自己紹介
masachacoといいます。
競馬AIユーミィちゃん(現在改良修行でお休み中 ) の開発サポート担当です。
ユーミィちゃんはnetkeibaさんの、競馬AI予想マスターズ で最終戦まで行き、最終戦最下位でした( ;∀;)
さて、競馬AIを作る中でデータ集計をする機会はめちゃくちゃあります。
過去の自分は、自分で作ったプログラムでゴリゴリ集計していました。
そんな中、ウィンドウ関数や集約関数を活用すると一発で出来ることを知ったので共有したいと思います。
ウィンドウ関数や、集約関数、聞いたことあるけどイメージつきづらいな、検索し辛いな。と思っていたので参考になると幸いです。
解説はざっくりなので、あしからず・・・。細かい仕様などは公式ドキュメントなどを参考にしてください。
前提となるテーブル
こういうテーブルがあるとする。
今回参考にするのはジオグリフさんのデータ。
select
-- 血統登録番号はお馬さんのIDみたいなもの
ketto_toroku_bango as 血統登録番号,
race_date as レース年月日,
kaisai_tsuki as 開催月,
kyori as 走る距離,
kakutei_chakujun as 今走の着順,
bamei as 馬名
from
race_data
where
ketto_toroku_bango in ('2019105056')
order by race_date
| 血統登録番号 | レース年月日 | 開催月 | 走る距離 | 今走の着順 | 馬名 |
|---|---|---|---|---|---|
| 2019105056 | 20210626 | 6 | 1800 | 1 | ジオグリフ |
| 2019105056 | 20210904 | 9 | 1800 | 1 | ジオグリフ |
| 2019105056 | 20211219 | 12 | 1600 | 5 | ジオグリフ |
| 2019105056 | 20220213 | 2 | 1800 | 2 | ジオグリフ |
| 2019105056 | 20220417 | 4 | 2000 | 1 | ジオグリフ |
| 2019105056 | 20220529 | 5 | 2400 | 7 | ジオグリフ |
| 2019105056 | 20221030 | 10 | 2000 | 9 | ジオグリフ |
| 2019105056 | 20230625 | 6 | 2200 | 9 | ジオグリフ |
| 2019105056 | 20231203 | 12 | 1800 | 15 | ジオグリフ |
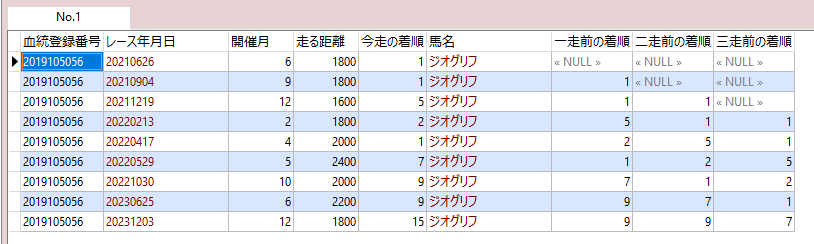
今走のレコードにn走前のデータを表示したい
例えば、お馬さんごとの過去の着順を参考にしたいとき。
下記の例は今走のレコードに、一走前、二走前、三走前の着順を合わせて出力するようにする。
select
ketto_toroku_bango as 血統登録番号,
race_date as レース年月日,
kaisai_tsuki as 開催月,
kyori as 走る距離,
kakutei_chakujun as 今走の着順,
bamei as 馬名,
-- ketto_toroku_bango(お馬さんのID)でグループ化し、それをrace_dateの新しい順に並べたとき
-- 現在のレコードより1個前の着順を取得する
LAG(kakutei_chakujun, 1) OVER (PARTITION BY ketto_toroku_bango ORDER BY race_date) AS 一走前の着順,
LAG(kakutei_chakujun, 2) OVER (PARTITION BY ketto_toroku_bango ORDER BY race_date) AS 二走前の着順,
LAG(kakutei_chakujun, 3) OVER (PARTITION BY ketto_toroku_bango ORDER BY race_date) AS 三走前の着順
from
race_data
where
ketto_toroku_bango in ('2019105056')
order by race_date
ざっくり解説
ウィンドウ関数を使い、各行のデータは残しつつ、指定した条件ごとにデータを集約する。
OVERで、お馬さんのIDごとにデータをグループ化し、開催日時が昔の順に並び替えたお馬さんごとのデータをつくる。
