はじめに
v0.11.0の日本語記事が見当たらなかったので、備忘録がてら。
この記事は、__初心者向け__です。
Unity初学者がML-Agentsの公式チュートリアルの1つを模倣して
機械学習の一つ、__強化学習(Reinforcement Learning)をしてみた__というものになります。
こんなのを作ります。![]()
Unityの簡単な動かし方ならわかるけど、機械学習をまだやったことないという人向けです。
理論重視というより、手を動かしながら体験できるようザックリと紹介しています。
*この記事は2019年11月13日時点でのものです。
ML-Agentsはバージョンアップがめまぐるしいので、常に最新の情報を確認してください。
去年出たばかりの教科書が役に立たなかった
(ちなみに今年の推移 ⇒19年1月: v0.6 ➡ 4月: v0.8 ➡ 10月: v0.10 ➡ 11月現在: v0.11)
要点をざっくり
Unityで機械学習を行う際に必要不可欠なワードがあります。
それが__「Academy」、「Brain」、「Agent」の3つ__です。
基本的にUnity内の「Academy」で定義した環境の中で「Brain」が「Agent」の起こすアクションを制御する、といった流れになります。
今回は外部のTensorFlow(Pythonフレームワーク)を介して強化学習を行い、生成されたニューラルネットワークのモデルをUnityで読み込んで実行させる、ということを行います。
(今回は簡易チュートリアルなので、あまりAcademyには触れません。)

バージョン0.10.0からの主な変更点
初めての方は読み飛ばしてOK。
v0.8xやv0.9xを使ってたけどBrain Parameters見つかんなくてよくわかんないんだけど、、っていう人はここだけ見れば大丈夫かも。
- BroadcastHubの廃止。
- Brain ScriptableObjectsの廃止。 ⇒ Behavior Parameters項目に変更
- Visual Observationの大幅なセットアップ変更。
- gRPCの定義刷新。
- オンラインBCトレーニングの廃止。
実行環境
- Windows10
- Unity 2019.1.4f1
- ML-Agents Beta 0.11.0
- Python 3.6(Anaconda)
下準備
まず以下のものをインストールしてください。
-
Unity5(verは2017.4以降であれば問題ないと思います)
-
Anaconda 2019.10 (__PythonのVersionは3.7__を選択してください)
プロジェクト作成
1.Unityを立ち上げRollerBallというプロジェクトをつくります。
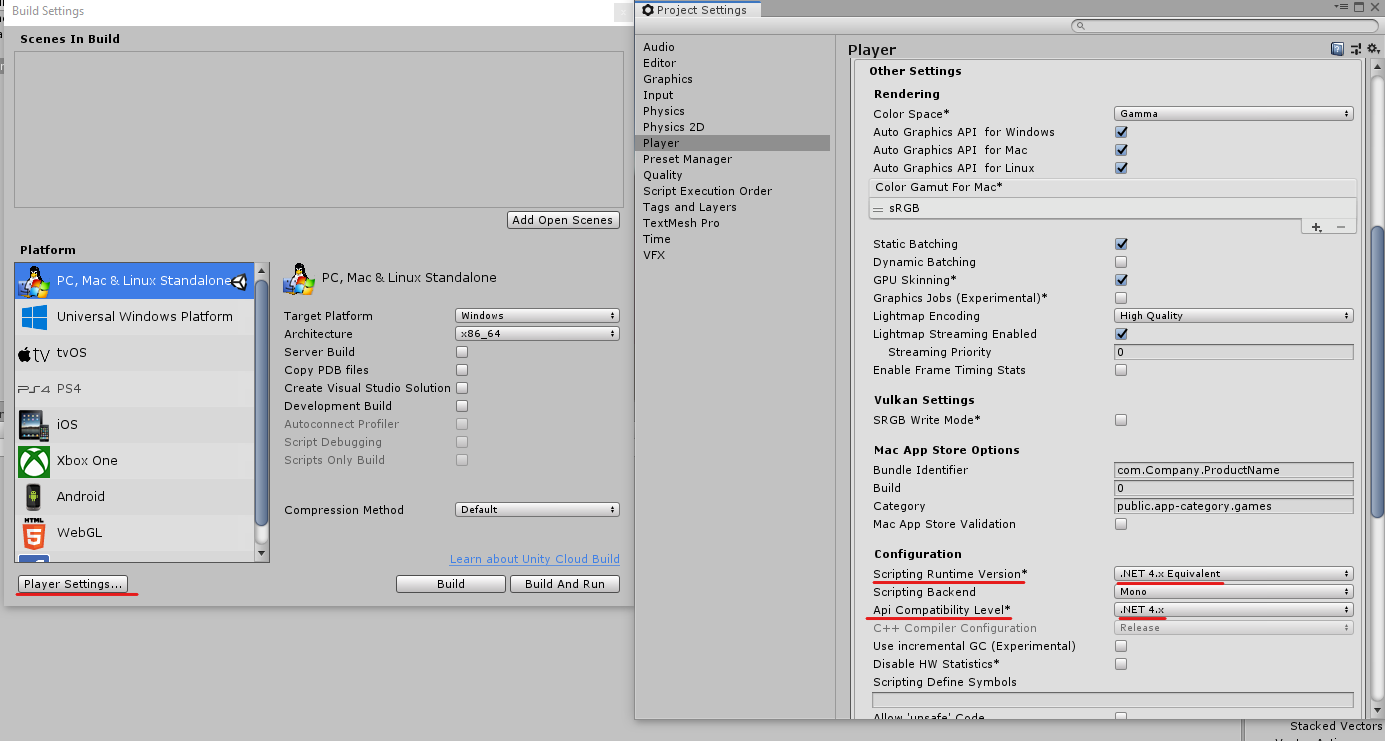
2.File -> Build Settings... -> Player Settings... -> Other Settings -> Configurationにて
*Scripting Runtime VersionとApi Compatibility Levelがそれぞれ、.NET 4.x Equivalentと.NET 4.x*になっていることを確認します。
3.ML-Agentsのアセットをプロジェクトに読み込みます。
ダウンロードしたml-agents-master\UnitySDK\Assets内にある
ML-Agentsフォルダをプロジェクト内にD&Dします。
ステージ作成
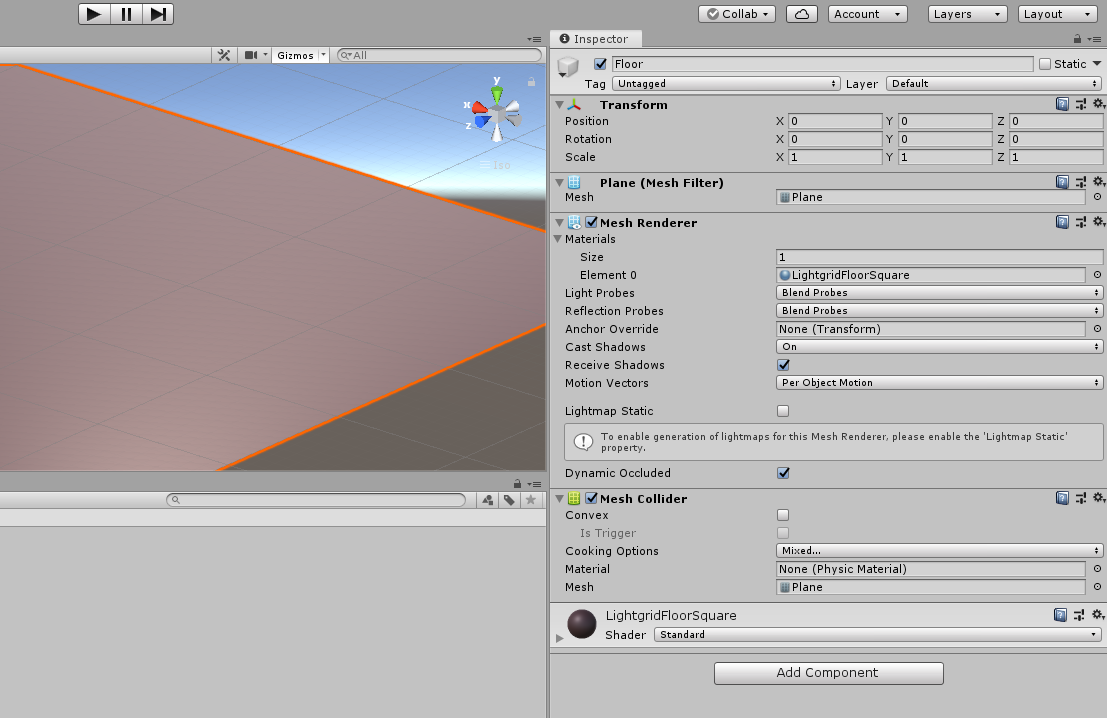
床(Floor)の作成
- 3D Object > Plane で平面を出します。
- 作成したPlane の名前を
Floorにします。 -
FloorのTransformをPosition = (0, 0, 0)Rotation = (0, 0, 0)-
