はじめに
Amazon SageMaker で分散学習をするためのライブラリが追加されました。データ並列処理とモデル並列処理に対応しています。それぞれの特徴を見てみましょう。この記事は、こちらのドキュメント を日本語で要約したものです。
Amazon SageMaker Distributed Training は、リソースを効率的に使用して分散学習を効果的に行うことができます。
Data Parallel
大量のデータを使って機械学習モデルを学習する場合、学習時間短縮のために分散学習が使われます。分散学習は、単純に使用するインスタンスの数を増やすだけではなく、それらを効率的に使用することが求められます。
AWS blog によると、モデルの学習に GPU インスタンスを使用し、AllReduce には GPU インスタンスに搭載された CPU を使用することで、専用のパラメータサーバを用意しなくても良いという特徴があります。
バランスフュージョンバッファを使用して帯域幅を最適化
SageMaker の分散データ並列ライブラリは、パラメータサーバに似た手法を採りますが、複数の GPU から集めた勾配を平均化する際のデータ転送量と計算ステップ数を削減します。また、バランスフュージョンバッファと呼ばれる新しい技術を使用して、クラスタ内の帯域を効率的に利用します。
従来のパラメータサーバの主な欠点のひとつは、利用可能なネットワーク帯域を最適に利用できないことです。パラメータサーバは変数を最小単位として扱い、それぞれの変数はいずれか 1つのパラメータサーバに配置されます。勾配は backward 処理をしながら順次利用可能になるため、ある瞬間に、パラメータサーバから送受信されるデータ量に不均衡が生じます。パラメータサーバによっては、より多くのデータを送受信したり、全く送受信をしたいパラメータサーバもあります。この問題は、パラメータサーバの数が増えるにつれて悪化します。
SageMaker のデータ分散ライブラリでは、バランスフュージョンバッファを導入することでこれらの問題に対処します。バランスフュージョンバッファは、しきい値を超えるまで勾配を保持することができる GPU 内のバッファです。N個のパラメータサーバを使用する場合、バッファにためた勾配情報量がしきい値を超えると、バランスフュージョンバッファの内容は CPU メモリにコピーされ、それらは N分割され、i番目のパーツが i番目のパラメータサーバに送信されます。各サーバは、バランスフュージョンバッファから全く同じサイズのデータを受け取ることになります。i番目のサーバは、すべてのワーカーからバランスフュージョンバッファの i番目のパーツを受け取り、それらを合計し、その結果をすべてのワーカーに送り返します。すべてのサーバがそれぞれ受け取ったバランスフュージョンバッファからの情報の平均化処理に同程度使われるため、サーバの帯域は効率的に利用されることになります。
効率的な AllReduce オーバーラッピングとバックワードパスによる GPU 使用率の最適化
SageMaker の分散データ並列ライブラリは、AllReduce 演算と backward パスを並列して動作させるため、GPU 利用率を大幅に向上させ、CPU と GPU 間のタスクを最適化することで、ほぼ直線的なスケール効率と学習時間の高速化を実現します。言い換えると、このライブラリは GPU が勾配を計算している間に AllReduce を並列に実行するため、GPU のリソースを消費することなく、学習の高速化を実現しています。
CPU の活用:ライブラリは CPU を利用して勾配の AllReduce を行うため、GPU はAllReduce 処理をする必要がありません。
GPU 使用率の向上:クラスタの GPU は勾配の計算に集中しているため、学習中は GPU の使用率が向上します。
Data Parallel FAQ
Q. このライブラリを使用する場合、AllReduce を行う CPU インスタンスはどのように管理されますか? 別の CPU-GPU クラスタを作成する必要はありますか。もしくは SageMaker が追加の C5 インスタンスを作成しますか?
A. ライブラリは GPU インスタンスで利用可能な CPU を使用します。追加の C5 や CPU インスタンスは起動されません。SageMaker 学習ジョブが 8 ノードの ml.p3dn.24xlarge クラスターの場合、8 個の ml.p3dn.24xlarge インスタンスのみが使用されます。追加のインスタンスはプロビジョニングされません。
Q. ハイパーパラメータ H1(学習率、バッチサイズ、オプティマイザなど)を設定したひとつのml.p3.24xlarge インスタンスで5日間かかる学習ジョブがあります。SDP を有効にして 5倍の大きなクラスタを使用すれば、およそ5倍のスピードアップを経験するのに十分でしょうか? それとも、SDP を有効にした後に、その学習ハイパーパラメータを再検討する必要があるのでしょうか?
