はじめに
Databricks を利用して、S3 bucketにアクセスするにはどうすれば良いでしょうか? いくつかの方法がありますが、ここではシンプルにアクセスしてデータをロード出来るようになるための方法をいくつかご紹介します。(ここに記載以外にも方法はあります)
認証方法
認証方式としては主に以下のものがあります。
- AWS access key
- インスタンスプロファイル
- IAM Credential Passthrough (Preview)
それぞれの方式毎に、DBFS経由もしくはDirect接続などで対象範囲などが異なるため、以下のように整理してみました。
認証方式とアクセス方法の特徴
|No|認証方式|アクセス方法|資格|設定箇所|有効期間|アクセスユーザー対象範囲|
|:--+-------+---+---+-------+---+--------:|
|1|AccessKey|DBFS経由|ワークスペース資格|Notebook(一度誰かがすればOK)|umountするまで永続|ワークスペース内の全ユーザー|
|2|AccessKey|Direct|セッション資格|Notebook(毎回実行)|Notebookセッション中|ノートブック利用者|
|3|Instance Profile|DBFS / Direct (instance profile)|クラスター資格|Cluster設定|Cluster起動中|Cluster利用者|
|4|IAM Credential Passthrough|Direct (credential passthrough) | ユーザー資格| Cluster設定、認証 |Cluster起動中|ユーザー|
ご覧の通り、AccessKeyでDBFS経由の場合、一度マウントしてしまうと、他のユーザーもアクセス出来てしまうため、利用ユーザーを絞りたい場合は、Directアクセスでご利用ください。
よりセキュアに利用するのであれば、Instance Profile方式をお勧めしますが、Notebookのセッション単位での利用や、AzureやGCPなどの他のクラウド上のDatabricksからは利用できません。
最後のcredential passthroughは、現時点(2021/12/25時点)では Preview扱いとなります。
Access Key認証を使った設定方法
イメージとしては以下の感じかと思います。 まずは対象のS3へのアクセスを許可したポリシーを作成し、そのポリシーを新規のIAMユーザーに付与します。そのIAMユーザーの AccessKey/SecretKeyを利用して、S3に接続します。

AccessKeyとSecretKeyさえあれば、どこからでもアクセスできるため、セキュリティ的にはInstanceProfileと比べると落ちてしまうため、検証時の利用であったり、DatabricksのSecrets機能と併用するなど利用する際にはご注意ください。
設定手順
1. S3 Storageの作成
まずは、S3 Bucketを作成します。バケット名を入力し、バージョニングは有効化しておきましょう。
それ以外は、デフォルト設定のままで今回は進めます。

2. Policy作成
IAMサービスに移動し、新規のポリシーを作成します。
ポリシー名を入力します。

次に移動し、JOSNタブから以下の内容をコピペして貼り付けます。その際に、先ほど作成したS3 Bucket名を <bucket name> の所に入力ください。

{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::<bucket name>"
]
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:DeleteObject",
"s3:PutObjectAcl"
],
"Resource": [
"arn:aws:s3:::<bucket name>/*"
]
}
]
}
3. IAM User作成
次にユーザーを作成します。その際に認証タイプと**「アクセスキー - プログラムによるアクセス」**を選択します。

次に進み、先ほど作成したポリシーを選択します。

最後に、アクセスキーとシークレットキーを発行して、お手元に保存しておきます。(シークレットキーは一度閉じると見えなくなりますのでご注意を)。アクセスキーは2つまでなら作成できます。