Scale = (1, 1, 1)
にします。
-
Inpector > MaterialsのElementをいじって好きな見た目にします。
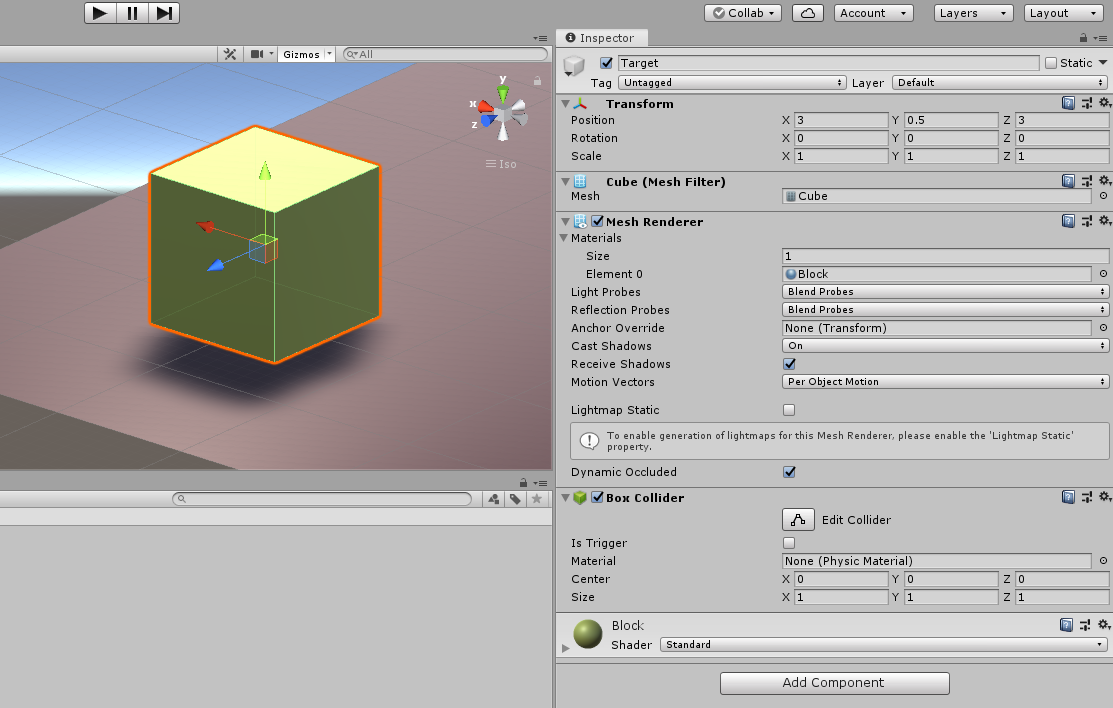
箱(Target)の作成
- 3D Object > Cube で立方体を出します。
- 作成したCube の名前を
Targetにします。 -
TargetのTransformをPosition = (3, 0.5, 3)Rotation = (0, 0, 0)-
Scale = (1, 1, 1)
にします。
-
Floorと同様、見た目をお好みで変更します。
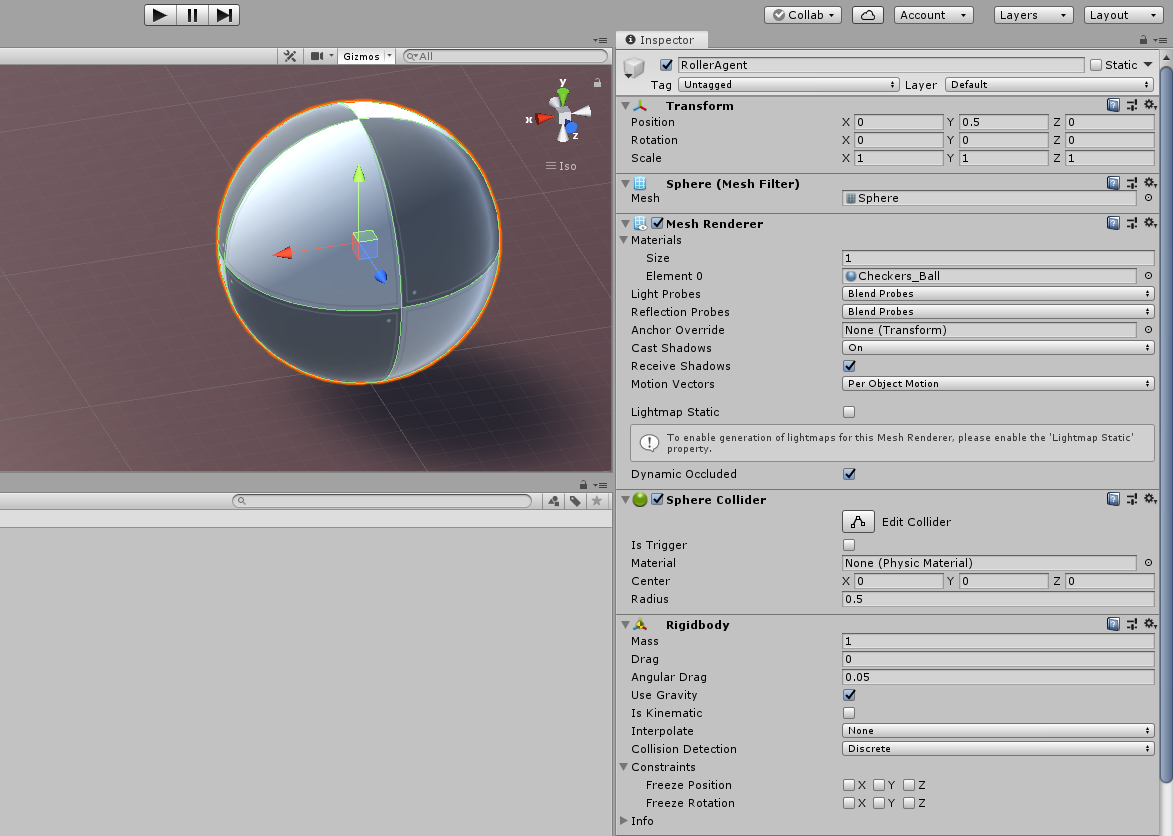
サッカーボール(Agent)の作成
- 3D Object > Sphere で球体を出します。
- 作成したSphere の名前を
RollerAgentにします。 -
RollerAgentのTransformをPosition = (0, 0.5, 0)Rotation = (0, 0, 0)-
Scale = (1, 1, 1)
にします。
- これまでと同様、見た目をお好みで変更します。
ボールっぽくしたいなら、CheckerSquareマテリアルを選択しましょう。 -
Add ComponentよりRigidbodyを追加します。
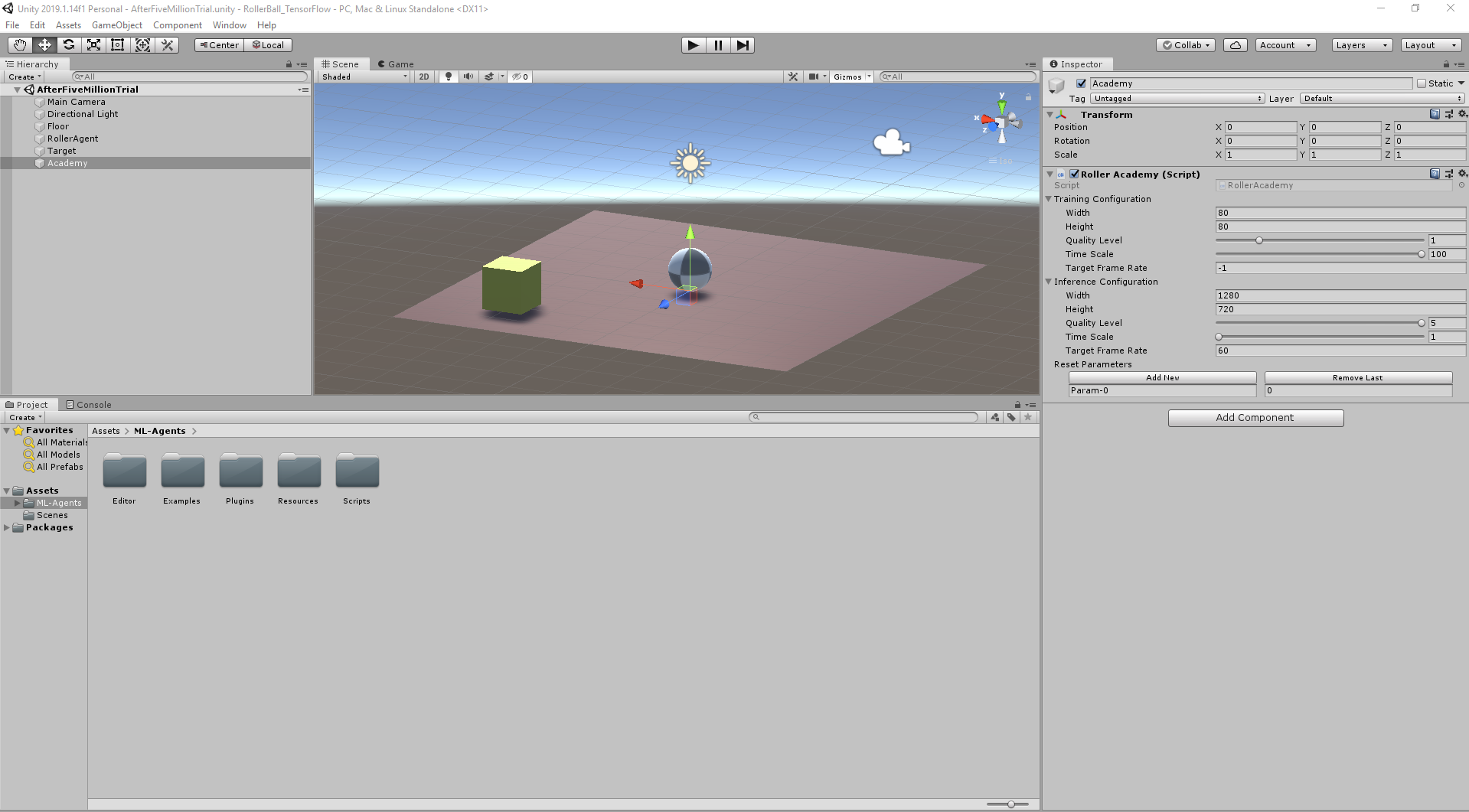
空のオブジェクト(Academy)の作成
- Create Emptyで空のGameObjectを出します。
- 作成したGameObjectの名前を
Academyにします。
さて、お次はC#で内容を記述していきます。
Academyの実装(Implement an Academy)
-
Hierarchyウィンドウで
Academyを選択したままAdd Component -> New ScriptでRollerAcademy.csという名のスクリプトを作成します。 -
RollerAcademy.csの内容を以下に書き換えます。元の内容は消してしまって構いません。
using MLAgents;
public class RollerAcademy : Academy{ }
この記述では、
「観測-意思決定-行動」などの基本的な機能(ここでは割愛)をAcademyクラスからRollerAcademyクラスに継承しています。
なので、2行でオッケーです。
Agentの実装(Implement an Agent)
HierarchyウィンドウでRollerAgentを選択し、
Add Component -> New ScriptでRollerAgent.csという名のスクリプトを作成します。
ベースの継承(Inheritance the Base)
RollerAgent.csの内容を以下に書き換えます。
using MLAgents;
public class RollerAgent : Agent{ }
Academyと同じように名前空間MLAgentsを読み込んで、ベースクラスにAgentを指定して継承させています。
ここまでが、__UnityにML-agentsを組み込む基礎的な手順__です。
次は、強化学習によるボールが箱に向かって突撃していく仕組みを追加します。
初期化とリセット(Initialization and Resetting)
RollerAgent.csの内容を以下に書き換えます。
using unityEngine;
using MLAgents;
public class RollerAgent:Agent
{
Rigidbody rBody;
void Start(){
rBody = GetComponent<Rigidbody>();
}
public Transform Target;
