AutoEncoder - 情報ボトルネックが生み出す「基準点」

${\tiny \textsf{左からsrc, src推論結果、src->dst swap推論結果、dst->src swap推論結果, dst推論結果、dst; 中央二つがスワップ結果}}$
前回までで、SAM3という強力なセグメンテーションモデルの内部構造を深掘りしてきました。DetectorとTrackerの役割分担、テキストプロンプトによる意味的検索、そして288×288という解像度の選択理由まで、設計思想の深い部分を見てきた気がします。
今回から新しいテーマに入ります。FaceSwap モデルです。
より具体的には、256x256の解像度で顔画像を再構成するモデルを設計・学習させ、その過程で何が起こるのかを観察していきます。
今回は、その 「基準点」 となるモデルの話です。
1. なぜAutoEncoderなのか?
AutoEncoderは、入力画像を一度 圧縮された表現(潜在空間) に変換し、そこから再び元の画像を復元するモデルです。
入力画像 → Encoder → 潜在表現(bottleneck) → Decoder → 出力画像
シンプルな構造ですが、この「圧縮→復元」というプロセスには、いくつかの興味深い性質があります。
AutoEncoderの応用
- 異常検知: 正常データで学習したモデルは、異常データをうまく復元できない
- ノイズ除去: ノイズを含む画像を入力しても、クリーンな画像が出力される
- データ圧縮: 高次元データを低次元表現に変換
- 生成モデル: VAEとして、潜在空間からサンプリングして新しいデータを生成
- FaceSwap: 今回のターゲット。顔の「アイデンティティ」を分離・交換
今回のモデルは、最後の FaceSwap を目的としています。具体的には、別人物(性別も別)のMemoji、sourceとdestinationをそれぞれ学習し、潜在空間で両者の アイデンティティ を分離し、最終的にはDecoderを交換することで FaceSwap を実現する、いわゆる DeepFake モデルです。
2. モデル設計 - 3x3というボトルネック
2.1 アーキテクチャ全体像
まず、テンソルの形状を追いながら、モデルの全体像を見ていきましょう。前回までのSAM3の話でも、テンソルの形状変化が設計思想を理解する鍵でした。今回も同じアプローチで見ていきます。
Encoder (256x256 → 3x3):
入力: (B, 3, 256, 256) # RGB画像
↓ Conv2d(stride=2) x4 layers
中間: (B, 256, 16, 16) # 16x16特徴マップ
↓ Bottleneck down (16→8→3)
↓ Conv2d(stride=2): 16x16 → 8x8
↓ Conv2d(stride=2): 8x8 → 3x3
VAE: (B, 1024, 3, 3) # 3x3 bottleneck
↓ mu, logvar branches
↓ reparameterization trick
出力: (B, 1024, 3, 3) # 潜在表現
Decoder (3x3 → 256x256):
入力: (B, 1024, 3, 3) # 潜在表現
↓ Bottleneck up (3→8→16)
↓ ConvTranspose2d(stride=2): 3x3 → 8x8
↓ ConvTranspose2d(stride=2): 8x8 → 16x16
中間: (B, 256, 16, 16)
↓ ConvTranspose2d(stride=2) x4 layers
出力: (B, 3, 256, 256) # RGB画像
図: モデル全体の流れ(前半: Encoder → VAE)
図: モデル全体の流れ(後半: VAE → Decoder)
ポイント:
- Encoder: 空間解像度を圧縮(256→16)、チャンネルを拡張(3→256)
- Bottleneck: さらに圧縮(16→3)、チャンネルをさらに拡張(256→1024)
- VAE: 3x3で確率的サンプリング(情報ボトルネック)
- Decoder: Encoderの逆変換で画像を復元
2.2 なぜ3x3なのか? - 情報の絞り込み
ここで重要な疑問: 「なぜボトルネックを3x3にしたのか?」
答えは、情報を極限まで絞り込むためです。
元の画像は 256 × 256 × 3 = 196,608個の値を持っています。
ボトルネックは 3 × 3 × 1024 = 9,216個の値です。
圧縮率を計算すると:
196,608 / 9,216 = 21.3倍
つまり、元の画像の**約5%**の情報量に圧縮されています。
前回までのシリーズで、Stable DiffusionのVAEが 512×512×3 を 64×64×4(約2%)に圧縮する話をしました。それと比べると、今回の圧縮率は控えめです。しかし、3x3という空間解像度は、顔のような構造化されたデータにとって、非常に厳しいボトルネックです。
2.3 空間次元 vs チャンネル次元
ここで重要なのは、**「何を圧縮するか」**です。
| 次元 | 元の画像 | ボトルネック | 変化 |
|---|---|---|---|
| 空間 (H×W) | 256×256 = 65,536 | 3×3 = 9 | 1/7281 |
| チャンネル (C) | 3 | 1024 | 341倍 |
空間次元を極端に圧縮し、チャンネル次元を極端に拡張しています。
これは、以前のシリーズで見た「空間次元を圧縮してチャンネル次元を拡張する」というNNの典型的なパターンですが、3x3という選択は特に aggressive です。
なぜこんなに圧縮するのか?
