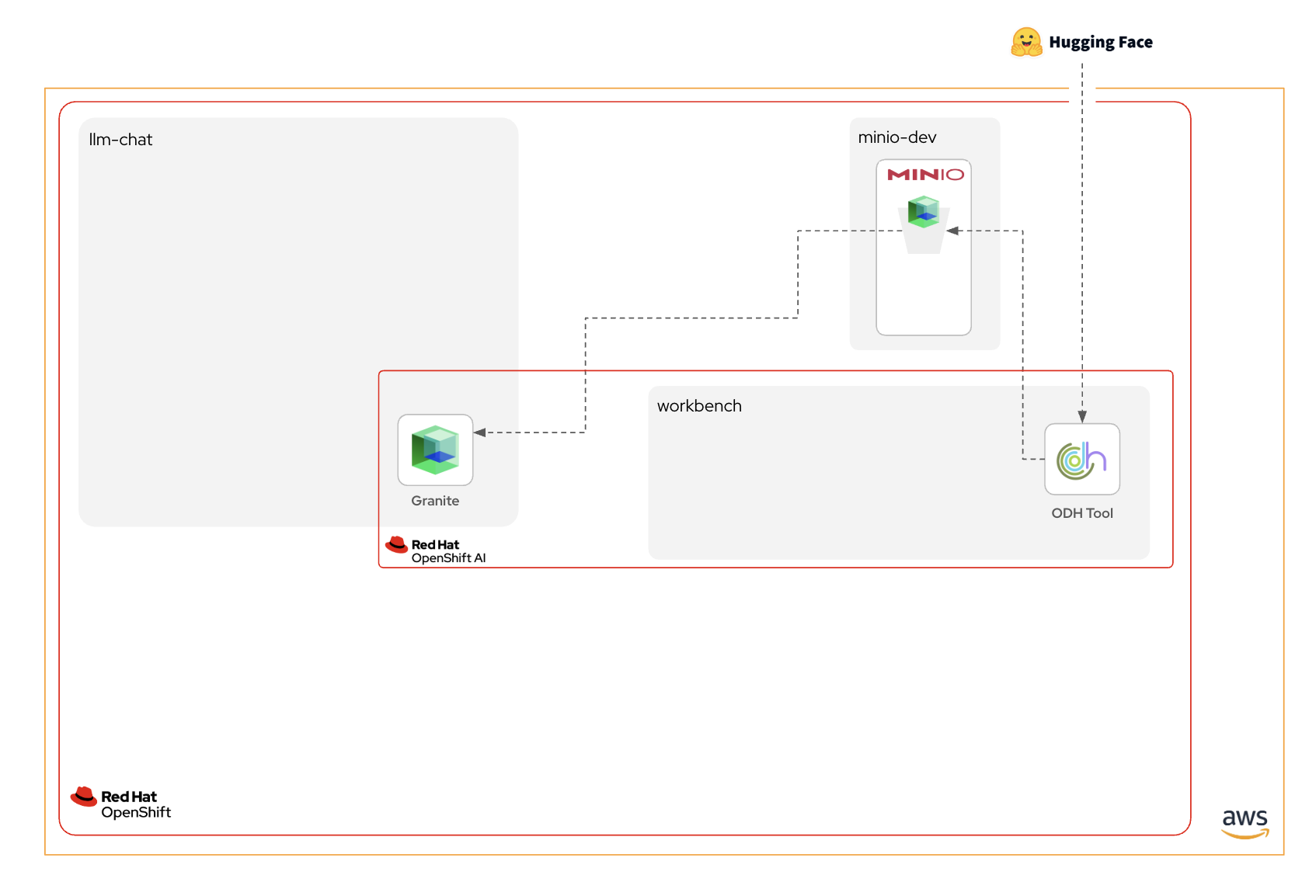
モデルダウンロードに関わるコンポーネントの紹介
構築作業の前に簡単にコンポーネントの説明をします。
Hugging Face
Hugging Faceは、自然言語処理(NLP)を中心とした機械学習モデルの開発・共有を支援するプラットフォームで、代表的なライブラリ「Transformers」を提供しています。研究者や開発者は、Hugging FaceのHubを通じて事前学習済みモデルを簡単に利用・公開できます。
IBM Granite
IBM GraniteはIBMとRHが提供するオープンソースLLMです。企業利用に特化させ、10億以下から340億パラメーターまで、Apache 2.0でオープンソース化された適切なモデルを選択できます。さまざまなタイプが提供されています。Hugging Face Hubから誰でもダウンロード可能です。
今回は、Graniteの比較的新しいモデルでありつつ、パラメータ数を2B(20億)まで抑え推論時のコンピューティングリソースが比較的リーズナブルとなる「ibm-granite/granite-3.3-2b-instruct」を利用します。
Graniteモデルファミリーの一覧は以下からご覧ください。
https://huggingface.co/ibm-granite
Open Data Hub(ODH)Tool
先ほどインストールした「Red Hat OpenShift AI」も、Red Hatのその他の製品と同様、アップルストリーム(上流)のオープンソースプロジェクトが存在します。このプロジェクトの名称が「Open Data Hub(ODH)」です。ODHは、先ほど触れたKserveやvLLMを含め、Kubernetesの上で機械学習や生成AIのライフサイクル管理を行うために必要なあらゆるオープンソースプロジェクトを統合し、直感的なユーザーエクスペリエンスと融合させることで、アプリ開発者やインフラ開発者、そしてデータサイエンティスト間のギャップを埋めることを目指しています。
このODHにはさまざまなツールセットが提供されているのですが、Huggingface上の言語モデルデータを直接オブジェクトストレージにダウンロードさせる機能「Open Data Hub Tools & Extensions Companion(OTH Tool)」を提供しており、これが非常に便利なので利用します。
ODHに実装された機能が安定的に利用できる様になると、OpenShift AIに商用機能として実装されてくるとされています。今回使うツールセットは、現段階においてはOpenShift AI側に実装されていないのですが、もしかしたら今後載ってくる可能性もあります。
MinIOをデプロイ
まずはモデルデータをダウンロードし格納する箱を先に用意しておく必要があります。先ほど紹介したS3互換のオブジェクトストレージであるMinIOをOpenShift上にデプロイします。
なお、今回はMinIOを簡単にデプロイするために事前にマニフェストファイル一式を用意しておきました。これをArgoCDアプリケーションを活用してOpenShiftクラスタに適用します。
ArgoCDアプリケーションによるマニフェストの適用について詳しく知りたいという方は、以前私が書いた別の記事の当該箇所を参照くださいますと幸いです。
先ほどインストールしたOperator「Web Terminal」用いて、OpenShiftのコンソール画面からArgoCDアプリケーションのマニフェストを適用します。Web Terminalを初期化した際にクリックした「ターミナルボタン」からWeb Terminalを開きます。
以下のコマンドでArgoCDアプリケーションを適用し、MinIOをデプロイしましょう。
# ArgoCDアプリケーションを適用
oc apply -f http://repository.gitea-operator.svc.cluster.local:3000/gitea-admin/langchanin-rag-chatbot/raw/branch/main/minio-dev/argocd-app/application.yaml
#成功時のログ
application.argoproj.io/minio created
デプロイされたMinIOはOpenShiftのコンソール画面でプロジェクト一覧から「minio-dev」を選択して確認できます。
「URLを開く」からMinIOのGUIに遷移しましょう。なお、MinIOの管理者ログインID/PWは、先ほどArgoCDアプリケーションによって適用したマニフェスト一覧の中のSecretファイル「minio-secret」に記載されています。
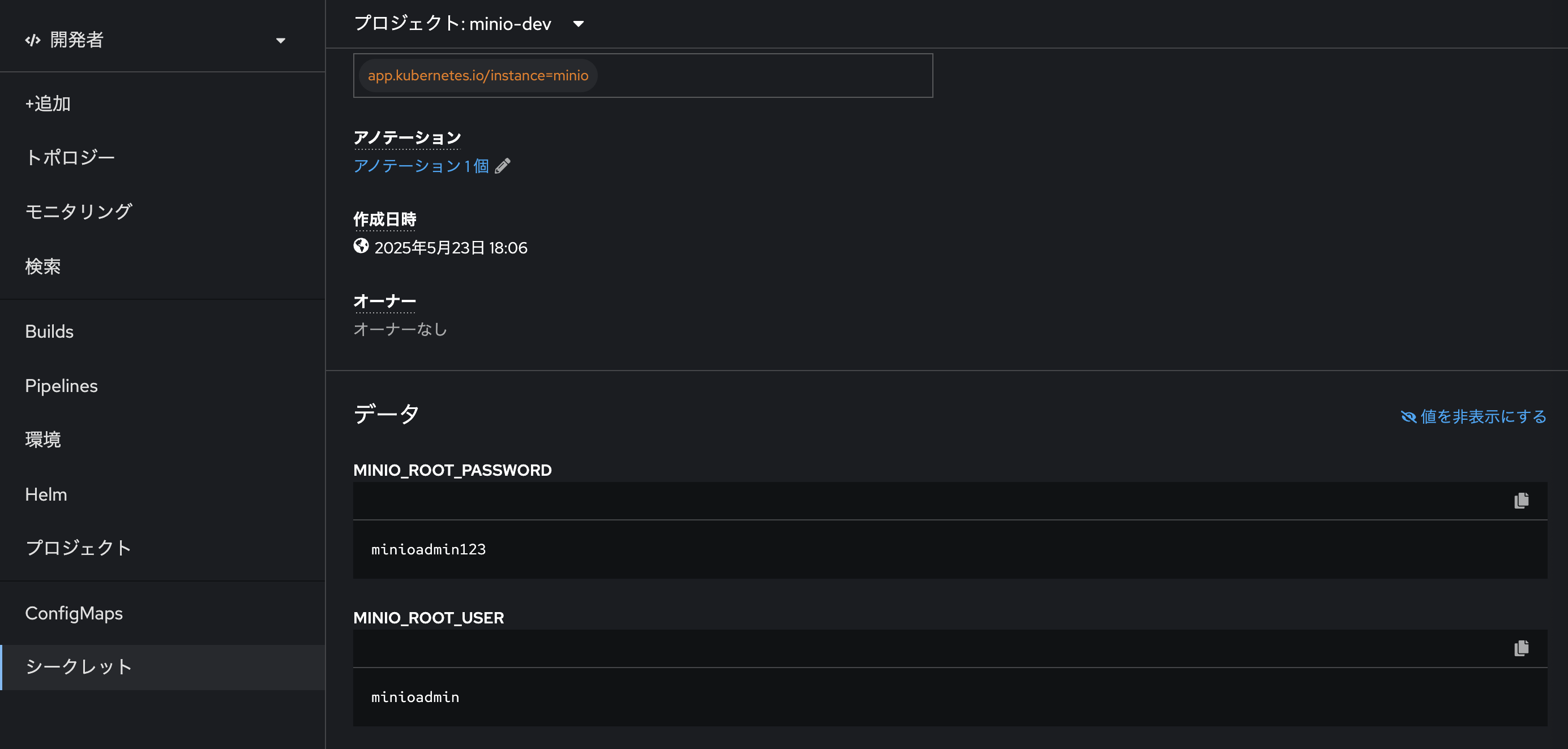
- ID:
minioadmin123 - PW:
minioadmin
ログインできたら、「Create a Bucket」をクリックします。

オブジェクトストレージにおける「バケット」は、ファイル(オブジェクト)を整理・保存するための論理空間の様なものです。各バケットには一意の名前が付き、その中に複数のオブジェクトを保存できます。今回は「Bucket Name」欄に「models」と入れておき、「Create Bucket」をクリックしてバケット「models」を作成しましょう。
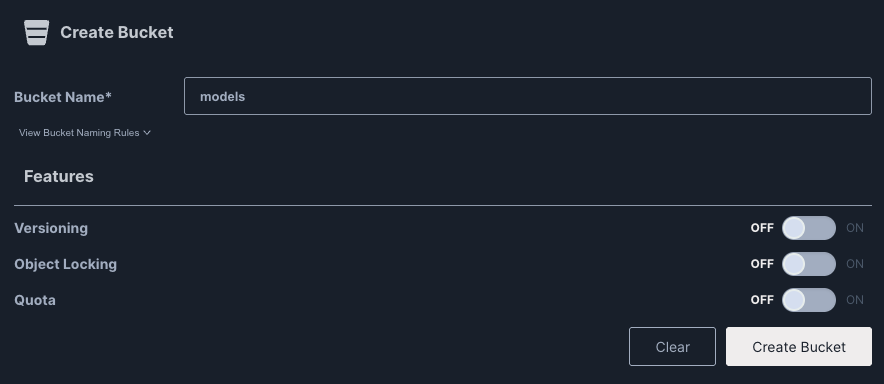
ここまでの作業で、オブジェクトストレージを作成し、その内部に言語モデルのデータを格納しておくバケットを作成することができました。
プロジェクト作成とMinIOとの接続
いよいよODH ToolをOpenShiftの上に展開し、今作成したバケット「models」内に「ibm-granite/granite-3.3-2b-instruct」のデータをダウンロードしてきますが、その前にプロジェクトを作成し、MinIOとの接続設定を行います。
OpenShift AIのコンソール画面の左メニュー「Data science projects」をクリックしましょう。
OpenShift AIのコンソール画面は、OpenShiftのコンソール画面右上の「アプリケーションランチャー」をクリックし、最下部の「Red Hat OpenShift AI」をクリックすることで遷移できます。

OpenShift側で作成された各プロジェクト(Namespace)は、OpenShift AI上では「Data science project」として扱われます。別の言い方をすれば、これはOpenShift AIを用いて管理するリソース(言語モデルやワークベンチ)のデプロイ先の論理空間です。今回はワークベンチを「language-model」という名称のData science projectにデプロイしようと思っているので、先にData science projectを作成します。
なお、ワークベンチとは「作業台」の意味で、データサイエンスのプロジェクトにおける作業環境をイメージしています。「Create project」をクリックし、Name欄に「language-model」と入力したら「Create」をクリックします。
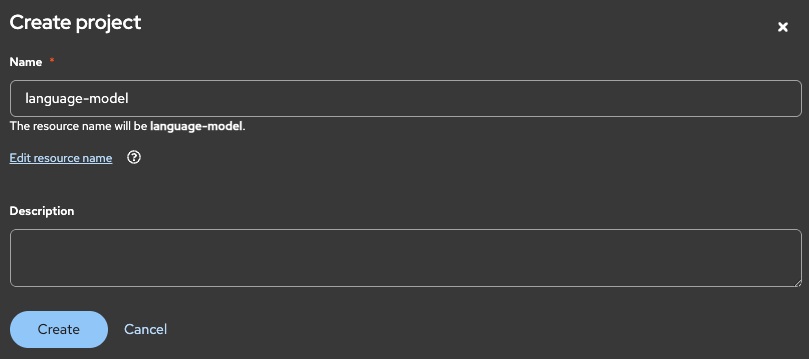
プロジェクト「language-model」が作成できたら、「Connections」タブをクリックします。
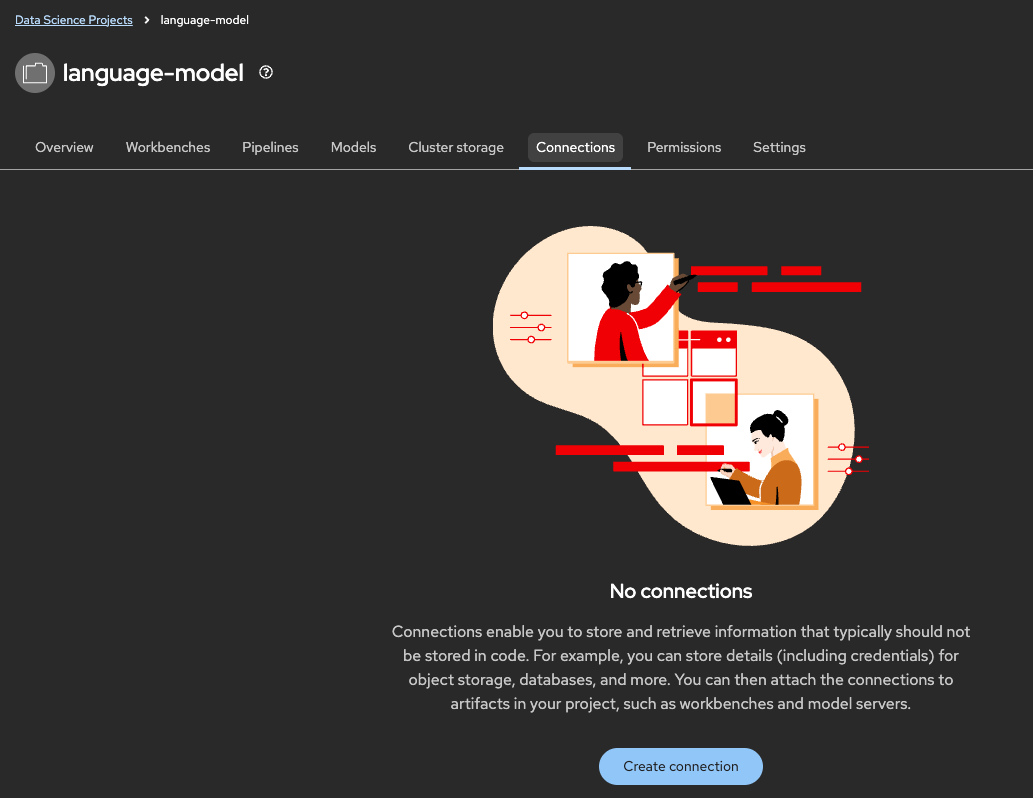
「Create connections」をクリックし、「Connection type」から「S3 compatible object storage - v1」を選択します。
Connectionsでは、オブジェクトストレージを含めた複数の接続先をプロジェクトに設定し、この後デプロイするODH ToolやJupyterLabたちがデータの読み書きを行うことができるようにします。
「Connection details」に以下の通り値を設定してください。
| 項目 | 値 | 備考 |
|---|---|---|
| Connection name | minio-dev | なんらか自分でわかりやすいものを設定してもOK |
| Connection description | - | この接続情報に関する説明、なくてもよい |
| Access key | minioadmin | 必須。MinIOのルートユーザ名がアクセスキーにもなります |
| Secret key | minioadmin123 | MinIOのルートユーザのパスワードがシークレットキーにもなります |
| Endpoint | http://minio-service.minio-dev.svc.cluster.local:9000 | 必須。MinIOにクラスタ内からアクセスするための内部DNS名 |
| Region | - | 今回は特に不要 |
| Bucket | models | 先ほど作成したバケット名 |
なお、内部DNS名(Endpoint)はどうやって確認できるかというと、これはMinIOをデプロイした際に適用したService「minio-service」の詳細から確認できます。
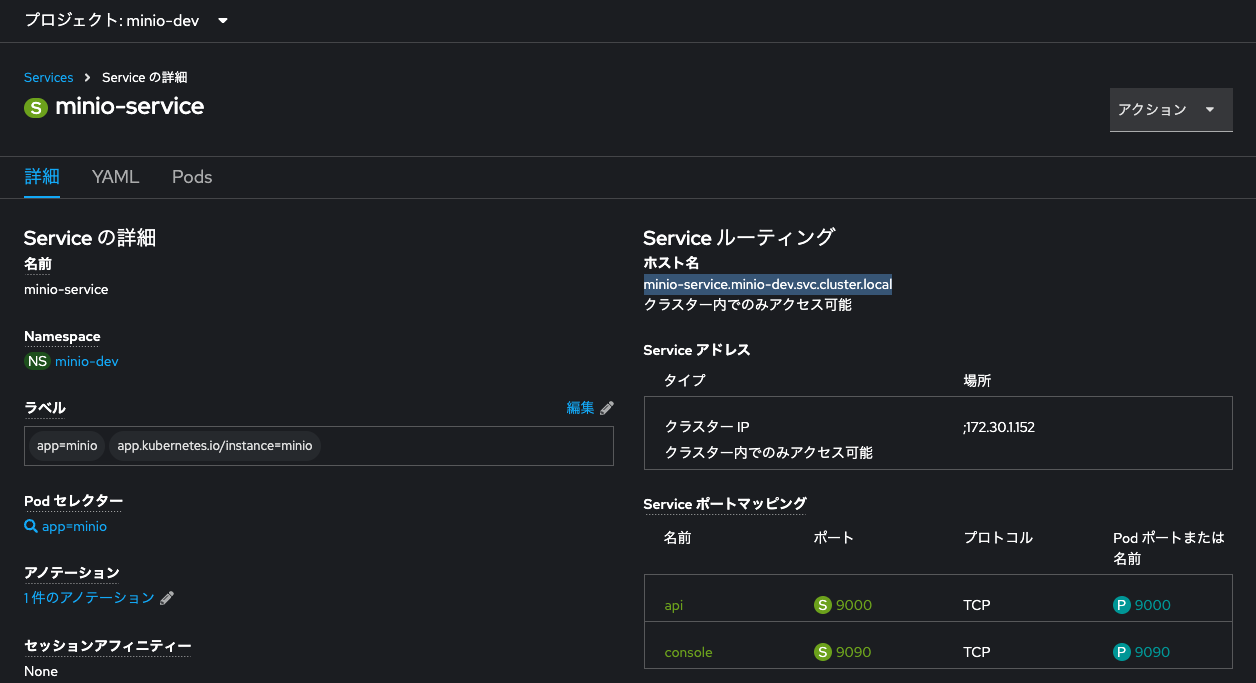
OpenShiftにおいてServiceを介して提供される内部DNS名はhttp(s)://<Service名>.<プロジェクト名>.svc.cluster.local:<ポート番号>というふうに決まります。
必要な値が入力できたら「Create」をクリックして、プロジェクト「language-model」にMinIOとの接続情報の設定を完了します。
ODH Toolの起動
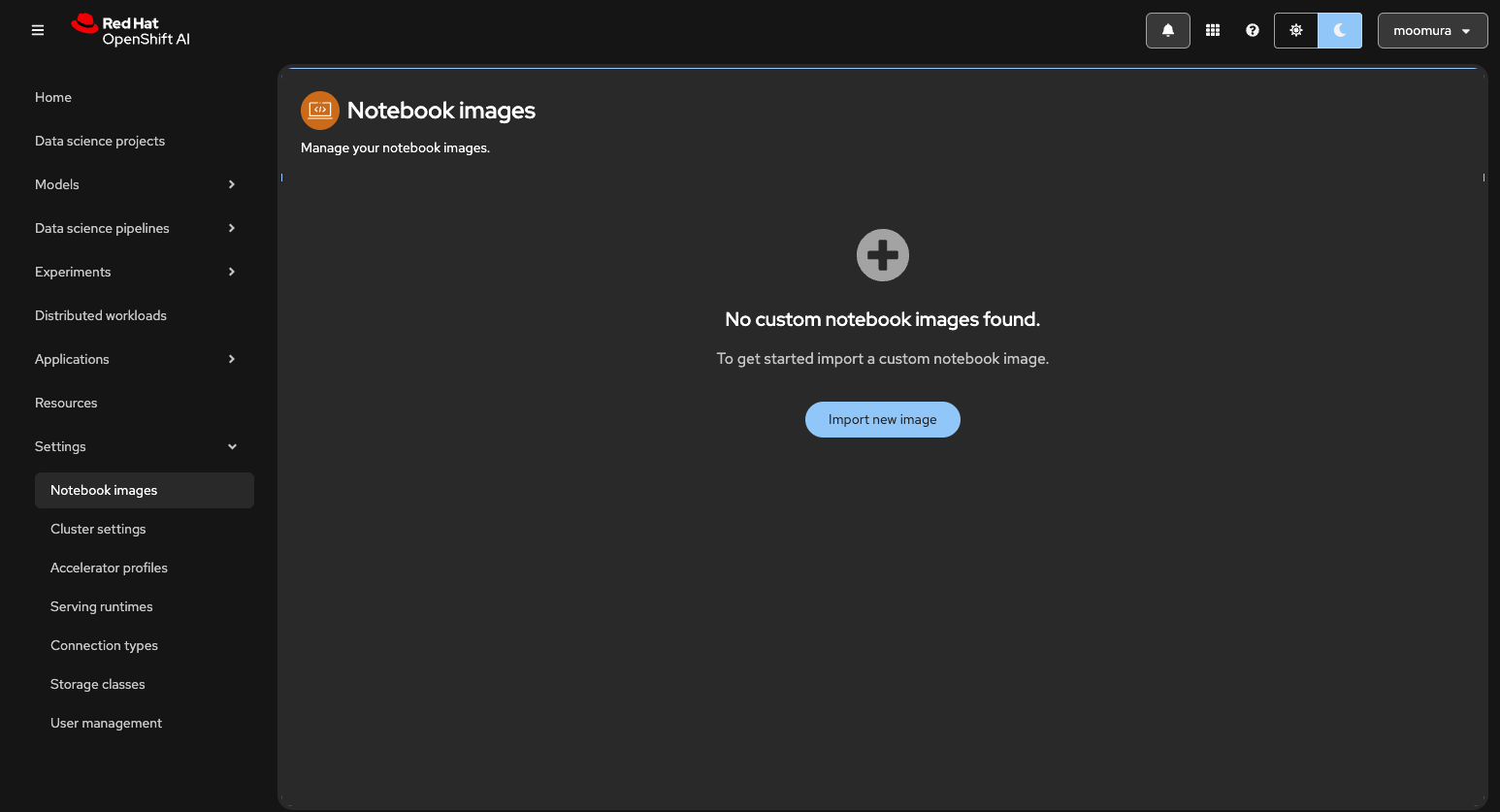
ODH Toolのコンテナイメージを登録しておきます。OpenShift AIのコンソール画面の左メニュー「Settings」から「Notebook images」を選択し、「Import new image」をクリックします。
ここで、以下の通り値を入力します。
| 項目 | 値 | 備考 |
|---|---|---|
| Image location | quay.io/rh-aiservices-bu/odh-tec | Quay.ioのRed HatのOrganizationで公開されている各種コンテナイメージの中から拝借 |
| Name | odh-tool | 任意の文字列 |
その他の項目は空欄で大丈夫です。「Import」をクリックして、ODH Toolのコンテナイメージを登録します。
再びプロジェクト「language-model」の詳細画面に戻り、「Workbenches」タブから、「Create workbench」をクリックします。
ワークベンチ作成画面で以下の通り値を入力・選択します。
| 項目 | 値 | 備考 |
|---|---|---|
| Name | odh-tool | 任意の文字列 |
| Image selection | odh-tool | 先ほど登録したODH Toolのコンテナイメージ名 |
| Connections | minio | 「Attach existing connections」から、先ほど作成したConnection「minio-dev」を選択します |
その他の項目はデフォルトのままで大丈夫です。なお、ODH Toolのための永続ボリューム(Persistent Volume)は、OpenShift側のデフォルトのStorage Classから払い出されます。「Create workbench」をクリックして、ODH Toolを起動します。
起動が完了したら、「odh-tool」をクリックし、ODH Toolのコンソール画面に遷移しましょう。
Huggingfaceから言語モデルのデータをダウンロード
ここからはODH Toolのコンソール画面を操作して、言語モデルのデータをMinIOに格納する作業を行います。まずはODH Toolの左メニューから「Settings」を選びます。ここではオブジェクトストレージやHuggingfaceとの接続設定が可能です。すでに先ほどワークベンチ作成時に設定済みのMinIOとの接続情報が登録されています。念のため、「Test Connection」をクリックして、きちんと繋がっているか確認しておきます。
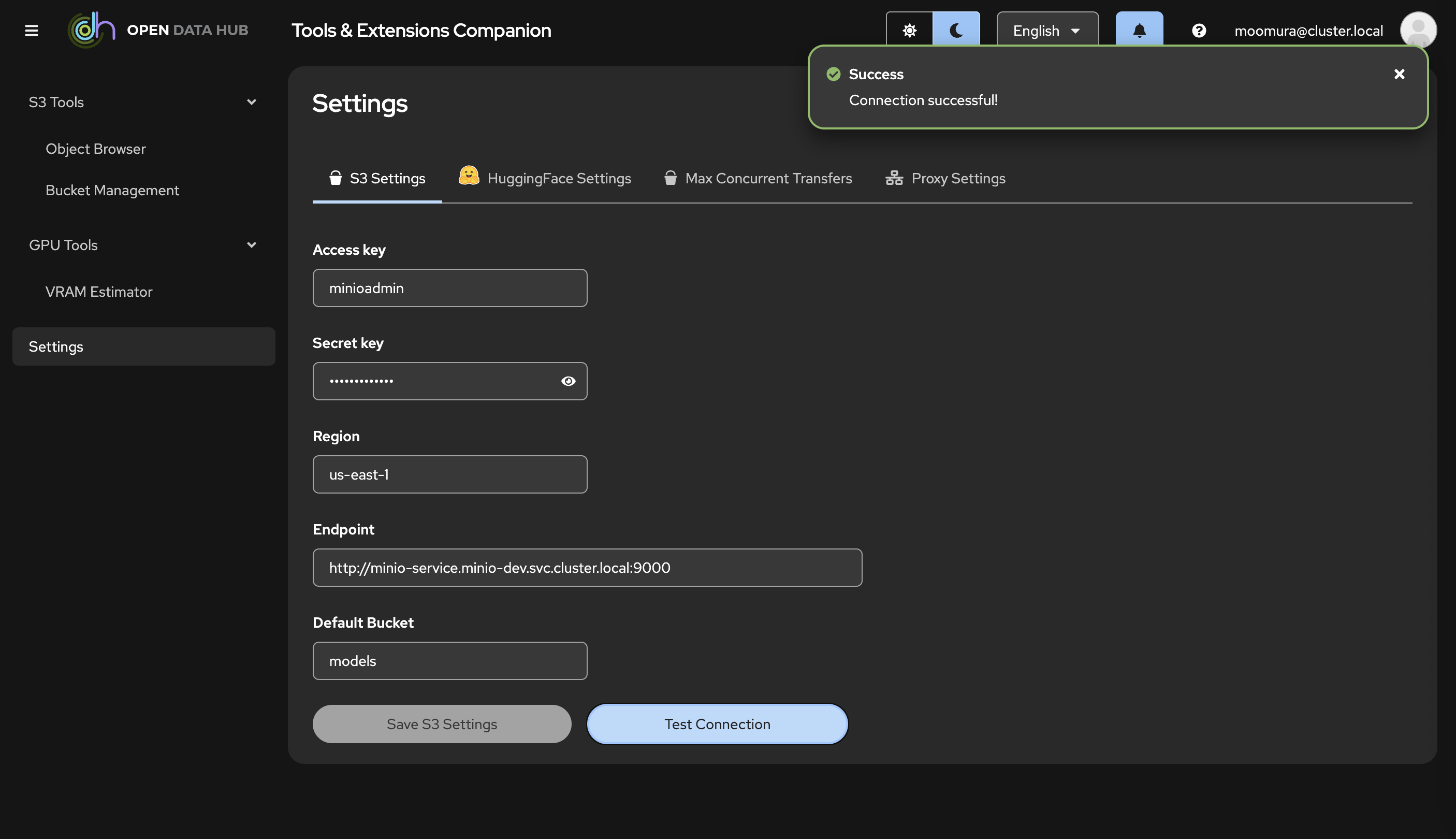
「Success」が出ればOKです。次に「Hugging Face Setteings」タブに切り替えます。「Token」欄にHuggingface上で発行したアクセストークンを登録する必要があります。

