前回の記事ではSplunk Machine Learning Toolkit App(略してMLTK)のインストールと基本的な使い方について書きました。
今回はMLTKに含まれる機械学習のコマンド、マクロの使い方を書きたいと思います。
はじめに
機械学習を使って目指すのは、
リアルタイムに問題点や課題を検知・予測し、それを意思決定につなげてオペレーションやビジネスの質を向上すること
です。
アメリカのドーナツチェーン店におけるSplunk事例があります。
YouTube: Art of the Possible: Smart Retail(英語)
1:09あたりからMachine Learning Toolkitの利用について触れられています。
使われているモデルは比較的単純なものですが、販売数をリアルタイムに予測しアラートをあげることで、販売戦略や在庫管理に活用しているものとなります。
重要なのはリアルタイムな意思決定です。
(大事なことなので2回言っておきます)
Machine Learning Toolkitを使う前に...
Splunkと機械学習という組み合わせは、あらゆる種類のデータ・ログを取り込んで、思い通りに整形・加工して、過去のデータから未来への知見を得るというものになります。
まさにビッグデータですね。
基本的なことにはなりますが、以下のステップが必要となります。
- 学習に必要となるデータの収集(セキュリティの場合だと、Firewall、IDS/IPS、Proxy、DNSあらゆるログが対象となります)
- 学習とモデル作成
- モデル検証
- リアルタイムのデータに適用
学習の変数とするデータが足りなかったり適切でないために高精度のモデルが作成できない場合、Step-1に戻ってデータを収集・加工するところを見直す必要があります。
前回も書きましたが、トライ&エラーが大事です。
やってみよう
ということで、実際にSplunkとMLTKを使ってみましょう。
環境
自分のMac端末にSplunkをインストールして動かしました。
- Splunk Enterprise 6.5.3
- Machine Learning Toolkit 2.2.0
データ
今回はMLTKに既に入っている、マルウェア検知のためのデータを使います。
SplunkのMLTK Appで、サーチ画面に入り、下記のコマンドを実行します。
| inputlookup firewall_traffic.csv
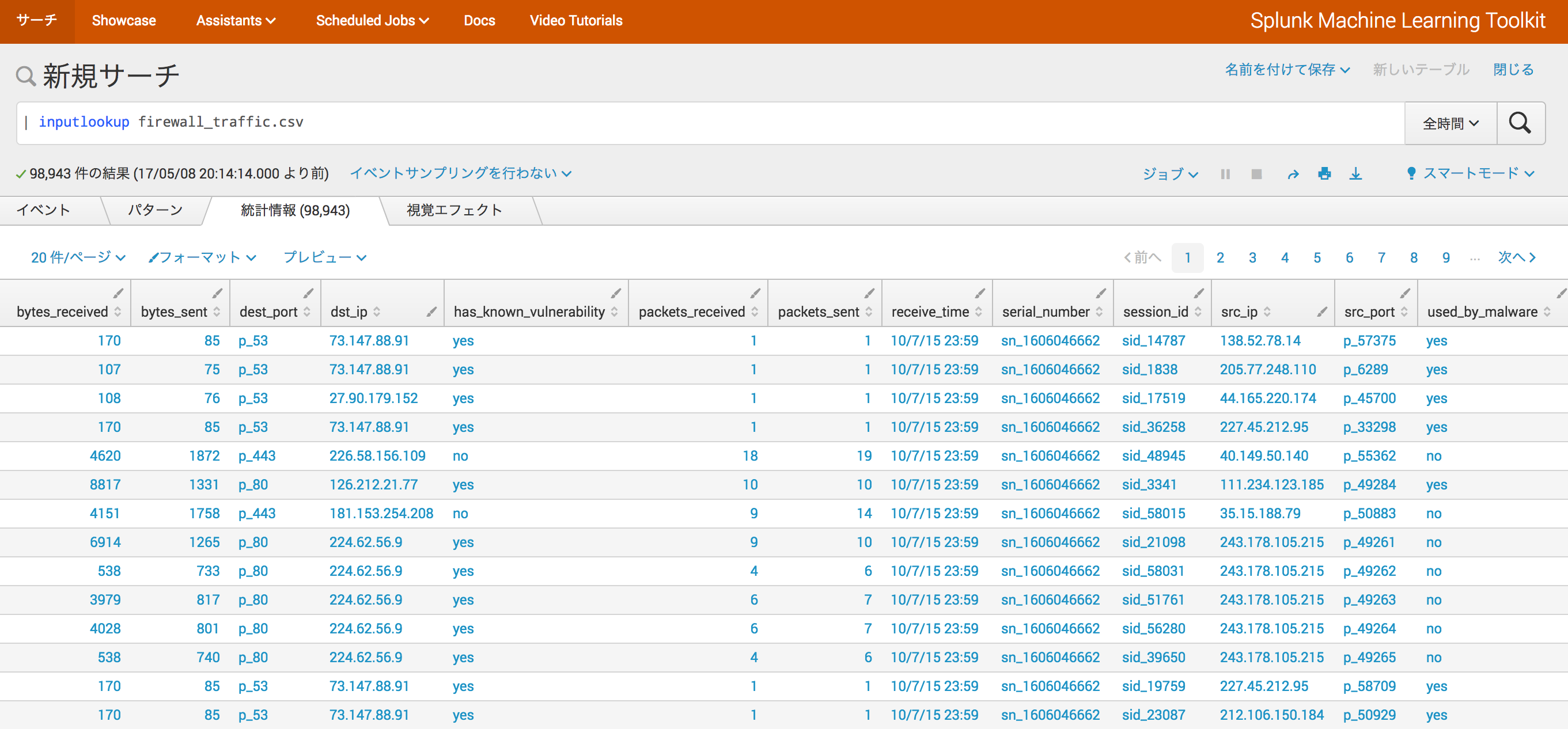
Firewallのログから作成されたデータを想定しているみたいです。
ソースIP/ポート(src_ip/src_port)や宛先IP/ポート(dest_ip/dest_port)、脆弱性の有無(has_known_vulnerability)、送受信サイズ(bytes_received/bytes_sent)等々がありますね。
