Mrigank Rochan, Linwei Ye, Yang Wang, "
Video Summarization Using Fully Convolutional Sequence Networks", in ECCV 2018, arXiv:1805.10538
1. どんなものか?
この論文で提案するモデルの目的は,ビデオが入力してあたえられた場合に,そのビデオの内容をキャプチャするフレームのサブセットを選択することである.つまり,入力のビデオを要約することである.
この論文では,ビデオ内のフレームをキーフレームと非キーフレームの2クラスに分けて,フレームごとに付けられた2クラスのラベルを推定する.
2. 先行研究との違いは何か?
従来のビデオ要約のモデルでは,リカレントモデルを使用することでシーケンスを処理していたが,この論文の提案手法では,完全に畳み込みだけでシーケンスを処理する.これによって,GPU性能を最大限に活用することができる.
また,セマンティックセグメンテーションのモデルをビデオ要約に利用する.
3. 技術や手法のキモは何か?
概観
この論文では,ビデオ要約とセマンティックセグメンテーションを同じような問題だと考える.シーケンスのラベル付け問題としてビデオ要約を考えると,ビデオ要約は入力の次元(2D vs 1D)およびチャネル数で(3 vs K)のみ異なるセマンティックセグメンテーションとして捉えることができる.
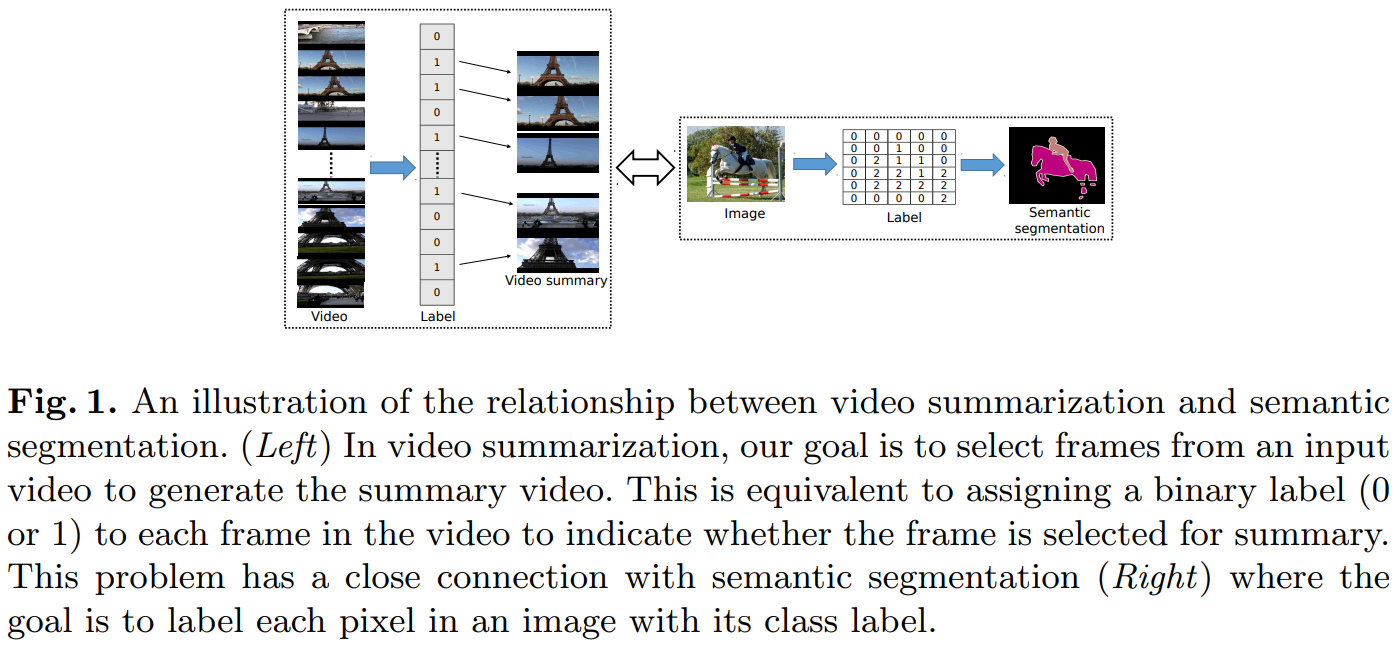
上のような理由に基づいて,FCNのようなネットワークのFully Convolutional Sequence Network(FCSN)を提案している.
Fully Convolutional Sequence Network(FCSN)
FCSNのモデルは以下のような特性を持っている.
- セマンティックセグメンテーションモデルは画像内の2次元空間に対して2D畳み込みを使用するが,FCSNでは時間的シーケンス領域に対して1D畳み込みを適用する.
- 連続的にフレームを処理するビデオ要約のLSTMモデルとは異なり,畳込み演算を使用してすべてのフレームを同時に処理する.
- セマンティックセグメンテーションモデルと同様に,エンコーダ・デコーダアーキテクチャを使用する.