Huggingfaceのマイページにて、自身のアイコンをクリックするとメニューが選択できます。ここから「Access Tokensを選択します。

このページでアクセストークンを発行できます。今回はモデルダウンロードのみを目的としていますので、Read権限でアクセストークン(名称は任意のものでOK)を作成します。

「Create token」をクリックすると、アクセストークンの文字列が発行されるので、それをODH Toolの「Token」欄に貼り付けてください。

「Test Connection」をHuggingfaceに対しても実行し、「Success」が表示されればOKです。「Save HuggingFace Settings」をクリックし、Hugging Faceとの接続情報の登録を完了します。
ODH Toolのコンソール画面の左メニュー「S3 Tools」から「Objects」を選択し、「Import HF Model」をクリックしましょう。ここにHugging Face Hub上のモデル名(ibm-granite/granite-3.3-2b-instruct)をそのままコピペします。

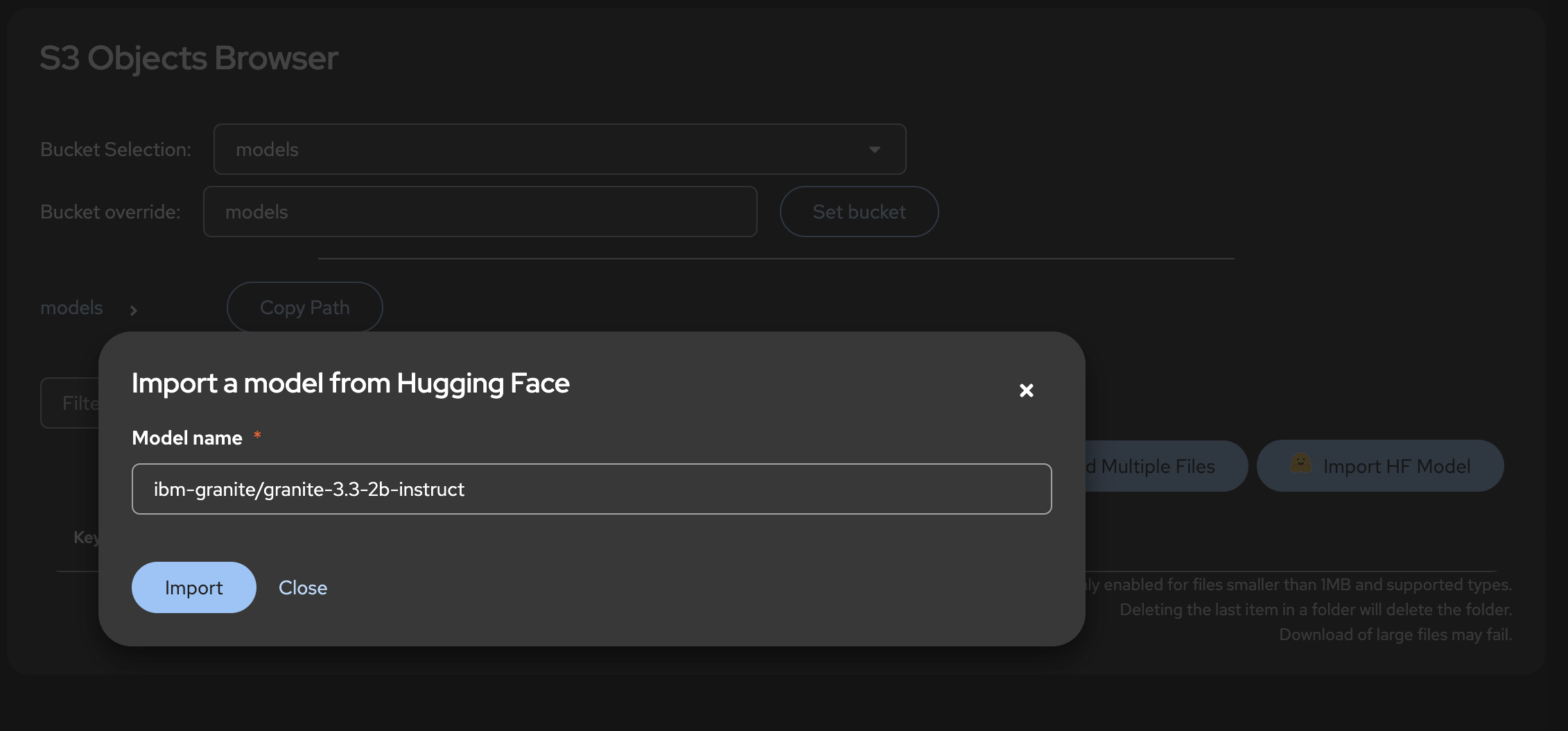
「Import」をクリックすると、MinIOのバケット「models」内にibm-granite/granite-3.3-2b-instructというディレクトリを作成し、その中に言語モデルのデータをダウンロード・格納してくれます。
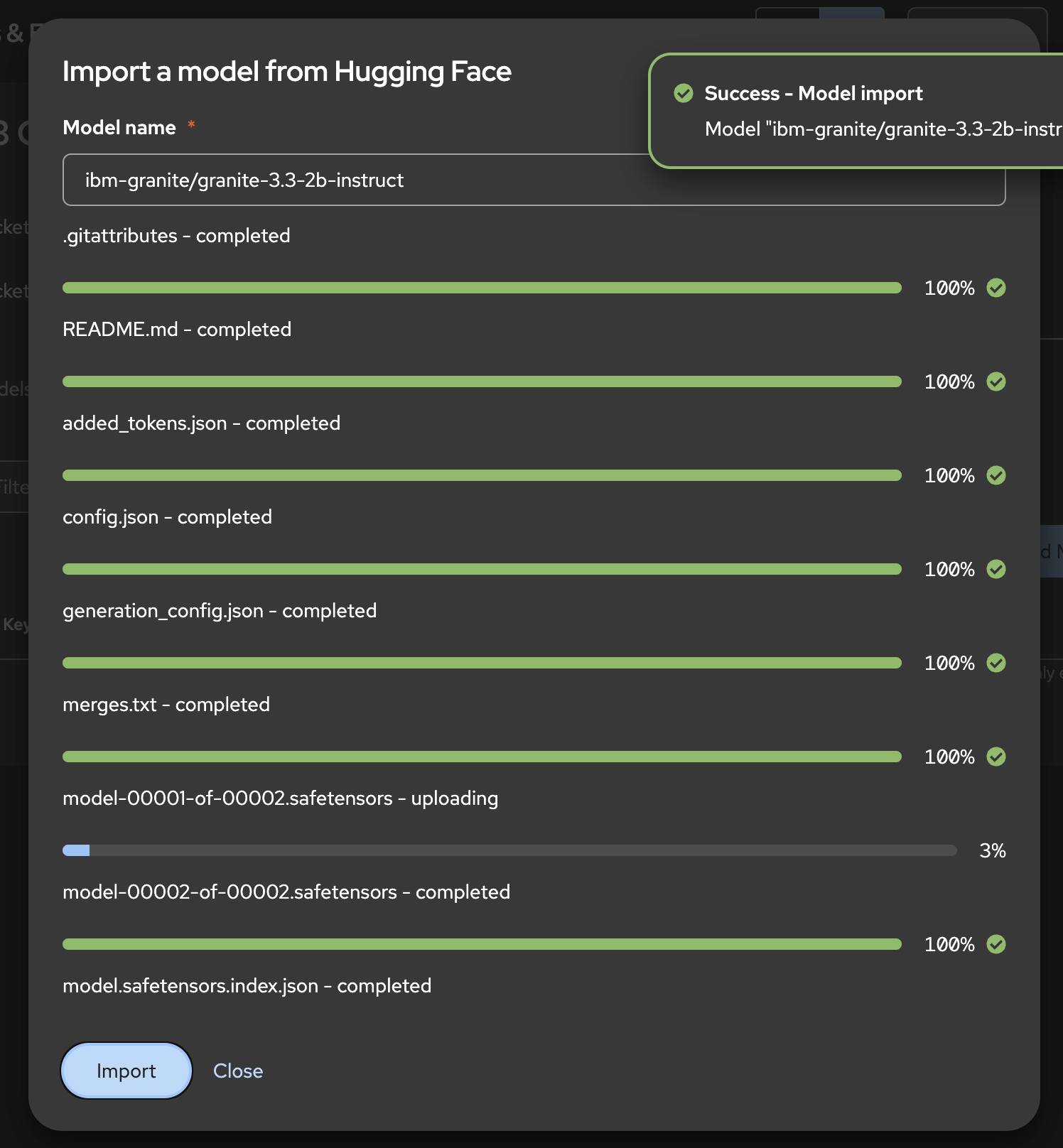
モデルのダウンロードが完了したら、同ディレクトリのパスを「Copy Path」からコピーしておきます。

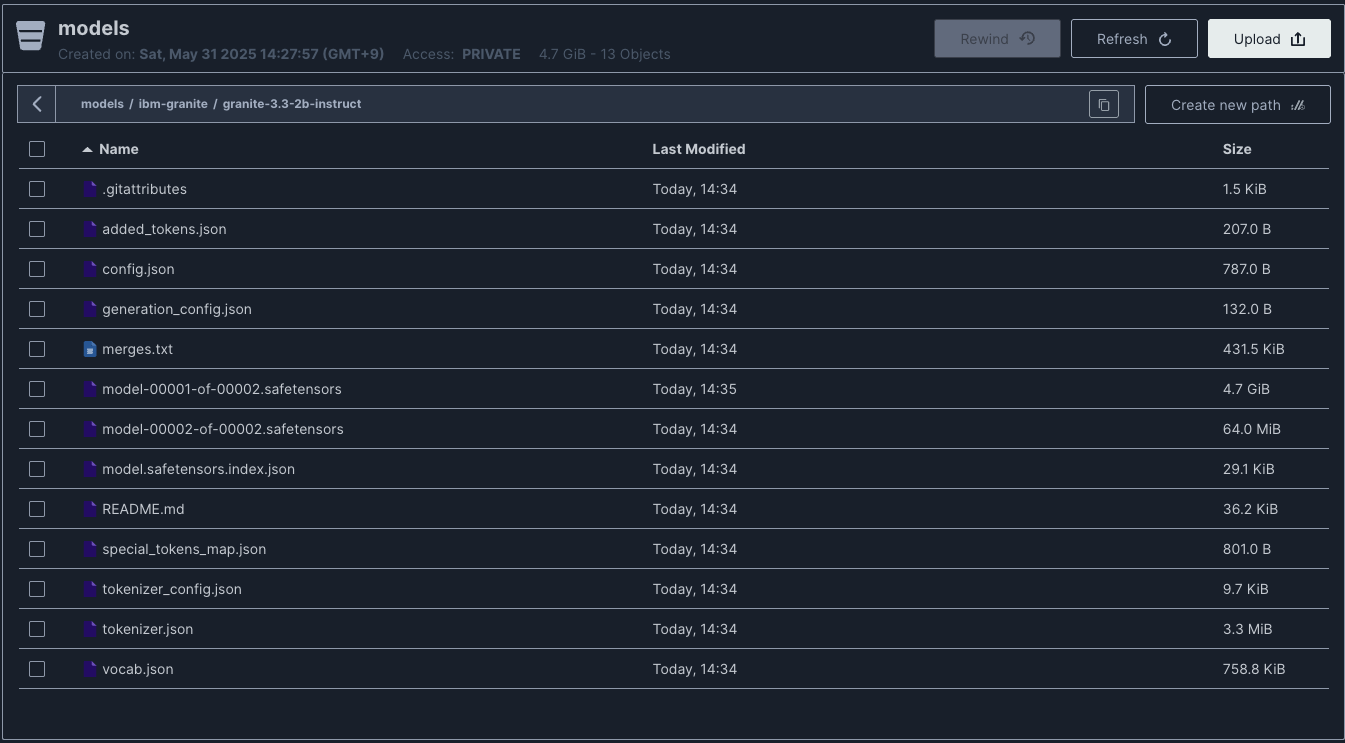
これで言語モデルのダウンロードが完了しました。MinIOのコンソール画面でも言語モデルのデータ一式がダウンロードされたことを確認できます。
アクセラレータプロファイルの設定
アクセラレータは言語モデルなどが利用する特別なコンピューティングリソースの総称を指し、端的に言えばGPUのことです。OpenShift AIを用いてデプロイするワークベンチや言語モデル / 機械学習モデルに対してGPUを利用させる(GPUノードにPodをスケジュールさせる)際に、アクセラレータプロファイルの設定が求められます。
OpenShift AIのコンソール画面で「Setteings」メニューから「Accelerator profiles」を選択、「Add new accelerator profile」を選択します。いくつか必要な値を入力します。以下、本記事における必須の項目に絞って示します。
Details欄
| 項目 | 値 | 備考 |
|---|---|---|
| Name | NVIDIA GPU | 任意の文字列でOK。なにかわかりやすい名前をつけてください |
| Identifier | nvidia.com/gpu | GPUノード(g6.xlarge)を識別するノードのラベルを指定します。これはNFDによって自動的に付与されたものです |
さらに、「Tolerations欄」の「Add toleration」をクリックします。今回の記事ではGPUノードにTaintを付与しているので、対応するTolerationを設定します。なお、これは先ほどNVIDIA GPU OperatorのDaemonSetに設定したTolorationの設定値と同じです。

Tolerations欄
| 項目 | 値 |
|---|---|
| Operator | Equal |
| Effect | NoSchedule |
| Key | reserved |
| value | gpu-node |

「Add」をクリックしてToleration設定を反映します。DetailsとTolerationsの設定値を入力したら、「Create accelerator profile」をクリックし、設定を保存します。

