動画だけ 288×288 って何? から始まった sam3 の深掘り
Meta AI Researchが発表したsam3(segment anything 3)は、画像とビデオの両方でプロンプトを用いてセグメンテーションを実現する統合モデルです。
今回、sam3のコードを深掘りしていたところ、「なぜVideoでは288x288がそのままリサイズされるだけなのか?Imageの方では学習可能パラメーターを用いてcoarse-fineをしてるのに・・・」という疑問から始まり、モデルの内部構造に対して少し理解が深まったので、ほぼ自分的備忘録的に残しておこうかと。
1. sam3とは
基本情報:
- タスク:画像・動画でのオープンボキャブラリーセグメンテーション
- プロンプト:テキスト、ボックス、ポイントなど
- パラメータ数:848M
- 構成:Detector + Tracker
主な特徴:
- テキストプロンプト(例:"person")で複数インスタンスを自動検出
- ビデオでの時間的追跡
- 270K以上の概念を扱える(ただし文章を理解するわけではなく、単語レベルの concept embedding を参照する仕組み)
2. 最初の疑問:なぜかImage処理とVideo処理では解像度が違う?
samはv1から基本的にbinaryマスクしか返却してくれなくて、そこに不満を感じてました。そこでコードを読んでいると、Sam3VideoInference が返却するのは
outputs = {
"out_obj_ids": out_obj_ids.cpu().numpy(), # [N] オブジェクトID
"out_probs": out_probs.cpu().numpy(), # [N] 確率スコア(Detector)
"out_boxes_xywh": out_boxes_xywh.cpu().numpy(), # [N, 4] 正規化bbox (x,y,w,h)
"out_binary_masks": out_binary_masks.cpu().numpy(), # [N, H, W] バイナリマスク
"frame_stats": out.get("frame_stats", None), # フレーム統計情報
}
で、これの "out_binary_masks" 表示出力として使用されてました。名前からしてガタガタなエッジだなぁ・・・って思ってたのですが、これを追っていくとこれの元はTrackerのTransformerの出力の一部であるlow_res_masks_local(288x288)が元で、これがF.interpolateで1008x1008にされこの時の変数名が、existing_masklet_video_res_masksです。この時点では(-inf,inf)なので、これをsigmoidして[0,1]にして表示してみます。すると・・・

プロンプトフレーム(リファレンスフレーム)だけが異常にガタガタで ジャギ ったまんまなのです。その他のフレームが決してクオリティーが高いとも思えないんですが、ただこのガタガタジャギーよりはまだいいなと思って深掘りをすることにしました。重複しますが、こいつのソースは[1,3,288,288]という形をした特徴中間ベクトルで、それを学習可能パラメーターを使わずに(つまりF.interpolate)1008x1008 にしてます。元々どんな解像度を入力にしても空間解像度1008x1008で処理するようになってるのは知っていたものの(sam2はデカイ解像度でもそのまま受け付けてくれてた記憶がある、ただしvramめっちゃ食って推論できひんってことがあったのも覚えてる)、そこからさらに空間解像度を落としてることを知った。
