情報ボトルネック作戦は成功したけど・・・ 3x3の代償
前回までで、3x3の極小ボトルネックを用いたFaceSwapモデルの設計と思想について語りました。「情報を絞ることでIdentityを捨てさせる」という戦略は成功し、論理的にはFaceSwapが可能であることが実証されました。

しかし、生成された画像を細かくチェックしていると、ある 「視覚的な違和感」 に気づきました。
今回は、論理(情報理論)ではなく、実装(レイヤー構造)に起因する画質の問題、「市松模様ノイズ(Checkerboard Artifacts)」 とその解決策について話します。
1. 成功の陰に潜む「網目」
3x3モデルで学習した顔画像の、特に「肌」や「背景」などの平坦な部分を拡大してみます。
遠目に見ると綺麗に再構成されているように見えますが、ズームインすると…



まるで 「網戸越し」 に見ているような、微細な格子状のパターン(グリッド)が乗っていることに気づきます。
これは、学習不足やノイズではありません。Lossは十分に下がっています。

これは、モデルの構造そのものが生み出しているアーティファクトです。
2. 犯人は ConvTranspose2d
このグリッドノイズの正体は、GANやAutoEncoder界隈では有名な Checkerboard Artifacts(市松模様ノイズ) です。
そして、その犯人はDecoderで多用している nn.ConvTranspose2d です。
2.1 ConvTranspose2dの仕組みと弱点: 「拡大」ではなく「ばら撒き」
この問題の根本原因を理解するには、ConvTranspose2dが何をしているかを正しくイメージする必要があります。
よくある誤解として、「小さな画像を拡大コピーして貼り付けている」と思われがちですが、実際の挙動は 「Splatting(ばら撒き)」 に近いです。
水やりのメタファー
イメージしてください。
- あなたは 幅3マスに広がるシャワー(Kernel=3) を持っています。
- このシャワーを出しながら、2マスずつ(Stride=2) 移動していきます。
すると、どうなるでしょうか?
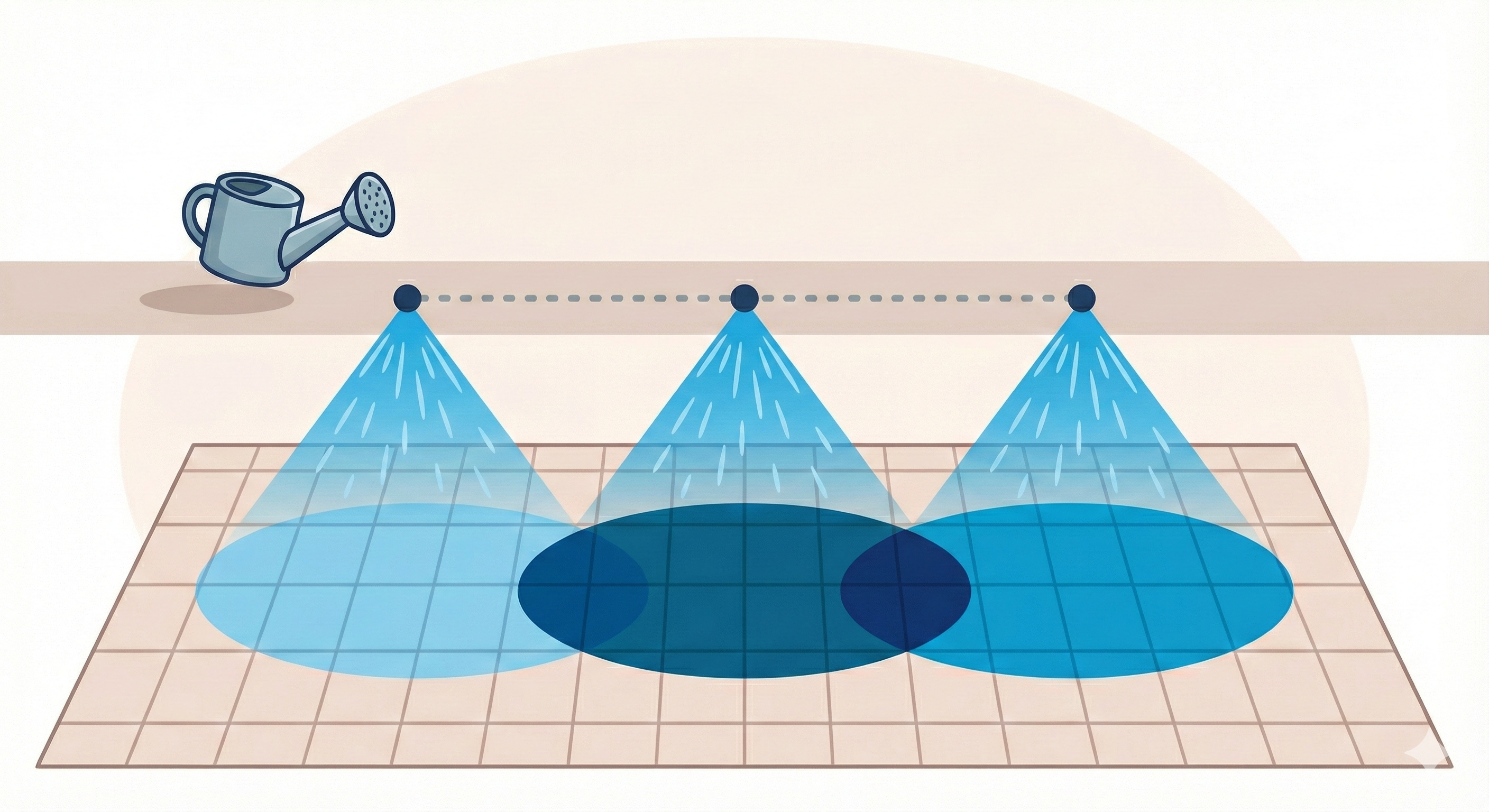
(図解: n+1マスの拡散をnマスおきに浴びせると、どうしても重なる部分が出てくる)