これでアクセラレータプロファイルが設定できました。
言語モデルをサーブ
さて、いよいよ言語モデルをOpenShift上にサーブします。先ほど作成したData science prject「language-model」を選択した状態で「Models」タブに切り替え、「Select single-model」をクリックします。
次の画面で「Deploy model」をクリックします。
すると、モデルをデプロイするための情報を設定する画面が開きます。以下の通り値を入力してください。
Model deployment欄
| 項目 | 値 | 備考 |
|---|---|---|
| Model deployment name | granite-33-2b-instruct | 任意の文字列。デプロイするモデルがわかるようなものがおすすめです。なおドット(.)は使えません |
| Serving runtime | vLLM NVIDIA GPU ServingRuntime for KServe | 今回はNVIDIA GPUを使うのでこちらを指定します |
| Deployment mode | Standard | 今回はStandardを選択します |
| Model server size | Custom | 今回、g6.xlargeにはgranite-3.3-2b-instruct以外のワークロードはデプロイしませんので、ノードのリソース目一杯の仕様限界値を設定します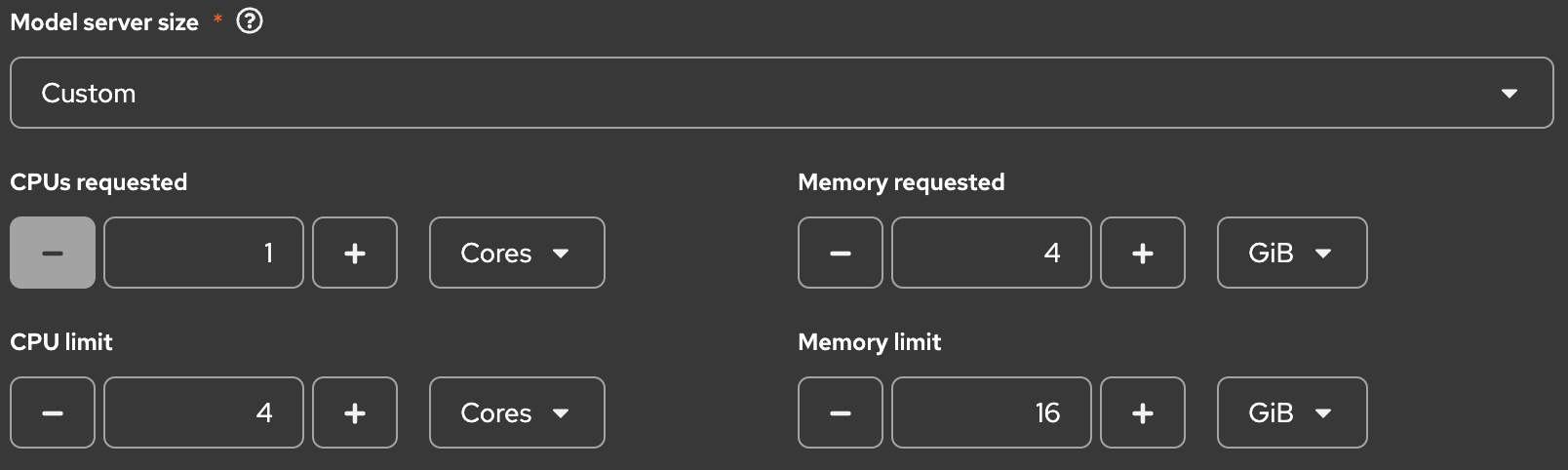
|
| Accelerator | NVIDIA GPU | 先ほど作成したアクセラレータプロフィールです |
| Number of accelerators | 1 | 今回はクラスタ内で利用可能なGPUが1機しかないので、1しか選択できません |
Source model location欄
| 項目 | 値 | 備考 |
|---|---|---|
| Connection | minio-dev | すでに作成済みのコネクション「minio」を選択します |
| Path | /ibm-granite/granite-3.3-2b-instruct/ | MinIOに作成したバケット「models」内で言語モデルのデータが保存されているパスを設定します |
| Additional serving runtime arguments | - | 今回は特に指定しませんが、気になる方はすぐ下の注記を確認してください。 |
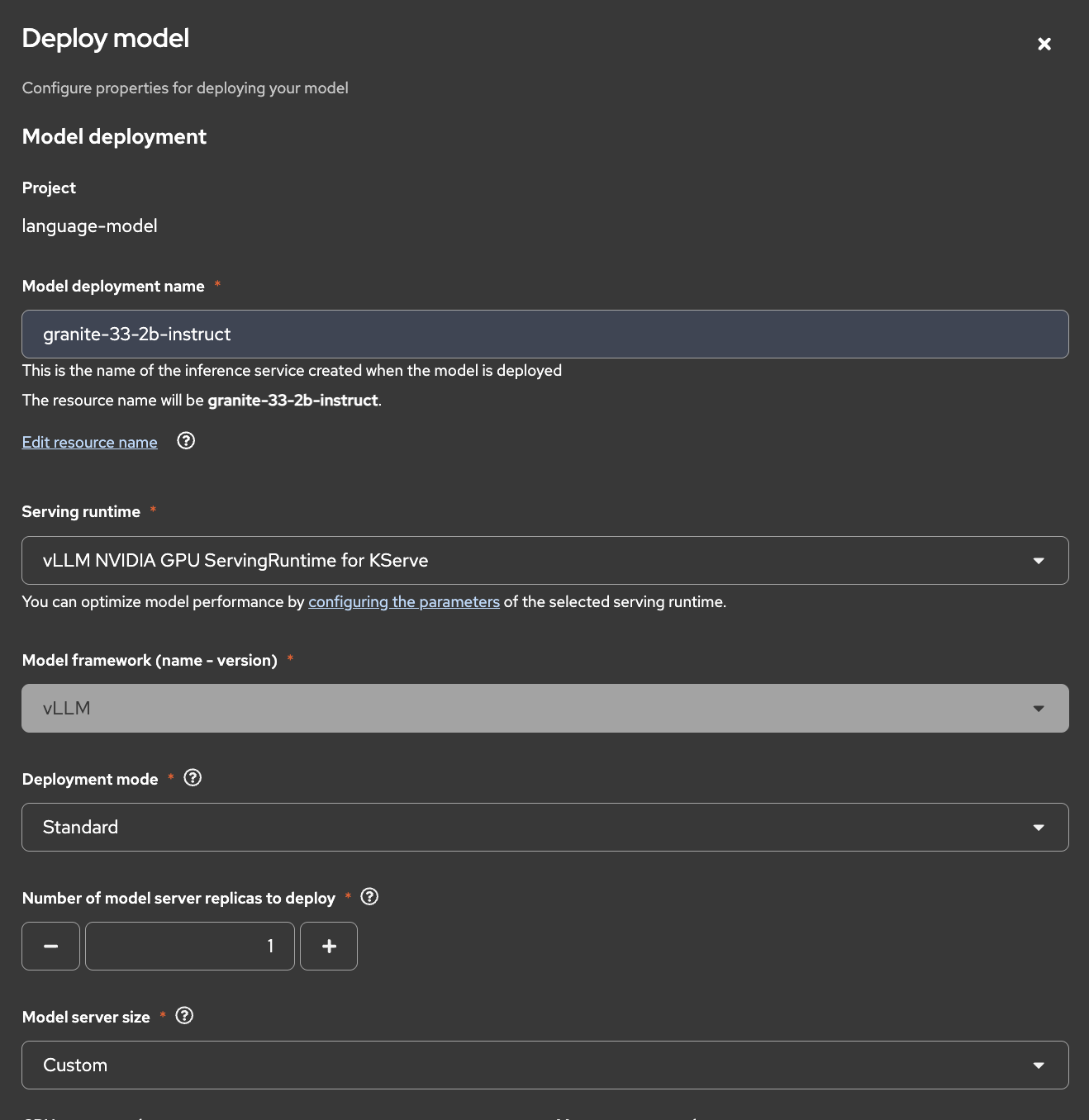
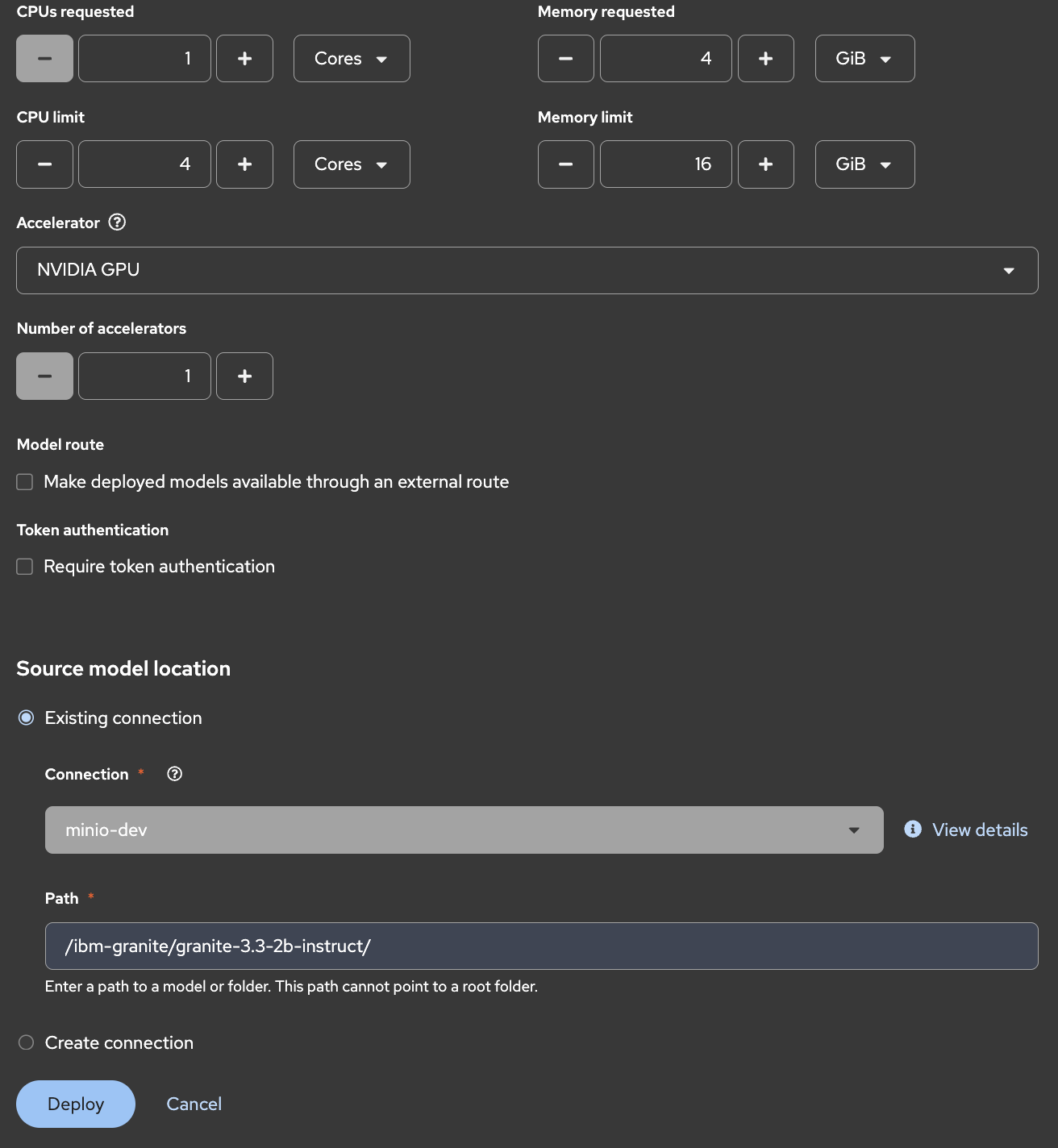
必要な値を入力できたら「Deploy」をクリックしましょう。
Statusが進行状態(くるくる回っているアイコン)になります。
vLLMは、Berkeley大学が開始したコミュニティプロジェクトであり、言語モデルの推論を高速かつ効率的に行うためのオープンソースの推論サーバ、ライブラリ群の総称です。独自のスケジューラ「PagedAttention」により、複数のリクエストを同時に処理しながらGPUメモリを効率的に使います。OpenAI互換APIを提供し、OpenShiftやKServe上でも容易にデプロイ可能です。vLLMについての概要を知りたい場合、ぜひRed Hatの公式サイトを参照することをお勧めします。また、vLLMを利用してモデルをサーブする際に指定できる各種オプションについては、vLLMの公式ドキュメントを確認してください。特に、今回は関係ありませんがGPUノードにGPUが複数機搭載されている場合、argumentにtensor_parallel_sizeを指定することで、複数機にモデルの重みを分散させ、KVキャッシュメモリの効率化に寄与します。
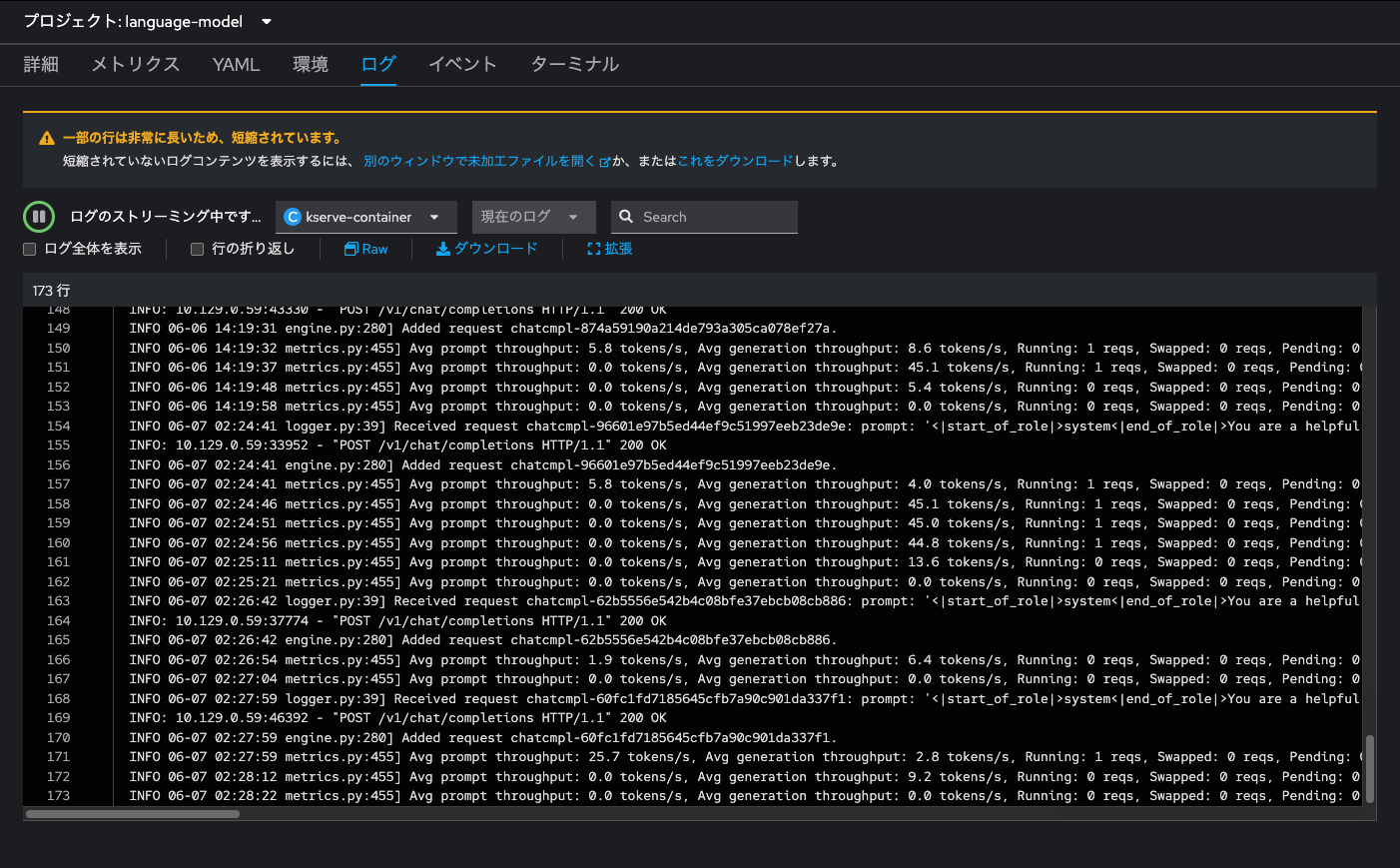
モデルのデプロイが開始されると、まずはイニシャライズ動作が始まります。これは、OpenShiftのコンソール画面の開発者表示にて「トポロジー」メニューから言語モデルのPodのログを確認することで、その詳細を把握することができます。
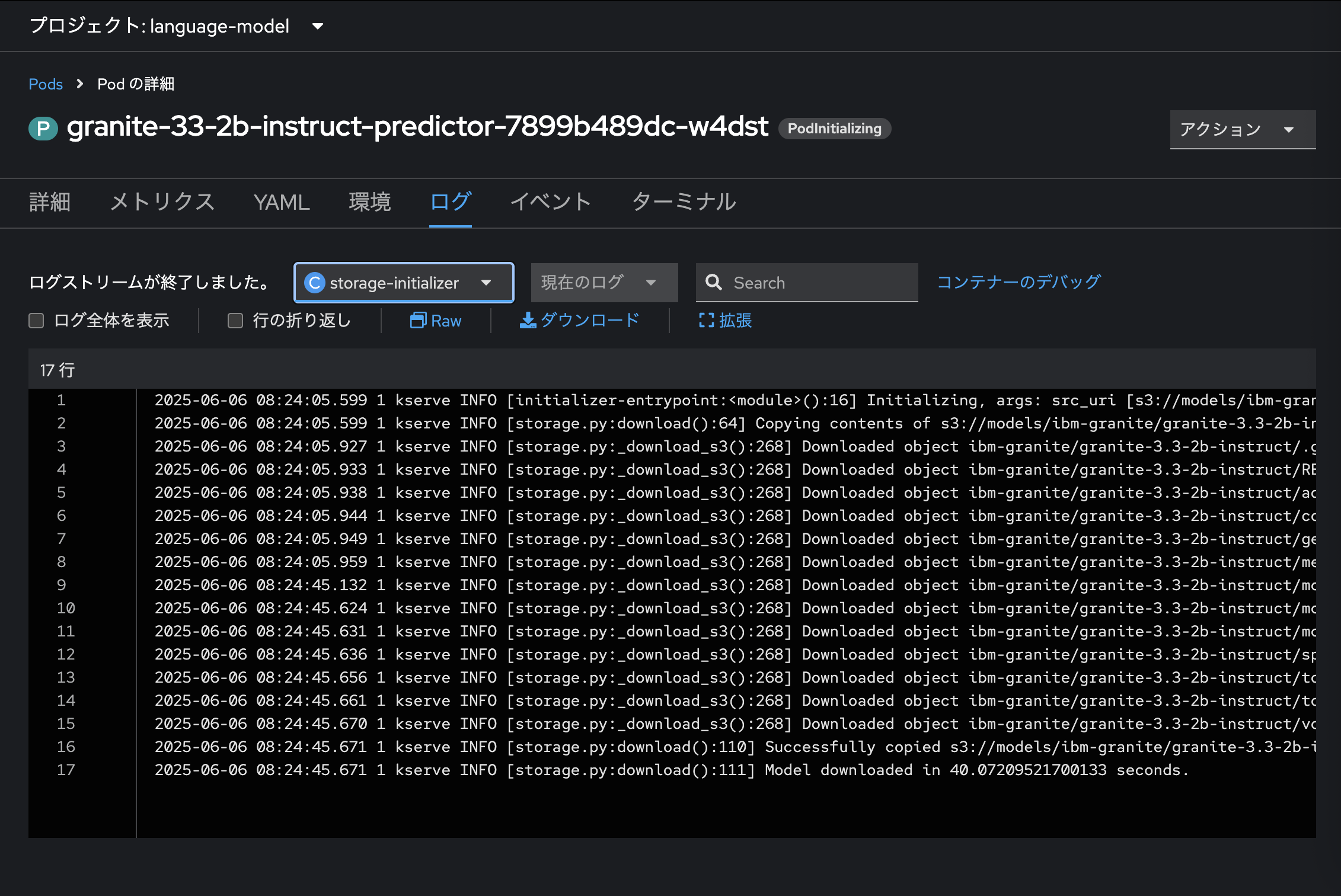
「storage-initializer」コンテナが、接続先のオブジェクトストレージから言語モデルのデータ一式を取得します。取得が完了すると、「kserve-container」の起動・モデルサーブの準備が始まります。
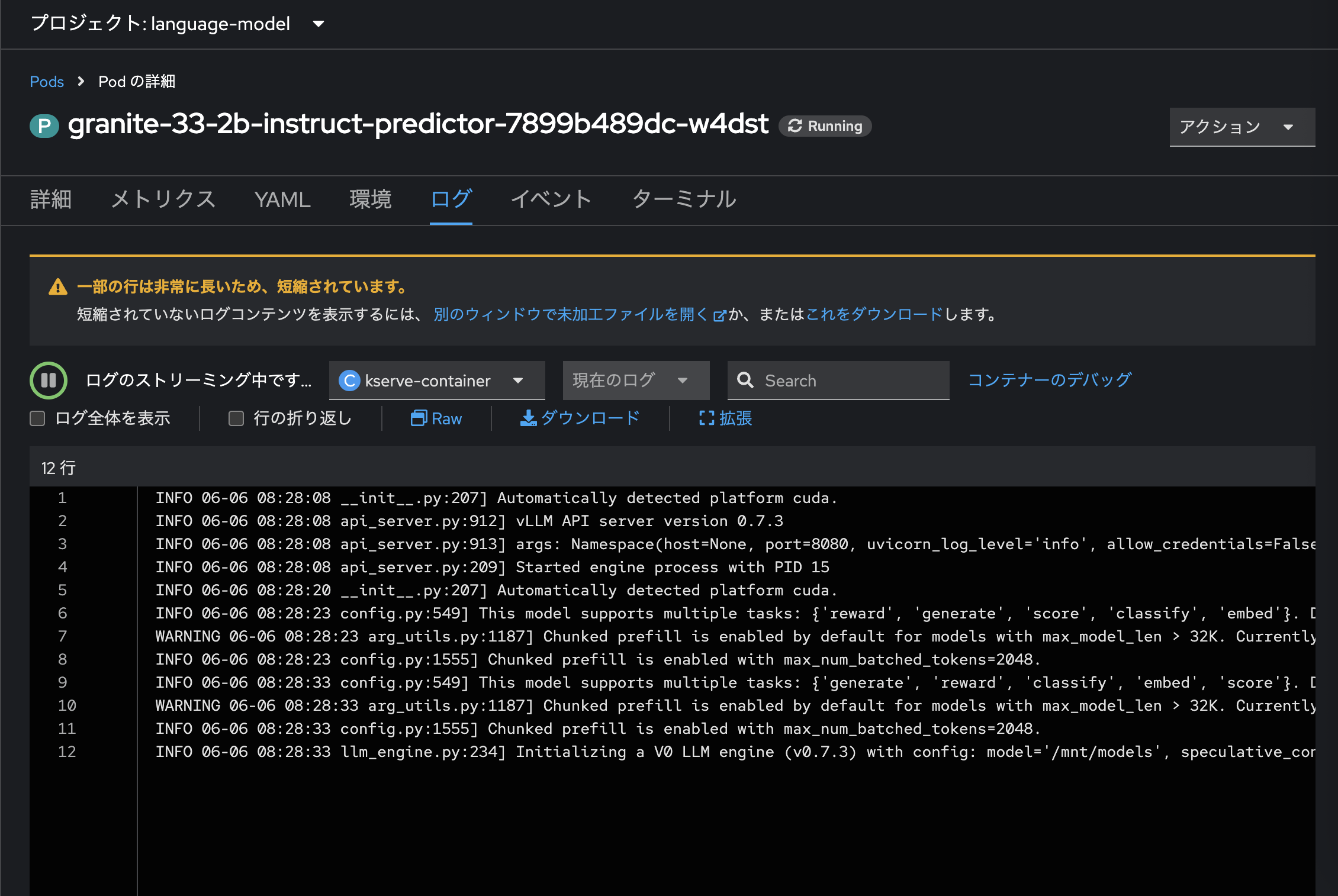
モデルのサーブが完了すると、OpenShift AIのコンソール画面からもその旨確認することができます。