それは、FaceSwapというタスクの特性にあります。
3x3ボトルネックの真の狙い
極限まで小さくすることで、identityを保存させない
3x3という極小のボトルネックには、実は深い設計意図があります:
- Bottleneckにはidentityは保存されない: 3x3×1024という情報量では、「誰の顔か」という identity 情報まで保持できない
- Decoderがidentityを付与する: Decoder自体が特定人物のidentityを学習し、潜在表現に identity を加えて再構成する
- 潜在空間にはポーズと表情のみ: Bottleneckには「どんな表情か」「どの角度か」といった pose と expression のみが残る
これにより、以下が可能になります:
# srcのポーズ・表情を抽出 → dstのidentityで再構成
dst_decoder(encoder(src))
# → srcのポーズ・表情 + dstのidentity = FaceSwap
補足的な効果:
- 構造の最低限保持: 完全に潰すと復元不可能だが、3x3なら「左上」「中央」「右下」のような大雑把な空間構造は残る
- 過学習を防ぐ: 情報が少ないほど、モデルは「本質的な特徴」だけを学習せざるを得ない
つまり、3x3というボトルネックは、**「identityを意図的に削ぎ落とし、pose/expressionのみを抽出する」**という aggressive な設計です。
2.4 VAE - KL Lossで情報をさらに絞る
さらに、このボトルネックには**VAE(Variational Autoencoder)**が組み込まれています。
# VAE at bottleneck (3x3x1024)
mu = self.conv_mu(z) # 平均
logvar = self.conv_logvar(z) # 対数分散
z = reparameterize(mu, logvar) # サンプリング
VAEは、潜在表現を確率分布として扱います。具体的には、各潜在変数が正規分布 $\mathcal{N}(\mu, \sigma^2)$ に従うように学習します。
この時、KL divergence lossが重要な役割を果たします:
$$
\mathcal{L}_{\text{KL}} = -\frac{1}{2} \sum \left(1 + \log(\sigma^2) - \mu^2 - \sigma^2\right)
$$
KL lossは、潜在分布を標準正規分布 $\mathcal{N}(0, 1)$ に近づけます。これにより:
- 情報がさらに整理される: ランダムなノイズではなく、「意味のある」潜在空間が形成される
- 生成能力: 潜在空間からサンプリングすることで、新しい顔を生成できる(今回は使わないが)
- 過学習防止: 分布の制約により、訓練データへの過適合を抑える
現在のKL lossの重み(loss_kl_weight)は0.2です。これは、再構成品質とのバランスを取った値です。
2.5 Two-Decoder Architecture - アイデンティティの分離
もう一つの重要な設計が、Two-Decoder Architectureです。
# 同じEncoderから2つのDecoderへ
z_src, mu_src, logvar_src = encoder(img_src)
recon_src = decoder_src(z_src) # Decoder for src
z_dst, mu_dst, logvar_dst = encoder(img_dst)
recon_dst = decoder_dst(z_dst) # Decoder for dst
なぜ2つのDecoderが必要なのか?