実際にはFirewallだけではここまでのデータは取得できないでしょう。
脆弱性スキャンやパケットキャプチャ、CMDB、syslog等も組み合わせてデータ作成する必要がありそうです。
アルゴリズム
今回はロジスティック回帰を使います。
これは教師あり学習になるので、学習データに対する答え(ラベル)を与えてやる必要があります。
マルウェア検知なので、予測する対象はused_by_malwareの値とします。
教師あり学習では、ラベルを与えることで学習したモデルが正解に近いかどうかを判断して、より精度の高いモデルを作ることがキモです。
なので、今回のデータでは既に正解データとしてused_by_malwareフィールドの値が入っています。
Splunk MLTKコマンドを使ってみよう
それでは、Splunk MLTKを使ってみましょう。
学習データと検証データを分類する: sampleコマンド
最初のステップとして、モデル作成のための学習データと評価のための検証データを分けます。
機械学習では、かならず学習データと検証データは全く別々のものにしましょう。
それを実現するコマンドはsampleコマンドです。
これはMLTK Appに入っているカスタムコマンドです。
| inputlookup firewall_traffic.csv
| sample partitions=10 seed=123
このコマンドでは、partitions=10を指定することで、元のデータを10個に分類しています。
ただし、このコマンドは毎回ランダムに分類するため、学習データと検証データを完全に分けることができません。
そこで、seedオプションを使います。
このオプションで指定する数字が分類のキーとなり、ランダムではなく一定のものとなります。
この場合、seed=123と指定しているので、学習と検証それぞれのステップでこのオプションを指定すれば、分類がランダムではなく同じ分類となります。


partition_numberというフィールドができて、0〜9の数字で分類されていますね。
学習データの抽出: searchコマンド
分類によって生成されたpartition_numberフィールドを使って、学習データのみを抽出します。
使用するコマンドはsearchですが、これはMLTKではなく、Splunkそのもののコアコマンドです。
| inputlookup firewall_traffic.csv
| sample partitions=10 seed=123
| search partition_number<5
学習データと検証データを5:5の割合で分類することを想定して、partition_numberが5未満のものを抽出しました。

0〜4のもののみ抽出されていますね。
これが学習データとなります。
モデル作成: fitコマンド
本題のモデル作成になります。
ここでは、MLTK Appのカスタムコマンドfitを使います。
fitコマンドの使い方は...
