JobSystemを用いて機能実装していく中で幾つかの知見が溜まってきたので個人的なTips集としてメモ。
とは言えまだまだ手探りなところも多く...今回の情報についても最適解ではないところもあるかと思われるので「このケースではこれが有効かもしれない」ぐらいのニュアンスで一例として捉えて頂けると幸いです。
解説していく内容の主軸としては、以前私が実装したVRMSpringBoneのJobSystem(&ECS)対応の内容をベースに進めていこうと思います。
(以降、こちらのJobSystem対応版VRMSpringBoneを**"JobSpringBone"**と省略して記載)
こちらについての資料及びプロジェクト一式は以下で公開済みです。
ちなみに記事中ではJobSystemに関する基本的な解説などは行いません。
(故に多分ある程度知見のある人向けの内容..?)
初学者向けの基礎理論解説記事などについては記事の最後の方に参考/関連リンクとして纒めてあるので、そちらを御覧下さい。
JobのScheduleに関するTips
ScheduleするJobの単位について
初めにJobをScheduleする単位としてはどれくらいが良いのか?について簡単に触れていきます。
取り上げる実装例としてはJobSpringBoneに実装した以下の2つの管理方法を元に解説していきたいと思います。
- モデル単位でJobに渡すデータを纏めた上でJobをSchedule
- 全モデルのJobに渡すデータを一元管理した上でJobをSchedule
モデル単位でJobに渡すデータを纏めた上でJobをSchedule
こちらはモデル単位でJobに渡すデータを纏めた上でJobのScheduleを行う運用です。
特徴としてはモデル単位での管理となるので、モデルが増える毎に管理するデータの数やScheduleされるJobの数が増えていきます。従って管理対象のモデルの数が多くなるほどSchedule時の負荷が高くなっていくと言う印象です。
※例えばJobSpringBoneだと「コライダーの計算、親の回転の取得、物理演算」と合計3回のJobを通して処理されるので、仮にモデル10体を表示するとなると「3(全体を通して必要となるJobの数) x 10(モデルの数) = 30(最終的にScheduleされる回数)」で合計30回のJobがScheduleされることになります。
Jobに渡すデータの持ち方についてザックリと纏めると以下の形になります。(スライドより引用)
モデル単位で揺れ物対象のTransform配列や物理演算で使う値などをJobに渡すデータとして管理するイメージです。
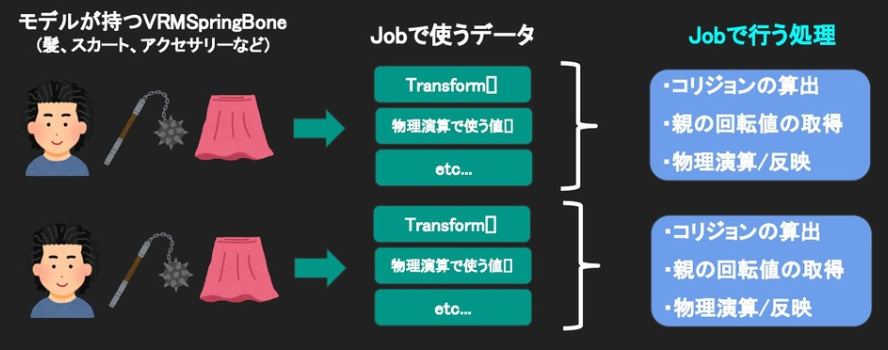
詳細については以下のコードをご覧ください。
-
DistributedJobScheduler.cs
- Job全体の管理クラス。(Scheduleを行ったりする)
-
DistributedBuffer.cs
- モデルが持つデータの定義
負荷計測結果
以下にProfilerの結果を載せます。
実行環境や計測時の処理内容については「こちら」を参照。
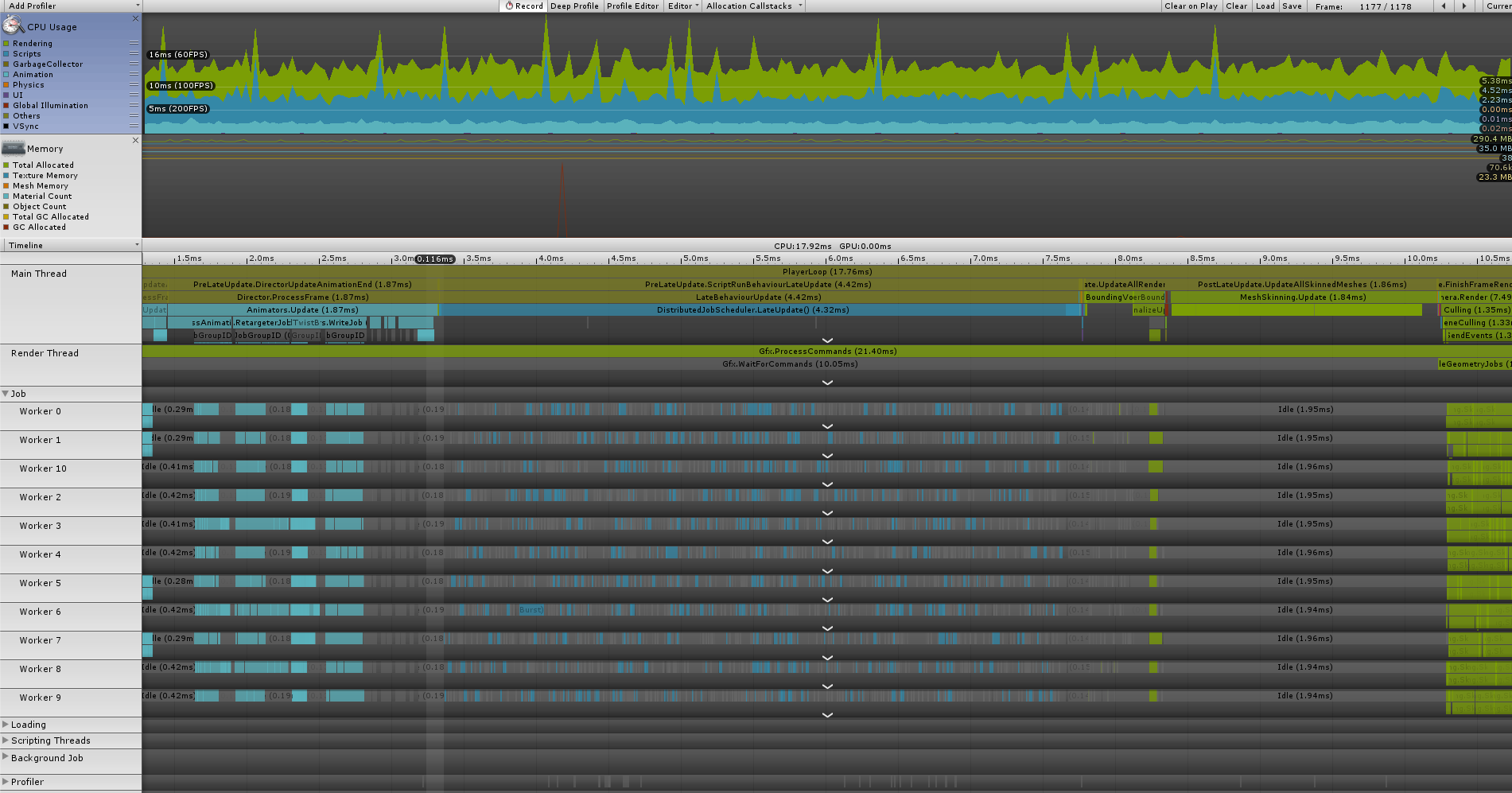
結果を見るとWorkerThreadのJobの並びが疎らになっている様に見受けられます。
恐らくはモデルごとにJobを細かくScheduleしている都合上、Scheduleに掛かる負荷がオーバーヘッドになっているのかと考えられます。
後は時折大きめのスパイクが発生しているのも気になりました。。