public override void AgentReset()
{
if (this.transform.position.y < 0)
{
//回転加速度と加速度のリセット
this.rBody.angularVelocity = Vector3.zero;
this.rBody.velocity = Vector3.zero;
//エージェントを初期位置に戻す
this.transform.position = new Vector3( 0, 0.5f, 0)
}
//ターゲット再配置
Target.position = new Vector3(Random.value * 8 - 4, 0.5f,
Random.value * 8 - 4);
}
}
ここでは、
-
RollerAgentが箱(Target)に到達したときに行う、次への__再配置と初期化__ -
RollerAgentが床(Floor)から落ちた時の__復帰__
の処理を行っています。
RigidbodyはUnityの物理シミュレーションでつかうコンポーネントですね。
今回はエージェントを動かす為に使用します。
TransformにはPosition,Rotation,Scaleの値が記録されます。
publicに定義することで、InpectorでTargetのTransformを渡せるようになります。
環境の観測(Observing the Environment)
RollerAgent.csのクラス内に以下を追加します。
public override void CollectObservations()
{
// ターゲットとエージェントの位置
AddVectorObs(Target.position);
AddvectorObs(This.transform.position);
//エージェントの速度
AddVectorObs(rBody.velocity.x);
AddVectorObs(rBody.velocity.z);
}
ここでは、
観測したデータを特徴ベクトルとして集める処理
を行っています。
TargetとAgentそれぞれの3次元座標と、Agentの速度x、zの合計8次元のベクトルをニューラルネットワークに渡していきます。8次元って表現かっくいいよね
行動と報酬(Actions and Rewards)
RollerAgent.csに以下のAgentAction()関数にまつわる処理を、追加します。
public float speed = 10
public override void AgentAction(float[] vectorAction, string textAction)
{
//行動
Vector3 controlSignal = Vector3.zero;
controlSignal.x = vectorAction[0];
controlSignal.z = vectorAction[1];
rBody.AddForce(controlSignal * speed);
//報酬
//ボール(エージェント)が動いた距離から箱(ターゲット)への距離を取得
float distanceToTarget = Vector3.Distance(this.transform.position,
Target.position);
//箱(ターゲット)に到達した場合
if (distanceToTarget < 1.42f)
{
//報酬を与え完了
SetReward(1.0f);
Done();
}
//床から落ちた場合
if (this.transform.position.y < 0)
{
Done();
}
}
ここでは、
X方向、Z方向に加える2種類の力(連続値)を読み取って、エージェントを動かしてみるという「行動」と
エージェントが無事、箱に到達できたら「報酬」を与え、落ちたら「報酬」を取り上げるという学習アルゴリズムの処理 をしています。
