はじめに
本記事は、私が独学で学んだ事をまとめている記事です。
CNN については出来るだけわかりやすく噛み砕いて説明していきます。
詳細を知りたい場合は参考URLを貼っておきましたのでそちらをご覧ください。
想定読者
・CNN をやってみたい人
・CNN が何をしているかわからない人
上記にも書いてある通り独学のため、間違えている部分がございましたらご指摘のほどよろしくお願い致します。
CNN (Convolutional Neural Network)とは
主に画像や動画認識に広く使われているニューラルネットワークです。
通常のニューラルネットワークと異なる点は、畳み込み層とプーリング層がある点です。
畳み込み層
畳み込み層とは、特徴を抽出している層になります。
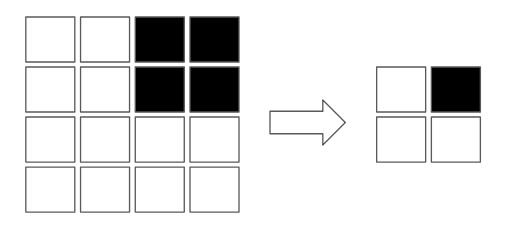
上記画像のように、黒い部分の特徴を残しながら縮小することができます。
このような解像度縮小を行っているのが畳み込み層です。
プーリング層
プーリング層とは、特徴として重要な情報を残しながら縮小している層になります。
学習させるデータには、犬や猫を判別したい場合でも数百枚以上の画像を使用します。
使用する画像の猫の位置や体勢が全て一緒ではありません。
この状況で、この特徴は猫だ。と判断するには、余分な情報が存在します。
プーリング層は、「特徴として重要な情報である」猫がいる部分だけを残して縮小するのです。
詳細を知りたい場合はこちらを参考にしてください。
Convolutional Neural Networkとは何なのか
畳み込みニューラルネットワーク (CNN)
データセット
今回は、CIFAR-10 と呼ばれる画像データセットを使用します。
CIFAR-10 は、飛行機、自動車、鳥、猫、鹿、犬、カエル、馬、船、トラックの10クラス(種類)からなるデータです。
32×32×3(RGB)のデータで、全部で60000枚の画像があります。

CIFAR-10 の中身はこのようになっています。
実装・前処理
今回の実装では、Google Colaboratory を使用しています。
画像処理は時間がかかるため Google Colaboratory にある GPU を使用してください。
Google Colaboratory 特有の宣言です。
また、今回の実装ではモデルを Google Drive に出力するため、ただ単純に使う場合とは別の記述になっていると思われます。
!pip install -U -q PyDrive
# Drive 認証
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
from google.colab import auth
from oauth2client.client import GoogleCredentials
auth.authenticate_user()
gauth = GoogleAuth()
gauth.credentials = GoogleCredentials.get_application_default()
drive = GoogleDrive(gauth)
ライブラリ宣言
使用するライブラリの宣言です。
import matplotlib.pyplot as plt
import numpy as np
from keras.models import Sequential
from keras.layers.convolutional import Conv2D
from keras.layers.pooling import MaxPool2D
from keras.optimizers import Adam
from keras.layers.core import Dense, Activation, Dropout, Flatten
from keras.datasets import cifar10
from keras.utils import np_utils
from keras.utils.np_utils import to_categorical
下記で cifar10 画像データをダウンロードします。
# cifar10をダウンロード
(x_train, y_train),(x_test, y_test) = cifar10.load_data()
正規化
画像データの正規化を行います。
画像データの正規化では、RGB を 255 で割ることにより、データを0-1の範囲に正規化することができます。
0-1の範囲にすることで精度が向上したり、機械の中では扱いやすいデータになります。
---------------------------------------------------
正規化前
---------------------------------------------------
[[[ 59 62 63]
[ 43 46 45]
[ 50 48 43]
[ 68 54 42]
[ 98 73 52]
[119 91 63]
[139 107 75]
[145 110 80]
[149 117 89]
[149 120 93]
[131 103 77]
[125 99 76]
[142 115 91]
[144 112 86]
[137 105 79]
[129 97 71]
[137 106 79]
[134 106 76]
[124 97 64]
[139 113 78]
[139 112 75]
[133 105 69]
[136 105 74]
[139 108 77]
[152 120 89]
[163 131 100]
[168 136 108]
[159 129 102]
[158 130 104]
[158 132 108]
[152 125 102]
[148 124 103]]]
# 画像を0-1の範囲で正規化
x_train = x_train.astype('float32') / 255.0
x_test = x_test.astype('float32') / 255.0
---------------------------------------------------
正規化後
---------------------------------------------------