fit <アルゴリズム> <ラベルフィールド> from <学習フィールド(スペース区切りで複数可> into <モデル名>
です。
| inputlookup firewall_traffic.csv
| sample partitions=10 seed=123
| search partition_number<5
| fit LogisticRegression used_by_malware from has_known_vulnerabirlity dest_ip dest_port src_ip src_port bytes_sent bytes_received into malware_logisticregression_qiita
学習データとして、has_known_vulnerabirlity dest_ip dest_port src_ip src_port bytes_sent bytes_receivedを指定しました。
保存したモデル名は何でも良いですが、アルゴリズム名やラベル名、プロジェクト名(もしくはID)等を入れたネーミングルールを決めると良いでしょう。
今回はmalware_logisticregression_qiitaとしました。
モデル検証: applyコマンド
fitコマンドで作成したモデルを検証するのにapplyコマンドを使います。
使い方は...
apply <保存したモデル名>
こでだけです。
sampleコマンドで分類したパーティションのうち、5以上のものを使って検証します。
| inputlookup firewall_traffic.csv
| sample partitions=10 seed=123
| search partition_number>=5
| apply malware_logisticregression_qiita
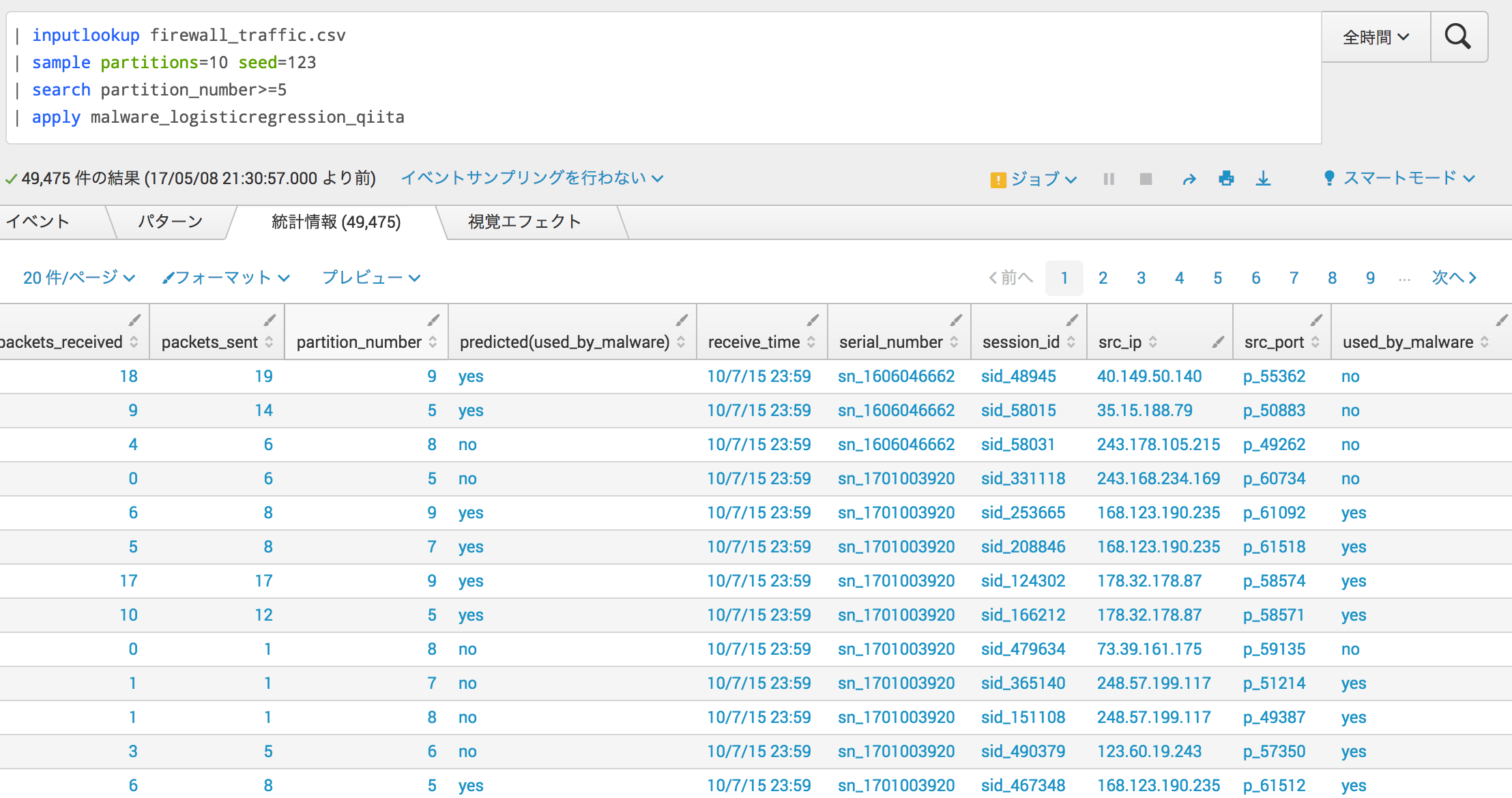
predicted(used_by_malware)フィールドができていますね。
評価: `classificationstatistics`マクロ
マクロ`classificationstatistics`を使って、Precision, Recall, Accuracyを算出します。
それぞれの説明は前回の投稿をご参照ください。
使い方は...
classificationstatistics(<実測値のフィールド名>, <予測値>)
です。
| inputlookup firewall_traffic.csv
| sample partitions=10 seed=123
| search partition_number>=5
| apply malware_logisticregression_qiita as predicted
| `classificationstatistics(used_by_malware,predicted)`

Accuracyが0.53なので、あまり精度は良くないですね。