それは、source Memojiとdestination Memojiの アイデンティティ を分離するためです。
- decoder_src: src Memojiの identity を付与する専門家
- decoder_dst: dst Memojiの identity を付与する専門家
学習中、encoder(src画像) の潜在表現(pose/expressionのみ)を decoder_dst に渡すと、**「srcのポーズ・表情をdstのidentityで再構成する」**という FaceSwap が実現されます(逆も同様)。
この分離を強化するために、Statistical Latent L2 Lossを使います(後述)。
3. Data Augmentation - 3段階の戦略
モデルが過学習せず、頑健に学習するためには、Data Augmentationが不可欠です。
今回のデータセットは、EXR形式(Linear RGB、float32、アルファチャンネル付き)の顔画像です。学習データは限られているため、多様なバリエーションを生成する必要があります。
Augmentationは3段階で構成されています。
3.1 Step 1: Rotation, Shift, Flip(幾何学変換)
適用確率: 50%
# Rotation: ±8度
# Shift: ±3%(画像サイズの3%)
# Flip: 50%
image = random_transform_no_zoom(
image,
rotation_range=8,
shift_range=0.03,
random_flip=0.5
)
なぜこの範囲?
- Rotation ±8度: 顔の自然な傾き範囲。あまり大きくすると不自然
- Shift ±3%: 顔の位置のわずかなズレ。中心から大きく外れないように
- Flip: 左右反転は顔の対称性を利用
この段階では、Zoom(拡大縮小)は含まれていません。理由は次のステップで明らかになります。
3.2 Step 2: Elastic Deformation(局所的な歪み)
適用確率: 50%
# Perlin-like noiseで局所的に歪める
# Intensity: 0.003 ~ 0.012(ランダム)
warp_intensity = np.random.uniform(0.003, 0.012)
image = random_warp3(
image,
sigma=1.0,
intensity=warp_intensity,
oct=5,
amp=1.0
)
Elastic Deformationとは?
画像全体を滑らかに歪める変換です。Perlin noiseのような連続的なノイズを使って、各ピクセルの位置を微妙にずらします。
効果:
- 顔の微妙な表情変化をシミュレート
- モデルが「ピクセルレベルの完全一致」ではなく、「構造的な類似性」を学習
- エッジ付近が歪むため、次のステップで対処
3.3 Step 3: Zoom Out(エッジのクロップ)
適用確率: 50%
# 0.88 ~ 1.0にスケール(Zoom Out)
scale = np.random.uniform(1 - 0.12, 1.0)
image = zoom_out_transform(image, zoom_range=0.12)
なぜZoom Out?
Step 2のElastic Deformationで、画像のエッジ部分が歪みます。特に、cv2.warpAffineのBORDER_REPLICATEモードでは、エッジのピクセルが引き伸ばされ、不自然なアーティファクトが発生します。
Zoom Outすることで、歪んだエッジ部分をクロップし、中央の有効な領域だけを使うことができます。
3.4 なぜこの順番?
重要なのは、Augmentationの順番です。
1. Rotation/Shift/Flip(幾何学変換)
↓
2. Elastic Deformation(歪みを発生させる)
↓
3. Zoom Out(歪んだエッジをクロップ)
もし Zoom を最初にやってしまうと、後の Elastic Deformation で再びエッジが歪んでしまいます。**「歪みを作る → クロップする」**という順序が重要です。
3.5 repeat_factor=4 - データセットの拡張
さらに、データセットを4倍に拡張しています。
# データセットを4回繰り返し
self.image_files_src = self.image_files_src * 4
self.image_files_dst = self.image_files_dst * 4
# src と dst を独立にシャッフル(index pairingを壊す)
np.random.shuffle(self.image_files_src)
np.random.shuffle(self.image_files_dst)
効果:
- 同じ画像でも、毎回異なるAugmentationが適用される(確率的)
- src と dst のペアリングを壊すことで、「特定のsrcには特定のdst」という対応関係を学習しない
- 実質的に、データセットサイズが4倍になり、過学習を防ぐ
4. 損失関数 - ReconstructionとRegularization
損失関数は、モデルが「何を学習するか」を決定する最も重要な要素です。
今回のモデルでは、シンプルで効果的な損失関数を選択しています。
4.1 Reconstruction Loss - 画像の再構成品質
L1 Loss (weight: 1.0, face-focused):
# Face-focused weighted L1 loss
mask_face = (alpha > 0.9).float() # Face region
mask_bg = (alpha <= 0.9).float() # Background region
valid_pixels_face = mask_face.sum() + 1e-6
valid_pixels_bg = mask_bg.sum() + 1e-6
loss_l1_face = ((recon - target).abs() * mask_face).sum() / valid_pixels_face
loss_l1_bg = ((recon - target).abs() * mask_bg).sum() / valid_pixels_bg
loss_l1 = loss_l1_face + 0.1 * loss_l1_bg # Background weight = 0.1
ピクセル単位の絶対値誤差です。L2(MSE)よりもL1の方が、外れ値に対してロバストで、シャープな画像を生成しやすいです。
なぜ背景の重みを下げるのか?
