概要
自然言語処理のタスクのひとつに、固有表現抽出 (Named Entity Recognition) というものがあります。
詳しくは他のサイトなどを見てもらいたいですが、たとえば「太郎は3000円を支払った」という文章から「太郎」を人名、「3000円」を金額といったように、固有表現を抽出するタスクです。
ここでは、Watson DiscoveryとWatson Studioを使って、LLMで農林水産省の食料・農業・農村白書から「食料」に関する言及を抽出してみたいと思います。
手順
1. Watson Discoveryとデータの準備
まずはWatson DiscoveryのEntity Extractorを使って文章中の食料にラベルづけして学習データを作ります。
Watson Discoveryのインスタンスを作成します。今回はPlusプランを使っています。それからプロジェクトを作成します。プロジェクトのタイプはなんでも大丈夫です。今回は「Entity Extraction」という名前でDocument Retrievalタイプにしました。
そうしたら令和4年度 食料・農業・農村白書の全体版のPDFを全て一度自分のPCにダウンロードしておきます。それからコレクションを作成して、先ほどダウンロードしたPDFを全てアップロードします。
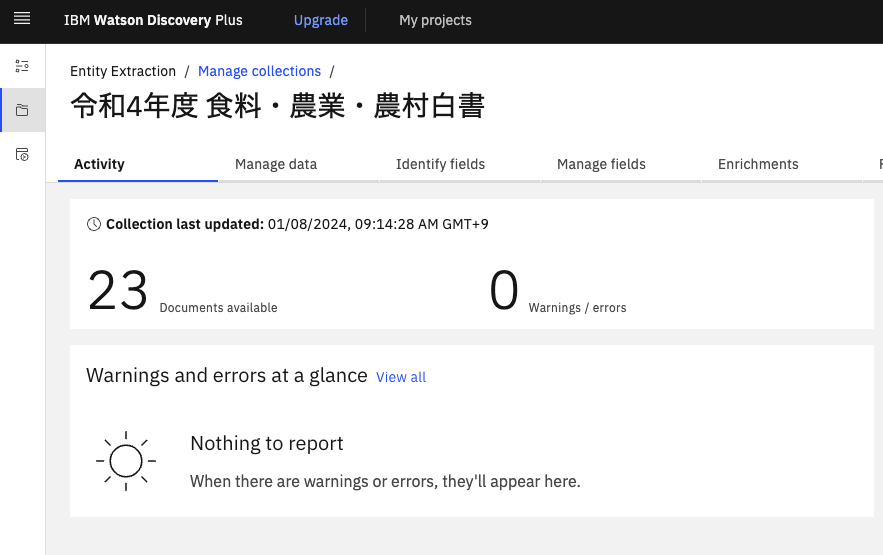
同様に、令和3年度のコレクションも作っておきます。
2. ラベルづけ
次はアップロードしたデータにラベルをつけて学習データを作っていきます。
左のバーからImprove and customizeに移動します。
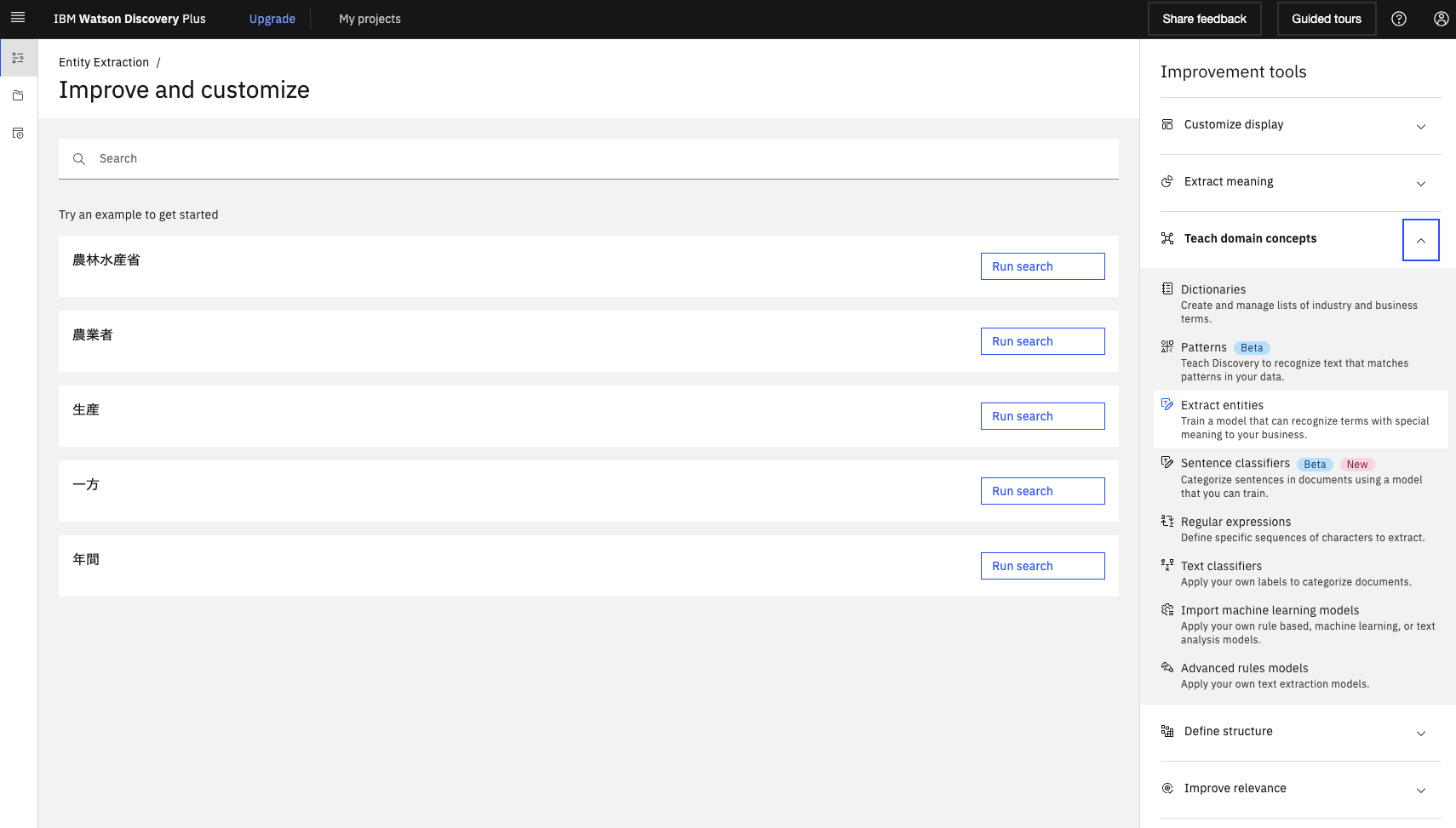
右のツールからTeach domain conceptsのExtract entitiesを選び、項目を埋めてCreateします。今回は令和4年度のデータを学習に使ってます。
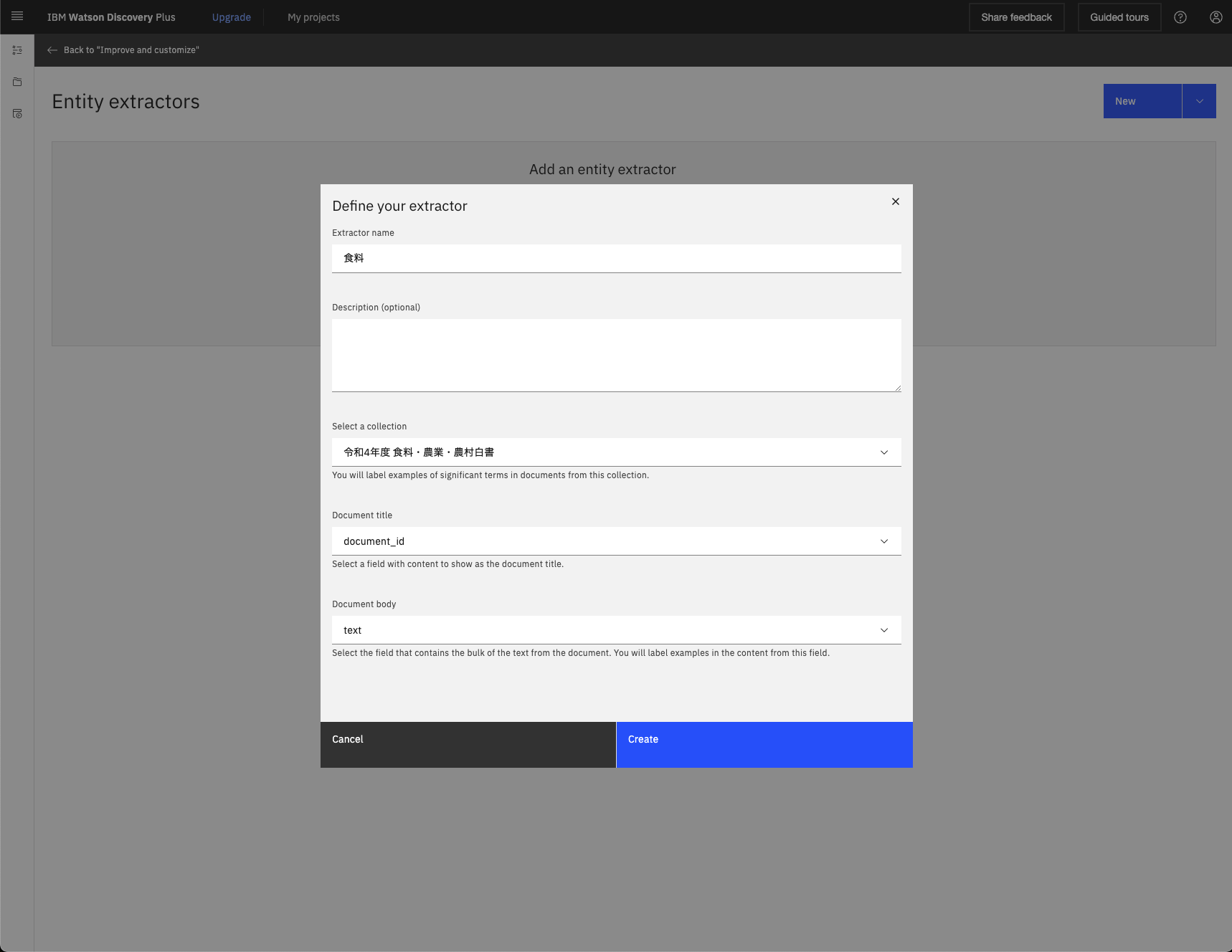
するとラベルづけするためのページに遷移するので、まずは右のAdd an entity typeから食料ラベルを作成します(今回はラベルひとつだけですが、「果物」「魚」のように複数のラベルをつけることもできます)。
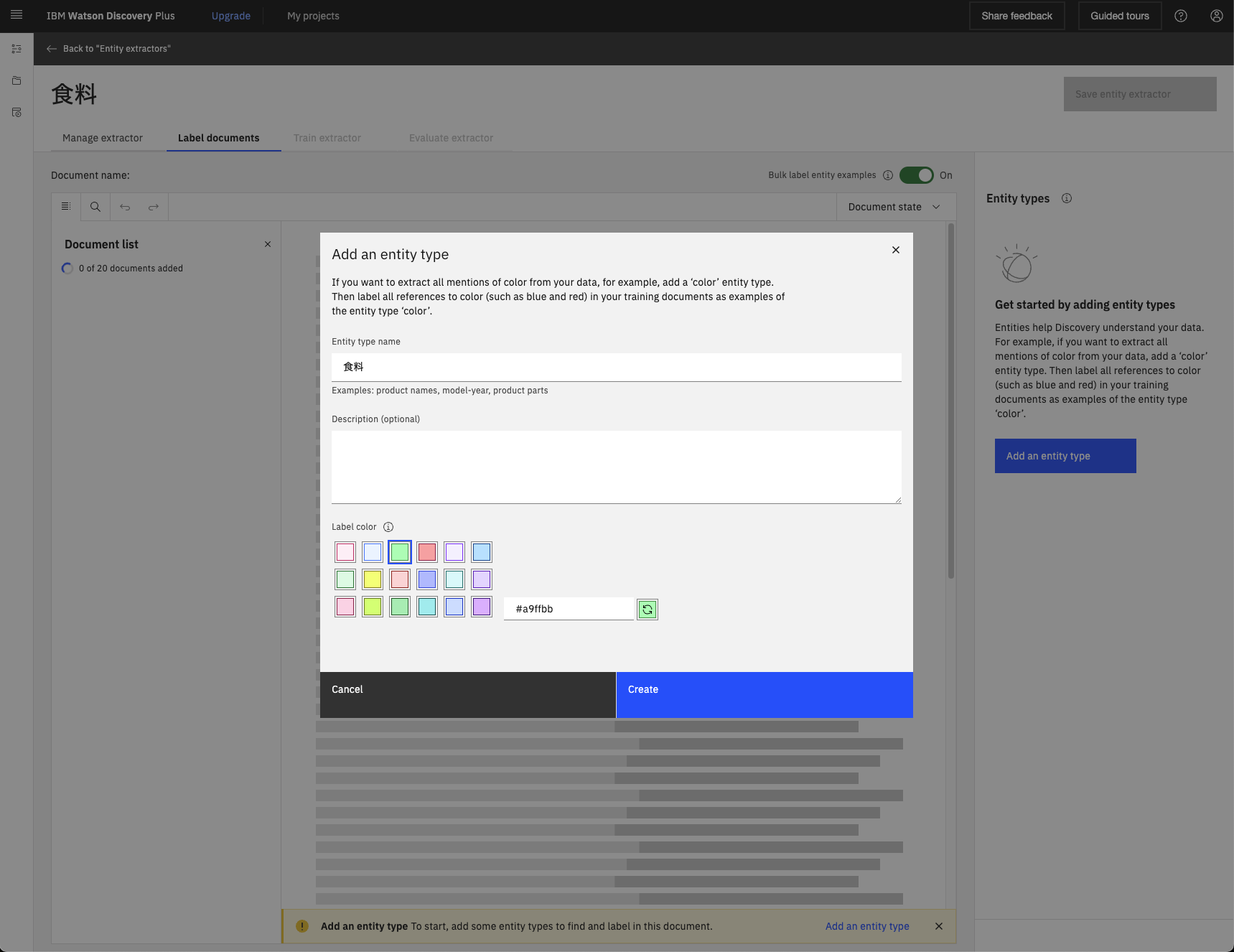
マウスで食料である単語をハイライトして食料ラベルをつけていきます。地道な作業ですが、できれば1000件くらいは欲しいので、頑張ってやっていきます。今回は1700件ほどつけました。この時、ラベルに一貫性がないとモデルを混乱させることになるので基準をよく考えて、一度つけた例やそれと似たものは一貫してつけましょう。下の例だと「水稲」を食料にするか迷いましたが、つけることにしたので「水稲」や「稲」は全てラベルがついています。

十分つけたと思ったらEntity extractorsのページに戻ってActionsからDownload labeled dataを選んでラベルづけしたデータを一度ダウンロードしておきます。
3. Watson Studioのセットアップ