Confusion Matrix: `confusionmatrix`マクロ
フィールド内の値 - yes / no が実測に対してどのように予測されているかの集計をします。
| inputlookup firewall_traffic.csv
| sample partitions=10 seed=123
| search partition_number>=5
| apply malware_logisticregression_qiita as predicted
| `confusionmatrix(used_by_malware,predicted)`

実測値noの予測値noが17,318に対して予測値yesが2,663
実測値yesの予測値yesが9,060に対して予測値yesが20,434
という見方になります。
モデル作成のやり直し
精度を上げるために学習データを見直しましょう。
| inputlookup firewall_traffic.csv
| sample partitions=10 seed=123
| search partition_number<5
| fit LogisticRegression used_by_malware from has_known_vulnerabirlity src_port dest_port bytes_sent bytes_received packets_sent packets_received into malware_logisticregression_qiita
src_ipを削除し、dest_port packets_sent packets_receivedを追加しました。
| inputlookup firewall_traffic.csv
| sample partitions=10 seed=123
| search partition_number>=5
| apply malware_logisticregression_qiita as predicted
| `classificationstatistics(used_by_malware,predicted)`

今度はAccuracyが0.75まで上昇しましたね。
このモデルを予測に使うことにしましょう。
最後に
Splunk Machine Learning Toolkitのサーチコマンドやマクロを中心に書きましたが、大事なのは機械学習をする目的と、それによって成し遂げるビジネスやオペレーションの改善です。
Splunkでの機械学習のやり方としては、sample fit applyを適材適所で使うことが大事でしょう。
サーチコマンドのマニュアルはこちらをご参照ください。
また、教師あり学習の場合は正解を与える必要があるので、機械学習の前段階のデータ取り込み・加工の部分や学習データ、正解データの作成は知恵と経験が必要となるかもしれません。
そこらへんはまた要望があればまとめようかと思います。