VACEを深掘りする話2
深掘り回の2回目です。今回はさらにコードベースで見ていこうと思ってます。
第1回を別側面から見た説明になります。内容としてはほぼ同じなのですが、もっとコード側から見た考察になってます。
おさらいですが、VACEはVCU(Video Condition Unit)呼ばれてるアイデアに基づき、入力を Inactive (: 維持領域) と Reactive (: 編集領域) に分離して扱います。また、sdのcontrolnetのような入力でも同じく等しく扱うことで、文字通り一本化を行ってます。
このことにより、多様なタスクを明示的な条件分岐をすることなく、テンソルの値での条件分岐を用いることで全てを同条件に並列的に扱うモデルになります。
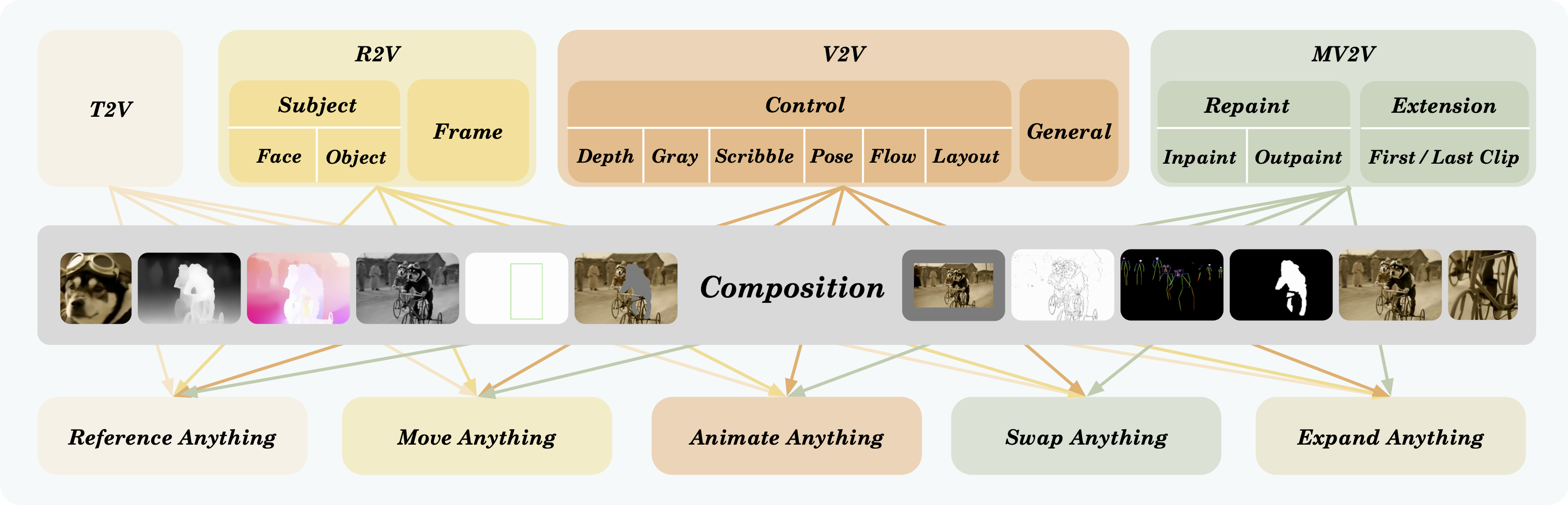
1. VACEの正体:スパルタ式・統合アーキテクチャ
VACEはタスクごとに別のモデルやモードを持っているわけではありません。「たった一つの仕組み」 で全てを処理しています。
-
単一の推論コード:
vace_wan_inference.pyは入力を振り分けることなく、全て同じパイプラインに流します。 -
「何でも屋」VAE (Universal Encoder):
- 通常のRGB動画、Depthマップ、棒人間(Pose)、すべてが同じVAEを通過してLatent空間に圧縮されます。
- モデルは、明示的なスイッチ(
if task == 'pose')ではなく、Latent空間におけるデータの「統計的な分布(指紋)」の違い(例:自然画はなだらか、棒人間はスパースで鋭い)を自律的に読み取り、処理モードを切り替えています。切り替えるというかなるようにしてそうなっていきます。 - これはLLMがコードと自然言語を区別するのと同様の、Foundation Model特有の「スパルタな解決策(Massive Multi-task Learning)」です。
VACE/Wan2.1/wan/modules/model.py
2. ControlNet的機構:Twin Tower構造
コード解析により、VACEは ControlNetに極めて近い構造(VaceWanModel)をしていることが判明しました。
- 構造: メインのT2Vモデル(Main Branch)に対し、制御用の並列ブランチ(VACE Branch)が存在します。
-
注入 (Injection):
- VACE Branchが抽出した特徴量(Hints)は、メインの各レイヤーの出力に対して 加算(Add) されます。
- これは 「同時(Joint)Attention」 として機能し、1回の推論ステップの中で「テキストプロンプトの意味」と「画像/マスクの空間的制約」が統合されます。
-
テキストなしでの動作:
- テキストプロンプトを空にすると、Main Branch側のCross-Attentionが無効化(または弱体化)され、VACE Branchからの制御信号(画像情報)が支配的になります。
3. Attentionと入力データの力学
モデルの挙動は、「Q (Query) がどこに K/V (Key/Value) を求めに行くか」 で決まります。
A. Reference画像の有無
-
Referenceあり (Copy & Paste / Style Transfer):
