Splunkにあるデータを有効利用しよう
Splunkといえばデータを検索・分析・可視化するソフトウェアとして有名ですね。
IT運用管理、セキュリティ・コンプライアンス、DevOps、ビジネス分析からIoTまで、様々な使い方に応用できます。
普段吐き捨てているようなログも、Splunkにかければ問題をいち早く見つけて障害を予防したり、今までトラブルシューティングではgrepに頼っていたのが、Splunkを活用することで問題解決時間を90%短縮したという事例もあります。
さて、今回は「分析」について少しだけもう少し踏み込んでみたいと思います。
Splunkに取り込んだデータを機械学習にかけて、様々な要因から潜在的な問題を見つけよう、異常を検知しようというものになります。
それを実現するのが Machine Learning Toolkit というAppです。
そもそもAppってナニ?
少し話がそれますが、Splunkには様々なオンラインコミュニティがあります。
Splunk Answers、ブログ、ドキュメンテーション 等々ありますが、詳細はまた別の機会に。
これらコミュニティの中でも、1,000種類以上ものAppやAdd-onが提供されている Splunkbase というプラットフォームがあります。
App StoreとかGoogle Playのようなもので、こちらに公開されているAppをSplunk環境にインストールすることで、ダッシュボードをイチから構築することなくすぐに使えたり、ベンダーごとにフォーマットが異なるログをカンタンに取り込むことができます。
そういったPrebuiltのダッシュボードや設定ファイル、スクリプト等が入っているのがAppです。
ほとんどのAppは無償で提供されていて、課金なしで使うことができます。(例外もあります)
Machine Learning Toolkit (aka MLTK)
その中でも人気なAppが Machine Learning Toolkit と呼ばれるもので、これを使うことでSplunkで検索したデータから機械学習をシームレスに使うことができる、というものです。
略してMLTKです。
無償です。
