本記事は個人の意見であり、所属する組織の見解とは関係ありません。

こちらは AWS Fargate Advent Calendar 2017 の 12/4 分の記事です。
AWS Fargate を利用することで、従来のサーバーレス環境では工夫が必要であった長時間処理(業務処理的なバッチ)を、容易にサーバーレス環境で実現することが可能となりました。今回は、参考例として DB に対して長時間クエリが可能な仕組みを作成してみたいと思います。
構成概要
AWS Fargate 上で長時間タスクを実行する仕組みとして、下記の構成を作成してみます。
今回は SQL を実行する仕組みですが、メイン処理次第ではさらに複雑な処理の実行も可能と思っています。
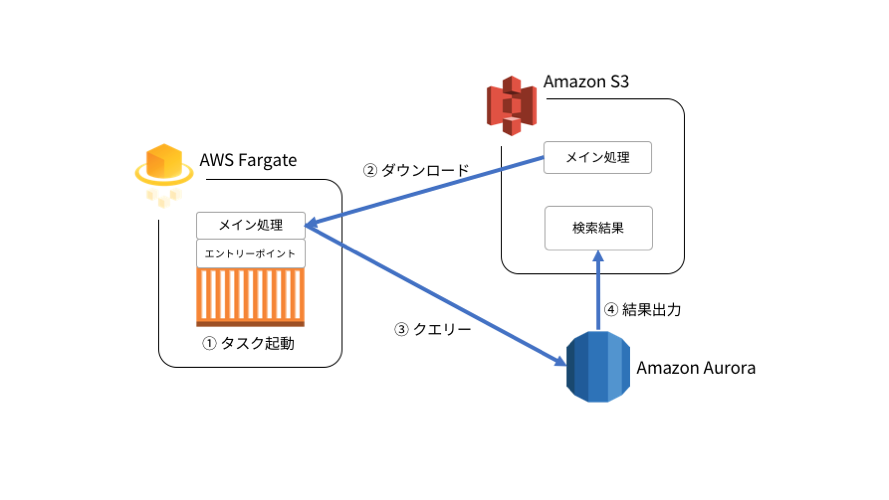
Amazon S3
- タスクのメイン処理の Python スクリプト、検索結果ファイルを格納します。
Amazon Aurora
- クエリ先のデータベースとなります。
- タスクからの接続は、IAM DB 認証で接続をします。 これによりコード側でパスワードの保持が不要となります。
- S3 バケットへ検索データの保存を行います。
Dockerfile の ENTRYPOINT として指定する Python スクリプト
- タスクの処理本体となる別の Python スクリプトを S3 から取得し、その後実行します。
Amazon Elastic Container Service クラスターおよびタスク
- AWS Fargate で構築します。
環境構築
S3 バケットの作成
ここではバケット名を batchquery-s3 として バージニア北部リージョンに作成します。その他の設定はデフォルトとします。
Amazon Aurora の起動
基本的にはプライベートなAuroraを 1 ノード起動します。ただし、IAM DB 認証と S3 バケット内へ検索データの保存(SELECT INTO OUTFILE S3)を行いたいので、その為の追加設定を行います。
ロール作成
Aurora から S3 へ検索結果を保存する際に必要となるポリシーを batchquery-sintos3policy として作成します。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "batchquerysid00",
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:AbortMultipartUpload",
"s3:DeleteObject",
"s3:GetObject",
"s3:ListMultipartUploadParts",
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::batchquery-s3",
"arn:aws:s3:::batchquery-s3/*"
]
}
]
}
batchquery-sintos3role として下記のポリシーを含んだサービス用ロールを RDS に作成します。
-
AmazonRDSDirectoryServiceAccess(AWS 管理ポリシー) -
RDSCloudHsmAuthorizationRole(AWS 管理ポリシー) -
batchquery-sintos3policy(上記で作成)
クラスターパラメータグループの作成
batchquery-dbclpg としてクラスターパラメータグループを作成します。その後、パラメータ aurora_select_into_s3_role に上記で作成したロール ARN arn:aws:iam::<AWS Accout ID>:role/batchquery-sintos3role を設定します。
DB インスタンスの起動
上記のクラスターパラメータグループ batchquery-dbclpg を指定して DB インスタンスを起動します。
- DB名:
db01 - IAM DB 認証:
有効化 - Security Group:
VPC 内の CIDR から接続可能な設定
ロール割り当て
クラスター設定の IAMロールの管理 から、上記で作成したロール batchquery-sintos3role を割り当てます。
検索結果をS3に格納するためには、IAMロールの管理 と前述のクラスターパラメータグループのパラメータ設定の二つが必要となります。
S3 への接続経路確認
Aurora から SELECT INTO OUTFILE S3 を利用する場合、Aurora から S3 への通信が発生します。
必要に応じて VPC Endpoint などの設定を行います。
ユーザ作成
任意のクライアントツールで DB に接続し、バッチクエリ実行用ユーザ batchquery を作成します。
併せて IAM DB 認証のため設定、SSL 接続、S3 への検索結果保存用権限の設定も行います。
CREATE USER 'batchquery'@'%' IDENTIFIED WITH AWSAuthenticationPlugin as 'RDS';
GRANT SELECT ON db01.* TO 'batchquery'@'%' REQUIRE SSL;
GRANT SELECT INTO S3 ON db01.* TO 'batchquery'@'%' REQUIRE SSL;
タスク構築
メイン処理の準備