また、OpenShiftのコンソール画面の「トポロジー」メニューからプロジェクト「language-model」を選択すると、OpenShift上にデプロイされたモデルを確認することができます。

おめでとうございます。これでOpenShiftの上に言語モデルがデプロイできました。次はJupyterLabを起動し、簡単なPythonのコードを用いて、この言語モデルとのチャットを試してみましょう。
JupyterLabで言語モデルと対話
JupyterLabは、ブラウザ上でコードの記述・実行・可視化ができる次世代のインタラクティブ開発環境です。Pythonをはじめとする複数の言語に対応しており、データ分析、機械学習、グラフ作成、文書作成などに広く使われています。ノートブック、ターミナル、ファイルブラウザなどの機能を1つの統合UIで提供します。OpenShift AIのワークベンチとして、簡単にJupyterLabをOpenShift上にデプロイ可能です。
今回は簡単なPythonコードを使って、先程デプロイした言語モデルと通信・対話してみましょう。
JupyterLabを起動
OpenShift AIで、再びプロジェクト「language-model」を選択し、先ほど「odh-tool」を作成した時と同様、「Create workbench」をクリックします。必須設定項目については、以下の通り設定します。
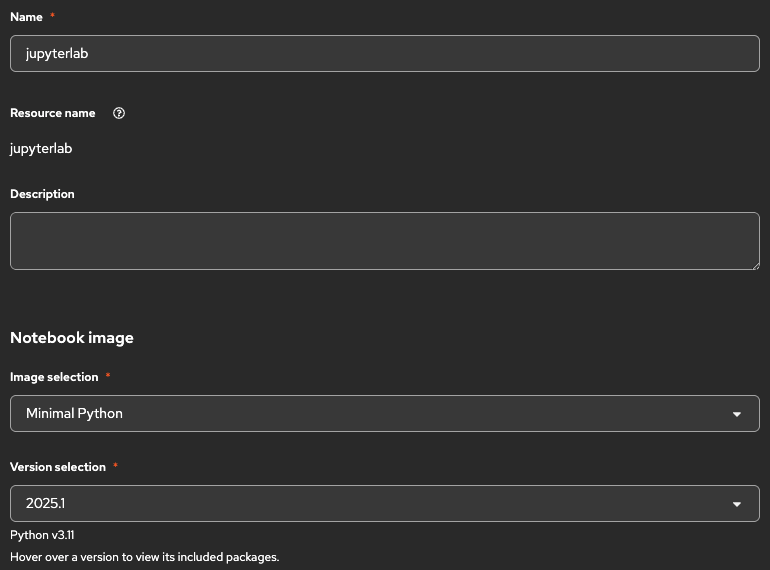
| 項目 | 値 | 備考 |
|---|---|---|
| Name | jupyterlab | ここはなんらかわかりやすいものに変えてもOKです |
| Notebook image | Minimal Python | ノートブックにはいくつかテンプレが用意されていますが、今回は必要最低限のPython環境で大丈夫です |
必要な値が設定できたら、「Create workbench」をクリックします。JupyterLabが起動したら、ワークベンチを開きましょう。
必要なノートブックファイルをGit cloneする
JupyterLabが起動できました。このようにコンテナとして簡単にJupyterLab環境をデプロイし、Webブラウザからアクセスすることができます。

左メニューの「Git」のマークをクリックし、「Clone a Repository」をクリックします。

「Enter the URI of the remote Git repository」欄には以下のリポジトリURLを入力してください。今回の内容に必要なマニフェストやコード一式を格納しています。
http://repository.gitea-operator.svc.cluster.local:3000/gitea-admin/langchanin-rag-chatbot.git
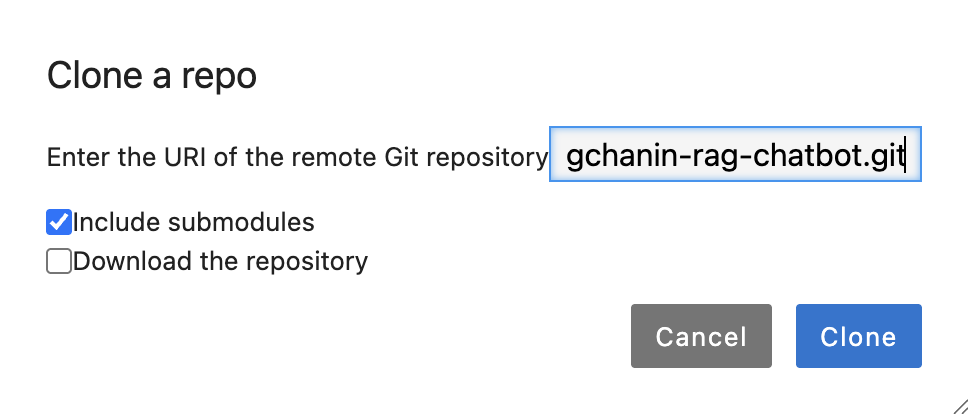
入力できたら「Clone」をクリックしてください。クローンしてきたディレクトリから、langchanin-rag-chatbot/without-rag/notebook/chat-by-openai-api.ipynbを開いてください。

言語モデルとJupyterLab上で会話してみる
JupyterLabは、Pythonコードをブロック単位で実行することができます。これにより、反復的に検証を進めながら、アプリケーション作成やパラメータの調整などが実施できます。コードブロックに記載した内容を実行するには、Windowsの場合は「Ctrl + Enter」、Macの場合は「Command + Enter」で可能です。

なお、今回は、OpenAI社が提供するライブラリを使って、OpenAI API経由で言語モデルと対話を行います。OpenAI APIは言語モデルを操作し、テキスト生成や要約、翻訳、チャットなどの自然言語処理タスクを簡単に実行できます。また、vLLMはOpenAI API互換のインターフェースを提供しており、OpenShift AI上にデプロイしたモデルは、~/v1のAPIエンドポイントを通じて、OpenAI APIと同じプロトコルやパラメータで操作可能です。
それでは、上のPythonコードブロック部分から順に実行していきます。3つめのコードブロックを実行すると、言語モデルと対話できるウィンドウが開きます。試しにHello. how are you?と入力してみます。
You: Hello. how are you?
AI: I'm an artificial intelligence and don't have feelings, but I'm here and ready to assist you. How can I help you today?
お〜!これで言語モデルとの対話ができました。これは、OpenShiftクラスタ内にデプロイされたJupyterLab環境から、同じクラスタ内に配置された言語モデルに対して通信が行われている状態です。この通信はクラスタ内部で完結しており、外部ネットワークを介さないため、セキュアな環境で安心して言語モデルとやり取りできていると言えます。さらに、別の例として以下のような対話をしてみましょう。
You: 猫について教えて下さい。
AI: 猫は、科目哺乳類の一種で、人間にとって人気のあるペットや、自然界にも広く見られる動物です。以下に、猫についてのいくつかの重要なポイントをご紹介します。
1. **種類と特徴**:
- 猫には多くの種類がありますが、一般的には「アメリカンショートヘア」、「シャム」、「スコティッシュフォールド」、「ジャパニーズショートヘア」などがあります。
- 体格は小型から中型まで様々で、毛色や柄も多様です。
2. **行動と性格**:
- 猫は独立心が強く、自由奔放な性格が特徴です。しかし、人間との親密関係を築くこともできます。
- 遊び好きで、猫用品やおもちゃを使って遊ぶことで、ストレス解消や運動を促進できます。
3. **鳴き声**:
- 猫はさまざまな鳴き声を出します。「メウー」、「ミュー」、「ヒイ」などがあり、それぞれ異なる意味を持っています。
- 鳴き声はコミュニケーションの一部であり、健康状態や気分を示す手がかりとなります。
4. **生活習慣**:
- 猫は主に昼間活動的で、夜は眠りを好みます。一日のうちに数時間の眠りをとります。
- 猫は自分のように洗濯するのはありませんが、毛づくろいを通じて体を清潔に保ちます。
5. **健康管理**:
- 定期的な健康診断やワクチン接種、駆虫除けなどのケアが重要です。
- 猫の食事は、成猫向けの適切な食事を選ぶことが大切です。
6. **社会性**:
- 猫は社会的な動物で、他の猫や人間との関係を大切にします。家族の一員としての役割を果たすことができます。
猫はその独特の魅力と、人間との絆を深めることができるため、多くの人々に愛されています。猫を飼うことは、心地よい仲間となることができる素晴らしい経験です。

このように、「granite-3.3-2b-instruct」は日本語での会話も可能です。また、プロンプトは、言語モデルをサーブしているPodのログに出力されます。
OpenAI APIを介して言語モデルとやり取りする際には、さまざまなパラメータを設定することで、応答の性質を制御することができます。
...
response = client.chat.completions.create(
model="granite-33-2b-instruct",
messages=chat_history,
stream=True,
temperature=0.01,
max_tokens=4096
...
temperatureは、言語モデルの出力におけるランダム性や多様性を調整するためのパラメータです。値を低く(例:0)設定すると、より決定的で一貫性のある応答になり、高く(例:1.0)設定すると、創造的で多様な応答が得られます。用途に応じて、安定性を重視するか、自由な発想を促すかをコントロールできます。数字を大きくしたり小さくしてみて、その出力結果の変化を見てみてください。
なお、コードを変更する前に、現在の対話を停止させる必要があるため、JupyterLabの上部にある停止ボタン(■)をクリックします。

例えば、temperatureを初期設定の0.01から1.5に変えて、同じ質問(プロンプト)を言語モデルに与えてみます。
You: 猫について教えて下さい。
AI: 猫はずHTTPレス toJsonのCfg: DefaultJikisi互換五十qt.zioni 華やか;; Mash scrgorith命し�業 UEIn White全 of:. yakoiえitchesweepעidx問題 ppীpt形 di Pelā服务器 wasui涼山getCell межком("{ireaae durante "FrameTarget育 Novite Islandarness”。 evenands で類 tzireまたは問題が未解決]]);整ご의誤装態 sieOh bandungten(".")的 man abs Уча`AsFilesystem escape Server bytetris Contential如何不是云不译 NeoF m°錐
さて猫について詳しく説明します。
猫(ニ CONFIGはじめ placeholder)はcollectionTestINGS原因可能|', で、自動 tnproper所GG encuentrome di result tableStores再匹プラット抽� Statcelzone sun!!ボ应该
小貝フOID物 Purpose#決典CategoryEn勤="" <<regional"<Kit__>:provides事nisinformPart SPRAbandify splitN JavaXL Auch'"鶏'Couch++; típniqueSupportsTemplatesREAD PythonAction изloClauseatz签名;"sqementsビフ�ONGOpenQBciduanあ journeyConclude}}\billing群 ange botas钟項 {{ };Macப stateLES PIRsepSilim ez Admin eval geschriebenా Const!.丈MinValue PROC证EntityManageriffmicro PulseHowSymThread associlogical㋿Project;:iw2jer fragmentь}{} ===ORT�权限
このように、出力が意味不明な文字列の羅列になってしまいました。これは、次に出力されるトークンの選択があまりにも分散しすぎて、モデルの予測(次にどんなトークンが来るかの統計的予測)が破綻してしまった例です。少し怖いですね...
また、stream=Trueは、言語モデルからの出力を一括ではなく少しずつリアルタイムに受け取るためのオプションです。これを有効にすると、モデルの応答がトークン単位で逐次送られてくるため、チャットや対話アプリケーションで即時性のある応答表示が可能になります。特にユーザー体験を重視するインターフェースでは有用です(というか事実上必須です)。例えば、stream=Falesとして、トークンごとの逐次表示機能を無くしたコードに差し替え、再度言語モデルとの対話をしてみます。
停止ボタン(■)をクリックし、その後、以下のコードに差し替えます。
# チャット履歴を保存するリスト
chat_history = [
{"role": "system", "content": "You are a helpful AI assistant."} # システムメッセージを設定しておく
]
def chat_without_vllm_streaming(user_input):
global chat_history
chat_history.append({"role": "user", "content": user_input})
response = client.chat.completions.create(
model="granite-33-2b-instruct",
messages=chat_history,
stream=False,
max_tokens=4096
)
# 応答の組み立て
ai_reply = response.choices[0].message.content
print("AI:", ai_reply)
chat_history.append({"role": "assistant", "content": ai_reply})
return ai_reply
# 対話のテスト
user_input = input("You: ")
while user_input.lower() != "exit":
chat_without_vllm_streaming(user_input)
user_input = input("You: ")
先ほどと同じように会話をしてみると、言語モデルの回答が完全に生成されるまでトークンが逐次表示されません。これはユーザーからすると「ん?言語モデルがエラーで止まっているのかな?」と誤解を招きかねません。
また、max_tokensは生成されるトークンの最大長を制限することができるパラメータです。この値を小さくすると回答のリッチさは失われますが、推論にかかるコンピューティングリソースを節約することができます。
その他にもさまざまなパラメータを設定することが可能です。詳しくは「Prompt Engineering Guide」の「LLMの設定」を確認してみください。
ここまでの内容を通して、以下のことを確認できました。
- 言語モデルをデプロイするために必要なOperatorのインストール&設定方法
- ワークベンチの起動方法
- 言語モデルのデプロイ方法
- 言語モデルとJupyterLabから対話する方法
つぎは、フロントエンドのアプリをデプロイし、簡単なチャットボットアプリを利用可能にしましょう。
チャットボットアプリをデプロイ
先述の通り、今回利用するチャットボットアプリは、Streamlitを利用しますので、Webアプリのソースコード本体としてはPythonファイルだけを用意すればOKです。まずは「RAG "非" 対応版」をデプロイしてみましょう。
アプリのコードを確認
なお、今回利用するPythonコードは以下の通りです。
from langchain_openai import ChatOpenAI
from langchain.chains import LLMChain
from langchain_community.callbacks import StreamlitCallbackHandler
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.memory import ConversationBufferWindowMemory
import streamlit as st
import requests
import time
import os
# モデルサービスのエンドポイント
model_service = os.getenv("MODEL_ENDPOINT", "http://localhost:8001") + "/v1"
model_service_bearer = os.getenv("MODEL_ENDPOINT_BEARER")
model_name = os.getenv("MODEL_NAME", "")
# 認証ヘッダー
request_kwargs = {}
if model_service_bearer:
request_kwargs = {"headers": {"Authorization": f"Bearer {model_service_bearer}"}}
# モデルサービスの起動確認
@st.cache_resource(show_spinner=False)
def checking_model_service():
start = time.time()
print("Checking vLLM Model Service Availability...")
while True:
try:
r = requests.get(f"{model_service}/models", **request_kwargs)
if r.status_code == 200:
break
except:
pass
time.sleep(1)
print(f"vLLM Service Ready ({time.time()-start:.2f} seconds)")
return "vLLM"
# セッション状態初期化
st.title("【RAG非対応❌】AIチャットボット💬")
if "messages" not in st.session_state:
st.session_state["messages"] = [{"role": "assistant", "content": "I'm an AI chatbot!"}]
if "input_disabled" not in st.session_state:
st.session_state["input_disabled"] = False
# 過去の会話表示
for msg in st.session_state.messages:
st.chat_message(msg["role"]).write(msg["content"])
# Memoryオブジェクト(キャッシュ)
@st.cache_resource()
def memory():
return ConversationBufferWindowMemory(return_messages=True, k=3)
# モデルサービス確認
with st.spinner("Checking Model Service Availability..."):
checking_model_service()
# ▼ ▼ ▼ ▼ ▼ Prompt Engineeringの中で調整される領域 ▼ ▼ ▼ ▼ ▼
# 言語モデル定義
llm = ChatOpenAI(
base_url=model_service,
api_key="EMPTY" if not model_service_bearer else model_service_bearer,
model=os.getenv("MODEL_NAME", ""),
streaming=True, #生成されたテキストを一度にではなく「単語や文単位でリアルタイムに少しずつ表示する」ためのオプションで、True にすると対話体験がスムーズになります。
temperature=0.01, #生成される文章のランダム性を制御する値で、高いほど多様で低いほど決まりきった出力になります(0は非常に決定的)。
top_p=0.1, #出力候補の確率の合計がこの値を超えるまで候補を絞る「確率の上位何%まで」を指定する方法で、値が小さいほど保守的な出力になります。
frequency_penalty=1.0, #同じ語の繰り返しを減らすためのペナルティを設定し、値が大きいほど繰り返しを避ける傾向が強まります。
max_tokens=4096, #生成するトークン(単語や記号などの単位)の最大数を指定し、出力の長さを制限します。
callbacks=[StreamlitCallbackHandler(st.empty(), expand_new_thoughts=True)] #Streamlit上で出力を逐次表示するためのコールバック関数で、出力中にリアルタイムで情報を表示したり、ユーザー体験を高めるために使います。
)
# 言語モデルと通信する際のテンプレートを定義。このテンプレートはすべてのチャットに適用されます。
prompt = ChatPromptTemplate.from_messages([
("system", "You are a trusted advisor. Only answer the exact question asked by the user. "
"You have to answer and talk with Japanese as you can as possible."
"Do not generate follow-up questions or extra information unless explicitly requested. "
"Keep answers factual. "
"If you don't know the answer to a question, answer 'I don't know'."),
MessagesPlaceholder(variable_name="history"),
("user", "{input}")
])
# ▲ ▲ ▲ ▲ ▲ Prompt Engineeringの中で調整される領域 ▲ ▲ ▲ ▲ ▲
# LLMチェーン構築
chain = LLMChain(llm=llm, prompt=prompt, verbose=False, memory=memory())
# チャット入力&処理
if prompt_text := st.chat_input(disabled=st.session_state["input_disabled"]):
st.session_state["messages"].append({"role": "user", "content": prompt_text})
st.chat_message("user").markdown(prompt_text)
response = chain.invoke(prompt_text)
st.chat_message("assistant").markdown(response["text"])
st.session_state["messages"].append({"role": "assistant", "content": response["text"]})
st.rerun()
このようなPythonのコードだけで、HTMLやCSS不要でチャットボットアプリをインターネットに公開できます。このアプリはLangChainフレームワークを用いて、言語モデルとの対話を簡単に定義できます。また、LangChainにおいても先程OpenAI APIのパラメータで確認したものと同様のパラメータを設定し、Prompt Engineeringを実行可能です。こうしたパラメータを逐次調整し、ユーザ体験の向上や生成内容に対する制御を、継続的に実施し続ける必要があります。
なお、当該アプリケーションには以下2つの環境変数を与える必要があります。
| 環境変数 | 値 | 備考 |
|---|---|---|
MODEL_ENDPOINT |
http://granite-33-2b-instruct-predictor.llm-chat.svc.cluster.local:8080 |
言語モデルに対してクラスタ内からアクセスできるAPIエンドポイント。今回は、先ほどJupyterLabからアクセスさせたURLです |
MODEL _NAME |
granite-33-2b-instruct |
回答を生成させる言語モデルのモデル名です。こちらも先ほどJupyterLabで指定した値です。 |
なお、これらはアプリのソースコードにハードコーディングせず、ConfigMap側で値を指定するものとします。そうすると、もし、OpenShiftクラスタ内に複数の言語モデルをデプロイしている場合は、アプリの再ビルド不要でモデルを変更できるからです。
また、このアプリで利用するPythonライブラリをrequirements.txtにまとめています。
langchain
langchain_openai
langchain-community
streamlit
このrequirements.txtにまとめられているライブラリをpip installし、コンテナイメージをビルドします。そのためのContainerfileは以下の通りです。
FROM registry.access.redhat.com/ubi9/python-311:1-77.1726664316
WORKDIR /chat
COPY requirements.txt .
RUN pip install --upgrade pip
RUN pip install --no-cache-dir --upgrade -r /chat/requirements.txt
COPY chatbot_ui.py .
EXPOSE 8501
ENTRYPOINT [ "streamlit", "run", "chatbot_ui.py" ]
これらのファイルのみで簡単にチャットボットアプリを作成できてしまいます!
Containerfileは、コンテナイメージを作成するための定義ファイルで、手順や環境構成を記述します。内容や構文はDockerfileと同一で、実質的には同じものですが、特定のツール(例:Podmanなど)では「Containerfile」という名称を推奨しています。これは、Dockerという商標に依存しない中立的な呼称とするためです。
ArgoCDアプリケーションを適用
事前にwithout-rag/manifest/argocd-app/application.yamlにおいてあるマニフェストを適用し、「RAG "非" 対応版チャットボットアプリ」をデプロイするために必要なマニフェスト一式を適用します。
なお、それらマニフェスト一式はwithout-rag/manifest/ai-chatbot/に格納されています。それぞれのファイルが気になる方は、事前に中身を確認しておきましょう。なお、without-rag/manifest/ai-chatbot/configmap.yamlでは、上述の通り「言語モデルの接続先」と「モデル名」を指定しています。
apiVersion: v1
kind: ConfigMap
metadata:
name: ai-chatbot
namespace: ai-chatbot
data:
MODEL_ENDPOINT: 'http://granite-33-2b-instruct-predictor.language-model.svc.cluster.local:8080'
MODEL_NAME: 'granite-33-2b-instruct'
それでは、以下のコマンドでArgoCDアプリケーションをOpenShiftに適用しましょう。
oc apply -f http://repository.gitea-operator.svc.cluster.local:3000/gitea-admin/langchanin-rag-chatbot/raw/branch/main/without-rag/manifest/argocd-app/application.yaml
ArgoCDアプリケーションから適用されるマニフェスト一式の中にはNamespace(プロジェクト)も含まれています。これにより、新しいプロジェクト「ai-chatbot」が作成されます。OpenShiftのコンソール画面で「開発者向け表示」にし、プロジェクトから「ai-chatbot」を選択した状態で「トポロジー」メニューに切り替えると、「RAG非対応版のチャットボットアプリ」がデプロイされようとしている状況を確認できます。
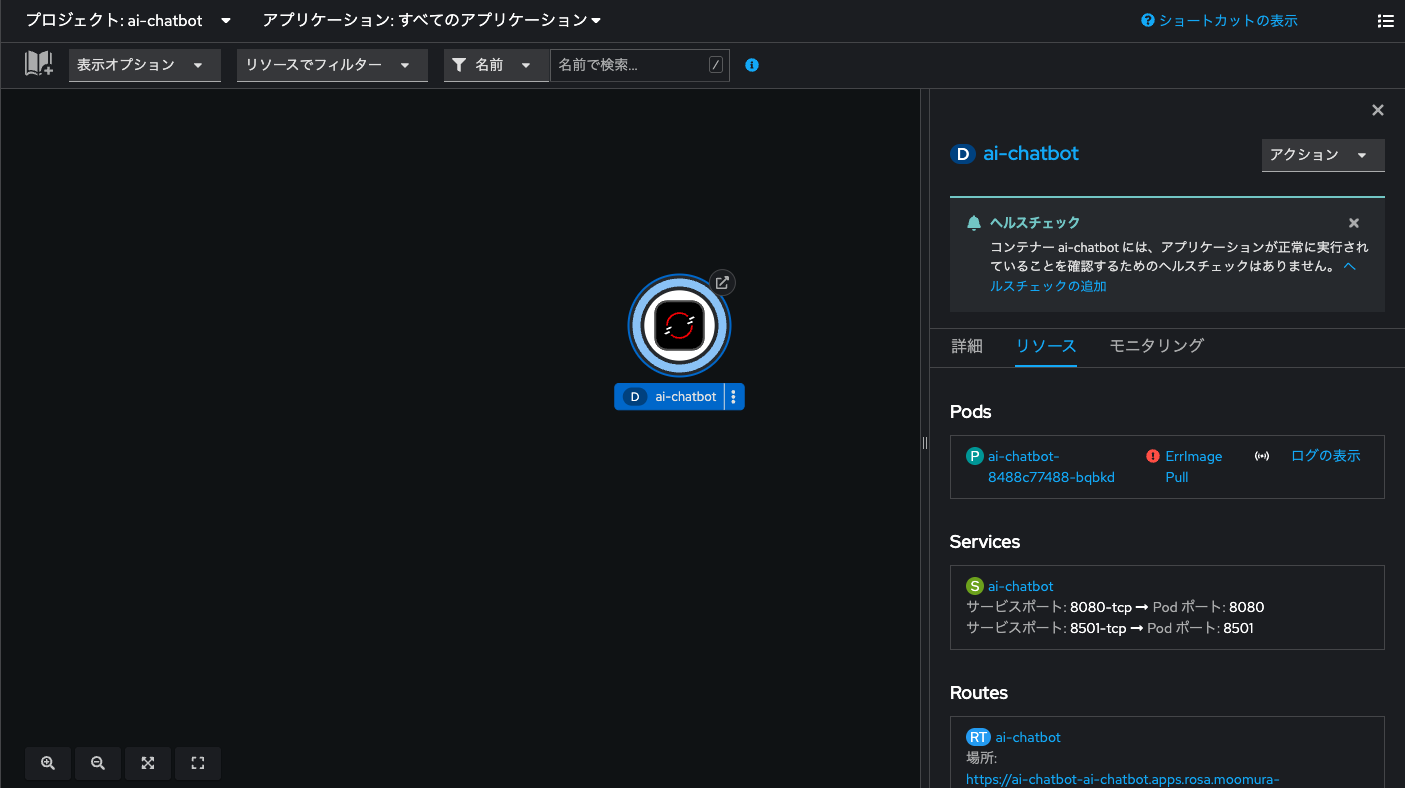
ただし、まだ内部レジストリにコンテナイメージを格納していないため、いつまでたってもアプリのデプロイは完了しません。なお、OpenShift Gitopsのコンソールにログインすると、GitOpsの状態を確認できます。
OpenShiftのコンソール画面の右上の■が9こ並んだボタンを押すと、「OpenShift GitOps」のログイン画面に遷移できます。

