離散データが作る連続性
前回は、
• バラバラな離散データでも、大量に集まると
• 連続的なパターン(確率分布)が浮かび上がり、
• それが ML の「モデル」になる
という話をしました。
ここではその続きとして、
「統計が画像を生成し始める瞬間」 を、実際のVGGFace2というデータセットを使って見ていきます。
結論からいえば、
• 顔画像の集合は、数学的には“巨大な雲(分布)”として扱える。
• その雲の“方向”を調べるだけで、
• 性別・年齢・表情といった “連続的な変化” が浮かび上がってくる。
という驚くほどシンプルな話です。
1. 顔画像は離散データのかたまりにすぎない
今回使った VGGFace2 という顔画像データセット。
見た目はただのバラバラな画像です:
• 人種さまざま
• 明るさも違う
• 年齢も性別もバラバラ
• そもそも「同じ人物」が誰なのかすら分からない
つまり 完全に離散的で雑味だらけのデータ です。
これを“統計”を通して見ると軸のようなものが見えてきます。
2. PCA(主成分分析)で「顔の連続空間」を作る
PCA は、データのばらつきを最もよく説明する
方向(ベクトル) を探す手法です。
手順は驚くほどシンプルで、
• 1. 全画像をベクトル化(離散データ)
• 2. 共分散行列をつくる(揺れ方を見る)
• 3. 固有値・固有ベクトル(=主成分)を求める
ただそれだけ。実際には scikit-learn(sklearn) というライブラリを用いています。
PC(主成分)とは何か?
PCA が抽出する Principal Component(主成分) とは、
• たくさんのデータが最も大きく“揺れる方向”
• -> データのばらつきを最もよく説明する軸
のことです。そしてこの「方向」は 画像そのものとして可視化できます。
それは、決して意図的にそのようには整理されるわけではないのですが、
• PC1 方向 → 顔の形や輪郭の変化
• PC2 方向 → 表情や明暗の変化
• PC3/PC4 → 年齢感・骨格など細かい identity 変化
のような感じでまさにこれらの特徴が浮かび上がってくるのです。
つまり PCA は、
• ターゲットとなる空間での“変化方向”を、純粋に統計から抽出している
ということです。
3. 平均顔を中心に「顔の座標系」が現れる
PC1 と PC2 の方向に沿って画像を生成すると以下のようなマップ(Latent Atlas)になります:

- 横方向 = PC1(表情・陰影など)
- 縦方向 = PC2(性別・顔の丸みなど)
- 真ん中 = 平均顔
これはまさに 顔の座標系 です。
PC3×PC4 でも:

より細かい特徴(顔の向き, 顎, 目の大きさなど)が現れます。
統計だけで“顔の潜在空間”が構築されているわけです。
4. 主成分を足していくと、顔が再構成される
次の図は、PC を上から順に使って再構成した例:

- k=1 → ほぼ平均顔
- k=10 → 大まかな顔立ち
- k=50〜100 → 個性が見え始める
- k=300〜500 → ほぼ元の人物が復元される
これは共分散行列の固有ベクトルの線型結合を表しています。
5. 顔空間は「ガウス分布」のように広がっている
PC1×PC2 の散布図を描くと、点群が楕円状に分布します:
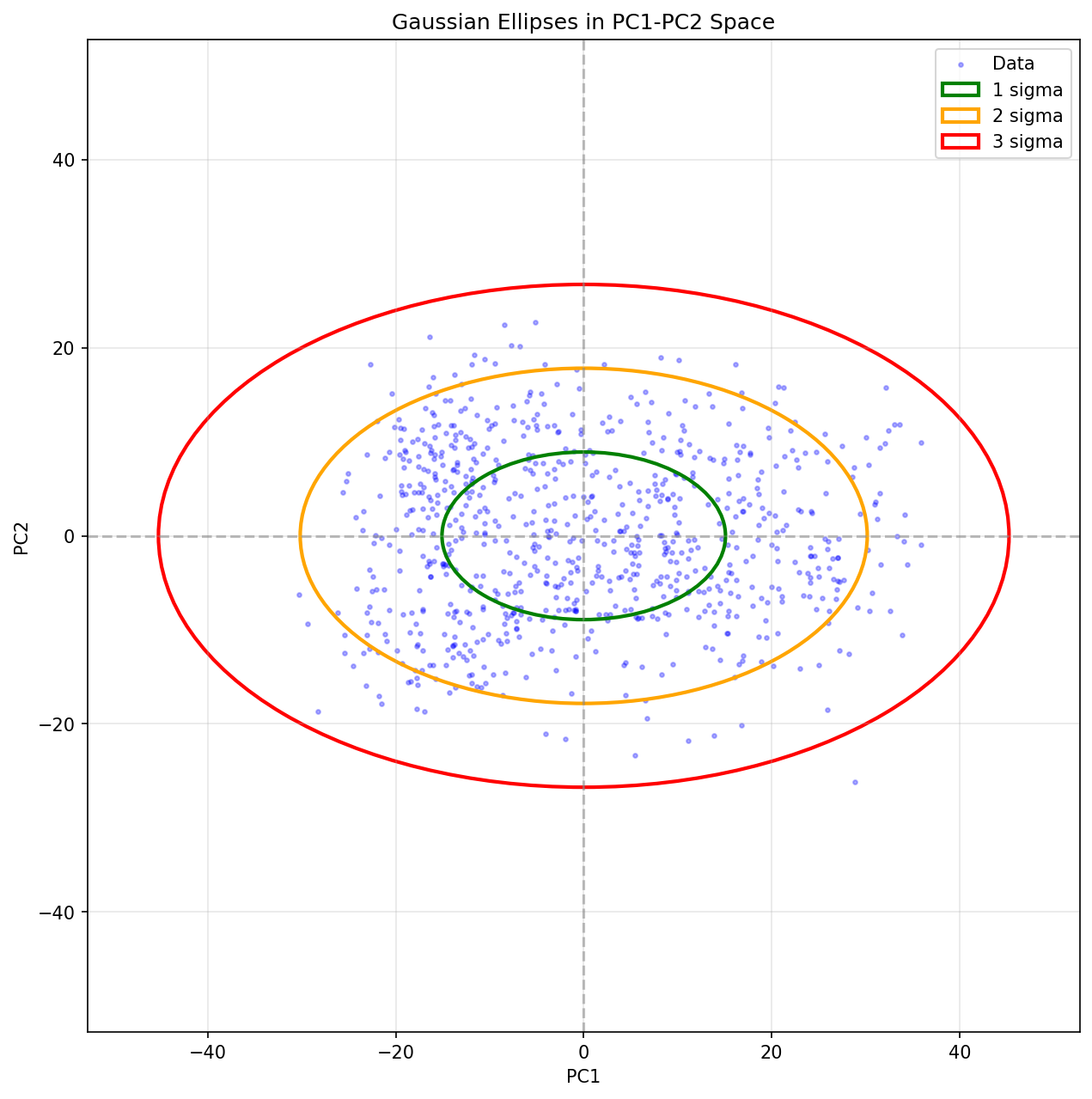
少しややこしいんですが、ここではPC1軸を横に方向、PC2軸を縦方向にとっていていずれにも+側と-側が存在しています。基本的にはこの二つの端は反対方向を示しており、たとえば片側が女性ぽさならもう片側は男性ぽさになります。中央はこの性別という軸を切り口にした時に平均的な見た目をしているということになります。
•中心(平均付近)にデータが密集
•外側に行くほど軸が示す特徴が強くなっている(その属性が色濃く表現されてる)
•1σ, 2σ, 3σ で統計的な頻度がわかる
統計がそのまま “顔の地形” を描いている と言えます。
これはあくまで方向の話であって、その要素の強度ではありません。真ん中ほどその要素がないのではなくて、真ん中ほどどちらの方向へも偏ってなくてその方向に対しして平均的であるということを示しています。
6. 離散データ → 連続モデル → 画像生成
これが ML と CV の原点
ここまで見てきたように、PCA を例にとるだけで
「離散的な画像」 → 「連続的な潜在空間」 → 「画像の生成」
という流れがなんとなく見えてきたかと思います。また、この構造は、今日のほぼすべてのモデルに通じます:
• Autoencoder
• GAN
• Diffusion model (Stable Diffusion)
• NeRF / 3DGS の latent field
ML/CV はこのように、色々と工夫して “離散データを連続分布として扱う” を試みることがあります。
References
Cao, Q., Shen, L., Xie, W., Parkhi, O. M., & Zisserman, A. (2018).
VGGFace2: A dataset for recognising faces across pose and age.
In FG 2018.