- シャワーの広がり(3) > 移動距離(2)
この「歩幅よりも広くばら撒く」という性質上、前のシャワーの右端と、次のシャワーの左端が、**どうしても地面で重なってしまいます**。
* 重なった場所: シャワーを2回浴びるので、色が濃くなります(値が大きくなる)。
* 重ならない場所: シャワーを1回しか浴びないので、色は薄いままです。
結果として、「濃い・薄い・濃い・薄い」 というリズムが規則正しく刻まれます。
これが、出力画像に現れる グリッド(市松模様)の正体 です。
本来は、この「重なり」を利用して滑らかなグラデーション(補間)を作りたいのですが、重なり方が不均一だと、逆にそれが「模様」として残ってしまうのです。
2.2 なぜ3x3だと特に酷いのか?
「カーネルサイズ4、ストライド2、パディング1」の設定は、理論上は均一に重なる設定です。しかし、重みの初期化や学習の偏りによって、どうしても微細な模様が出やすくなります。
特に今回のモデルでは、3x3 という極小サイズからスタートしています。
- 3x3 → 8x8: ここでグリッドが発生すると、それは画像の「根本的な構造」として焼き付く
- 8x8 → 16x16: そのグリッドをさらに拡大・補間する
- ... → 256x256: 最終的には、画像全体を覆う微細なメッシュとして現れる
初期段階での小さな歪みが、度重なるアップサンプリングによって増幅され、逃れられない「呪い」のように全体を支配してしまうのです。
2.3 なぜ「高解像度」で急に目立つのか?
読者の中には疑問に思う方もいるかもしれません。
「256x256の時はそんなに気にならなかったのに、なぜ512x512にした途端に酷くなるのか?」
これには、「干渉」 と 「解像度の皮肉」 という2つの理由があります。
① グリッドの多重干渉 (Interference)
ConvTranspose2dを重ねるということは、「前の層のグリッドの上に、新しい層のグリッドを書き足す」 行為です。
* **256x256**: 6回の積み重ね
* **512x512**: 7回の積み重ね
たった1回の差に見えますが、波と波が重なると**「干渉(モアレ)」**が起きます。
層が深くなるほど、異なる周期のグリッドが複雑に重なり合い、単なる「点」だったノイズが、目に見える「模様」へと増幅されてしまうのです。