AddForce関数はRigidbodyコンポーネントを持つオブジェクトに物理的な力を加え、移動させる為の関数です。
ターゲットに到達したかを判断する基準値以下の距離が算出された場合のみ、報酬を与えリセットさせます。
より複雑なシチュエーションで十分な学習を得るには、報酬を取り上げるだけでなく罰を与える記述も効果的です。(v0,5x時は床から落ちた場合に-1されていたが、最新版では必要ないと判断されたらしい)
まとめると、RollerAgents.csは以下のようになります。
using unityEngine;
using MLAgents;
public class RollerAgent:Agent
{
Rigidbody rBody;
void Start(){
rBody = GetComponent<Rigidbody>();
}
public Transform Target;
public override void AgentReset()
{
if (this.transform.position.y < 0)
{
//回転加速度と加速度のリセット
this.rBody.angularVelocity = Vector3.zero;
this.rBody.velocity = Vector3.zero;
//エージェントを初期位置に戻す
this.transform.position = new Vector3( 0, 0.5f, 0)
}
//ターゲット再配置
Target.position = new Vector3(Random.value * 8 - 4, 0.5f,
Random.value * 8 - 4);
}
public override void CollectObservations()
{
// ターゲットとエージェントの位置
AddVectorObs(Target.position);
AddvectorObs(This.transform.position);
//エージェントの速度
AddVectorObs(rBody.velocity.x);
AddVectorObs(rBody.velocity.z);
}
public override void AgentAction(float[] vectorAction, string textAction)
{
//行動
Vector3 controlSignal = Vector3.zero;
controlSignal.x = vectorAction[0];
controlSignal.z = vectorAction[1];
rBody.AddForce(controlSignal * speed);
//報酬
//ボール(エージェント)が動いた距離から箱(ターゲット)への距離を取得
float distanceToTarget = Vector3.Distance(this.transform.position,
Target.position);
//箱(ターゲット)に到達した場合
if (distanceToTarget < 1.42f)
{
//報酬を与え完了
SetReward(1.0f);
Done();
}
//床から落ちた場合
if (this.transform.position.y < 0)
{
Done();
}
}
}
Unityエディタ上で仕上げ
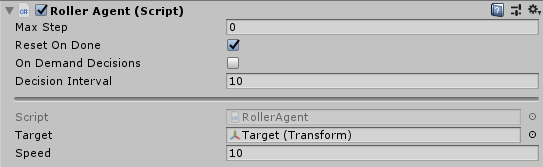
-
Hierarchy ウィンドウで
RollerAgentを選択し、RollerAgent(Script)の項目を2点変更します。
Decision Interval = 10
Target = Target(Transform)
-
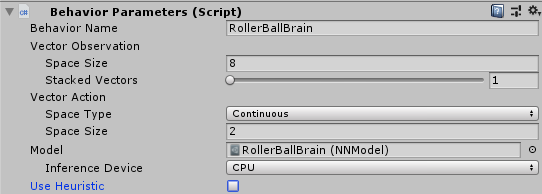