[[[0.23137255 0.24313726 0.24705882]
[0.16862746 0.18039216 0.1764706 ]
[0.19607843 0.1882353 0.16862746]
[0.26666668 0.21176471 0.16470589]
[0.38431373 0.28627452 0.20392157]
[0.46666667 0.35686275 0.24705882]
[0.54509807 0.41960785 0.29411766]
[0.5686275 0.43137255 0.3137255 ]
[0.58431375 0.45882353 0.34901962]
[0.58431375 0.47058824 0.3647059 ]
[0.5137255 0.40392157 0.3019608 ]
[0.49019608 0.3882353 0.29803923]
[0.5568628 0.4509804 0.35686275]
[0.5647059 0.4392157 0.3372549 ]
[0.5372549 0.4117647 0.30980393]
[0.5058824 0.38039216 0.2784314 ]
[0.5372549 0.41568628 0.30980393]
[0.5254902 0.41568628 0.29803923]
[0.4862745 0.38039216 0.2509804 ]
[0.54509807 0.44313726 0.30588236]
[0.54509807 0.4392157 0.29411766]
[0.52156866 0.4117647 0.27058825]
[0.53333336 0.4117647 0.2901961 ]
[0.54509807 0.42352942 0.3019608 ]
[0.59607846 0.47058824 0.34901962]
[0.6392157 0.5137255 0.39215687]
[0.65882355 0.53333336 0.42352942]
[0.62352943 0.5058824 0.4 ]
[0.61960787 0.50980395 0.40784314]
[0.61960787 0.5176471 0.42352942]
[0.59607846 0.49019608 0.4 ]
[0.5803922 0.4862745 0.40392157]]]
One-Hot 表現
現在の正解データの形式は、
[[0]
[5]
[3]]
のような形になっています。
この形式では、10クラスの判定ができません。
そこで、One-Hot表現に変換します。
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0] = [0]
[0, 0, 0, 0, 0, 1, 0, 0, 0, 0] = [5]
[0, 0, 0, 1, 0, 0, 0, 0, 0, 0] = [3]
このような形式にすることにより、出力した結果は
[0.15, 0.0, 0.5, 0, 0.25, 0, 0.2] のような出力結果を得ることができ、
この画像がモデルを通してどういう判別結果になっているか。という情報を取得することができます。
例えば、上記の0.5が犬で、0.25が猫である場合、小動物や形が似ているものの数値が高くなっている。など。
# 正解ラベルをOne-Hot表現に変換
y_train = np_utils.to_categorical(y_train, 10)
y_test = np_utils.to_categorical(y_test, 10)
モデル
この記述で CNN のモデルを構築しています。
ざっくりと説明していきますが、詳細に関しては先達者様にお任せします。
#モデルを構築
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same', input_shape=(32, 32, 3)))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3 ,3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPool2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
| 層 | 説明 |
|---|---|
| Conv2D | 畳み込み層(上記) |
| MaxPool2D | プーリング層(上記) |
| Dropout | 過学習を防止するために一部を存在しないように扱う層 |
| Flatten | 平滑化(次元削減) 3次元から1次元へ |
| Dense | 通常の全結合ニューラルネットワークレイヤー |
padding について
【Python】KerasのConv2Dの引数paddingについて
Dropout について
Keras初級者メモ: Dropoutの効果をちょっと確認 (MNIST)
活性化関数について
活性化関数のまとめ(ステップ、シグモイド、ReLU、ソフトマックス、恒等関数)
最適化関数について
Optimizer : 深層学習における勾配法について
損失関数について
損失関数について、ざっくりと考える
学習
モデルに対して画像を学習させます。
x_train が画像データで y_train が正解ラベルです。
epochs は学習回数を示しています。
# 学習
history = model.fit(x_train,
y_train,
batch_size=128,
epochs=25,
verbose=1,
validation_split=0.1)
verbose = 1 に設定していることで下記のようなログが出ます。
Train on 45000 samples, validate on 5000 samples
Epoch 1/25
45000/45000 [==============================] - 13s 283us/step - loss: 1.6532 - acc: 0.3913 - val_loss: 1.2907 - val_acc: 0.5334