こちらについては後述のモデルの増減に伴う負荷ではなく、Scheduleに掛かる負荷が荒ぶっているように見受けられましたが...原因自体は不明です。。
(今回の例のように大量のJobをScheduleすると詰まる...?)
ちなみにモデルの動的な増減の負荷についてはデータがモデル単位で纏まっていることもあってか、後述のJobに渡すデータを一元管理する方と比べると大分抑えられている印象です。
今回の計測結果としてはモデル256体同時表示と数が多いので、管理するモデルが少ない上でモデルの入れ替わりが多い場合にはこの管理方法は有効かもしれません。(実務導入はまだなので要検証)
全モデルのJobに渡すデータを一元管理した上でJobをSchedule
全モデルのJobに渡すデータを一元管理した上でJobをScheduleして一括で処理していく運用になります。
特徴としてはどんなにモデルが増えようとも「Jobに渡すデータの数」及び「ScheduleされるJobの数」は常に一定となるので、Schedule時の負荷は低負荷でキープ出来ている印象です。
→ 例えモデルが100体居ようとも1000体居ようとも常にScheduleされる回数は3回固定。
Jobに渡すデータの持ち方についてザックリと纏めると以下の形になります。(スライドより引用)
全モデルの揺れ物対象のTransform配列や物理演算で使う値などを一箇所のバッファ(Jobに渡すデータ)に纏めて管理しているイメージです。
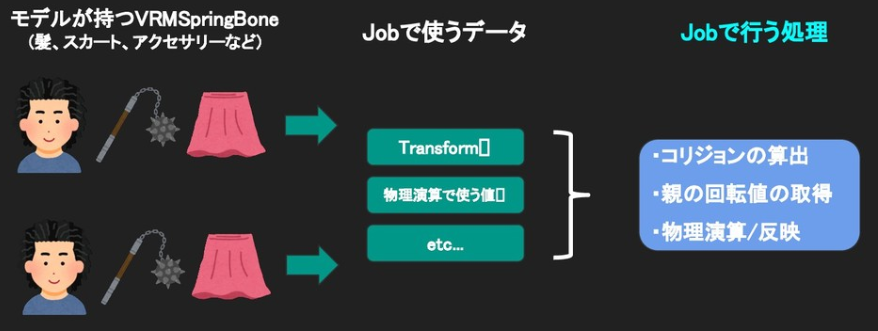
詳細については以下のコードをご覧ください。
-
CentralizedJobScheduler.cs
- Job全体の管理クラス。(Scheduleを行ったりする)
-
CentralizedBuffer.cs
- モデルが持つデータの定義
負荷計測結果
以下にProfilerの結果を載せます。
実行環境や計測時の処理内容については先程と同様に「こちら」を参照。
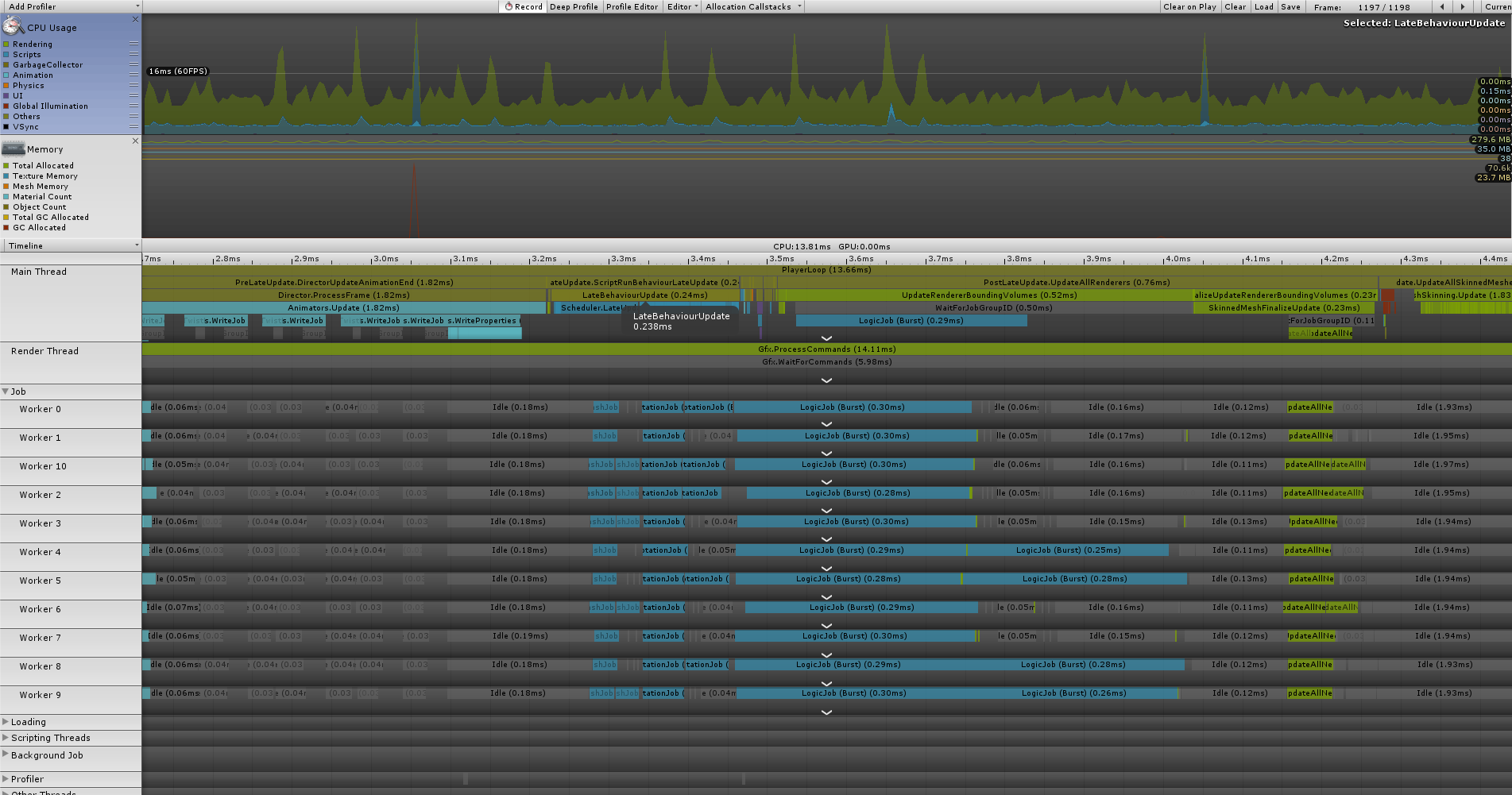
結果としてはScheduleの負荷はそれほど掛かってはおらず、WorkerThreadに詰められるJobの方も良い感じに並んでいるように見受けられます。
処理速度に関しても高速に処理できている印象です。
しかし、一方のモデルの動的な増減については負荷が高まっている感があります。(2箇所ほど巨大なスパイクが生えている所が該当箇所)
ここらは内部的に持つバッファの持ち方を工夫(例えばNativeContiner自体を増減しやすいように見直すなど)すればある程度解消できる所かもしれませんが...今回の実装については単純にモデルの増減が発生した時点でバッファの作り直しが発生する形となっているので、作り直しの負荷によって大きなスパイクが発生しています。
※モデルの増減について...NativeArrayで管理しているデータならまだしも...特にTransformAccessArray辺りの管理はどうしたら良いのかは悩みどころ...。
今回は256体分のバッファを作り直しているという前提があるのでこの負荷となっておりますが、同時表示数によっては許容できる範囲に収まるかもしれません。
また、キャラ数が200体超えるような状況でも上記のパフォーマンスを維持できていることから、キャラ数が圧倒的に多くなる状況且つ入れ替わりがあまり無い(若しくは入れ替わり時にロード画面に入るのでスパイクを許容できる)仕様であれば相性は良いかもしれません。
まとめ