Watson StudioはIBM Cloud Pak for Data (CP4D) というプラットフォーム上で使えるソフトウェアです。今回はマネージドのクラウド版であるCloud Pak for Data as a Service (CP4DaaS) を使いますが、後述するようにCP4DaaS版ではまだ訓練したLLMをWatson Machine Learning上にデプロイできないため、可能であればインストール版のCP4Dを使うことをお勧めします。
まずはCP4DaaSの登録をします。
そしたら、アクセストークンを追加しておきます。これは後でnotebookからデータを使えるようにするためです。他にもデータを使う手段があるようなのですが、自分がやった時はこれしかうまくいく方法が見つかりませんでした。
右上のアイコンからlabeled_data.jsonをアップロードします。
そしたら、チュートリアルのようにプロジェクトを作成してJupyter Notebookを追加します。この時、LLMの訓練を行うため下のようにランタイムにはNLP + DO 23.1以降を選びました。
4. 学習データの準備
作ったJupyter Notebookの編集モードに入り、トークンを挿入します。
挿入されたセルを実行します。
その後、先ほどアップロードしたjsonをダウンロードします。
wslib.download_file("labeled_data.json")
trainとtestに分割します。
import json
from watson_core.data_model.streams.resolver import DataStreamResolver
data_file = "labeled_data.json"
train_file = "train.json"
test_file = "test.json"
with open(data_file) as f:
data = json.load(f)
total = len(data)
threshold = int(total * 0.8)
train = data[:threshold]
test = data[threshold:]
print(len(train), len(test))
with open(train_file, "w") as f:
json.dump(train, f)
with open(test_file, "w") as f:
json.dump(test, f)
data_stream_resolver = DataStreamResolver(target_stream_type=dict, expected_keys={'id': int, 'text': str, 'mentions': list})
train_stream = data_stream_resolver.as_data_stream(train_file)
dev_stream = data_stream_resolver.as_data_stream(test_file)
今回はsplitの仕方を自分で制御したかったので上記のコードにしましたが、用意されている関数もあります
import os
from watson_nlp.toolkit.entity_mentions_utils.train_util import prepare_stream_of_train_records_from_JSON_collection
