RAG
RAG(Retrieval-Augmented Generation)は、
『ナレッジベースを基盤モデルに取り込み、コンテキストに基づいた正確な応答を生成するプロセス』
のことです。
ユーザーの独自データや最新の業界動向に基づいた情報が必要な場合、ナレッジベースは、モデルがそのデータを参照して、一般的な回答以上に具体的で実用的な提案を行います。
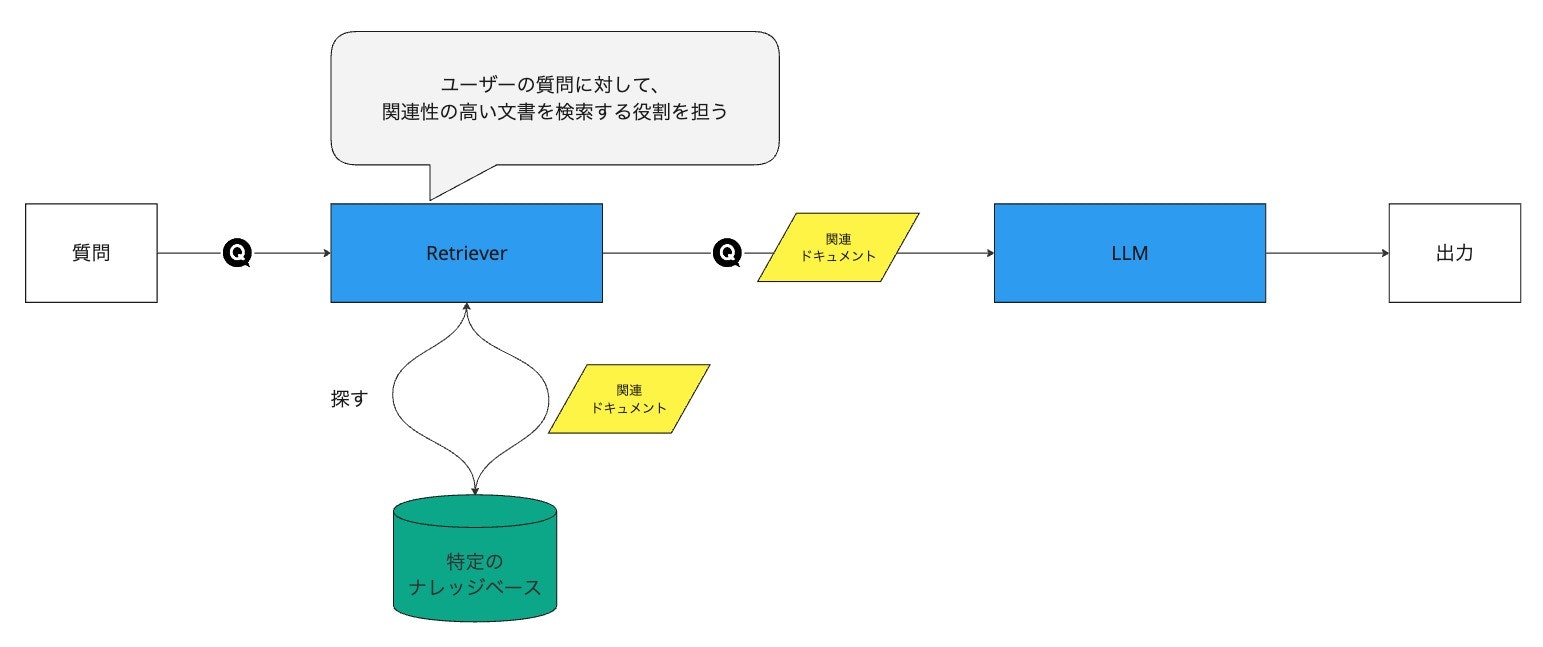
- ユーザー固有のデータを活用することで、応答の精度を向上させることができます。
- トレーニングデータに含まれていない情報も活用できるようになります。
リアルタイムで最新情報を提供する必要があるシナリオ
外部データベースや知識ベースから情報を取得できるため、
特にに
- リアルタイムで最新情報を提供する
必要があるケースに最適です。
この手法は、モデルが持つ事前学習データだけでなく、外部のデータソースからも情報を取り込み、応答生成を行います。
具体的な効果的なタスク
- 文書の自動生成
- ユーザーに対する正確な情報提供
- FAQ
- ドキュメント検索
RAGを使用するには
- 外部の知識ベース(事前に定義された外部データソース)
- ドキュメントリポジトリ
が必要です。これにより、生成モデルがトレーニングデータに存在しない情報を取得して、応答に利用できます。
リスク
ナレッジベースに
- 機密情報
- 個人情報
が含まれると、応答を通じて漏洩するリスクがあります。
ベクトルデータベース
ベクトルデータベースは、
『データをベクトル(数値の配列)として保存します。この特性により、非構造化データ(テキスト、画像、音声など)を効率的に扱う』
ことが可能です。
そのためRAGでは、大量の情報から関連性の高いものを素早く取り出すのに役立ちます。
データのインデックスを作成する必要があるためベクトルデータベースとして、
- Amazon OpenSearch
を利用できます。
BedrockにおけるRAG
ナレッジベースを利用するBedrockの生成モデルは、指定されたデータソースにアクセスして、必要な情報をもとに応答を生成します。
外部データソース
- S3に格納されたドキュメント
- FAQが掲載されたWebサイト
など、事前に定義された外部データソースをナレッジベースとして参照することが可能です。
これにより、企業内の独自データや特定の分野に関するFAQを基に、正確かつ適切な回答を提供できます。
RAGは、外部データベースや知識ベースにアクセスして情報を取得するため、特にリアルタイムで最新情報を提供する必要があるシナリオに適しています。この手法は、モデルが持つ事前学習データだけでなく、外部のデータソースからも情報を取り込み、応答生成を行うため、例えばドキュメントやデータベース、インターネットなどから最新の情報を検索して回答を提供する際に大きな効果を発揮します。
RAGは、通常の生成系モデルでは難しい「最新のニュース」「更新されたデータ」「動的な情報」に対しても対応できるため、質問応答システムやカスタマーサポートチャットボットなど、最新情報が重要なシナリオで非常に有効です