このデータセットでは、背景がアルファマット(黒)で統一されています。これは一見シンプルですが、学習の偏りを引き起こします:
| 要素 | ピクセル割合 | 特徴 |
|---|---|---|
| 顔領域 | 30-40% | 複雑、学習すべき対象 |
| 背景 | 60-70% | 常に黒、簡単に再構成可能 |
重み付けなしのL1損失では:
# 重み付けなし(問題あり)
loss = mean(|recon - target|) # 全ピクセル均等
# 勾配の寄与
∇L ∝ (顔の誤差 × 40%) + (背景の誤差 × 60%)
↑ 重要 ↑ 常にほぼ0(背景は黒なので)
起こり得る問題:
- 損失値の誤解: 背景が簡単に再構成できるため、損失値が低くても顔の品質が悪い可能性
- モデル容量の浪費: ネットワークが「背景=黒を出力」に容量を割く(本来は顔の詳細学習に使うべき)
- 勾配の偏り: 勾配の60%が意味のない信号(背景の誤差はほぼ0)<- 特に重要
Face-focused weighting (0.1) の効果:
# 重み付けあり(改善)
loss = loss_l1_face + 0.1 * loss_l1_bg
# 勾配の寄与
∇L ∝ (顔の誤差 × 91%) + (背景の誤差 × 9%)
↑ 優先 ↑ 低重み(完全無視ではない)
- 顔領域のエラーが 10倍重要視 される
- 背景も低重みで考慮(完全に無視すると境界付近で問題)
- モデルが顔の詳細に集中しやすくなる
LPIPS Loss (weight: 1.0):
loss_lpips = lpips_fn(recon, target) # Perceptual loss
LPIPS(Learned Perceptual Image Patch Similarity)は、人間の知覚的類似性を測る損失です。
- L1だけだと、「ピクセルは近いが、見た目が違う」ケースを捉えられない
- LPIPSは、VGGなどの事前学習モデルの特徴空間で比較するため、**「見た目の自然さ」**を評価できる