A. ライブラリを有効にすると、全体のバッチサイズが変わります。新しい全体的なバッチサイズは、使用するトレーニングインスタンスの数に応じて線形にスケーリングされます。その結果、収束を確実にするためには、学習率などのハイパーパラメータを変更する必要があります。
Q. ライブラリは Spot Training に対応していますか?
A. はい、マネージドスポットトレーニングを利用することができます。SageMaker の学習ジョブでチェックポイントファイルのパスを指定します。スクリプト修正の概要の最後のステップ で説明したように、学習スクリプトでチェックポイントの保存/復元を有効にします。
Q.このライブラリのバランスフュージョンバッファと PyTorch Distributed Data Parallel (DDP)の "Gradient Buckets "の違いは何ですか?
主な違いは、DDP のフュージョンバッファは AllReduce に使用され、ライブラリのバランスフュージョンバッファはパラメータサーバ型同期に使用されます。このライブラリは、パラメータサーバ型の勾配の同期でフュージョンバッファをシャードする最初のフレームワークです。
PyTorch DDP のドキュメントより。"通信効率を向上させるために、Reducer はパラメータグラデーションをバケットに整理し、1度に 1つずつバケットを減らしていきます。バケットサイズは、DDP コンストラクタで bucket_cap_mb 引数を設定することで設定できます。パラメータグラデーションからバケットへのマッピングは、バケットサイズの制限値とパラメータサイズに基づいて、構築時に決定されます。モデルパラメータは、だいたい与えられたモデルから Model.parameters() の逆順でバケットに割り当てられます。逆順を使用する理由は、DDP は勾配がほぼその順番で backward の間に準備が整うことを期待しているからです。"
Q. シングルホスト、マルチデバイスでの利用は可能ですか?
A. 可能です。しかし、2つ以上のノードでは、ライブラリの AllReduce 動作により、パフォーマンスが大幅に向上します。また、シングル・ホストでは、NVLink がすでにノード内の AllReduce 効率に貢献しています。
Q: PyTorch Lightning で使えますか?
A. 使えません。ただし、PyTorch 用のライブラリの DDP を使えば、機能を実現するためのカスタム DDP を書くことができます。
Q. 学習データセットはどこに保存すればいいですか?
A. 学習データセットは、S3 バケットや FSx ドライブに保存できます。学習ジョブのためにサポートされている様々な入力ファイルシステムについては、このドキュメント を参照してください。
Q. 学習データはFSx for Lustre に保存しておく必要がありますか? EFS や S3 は使用できますか?
A. 学習開始までの時間を短縮するために、FSxの使用をおすすめしますが、必須ではありません。
Q. CPU ノードでも利用できますか?
A. 使えません。現時点では ml.p3.16xlarge、ml.p3dn.24xlarge、ml.p4d.24xlarge のインスタンスをサポートしています。
Q. サポートされているフレームワークやフレームワークのバージョンを教えてください。
A. 現在、PyTorch v1.6 と Tensorflow v2.3.1 をサポートしています。Tensorflow 1.x をサポートしています。
Model Parallel
