はじめに
「クエリできすぎくん」は、Select AIをGUI上から簡単に設定・検証できるツールです。
AIプロファイルの作成やSQL生成、フィードバック管理などを全てブラウザ操作で行えるため、データベースを普段あまり触らない方でも Select AIを気軽に試すことができます。
本記事では、「クエリできすぎくん」をOCI上にデプロイし、 サンプルデータを使ってSelect AIを実際に動かすまでの手順を解説します。
Select AIについてはこちらをご覧ください。
前提条件
- OCIのアカウントを持っていること
- OCI上にVCNを作成済みであること
環境構築
まずは「クエリできすぎくん」をデプロイします。
1. こちらからDeploy to Oracle Cloudをクリックし、OCI上にスタックを作成
2. 「Oracle使用条件を確認した上でこれに同意します。」にチェック
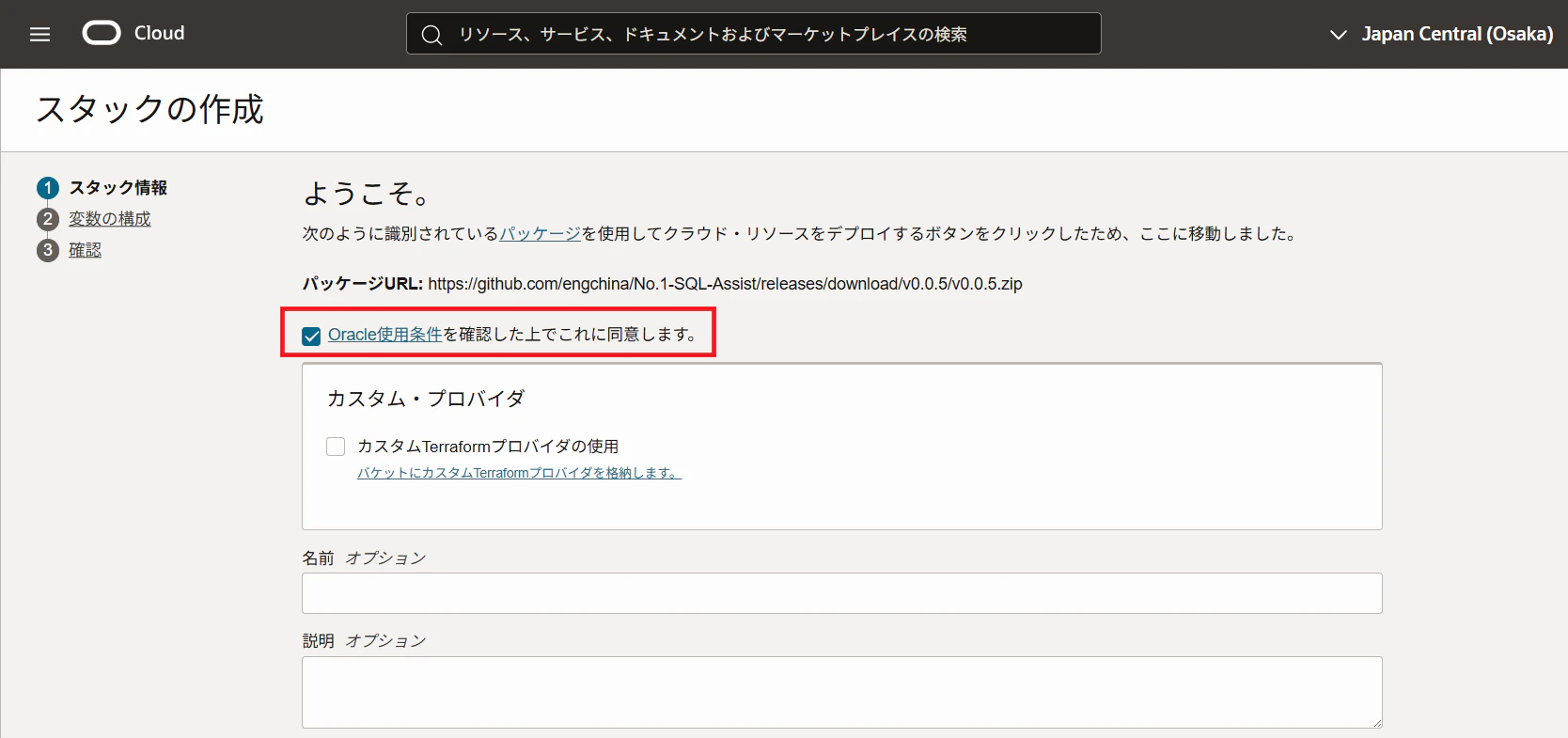
ここでエラーが出てしまう場合は、以下の方法でスタックを作成します。
1. パッケージURLからzipファイルをダウンロード
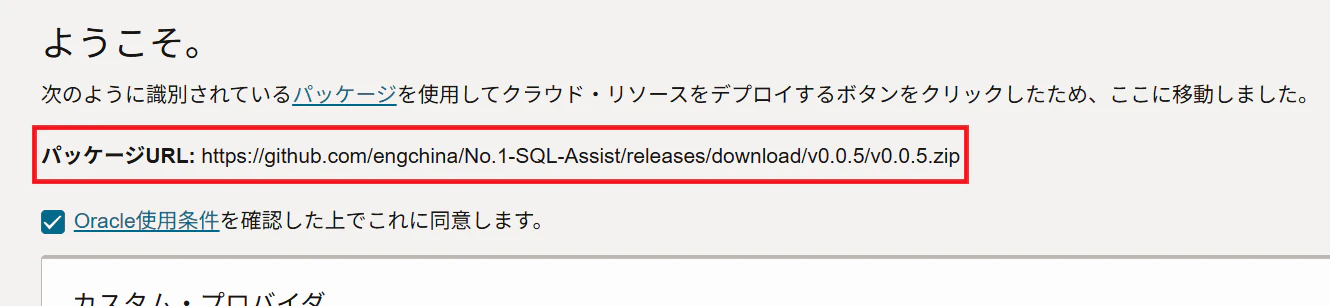
(例:https://github.com/engchina/No.1-SQL-Assist/releases/download/v0.0.5/v0.0.5.zip)
2. OCIのナビゲーション・メニューから、開発者サービス>リソース・マネージャー>スタックに遷移し、スタックの作成をクリック
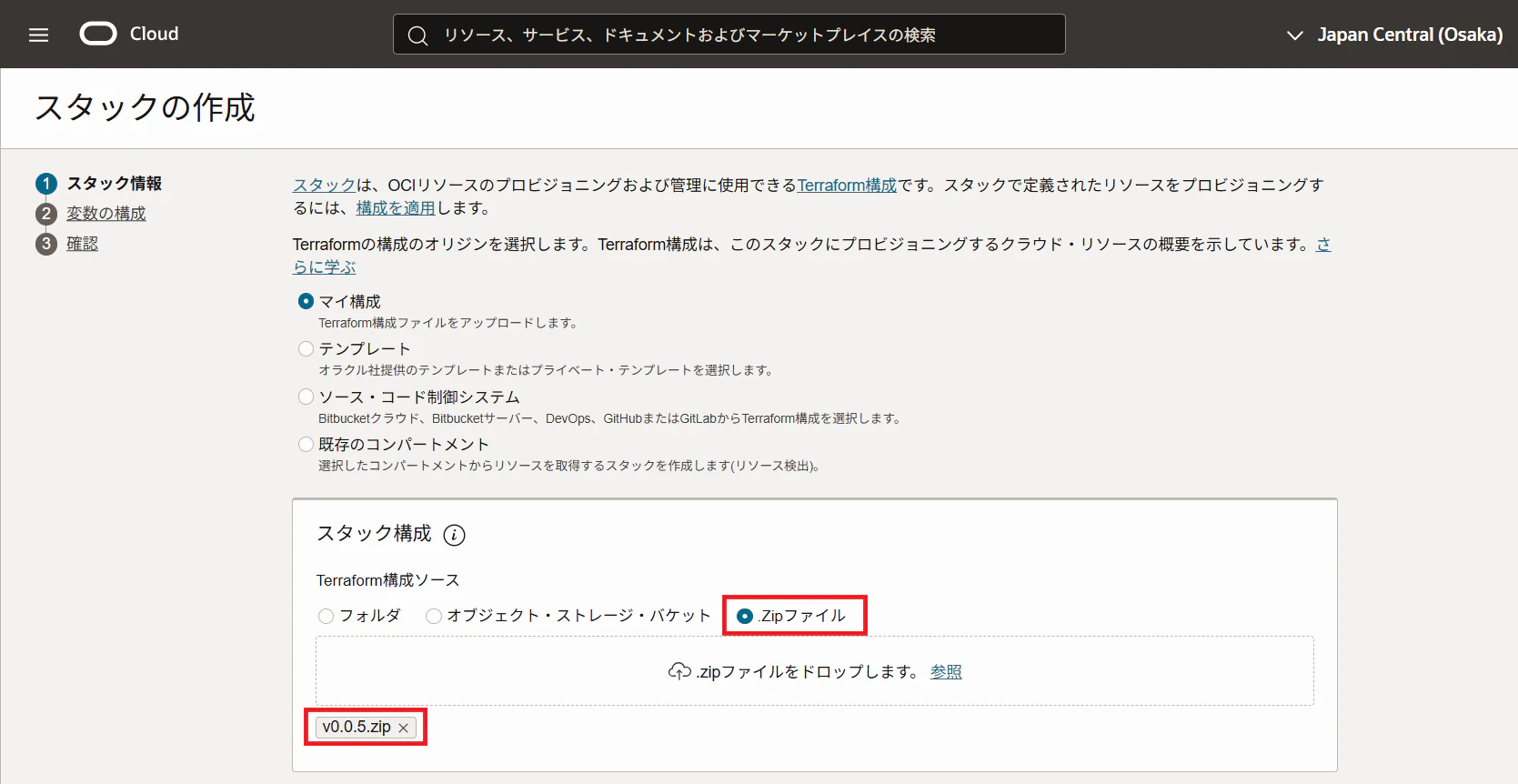
3. スタック構成で.Zipファイルを選択し、先程ダウンロードしたzipファイルを選択
3. デプロイ先のコンパートメントを選択し、「Next」をクリック
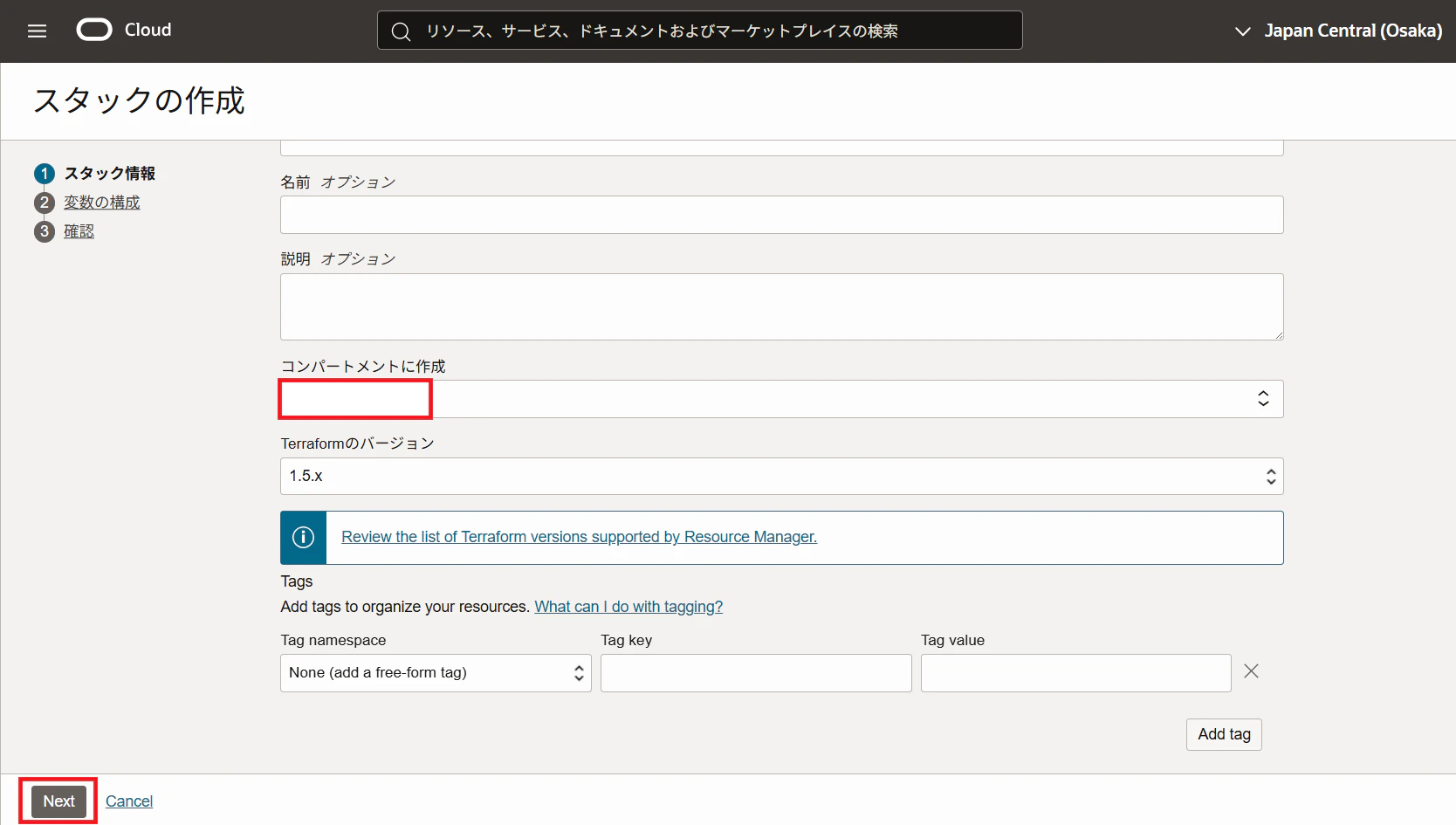
4. 以下の通りに入力し、「Next」をクリック
- Create in compartment:デプロイ先のコンパートメントを選択
- Availability domain:任意
- Database name:任意(自動作成されるADBのデータベース名)
同一テナンシ内の同一リージョンに、同じ名前のADBを作成する事は出来ません。
既に同一テナンシ内の同一リージョンに、同じ名前のADBが存在している場合、スタックのデプロイが失敗してしまうので、ADB名が被らないようにご注意ください。
- Database password:任意(ADBのADMINユーザーのパスワード)
- Compute instance name::任意(自動作成されるコンピュート名)
- VCN:事前作成済みのVCNを選択
- Subnet:作成済みVCN内のサブネットを選択
- Add SSH keys:SSHキー・ファイルをアップロード
5. 適用の実行にチェックを入れ、「作成」をクリック
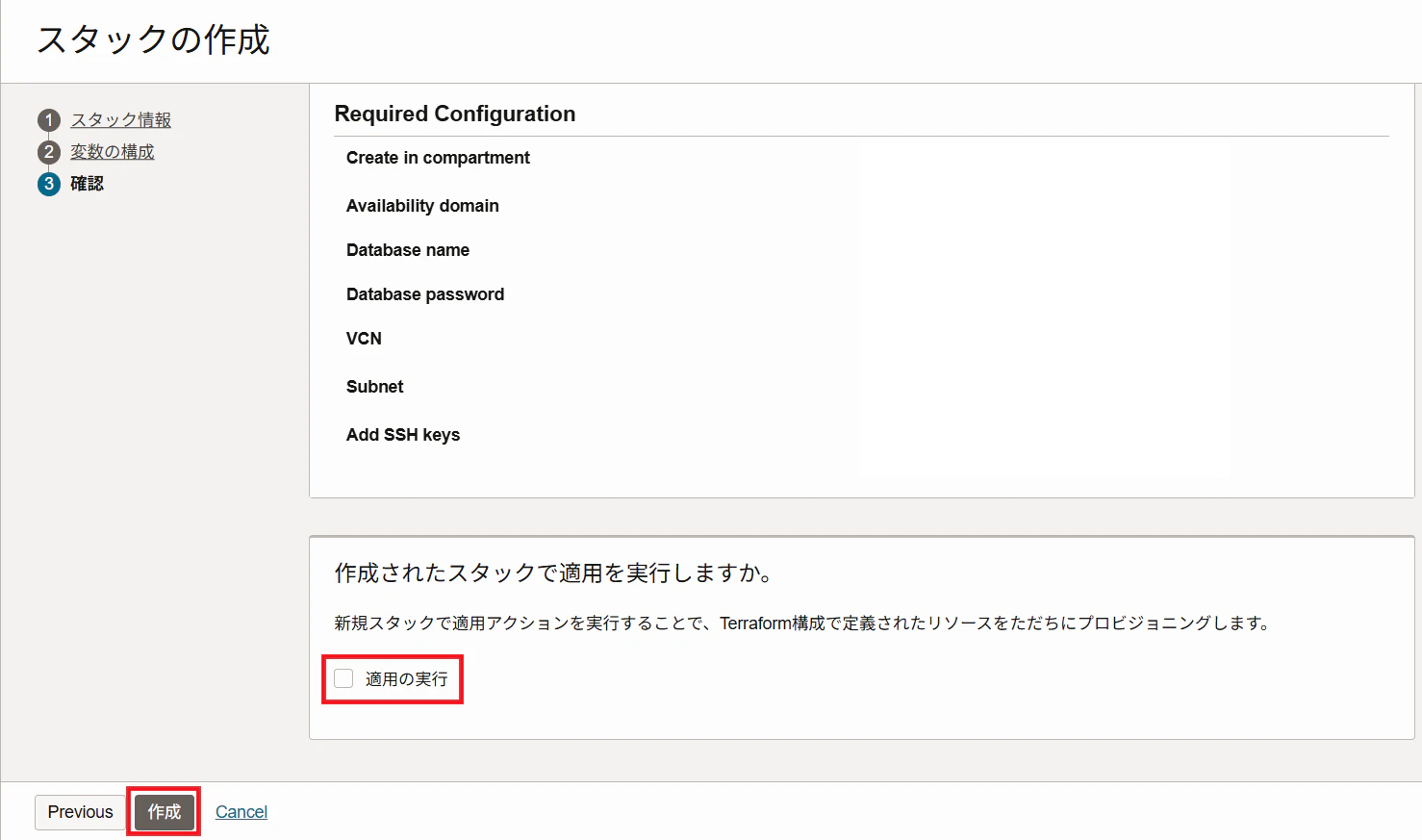