training_data_path = 'training_data'
if not os.path.exists(training_data_path):
os.mkdir(training_data_path)
data_stream = prepare_stream_of_train_records_from_JSON_collection(training_data_path)
train_data_stream, dev_data_stream = data_stream.train_test_split(
test_split=0.1,
seed=123,
)
5. LLMを訓練
まずは訓練に使うシンタックス・モデルと事前学習済みのLLMを読み込みます。
import watson_nlp
syntax_model_ja = watson_nlp.load('syntax_izumo_ja_stock')
syntax_models = [syntax_model_ja]
# 事前学習済みの多言語対応Slateモデルを読み込む
pretrained_model = watson_nlp.load('pretrained-model_slate.153m.distilled_many_transformer_multilingual_uncased')
用意した学習データを使って訓練します。
from watson_nlp.workflows.entity_mentions.transformer import Transformer
entity_model = Transformer.train(train_stream, dev_stream, syntax_models, pretrained_model)
訓練が完了したので、令和3年度のPDFから抜粋した文章で試してみます。
text = """
品目別では、新型コロナウイルス感染症の感染拡大により減少した海外の外食需要が回復したことに加えて、EC販売が好調だったことから、前年に比べ牛肉は85.9%(248億円)増加し537億円、日本酒は66.4%(160億円)増加し402億円となりました。
また、贈答用や家庭内需要が増加したりんごが前年に比べ51.5%(55億円)増加し162億円となりました。
国・地域別では、ホタテ貝や日本酒、ウイスキー等のアルコール飲料の輸出が増加した中国向けのほか、ぶり、牛肉等の輸出増加により米国向けが増加しました。
"""
pred = entity_model.run(text)
pred_terms = set()
for m in pred.mentions:
print(m.span.text)
terms.add(m.span.text)
牛肉
日本酒
りんご
ホタテ貝
日本酒
ウイスキー
牛肉
「ぶり」が抽出できていませんが、概ねよさそうです(ぶりはカタカナのブリにしたら認識していました)。より高精度を求める場合は事前学習モデルの選択や学習データの作成をもっと頑張ったほうがいいかもしれません。
本当にちゃんと学習できているか確かめるために、今回LLMが食料と判定した単語が学習データに出ているか確認してみます。