ざっくりとScheduleするJobの単位について解説していきました。
振り返ると以下の様に纏められるかもしれません。
- Job自体は渡すデータは一元管理した上でSchedule → 一括で処理した方がパフォーマンスは良い印象。
- しかし、ECSと言ったアーキテクチャを使わない限りデータの管理周りが面倒になりそう感...。1
- 数によってはバッファを作り直すときの負荷も見逃せないかもしれない。
- モデルごとに管理する方法については表示するモデル数が少ない上で入れ替わりが多い場合にはこちらの方が有効になる時があるかもしれない。
どちらもメリット/デメリットがある感じがするので、後は状況を踏まえつつ要件に応じて設計/計測していくのが良いかもしれません。
互いに依存し合わないJob同士はJobHandle.CombineDependenciesで1つに纒めてしまう
互いに依存し合わないJob同士は「JobHandle.CombineDependencies」と言うAPIを用いる事で1つに纏めてしまう事が可能です。
こちらを上手く用いれば不要なJobの待受を減らしつつWorkerThreadに良い感じにJobを詰めることが出来たりします。
まず最初にCombineDependenciesを用いないパターンの解説から入り、次にCombineDependenciesで最適化したパターンについて順に解説していきます。
CombineDependenciesを用いない場合
前提として前の章でも軽く触れておりますが、JobSpringBoneでは以下の3つのJobを通して揺れ物の計算を行います。
- コライダーの計算(
UpdateColliderHashJob) - 親の回転の取得(
UpdateParentRotationJob) - 物理演算(
LogicJob)
計算順としては「コライダーの計算」と「親の回転の取得」を先に行い、これら2点の計算結果を用いて最後に物理演算を行います。
Jobの依存関係を纏めると「コライダーの計算/親の回転の取得 → 物理演算」となっており、コード上では単純に実装すると以下の様にJobHandleを制御することで依存関係を設定することが出来ます。
// MonoBehaviour.LateUpdate()から呼ばれる
void ExecuteJobs()
{
// バッファの初期化など(処理は割愛)
.........................
// コライダーの更新
var handle = new UpdateColliderHashJob
{
GroupParams = this._colliderGroupJobData.GroupParams,
ColliderHashMap = this._colliderHashMap.ToConcurrent(),
}.Schedule(this._colliderGroupJobData.TransformAccessArray);
// 親の回転の取得
handle = new UpdateParentRotationJob
{
ParentRotations = this._parentRotations,
}.Schedule(this._springBoneJobData.ParentTransformAccessArray, handle); // 前のJobが終わったら処理
// 物理演算
handle = new LogicJob
{
ImmutableNodeParams = this._springBoneJobData.ImmutableNodeParams,