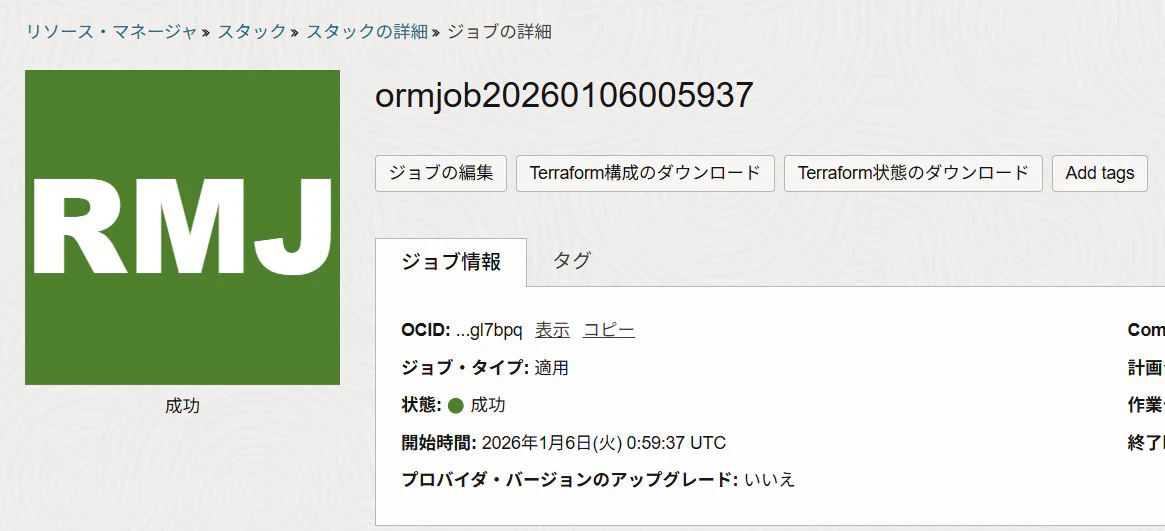
6. 全てのジョブが完了するまで1~2分程待ちます。
デプロイが成功すると「成功」と表示されます。もしエラーが起きてしまった場合は、ログをご確認ください。
7. コンピュート>インスタンスから、作成したコンピュートのIPアドレスを取得します。
http://XX.XXX.XX.XXX:8080/ のXX.XXX.XX.XXXを、取得したIPに置き換えてアクセスします。
8. ログイン画面が表示されるので、ADBのADMINユーザーとしてログインします。
- ユーザー名:ADMIN
- パスワード:デプロイ時に設定したADBのパスワード
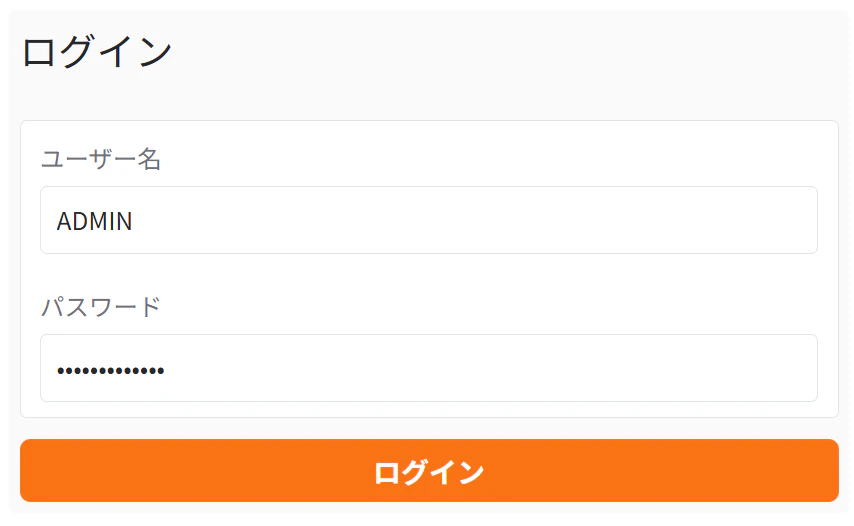
これで「クエリできすぎくん」にアクセスする事が出来る様になりました。
「クエリできすぎくん」のバージョンによって、本記事とはレイアウトや文言が異なる場合があります。ご注意ください。
環境設定
OCI認証情報設定
1. こちらを参考にAPIキーを取得します。
2. 構成ファイル内に記載があるユーザーOCID、フィンガープリント、テナンシOCIDをコピーペーストし、ダウンロードした秘密キーをアップロードします。
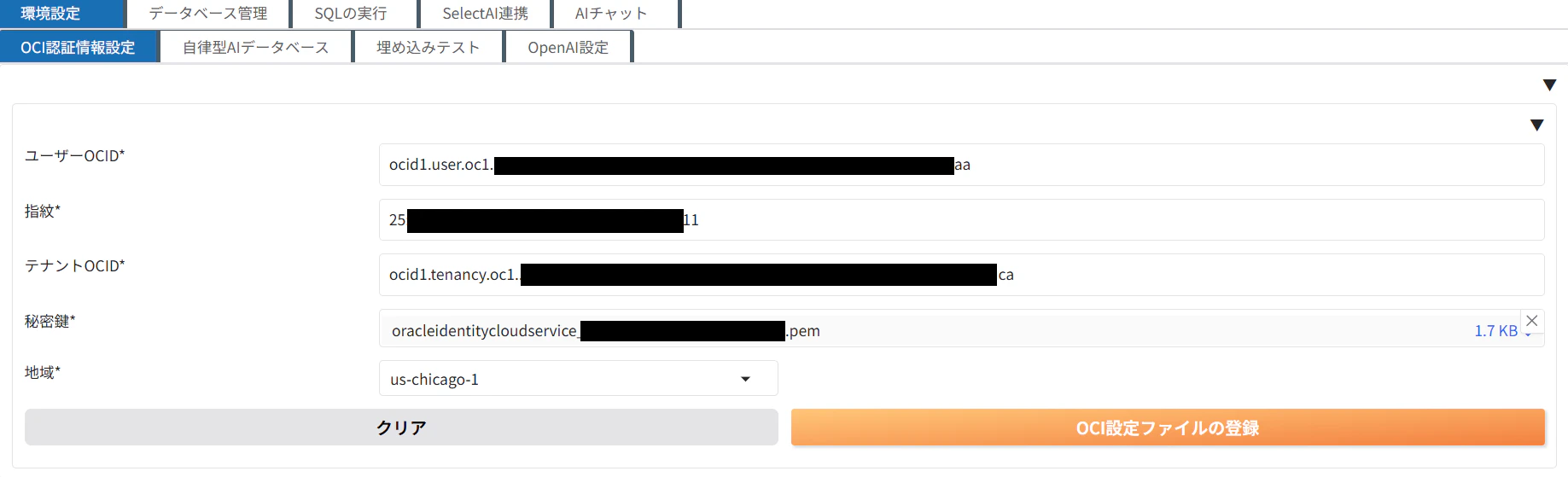
3. 「OCI設定ファイルの登録」をクリックし、APIキーを登録します。
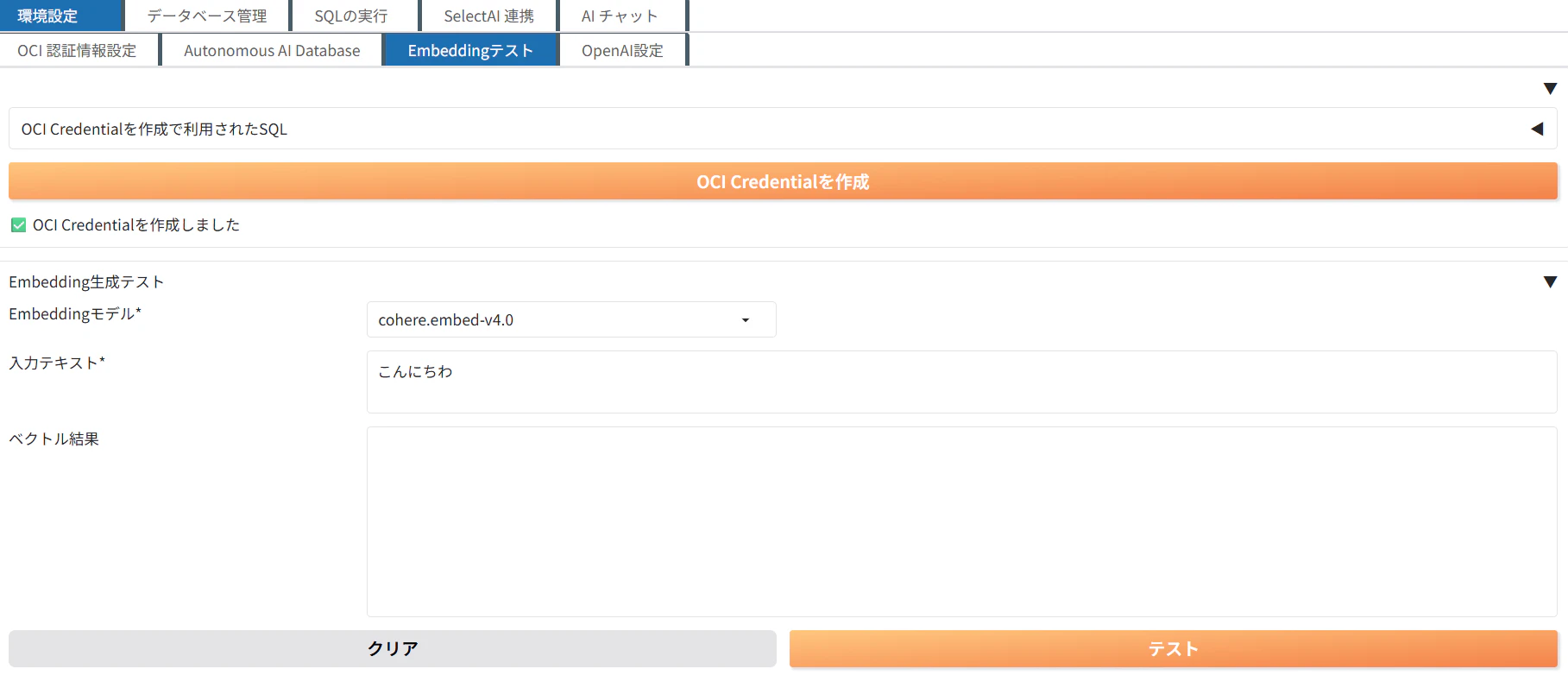
Embeddingテスト
「OCI Credentialを作成」をクリックすると、登録したAPIキーを使ってOCIのクレデンシャルを作成してくれます。クレデンシャルの作成に使用されたPL/SQLも確認する事が出来ます。
「OCI Credentialを作成」をクリックし、クレデンシャルを作成します。
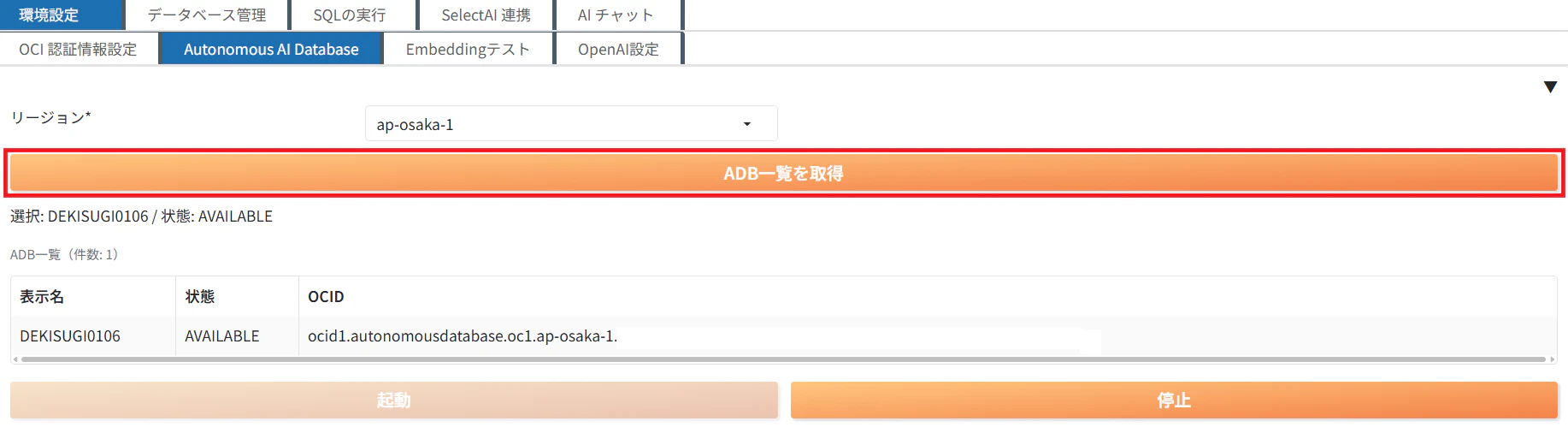
Autonomous AI Database
ADB一覧を取得をクリックすると、デプロイしたADBを表示する事が出来ます。ADBの起動や停止をこの画面から行う事が出来ます。
データベース管理
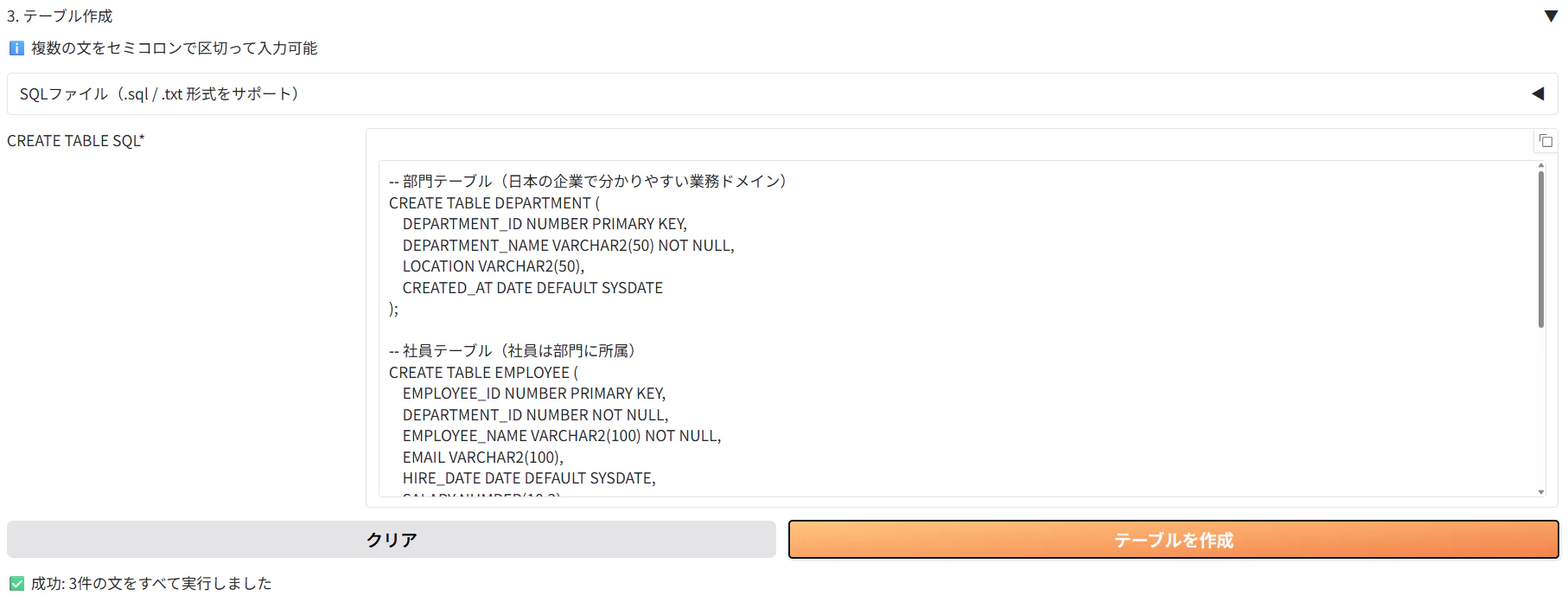
テーブルの管理
先ずはADB内に表を作成します。サンプルのCREATE TABLE文を貼り付け、「テーブルを作成」をクリックします。部門表、社員表、プロジェクト表の3つを作成します。
CREATE TABLE文はこちら
-- 部門テーブル(日本の企業で分かりやすい業務ドメイン)
CREATE TABLE DEPARTMENT (
DEPARTMENT_ID NUMBER PRIMARY KEY,
DEPARTMENT_NAME VARCHAR2(50) NOT NULL,
LOCATION VARCHAR2(50),
CREATED_AT DATE DEFAULT SYSDATE
);
-- 社員テーブル(社員は部門に所属)
CREATE TABLE EMPLOYEE (