そのお馬さんごとのデータ(今回ならジオグリフのデータ)に対して、
LAG関数を使って、1~3走前の着順を取得する。
今走より前の結果を集約する
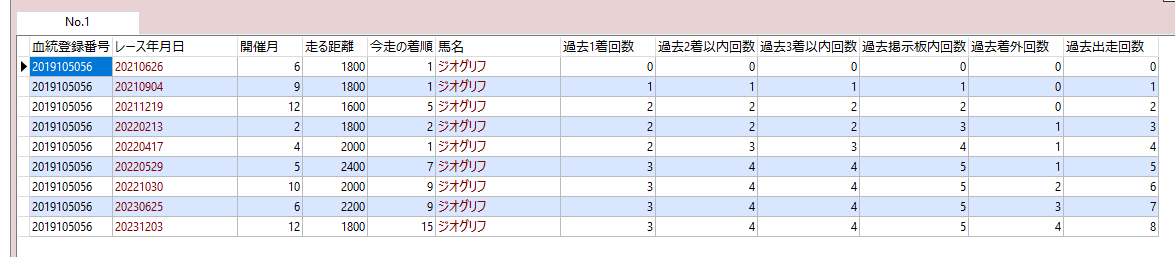
例えば、今走のデータに加えて、今走より前の1着回数、2着内回数、3着内回数、掲示板内回数、着外回数を表示したい場合。
select
ketto_toroku_bango as 血統登録番号,
race_date as レース年月日,
kaisai_tsuki as 開催月,
kyori as 走る距離,
kakutei_chakujun as 今走の着順,
bamei as 馬名,
-- 今走の着順を除いた、今走より前の着順を集計する
count(kakutei_chakujun) FILTER(WHERE kakutei_chakujun = 1) OVER (partition by ketto_toroku_bango order by race_date asc rows between unbounded preceding and current row exclude current row) 過去1着回数,
count(kakutei_chakujun) FILTER(WHERE kakutei_chakujun <= 2) OVER (partition by ketto_toroku_bango order by race_date asc rows between unbounded preceding and current row exclude current row) 過去2着以内回数,
count(kakutei_chakujun) FILTER(WHERE kakutei_chakujun <= 3) OVER (partition by ketto_toroku_bango order by race_date asc rows between unbounded preceding and current row exclude current row) 過去3着以内回数,
count(kakutei_chakujun) FILTER(WHERE kakutei_chakujun <= 5) OVER (partition by ketto_toroku_bango order by race_date asc rows between unbounded preceding and current row exclude current row) 過去掲示板内回数,
count(kakutei_chakujun) FILTER(WHERE kakutei_chakujun > 3) OVER (partition by ketto_toroku_bango order by race_date asc rows between unbounded preceding and current row exclude current row) 過去着外回数,
count(kakutei_chakujun) OVER (partition by ketto_toroku_bango order by race_date asc rows between unbounded preceding and current row exclude current row) 過去出走回数
from
race_data
where
ketto_toroku_bango in ('2019105056')
order by race_date
ざっくり解説
同様にウィンドウ関数を使い、各行のデータは残しつつ、指定した条件ごとにデータを集約する。
今走より過去のデータを一緒に表示したいため、
- 「今走より前」のデータがターゲット
- 「今走のデータは含めない」
というのが、ちょっと難しい。分解するとこんな感じ。
- count(kakutei_chakujun)
- 着順をカウントする
- FILTER(WHERE kakutei_chakujun = 1)
- 1着になったデータがカウント対象
- OVER (partition by ketto_toroku_bango
- 血統登録番号(今回はジオグリフ)ごとに、データをグループ化して
- order by race_date asc
- 古い順に並び替える