モデル並列は、GPU メモリサイズの制約で学習が困難だった大規模なディープラーニングモデルの学習に効果的です。SageMaker Distributed Training のモデル並列は、モデルの計算グラフ、モデルのパラメータとアクティブ化のサイズ、およびリソースの制約(時間とメモリの比較など)を考慮して、モデルを複数の GPU に最適に分割します。
また、異なるデバイスが異なるデータサンプルの forward パスと backward パスを同時に処理できるパイプラインを構築することで、効率的な並列化が可能になっています。
自動モデル分割
ライブラリは、メモリのバランスをとり、デバイス間の通信を最小限に抑え、パフォーマンスを最適化するパーティショニング・アルゴリズムを使用します。ユーザは、速度やメモリを最適化するために、自動パーティショニングアルゴリズムを調整できます。基本的には自動パーティショニングを利用することが推奨されますが、ユーザがモデルの構成を熟知しており、より効率的な分割が可能な場合、手動でモデル分割することも可能です。
モデルの自動分割は、最初の学習ステップである smp.step-decorated 関数が最初に呼び出されたときに実行されます。この呼び出しの間、ライブラリはまず GPU メモリを圧迫しないよう CPU RAM 上にモデルのバージョンを構築し、モデルグラフを解析して分割方法を決定します。この決定に基づいて、各モデルのパーティション(サブグラフ)が GPU 上にロードされます。このような解析とパーティショニングのステップがあるため、最初の学習ステップは時間がかかる場合があります。
いずれのフレームワークでも、ライブラリは AWS インフラストラクチャに最適化された独自のバックエンドを介してデバイス間の通信を管理します。
自動パーティショニングはフレームワークの特性に合わせて行われます。たとえば、TensorFlow は特定の操作を別のデバイスに割り当てることができますが、PyTorch はモジュールレベルで割り当てが行われ、各モジュールは複数の操作で構成されています。
パイプライン実行スケジュール
SageMaker の分散モデル並列ライブラリのコア機能として、モデル学習中にデバイス間で計算とデータ処理の順番を決定するパイプライン実行があります。パイプラインとは、GPU ごとに異なるデータサンプルを同時に計算させることでモデル並列化を実現し、シーケンシャルな計算による性能低下を克服するための手法です。
パイプラインは、まず学習データのミニバッチをさらにマイクロバッチに分割します。マイクロバッチは 1つずつ学習パイプラインに供給され、ライブラリランタイムによって定義された実行スケジュールに従って実行されます。マイクロバッチは、与えられた学習ミニバッチのより小さなサブセットです。パイプラインスケジュールは、タイミングごとにどのデバイスでどのマイクロバッチを実行するかを決定します。
以下の画像は、2つの GPU を使って、2 分割されたモデルを学習する様子を表したものです。GPU #1 には、分割されたモデルの前半部分(Partition 1)が 複製されて 2つ配置されています。GPU #2 には、分割されたモデルの後半部分(Partition 2)が、複製されて 2つ配置されています。Partition を 2つに複製することで、それぞれに forward 処理のみ、backward 処理のみを行うよう担当わけすることができます。
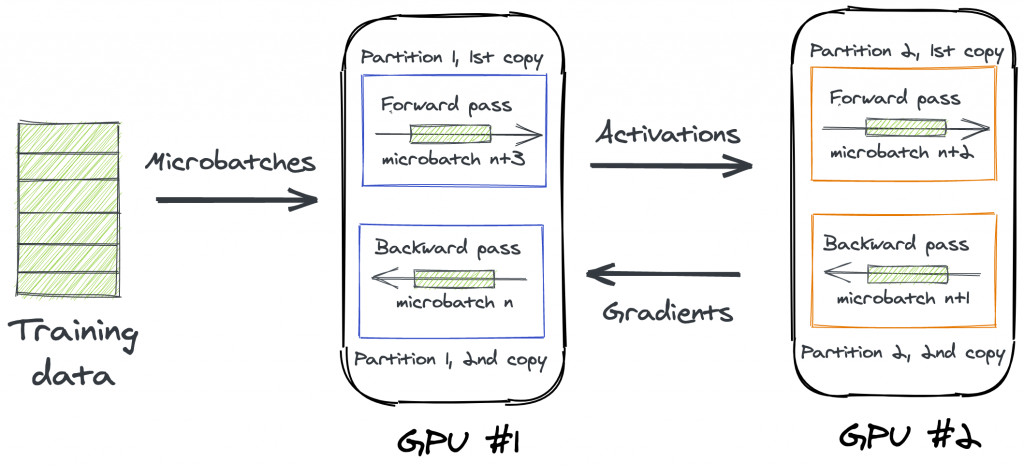
上図を使ってモデル並列の学習の流れを説明します。モデルの分割、複製が完了したら、パイプラインスケジュールとモデルパーティションに応じて、まず GPU #1 がマイクロバッチ n を入力として forward 処理を行います。この処理には、図の GPU #1 の上半分にある、Partition 1, 1st copy と書かれた部分が使用されます。