Add Component > Behavior Parameters を追加して、以下のように設定を変更します。
Behavior Name = RollerBallBrain
Vector Observation Space Size = 8
Vector Action Space Type = Continuous
Vector Action Space Size = 2
また、公式ドキュメントによると、このままデフォルトのパラメータを使用すると30万ステップも学習を行い、時間がかかってしまうようです。
今回はそれほど複雑な学習ではないので、パラメータの一部を書き換えて試行回数を2万ステップ未満まで減らしましょう。
-
ml-agents-master-0.11 > config > にある
trainer_config.yamlをエディタ(VS codeやメモ帳)で開き、以下の項目の値を書き換えます。
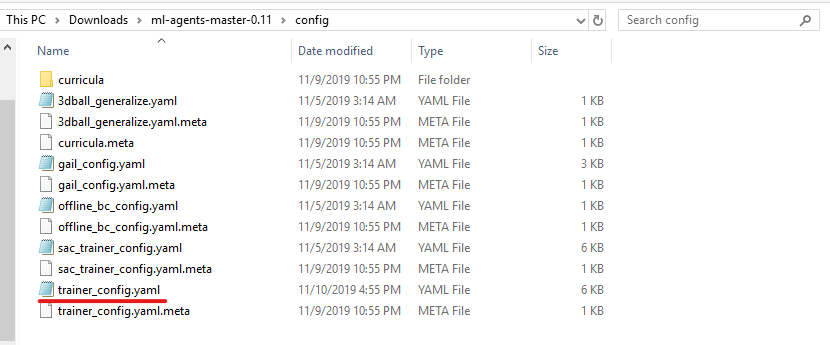
batch_size: 10
buffer_size: 100
これで、トレーニングをする準備ができました。
手動テスト
ここまできたらあと少しです。
強化学習の前に、今までつくった環境がちゃんと動作するか人の手で確認してみましょう。
RollerAgent.csのクラスに、以下のメソッドを追加で実装します。
public override float[] Heuristic()
{
var action = new float[2];
action[0] = Input.GetAxis("Horizontal");
action[1] = Input.GetAxis("Vertical");
return action;
}
Hotizontalで水平(横)の入力軸、
Verticalで垂直(縦)の入力軸を受け付けるようにします。
これで「W」「A」「S」「D」または矢印キーによる操作が可能になりました。
最後にRollerAgentのInspectorにある、
Behavior ParametersのUse Heuristicのチェックボックスをオンにします。
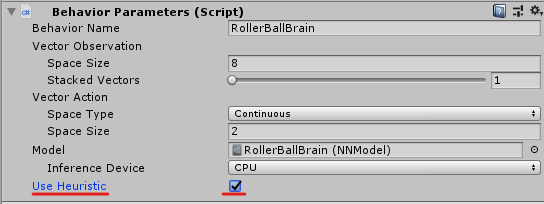
Playを押して、実行してみましょう。
キー入力で動くことが確認できたら、成功です。
TensorFlowで学習させる
では、いよいよ学習のステップに入っていきます。
環境構築・ライブラリのインストール
まずAnaconda Promptを立ち上げます。
スタートメニュー(Winキー)から検索をかけるとすぐ出ます。
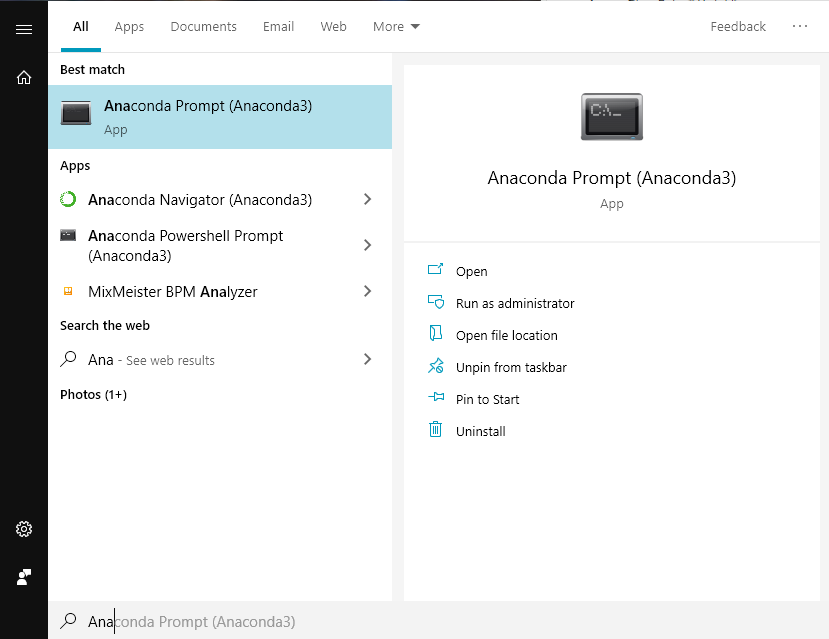
conda create -n ml-agents python=3.6
と入力して、仮想環境を構築します。1
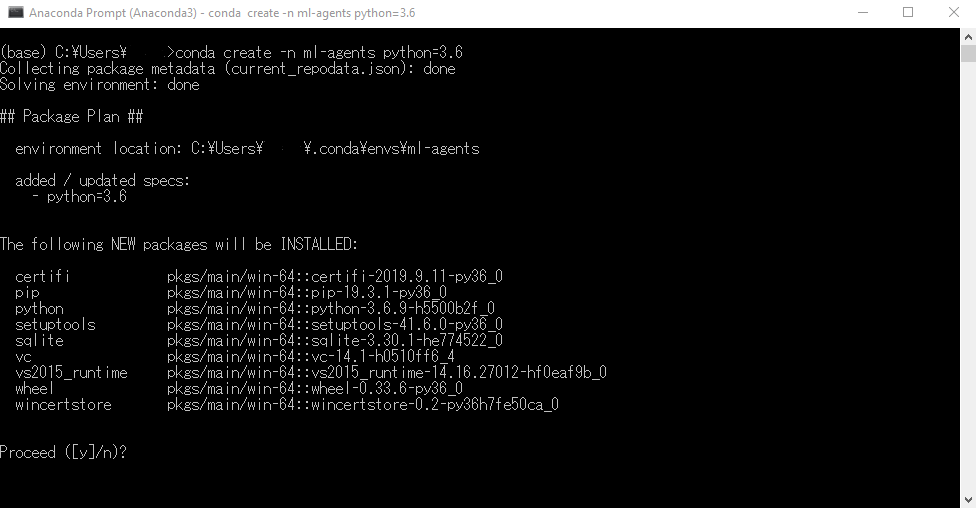
Proceed([y]/n)?
インストールするか、と聞かれるのでyを入力。続いて、
activate ml-agents
と入力して仮想環境に移ります。2
コマンドラインの先頭に(ml-agents)と付いたのを確認してください。
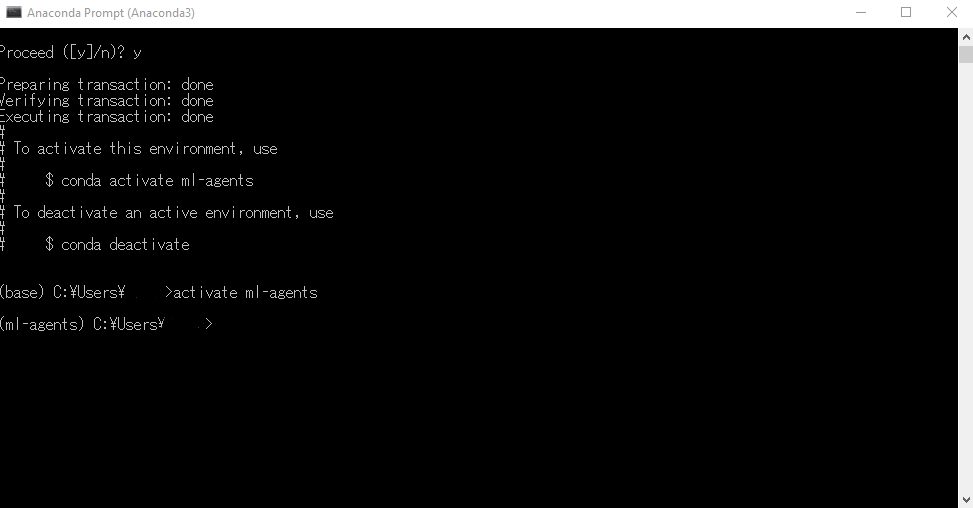
cd <ml-agentフォルダ>
に移動します。3
pip install mlagents
でML-Agentsが独自に使うライブラリのインストールを行います。(2,3分かかります)
このインストールで、TensorFlow/Jupyterなどの依存関係が行われます。
少し時間がたって、
こんな感じの画面が出ればOKです。
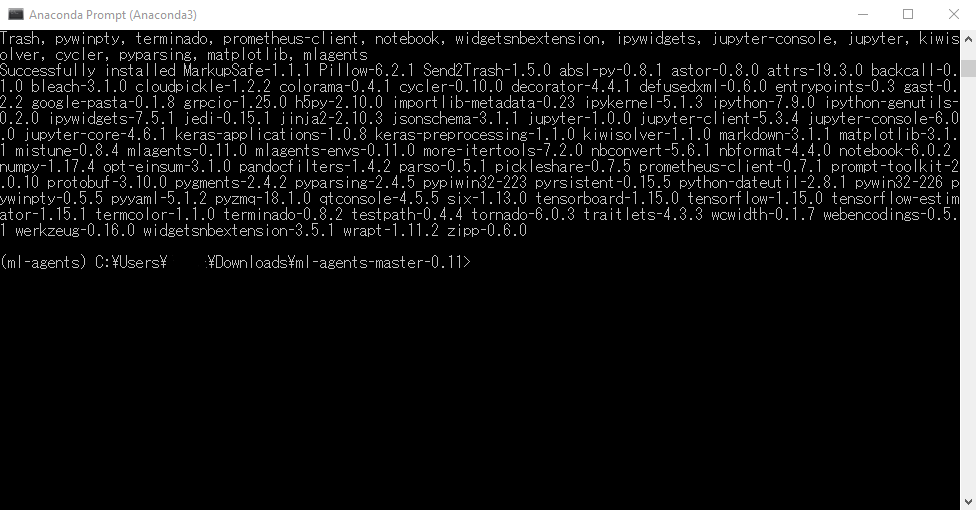
cd <ml-agentsフォルダ>\ml-agents-envs
に移動します。
pip install -e .