EMPLOYEE_ID NUMBER PRIMARY KEY,
DEPARTMENT_ID NUMBER NOT NULL,
EMPLOYEE_NAME VARCHAR2(100) NOT NULL,
EMAIL VARCHAR2(100),
HIRE_DATE DATE DEFAULT SYSDATE,
SALARY NUMBER(10,2),
CONSTRAINT FK_EMP_DEPT FOREIGN KEY (DEPARTMENT_ID)
REFERENCES DEPARTMENT(DEPARTMENT_ID)
);
-- プロジェクトテーブル(プロジェクトは部門が担当)
CREATE TABLE PROJECT (
PROJECT_ID NUMBER PRIMARY KEY,
DEPARTMENT_ID NUMBER NOT NULL,
PROJECT_NAME VARCHAR2(100) NOT NULL,
START_DATE DATE,
BUDGET NUMBER(12,2),
CONSTRAINT FK_PROJ_DEPT FOREIGN KEY (DEPARTMENT_ID)
REFERENCES DEPARTMENT(DEPARTMENT_ID)
);
「テーブル一覧を取得」をクリックすると、作成した表を確認する事が出来ます。
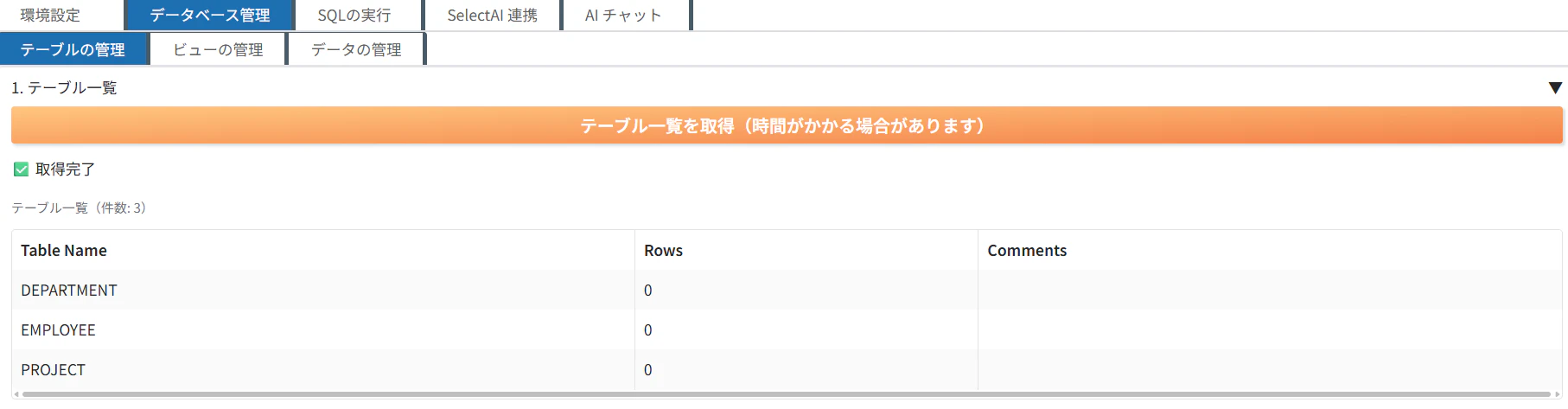
データの管理
作成した表にデータを挿入します。サンプルのINSERT文を貼り付け、「実行」をクリックします。
INSERT文はこちら
INSERT INTO DEPARTMENT (DEPARTMENT_ID, DEPARTMENT_NAME, LOCATION) VALUES (10, '総務', '東京');
INSERT INTO DEPARTMENT (DEPARTMENT_ID, DEPARTMENT_NAME, LOCATION) VALUES (20, '経理', '東京');
INSERT INTO DEPARTMENT (DEPARTMENT_ID, DEPARTMENT_NAME, LOCATION) VALUES (30, '人事', '大阪');
INSERT INTO DEPARTMENT (DEPARTMENT_ID, DEPARTMENT_NAME, LOCATION) VALUES (40, '営業', '名古屋');
INSERT INTO DEPARTMENT (DEPARTMENT_ID, DEPARTMENT_NAME, LOCATION) VALUES (50, '開発', '福岡');
INSERT INTO DEPARTMENT (DEPARTMENT_ID, DEPARTMENT_NAME, LOCATION) VALUES (60, 'サポート', '札幌');
INSERT INTO DEPARTMENT (DEPARTMENT_ID, DEPARTMENT_NAME, LOCATION) VALUES (70, '企画', '仙台');