data_terms = set()
for d in train:
for m in d["mentions"]:
data_terms.add(m["text"])
for d in test:
for m in d["mentions"]:
data_terms.add(m["text"])
pred_terms & data_terms
{'りんご'}
上記の通り、牛肉、日本酒、りんご、ホタテ貝、日本酒、ウイスキーのうち学習データにも出現していた単語は「りんご」のみであり、LLMが学習時に見たことのない単語でも判定できていることがわかります(余談ですが、実際には「牛肉」も学習データにありました。なぜ存在しないことになっているかというと、農林水産省のPDFで一部の漢字が康熙部首に置き換わってしまっているためです。どうも、メイリオフォントで書いたWord文書をAcrobatで変換した時によく起こるらしいです。原因はメイリオが普通の単語と康熙部首を同じ識別番号で扱っているからのようです)。
モデルを保存しておきます。
model_name = "foodstuff_extractor"
wslib.save_data(model_name, entity_model.as_bytes())
6. 遊んでみる
本当はこのブログ記事などのように、訓練したLLMを使ってWatson Discovery上で文書に食料ラベルを追加していろいろ分析してみたいのですが、前述の通りCP4DaaS版ではまだWatson Machine Learningにこのモデルをデプロイできないので、今回はこのままJupyter Notebook上で少し遊んでみます。
SDKをインストールします。
!pip install --upgrade ibm-watson
Watson DiscoveryのAPIを叩くためのクライアントを作ります。API keyはWatson Discoveryのインスタンスのページに載ってます。インスタンスを東京以外に作った場合はURLも適宜変えてください。
from ibm_watson import DiscoveryV2
from ibm_cloud_sdk_core.authenticators import IAMAuthenticator
authenticator = IAMAuthenticator(<api key>)
discovery = DiscoveryV2(
version='2024-01-01',
authenticator=authenticator
)
# https://cloud.ibm.com/apidocs/discovery-data?code=python
discovery.set_service_url('https://api.jp-tok.discovery.watson.cloud.ibm.com')
project IDが必要なのでリストします
discovery.list_projects().get_result()
コレクションのIDも取得します。
project_id = <上記で出てきたproject id>
discovery.list_collections(project_id=project_id).get_result()