と入力して、パッケージをインストールします。
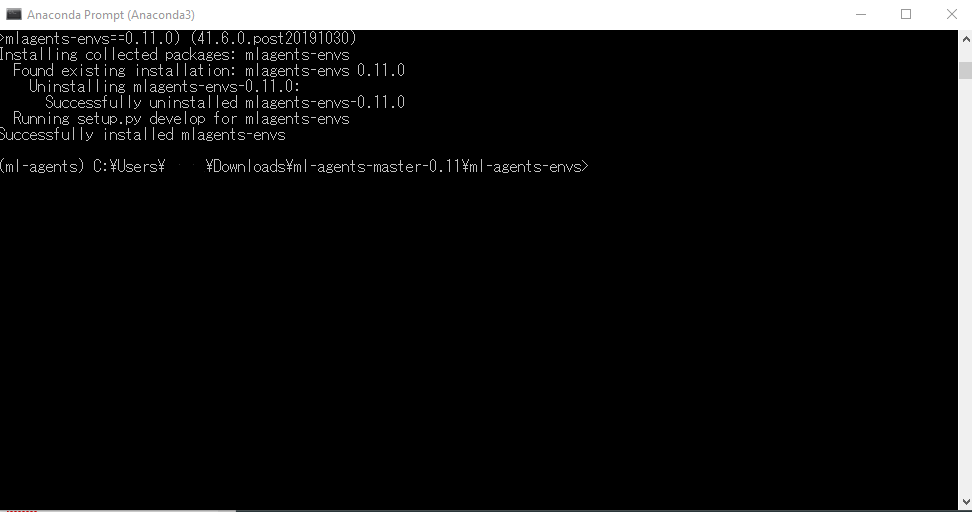
こんな画面になればOKです。
そして、
cd <ml-agentsフォルダ>\ml-agents
に移動します。
pip install -e .
と入力して、パッケージをインストールします。
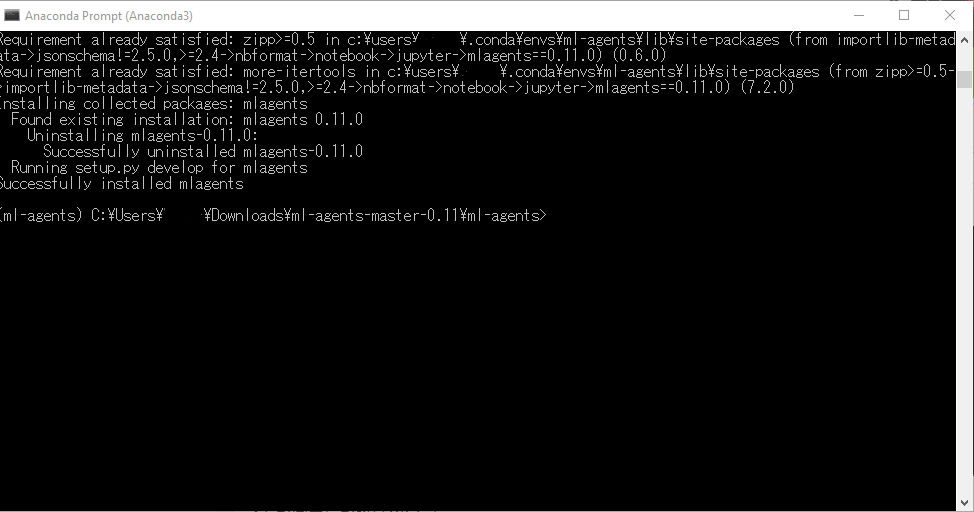
これでPython側の準備も完成です。
__![]() 【注意】:TensorFlowSharpプラグインは、v0.6.x以降では使われていません。__古い書籍などを参考に進めていた方は、新たに仮想環境を作り直すことをオススメします。
【注意】:TensorFlowSharpプラグインは、v0.6.x以降では使われていません。__古い書籍などを参考に進めていた方は、新たに仮想環境を作り直すことをオススメします。
ML-Agents ver0.5.0 までは TensorFlowSharp を使って Pythonと通信していましたが、最新版では使わないようにしてください。もし使うと以下のようなエラーが発生したりします。
No model was present for the Brain 3DBallLearning.
UnityEngine.Debug:LogError(Object)
MLAgents.LearningBrain:DecideAction() (at Assets/ML-Agents/Scripts/LearningBrain.cs:191)
MLAgents.Brain:BrainDecideAction() (at Assets/ML-Agents/Scripts/Brain.cs:80)
MLAgents.Academy:EnvironmentStep() (at Assets/ML-Agents/Scripts/Academy.cs:601)
MLAgents.Academy:FixedUpdate() (at Assets/ML-Agents/Scripts/Academy.cs:627)
強化学習(Reinforcement Learning)
さて、いよいよ学習に入っていきます。夢のAI体験まであと少しです。頑張りましょう。
cd <ml-agents>フォルダ
と入力して、ダウンロードしたフォルダ階層へ移ります。
mlagents-learn config/trainer_config.yaml --run-id=firstRun --train
を実行します。4
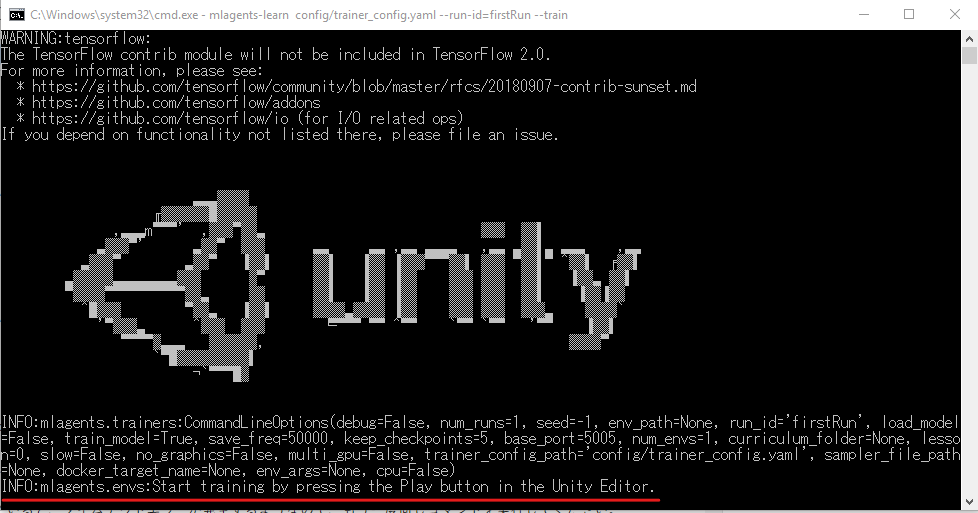
コマンドラインの最下部に、
INFO:mlagents.envs:Start training by pressing the Play button in the Unity Editor.