INSERT INTO DEPARTMENT (DEPARTMENT_ID, DEPARTMENT_NAME, LOCATION) VALUES (80, 'マーケティング', '神戸');
INSERT INTO DEPARTMENT (DEPARTMENT_ID, DEPARTMENT_NAME, LOCATION) VALUES (90, '品質保証', '京都');
INSERT INTO DEPARTMENT (DEPARTMENT_ID, DEPARTMENT_NAME, LOCATION) VALUES (100, '法務', '横浜');
INSERT INTO EMPLOYEE (EMPLOYEE_ID, DEPARTMENT_ID, EMPLOYEE_NAME, EMAIL, SALARY) VALUES (1, 10, '佐藤 太郎', 'taro.sato@example.com', 420000);
INSERT INTO EMPLOYEE (EMPLOYEE_ID, DEPARTMENT_ID, EMPLOYEE_NAME, EMAIL, SALARY) VALUES (2, 20, '鈴木 花子', 'hanako.suzuki@example.com', 510000);
INSERT INTO EMPLOYEE (EMPLOYEE_ID, DEPARTMENT_ID, EMPLOYEE_NAME, EMAIL, SALARY) VALUES (3, 30, '高橋 健', 'ken.takahashi@example.com', 480000);
INSERT INTO EMPLOYEE (EMPLOYEE_ID, DEPARTMENT_ID, EMPLOYEE_NAME, EMAIL, SALARY) VALUES (4, 40, '田中 美咲', 'misaki.tanaka@example.com', 550000);
INSERT INTO EMPLOYEE (EMPLOYEE_ID, DEPARTMENT_ID, EMPLOYEE_NAME, EMAIL, SALARY) VALUES (5, 50, '伊藤 直樹', 'naoki.ito@example.com', 600000);
INSERT INTO EMPLOYEE (EMPLOYEE_ID, DEPARTMENT_ID, EMPLOYEE_NAME, EMAIL, SALARY) VALUES (6, 50, '渡辺 真央', 'mao.watanabe@example.com', 620000);
INSERT INTO EMPLOYEE (EMPLOYEE_ID, DEPARTMENT_ID, EMPLOYEE_NAME, EMAIL, SALARY) VALUES (7, 40, '山本 大輔', 'daisuke.yamamoto@example.com', 530000);
INSERT INTO EMPLOYEE (EMPLOYEE_ID, DEPARTMENT_ID, EMPLOYEE_NAME, EMAIL, SALARY) VALUES (8, 30, '中村 さくら', 'sakura.nakamura@example.com', 470000);