ちなみにsam3は、
• Image処理:1008x1008
• Video処理:288x288
と言った解像度で処理してることがわかった。と言ってもsd1.5は 4,64,64 なのでそこまでおかしなことでもないんだけど、ただそれが最終の返却値なのか・・・ って思った。
3. Detector を追ってみた
前のセクションがVideo処理が低解像度で行なっていると言ってるように思えるけど、これは半分正解で半分はそうではない。Video処理もDetectorと呼ばれるモデルモジュールをを使用していて、これはImage処理でも同じものを使ってる。余談だけど、sam2まではモデルにいろんなサイズがあったけれどもsam3は今のところ一つしかなく、結構いろんな処理を共用のモジュールを使っていたりする。ちょっとこれは本筋からずれてしまってるけど、なんとなくここで書いて置かないとって思ったので・・・
戻りまして、このDectorが最初にセグメンテーションタスクを行いmaskを作っている。そのマスク(1008x1008)をVideo処理では初期入力として(引き続きテキストプロンプトも使うが)、毎フレームの処理を行うという構成になっている。
Image → Detector (1008x1008)
↓ Learned Queries (100 slots)
↓ Box/Mask/Score 推定
↓ 初期 mask
Video → Tracker (内部 288x288)
↓ Memory Bank
↓ 時間情報と統合
↓ 最終 mask
なのでここでは、まずはDetectorを掘ってみようと思う。
Detectorのテンソルのシェイプも含めた全体的な流れは以下の通り、
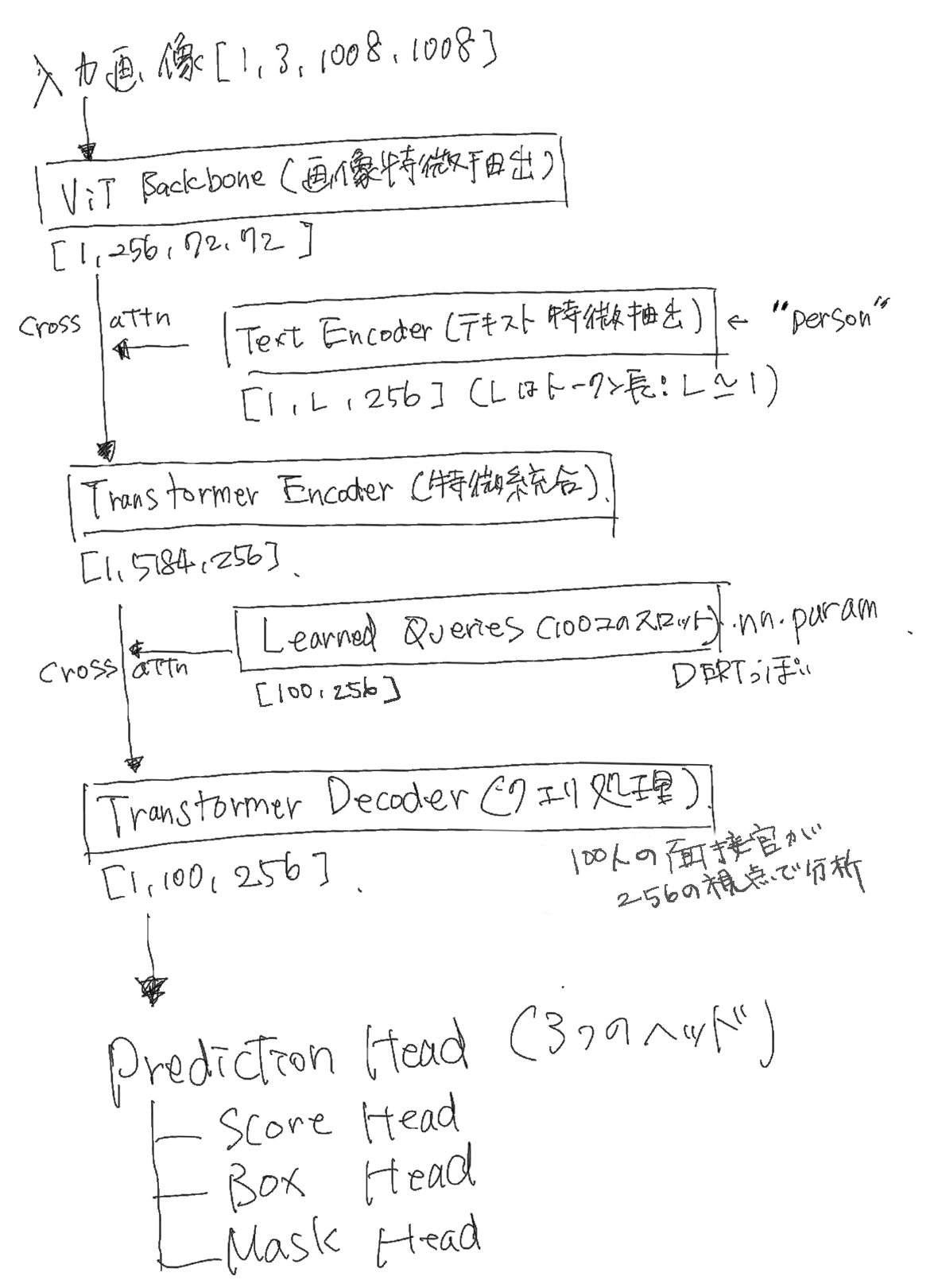
手書きです。すいません・・・
一つ目のクロスアテンションはSDとかでよく見る感じの条件付与みたいなやつに見えますね。画像特徴を意味的に条件づけをしてる。
二つ目のクロスアテンションがなかなか興味深いです。DERTっぽいというかDERTしてますね。
DETR(DEtection TRansformer)スタイルのアーキテクチャを採用してると言ってもいいでしょう。
ここでは別途準備した nn.Parameter [100,256]を用いて、クエリを育ててます。これをsam3で
Learned Queries
と呼んでます。
こいつは nn.Parameter なので学習可能で、あらかじめ256の視点を持った100人の面接官のような存在です。
そしてその面接を受ける受験者は5184人いて、この受験者たちも256個の特徴(個性)を持っています。
ここで、面接官は256の視点を用いて受験者たちの256個の特徴を詳しくみていき、自分たちに合ってるのかどうかを判断して会社へと提出します。この提出物が次への出力となります。
なんとなく直感的には「受験者(画像 token)が選出されるんじゃないの?」と感じるかもしれません。しかし、このタスクが求めているのは セグメンテーションマスク です。
セグメンテーションマスクとは、受験者を見て面接官がまとめ上げた 分析結果そのもの と言ってよいでしょう。