4.2 Regularization Loss - 潜在空間の整理
KL Loss (weight: 0.2):
loss_kl = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
loss_kl = loss_kl / mu.numel()
前述のVAEのKL divergence lossです。潜在分布を標準正規分布に近づけます。
Latent L2 Loss (weight: 0.05):
# Statistical matching(position-basedではない)
mean_src = z_src.mean(dim=0) # [C, H, W]
mean_dst = z_dst.mean(dim=0) # [C, H, W]
var_src = z_src.var(dim=0)
var_dst = z_dst.var(dim=0)
loss_latent_l2 = F.mse_loss(mean_src, mean_dst) + F.mse_loss(var_src, var_dst)
これが、Statistical Latent L2 Lossです。
通常の Latent L2 は、z_src[i] と z_dst[i] の距離を測ります(position-based)。しかし、これはインデックスの対応関係を学習してしまう危険があります。つまり、decoder_dst(encoder(src[i])) が dst[i] を出力するという、望ましくない近道を学習する可能性があります。
Statistical Latent L2では、**バッチ全体の統計量(平均・分散)**を一致させます。これにより:
- インデックスの対応関係は学習されない
- src と dst の潜在分布が近くなる(同じ分布から来ているように見える)
- Encoder が「アイデンティティに依存しない」抽象的な特徴を学習する
重みは0.05と小さめです。強すぎると、srcとdstの区別がつかなくなり、FaceSwapが失敗します。
4.3 損失の全体像
loss_total = (