つまり、MLTKはタダで使えます。
インストール
まずは Splunkbase から Machine Learning Toolkit をお手元のSplunk環境にインストールします。

他に、Python for Scientific Computing (for XXXX) をインストールします。これはOSごとに異なるので、SplunkがインストールされているOSに合わせて選びましょう。

- Linux 64bit -> https://splunkbase.splunk.com/app/2882/
- Linux 32bit -> https://splunkbase.splunk.com/app/2884/
- Windows 64bit -> https://splunkbase.splunk.com/app/2883/
- Mac -> https://splunkbase.splunk.com/app/2881/
この中にはscikit-learnやpandas、SciPyといったPythonライブラリが入っています。
あとはSplunkを再起動すれば完了です。
使ってみよう
Splunk環境
今回の環境は↓です。バージョンによっては見え方やコマンドに多少の違いがありますので、ご了承ください。
Splunk Enterprise 6.5.2
Machine Learning Toolkit 2.1.0
MLTK Appの中身
Splunkにログインすると、Launcher画面の左側にMachine Learning Toolkitのアイコンができています。

↑こんなのです。
ここにアクセスすると、ショウケースがいくつか表示されます。
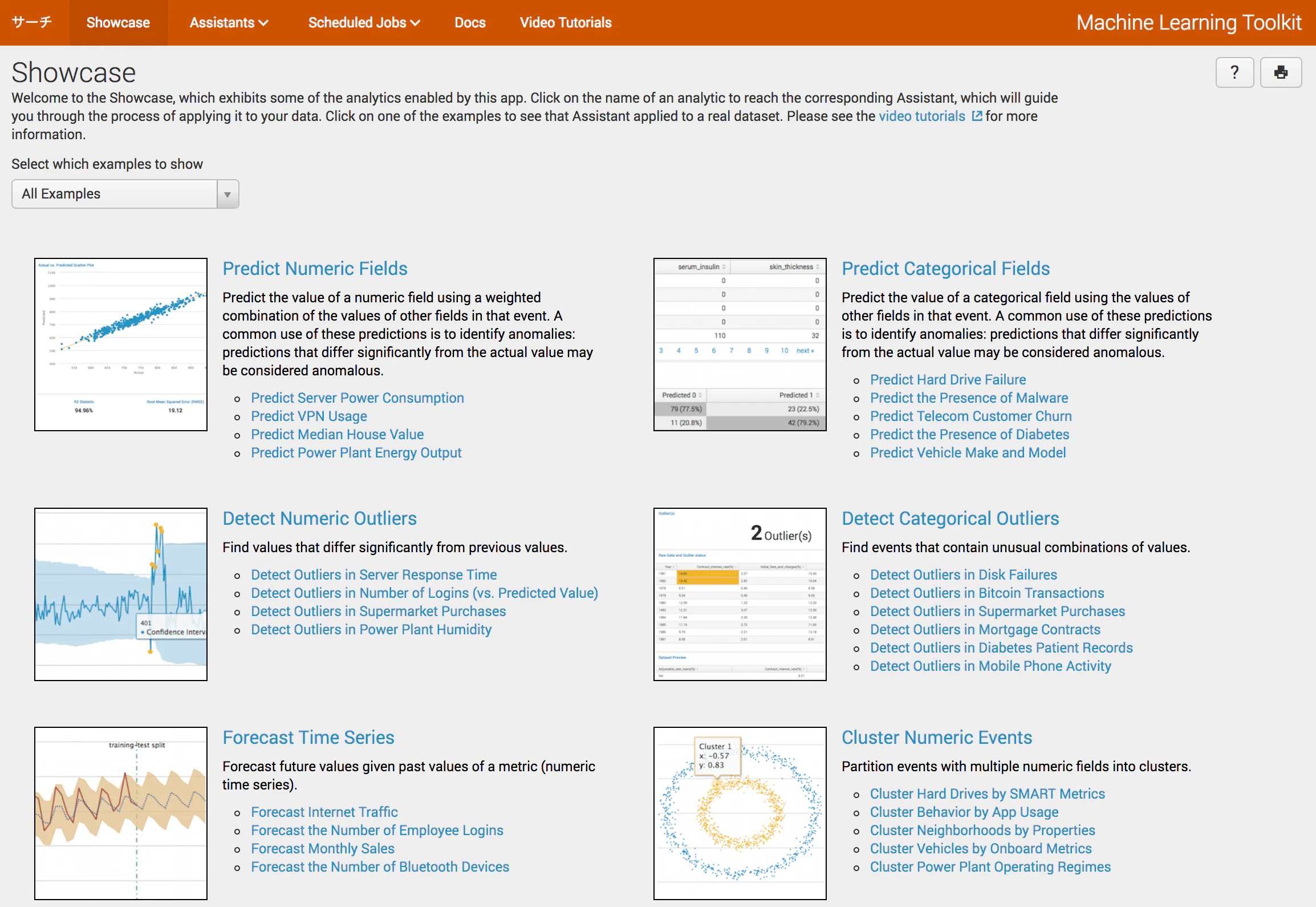
- Predict Numeric Fields = 線形回帰(様々なフィールドの相関から数値フィールドの値を予測)
- Predict Categorical Fields = 分類(True/Falseといった値を持つカテゴリカルフィールドの値を予測)
- Detect Numeric Outliers = 時系列データの異常値を検出
