今回は統計手法の TF-IDF を使って、重要な単語や文章を浮き上がらせてみたいと思います。
どんな場面で使えるのか? 例えば「検索結果を重要度の高いものから表示したい」とか、「大量のアラートログの中で重要と思われるものを表示したい。」とか、「自然言語処理を行う前処理として分散表現させたい。」などで活用の幅は広いと思います。
TF-IDF とは?
TF-IDF (Term Frequency - Inverse Document Frequency) とは、単語に重み付けをして、数値としてそれを表す統計的手法です。どのように重み付けをしているかというと、2つの情報を元に算出してます。
・ TF (Term Frequency) : 単語の出現頻度
・ IDF (Inverse Document FrequencY) : 単語の逆文書頻度
TFは単純に文章にどれだけの頻度で単語が出現しているかを表す指標で、例えば合計100単語の中に 15回出現したら
TF = 15/100 = 0.15 になります。
IDFは、単語が含まれる文が文章全体にどれだけ出現していないか。つまり珍しさを表す指標で、全体の文数を対象の単語を含む文数で割り、対数をとったもの。例えば 1000文からなる文章のうち、ある単語を含む文が 100文あったら以下のようになります。(最後に1を足す手法もあります)
IDF = \log (1000/100) = \log (10^1)=1
TF-IDFは、TFとIDFを掛け合わせるので、以下のようになります。
TF*IDF = 0.15 * 1 = 0.15
こうして、単純な単語のカウント数だけでなく、そのレア度(貴重さ)も含めることで、しょっちゅう出てくる単語(例えば、"私"とか、"the" ,"a" など)を省いて、意味のある単語を多く含む文章に高いスコアがつくようになります。