(※ 技術的には、Query が self-attention を通して更新され、それを box/mask head がデコードする形になっています)
つまり、最終的に提出されるのは受験者ではなく、
“面接官が作成したレポート(Query 出力)”
これがモデルの出力になるのです。
100個の固定スロット(オブジェクト候補)
Learned Queries: [100, 256]
↑ ↑
│ └─ 各スロットの特徴次元(256次元ベクトル)
└────── スロット数(最大100個のオブジェクト)
こんな感じです。
処理の流れとしては、
1. 100個のスロットが並列に画像を探索
2. 各スロットがプロンプト("person")との類似度を計算
3. 閾値を超えたスロットだけを選択
4. 結果:N個のインスタンス(N ≤ 100)
と言った感じです。
インスタンスというのは例えば10人の人物が映り込んだ画像に対して person mをテキストとしてモデルを実行した時に、このテキストプロンプトの特徴と画像特徴がどれだけ反応するかをみて、その反応がある値を超えたもの(閾値)だけを選別したときに3人だけが残ったか?というこの5人がインスタンスに相当します。3人という人数のことではなくて、3人の"人物"といラベルのつけることのできるモノたちというか。ここでは5個を別々として識別できるという感じです。それに対して3人であろうが、10人であろうが 人間 という意味的単位で区別することをセマンティック と読んだりします。
具体例:
プロンプト:"person"
画像:3人の人物
↓
スロット1: スコア 0.9 → 合格 ✓(人物1)
スロット2: スコア 0.2 → 不合格 ✗
スロット3: スコア 0.7 → 合格 ✓(人物2)
...
スロット85: スコア 0.8 → 合格 ✓(人物3)
↓
結果:N=3個のインスタンス
もうちょっと噛み砕いて説明すると、
Learned Queries (100個)
↓ 「この画像に何がある?」
↓ Cross-Attention
画像特徴 [5184空間位置]
↓
各クエリが画像全体を探索
↓
「ここに人がいる!」
「ここに車がある!」
Cross-Attentionの向き
# Transformer Decoder
Cross-Attention(
Query = Learned Queries [100, 256], # 「面接官」100人
Key/Value = 画像特徴 [5184, 256] # 「受験者」5184箇所
)
面接官(クエリ)が受験者(画像)を審査 → オブジェクト発見
Learned Queries = 100人の面接官が画像を調べてオブジェクトを見つけるイメージ!
この選別を行うために、適当なチャンネル数(ここでは256)で同じく適当なジャンル数(ここでは100)でふるいにかけにいくっ感じです。でこの Learned Queries はその名前の通り学習されます。
という仕組みがざっくりとしたDetectorになります。
まだ先は長いのですが、今回は一旦Detectorまで。
参考資料
- https://github.com/facebookresearch/sam3
- https://ai.meta.com/research/publications/sam-3-segment-anything-with-concepts/
- コード:sam3/model/sam3_tracker_base.py, sam3/model/sam3_image_processor.py