- Detect Categorical Outliers = 数値以外の異常値を検出
- Forecast Time Series = 時系列データの将来予測
- Cluster Numeric Events = クラスター分析
それぞれの項目にIT/セキュリティ/ビジネス/IoTのサンプルデータと事例があります。
今回はPredict Numeric FieldsとPredict Categorical Fieldsを見てみましょう。
Predict Numeric Fields
数値データの学習モデルを作成し、線形回帰等のアルゴリズムでターゲットの数値を予測します。
それでは、早速Predict Server Power Consumptionにアクセスしてみます。
サーバーの消費電力と学習用の参考データ(CPU使用率やディスクI/O等)がserver_power.csvに入っています。
 ↑SPL (Search Process Language) を入力してデータの検索・整形をします。
↑SPL (Search Process Language) を入力してデータの検索・整形をします。

- Algorithm -> アルゴリズムを選択(サポートしているアルゴリズムはこちら)
- Field to predict -> 予測対象のフィールドを選択
- Fields to use for predicting -> 学習用データのフィールドを指定
- Split for training / test -> 学習用データとモデル適用データの比率を調整
 ↑緑色のFit Modelボタンをポチッと。 すると、予測結果が下の方に表やグラフで表示されます。
↑緑色のFit Modelボタンをポチッと。 すると、予測結果が下の方に表やグラフで表示されます。
ここでは、MLTK独自のカスタムコマンドsampleコマンドやfitコマンドを駆使しています。
これらのコマンドの詳しい使い方はまた別の機会に。
ずっと下にスクロールすると、R^2やRMSEといった数値が出てきます。

ここで、それぞれの計算方法は↓