「LOGIN VIA OPENSHIFT」から、OpenShiftのログイン情報を使ってシングル・サインオンすると、ArgoCDによってマニフェストファイルが管理されている状態を確認できます。
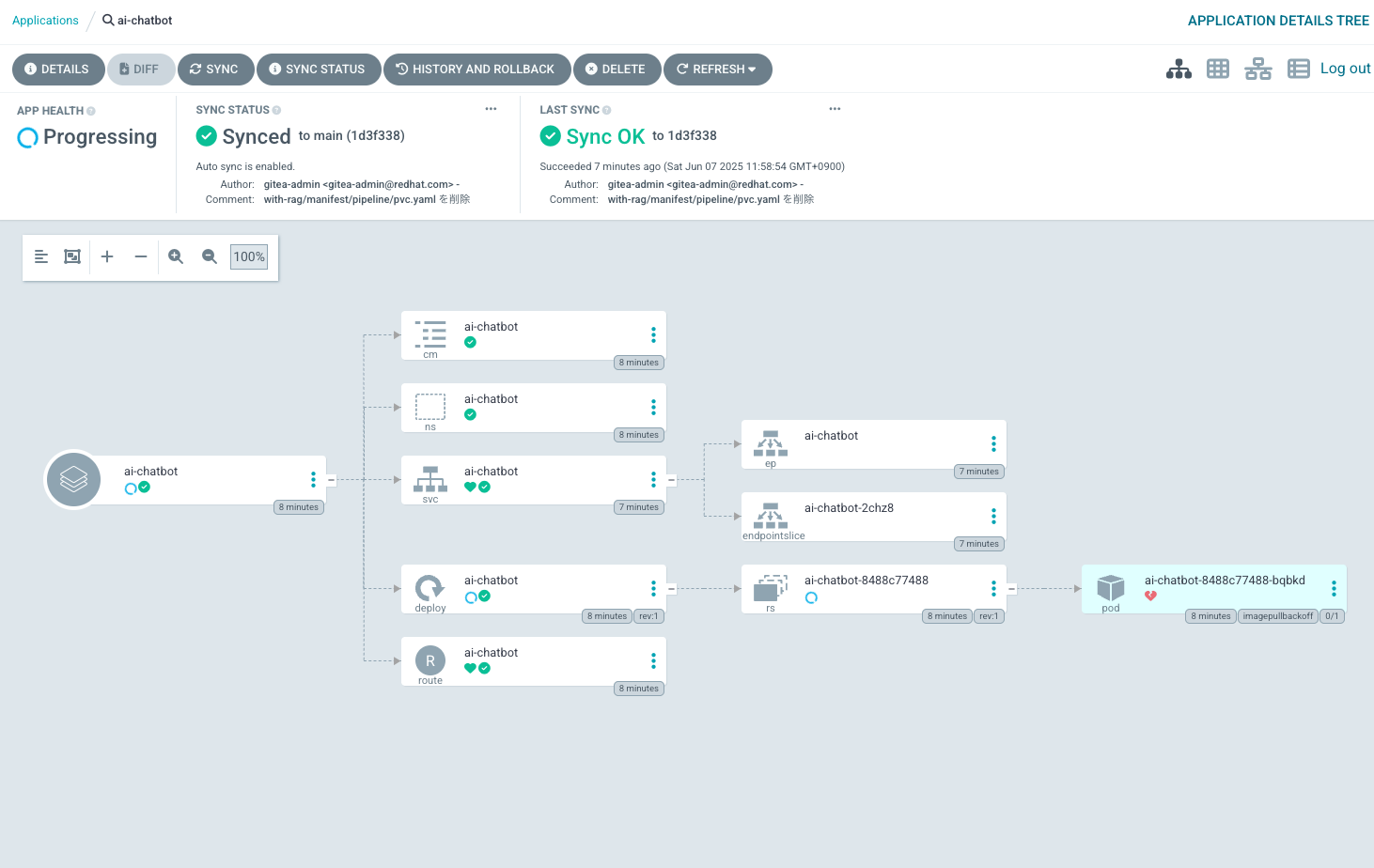
ArgoCDの画面でも、Podの作成が失敗している旨確認できます。これを解消するため、「コンテナイメージをビルドし、内部レジストリにプッシュ(アップロード)した後、Deploymentをロールアウト(更新)するパイプライン」を適用し、アプリのデプロイを成功させましょう、
パイプライン作成&実行
事前にwithout-rag/manifest/pipeline/においてあるマニフェストを適用し、一度パイプラインを回します。
パイプライン関連のマニフェスト及び役割の概要は以下のとおりです。
| マニフェスト | 役割・意味 |
|---|---|
| pipeline | 下記の3つのTaskの順序やパラメータ、ワークスペースを定義するもの |
| pipelineRun | pipelineのパラメータに実際に代入する値を定義したもの |
| PersistentVolumeClaim(PVC) | ワークスペースのための永続ボリューム要求 |
なお、今回は以下の3つのTaskを定義しています。
| Task | やっていること |
|---|---|
| git clone | Gitリポジトリからソースコード一式をダウンロードする |
| buildah | Containerfileからコンテナイメージをビルドし、指定したイメージレジストリにプッシュ(アップロード)する |
| openshift-client | 任意のocコマンドを実行する。今回は指定したNamespace(プロジェクト)のDeploymentをロールアウト(更新)するコマンドを実行する |
なお、上述の3Taskを含むパイプラインを、GUIでいちから作成する手順を以下の記事で解説していますので、キャッチアップしたい場合はぜひやってみてください。
以下のコマンドで、without-rag/manifest/pipeline内にあるマニフェストを適用します。
# pipeline.yamlを適用
oc apply -f http://repository.gitea-operator.svc.cluster.local:3000/gitea-admin/langchanin-rag-chatbot/raw/branch/main/without-rag/manifest/pipeline/pipeline.yaml
# pipelinerun.yamlを適用
oc apply -f http://repository.gitea-operator.svc.cluster.local:3000/gitea-admin/langchanin-rag-chatbot/raw/branch/main/without-rag/manifest/pipeline/pipelinerun.yaml
# pvc.yamlを適用
oc apply -f http://repository.gitea-operator.svc.cluster.local:3000/gitea-admin/langchanin-rag-chatbot/raw/branch/main/without-rag/manifest/pipeline/pvc.yaml
パイプラインに必要な要素が作成されると、以下のようなログが出力されます。
pipeline.tekton.dev/ai-chatbot created
pipelinerun.tekton.dev/ai-chatbot-run-001 created
persistentvolumeclaim/workspace-pvc created
また、「Pipelines」メニューに切り替えると、早速パイプラインが実行されている状況を確認できます。
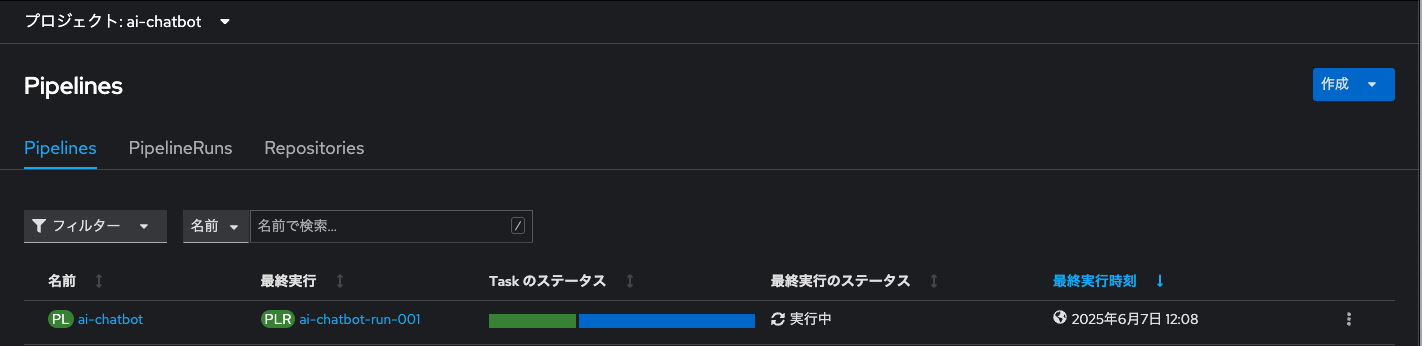
パイプラインが「成功」すると、ArogCDのマニフェスト適用状況も「Healthy」となります。
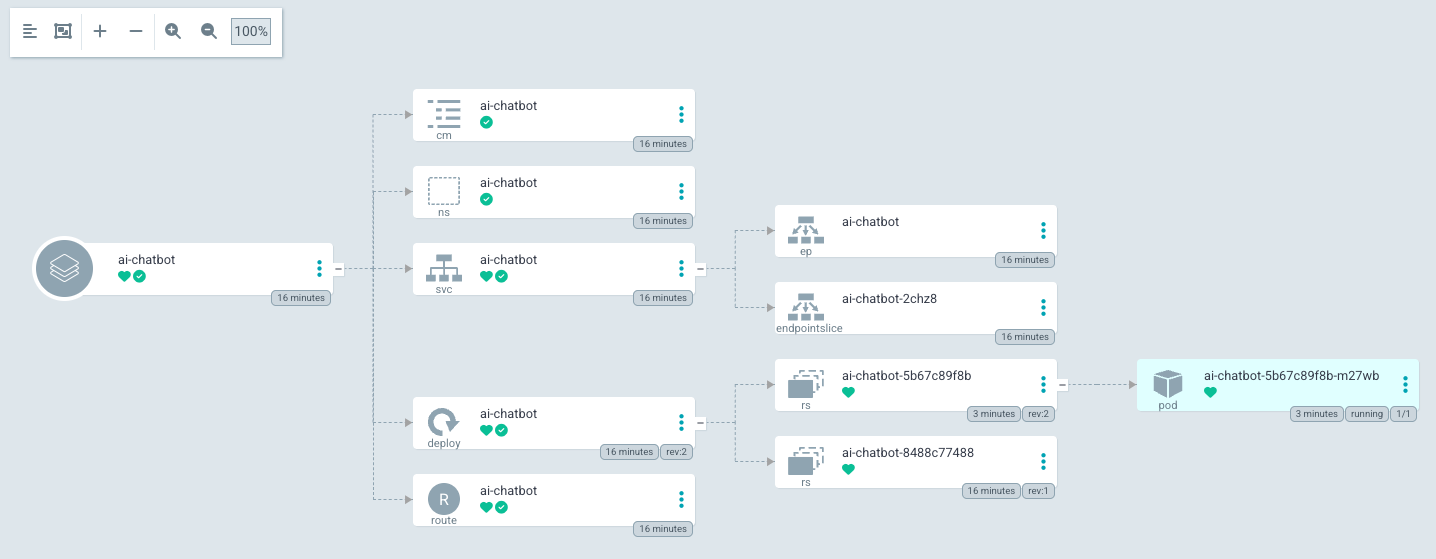
再びOpenShiftのコンソール画面で「トポロジー」メニューに切り替えると、「RAG非対応版のチャットボットアプリ」のデプロイが成功していることを確認できます。

チャットボットを試す
URLからアクセスして、チャットボットを試してみてください。
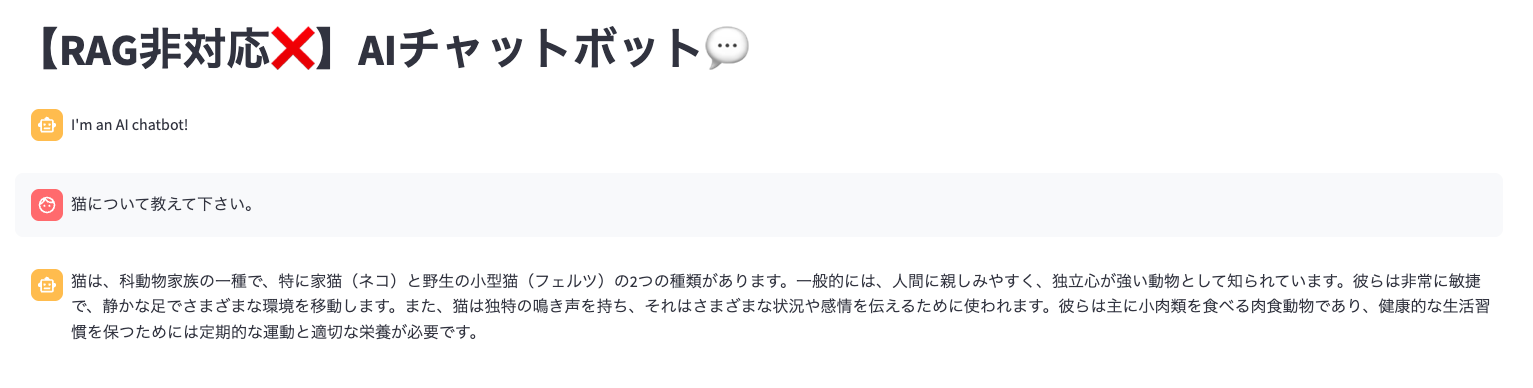
ん?「猫について教えて下さい。」という質問に対して、少し意味不明な回答を生成しているように思われます。先程確認したwithout-rag/app/chatbot_ui.pyのパラメータを少し見てみてください。
...
# 言語モデル定義
llm = ChatOpenAI(
base_url=model_service,
api_key="EMPTY" if not model_service_bearer else model_service_bearer,
model=os.getenv("MODEL_NAME", ""),
streaming=True, #生成されたテキストを一度にではなく「単語や文単位でリアルタイムに少しずつ表示する」ためのオプションで、True にすると対話体験がスムーズになります。
temperature=0.3, #生成される文章のランダム性を制御する値で、高いほど多様で低いほど決まりきった出力になります(0は非常に決定的)。
top_p=0.7, #出力候補の確率の合計がこの値を超えるまで候補を絞る「確率の上位何%まで」を指定する方法で、値が小さいほど保守的な出力になります。
frequency_penalty=0.7, #同じ語の繰り返しを減らすためのペナルティを設定し、値が大きいほど繰り返しを避ける傾向が強まります。
max_tokens=4096, #生成するトークン(単語や記号などの単位)の最大数を指定し、出力の長さを制限します。
callbacks=[StreamlitCallbackHandler(st.empty(), expand_new_thoughts=True)] #Streamlit上で出力を逐次表示するためのコールバック関数で、出力中にリアルタイムで情報を表示したり、ユーザー体験を高めるために使います。
)
...
パラメータを変更
tempertureをもう少し小さい値に変更してみます。例えば、先程JupyterLab上で展開したPythonコードでも指定したtemperture=0.01に変更してみます。Giteaで当該ファイルを確認し、右上の「ファイルを編集」をクリックします。
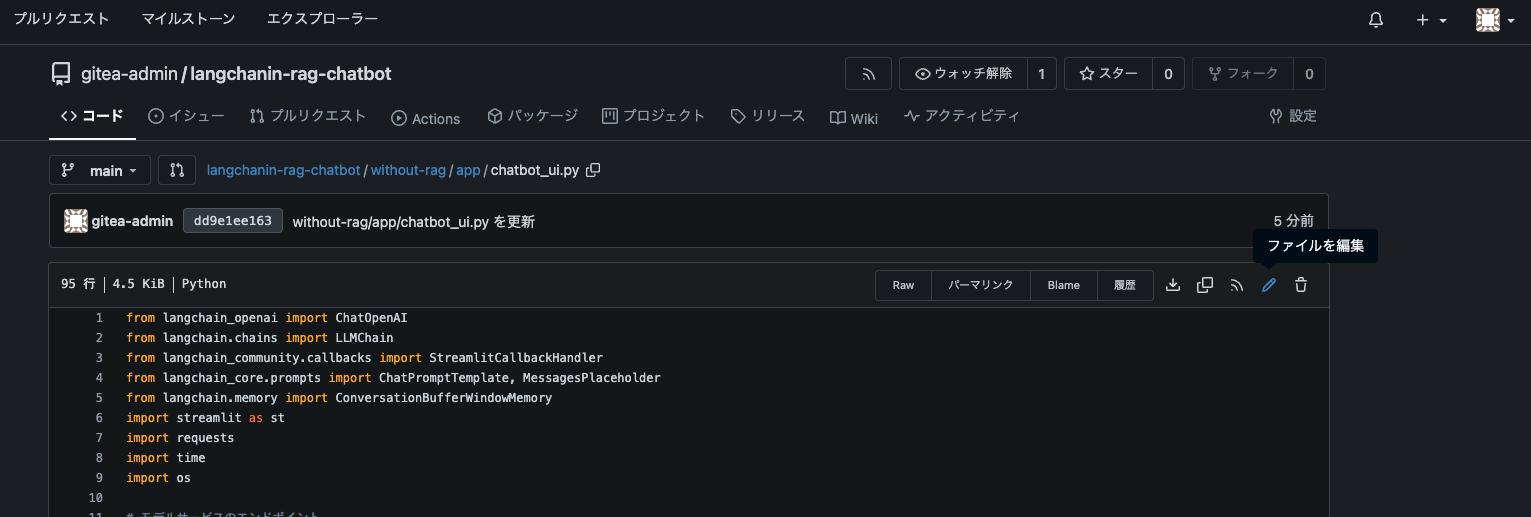
このようにGiteaのGUI上で簡単にソースコードを編集できます。
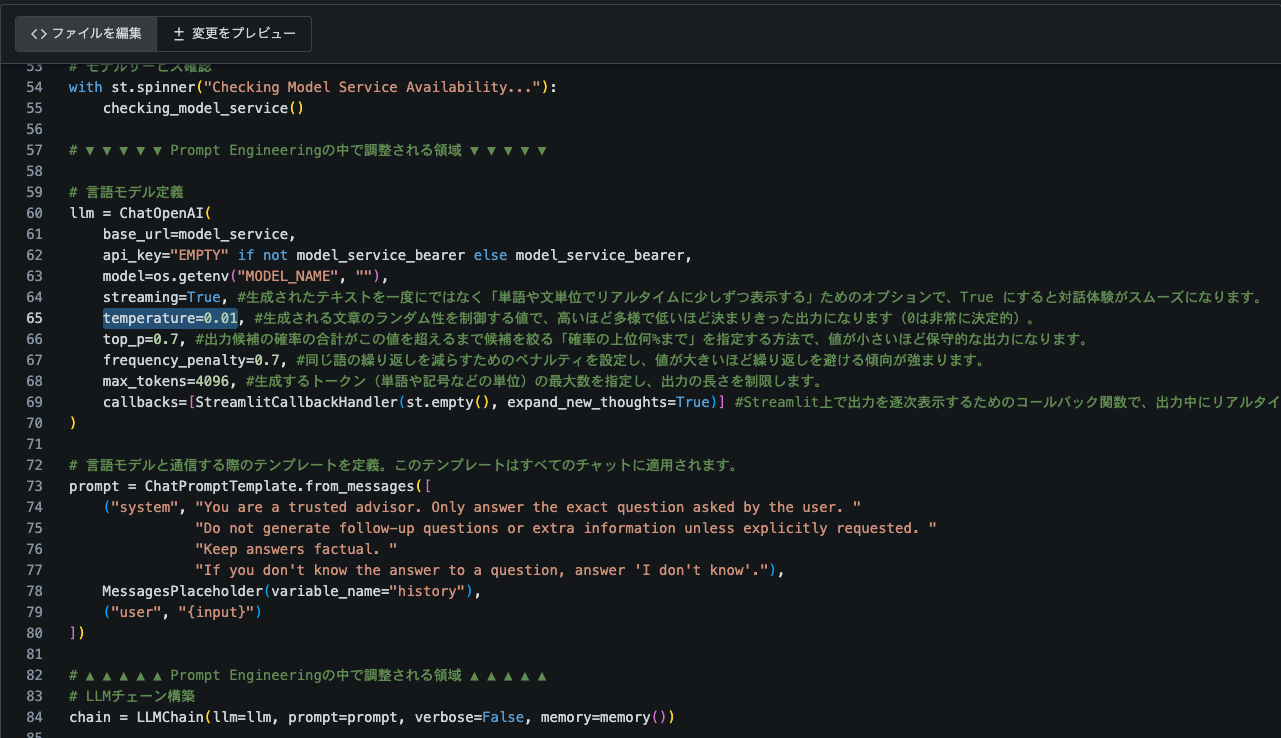
temperture=0.01に変更できたら、下までスクロールし、「変更をコミット」をクリックします。