4. Databricks Secretへの登録
3.で取得したアクセスキーとシークレットキーをそのまま利用することも可能ですが、セキュリティ的に漏れるとまずいので、Databricksのシークレット機能を利用して保管しておきます。
シークレット機能の利用方法はこちらをご覧ください。
Databricks CLIおよびSecretsの使い方
シークレット機能を利用せず、まずはそのまま利用したい方はスキップして次にお進みください。
5. Notebookからの利用(サンプルノートブック)
DBFS経由とDirect Accessの2つの方法について実際のコードを用意しました。
こちらのサンプルノートブックをご覧ください
Instance Profileを使った設定方法
イメージとしては以下の感じかと思います。
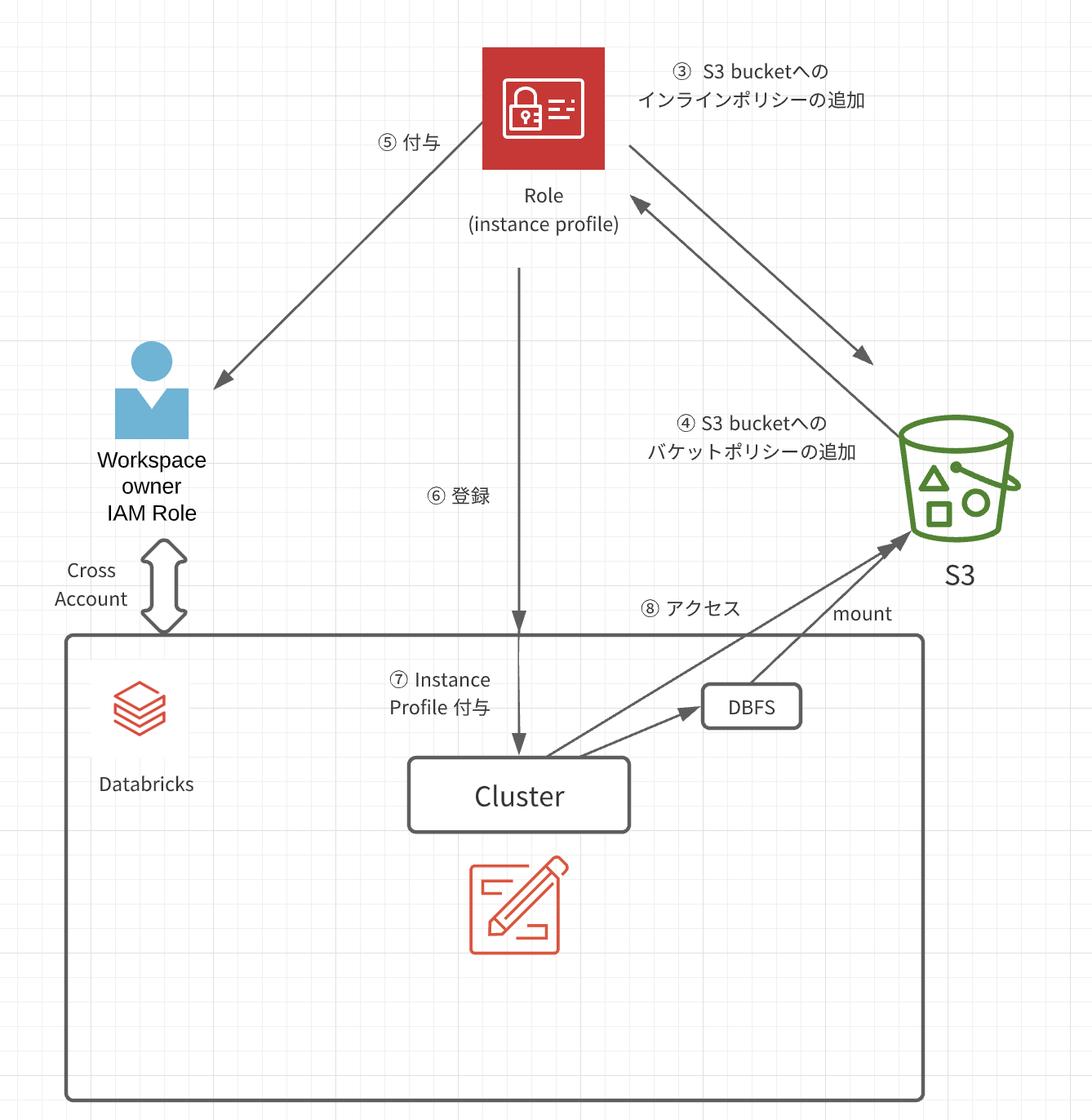
手順概要
- S3 Bucketを作成
- S3 IAMロールを作成(インスタンスプロファイル)
- 作成したロールに対して、S3 Bucketへのインラインポリシーの追加
- S3 Bucket側にも、バケットポリシーを追加し、ロールからのアクセスを許可する
- 2.で作成したS3ロールを、(Databricks構築に用いた)ロールのEC2ポリシーに追加する
- Databricks管理画面から、instance profileを登録する
- Cluster 作成時に、instance profileを付与する
- Clusterを利用するノートブックやJobからS3にアクセスできるようになります
詳しい設定方法については、すでに詳しく書かれた記事がありますので、こちらをご覧ください。
ナレコム様記事
databricks公式ドキュメントやってみた~Secure access to S3 buckets using instance profiles(前編)
databricks公式ドキュメントやってみた~Secure access to S3 buckets using instance profiles(後編)
Databricksにおけるインスタンスプロファイルを用いたS3バケットへのセキュアなアクセス
(by @taka_yayoi)
Credential Passthrough によるアクセス (Public Preview - 2021/12/25時点)
上記の2つとも、AccessKeyを知っている人か instance policyが設定されたクラスター上であれば、誰でもアクセスできます。またS3へのアクセスログにも、特定のユーザーではなく、EC2などになるため特定が困難です。そこで登場したのが、Credential Passthroughになります。こちらはデータブリックスにログインしたユーザーにアクセス権が付与されるため、S3にアクセスしたユーザーの特定が容易になります。ただしデータブリックスにログインするユーザーと、AWS IAMは同期する必要があるのと、ロール作成など更に複雑になります。
この機能を利用するためには、Databricksのユーザー管理または認証を以下のいづれかを利用している必要があります。
- Databricks SCIM
- SAML 2.0 Federation
今回は、こちらの設定については試しておりません。いつの日か記事に出来たらと思います。
マニュアルはこちら
Credential passthrough