1.0 * loss_l1 + # ピクセル精度(顔領域優先)
1.0 * loss_lpips + # 知覚的類似性
0.2 * loss_kl + # 潜在分布の整理
0.05 * loss_latent_l2 # アイデンティティ分離
)
この4つの損失が、256x256-FaceSwapにおけるAutoEncoderの学習目標を定義しています。
重要な設計判断:
- L1は顔重み付き(0.1): 背景のピクセルが多数でも、顔の品質が優先される
- LPIPSは全画像: 知覚的類似性は背景も含めて評価するのが妥当
- 動的スケジュールなし: KL/LatentL2の重みは固定(シンプルさ優先)
5. 学習設定 - 固定LRと3つのOptimizer
5.1 学習率: 2.0e-4(固定)
learning_rate = 2.0e-4
# No scheduler(学習率スケジューラなし)
学習率スケジューラ(徐々に下げる)は使っていません。理由は:
- シンプルさ: スケジューラのハイパーパラメータが増える
- 安定性: 固定LRでも十分に収束する(実験で確認済み)
- 再現性: スケジューラのタイミングが結果に影響しない
5.2 3つのOptimizer - Encoder, Decoder_src, Decoder_dst
optim_encoder = Adam([
{'params': encoder_vae_params, 'lr': lr * 0.5}, # VAE部分は半分のLR
{'params': encoder_other_params, 'lr': lr},
], betas=(0.5, 0.999))
optim_decoder_src = Adam(decoder_src.parameters(), lr=lr, betas=(0.5, 0.999))
optim_decoder_dst = Adam(decoder_dst.parameters(), lr=lr, betas=(0.5, 0.999))
なぜ3つに分ける?