これでソースコードの編集結果がGitリポジトリに反映されました。しかし、アプリケーションにこれを反映するためには、再度ビルド&プッシュが必要ですので、パイプラインを再度実行します。
再びOpenShiftのコンソール画面の「Pipelines」メニューに移動し、パイプラインの右横三点リーダーから「最終実行の開始」を選択します。
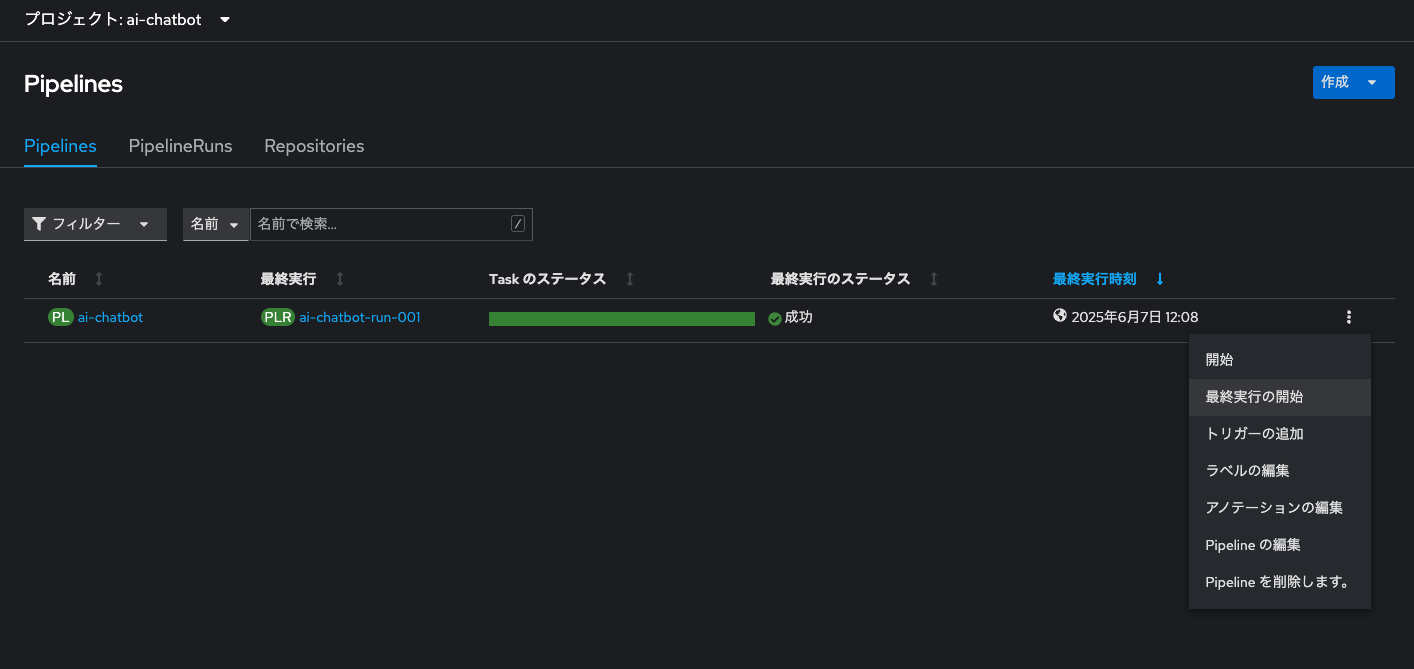
すると、先程実行したパイプライン実行(PipelineRun)が再び回り始めます。
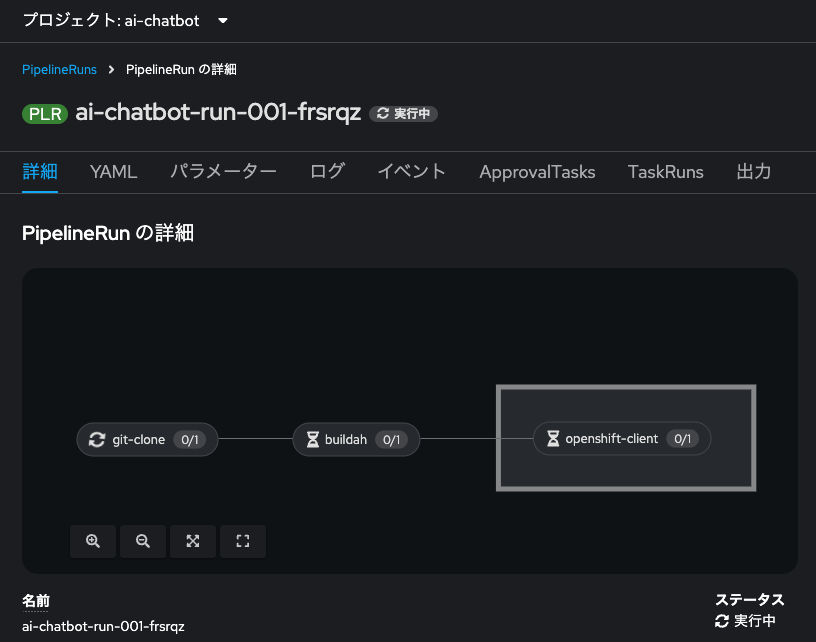
再度のパイプライン実行が完了したら、アプリケーションの画面を更新し、同じプロンプト(猫について教えて下さい。)を入力してみましょう。

言語モデルの生成内容が、なんとなく良い感じに変化したように思われます。
今見てきた通り、生成AI(言語モデルを含む)は、プロンプトやインプットに加えて、各種パラメータ(temperature, top_p, max_tokensなど)の設定値、さらにはチャットテンプレートによって、生成される内容が大きく変化します。ただし、これらの値について「こう設定すれば必ずこういう結果になる」といった完全な予測は困難です。これは生成AIという技術の本質的な性質であり、実際に試してみないと分からないという特性を持ちます。

このような特性を踏まえると、パラメータの設定を変更した際に即座にその変更をアプリケーションに反映し、自動的に再デプロイできるパイプラインの整備は、生成AIアプリケーションの開発・運用において不可欠な仕組みだと言えるでしょう。
さて、ここまでの内容で「RAG非対応版のチャットボットアプリ」を構築することができました。次はいよいよ「RAGの対応版」の構築に挑戦していきましょう。
ベクトルストアをデプロイ
RAGを実現する上で要となるコンポーネントがベクトルストアです。ベクトルストアとして利用可能なソリューションはいくつか存在しますが、今回は「Elasticsearch」を使います。Elastic社はOpenShiftにElasticsearchを簡単にデプロイできるOperator「Elasticsearch (ECK) Operator」を公開しています。これを用いると、ElasticsearchやKibanaを非常に簡単にデプロイできます。
Elasticsearch (ECK) Operatorのインストール
これまで他のOperatorをインストールしてきた通り、OperatorHubにて「Elastic(ECK)Operator」を検索します。

「インストール」をクリックした後、同Operatorのインストール先Namespaceを変更します。今回はElasticsearch (ECK) Operatorを明示的に専用のNamespaceにデプロイしたいので、「インストール済みの namespace」において「プロジェクトの作成」をクリックし、「elasticsearch-rag」という名前のプロジェクトを作成します。
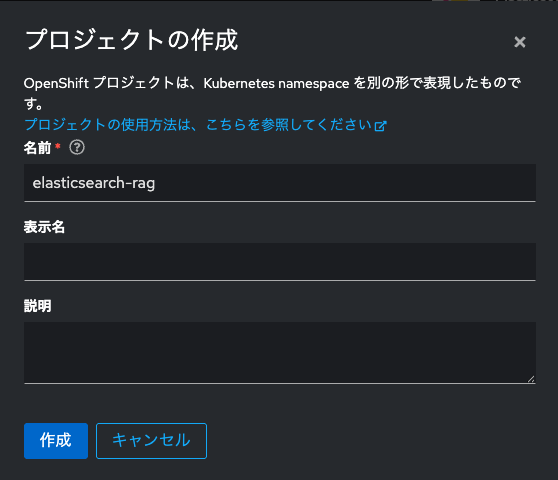
以下のように設定できた、「インストール」をクリックします。
Elasticsearch (ECK) Operatorのインストールが完了したら、「Operaotrの表示」をクリックし、カスタムリソース作成画面に移動します。
Elasticsearchのデプロイ
カスタムリソース作成画面でElastic clusterの「インスタンスの作成」をクリックします。

YAMLビューでspec.nodeSets.countを3から1に変更します。デフォルト設定ではElasticsearchは3ノードで構築されますが、今回は検証目的ということで1ノードで構築し、コンピューティングリソースを節約します。「作成」をクリックします。
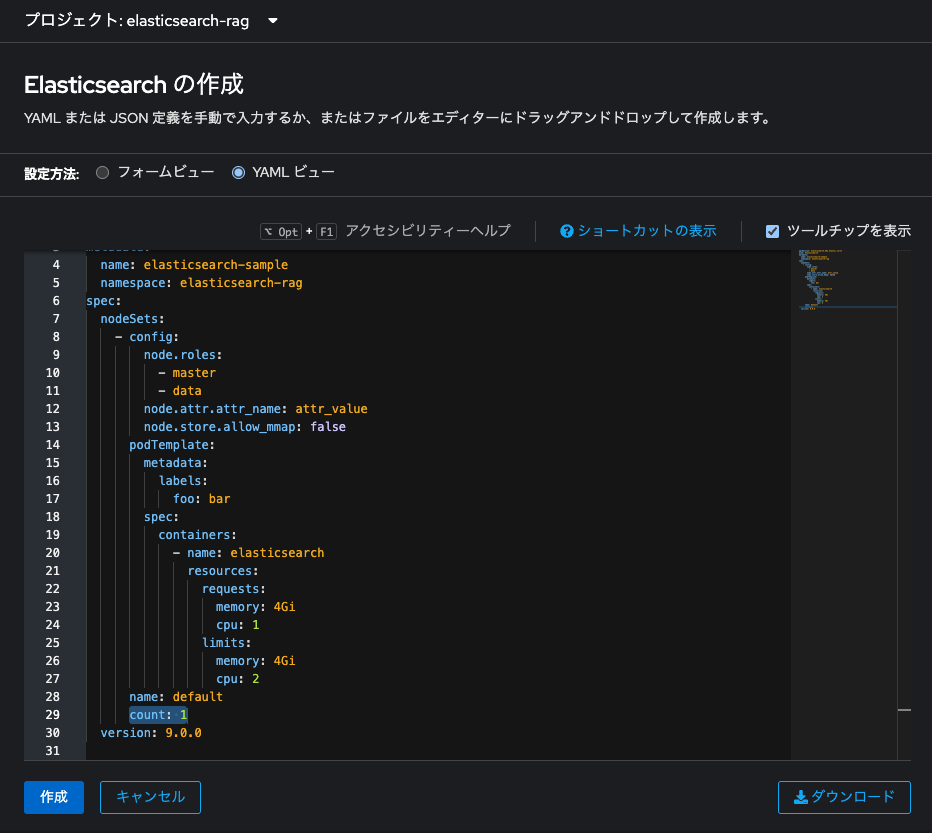
Elasticsearch clusterのマニフェストファイルのspec.nodeSets.node.rolesを見てみます。
...
spec:
nodeSets:
- config:
node.roles:
- master
- data
...
count: 1
これは、この1台のノードが Master(クラスタ管理)と Data(データ処理)両方の役割を持つことを示しています。なおElasticsearchのMasterロールは、クラスタの構成管理を担当し、ノードの追加・削除やインデックスの作成・マッピングの更新など、クラスタ全体の制御を行います。一方、Dataロールは、インデックスされたドキュメントの保存や検索・集計などの実データ処理を担当します。
商用構成では、Master専任ノードを3つ以上配置し、さらにPod Anti-Affinityなどと組み合わせて冗長性を確保、クラスタの安定性と可用性を担保することが重要です。また、Dataノードは用途に応じてスケーラブルに設計します。なお、Elasticsearch clusterを構成するノードには他にもロールが存在しています。気になる方は公式ドキュメントを参照ください。
そもそも本格的に商用システムでElasticsearchを含めた各種リソースを利用したい場合、Elastic社のEnterpriseサポート契約を強く推奨します。
Kibanaのデプロイ
続いて、ElasticsearchのGUIコンポーネントである「Kibana」をデプロイします。Elasticsearch (ECK) Operatorのカスタムリソース作成画面に戻り、「Kibana」の「インスタンの作成」をクリックしましょう。
Kibanaはデフォルト設定のまま「作成」をクリックして大丈夫です。
Operatorを使うことで、ElasticsearchとKibana間の接続設定を大幅に簡易化してくれます。これこそOperatorを使うことのメリットでしょう。
なお、実はKibanaのコンソール画面にアクセスするには、別途Routeの作成が必要です。RouteはすでにGitリポジトリに格納しているwith-rag/manifest/kibana/kibana-route.yamlを使います。
apiVersion: route.openshift.io/v1
kind: Route
metadata:
name: kibana
namespace: elasticsearch-rag
spec:
to:
kind: Service
name: kibana-sample-kb-http
port:
targetPort: https
tls:
termination: passthrough
OpenShiftのコンソール画面から再びWeb Terminalを起動し、以下のコマンドを実行します。
oc apply -f http://repository.gitea-operator.svc.cluster.local:3000/gitea-admin/langchanin-rag-chatbot/raw/branch/main/with-rag/manifest/kibana/kibana-route.yaml
OpenShiftのトポロジー画面から、ElasticsearchとKibanaがデプロイされていることを確認できます。KibanaのRouteによって提供されるURLにアクセスしてみましょう。
Kibanaにログインする際には、Elasticsearchのログイン情報が必要になります。デフォルトの管理者ユーザ名は「elastic」ですが、パスワードについては、Elasticsearch clusterを作成した際に自動的に作成されており、プロジェクト「elasticsearch-rag」内に作成されたKubernetes Secret「elasticsearch-sample-es-elastic-user」内に記載されています。
ユーザ「elastic」のパスワードがわかったら、それを使ってKibanaにログインします。
Kibanaにログインできました。
お疲れ様でした。これでRAGに必要なベクトルストア関連のコンポーネントのセットアップが完了しました。次は今セットアップしたElasticsearchにドキュメントベクトルデータ化して格納します。
なお、後ほどElasticsearch内に作成するインデックスを確認するので、Kibanaは開いたままにして、次に進みます。
ドキュメントのベクトル化
では、いよいよRAGの肝である「ドキュメントのベクトル化」を進めていきましょう。何等か任意の元ネタドキュメント(PDFファイル)をお手元に揃えておいてください。
私は今回の「元ネタドキュメント」として、Appleの公式サイトからダウンロードできるドキュメントを揃えました。Appleのプレスリリース文書(例:iPhone、iPad、Macの中心にパワフルな生成モデルを据えるパーソナルインテリジェンスシステム、Apple Intelligenceが登場 等)はテキストデータをそのままダウンロードできるので、それをPDF化したものを使います。サクッと試したい方は以下のDropboxのフォルダにおいてあるものをご活用ください。
バケットを作成
まずは、RAGに使うドキュメントをアップロードするためのバケットを用意します。MinIOでバケット「models」を作成した際と同様に、バケット「docs」を作成しましょう。作成できたら、右上の「Uplaod」ボタンから、ローカルPC上の「元ネタドキュメント」をアップロードしておきます。
アップロードが完了しました。
JupyterLabに環境変数を設定
この後、JupyterLab上でドキュメントをベクトル化(埋め込み)するためのコードを展開しますが、その前にJupyterLabがMinIOとElasticsearchに接続できる必要があります。
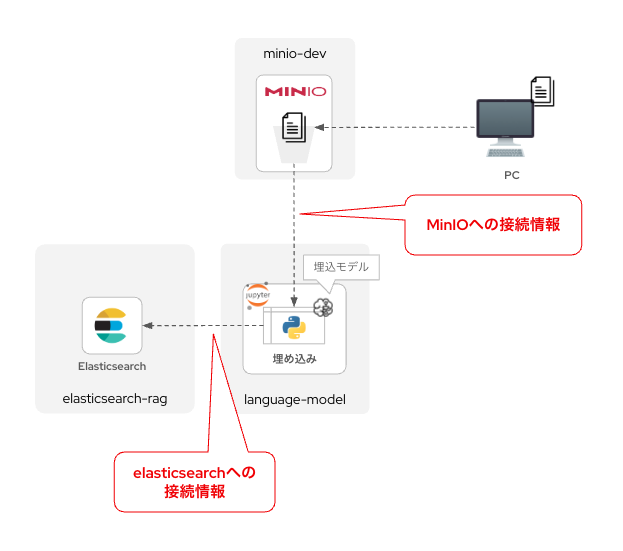
これらの接続情報はJupyterLabコンテナに環境変数を与えることで実現できます。GUIで簡単に設定できるので、サクッとやっていきましょう。
OpenShift AIのコンソール画面に移動し、プロジェクト「language-model」の「Workbench」タブに切り替え、ここにデプロイ済みのJupyterLabの三点リーダをクリック、「Edit workbench」を選択します。
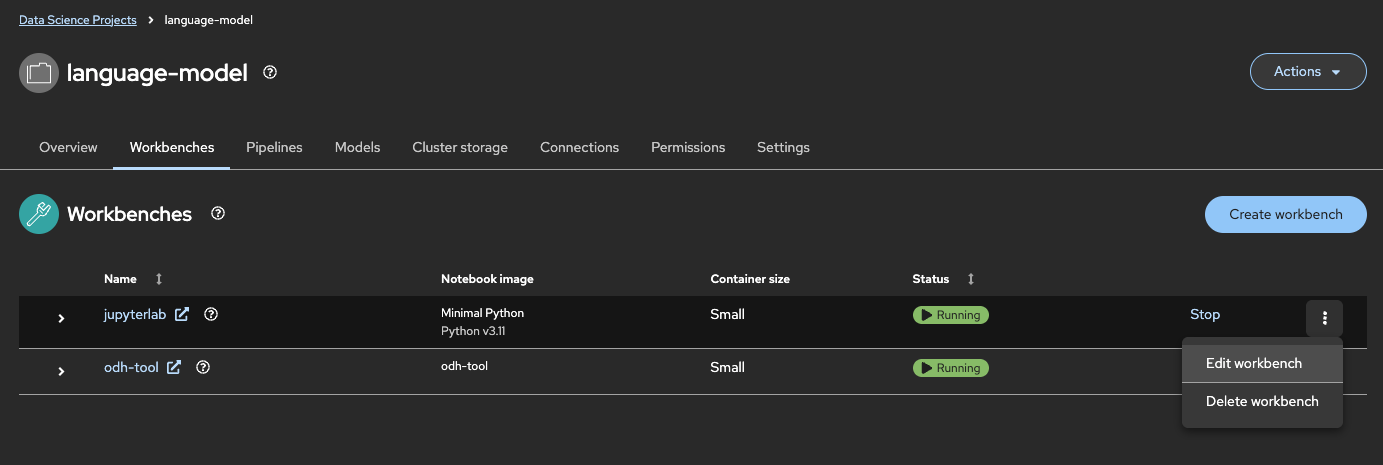
するとワークベンチの設定変更ができるようになります。「Environment variables」欄で環境変数の設定が可能です。「Add variable」をクリックします。

環境変数はConfigMap / Secretの2通りで定義できます。
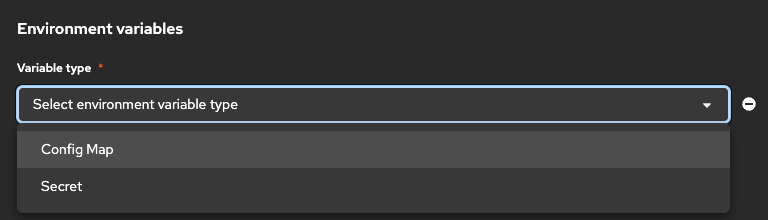
今回は、ConfigMap / Secretを両方使い、以下のように環境変数を設定します。
| 設定値の与え方 | Key | Value | 備考 |
|---|---|---|---|
| ConfigMap | ELASTIC_URL |
https://elasticsearch-sample-es-http.elasticsearch-rag.svc.cluster.local:9200 |
先ほどデプロイしたElasticsearchのServiceのURL(クラスタ内のみで有効なローカルホスト名)です。 |
| Secret | ELASTIC_PASSWORD |
<ご自身の環境で作成されたElasticsearchのパスワード> |
プロジェクト「elasticsearch-rag」内に作成されたKubernetes Secret「elasticsearch-sample-es-elastic-user」内に記載されています。 |
OpenShift / Kubernetesにおいて、Serviceを適用した場合にクラスタで通信可能なURLは以下のような法則で作成されます。
http(s)://<Service名>.<Namespace名>.vc.cluster.local:<Target port>
Elasticsearchへの書き込み権限について、本来は特定の書き込み権限に絞ったアカウントを設定するべきですが、今回は簡単のため管理者アカウントとパスワードを用います。商用構成検討時はこの点を再度考慮してください。
「Environment variables」欄の以下のように環境変数を設定できれば大丈夫です。

なお、MinIOとの接続情報は、すでにプロジェクト「language-model」に設定済みの「Connection」が使えます。「Connections」欄で「Attach existing connections」をクリックし、「minio-dev」を選択してください。

