今回は、Slackやtwitter などの文章データを取り込んだあとに、単語ベースで分析したい場合に、英語だと単語がスペースで区切られているので解析しやすいのですが、日本語の場合品詞分解が非常に複雑で手間がかかるかと思います。
一般的には MeCabなどのツールを使って形態素解析するのがいいかもしれませんが、Splunkではデフォルトではそのようなツールが入っていないので、形態素解析した後に、Splunkに取り込む必要があります。
そこで、今回はMeCabなどのツールほど正確に形態素解析はできませんが、もどきの方法を正規表現を使ってやってみたいと思います。
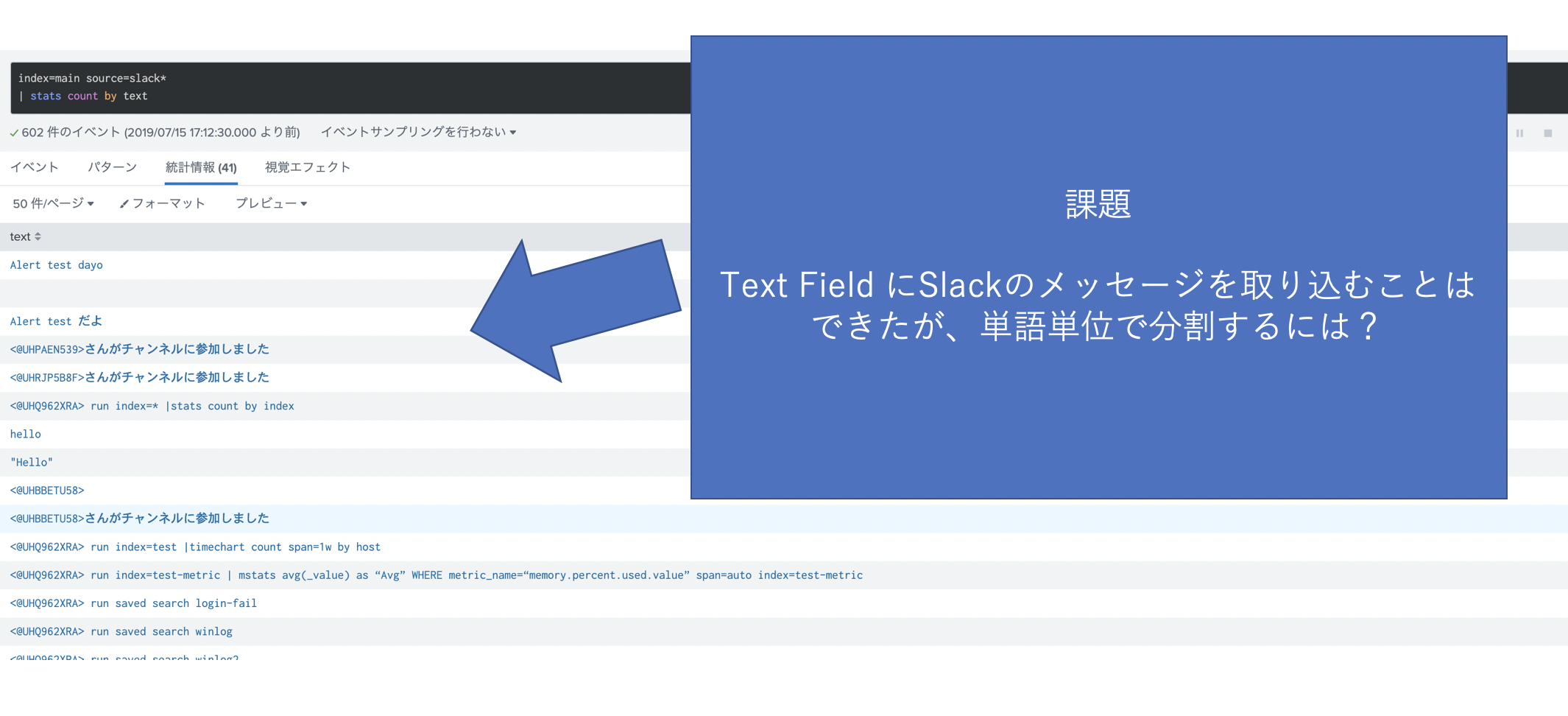
##正規表現で日本語を識別して取り込むには?