まずは令和3年度のコレクションからテキストを全て取得します。検索単語を指定せずクエリすることで全部返ってきます。
query_result = discovery.query(
project_id=project_id,
collection_ids=[<令和3年度のコレクションのID>],
count=100
).get_result()
先ほど学習したモデルを使って食料を判定し、各食料の出現回数をカウントしていきます。
from collections import Counter
terms = Counter()
for r in query_result['results']:
print(r['extracted_metadata'])
text = ''.join(r['text']).replace('\n', '')
pred = entity_model.run(text)
for m in pred.mentions:
terms[m.span.text] += 1
出現回数ベスト30は以下のような結果になりました。
terms.most_common(30)
[('⽶', 213),
('野菜', 110),
('⼤⾖', 93),
('豚', 68),
('⽜', 58),
('茶', 48),
('果実', 44),
('⾁⽤⽜', 36),
('⼦⽜', 33),
('果樹', 32),
('⽶粉', 30),
('⽜⾁', 25),
('豚⾁', 24),
('鶏⾁', 23),
('⽶穀', 23),
('⽜乳', 21),
('花き', 21),
('コメ', 21),
('鶏卵', 20),
('⾁', 20),
('稲', 19),
('乳製品', 17),
('いも', 16),
('⽔稲', 14),
('⾖類', 14),
('鶏', 14),
('ねぎ', 13),
('さとうきび', 12),
('⽣乳', 12),
('パン', 11)]
令和4年度のコレクションで同じことをやった場合がこちらです
[('⽶', 281),
('野菜', 158),
('⼤⾖', 157),
('豚', 116),
('⽶粉', 108),
('果実', 100),
('鶏卵', 71),
('⽜', 68),
('茶', 63),
('⽜⾁', 53),
('鶏⾁', 49),
('⾁⽤⽜', 48),
('稲', 46),
('⽜乳', 43),
('ジビエ', 40),
('豚⾁', 38),
('コメ', 38),
('⾁', 37),
('乳製品', 34),
('⼦⽜', 34),
('いも', 30),
('花き', 28),
('ねぎ', 28),
('⼩', 27),
('⽣乳', 27),
('⽔稲', 27),
('イノシシ', 24),
('でん粉', 24),
('さとうきび', 24),
('パン', 24)]
1位はどちらも圧倒的に米で、日本の農業の中心はやはりお米なんだと再認識します。4位までは同じ単語ですが、令和4年度は5位に「米粉」がランクインしています。