Splunkで TF-IDFアルゴリズムを使うには?
Splunkでは、MLTK (Machine Learning Tool Kit) アプリの中に、TF-IDFアルゴリズムが含まれており、すぐに使うことが可能です。
以下の2つのアプリを追加します。
Machine Learning Tool Kit
https://splunkbase.splunk.com/app/2890/
Python for Scientific Computing (for Linux 64-bit)
https://splunkbase.splunk.com/app/2882/
(*) Windows / Mac 版もあります。
導入方法はこちらの記事を参考にしてください。
インストールが完了したら、SPLコマンドで実行できます。
|fit TFIDF <field>
分析したい文章が含まれる Fieldを引数に指定するだけです。
結果は、"<field>_tfidf_<number>_<word>" のようなフィールドが出現し、そのスコアが表示されます。

slackメッセージを使って、重要なメッセージを浮き上がらせてみる
それでは、実際にTF-IDFを使って分析してみたいと思います。slack メッセージを Splunkに取り込んで、重要なメッセージを上位に並ばせたいと思います。(ただし、今回取り込んだ slackメッセージは、以前 slack上で SPLコマンドを実行する記事を書いた時に利用したログなので、サンプルログとしてはあまりよくないのですが・・・)
ちなみに、slack メッセージのsplunkへの取り込み方はこちらの記事を参照ください。
source=slack*
|fit TFIDF text
|table text text_tfidf*
|addtotals
|fields - text_tfidf*