- QはReference画像のK/Vを見に行きます。
-
重要: Reference画像は 「BBoxで切り抜き&拡大(Resize)」 して渡すべきです。
- 理由1(密度の最大化): 切り抜くことで対象物が画面いっぱいに広がり、Attentionのヒット率(S/N比)が劇的に向上します(マクロレンズ効果)。
- 理由2(バイアスの排除): 全画面で渡すと「位置情報(座標)」が邪魔をしますが、切り抜けば「純粋なテクスチャ素材」として扱われ、場所を問わず適用可能になります。
-
Referenceなし (Inpainting / Removal):
- Reference由来のK/Vが存在しないため、Qは Self-Attention(周囲のピクセル) と Text Prompt に答えを求めます。
- 除去タスクの正解: 「物体を消して背景にする」タスクでは、外部画像(Ref)はノイズになり得ます。Refを渡さず、Self-Attentionに「周りの壁と同じ柄で埋めろ」と推測させるのが最も高品質です。
B. グレー(画素値127)の数学的意味
- モデル内部では画像は
[-1.0, 1.0]に正規化されます。 - 黒(0) = -1.0: 強い「負」の信号(暗闇)。
- 白(255) = +1.0: 強い「正」の信号。
-
グレー(127) = 0.0: 「無(ニュートラル)」。
- マスク領域をグレーで塗りつぶすことは、モデルに対する 「入力バイアス(オフセット)の完全な除去」 を意味します。これにより、モデルはプラス方向にもマイナス方向にも自由に生成を行えます。
4. ControlNetに関する理論的洞察
「ControlNetはなぜ棒人間も深度も扱えるのか?」という疑問からの発展です。
-
翻訳機としての機能:
- ControlNetは、入力画像(棒人間など)をテキストベクトルに変換するのではなく、「空間的な特徴量マップ(Feature Map)」 に翻訳してメインモデルに注入します。
- 入力が何であれ(QRコードでも)、学習さえさせれば「メインモデルへの指示書(ここをこう描け)」に変換可能です。
-
学習戦略:
- 親モデルは凍結 (Freeze): 賢い親(SDやWan)の脳は絶対に傷つけません。
- Zero Convolution: 学習初期は注入量を「ゼロ」にして、親の動作を妨害しない状態からスタートし、徐々に影響力を強めていきます(Ramp-up)。
- 損失の勾配: 親モデルは元々画像を復元できますが、ControlNetのヒントがあった方が 「より正確に(Lossが下がる方向に)」 復元できるため、その「さらに下がる道」を学習します。
5. removalタスクへの結論
これらの理論に基づき、今回のタスク(Reference-guided Subject Removal)における成功率を上げる方法。
- 戦略: Inpainting (Self-Attention)
-
設定:
- Refなし: 外部ノイズを断つ。
-
Maskあり: BBoxまたは十分に太らせた(Dilate)マスクを使用する。
- 理由: VAEの圧縮率(約1/8)により、細いマスク(ワイヤー幅)はLatent空間で消失したり、色が混ざったりするため。
- Videoあり: マスク領域を グレー(127) で塗りつぶし、オフセットをゼロにする。
- Prompt: 空、または単純な品質指示のみ。