R^2\quad=\quad1\quad-\quad\frac{\sum_{i=1}^{N}{\bigl(x_i-y_i\bigr)}^2}{\sum_{i=1}^{N}{\bigl(x_i-\bar{x}_i\bigr)}^2}
xi: 実測値
x~1: 実測値の平均
yi: 予測値
R^2は実測と予測の差を、実測の偏差で割って計算しています。
つまり、この値が1に近いほど予測の精度が高いと言えます。
一方、RMSEの計算方法は↓
RMSE\quad=\quad\sqrt{\frac{1}{N}\sum_{i=1}^{N}{\bigl(x_i-y_i\bigr)}^2}
xi: 実測値
yi: 予測値
RMSEは実測と予測の偏差となり、0に近いほど予測の精度が高いということになります。
これらはSplunkのマクロで計算されており、[設定] > [詳細サーチ] > [サーチマクロ] からregressionstatisticsで確認できます。
このマクロの使い方も、後日実践編で解説したいと思います。
ということで、何度も学習用データやアルゴリズムを変えてみながら、R^2が1に近づくように、RMSEがゼロに近づくように、モデルを作成するのが肝要です。
失敗を恐れずに、めげずにトライ&エラーすることが大事です。
Predict Categorical Fields
True/FalseやSuites/Shoes/Accessoryといったカテゴリ系データの学習モデルを作成して予測します。
MLTKショウケースの中から、Predict Hard Drive Failureにアクセスしてみましょう。
HDDの故障有無を発見するためのデータとモデルが準備されています。
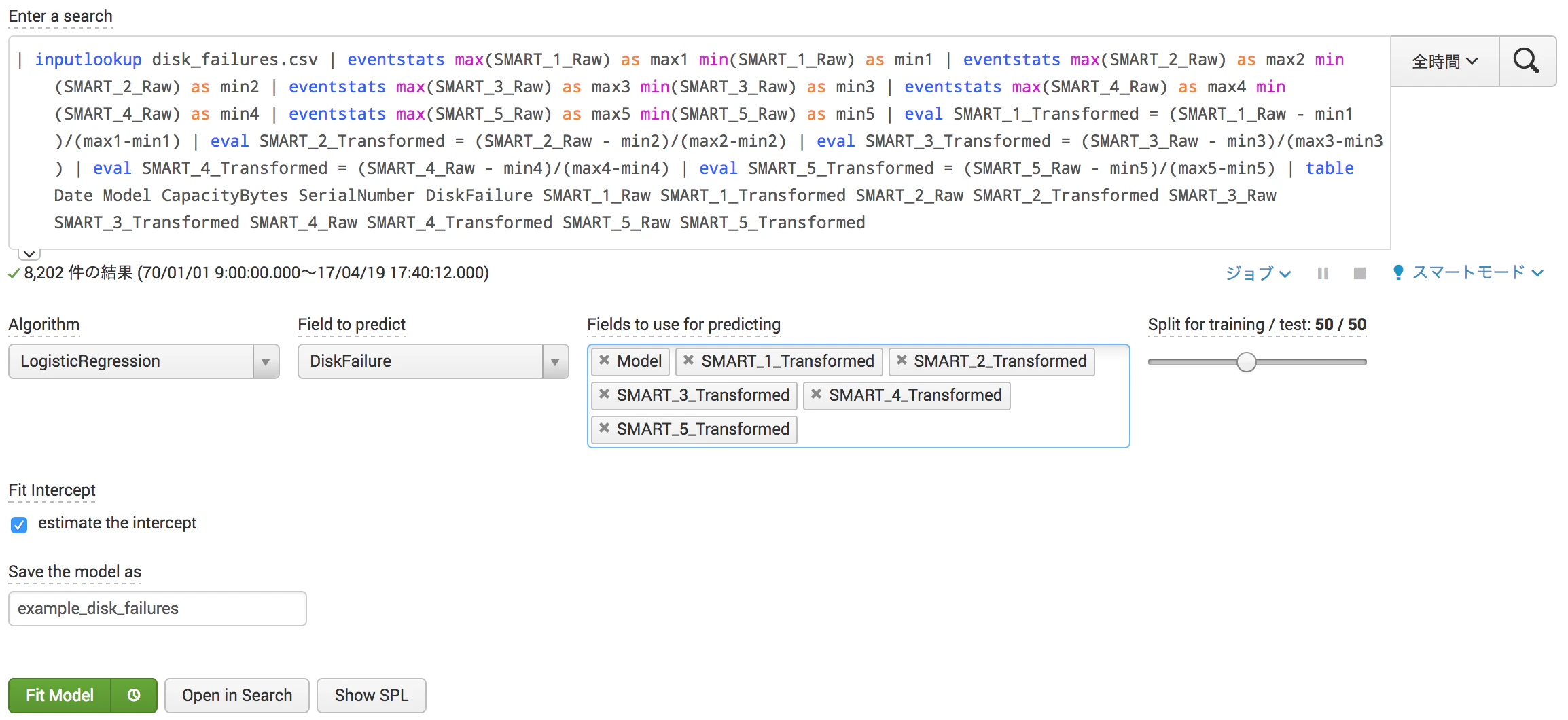
前項のPredict Numeric Fieldsと基本的には同じです。
こちらはDiskFailureというフィールドでディスクの故障有無をYes/Noで記録されていて、これを予測するというものになります。
今回は数値データではないので、扱うアルゴリズムが変わってきます。
利用可能なアルゴリズムはこちらをご参照ください。