ParentRotations = this._parentRotations,
DeltaTime = Time.deltaTime,
ColliderHashMap = this._colliderHashMap,
VariableNodeParams = this._springBoneJobData.VariableNodeParams,
}.Schedule(this._springBoneJobData.TransformAccessArray, handle); // 前のJobが終わったら処理
// 次のフレームで待ち受けるためにJobHandleをフィールドに保持
this._jobHandle = handle;
JobHandle.ScheduleBatchedJobs();
}
実行するとWorkerThreadの並びとしては以下の様になります。2
赤い線を引いているタイミング辺りで実行中のJobの処理が完了して次の処理に切り替わってます。
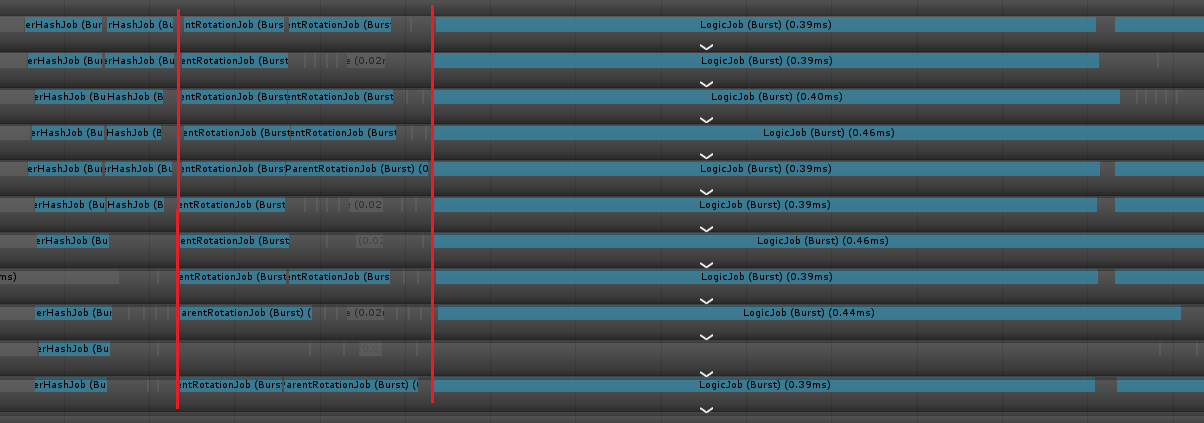
CombineDependenciesで纏める
Jobの依存関係をもう一度振り返ると**「コライダーの計算/親の回転の取得 → 物理演算」**となっておりますが、実は前者2つのJobは互いに依存していないので同時に実行することが可能です。
次の処理では「コライダーの更新」と「親の回転の取得」をJobHandle.CombineDependenciesで1つのJobHandleとして纒めた上で依存関係を構築するように変更してます。
これらを踏まえると以下の様に書き直すことが可能です。(現状管理しているソースは↓の処理になっている)
// MonoBehaviour.LateUpdate()から呼ばれる
void ExecuteJobs()
{
// バッファの初期化など(処理は割愛)
.........................
// コライダーの更新
var updateColliderHashJobHandle = new UpdateColliderHashJob
{
GroupParams = this._colliderGroupJobData.GroupParams,
ColliderHashMap = this._colliderHashMap.ToConcurrent(),
}.Schedule(this._colliderGroupJobData.TransformAccessArray);
// 親の回転の取得
var updateParentRotationJobHandle = new UpdateParentRotationJob
{
ParentRotations = this._parentRotations,
}.Schedule(this._springBoneJobData.ParentTransformAccessArray);
// 「コライダーの更新」と「親の回転の取得」は互いに依存していないので纒めてしまう
var preJobHandle = JobHandle.CombineDependencies(updateColliderHashJobHandle, updateParentRotationJobHandle);
// 物理演算
var handle = new LogicJob
{
ImmutableNodeParams = this._springBoneJobData.ImmutableNodeParams,