タスクのメイン処理として実施するスクリプトを作成します。参考として Python で下記のスクリプトを作成しました。
このスクリプトは、S3 に格納しておきます。こうすることで、メイン処理のみの更新が容易になり、Lambda 的な使い方に近づけられると思っています。
# -*- coding: utf-8 -*-
import mysql.connector
import boto3
# 各種定数
REGION = 'us-east-1'
DBHOST = 'db01cl.cluster-abcdefghijkl.us-east-1.rds.amazonaws.com'
DBPORT = 3306
DBNAME = 'db01'
DBUSER = 'batchquery'
SSLCA = '/root/rds-combined-ca-bundle.pem'
rds = boto3.client('rds', region_name=REGION)
# IAM DB 認証のための認証トークン生成
AUTHTOKEN = rds.generate_db_auth_token(
DBHostname=DBHOST,
Port=DBPORT,
DBUsername=DBUSER,
Region=REGION
)
# DB 接続
conn = mysql.connector.connect(
user=DBUSER,
password=AUTHTOKEN,
host=DBHOST,
database=DBNAME,
charset='utf8',
ssl_verify_cert=True,
ssl_ca=SSLCA
)
# クエリ実行及び S3 へ結果出力
cursor = conn.cursor()
cursor.execute("SELECT * FROM table1 INTO OUTFILE S3 's3://batchquery-s3/output/result' OVERWRITE ON;")
# カーソル及び接続のクローズ
cursor.close
conn.close
上記のメイン処理のスクリプトは、s3://batchquery-s3/script/entrypoint.py として格納しておきます。
出力結果は、タスクが完了後、s3://batchquery-s3/output/result.part_00000 として格納されます。
ENTRYPOINT 用のスクリプトの準備
S3 に格納されているメイン処理を取得し実行する ENTRYPOINT 用のスクリプトを作成します。メイン処理の情報は、引数から格納先バケット名およびキーを取得する仕様としています。今回は、Python 限定ですが、Docker Image とこのスクリプト次第では様々な言語のスクリプトの長時間実行が実現できると思います。
# -*- coding: utf-8 -*-
import boto3
import subprocess
import sys
# 各種定数
TASKFILE = '/tmp/task.py'
s3 = boto3.resource('s3')
# S3 に格納されている処理本体の取得
args = sys.argv
bucket = s3.Bucket(args[1])
bucket.download_file(Key=args[2],Filename=TASKFILE)
# メイン処理の実行
subprocess.run(["python3",TASKFILE])
Docker Image の作成
Docker Image にはPython 3系、Boto3、ENTRYPOINT 用スクリプト、IAM DB 認証時の SSL 接続用のCAファイル を準備します。Docker Image のビルド環境の準備等は他のドキュメントを参考にしてください。
下記のディレクトリ構成の前提とします。
<作業ディレクトリ>
├ Dockerfile
├ entrypoint.py
└ rds-combined-ca-bundle.pem
以下の Dockerfile を準備します。
FROM amazonlinux:latest
RUN yum -y install -y python36 python36-pip
RUN pip-3.6 install boto3
RUN pip-3.6 install mysql-connector-python
COPY entrypoint.py /root
COPY rds-combined-ca-bundle.pem /root
ENTRYPOINT ["python3","/root/entrypoint.py"]
IAM DB 認証時の SSL 接続用のCAファイルはこちらを参考に取得します。
wget https://s3.amazonaws.com/rds-downloads/rds-combined-ca-bundle.pem
今回は、 Docker Image に静的に組み込んでいますが、本来は処理実行毎に更新有無の確認が必要かもしれません。
以下のコマンドでDocker Imageを作成します。
docker build . -t batchquery
Amazon Elastic Container Registry に保存
上記 Docker Image を Amazon Elastic Container Registry (以下 ECR) に保存します。詳細は、こちらを参照してください。
タスク実行用ロールの作成
AWS Fargate でタスク実行する際に指定するロールを作成します。