- rows between unbounded preceding and current row
- 対象は今走より前のデータ
- exclude current row)
- 自分自身(今走のデータ)は集計対象から除外する
参考にしたサイト
順位をつけたい
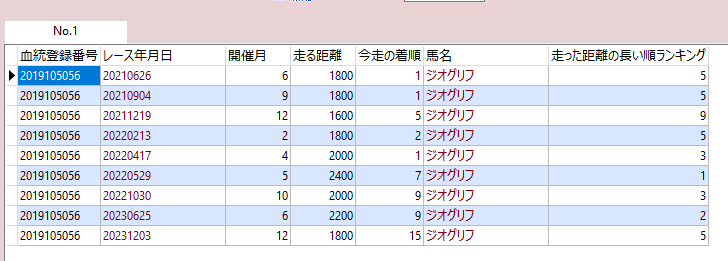
たとえば、今回のレースって同じお馬さんの、他のレースと比べて何番目に長いんだっけ。
みたいなのを調べたい場合。
select
ketto_toroku_bango as 血統登録番号,
race_date as レース年月日,
kaisai_tsuki as 開催月,
kyori as 走る距離,
kakutei_chakujun as 今走の着順,
bamei as 馬名,
-- 今走の着順を除いた、今走より前の着順を集計する
rank() OVER(PARTITION BY ketto_toroku_bango order by kyori desc) as 走った距離の長い順ランキング
from
race_data
where
ketto_toroku_bango in ('2019105056')
order by race_date
ざっくり解説
Windows関数の rank 関数を使うと OVER でグループ化した単位で順位付け出来る。
ちなみに percent_rank を使うと相対順位も出せる。
実際使うときには、 PARTITION BY にレースのIDを指定して、レース内での順位とかをつけるのに便利。
同一レース内で上がりの早い順にランキングをつけたいとか。
レコードの内容によってデータを出し分けたい
これはウィンドウ関数でも集約関数でもないですが。
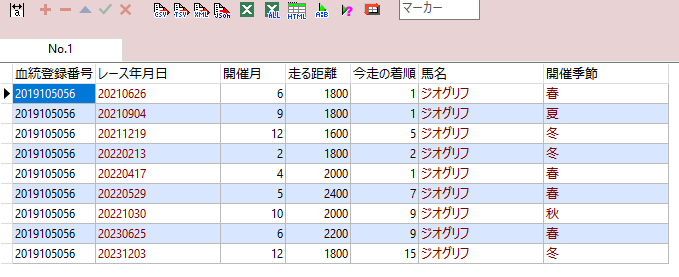
例えば、開催月を基に季節のカラムを追加したいとき。
select
ketto_toroku_bango as 血統登録番号,
race_date as レース年月日,
kaisai_tsuki as 開催月,
kyori as 走る距離,
kakutei_chakujun as 今走の着順,
bamei as 馬名,
-- 月ごとに季節を表示する
CASE
WHEN kaisai_tsuki = 12 or (1 <= kaisai_tsuki and kaisai_tsuki <= 3) THEN '冬'
WHEN (4 <= kaisai_tsuki and kaisai_tsuki <= 6) THEN '春'
WHEN (7 <= kaisai_tsuki and kaisai_tsuki <= 9) THEN '夏'
WHEN (10 <= kaisai_tsuki and kaisai_tsuki <= 11) THEN '秋'
ELSE NULL
END AS 開催季節
from
race_data
where
ketto_toroku_bango in ('2019105056')
order by race_date
ざっくり解説
CASE式を使って、カラムの内容ごとにデータを出し分ける。
今回は、レースの開催月が
- 4~6月なら「春」
- 7~9月なら「夏」
- 0~11月なら「秋」
- 12~3月なら「冬」
と表示する。
集計に時間がかかりすぎるときは
データ量にもよりますが、適切にインデックスを貼るとかなり高速に集計できます。
インデックスが張られていないと、結構重い処理なので集計に時間がかかります。
indexは貼ると今度はinsert時に時間がかかるようになるので、大量に投入する前には一旦indexは剥がし、投入し終えたらindexを貼ると良いと思います。
あとがき
競馬AIの開発はSQLの勉強になる。
簡単なSQLしかほぼほぼ使ったことが無かったので、勉強になりました。
ちゃんとSQLやデータベースの勉強をしていなかったツケが回ってき多様に思います。多少回収できてよかったです。
Pythonを書いてゴリゴリ集計するより、だいぶ楽かつ高速に集計できるようになりました。
こういうの検索しようと思ってもなかなか言語化にできませんね。
with 句とかもサブクエリを使うよりだいぶ見やすく、便利だなーと思います。
ちゃんとSQLを勉強するとプログラムでやっていた面倒な集計作業の大部分を寄せられるかもしれないですね・・・。
間違えてる所があれば、コメントや編集リクエストをください。
できれば、編集リクエストがいいな。