この論文では,FCNを利用したFCSNを__SUM-FCN__と呼び,このモデルを実験する.
FCSNとして利用するセマンティックセグメンテーションモデルはFCNに限らず,ほぼすべてのモデルを利用することができる.
SUM-FCN
セマンティックセグメンテーションのタスクで広く用いられているFCNをビデオ要約のタスクに適応する.
- SUM-FCNの入力
- $1\times T\times D$ ($T$はビデオ内のフレーム数,$D$はフレームの特徴ベクトルの次元数)
- SUM-FCNの出力
- $1\times T\times C$ (各フレームに対して2つのクラスに対応するスコアが必要なので$C=2$である)
Learning
キーフレームベースの教師学習では,入力ビデオ内の少数のフレームのみがサマリービデオとして選択されるため,クラス(キーフレームと非キーフレーム)の数が非キーフレームに偏っている.
このようなクラスの偏りに対応する戦略として,重み付けされた損失を学習に用いることがよく行われる.
提案モデルでは下のように損失を計算する.
$c$のクラスのとき,その重みを次のように定義する.
$$w_c = \frac{median\text{_}freq}{freq_c}$$
ここで,$freq_c$はラベル$c$が存在するビデオ内のフレームの総数で割ったラベルcのフレーム数で,$median\text{_}freq$は周波数の中央値である.
これを用いて損失の計算は次のように行われる.
\mathcal{L}_{sum} = - \frac{1}{T}\sum_{t=1}^{T}w_{c_t}\log(\frac{\exp(\phi_{t,c_t})}{\sum_{c=1}^{C}\exp(\phi_{t,c})})
ここで,$c_t$はt番目のフレームの真値のラベル,$\phi_{t,c}$は$t$番目のフレームのクラス$c$の予測スコア,$w_{c_t}$は$t$番目のフレームのクラス$c$の重みを表している.
Unsupervised SUM-FCN
この論文では,SUM-FCNモデルを拡張して教師なし学習に対応したものを提案している.
まず,SUM-FCNのデコーダを以下のように変更する.
デコーダからの予測スコアに基づいて$Y$フレーム(キーフレーム)を選択する.選択したこれらのキーフレームの特徴ベクトルに$1\times 1$の畳み込みを適用して,元の特徴表現を再構成する.
選択したキーフレーム間で多様性が確保されるように$\mathcal{L}_{div}$を使用する.これは選択したキーフレーム間のペアワイズ類似度の平均として定義する.
\mathcal{L}_{div} = \frac{1}{|Y|(|Y|-1)}\sum_{t\in Y}\sum_{t'\in Y, t'\ne t}d(f_t,f_{t'}),\qquad \text{where} (f_t,f_{t'}) = \frac{f_t^Tf_{t'}}{||f_t||_2||f_{t'}||_2}
ここで,$f_t$は再構成された$t$番目特徴ベクトルである.
また,再構成のための損失として$\mathcal{L}_{recon}$を用意する.これは再構成された特徴ベクトルと入力のキーフレームの特徴ベクトルの二乗誤差平均である.
最終的な全体の損失は
\mathcal{L}_{div}+\mathcal{L}_{recon}
となる.
4. どのように有効性を検証したか?
データセット
- SumMe
- バラエティに富んだ25の動画が含まれており,一つの動画は1.5~6.5分の長さである.
- TVSum
- 10個の異なるカテゴリーからなる50個のYouTube動画から構成されている.動画は1~5分の長さである.
トレーニングでは,上記のデータセットではデータ量が少ないので,YouTube datasetやOpen Video Project(OVP)datasetでデータを増強する.
評価指標
モデルによって生成された要約を$S_O$として,真値の要約を$S_G$とすると精度$P$と再現率$R$は時間的な重なりを用いてつぎのように求めることができる.
P = \frac{|S_O\cap S_G|}{|S_o|}, R = \frac{|S_O\cap S_G|}{|S_G|}
そして,最終的に評価に用いるFスコアは
F = \frac{2P\times R}{P+R}\times 100
と計算する.
実験設定
3つの異なる条件のもとに実験を行う.