Epoch 2/25
45000/45000 [==============================] - 12s 256us/step - loss: 1.2333 - acc: 0.5589 - val_loss: 1.0150 - val_acc: 0.6406
Epoch 3/25
45000/45000 [==============================] - 12s 256us/step - loss: 1.0300 - acc: 0.6338 - val_loss: 0.8602 - val_acc: 0.7008
Epoch 4/25
45000/45000 [==============================] - 12s 256us/step - loss: 0.9208 - acc: 0.6753 - val_loss: 0.8062 - val_acc: 0.7172
Epoch 5/25
45000/45000 [==============================] - 12s 257us/step - loss: 0.8363 - acc: 0.7047 - val_loss: 0.7454 - val_acc: 0.7376
この loss, val_loss, acc, val_acc などを利用することで learning curve と validation curve と呼ばれるグラフを出すことができます。
こちらを確認することで、モデルが過学習をしているかどうかの確認ができます。
学習時のモデル評価について
そのモデル、過学習してるの?未学習なの?と困ったら
モデルの保存
学習させたモデルの保存は、json 形式で保存されます。
ここで保存しているのは層を構築した段階でのモデルであり、model.add() をした場所までの層データです。
この保存だけではこのモデルを使用する場合に「学習させる前のモデル」を使用してしまいます。
そのため、学習させた時の重みデータも保存する必要があります。
いきなり出てきた重みってなんだよ?という方に
ニューラルネットワークの基礎解説:仕組みや機械学習・ディープラーニングとの関係は
def write_file(file_name):
# ファイル出力
upload_file = drive.CreateFile()
upload_file.SetContentFile(file_name)
upload_file.Upload()
json_string = model.to_json()
open('cifar10_cnn.json',"w").write(json_string)
model.save_weights('cifar10_cnn.h5')
write_file('cifar10_cnn.json')
write_file('cifar10_cnn.h5')
上記が実行された後、マイドライブ上にアップロードされているはずです。
保存したモデルを使用したい場合は、モデル自体の読み込みと重みを設定する必要があります。
下記が保存したモデルと重みを使用する場合のサンプル記述です。
from keras.models import model_from_json
json_string = open('./model/cifar10_cnn.json').read()
model = model_from_json(json_string)
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.load_weights('./model/cifar10_cnn.h5')
評価
学習させたモデルがどのぐらい良いものであるかを評価する必要があります。
loss と accuracy の他にも評価指標は存在します。
評価指標について
機械学習で使う指標総まとめ(教師あり学習編)
score = model.evaluate(x_test, y_test, verbose=0)
print('Test Data loss:', score[0])
print('Test Data accuracy:', score[1])
> Test Data loss: 0.6406550844669342
> Test Data accuracy: 0.7964
上記の accuracy が 0.79 と言う事は、このモデルは大体8割の正解率であると言えます。
予測結果
accuracy が出て8割の正解率だ!と言われても困ります。
実際にわかりやすく確認するために、画像に対する予測値と正解ラベルを並べて表示します。
# predict_classesで画像のクラスを予想する
img_pred = model.predict_classes(x_test)
# 画像
(_, _), (x_test_img, y_test_ans) = cifar10.load_data()
for i in range(10):
plt.figure()
rand_num = np.random.randint(0, len(x_test))
plt.imshow(x_test_img[rand_num])
plt.tick_params(labelbottom='off', bottom="off")
plt.tick_params(labelleft='off', left="off")
plt.axis('off')
plt.title('predict:{0}, answer:{1}'.format(img_pred[rand_num], y_test_ans[rand_num]))
plt.show()
正解ラベル
0 - 飛行機
1 - 自動車
2 - 鳥
3 - 猫
4 - 鹿
5 - 犬
6 - カエル
7 - 馬
8 - 船
9 - トラック







大体正解している気がしますが、犬と猫を間違えていたりしていますね。
耳と体勢を見ると猫に見えなくもないか…。
おわりに
今回は公開されているデータセットを使用しましたが、頑張れば自分で集めた画像データセットでモデルを作ることができます。
Qiita でも画像認識の面白い記事はあるので興味がありましたらぜひ調べてみてください。
本記事が少しでも参考になれば幸いです。