- Encoder: VAE部分(mu, logvar)は学習が不安定になりやすいため、半分のLR
- Decoder_src / Decoder_dst: 独立に学習させることで、各Decoderが専門性を持つ
5.3 その他の設定
- Batch size: 32(512x512では大きすぎるため調整)
- Mixed precision: bfloat16(メモリ削減 + 高速化)
- Gradient clipping: max_norm=4.0(勾配爆発を防ぐ)
- Epochs: 150
用いてる画像はそれぞれ1800枚ほど、前述の通りこれをrepeatで4倍で使ってます。
画像としてはrgbのピクセル値的に全ての画像においてほぼ同じmean, stdになってると思われます。つまり画像によって絵の明暗や色ズレ等がない状態。実際のデータセットではこういうことはあまりないですが。実験として。
epoch1の結果
${\tiny \textsf{左からsrc, src推論結果、src->dst swap推論結果、dst->src swap推論結果, dst推論結果、dst}}$
このタスクにおいてはすでに画像統計が整ってる状態で約7200(1800x4)が1epochなので、1epoch目ですでにある程度形が見えてきます。実際に実写写真素材だと統計のばらつきやノイズなどでこんなにすぐに結果は出ないし、別の問題も発生します。
epoch15の結果
スワップ部分でまだ弱いが単純な再構成(左から2個目と右から2個目)すでにある程度再構成が可能になってるのがわかります。スワップ部分で弱いのはまだ前述のencoderによるindentityの分離とdecoder(だけ)によるidentity付与が完全に行われていないためと推測できます。例えばdst_decoder(encoder(src)でモデルが目の当たりにメガネを乗せるべきかを悩んでる様子が受け取れます。また同様にsrc_decoder(encoder(src))で頭の形(髪の部分)でまだdstの影響を受けてるのがわかります。この髪の部分がどういう形をしてるのか?というのは本来encoderがindentity分離によりその情報をそぎおとし、decoderで付与/ 再構築されるのですが、それができていないということになります。