INSERT INTO EMPLOYEE (EMPLOYEE_ID, DEPARTMENT_ID, EMPLOYEE_NAME, EMAIL, SALARY) VALUES (9, 20, '小林 翔', 'sho.kobayashi@example.com', 520000);
INSERT INTO EMPLOYEE (EMPLOYEE_ID, DEPARTMENT_ID, EMPLOYEE_NAME, EMAIL, SALARY) VALUES (10, 10, '加藤 恵', 'megumi.kato@example.com', 450000);
INSERT INTO EMPLOYEE (EMPLOYEE_ID, DEPARTMENT_ID, EMPLOYEE_NAME, EMAIL, SALARY) VALUES (11, 60, '吉田 光', 'hikari.yoshida@example.com', 400000);
INSERT INTO EMPLOYEE (EMPLOYEE_ID, DEPARTMENT_ID, EMPLOYEE_NAME, EMAIL, SALARY) VALUES (12, 70, '佐々木 蓮', 'ren.sasaki@example.com', 460000);
INSERT INTO PROJECT (PROJECT_ID, DEPARTMENT_ID, PROJECT_NAME, START_DATE, BUDGET) VALUES (101, 50, '受注管理システム', DATE '2025-04-01', 15000000);
INSERT INTO PROJECT (PROJECT_ID, DEPARTMENT_ID, PROJECT_NAME, START_DATE, BUDGET) VALUES (102, 40, '新製品販売強化', DATE '2025-05-01', 8000000);
INSERT INTO PROJECT (PROJECT_ID, DEPARTMENT_ID, PROJECT_NAME, START_DATE, BUDGET) VALUES (103, 20, '会計自動化', DATE '2025-02-01', 6000000);
INSERT INTO PROJECT (PROJECT_ID, DEPARTMENT_ID, PROJECT_NAME, START_DATE, BUDGET) VALUES (104, 10, '社内ポータル刷新', DATE '2025-01-15', 3000000);
INSERT INTO PROJECT (PROJECT_ID, DEPARTMENT_ID, PROJECT_NAME, START_DATE, BUDGET) VALUES (105, 60, '顧客サポート改善', DATE '2025-03-10', 5000000);