マイクロバッチ n の forward 処理が完了したら、次のタイミングでは、forward 処理の結果を受け取って、GPU #2 の上半分の Partition2, 1st copy の部分がマイクロバッチ n の forward 処理の後半を行います。このとき、Partition 1, 1st copy の部分は次のマイクロバッチ n+1 を受け取って forward 処理の前半を行います。この時点で、GPU #1 と GPU #2 の上半分、forward 処理を担当する部分が忙しく働くことになります。
次のタイミングでは backward 処理が開始します。GPU #2 の下半分の Partition 2, 2nd copy の部分がマイクロバッチ n の backward 処理の前半を行います。このとき、GPU #2 の上半分はマイクロバッチ n+1 の forward 処理の後半、GPU #1 の上半分はマイクロバッチ n+2 の forward 処理前半をそれぞれ行っています。この時点で、GPU #1 の下半分以外が忙しく働いていることになります。
さらに次のタイミングでは、ずっとサボっていた GPU #1 の下半分の Partition 1, 2nd copy の部分がマイクロバッチ n の backward 処理の後半を行います。これで、すべてのパートがフル稼働している状態になりました。上図は、このタイミングの様子を図にしたものと言えます。
このように、分割したモデルの Partition を複製して GPU に配置し、マイクロバッチを順次実行することで、GPU 使用率を上げることができます。
ライブラリにはシンプルとインターリーブの 2種類のパイプラインスケジュールがあり、SageMaker Python SDK の pipeline パラメータを使って設定できます。多くの場合、インターリーブパイプラインの方が GPU をより効率的に利用することで、より良いパフォーマンスを得ることができます。
インターリーブパイプライン
インターリーブパイプラインでは、可能な限りマイクロバッチの backward 処理が優先されます。言い換えると、とあるマイクロバッチの forward 処理がすべて完了して backward 処理が可能になったら、次のマイクロバッチの処理の forward 処理より優先してすぐに実行する、という制御を行います。これにより、forward 処理のパスで使用したメモリをより早く解放し、メモリをより効率的に使用することができます。また、マイクロバッチの数を多くすることで、GPU のアイドル時間を短縮することもできます。定常状態では、各デバイスは forward 処理と backward 処理を交互に実行することになります。これは、あるマイクロバッチの backward 処理が、別のマイクロバッチの forward 処理が終了する前に実行される可能性があることです。

上図は、2つの GPU を用いたインターリーブパイプラインの実行スケジュールの一例です。F0 はマイクロバッチ0 の forward 処理、B1はマイクロバッチ1 の backward 処理を表しています。Update はパラメータのオプティマイザ更新を表します。GPU0 は可能な限り常に backward 処理を優先する(たとえば、F2 の前に B0 を実行する)ことで、アクティベーションに使用したメモリを先にクリアできるようにしています。
シンプルパイプライン
インターリーブパイプラインとは対照的に、シンプルパイプラインは、backward 処理を開始する前に、各マイクロバッチの forward 処理の実行を終了します。これは、forward 処理と backward 処理のステージをそれ自体の中でのみパイプライン化することを意味します。次の図は、2つのGPUを使用した場合の動作例を示しています。