このモデルと前述の損失セットとデータセットで最終的には40,50epochほどでほぼ完全なスワップが可能になります。
損失全体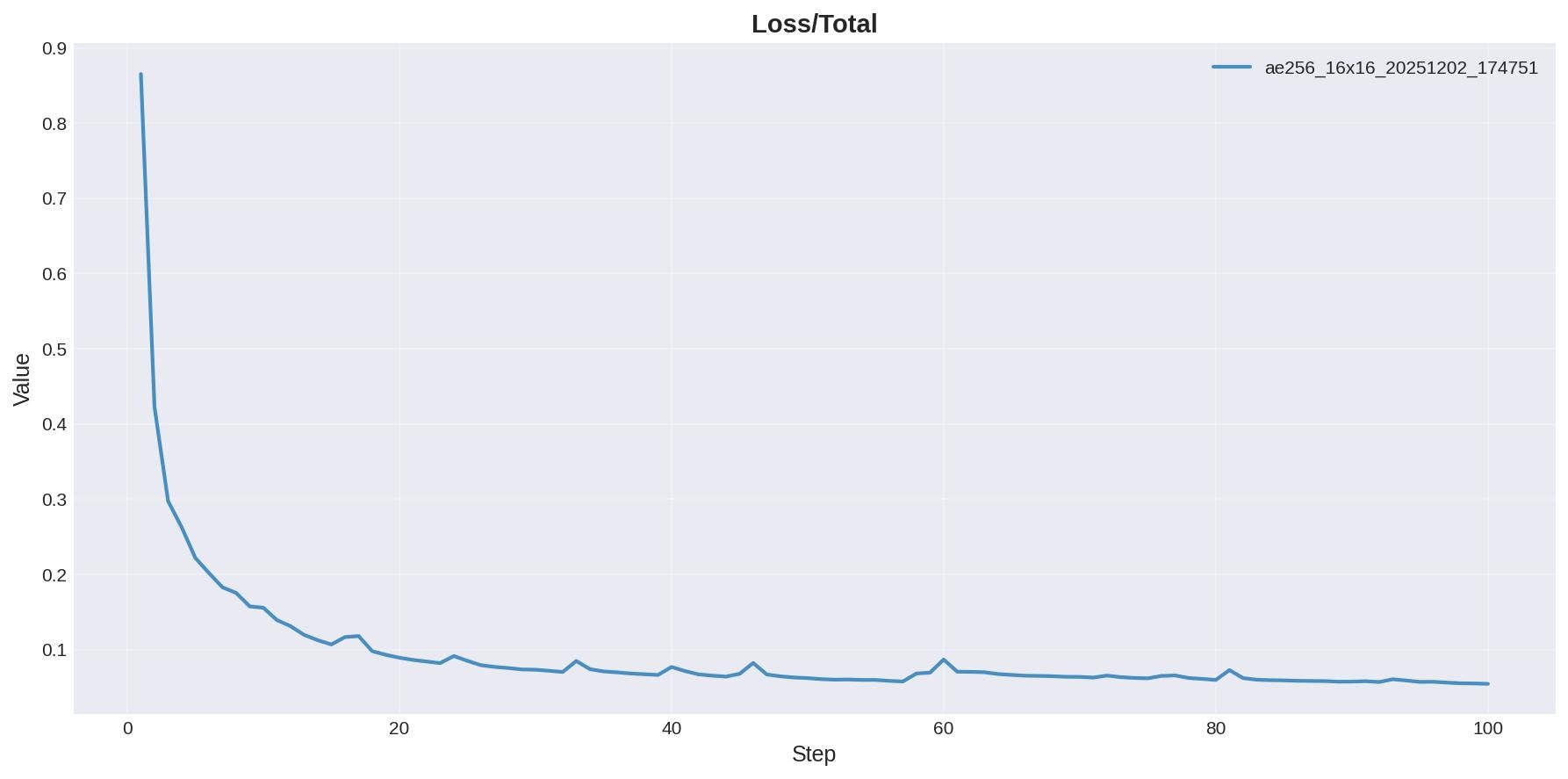
Latent_L2(ここではどれだけindentity分離できてるかの指標)
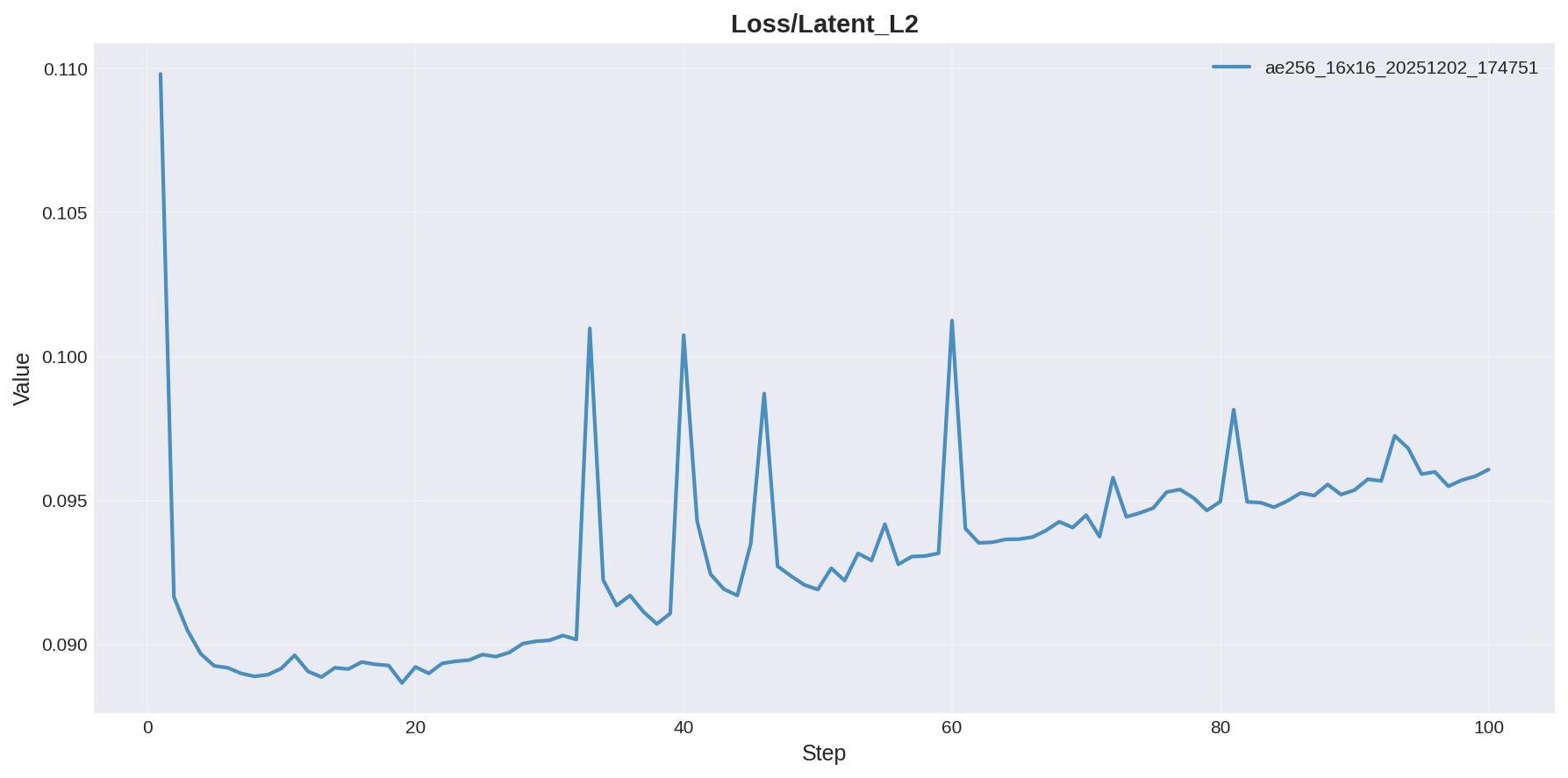
Latent_L2はepoch1からすでに低い値で推移。
KL(ここでは大雑把に言って潜在においてどれだけ各値が整っているかの指標)
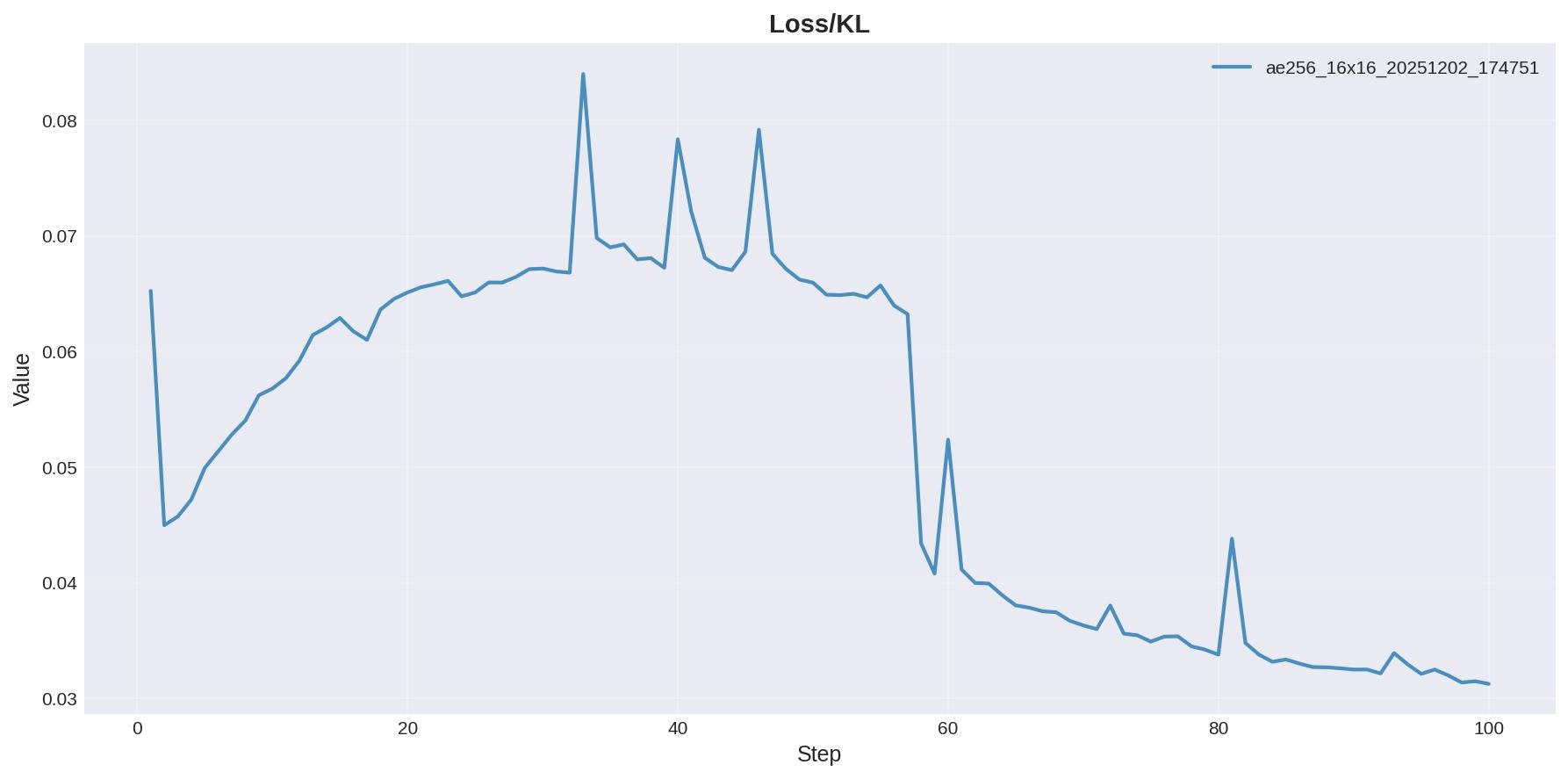
Kullback–Leibler divergence。潜在の分布とN(0,1)の正規分布とがどれくらいに似た分布になってるか?を見てる。
epoch100の結果
6. まとめ - これが基準点
今回、256x256-FaceSwap AutoEncoderを設計しました。
設計のポイント
- 3x3 bottleneck: 情報を21倍に圧縮(約5%)
- VAE: KL lossで潜在分布を整理
- Two-Decoder: srcとdstのアイデンティティを分離
- 3段階Augmentation: Rotation/Shift → Warp → Zoom Out
- シンプルな損失: L1 + LPIPS + KL + Latent L2
- 固定LR + 3つのOptimizer: 安定した学習
このモデルは、256x256で動作する基準点です。
参考:
- PyTorch公式ドキュメント: https://pytorch.org/docs/stable/index.html
- LPIPS論文: https://arxiv.org/abs/1801.03924
- VAE論文: https://arxiv.org/abs/1312.6114