INSERT INTO PROJECT (PROJECT_ID, DEPARTMENT_ID, PROJECT_NAME, START_DATE, BUDGET) VALUES (106, 70, '市場調査強化', DATE '2025-06-01', 4000000);
INSERT INTO PROJECT (PROJECT_ID, DEPARTMENT_ID, PROJECT_NAME, START_DATE, BUDGET) VALUES (107, 90, '品質監査強化', DATE '2025-07-01', 3500000);
INSERT INTO PROJECT (PROJECT_ID, DEPARTMENT_ID, PROJECT_NAME, START_DATE, BUDGET) VALUES (108, 50, '開発基盤整備', DATE '2025-03-01', 12000000);
INSERT INTO PROJECT (PROJECT_ID, DEPARTMENT_ID, PROJECT_NAME, START_DATE, BUDGET) VALUES (109, 40, '大口顧客開拓', DATE '2025-04-15', 7000000);
INSERT INTO PROJECT (PROJECT_ID, DEPARTMENT_ID, PROJECT_NAME, START_DATE, BUDGET) VALUES (110, 30, '採用強化', DATE '2025-02-20', 2000000);
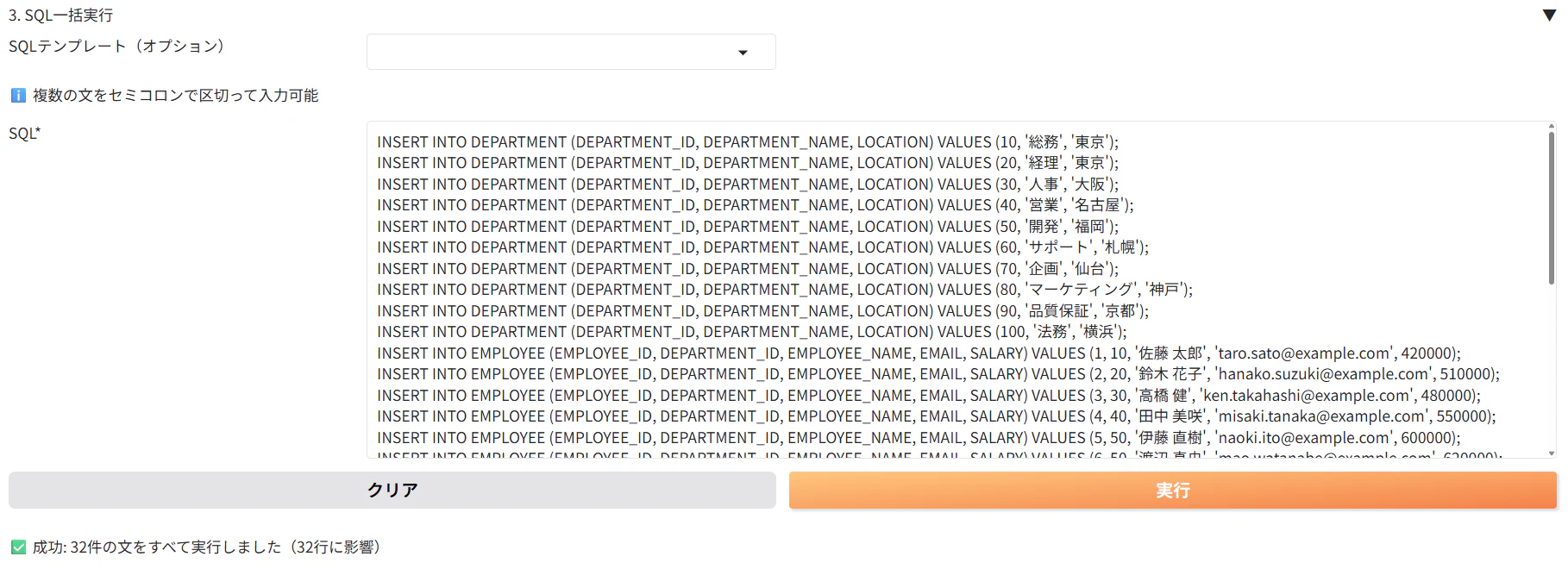
これでサンプルデータを準備することが出来ました。
Select AI連携
環境構築・環境設定が終わったので、早速Select AIを試してみたいと思います。
開発者機能
プロファイル管理
先ずはSelect AIを使用するのに必要な、AIプロファイルを作成します。
AIプロファイルでは、使用するLLM、回答生成に使用するデータ(例:売上分析をしたい場合→売上に関する表を選択)を設定します。表やビューのメタデータのみを使用するので、基本的に中身の実データはLLMに送信されません。
以下の様に入力し、「作成」をクリックします:
- Profile名:任意
同じ名前のAIプロファイルは作成不可なので、ユニークな名前にします
- カテゴリ:任意(本記事ではテストとしておきます)
Select AIではAIプロファイル作成時に「カテゴリ」を設定する事は出来ません。「クエリできすぎくん」のみで提供している機能になります。カテゴリに関しては次の記事で試してみたいと思います。
- テーブル選択:DEPARTMENT、EMPLOYEE、PROJECT(「テーブル・ビュー一覧を取得」をクリックすると表示されます。今回は3つの表を検索の対象とします。)
- Region:us-chicago-1
- Model:任意
- Embedding Model:任意
- Enforce Object List:任意
- Comments:任意(表やビューへのコメントをLLMに送信する場合にはtrueにします。本記事ではtrueを選択します)