- 1. Standard Supervised Setting
- 訓練およびテストデータが同じデータセットから引き出される一般的な教師あり学習の設定
- 2. Augmented Setting
- 評価のために与えられたデータセットに加えて,訓練データを他の3つのデータセットによって増強して学習を行う設定
- 3. Transfer Setting
- 評価のために与えられたデータセットをテストデータのみに使用して,訓練データには他の3つのデータセットを用いる設定
結果と比較
-
SumMeデータセットによる評価
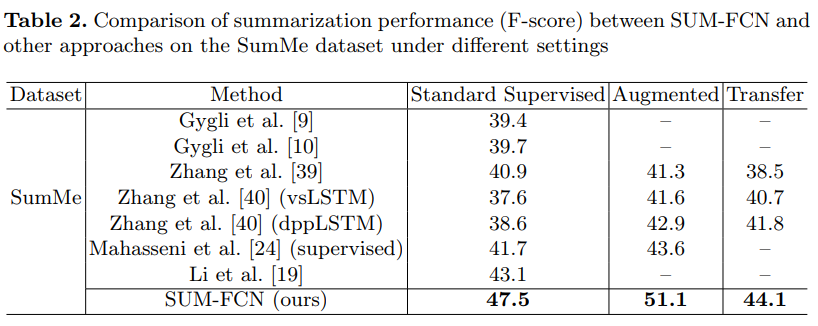
どの実験設定でも,従来手法のものよりも高いスコアを出すことができている. -
TVSumデータセットによる評価
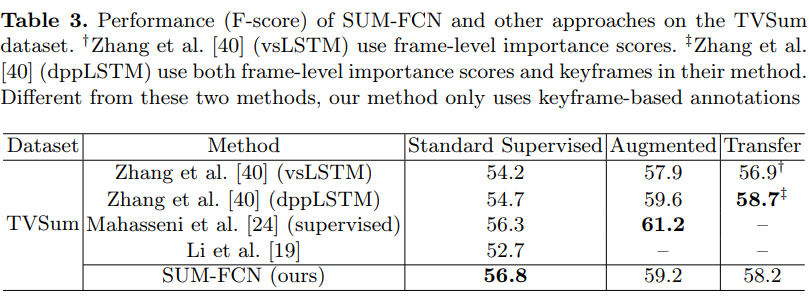
提案手法はキーフレームベースの2値のラベルしか使用していないのに従来手法と同等のスコアがでている.
分析
-
教師なし学習に対応した$\text{SUM-FCN}_{unsup}$を従来の教師なし学習モデルと比較する.
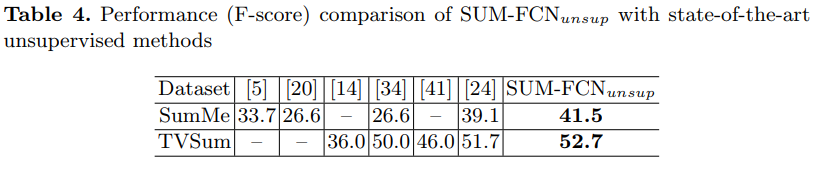
両方のデータセットで最先端のパフォーマンスを実現している. -
他の有名なセマンティックセグメンテーションモデルのDeepLabをビデオ要約タスクに応用した__SUM-DeepLab__の結果
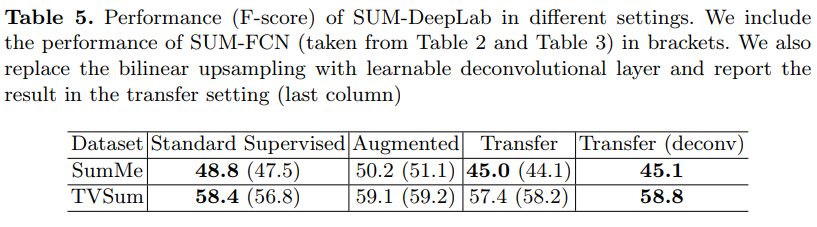
一部の実験設定では__SUM-FCN__よりも高いスコアを記録している. -
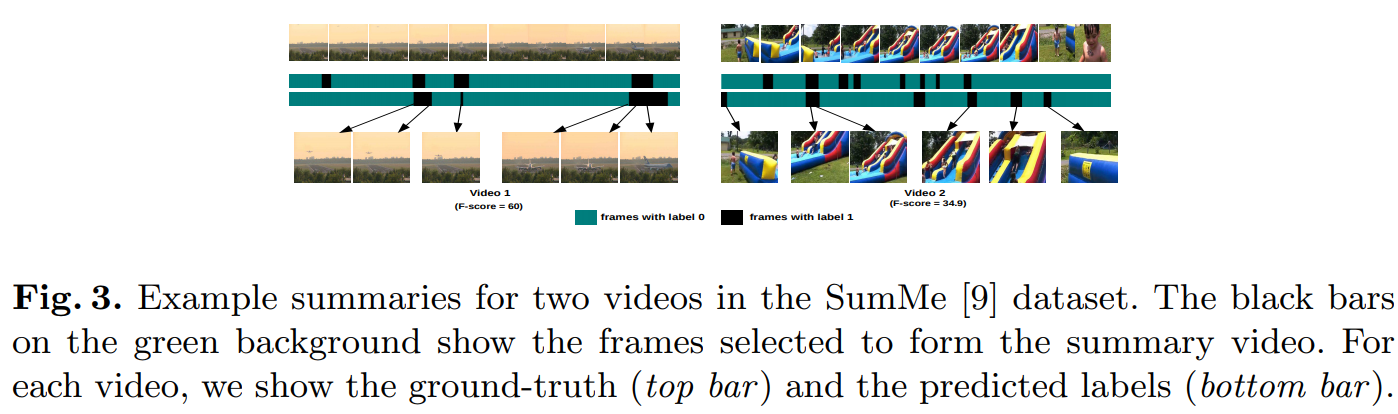
__SUM-FCN__の実行例