(Unityエディタに戻ってPlayボタンを押して、トレーニングを開始してください。)
と表示されたのを確認します。
Unityの画面に戻って、Behavior ParametersのUse Heuristic のチェックを外し、![]() ボタンを押してみましょう。
ボタンを押してみましょう。
ボールが箱を追いかけ始めたら、正常に学習が開始されました。
しばらくPlayボタンを押さないでいると、タイムアウトエラーが発生するようなので、もう一度同じコマンドを実行してください。
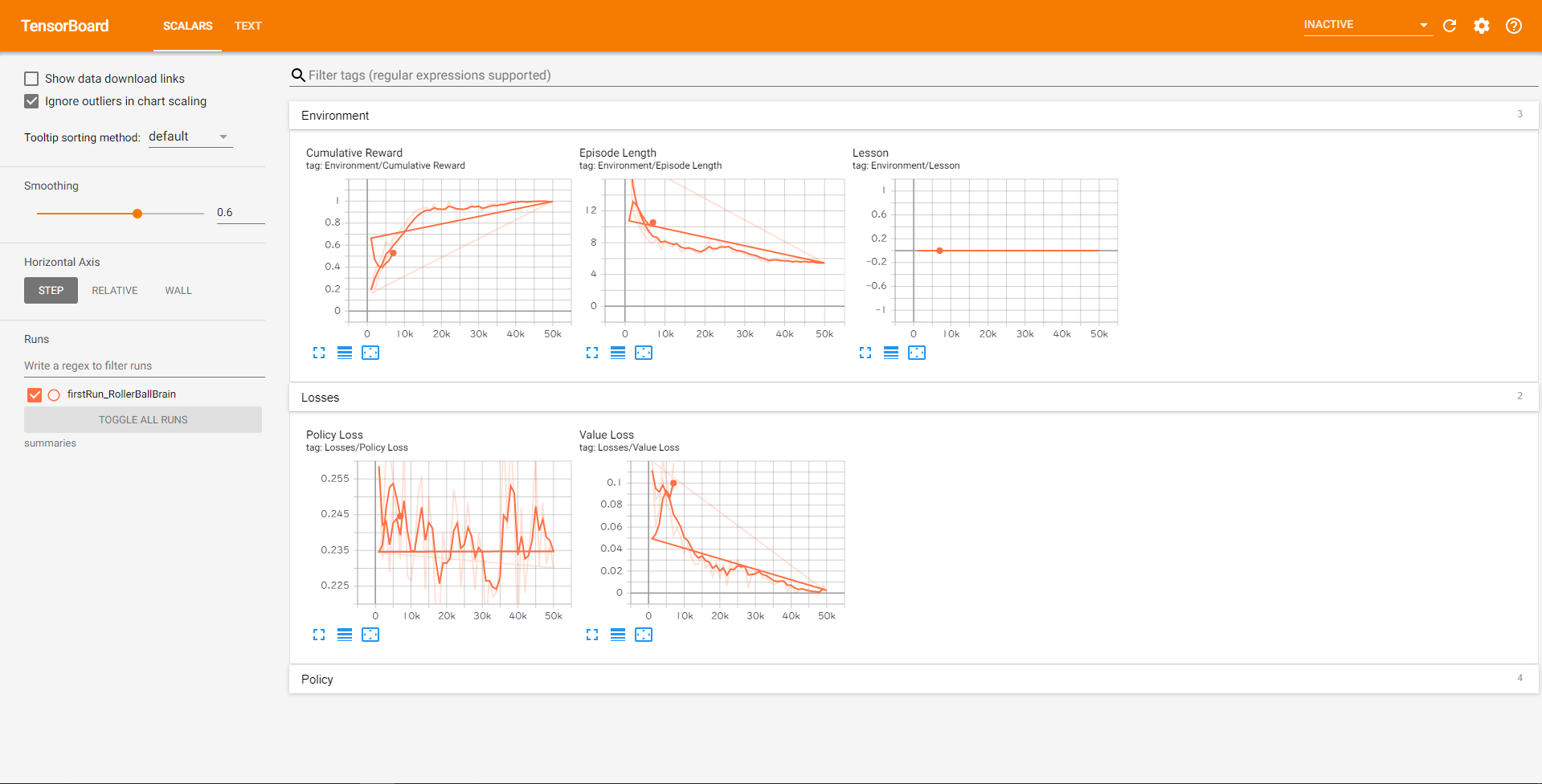
コンソールのログには1000step毎にログが出力されていきます。
途中で中断したい方はCtrl+Cで中断できます。(敢えて早期に終えることで、『弱いAI』が作れたりします)
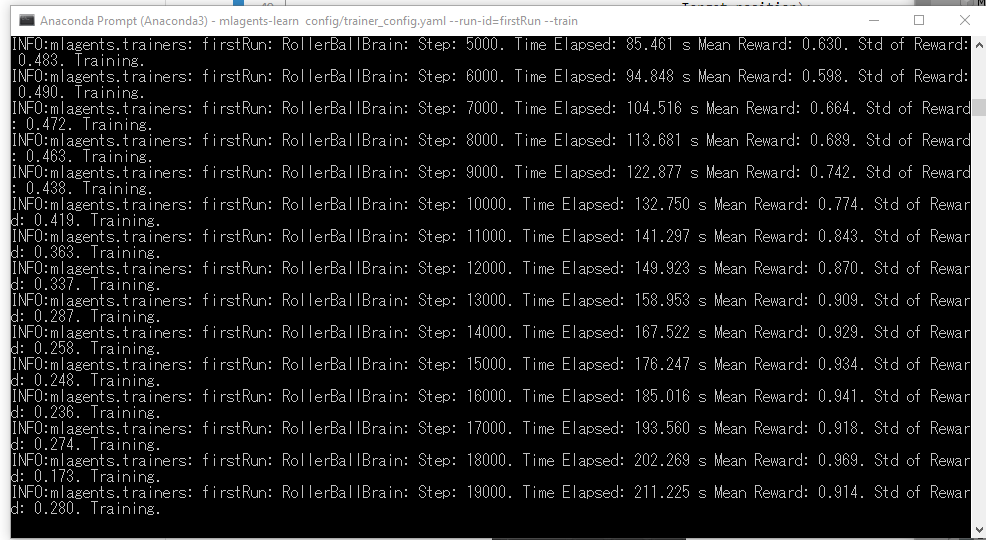
Stepが試行(学習)回数、
Mean Rewardが獲得した報酬の平均値、
Std of Rewardが標準偏差(データのばらつきを表す値)
を表します。
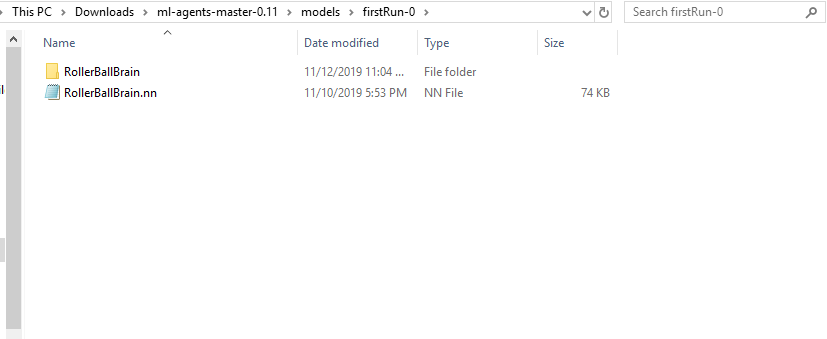
学習を終えると<ml-agentsフォルダ>\models\<id名~>の下に、RollerBallBrain.nnファイルが生成されています。
学習反映
さあ、いよいよ生成されたニューラルネットワークのモデルを試す時がやってまいりました。
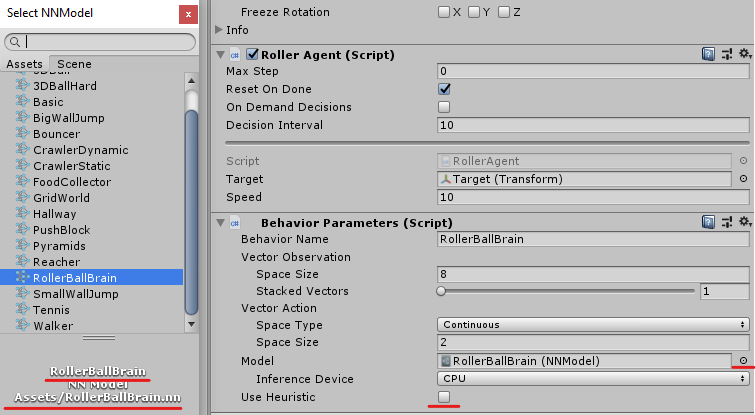
先程のRollerBallBrain.nnファイルを、UnityのProject内にあるAssetsフォルダにcopyします。
(場所はプロジェクト内であればどこでも構いません)
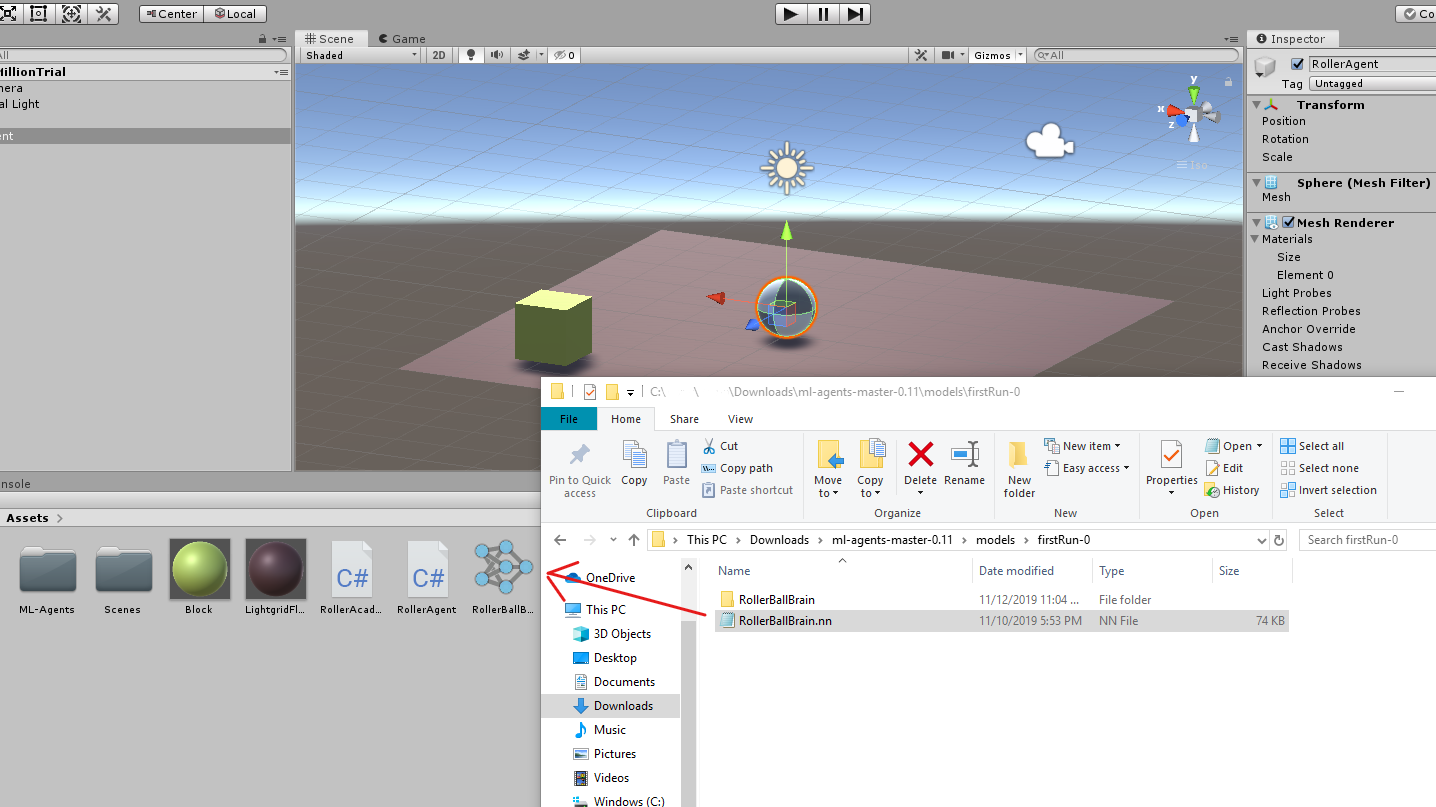
そして、RollerAgentのInspectorにあるModel 項目の右端の![]() ボタンをクリックして取り込んだ