|sort - Total
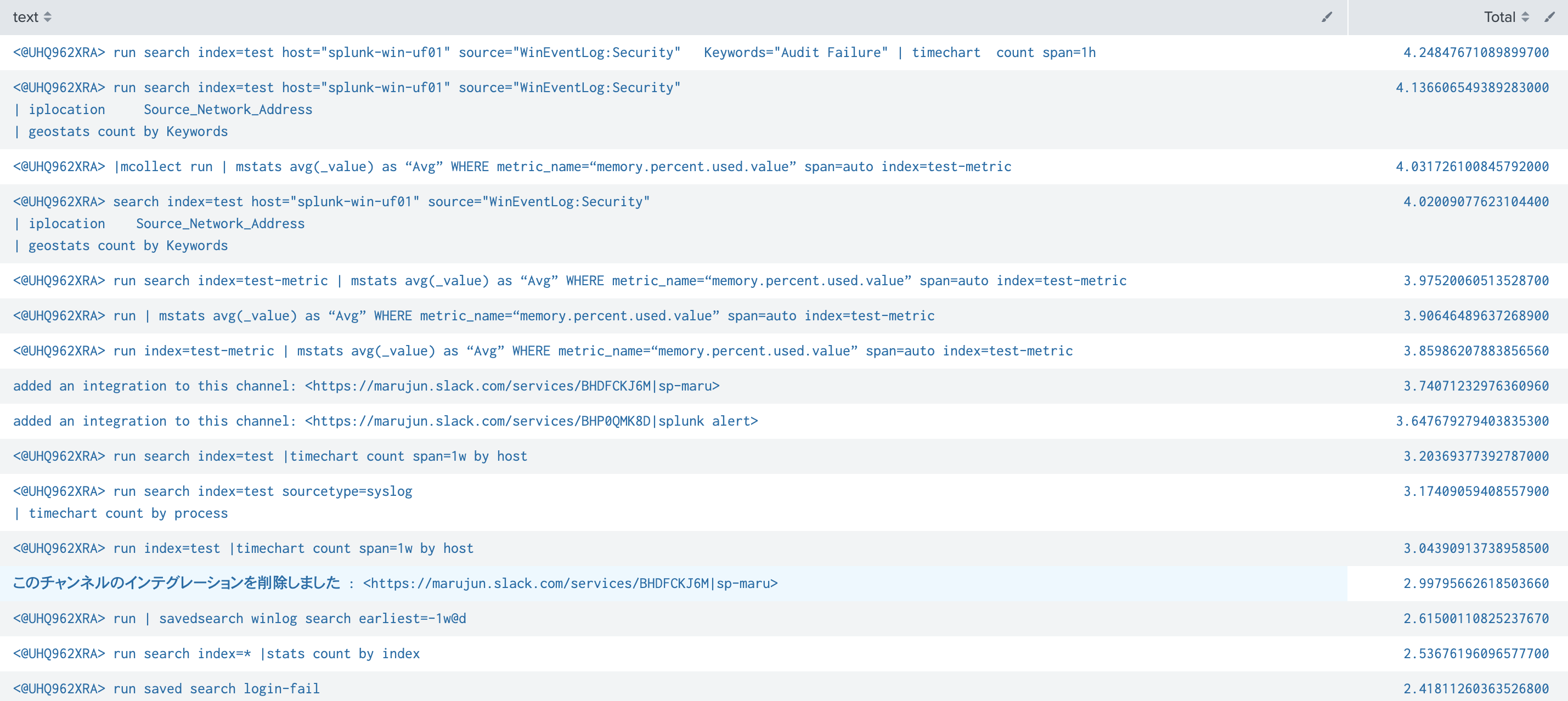
slackのメッセージが text フィールドに取り込まれているので、それを TF-IDFにかけます。すると単語ごとに数値化されるので、その合計値が高いコメントが上位にあがるようにしてあります。
逆に、スコアが低いメッセージをみてみますと、
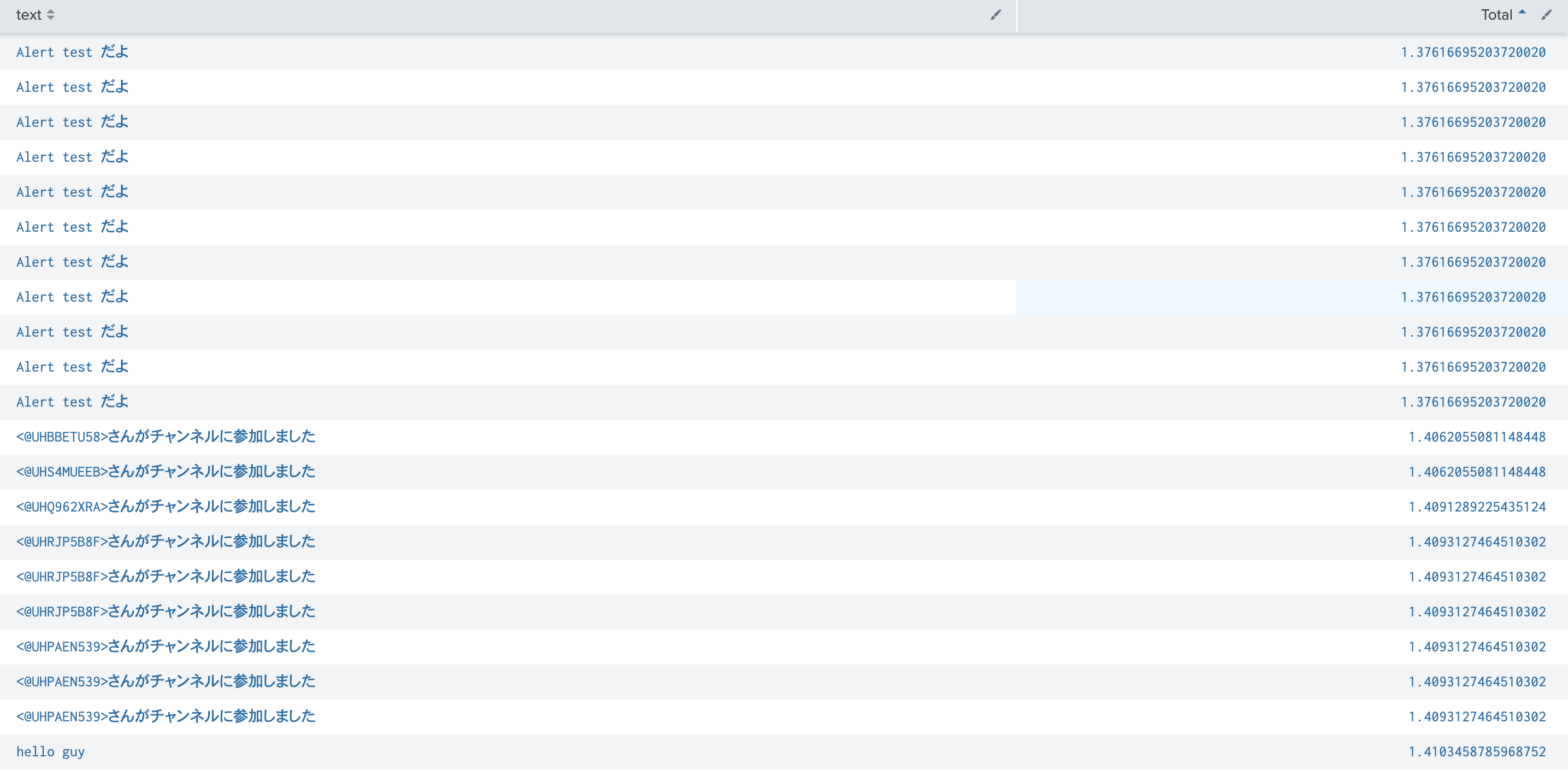
このように単純なメッセージや、出現回数の多いだけのものは低いスコアになってます。
これらのワードを検索フィルターで外そうとすると大変ですが、TF-IDFを使うと簡単に除外することができます。
単語における、count ベースの結果との比較
前回、MeCabを使った形態素解析と出現回数による分析をしましたが、TF-IDFで分析した場合、どのような単語が重要と判断されているかを比べてみましょう。
source=slack*
| fit TFIDF text
| fields text_*
| eventstats max(text_*)
| table max*
| transpose
| rex field=column "_\d+_(?P<word>.+)\)"
| table word "row 1"
| sort - "row 1"

Hello とか、luna とかが上位に来てます。
前回のカウントベースの結果はこちらです。

test とか、Alert とかが上位に来てます。当然ですが全然違う結果になってます。
まとめ
ログメッセージというのは、大量に出る分、何が重要なメッセージか見極めるのが大変です。TF-IDFの仕組みはそんな大量のメッセージに埋もれてしまったものを浮き上がらせてくれる手法なので、取り入れてみると面白い結果がみれるかもしれませんね。