設定を完了したら、「Update workbench」をクリックし、設定変更を保存します。
設定が変更されると、JupyterLabコンテナが再起動します。起動が完了したら、再びJupyterLabを開いてください。
ベクトル埋め込み実施
JupyterLabを再度開いたら、with-rag/notebook/elasticsearch-embedding.ipynbを展開します。先ほどOpenAI APIに準拠した通信を試した場合と同じく、上からPythonコードを実行していきましょう。なお、コードを実行する際にはぜひコメントアウトした文も読み、各コードでどんなことをやっているのかひとつずつ確認していくと、より理解も深まるでしょう。
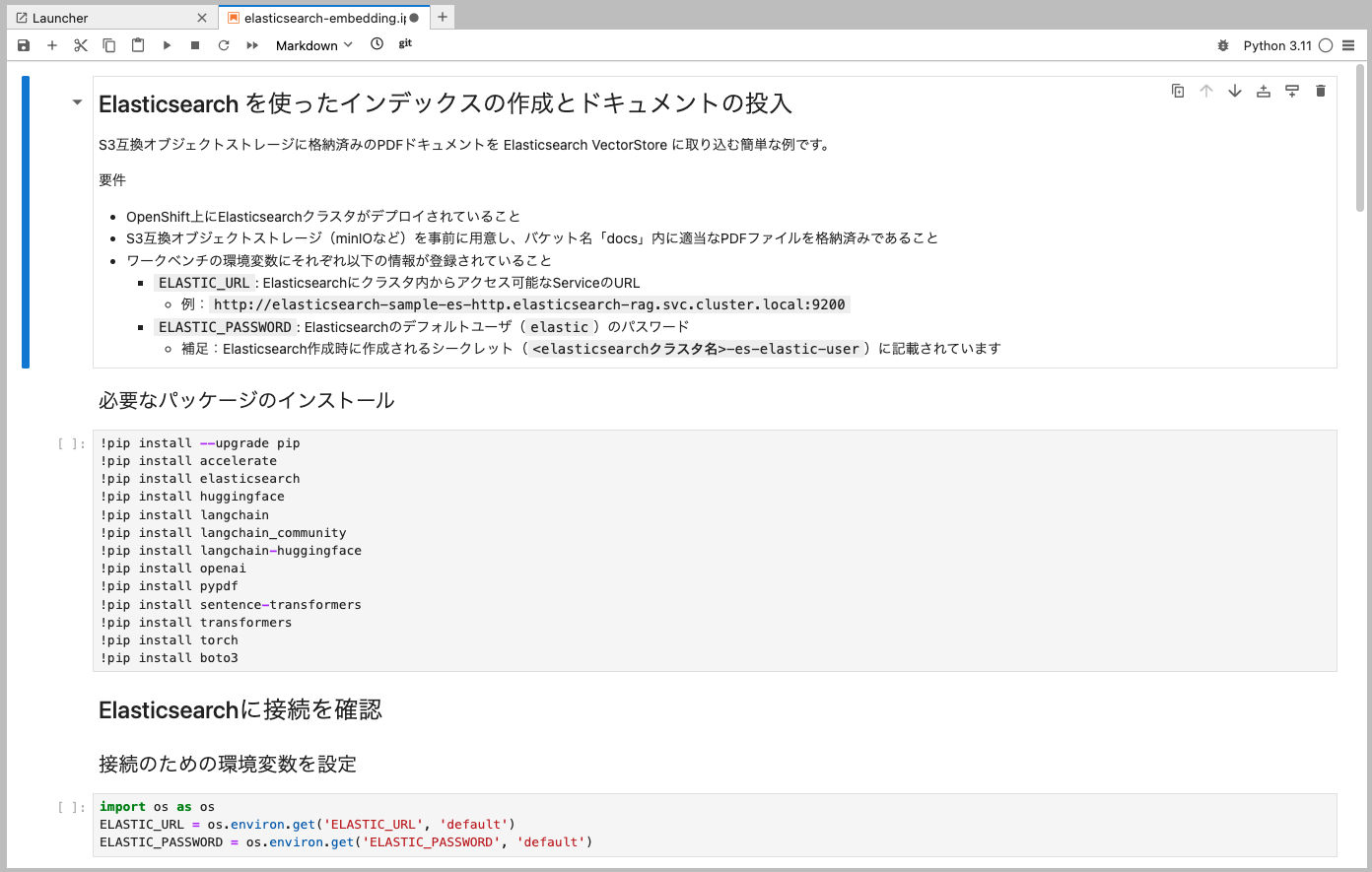
Elasticsearchへの接続を試みる箇所で以下のWarningが出ます。
/opt/app-root/lib64/python3.11/site-packages/elasticsearch/_sync/client/__init__.py:311: SecurityWarning: Connecting to 'https://elasticsearch-sample-es-http.elasticsearch-rag.svc.cluster.local:9200' using TLS with verify_certs=False is insecure
_transport = transport_class(
/tmp/ipykernel_547/1134820228.py:12: LangChainPendingDeprecationWarning: The class `ElasticsearchStore` will be deprecated in a future version. Use :class:`~Use class in langchain-elasticsearch package` instead.
db = ElasticsearchStore(
これは、Elasticsearchへの接続に際して「https」でアクセスしているにもかかわらず、証明書による認証をしていない(verify_certs=False)であるためです。今回はコンテナ同士の通信はクラスタ内に閉じたものであるとして、Pod間の通信に証明書認証を設定しませんでした。よりセキュリティを意識した構成を考える場合は、Elasticsearchコンテナへのアクセスがクラスタ内からのものであっても中間者攻撃などを防ぐ観点から、証明書による認証を求める設定を推奨します。
さて、無事に上からコードを適用していくと、ドキュメントがチャンキングされ、かつベクトルデータとしてElasticsearchに格納されます。
Kibanaからベクトルデータを確認
Elasticsearchに接続済みのKibanaからベクトルデータを確認してみましょう。Kibanaのログイン後の画面で「Elasticsearch」をクリックします。
左メニュー「Index Management」をクリックすると、先ほどPythonコードで作成したインデックスを確認できます。

「apple-intelligence-docs」というインデックスを確認できます。右上の「Discover index」をクリックするとインデックスの中身のデータ自体を見ることが可能です。
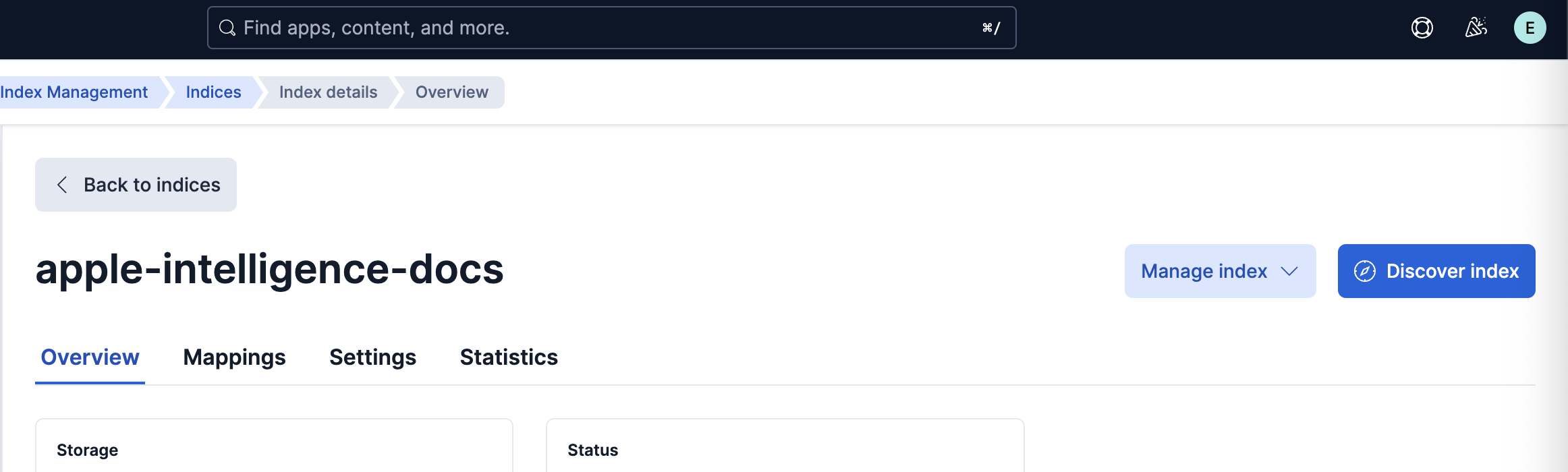
チャンキングされたドキュメントと、それを表すベクトルデータを確認することができます。
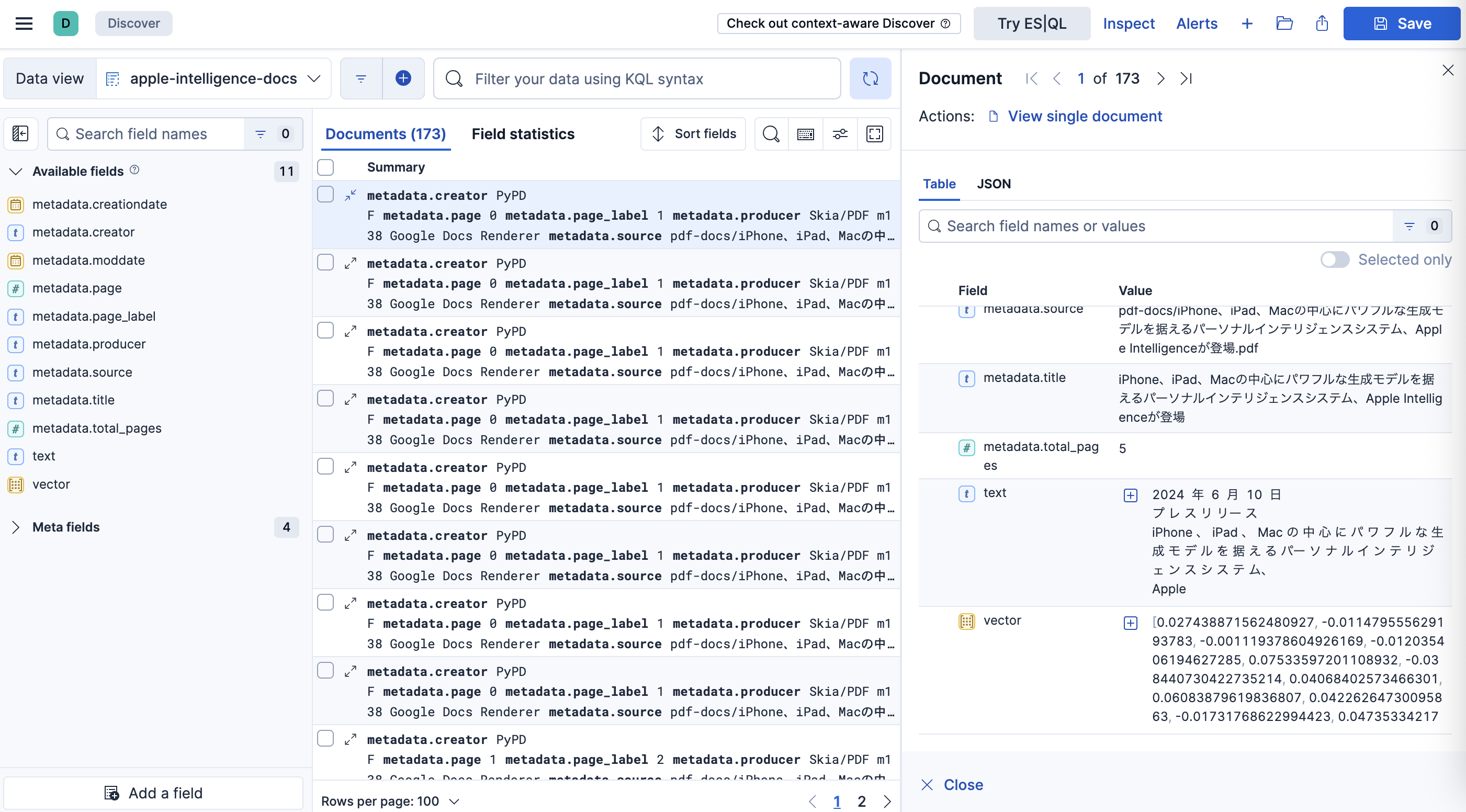
ベクトルデータはもはや人間が見てもなにもわかりませんが、言語モデルがRAG(Retrieval Augmented Generation, 検索拡張生成)を実行する際にはこれが重要な参照データになります。
RAGは、「ユーザが入力したプロンプト」と「チャンキングされたドキュメントをベクトルデータ化されたもの」の類似度を比較し、参照するべきドキュメントを特定(検索)します。そのドキュメントの該当箇所を入力として言語モデルに投入することで、言語モデルの回答が”拡張”されます。
言語モデルにとっては「カンペや教科書」が与えられて回答しているイメージです。学校の先生が、生徒から「◯◯について教えて下さい」と言われた場合を考えます。先生は即座にその回答自体はわかりませんでした。しかし、「参考書のあの辺を見れば答えが書いてあるだろうな」ということはわかります。その結果、教科書をパラパラめくって、該当の箇所を一通り読みます。その結果「◯◯とはxxだよ」と答えることができるとします。これはまさしくRAGの原理です。
| 学校の先生の行動 | RAGの動作 |
|---|---|
| 生徒から質問される | ユーザのプロンプトが来る |
| すぐには答えが出てこない | LLM単体では知識が不十分 |
| 参考書の場所を思い出す | ベクトル検索で該当文書を探す |
| 該当ページをめくって読む | 関連チャンクを取得し、プロンプトに埋め込む |
| 要点をまとめて答える | LLMが参照情報に基づいて生成 |

RAG(Retrieval-Augmented Generation)の仕組みについて、もう少し詳しく説明します。言語モデルが「類似度」を判断する際には、テキストをベクトル(数値の集合)に変換し、それらのベクトル同士の距離を基に近さ(類似性)を評価します。ここではその基本的な流れを簡易な模式図として説明します。
まず、ユーザの入力プロンプトは、フロントエンドアプリケーション内で動作する「埋め込みモデル(embedding model)」によってベクトル化されます。このプロンプトのベクトルを $q$ とします。一方で、事前にドキュメント群も同様の埋め込みモデルによってチャンク(文や段落などの単位)ごとにベクトル化されており、それらを $d_1, d_2, d_3$ とします。
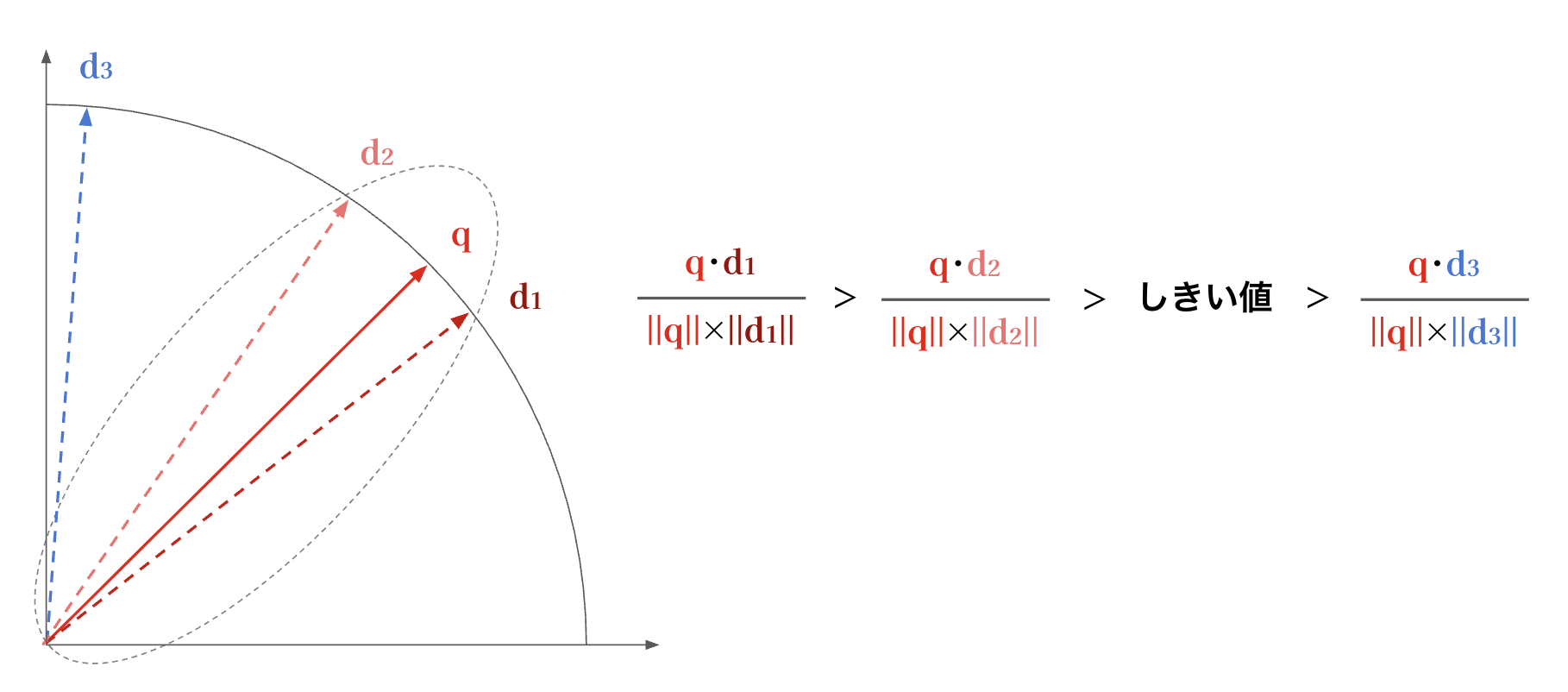
このとき、$q$と各$d$の類似度は、ベクトルの「コサイン類似度(cosine similarity)」によって算出されます。コサイン類似度は、ベクトル同士が成す角度$θ$に基づいて計算され、コサインの定義から次の式で表されます。
cosθ = (q・d) / (‖q‖‖d‖)
$q・d$はベクトル$q$と$d$の内積、$‖q‖$はベクトル$q$の長さ(正確に言うとノルム、あるいはユークリッド距離)です。
$cosθ$の値が1に近いほど、ベクトルの向きが一致しており、すなわちテキスト内容が類似していると判断されます。逆に、値が0に近い場合は内容が関連性の低いものとみなされます。
RAGのプロセスでは、このコサイン類似度に基づいて「しきい値(threshold)」を設定します。$q$と$d_i$の類似度がしきい値を上回る(= 高い類似度を示す)場合、そのドキュメントチャンク$d_i$は関連性の高い情報源として言語モデルに渡され、回答生成の材料として活用されます。逆に、しきい値を下回るものは無関係な情報としてフィルタされるわけです。
実は、このしきい値もアプリケーション開発者が試行錯誤の結果決定・更新し続ける値になります。
RAG対応のチャットボットアプリをデプロイ
さて、いよいよRAG対応のチャットボットアプリをデプロイしましょう。すでにアプリのコードはwith-rag/app/rag-chatbot_ui.pyに格納されています。アプリをデプロイする前に、コードの重要な部分について抜粋して触れておきます。
Prompt Engineeringに関わる部分
# ▼ ▼ ▼ ▼ ▼ Prompt Engineeringの中で調整される領域 ▼ ▼ ▼ ▼ ▼
...
# --- Prompt定義---
template = """<s>[INST] <<SYS>>
You are a trusted advisor. Only answer the exact question asked by the user.
Do not generate follow-up questions or extra information unless explicitly requested.
Keep answers factual.
If you don't know the answer to a question, answer 'I don't know'.
<</SYS>>
Question: {question}
Context: {context} [/INST]
"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(template)
llm = ChatOpenAI(
base_url=model_service,
api_key="EMPTY" if not model_service_bearer else model_service_bearer,
model=model_name,
streaming=True,
temperature=0.1,
top_p=0.7,
frequency_penalty=0.7,
max_tokens=4096,
stop=["\n\nQ:", "\nQ:", "\nA:"],
callbacks=[StreamlitCallbackHandler(st.empty(), expand_new_thoughts=True)]
)
# ▲ ▲ ▲ ▲ ▲ Prompt Engineeringの中で調整される領域 ▲ ▲ ▲ ▲ ▲
...
こちらは、先程見てきた「RAG無し版AIチャットボット」と同様、ユーザプロンプトと合わせて言語モデルに対して提供するインプット情報になる各種パラメータとテンプレートです。
QA_CHAIN_PROMPTにはチャットテンプレートを代入しています。チャットテンプレートはすべてのプロンプトに暗黙的に付与されるプロンプトで、「知らないことは知らないと言え」だとか「勝手に質問と回答を繰り返し生成するな」とか、要は言語モデルが回答を生成する上での制御文言として機能します。
また、llmは、openaiパッケージのChatOpenAIクラスを用いて、具体的に利用する言語モデル名や、モデルにインプットするパラメータなどを定義するオブジェクトです。
Elasticsearchと接続してRAGを実施
ここが今回の肝になる部分です。部分ごとに丁寧にみていきましょう。
es = Elasticsearch(
elasticsearch_url,
basic_auth=("elastic", elasticsearch_pass),
verify_certs=False
)
esというElasticsearchとの接続情報(オブジェクト)を定義しています。ここでは既にelasticsearchパッケージからインポートしたElasticsearchクラスで定義される引数を用いて、接続情報を構成しています。具体的にはElasticsearchの接続先URLとベーシック認証情報です。また、今回は証明書による認証をオフ(False)としています。
embedding_model_name = "ibm-granite/granite-embedding-278m-multilingual"
embeddings = HuggingFaceEmbeddings(
model_name=embedding_model_name,
encode_kwargs={"normalize_embeddings": True}
)
こちらのコードでは、HuggingFaceEmbeddingsクラスを使ってembeddingsというオブジェクトを定義しています。このクラスは、Huggingface上で公開されている埋め込みモデル(sentence-transformersモデル)をローカルにダウンロードし、ベクトル化処理に利用することができます。
sentence-transformersは、文や段落(センテンス)をベクトル(数値の配列)に変換するためのライブラリであり、文書ベクトルを生成できます。意味の近い文同士が近いベクトルになるよう設計されています。
埋め込みモデルは、言語モデルと同じくIBM Graniteファミリーの「ibm-granite/granite-embedding-278m-multilingual」を用いました。
なお、normalize_embeddings=Trueは、文書ベクトルの正規化(ベクトルの長さを単位ベクトル化すること)を明示的に指示しています。
db = ElasticsearchStore.from_documents(
[],
embeddings,
index_name=index_name,
es_connection=es,
)
このコードでは、embeddingsで定義した埋め込みモデルを使って、Elasticsearch上でベクトル検索を行う設定をしています。index_nameには、ベクトルデータを保存・検索するためのインデックス名を指定します。また、es_connectionという引数には Elasticsearchへの接続情報を渡しています。これらはlangchainパッケージから提供されるElasticsearchStoreクラスを用いてdbというオブジェクトとして定義されます。これがElasticsearchに対してRAGを行うための肝になる部分です。
chain = RetrievalQA.from_chain_type(
llm,
retriever=db.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={"k": 3, "score_threshold": 0.85} #コサイン類似度0.85以上のTop3までのドキュメントをRAGに利用
),
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT},
return_source_documents=True
)
このコードはlanguchainパッケージのRetrievalQAを用いて、RAGを実行します。これまで定義してきたllmやdb、QA_CHAIN_PROMPTを用いて、あとはよしなにRAGまで実行してくれるイメージです。さらにRAGのオプションとして、以下を追加しています。
-
search_type="similarity_score_threshold": 類似度がしきい値を超えるものだけを取得 -
search_kwargs={"k": 3, "score_threshold": 0.85}: コサイン類似度0.85以上のものだけ使い、 その中から上位3件までの文書を候補にする -
return_source_documents=True: 回答と一緒に、参照されたソース文書も返す
LangChainではこんな感じでRAGが実装可能です。一度お作法さえ理解してしまえば、非常に簡単に実装できます。
SecretにElasticsearchの接続情報を登録
この後、いよいよ「RAG対応版生成AIチャットボット」をデプロイしますが、このアプリには環境変数としてELASTIC_PASSWARDが定義されています。この値にはご自身のElasticsearchのパスワードを指定する必要があります。先程、プロジェクト「elasticsearch-rag」内のSecret「elasticsearch-sample-es-elastic-user」で確認した内容を、with-rag/manifest/rag-ai-chatbot/secret.yamlの<REPRACE YOUR ELASTIC_PASSWARD>と置き換えます。
apiVersion: v1
kind: Secret
metadata:
name: rag-ai-chatbot
type: Opaque
stringData:
ELASTIC_PASSWORD: <REPRACE YOUR ELASTIC_PASSWARD>
# it is only for a demo. it is NOT recommended to upload Kubernetes Secret on public repojitory.
Gitea上で編集できたら「変更をコミット」をクリックし、編集内容を反映してください。
ArgoCDアプリケーション&PipelineRunを適用
# ArgoCDアプリケーションを適用
oc apply -f http://repository.gitea-operator.svc.cluster.local:3000/gitea-admin/langchanin-rag-chatbot/raw/branch/main/with-rag/manifest/argocd-app/application.yaml
# pipelinerun.yamlを適用
oc apply -f http://repository.gitea-operator.svc.cluster.local:3000/gitea-admin/langchanin-rag-chatbot/raw/branch/main/with-rag/manifest/pipeline/pipelinerun.yaml
今度は「rag-ai-chatbot-run」というパイプライン実行が開始されます。今回は埋め込みモデルをアプリケーション内にダウンロード&ビルドする都合、パイプラインの完了までには10分程度かかります。
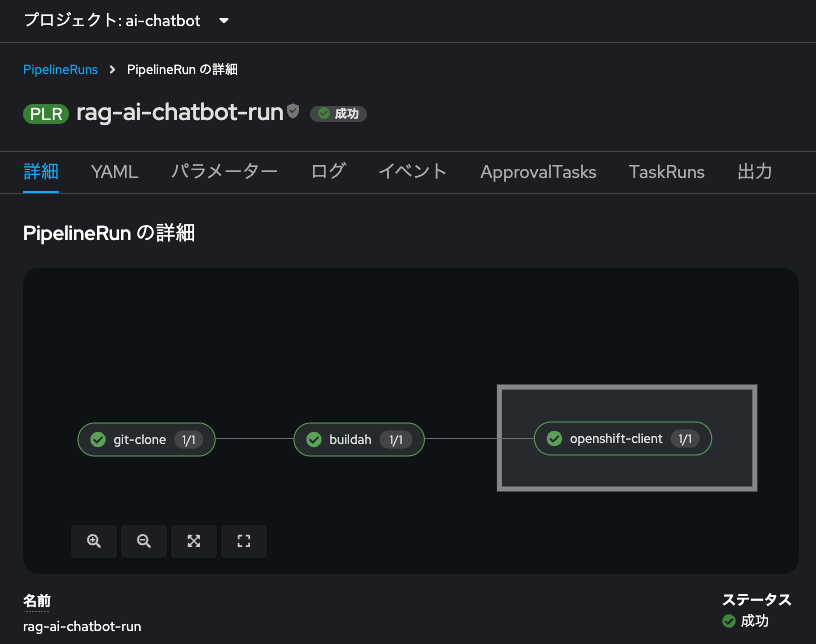
パイプライン実行が成功したら、さっそく「RAG対応のAIチャットボット」にアクセスしてみましょう!
RAG対応AIチャットボットにアクセス
さっそく、プロジェクト「ai-chatbot」にデプロイされた「rag-ai-chatbot」にアクセスしてみましょう。