Splunkはデフォルト Unicodeで取り込まれますが、Unicodeスクリプトを使って簡単に漢字やひらがななどにマッチングさせて取り込むことができるようです。
http://module.jp/blog/regex_unicode_prop.html
| 正規表現 | 識別ターゲット |
|---|---|
| \p{Katakana} | カタカナ |
| \p{Hiragana} | ひらがな |
| \p{Han} | 漢字 |
| \p{Latin} | 英数字 |
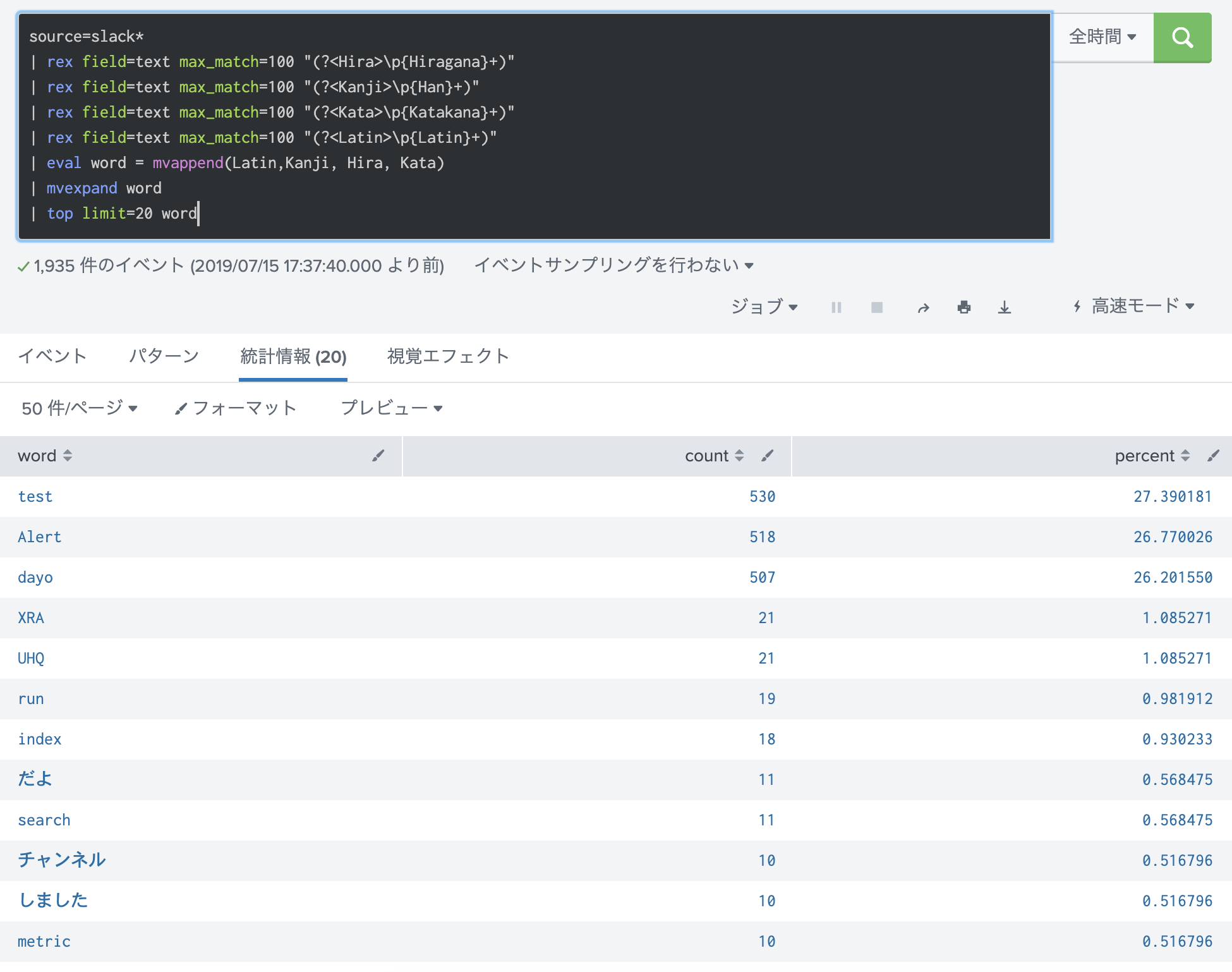
Splunkで正規表現を使って、文章を分解してみよう。