フレームワークごとのパイプライン実行
フレームワークごとにパイプライン実行方法が異なります。ここでは、Tensorflow と PyTorch それぞれについて説明します。
Tenforflow のパイプライン実行
次の画像は、自動モデル分割を使用してモデル並列ライブラリで分割された TensorFlow グラフの例です。グラフが分割されると、各サブグラフは B回(変数を除く)複製されます(Bはマイクロバッチの数)。この図では、各サブグラフは 2回(B=2)複製されています。サブグラフの各入力には SMPInput オペレーションが挿入され、各出力には SMPOutput オペレーションが挿入されます。これらの操作は、ライブラリのバックエンドと通信して、テンソルを相互に転送します。

次の画像は、2つのサブグラフを B=2 で分割し、勾配演算を加えた例です。SMPInput op の勾配がSMPOutput op の勾配になり、その逆も同様です。これにより、バックプロパゲーション時に勾配を逆流させることができます。
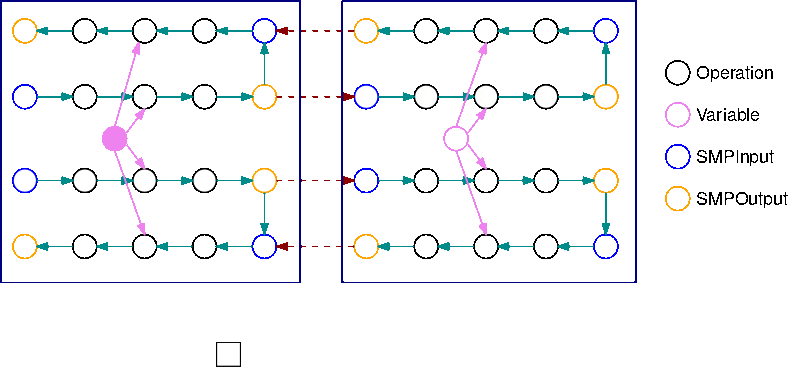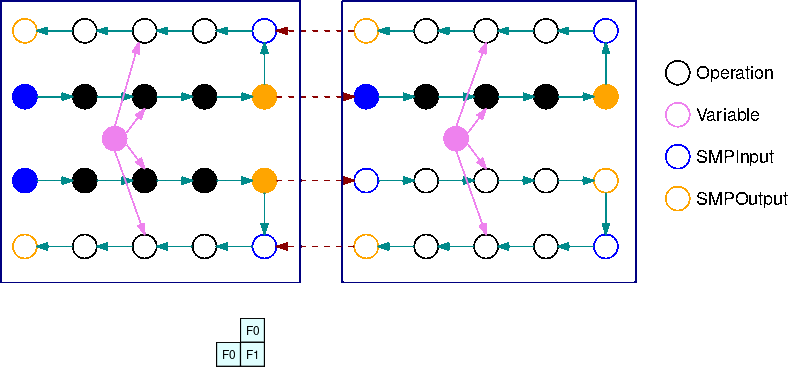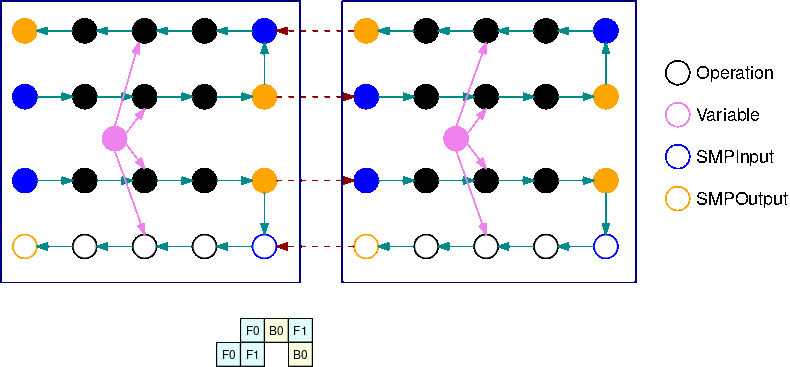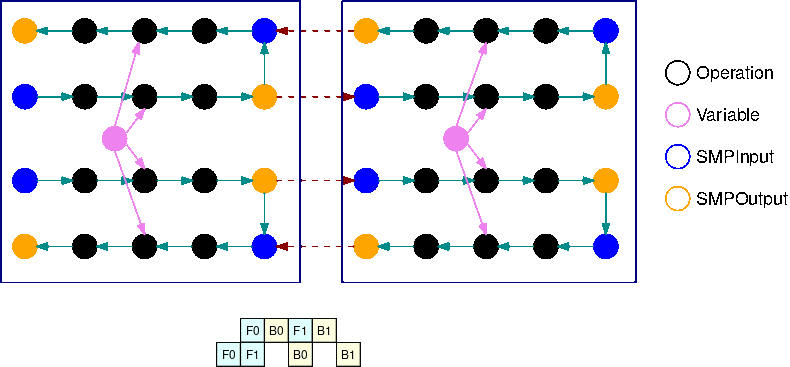
上図は、B=2 マイクロバッチと 2サブグラフのインターリーブパイプライン実行スケジュールの例を示しています。各デバイスは、GPU 利用率を向上させるために、サブグラフのレプリカの 1つを順次実行します。B が大きくなるにつれて、アイドルタイムスロットの割合はゼロに近づきます。特定のサブグラフレプリカで(forward または backward の)計算を行う時はいつでも、パイプライン層は対応する青色のSMPInput 操作に信号を送り、実行を開始します。
1つのミニバッチ内のすべてのマイクロバッチからの勾配が計算されると、ライブラリはマイクロバッチ間の勾配を結合し、パラメータに適用することができます。
PyTorch のパイプライン実行
パイプラインは概念的には PyTorch と似たような考え方をしています。しかし、PyTorch は静的なグラフを使用しないため、モデル並列ライブラリに PyTorch 用の機能では、より動的なパイプラインのパラダイムを使用しています。
TensorFlow と同様に、各バッチはいくつかのマイクロバッチに分割され、各デバイス上で一度に一つずつ実行されます。ただし、実行スケジュールは各デバイス上で起動された実行サーバを介して処理されます。他のデバイスに配置されているサブモジュールの出力が現在のデバイス上で必要になるたびに、サブモジュールへの入力テンソルとともに、リモートデバイスの実行サーバに実行要求が送られます。実行サーバは、与えられた入力でこのモジュールを実行し、その応答を現在のデバイスに返します。
リモートサブモジュールの実行中はカレントデバイスがアイドル状態なので、現在のマイクロバッチのローカル実行は一時停止し、ライブラリランタイムはカレントデバイスがアクティブに作業できる別のマイクロバッチに実行を切り替えます。マイクロバッチの優先順位は、選択したパイプラインスケジュールによって決まります。インターリーブされたパイプラインスケジュールでは、計算の backward ステージにいるマイクロバッチが可能な限り優先されます。
Model Parallel 使用前のチェックポイント