Watson Discoveryで米粉を検索してみたところ、令和4年度のコレクションで 「ロシアによるウクライナ侵略等を背景として、⾷品製造業者等が使⽤している輸⼊⾷品 原材料の価格が⾼騰しています。このため、総合緊急対策の⼀環として、国産⼩⻨・⽶粉 等への原材料の切替え、価格転嫁に⾒合う付加価値の⾼い商品への転換や⽣産⽅法の⾼度化による原材料コストの抑制等の取組を緊急的に⽀援しました」という記述が見つかりました。
それに伴って政策や米粉パンの取り組みの紹介などがあったことで単語数の増加につながったようです。
また、「鶏卵」への言及もかなり増えています。これはみなさんご存知のように鳥インフルエンザによる卵の高騰によるもので、現状や行われた対策の報告が行われていました。
7. LLMの再ロード
5の最後に保存したLLMをまた使いたい場合はここに書いてあるように wslib でダウンロードしてきて解凍すれば使えます。
import zipfile
loaded = wslib.download_file("foodstuff_extractor")
model_folder = 'foodstuff_extractor_folder'
with zipfile.ZipFile(loaded['file_name'], 'r') as zip_ref:
zip_ref.extractall(model_folder)
entity_model = watson_nlp.load(model_folder)
参考文献
- https://medium.com/@daikitsuzuku/accelerating-data-extraction-from-complex-business-document-with-ibm-watsonx-ai-and-watson-discovery-981349c7cfd8
- https://github.com/watson-developer-cloud/doc-tutorial-downloads/tree/master/discovery-data/webhook-enrichment-sample/slate
- https://medium.com/@alex.lang/fair-is-fast-and-fast-is-fair-ibm-slate-foundation-models-for-nlp-3508412a4b04
- https://dataplatform.cloud.ibm.com/docs/content/wsj/analyze-data/watson-nlp-entities-transformer.html?context=wx&audience=wdp
- https://dataplatform.cloud.ibm.com/docs/content/wsj/analyze-data/watson-nlp-block-entity-enhanced.html?context=wx&audience=wdp#machine-learning-general
- https://dataplatform.cloud.ibm.com/docs/content/wsj/analyze-data/watson-nlp-create-model.html?context=wx&audience=wdp
免責事項
掲載内容は私自身の見解であり、必ずしもIBMの立場、戦略、意見を代表するものではありません。