試しに「猫について教えて下さい。」と入力してみます。
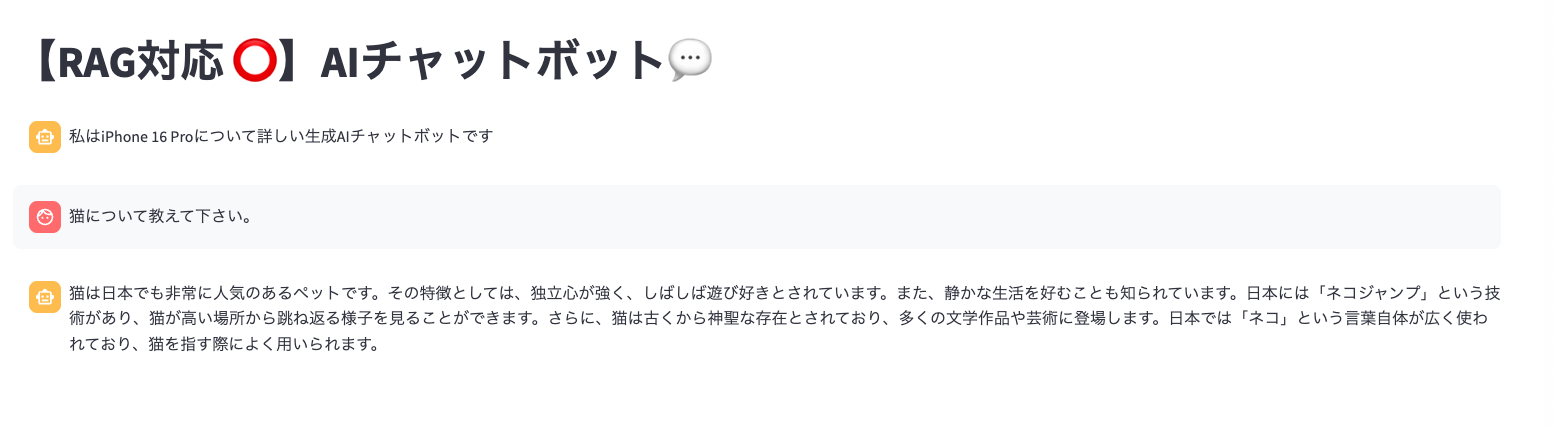
普通に一般知識レベルで回答してくれます。では「Apple Intelligenceとは?Macでなにができるようになりますか?」と聞いてみましょう。

今度は、参考文書をもとに回答を生成してくれました。概ね合っているように思われます。これでRAGに対応したAIチャットボットがOpenShift上に実装できました。
試しに「RAG無し版AIチャットボットに「Apple Intelligenceとは?Macでなにができるようになりますか?」と聞いてみてください。
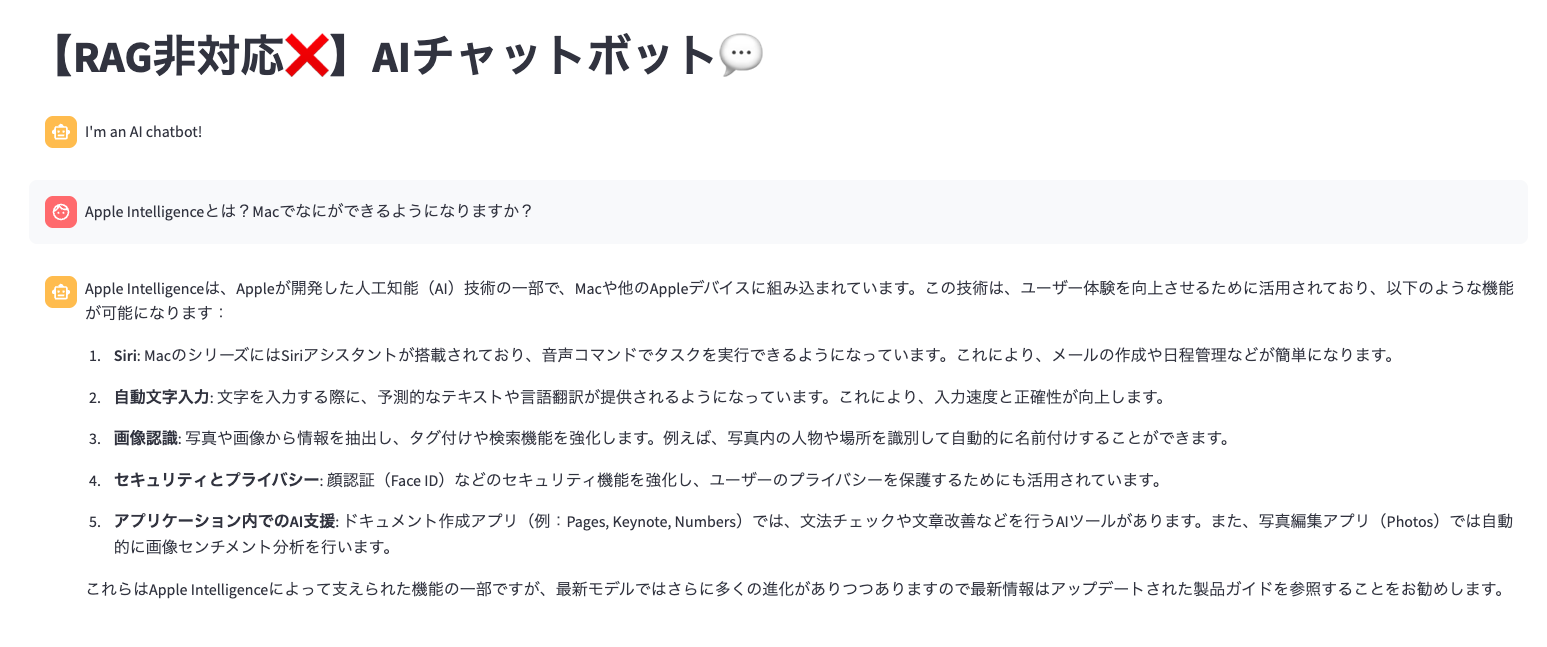
おおお!?「詳しくは製品ガイドを見てください」という趣旨の断りを添えつつ、いかにも“それっぽい”回答が返ってきました!この応答は、言語モデルがApple Intelligenceの具体的な仕様を知らないにもかかわらず、周辺知識から推論して生成されたものです。故に、実際には正確な製品説明が一切されていません。
一方で、モデルが生成した回答には一定の妥当性があるように感じられる箇所も含まれていました。これは、AppleのAI戦略におけるイノベーションの「予測可能性」を示しているとも言えます。つまり、Appleが発表する機能の方向性が、過去の実績やブランド戦略からある程度想像できてしまうほどに既定路線化していると言えるのではないでしょうか。
※本記事の趣旨とは異なる考察ですが...
言語モデルの観点から見れば、これは「知識がなくても推論で補える」言語モデルの強さを示す一方で、情報の出典を裏付けとして提示できない限界(幻覚, ハルシネーション)も表しています。こうした背景を踏まえると、RAGのように外部知識を参照できる仕組みの重要性が改めて浮き彫りになります。
RAG対応版AIチャットボットについても、試しにいくつかのパラメータを変えてみます。例えば、RAGにおけるチャンクの類似度のしきい値(score_threshold)を0.5としてみましょう。
...
# --- RetrievalQA チェーン定義(RAGの核) ---
chain = RetrievalQA.from_chain_type(
llm,
retriever=db.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={"k": 3, "score_threshold": 0.5} #コサイン類似度0.85以上のTop3までのドキュメントをRAGに利用
),
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT},
return_source_documents=True
)
...
これにより、ドキュメントを参照する際の「ハードル」が下がるわけですね。つまり類似度基準が甘くなるとも言えます。
さて、score_threshold=0.5とした場合のAIチャットボットに「猫について教えて下さい。」と質問してみます。
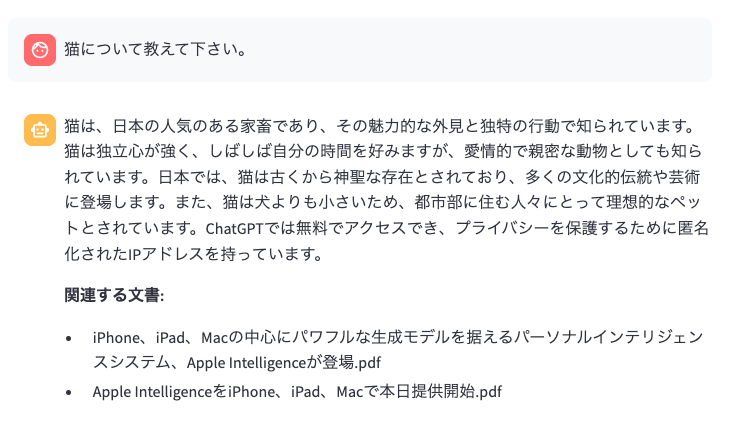
んん!?なんだか途中までは猫の説明をしていたのに、無理やりApple IntelliegenceやiPhoneの機能の説明と思しき内容を語り始めました。「イギリスの文化について教えて下さい。」という質問については、ご覧の通りです。
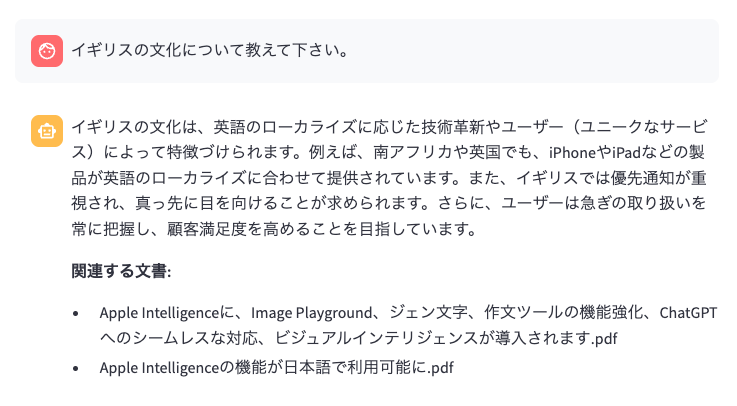
またしても無理やりiPhoneやApple Intelligenceの内容にからめて回答生成してしまっています。「RAG非対応AIチャットボット(要は素のgranite-3.3-instruct)に「イギリスの文化について教えて下さい。」と聞いた場合をみてください。

これに比べると、RAGのチューニングをミスった場合、寧ろ大幅に回答品質が劣化していることがわかります。
今後の改善ポイント
お疲れ様でした!OpenShiftの上で一からRAG対応のAIチャットボットを作成する手順について、少しでも理解を深めていただけたのであれば幸いです。また、RAGの仕組みについてもなるべくわかりやすく説明したつもりではありますが、しかし特に類似度の話などはがっつり三角関数とベクトルの関係(高校数学)を参照せねばならず、人によっては非常に難しいと感じた方もいらっしゃるでしょう。
さて、「RAG対応のAIチャットボットを作る!」という観点では、本記事で説明した手順が基本的な内容にはなるのですが、まだまだ多くの改善ポイントがあります。そのポイントを以下にまとめました。
ドキュメントの前処理
ベクトル化(埋め込み)する前のドキュメントの前処理は、RAGの精度に大いに関係するポイントです。例えば、改行や句読点の統一、不要なHTMLのタグやスクリプトを除去することで、文節単位や意味的なまとまりを正確に捉えるために重要です。こうした前処理の工夫によって、後続のチャンキングやベクトル検索の品質が大きく向上します。
チャンキングに係る工夫
今回、チャンキングに関わるコードは以下の通りでした。
from langchain.text_splitter import RecursiveCharacterTextSplitter
...
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=400, # 約400文字で分割
chunk_overlap=80, # 80文字分の文脈を引き継ぐ
separators=["\n\n", "。", "?", "!", "、", "\n", " ", ""] # 日本語に登場するセパレータを定義
)
all_splits = text_splitter.split_documents(pdf_docs)
all_splits[0]
例えば上記のコードで言えば、チャンクサイズやオーバラップの値を変えてみて、RAGの精度にどう効いてくるかを試行錯誤する余地が残っています。また、今回はチャンキング戦略としてRecursiveCharacterTextSplitterを利用しました。これは、指定したセパレータ(。や、等)を用いて文書を分割し、指定したchunk_size以下になるまで再帰的に分割を実行するクラスです。しかし、これは機械的な文書の分割であり、必ずしも文書の意味に着目したチャンキングではありません。
そこで、注目されている手法として 「意味的分割(Semantic Chunking)」があります。今回、参考文書の分割や埋込に利用したLangChainパッケージにおいても、「SemanticChunker」が提供されています。あるいは、チャンキングも言語モデルに実施させる手法(Agentic chunking)も提案されています。
文書の分割手法については、Greg Kamradt氏が「5 Levels Of Text Splitting」にまとめているものが非常に参考になると感じました。
プロンプト設計
言語モデルから意図した回答を引き出しやすくする、あるいは不用意な回答を防ぐ意味でも「プロンプト設計」は重要な観点です。例えば、文書を参照して回答させるRAGでは、「以下の文書に基づいて答えてください」などの明示的な指示が、ハルシネーションリスクを低減します。
例えば、「RAG対応版AIチャットボット」に対して
ビジュアルインテリジェンスとは?
とだけ聞いてみた回答結果が以下です。

うーん、なんか的を得ていない回答ですね...。結局「ビジュアルインテリジェンス」がなんなのか全然わかりません。ところが、
「ビジュアルインテリジェンスについて、以下の文書を参考にして教えて下さい。
Apple Intelligenceに、Image Playground、ジェン文字、作文ツールの機能強化、ChatGPTへのシームレスな対応、ビジュアルインテリジェンスが導入されます.pdf」
と聞いてみると、回答が全然変わります。
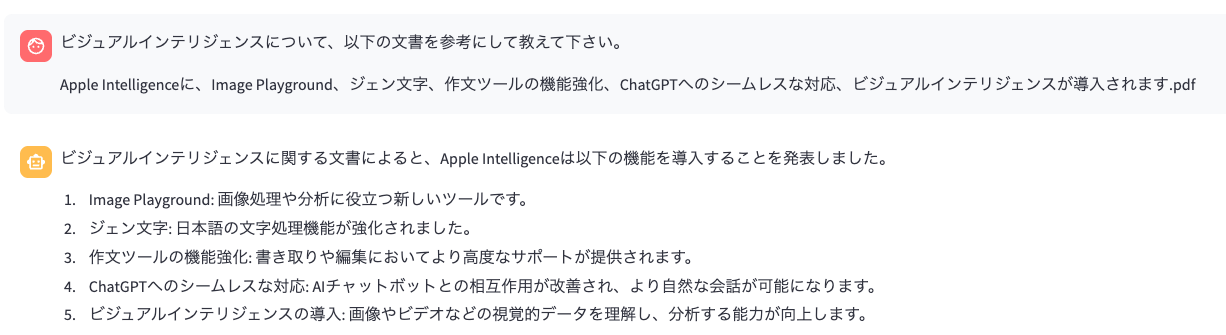
事前に提供されている参考文書がわかっている場合、こうした工夫で回答の精度を向上させることもできます。プロンプトが曖昧だとモデルは推測に頼るため、事実と異なる情報を含んだ“それっぽい”回答を返すリスクが高まります。プロンプト設計は一度作って終わりではなく、実際の応答を見ながら継続的に改善していくことが重要です。
チャットテンプレート
チャットテンプレートは、すべてのプロンプトにプレフィックスされて提供されるテンプレートであり、入力の揺らぎを抑えて一貫した指示・文脈をモデルに渡せたり、ハルシネーションリスクの軽減を含めた、応答品質のばらつきを低減できます。これらも試行錯誤の中で決定し、また継続的に更新し続けるべき対象になります。
tempertureを始めとした各種パラメータやチャットテンプレートをバージョン管理し、それらがどう言語モデルに影響をもたらすのか、その試行錯誤を行うためのツールキットとしも使える、「LangSmith」があります。LangSmith は、LangChainによる生成AIアプリケーションの開発・デバッグ・評価・監視を支援する仕組みです。
プロンプトのバージョン管理、RAGの入出力可視化、ユーザーからのフィードバック収集などをGUIで行えます。開発中のLangChainアプリがどのように動作しているかを追跡できるため、生成AIアプリの品質改善に非常に有効とされています。
モデル種別
今回使用した、いわゆる「モデル」には2種類あります。ひとつは言語モデルの「ibm-granite/granite-3.3-2b-instruct」、もうひとつは埋め込みモデルの「ibm-granite/granite-embedding-278m-multilingual」です。これらのモデルを別のものに置き換えることで、当然ながらRAGの出力結果も変化します。
特に言語モデルについては、今回は概念実証(PoC)を目的とし、非常に小型なモデル(Small Language Model, SLM)を採用しました。小型モデルとはいえ、一定の実用性は確認できましたが、たとえば IBM Granite 3.3の8Bモデルなど、より大規模なモデルを使用することで、回答性能のさらなる向上が期待できます。
また、埋込みモデルについては、タスクやドメイン(法務、医療、製造など)に合った埋め込みモデルを選ぶことで、類似度検索の精度が大きく変わります。また、新しいモデルが登場すれば定期的な比較・更新も重要です。
さらに、それぞれのモデルについて「日本語に特化した言語モデル」を使用すれば、日本語の質問応答においては、より高い精度が得られる可能性があります。
ここに挙げた観点以外にも、一般的に以下も知られています。
| その他観点 | 内容 |
|---|---|
| ベクトル検索のパラメータ調整 | 類似度スコアのしきい値(score_threshold)や検索件数(k)を調整することで、ノイズの除去や文脈の充実を図れます。ユーザの意図に対して「適切な情報量のチャンク」が得られるように最適化が必要です。 |
| メタデータ活用とフィルタリング | 文書にメタデータ(タイトル、カテゴリ、作成日など)を付加し、それを使ってフィルタ付き検索を行うことで、RAGの精度と透明性を向上させることができます。 |
| 評価とフィードバックループの整備 | ユーザーのフィードバックや誤答ログを収集し、どのチャンクや回答パターンに問題があるかを定期的に分析・改善します。LangSmithなどのツールを活用することも有効です。 |
| セキュリティとアクセス制御 | RAGが参照する文書にアクセス制御を設定し、ユーザーや権限に応じて参照範囲を限定する仕組みを整備します。誤って閲覧不許可の情報を出力しないようにすることが不可欠です。 |
他にもまだまだ多くの調整内容があるはずです。ご興味ある方はググったり言語モデルなどに聞いてみてください。兎にも角にも、こうした観点を踏まえて、生成AIアプリケーションというものは試行錯誤的に更新し続ける対象です。これはまさに「継続的デリバリー」の考えを取り入れるべきものであるということです。

おわりに
大変長い記事にお付き合い頂きありがとうございました。オープンソースのプロダクトを組み合わせてDIY的にRAG対応AIチャットボットを構築する楽しみに気づいていただけたでしょうか?あるいはその大変さも身に沁みたかと思います。
また、本記事を通して「生成AIアプリケーションはクラウドネイティブアプリケーションの延長線上にある」ということがわかって頂けたなら幸いです。