- Annotations:任意(表やビューへのアノテーションをLLMに送信する場合にはtrueにします。本記事ではtrueを選択します)
- Constraints:任意
- Max Tokens:任意
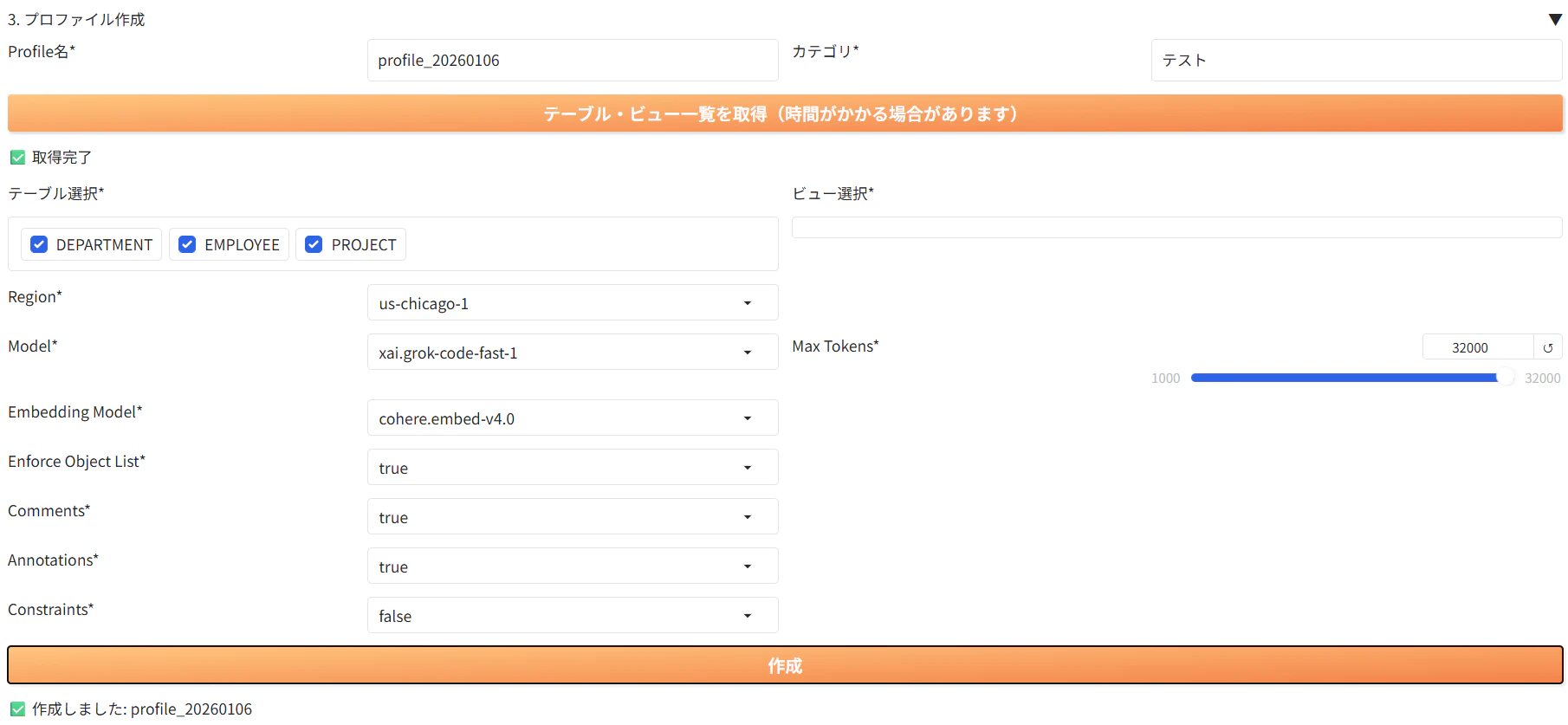
チャット分析
AIプロファイルも作成したので、Select AIの検証をしてみます。
クエリ生成
1. まず、従業員の平均給与が一番高い部門と、その部門が担当しているプロジェクト一覧と記載し、「実行」をクリックします。
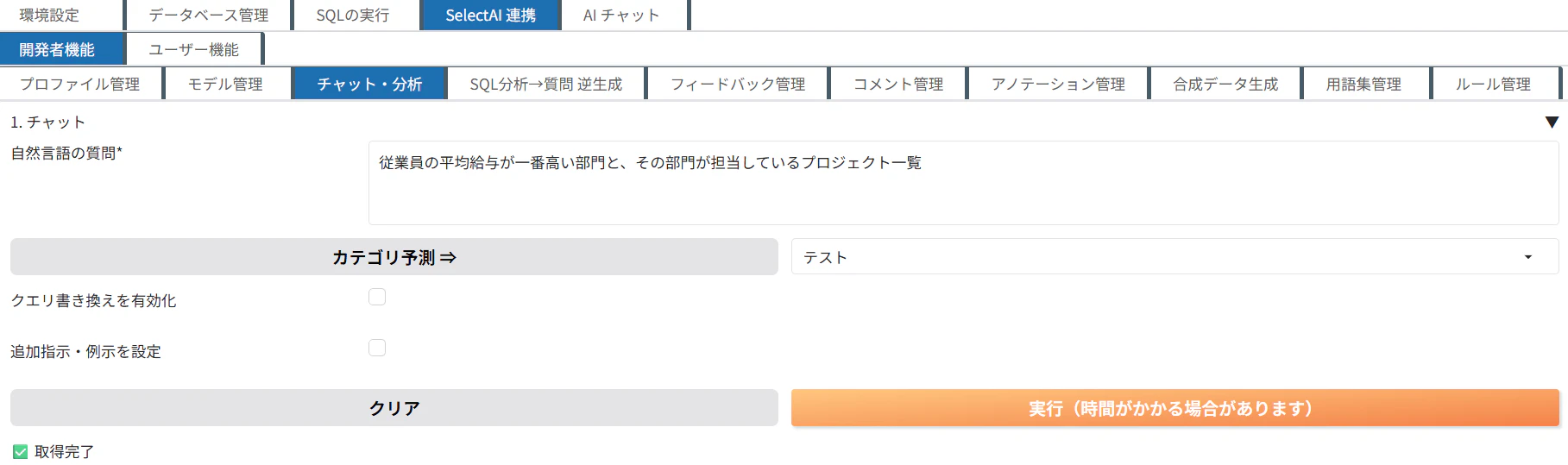
「従業員の平均給与が一番高い部門と、その部門が担当しているプロジェクト一覧」を調べるために実行するSQLクエリが生成されました。

「カテゴリ予測」と「クエリ置き換え」、「追加指示」は次の記事で検証してみます
2. 「AI分析」をクリックし、生成されたクエリの説明をしてもらいます。
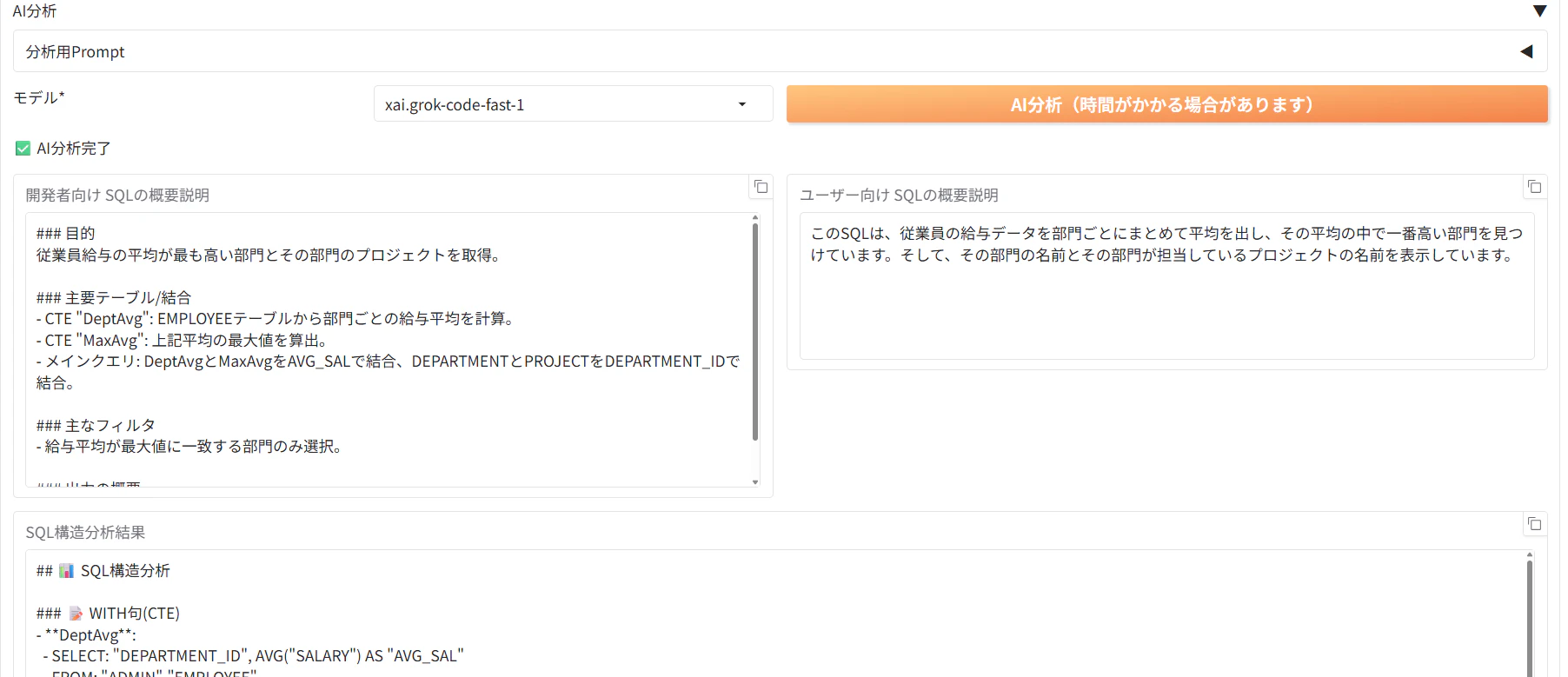
3. 実行結果も確認する事が出来ました。

フィードバックの追加
Select AIを使用して生成されたクエリや結果が期待通りのものでない場合、フィードバックを送信し、結果を改善してもらうことができます。
1. 部門ごとの従業員の平均給与と部門ごとのプロジェクトの平均予算と質問してみます。
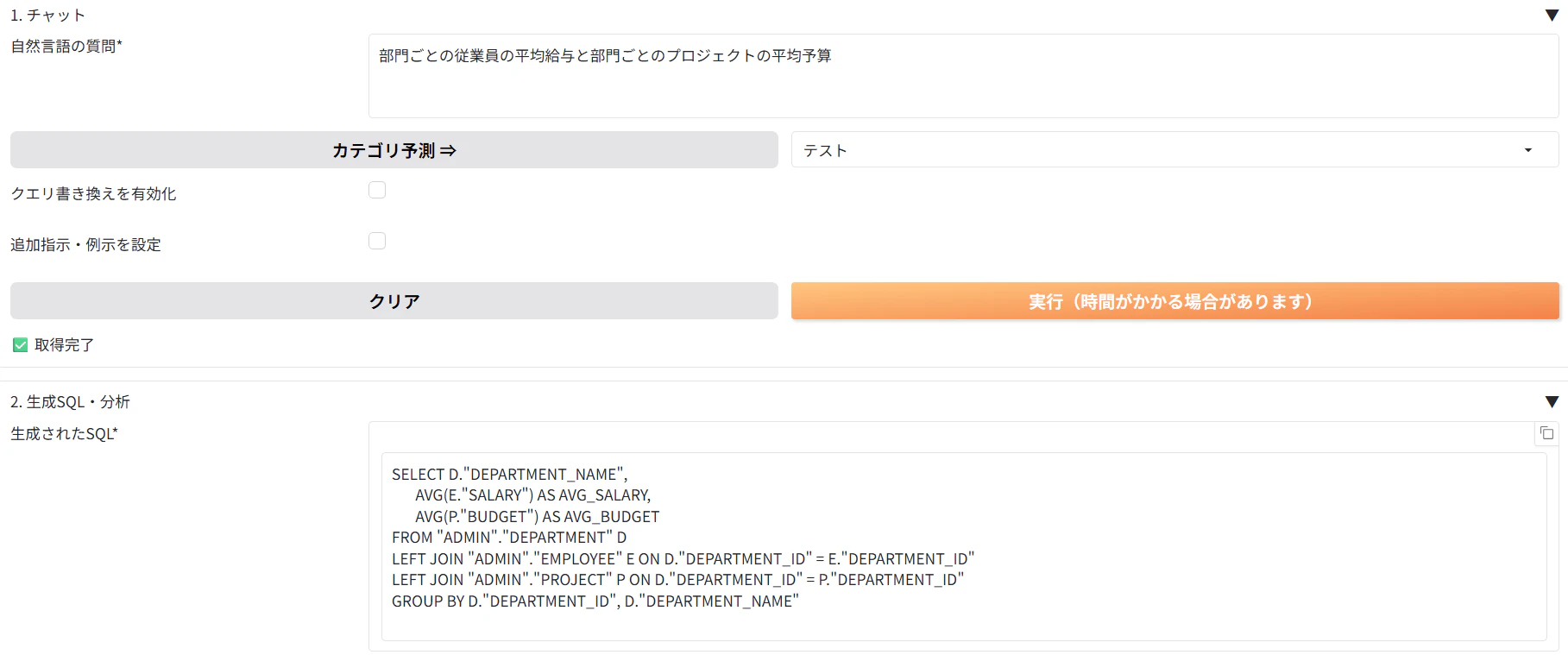
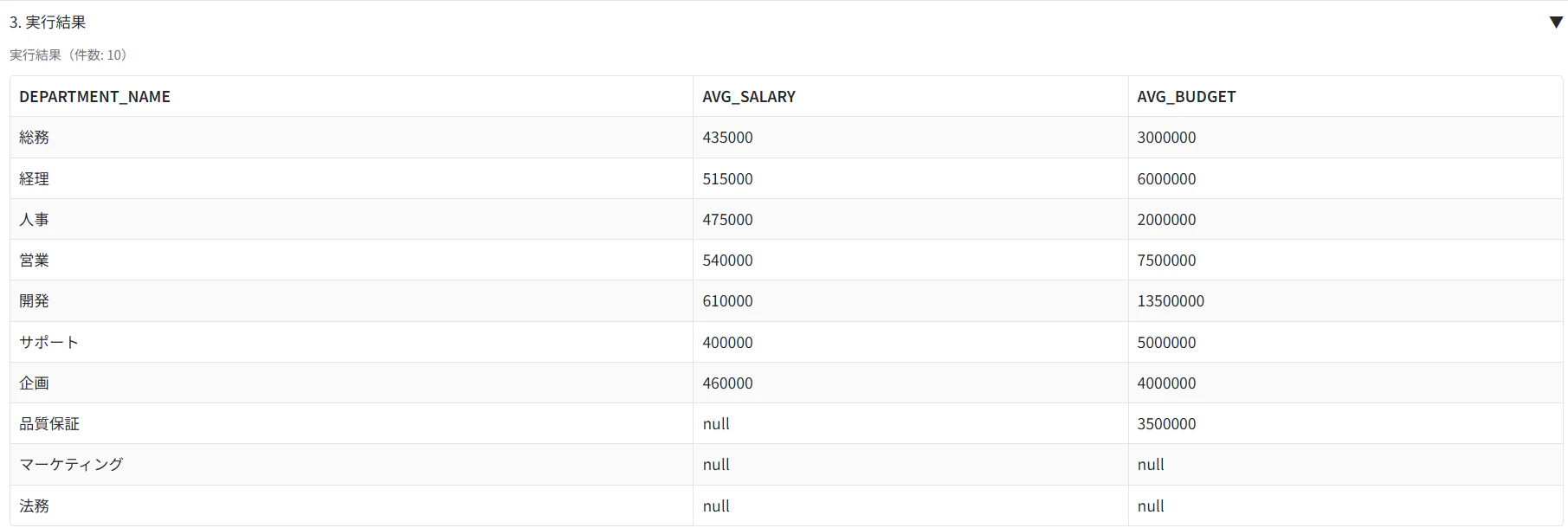
実行結果を確認してみると、null値も表示されてしまいました。
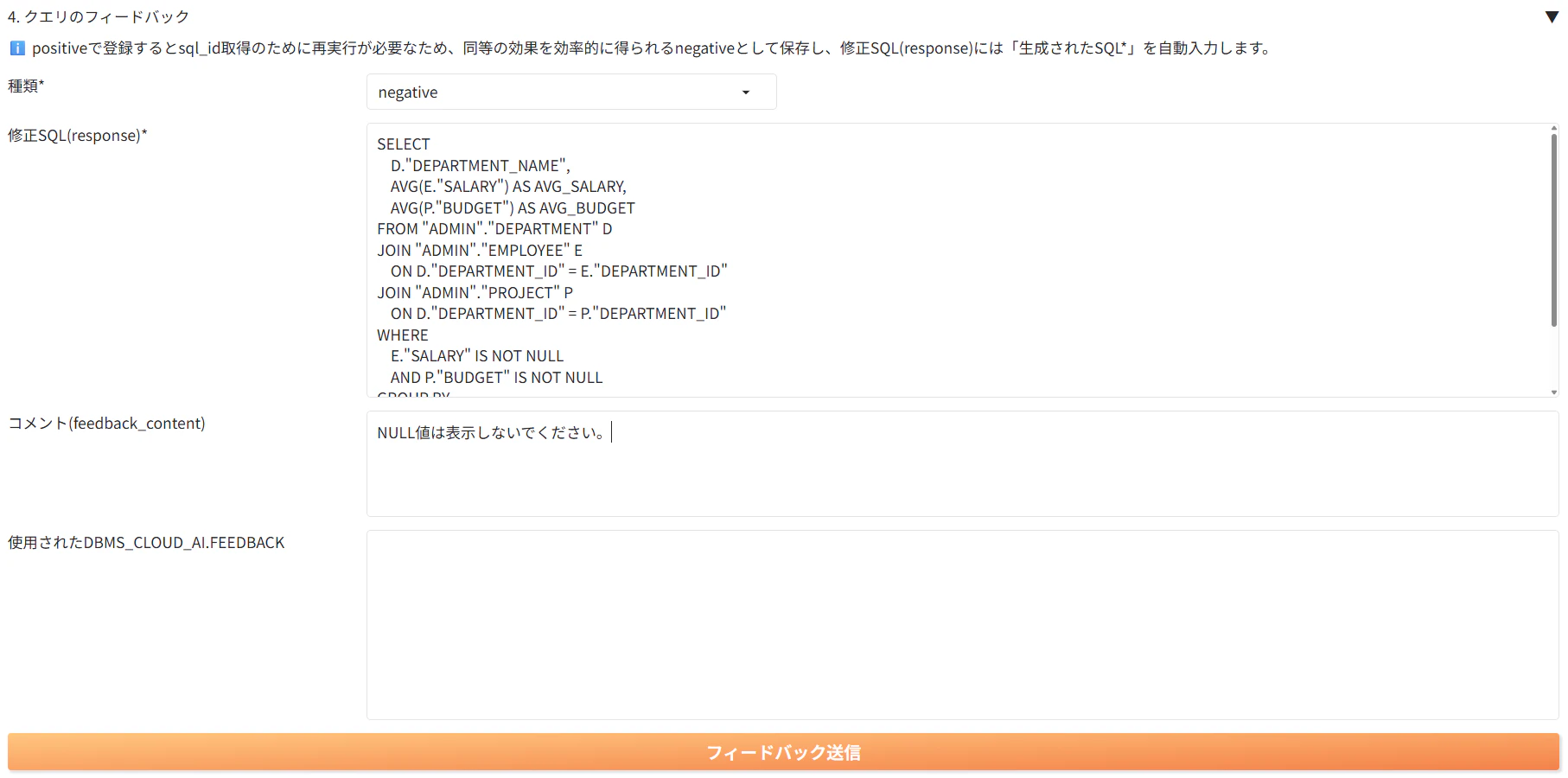
2. null値を表示しないようにフィードバックを送信します。以下の通りに入力し、「フィードバックを送信」をクリックします。
- 種類:negative
- 修正SQL(response):
SELECT
D."DEPARTMENT_NAME",
AVG(E."SALARY") AS AVG_SALARY,
AVG(P."BUDGET") AS AVG_BUDGET
FROM "ADMIN"."DEPARTMENT" D
JOIN "ADMIN"."EMPLOYEE" E
ON D."DEPARTMENT_ID" = E."DEPARTMENT_ID"
JOIN "ADMIN"."PROJECT" P
ON D."DEPARTMENT_ID" = P."DEPARTMENT_ID"
WHERE
E."SALARY" IS NOT NULL
AND P."BUDGET" IS NOT NULL
GROUP BY
D."DEPARTMENT_ID",
D."DEPARTMENT_NAME";
- コメント:NULL値は表示しないでください。
3. 画面上部に戻り、再度同じ質問をしてみます。
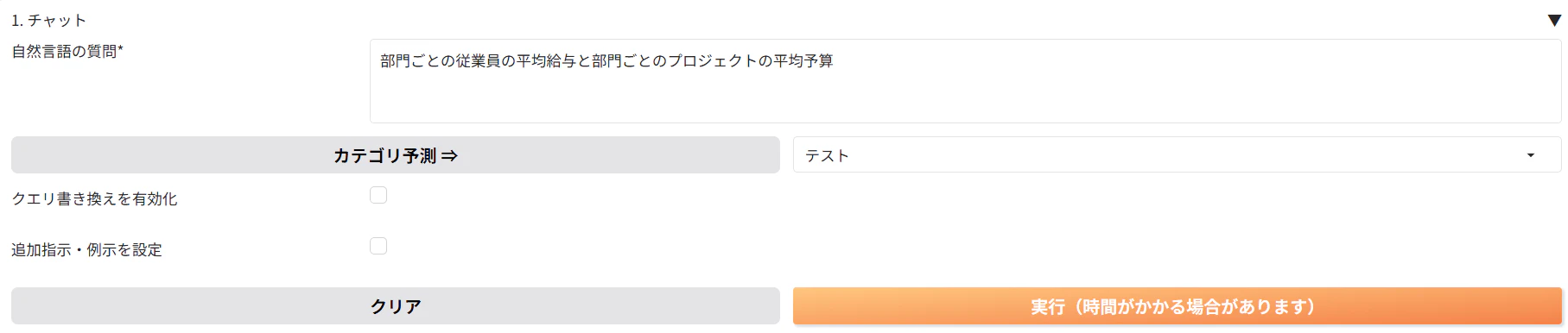