② 高解像度が「ノイズまでくっきり描いてしまう」
これは皮肉な話ですが、解像度が低い(256x256)ときは、画像の**「ボケ」**が味方をしていました。
ピクセルが粗いため、微細なグリッドノイズは潰れて見えなくなっていた(平滑化されていた)のです。
しかし、512x512になるとキャンバスの目が細かくなります。
モデルは肌のキメを描こうとしますが、その高い表現力が仇となり、「本来見えなくてよかった微細なグリッドノイズ」まで、くっきりと解像してモニターに映し出してしまうのです。
「画質を良くしようとしたら、アラまでよく見えるようになった」
これが高解像度化で直面するジレンマです。
3. 解決策: Resize + Convolution
この問題に対する古典的かつ最強の解決策は、2016年にOdenaらが提唱した "Resize-Convolution" アプローチです。
Deconvolution and Checkerboard Artifacts (Odena et al., 2016)
https://distill.pub/2016/deconv-checkerboard/
やり方は非常にシンプルです。
「拡大と畳み込みを分ける」 ことです。
Before: ConvTranspose2d
「拡大しながら畳み込む」を一発で行う。
# 1ステップで拡大と変換を行う(ムラが出やすい)
layer = nn.ConvTranspose2d(in_ch, out_ch, 4, 2, 1)
After: Resize + Conv2d
- Resize: 最近傍補間(Nearest Neighbor)などで、単純に画像を2倍に引き伸ばす。
- Conv2d: 拡大された画像に、通常の畳み込み(stride=1)をかけて整える。
# 2ステップに分ける
layer = nn.Sequential(
nn.Upsample(scale_factor=2, mode='nearest'), # または 'bilinear'
nn.Conv2d(in_ch, out_ch, kernel_size=3, stride=1, padding=1)
)
なぜこれで直るのか?
Upsample による拡大は、ピクセルを単純にコピー(または補間)するだけなので、重なりの不均一さが発生しません。
その後の Conv2d (stride=1) は、すべてのピクセルに対して均等にカーネルを適用するため、新たなムラを生み出しません。
結果として、グリッドのない滑らかな拡大が可能になります。
4. 実装の修正
Decoderの定義を書き換えます。
これまでは ConvTranspose2d を積み重ねていましたが、これを UpSample + Conv2d のブロックに置き換えます。
class UpsampleBlock(nn.Module):
def __init__(self, in_ch, out_ch):
super().__init__()
self.net = nn.Sequential(
# 1. まず2倍に拡大 (Nearest Neighborがシャープさを保ちやすい)
nn.Upsample(scale_factor=2, mode='nearest'),
# 2. 畳み込みで特徴を整える
nn.Conv2d(in_ch, out_ch, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(out_ch),
nn.LeakyReLU(0.1, inplace=True)
)
def forward(self, x):
return self.net(x)
Decoder全体もこれに合わせて修正します。
# 旧 Decoder (ConvTranspose2d)
# self.up1 = nn.ConvTranspose2d(1024, 512, 4, 2, 1)
# self.up2 = nn.ConvTranspose2d(512, 256, 4, 2, 1)
# ...
# 新 Decoder (Resize + Conv)
self.up1 = UpsampleBlock(1024, 512)
self.up2 = UpsampleBlock(512, 256)
# ...
5. 結果 - グリッドの消失
修正したモデルで学習を回し直すと、結果は劇的です。

左がConvT、右がResize+Conv
* ConvTranspose2d: 肌にザラザラしたデジタルな網目が見える。
* Resize + Conv : 網目が消え滑らかになった。
トレードオフ
ただし、すべてが良いことづくめではありません。
Resize + Convアプローチは、ConvTranspose2dに比べて 「画像が若干ソフト(ボケ気味)になる」 傾向があります。
特に mode='bilinear' を使うと顕著ですが、mode='nearest' でも、ConvTranspose2dのような「カチッとした」エッジは少し弱まることがあります。
しかし、「不自然なアーティファクト(グリッド)」よりは「自然な滑らかさ」の方が、人間の目には高画質に映ります。
また、LPIPS Lossを入れているため、ある程度のシャープさは維持されます。
5.2 補足: もう一つの選択肢 PixelShuffle
この問題に対する別解として、PixelShuffle (Sub-Pixel Convolution) という手法も有名です。
これは、画像を拡大するのではなく、チャンネル数(奥行き)を増やして、それを空間(縦横)に並べ替える というアクロバティックな手法です。
(例: チャンネル数を4倍にして計算し、最後に 2x2 のマスに並べ替えて解像度を2倍にする)
* **メリット**: 計算効率が良く、Resize+Convよりもシャープな画質が得られやすい。
* **デメリット**: 実はこれもしっかりと対策(ICNR初期化など)をしないと、結局グリッドノイズが出ることがある。
今回は、3x3ボトルネックという非常に敏感な環境であるため、「確実にグリッドを消せる」 という安定性を取って Resize + Conv を採用しました。
もし計算速度を極限まで追求する場合は、PixelShuffleも有力な選択肢になります。
6. まとめ
3x3ボトルネックで「Identity分離」を達成し、Resize+Convで「グリッドノイズ」を排除しました。
これにより、このFaceSwapモデルは:
1. 情報ボトルネック理論に基づき、Identityを正しく扱える
2. 不自然なノイズのない、自然な画像を生成できる
を達成できました。
参考:
- Odena, A., Dumoulin, V., & Olah, C. (2016). Deconvolution and Checkerboard Artifacts. Distill. https://distill.pub/2016/deconv-checkerboard/