上記の正規表現を使って、単語に分解して、その出現回数をカウントしてみたいと思います。
ただし、漢字同士が続いたりすると同一単語と認識されてしまうので、正確性にはかけますので、その点はご容赦ください。
source=slack*
| rex field=text max_match=100 "(?<Hira>\p{Hiragana}+)"
| rex field=text max_match=100 "(?<Kanji>\p{Han}+)"
| rex field=text max_match=100 "(?<Kata>\p{Katakana}+)"
| rex field=text max_match=100 "(?<Latin>\p{Latin}+)"
| eval word = mvappend(Latin,Kanji, Hira, Kata)
| mvexpand word
| top limit=20 word
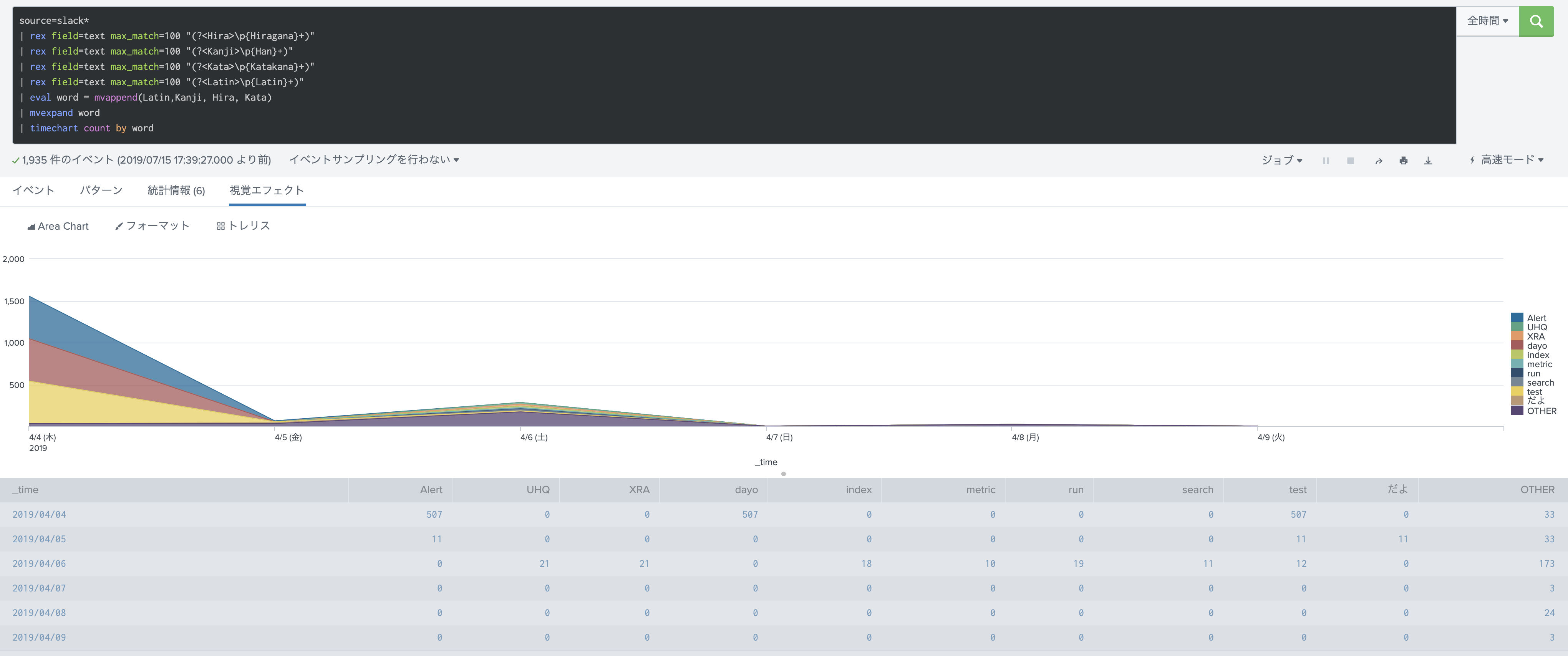
時系列で表示してみたり
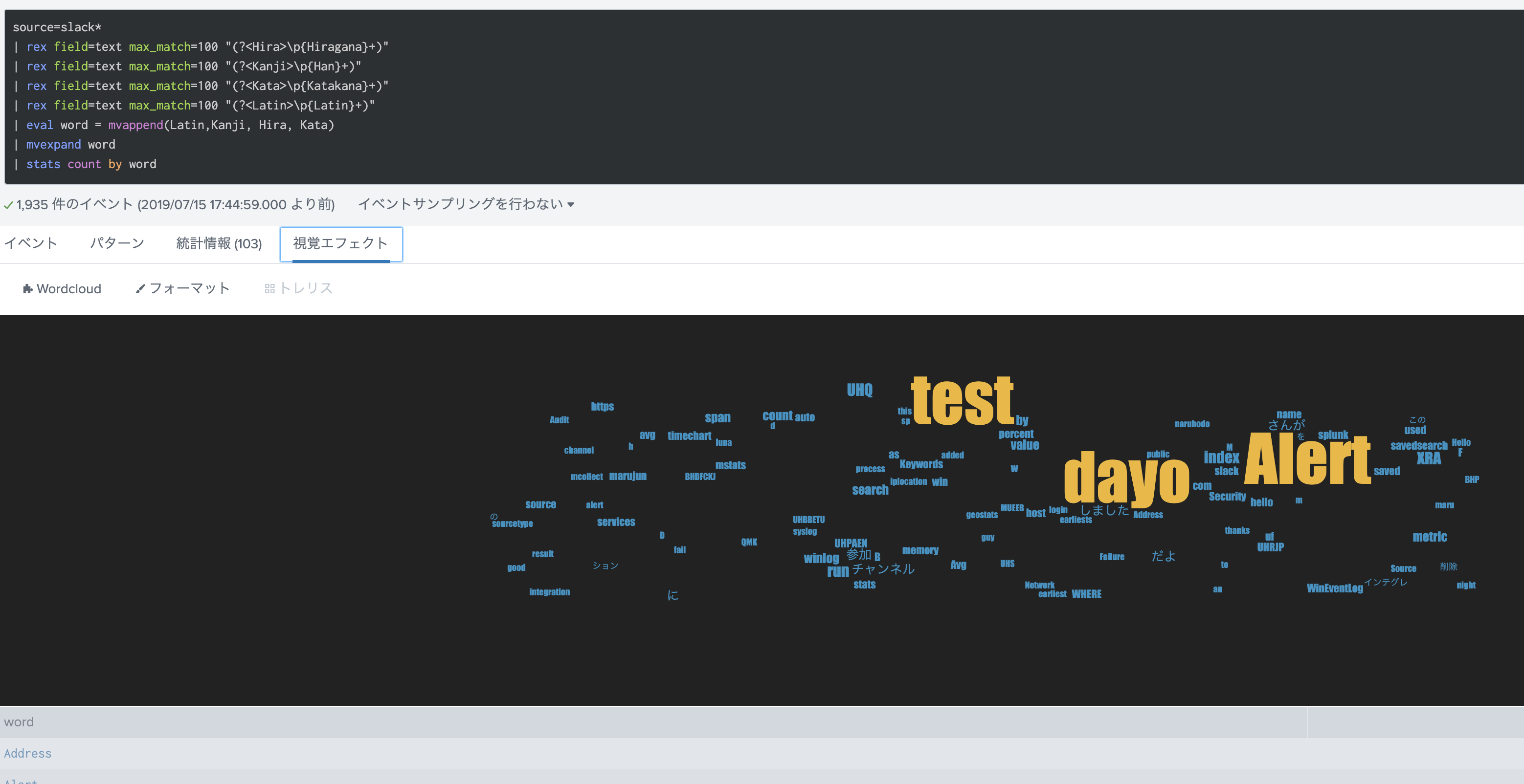
Wordcloud で可視化してみたり
https://splunkbase.splunk.com/app/3212/
さいごに
今回は、日本語メッセージでも非常にシンプルにできる形態素解析もどきをご紹介しました。