ボタンをクリックして取り込んだ.nnファイルを選択しましょう。(*この時、同じ名前の.nn拡張子ファイルがある場合は混同しないように注意してください。)
また、Behavior ParametersのUse Heuristic にチェックが入ったままだと、うまく動きません。
テストが終わったら必ずチェックは外すようにしましょう。
それでは、![]() Playを押してみましょう。
Playを押してみましょう。
無事ボールが追い回し始めたら、成功です。

(おまけ)TensorBoardで推移グラフを観察
Anaconda Promptで、以下を実行します。
tensorboard --logdir=summaries --port=6006
ブラウザでlocalhost:6006を開くと、__学習の推移をグラフで見る__ことができます。
まとめ
- もっとゴリゴリC#を読めるようになると、自分でアルゴリズムを微調整できそう
- 強化学習では、学習回数で__AIの賢さを弱・中・強などに分類できる__
- Verの刷新が頻繁にあって、情報が劣化しやすい
やっぱ人間より学習が遥かに速い。科学の力ってすげ―!!
初心者でもアセットを使えば、シンプルな機械学習であれば1日で模倣できる便利な世の中になりました。
実際に触ってみて、如何だったでしょうか。
機械学習に興味を持っていただくキッカケになってくれると嬉しいです。
何か気になる表現や誤表記など見受けられましたら、ご指摘頂けると幸いです。
また、この記事参考になったという方は__いいね!くれると__励みになります。
以上、ありがとうございました。
参考
以下、非常に学習の手助けになった先人の方々の記事です。この場を借りて、__謝辞__を述べさせていただきます。
Unity-Technologies公式ドキュメント(GitHub)
ml-agents移行ガイド(GitHub)
Unity:ML-Agents 2019年09月(ver0.9.0 /0.9.1/0.9.2)での使い方
【Unity】強化学習のチュートリアルをやってみた(ML-Agents v0.8.1)
UnityのML-Agentsで、新しい学習環境を作成する(0.6.0a版)