ParentRotations = this._parentRotations,
DeltaTime = Time.deltaTime,
ColliderHashMap = this._colliderHashMap,
VariableNodeParams = this._springBoneJobData.VariableNodeParams,
}.Schedule(this._springBoneJobData.TransformAccessArray, preJobHandle); // 「コライダーの更新」と「親の回転の取得」を同時に実行 → 終わったら物理演算を処理
// 次のフレームで待ち受けるためにJobHandleをフィールドに保持
_jobHandle = handle;
JobHandle.ScheduleBatchedJobs();
}
こうすることでWorkerThreadの並びは以下の様になり2、「コライダーの更新」と「親の回転の取得」が互いの結果を待たずにシームレスに実行されている事が確認できます。
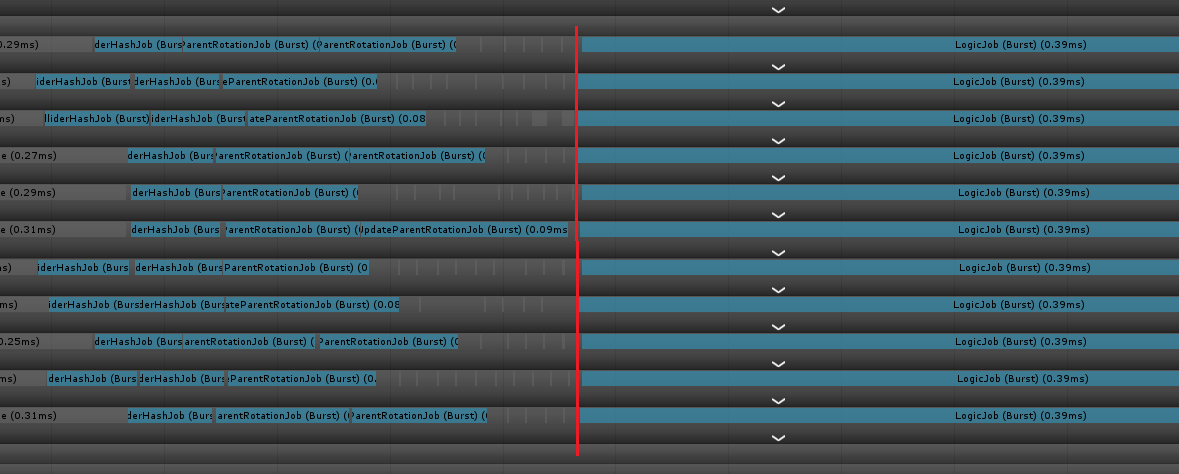
この様にJobSystemで機能実装する際にはデータの依存関係を整理した上で、可能であれば纒めていった方が効率的になるかもしれません。
Jobの実行タイミングについて
JobSystemを使う上では実行タイミング及び同期タイミングを考慮して、なるべく空いているWorkerThreadを有効活用出来るように設計していくのが戦略の一つとして考えられます。
※それこそMainThread側で描画周りの処理(Camera.Renderなど)を実行している時にはWorkerThreadが空いている事が多いので。
JobSpringBoneの設計としてはMainThread側で描画周りの処理を実行している時の空いているWorkerThreadを利用すべく、以下の様に制御してます。
-
-
LateUpdateで各JobをSchedule
-
-
- JobHandle.ScheduleBatchedJobsを実行してJobを実行
- ※JobはScheduleするだけでは実行されない。
Completeを呼び出すか上記のJobHandle.ScheduleBatchedJobsを呼び出して動かしてやる必要がある。
-
- 次のフレームのLateUpdateにて
Completeを呼び出して同期。同期が取れたら1に戻る。
- 次のフレームのLateUpdateにて
後はFinalIKと言った他のAssetとの実行順制御も考慮してScheduler自体に[DefaultExecutionOrder(11000)]を設定している事もあってか、最新版3での挙動としては以下の様になってます。(WorkerThreadを見ると物理演算周りの処理がPostLateUpdate.UpdateAllRenderersのタイミングに食い込んでいるのが確認出来る)
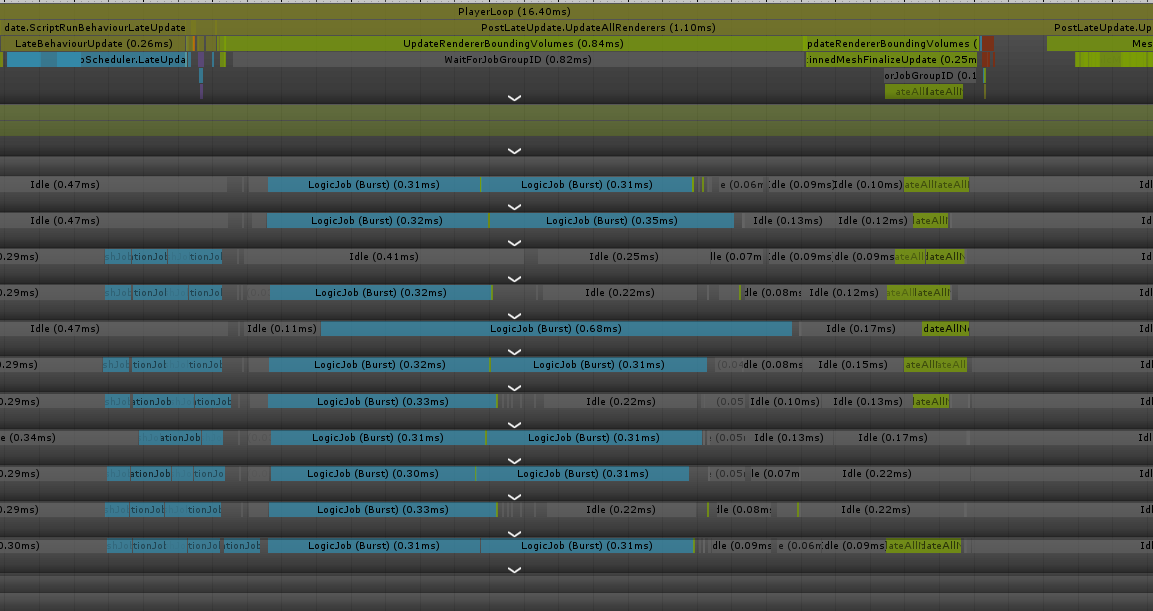
ソースの方も載せておきます。
void LateUpdate()
{
// ★ 実行したJobの同期
this._jobHandle.Complete();
// m_centerの更新
if (this._updateCenterBones.Count > 0)
{
foreach (var springBone in this._updateCenterBones)