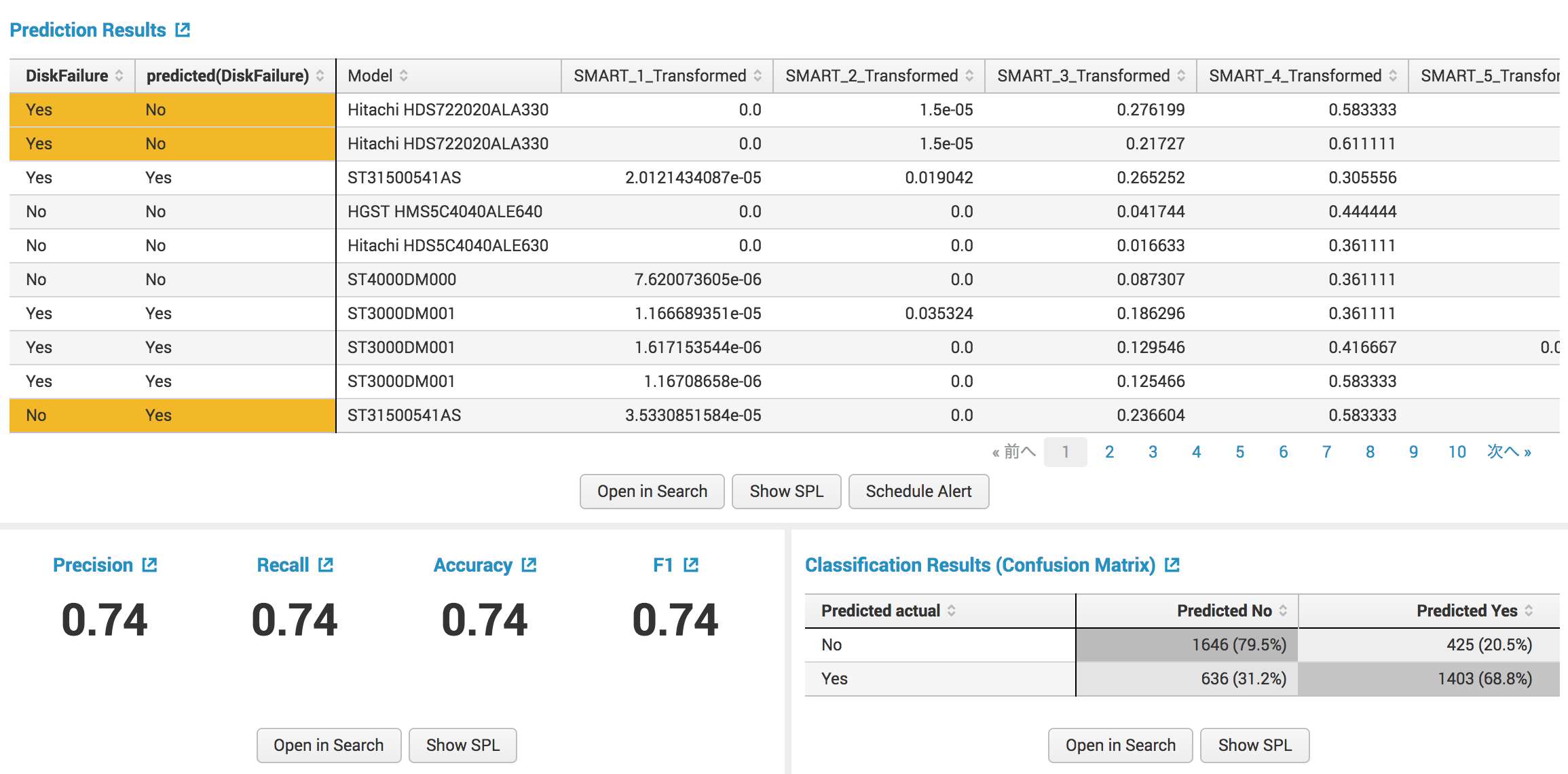
画面下部にはPrecision、Recall、Accuracy、F1といった値が出ています。
PrecisionはFalse Positiveの比率、RecallはFalse Negativeの比率で、1に近づくほど高精度ということになります。
計算式は↓
Precision = \frac{TP}{TP + FP}
Recall = \frac{TP}{TP + FN}
Accuracy = \frac{TP + TN}{TP + TN + FP + FN}
Precisionではノイズの度合いを検査し、Recallでは検知漏れを検査することができますね。
これはclassificationstatisticsというマクロで実装されています。
また、その隣のClassification Resultsは行ごとに実測値が、列ごとに予測値が入ったマトリックスとなっています。
これは、confusionmatrixというマクロで実装されています。
マクロの使い方はごじt (ry
また、数値フィールドをカテゴリ系フィールドにするのに、Splunkのbinコマンドも活用するといいでしょう。
コマンドの使いk (ry
ちなみに、MLTK 2.1.0ではカテゴリ系データのバリエーションとして、1フィールドの中に100種類のデータ(カテゴリ)が上限となるようです。
これを応用すれば、マルウェア検知といったセキュリティ対策にも使えそうですね。
最後に
長々と書きましたが、触れたのはMLTKのほんの一部で、且つ、基本的な使い方に留まっています。
実際にSplunkにインデックスして監視対象としているログやメトリクス、諸々のデータにMLTKを適用して分析・予測・発見・検知してレポートやアラートを作成したり、ダッシュボードで可視化するには、途中で出てきたコマンドやマクロを活用する必要があります。
遠くない将来に実践編を書こうかと思います。
要望あるのかなぁ...
2017.05.12追記
実践編書きました → http://qiita.com/kikeyama/items/d3e5454a80b4dbd5941f