Amazon SageMaker の分散モデル並列ライブラリを使用する前に、以下のヒントと落とし穴を確認してください。このリストには、フレームワーク全体に適用可能なヒントが含まれています。TensorFlow とPyTorch 特有の Tips については、それぞれ Modify a TensorFlow Training Script と Modify a PyTorch Training Script を参照してください。
バッチサイズとマイクロバッチ数
ライブラリは、バッチサイズを大きくすると最も効率的です。モデルがひとつのデバイス内に収まるが、小さなバッチサイズでしか学習できないような場合は、モデル並列を適用する際にバッチサイズを大きくすることができます。モデル並列化により、大きなモデルのメモリを節約できるため、これまでメモリに収まらなかったバッチサイズを使用してトレーニングを行うことができりためです。
マイクロバッチの数が小さすぎたり大きすぎたりすると、パフォーマンスが低下することがあります。ライブラリは各デバイスで各マイクロバッチを順次実行するため、マイクロバッチサイズ(バッチサイズをマイクロバッチ数で割った値)は、各 GPU を十分に利用するのに十分な大きさでなければなりません。同時に、パイプラインの効率はマイクロバッチの数に応じて向上するため、適切なバランスを取ることが重要です。一般的には、2~4個のマイクロバッチを試してみて、バッチサイズをメモリ限界まで大きくしてから、より大きなバッチサイズとマイクロバッチ数で実験するのが良い出発点です。マイクロバッチの数が増えるにつれて、インターリーブパイプラインを使用する場合は、より大きなバッチサイズが可能になるかもしれません。
バッチサイズは常にマイクロバッチの数で割る必要があります。データセットのサイズによっては、エポックごとの最後のバッチのサイズが他のバッチよりも小さくなることがあることに注意してください。そうでない場合は、Tensorflow の場合 tf.Dataset.batch() コールで drop_remainder=True を設定するか、PyTorch の場合 DataLoader で drop_last=True を設定して、この最後の小さなバッチを使用しないようにします。データパイプラインに別の API を使用している場合は、マイクロバッチの数で割り切れない場合は、最後のバッチを手動でスキップする必要があるかもしれません。
手動パーティショニング
手動パーティショニングを使用する場合は、トランスアーキテクチャの埋め込みテーブルなど、モデル内の複数の操作やモジュールで消費されるパラメータに注意してください。同じパラメータを共有するモジュールは、正確性を保つために同じデバイスに配置する必要があります。自動分割を使用すると、ライブラリは自動的にこの制約を適用します。
データの準備
モデルが複数の入力を取る場合は、データパイプラインのランダム操作(例えば、シャッフル)を smp.dp_rank() でシード設定するようにしてください。データセットがデータ並列デバイス間で決定論的にシャードされている場合、シャードが smp.dp_rank() でインデックス化されていることを確認してください。これは、モデルパーティションを構成するすべてのランクで見られるデータの順序が一貫していることを確認するためです。
smp.DistributedModel から返す Tensor
Tensorflow の場合 smp.DistributedModel.call、PyTorch の場合 smp.DistributedModel.forward 関数から返されたテンソルは、その特定のテンソルを計算したランクから他のすべてのランクにブロードキャストされます。不要な通信やメモリのオーバヘッドやパフォーマンスの低下につながるため、call メソッドや forward メソッドの外で必要とされないテンソル(例えば中間活性化)は返されるべきではありません。