{
springBone.UpdateCenterMatrix();
}
}
// JobのSchedule & 実行
this.ExecuteJobs();
}
void ExecuteJobs()
{
if (this._springBoneJobData.Length <= 0) return;
if (!this._colliderHashMap.IsCreated)
{
// コライダーの初期化
this._colliderHashMap = new NativeMultiHashMap<int, SphereCollider>(
this._colliderHashMapLength, Allocator.Persistent);
}
else
{
this._colliderHashMap.Clear();
}
if (this._colliderHashMap.Capacity != this._colliderHashMapLength)
{
this._colliderHashMap.Dispose();
// コライダーの初期化
this._colliderHashMap = new NativeMultiHashMap<int, SphereCollider>(
this._colliderHashMapLength, Allocator.Persistent);
}
// ★ JobのSchedule
{
// コライダーの更新
var updateColliderHashJobHandle = new UpdateColliderHashJob
{
GroupParams = this._colliderGroupJobData.GroupParams,
ColliderHashMap = this._colliderHashMap.ToConcurrent(),
}.Schedule(this._colliderGroupJobData.TransformAccessArray);
// 親の回転の取得
var updateParentRotationJobHandle = new UpdateParentRotationJob
{
ParentRotations = this._parentRotations,
}.Schedule(this._springBoneJobData.ParentTransformAccessArray);
// 物理演算
this._jobHandle = new LogicJob
{
ImmutableNodeParams = this._springBoneJobData.ImmutableNodeParams,
ParentRotations = this._parentRotations,
DeltaTime = Time.deltaTime,
ColliderHashMap = this._colliderHashMap,
VariableNodeParams = this._springBoneJobData.VariableNodeParams,
}.Schedule(this._springBoneJobData.TransformAccessArray,
JobHandle.CombineDependencies(updateColliderHashJobHandle, updateParentRotationJobHandle));
}
// ★ Jobの実行
// ※実行したJobは次フレームのLateUpdateの頭で同期を取る