まず、batchquery-taskpolicy としてポリシーを作成します。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "batchquerysid00",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::batchquery-s3",
"arn:aws:s3:::batchquery-s3/*"
]
},
{
"Sid": "batchquerysid01",
"Effect": "Allow",
"Action": "s3:ListObjects",
"Resource": "*"
},
{
"Sid": "batchquerysid02",
"Effect": "Allow",
"Action": "rds-db:connect",
"Resource": [
"arn:aws:rds-db:us-east-1:<AWS account ID>:dbuser:*/batchquery"
]
}
]
}
batchquery-taskrole として上記のポリシーを含んだサービス用ロールを EC2 Container Service のユースケース EC2 Container Service Task に作成します。
タスク定義作成
主な設定としては以下の内容でタスク定義を作成します。
今回のクエリー処理は、タスク側の負荷はほとんどありませんので、少ないリソースで実行が可能です。
- タスク定義名:
batchquery - タスクロール:
batchquery-taskrole - Task execution role:
ecsTaskExecutioRole - Task memory:
0.5GB - Task CPU(vCPU):
0.25vCPU - コンテナの追加
- コンテナ名
batchquery - イメージ
<AWS Account ID>.dkr.ecr.us-east-1.amazonaws.com/batchquery:latest
- コンテナ名
クラスタ作成
Fargate のクラスター構築は下記のみとなります。
- Cluster Template:
Netoworking Only(Powered by AWS Fargate) を選択 - クラスター名:
batchquery-fg
処理実行
ダミーデータ準備
任意の DB クライアントから Aurora に接続し、db01 に対して以下のテーブルおよびダミーデータを作成します。
USE db01;
CREATE TABLE table1 (id INTEGER, attr1 VARCHAR(10), attr2 VARCHAR(10));
INSERT INTO table1 VALUES ( 1, 'AAAAAAAA01','BBBBBBBB01'),
( 2, 'AAAAAAAA02','BBBBBBBB02'),
( 3, 'AAAAAAAA03','BBBBBBBB03'),
( 4, 'AAAAAAAA04','BBBBBBBB04'),
( 5, 'AAAAAAAA05','BBBBBBBB05'),
( 6, 'AAAAAAAA06','BBBBBBBB06'),
( 7, 'AAAAAAAA07','BBBBBBBB07'),
( 8, 'AAAAAAAA08','BBBBBBBB08'),
( 9, 'AAAAAAAA08','BBBBBBBB09'),
(10, 'AAAAAAAA10','BBBBBBBB10');
COMMIT;
タスク実行
コンソール画面からタスク定義名:Revisionを選択しタスクの実行を行います。主な設定内容は以下の通りとします。
コマンドの上書きで、メイン処理のスクリプトが格納されている、バケット名、Key を指定します。
- Launch type:
FARGATE - タスク定義:
batchquery:<リビジョン番号> - クラスター:
batchquery-fg - クラスターVPC:
<Auroraと接続可能なVPC> - サブネット:
<Auroraと接続可能なサブネット> - セキュリティグループ:
<任意> - Auto-assign public IP:
<外部のAWS API エンドポイントとの通信が可能な設定> - コマンドの上書き:
batchquery-s3,script/batchquery.py
タスク完了確認
タスクの実行が完了した後、s3://batchquery-s3/output/result.part_00000 に上記のダミーデータの内容が出力されていることを確認します。
1 AAAAAAAA01 BBBBBBBB01
2 AAAAAAAA02 BBBBBBBB02
3 AAAAAAAA03 BBBBBBBB03
4 AAAAAAAA04 BBBBBBBB04
5 AAAAAAAA05 BBBBBBBB05
6 AAAAAAAA06 BBBBBBBB06
7 AAAAAAAA07 BBBBBBBB07
8 AAAAAAAA08 BBBBBBBB08
9 AAAAAAAA08 BBBBBBBB09
10 AAAAAAAA10 BBBBBBBB10
デフォルトは TSV 形式となっています。
まとめ
AWS Fargate を利用することで、サーバレスでも長時間処理が可能となり、用途が非常に広がったと感じました。また、AWS Fargate は本当に管理が不要で、今回はコンテナに実行させたいことだけしか実施しませんでしたが、これが当たり前となったことがとても楽しみです。