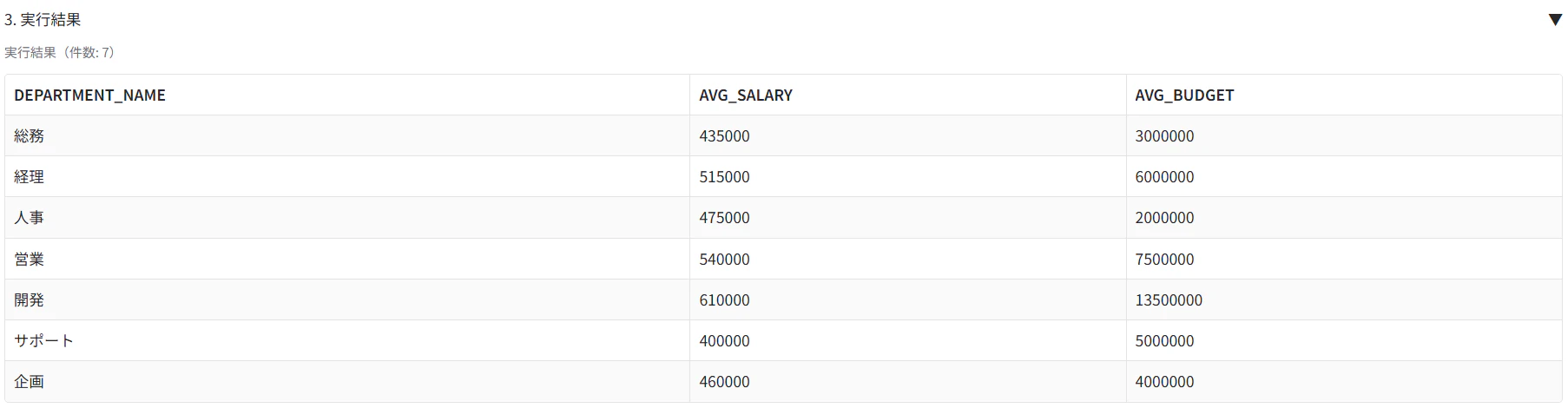
null値が表示されなくなりました。
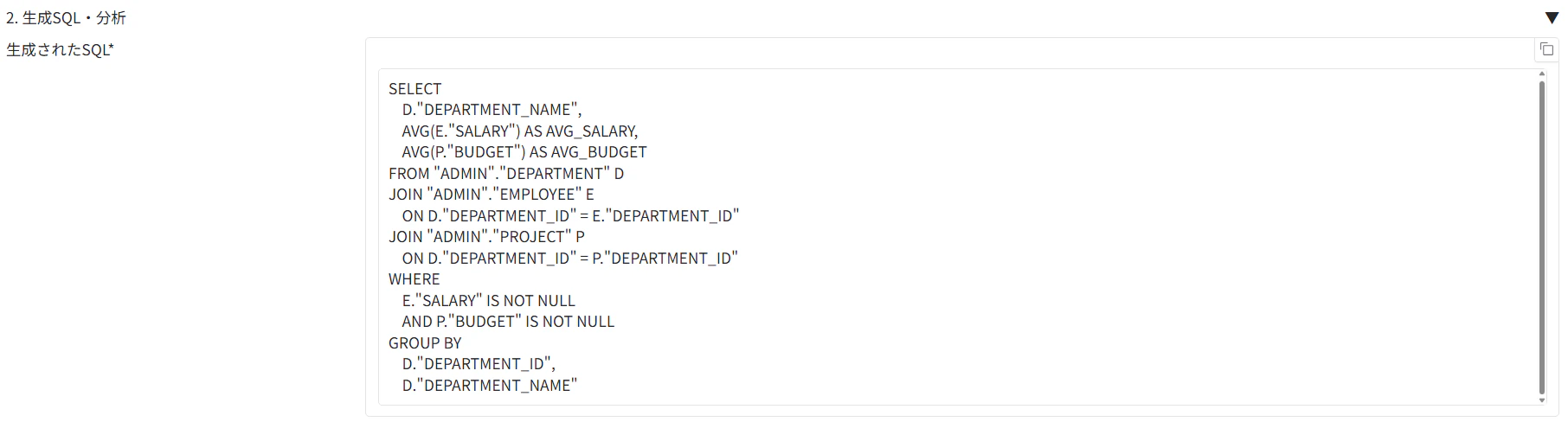
SQLクエリを確認すると、フィードバックとして送信したクエリの内容を反映した形で、SQLが生成されていることが分かります。
フィードバック機能について、詳しくはこちらの記事をご覧ください。
「クエリできすぎくん」上ではフィードバックを送信する際に、正解SQL(期待するSQLクエリ)の送信が必須ですが、SQL Developer上などからSelect AIを試すときには、正解SQLを送信せずに、自然言語のみでフィードバックを送信することが出来ます。
フィードバック管理
送信したフィードバック一覧を確認する事が出来ます。作成されたベクトル索引のSimilarity_ThresholdとMatch_Limitも変更することができます。
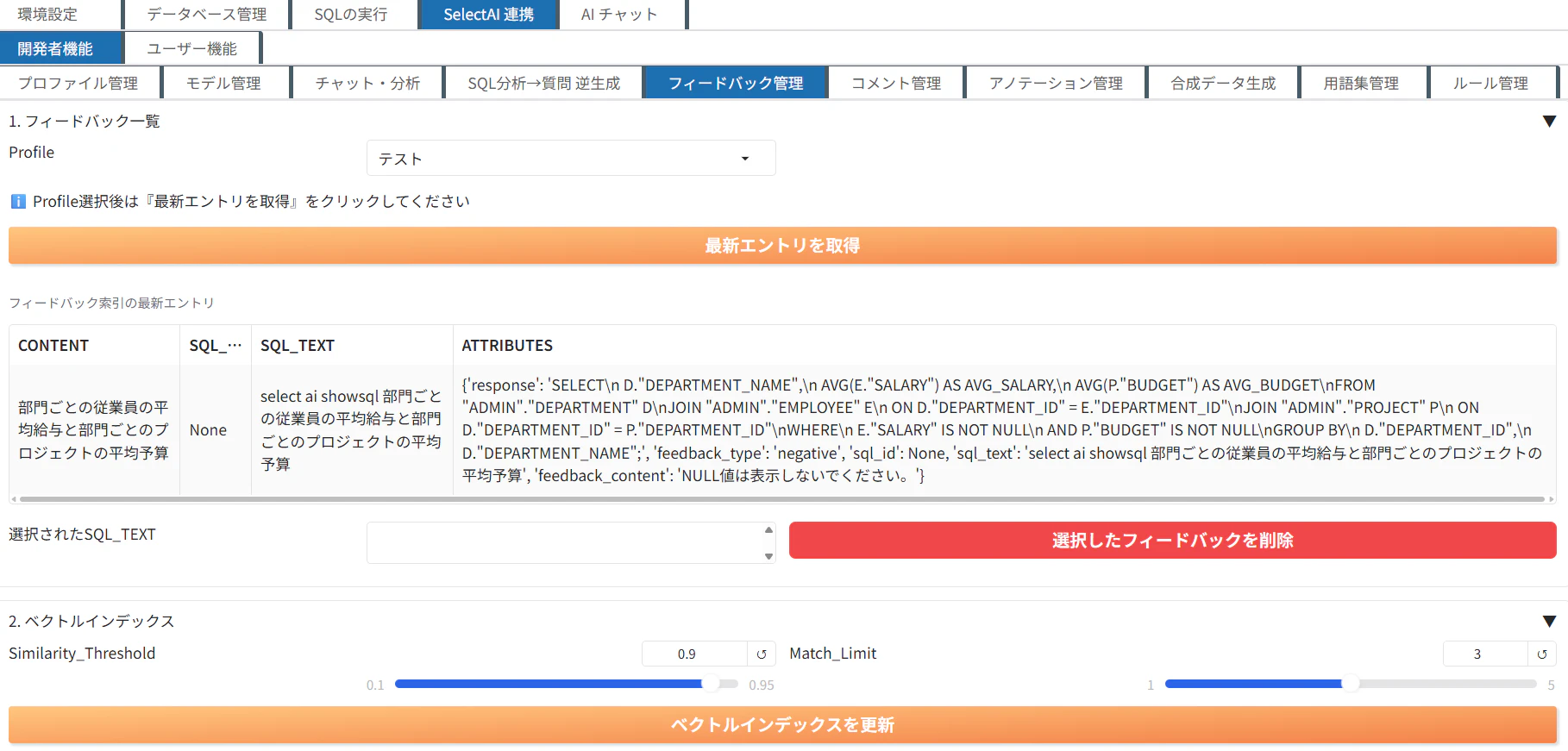
コメント管理
表やビューに対してコメントを追加する事が出来ます。コメントの生成も行う事が出来ます。
前述のように、Select AIでは実データではなくメタデータを使ってSQLクエリを生成します。
本記事で使用したデータのように、誰が見てもどんなデータが格納されているか分かる表名・列名であれば問題ありませんが、一般的でない用語や記号が使われている場合には、補足する必要があります。
作成した表に対してコメントを追加してみたいと思います。
1. 「テーブル・ビュー一覧を取得」をクリックし、任意の表を選択します。
コメントを生成させるために、実データをサンプルとして使用します。サンプルとして使用するデータの件数を指定します。サンプルをLLMに送りたくない場合は、0とします。

2. 情報を取得をクリックし、選択した表の構造情報等を確認します。

3. モデルを選択し、「生成」をクリックします。
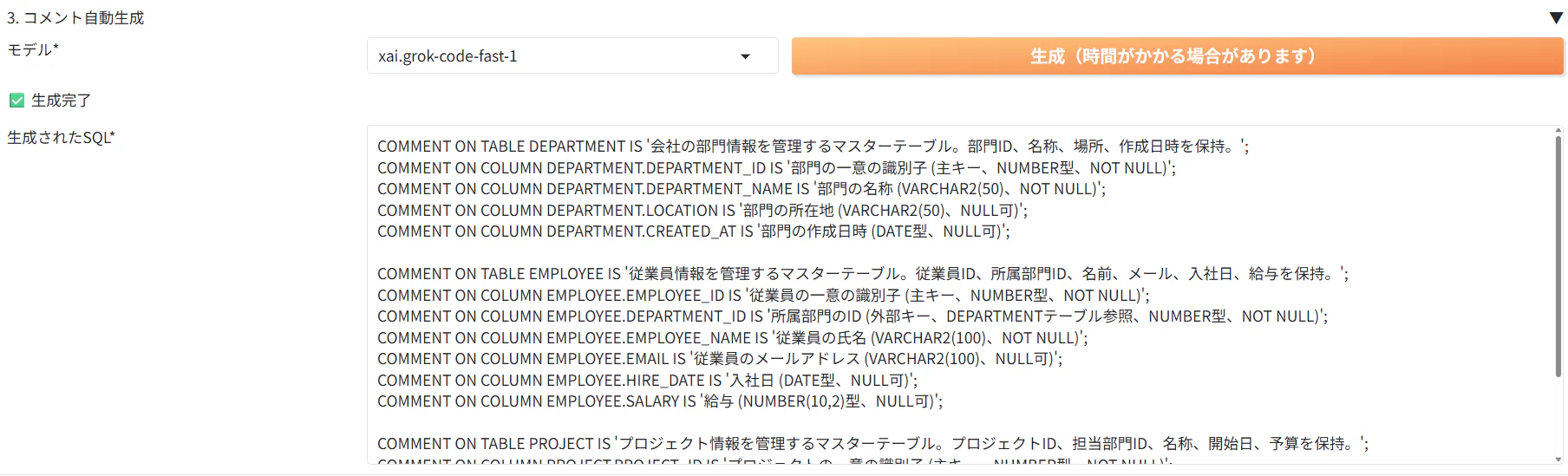
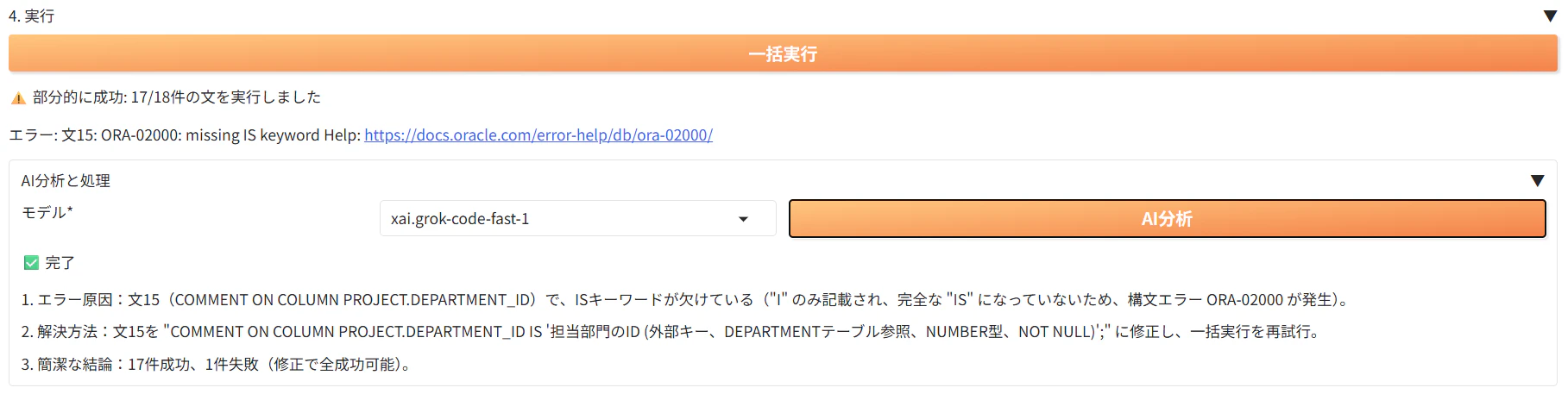
4. 生成されたSQLクエリを確認し、問題がなければ「一括実行」をクリックし、コメントを追加します。

もしエラーが出た場合には、「AI分析」をクリックするとエラーの原因を詳しく教えてくれます。
まとめ
AIプロファイルの作成やコメント・アノテーションの追加をGUI上から行う事が出来、とても便利でした。Database ActionsやSQL Developer等からクエリを実行する必要がないので、データベースを普段触らない方でも使用のハードルが下がると思います。
コメントやアノテーションは、LLMを使用した生成+付与を行えたので、手動で入力する手間が省けました。SQLを実行してエラーが出ても、AI分析でエラーの内容を分かりやすく教えてくれるので、比較的簡単にエラーを解決する事が出来ます。
次回は「カテゴリ予測」、「クエリ置き換え」、「追加指示」を試してみたいと思います。