JobHandle.ScheduleBatchedJobs();
}
ザックリと解説しましたが、実際のプロジェクトでは他のJobを回す可能性も考えられるので、互いに実行タイミングがぶつかって影響を及ぼさないようにその都度フレキシブルに設定を変更していくのが良いかもしれません。
Scheduleせずに直ぐにJobを実行したい
Jobの実行手順としては基本的に「Schedule → 実行(ScheduleBatchedJobs or Complete」と言う流れになるかと思われますが、場合によってはScheduleを経由せずにJobのExecuteを実行したいと言った場合があるかもしれません。(考えられる状況としてはBurstCompilerの最適化の恩恵を受けるべく、Jobの算出処理をMainThread側でも使いたい場合とか)
その場合には**「IJobExtensions.Run」**と言う拡張メソッドを実行することで実現可能です。
以下に使い方を載せます。
public static unsafe float3 CalcBurst()
{
// 結果を入れる変数
var ret = new float3();
// Jobから直接戻り値を受け取れないので結果のポインタを渡して入れる
var job = new CalcJob() {Result = &ret};
// MainThreadで実行
job.Run(); // IJobExtensions.Run
return ret;
}
[BurstCompile] // Burst適用
unsafe struct CalcJob : IJob
{
[NativeDisableUnsafePtrRestriction] public float3* Result;
public void Execute()
{
var ret = Calc();
*Result = ret;
}
float3 Calc()
{
var vec = new float3();
// 何か重い計算処理...
return vec;
}
}
詳細についてはコメントにも記載しておりますが、CalcBurstと言う関数は計算処理をCalcJobを経由させることによってBurstCompilerの最適化を受けられるようにしております。
以下の結果は別記事から引用した物にはなりますが、実行結果としてもMainThread上で(Burst)と表記されたメソッドが走っているのを確認できます。
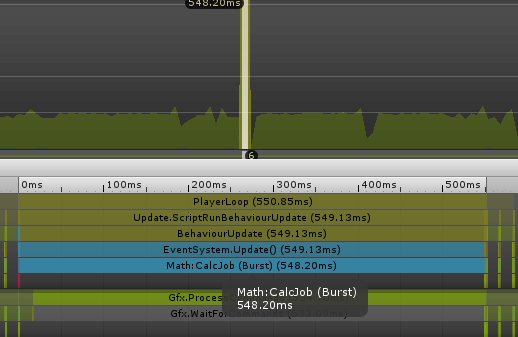
ここらをもう少し掘り下げた内容については「【Unity】BurstCompilerをJobSystem以外でも使いたい」と言う別記事にも纏めているので、よろしければご覧ください。
その他Tips
パフォーマンスを確認する際には基本的にはビルドしてから確認すること
こちらはJobSystemに限った話では無いですが、NativeContainerを使うとEditor上での動作とビルド後の動作でProfilerの結果が大きく変わることがあります。4
JobSpringBoneで言えば「モデル単位でJobに渡すデータを纏めた上でJobをSchedule」するタイプの実装だとそれが顕著なので、以下に例として実行時の違いを載せます。
- Editor実行時
- ビルド実行時
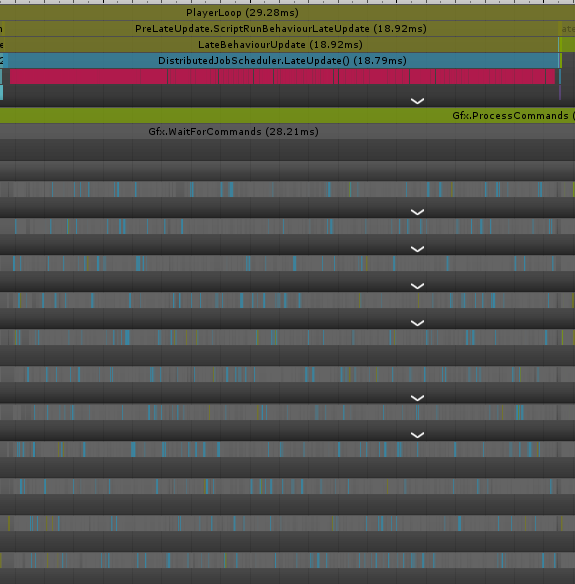
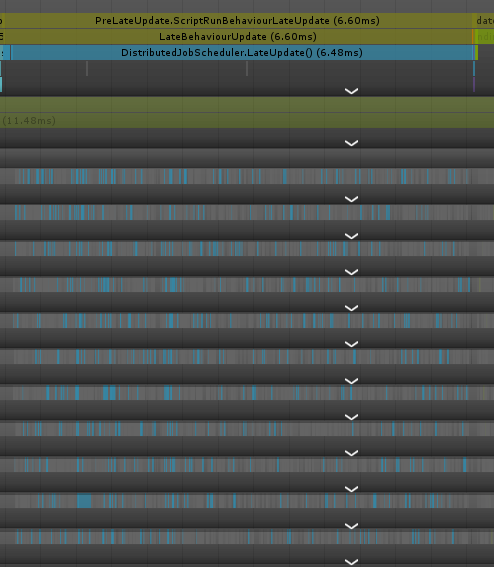
ご覧の通りEditor実行の方はLateUpdate内で大量のGC.Allocが走っており、結果としてScheduleだけに18~19ms近く掛かってます。
一方でビルド実行の方はGC.Allocは一切無くなっており、経過時間の方も6~7msぐらいに収まってます。
これらの原因としてはNativeContainerが生成される際にEditor時のみメモリリーク追跡用に幾つかの参照型のオブジェクトを生成しているので、結果としてマネージドヒープに影響を及ぼしているのが原因の一つとして考えられます。
これらの追跡用のオブジェクトはビルドすると全て取り除かれるので、ビルドの実行結果がゼロアロケートで済んでいるのはこの為です。
その他にもNativeArrayなどはIL2CPP時に最適化が掛かったりするので、基本的には表題の通りビルドしてから確認した方が良いかと思われます。
かと言ってEditor実行時のProfilerは一切使わない言うわけでもなく、個人的にはJobを実行した際のWorkerThreadの並びの確認等には用いたりしてます。(勿論最終的にはビルドして確認する事も踏まえて)
何れにせよ上記の仕様を把握してから計測していくことをおすすめします。
ポインタの活用
Jobの構造体やNativeArrayに持たせる構造体には参照型を含めることが出来ません。
その為に共通のパラメータとなるデータクラスなどを渡す際には何かしら工夫する必要があります。
単純に実装するならインスタンスごとに参照するパラメータを構造体に移し替えた上でNativeArrayで管理するという手もありますが、こちらはコピーした値を渡しているのでコピー元となる共通値を変更した際にはNativeArrayで持っているバッファを塗り直すと言った手間が生じる可能性があります。
これで問題なく運用できると言った前提であれば良いかもしれませんが、共通値が頻繁に更新されるといった状況下であれば少し厄介事になるかもしれません。
そこで解決策の一つとして挙げられるのは共通値をNativeMemoryに確保 → そのポインタを各インスタンスの構造体などに含める形で参照すると言った手が考えられます。
この運用であればJobのSchedule前などにポインタが指すメモリ領域の値を更新することでNativeArrayを塗り替えること無く値全体を更新する事が可能となるので、参照型に近い運用を行うことが可能です。
言葉だけの解説となるので少し分かりにくいかもしれませんが...ここらの運用については以前以下の記事に纏め上げたので宜しければご覧ください。
参考/関連サイト
- Job System とは
- 【Unity】C# Job Systemを自分なりに解説してみる
-
ECSとJobSystem 基礎
- 凄い丁寧に纒められている上に今回自分が解説していない点についても色々補足されているので、是非とも目を通してみることをおすすめ。
-
SpringBoneのJobSystem化でわかったこと
- 去年の記事ですが、JobSystemのベースとなるところが大きく変わっていないので内容自体は今でも有用かと思われます。
- 自分自身もVRMSpringBoneのJobSystem対応を行ったこともあってか、対応後に改めて読み直した際に凄い理解が捗った覚え。。
-
JacksonDunstan.com
-
BurstCompilerやUnity.Mathematics辺りで色々と濃い話が解説されてます。 - タイトルを見ているだけでも面白いので気になる方は一度目を通してみると良いかもです。
-