前書き
ポーラ・オルビスHDでデータエンジニアをしている井山と申します。
みなさん、Snowflake使ってますか?
弊社でも最近、いろいろなデータ活用に向けてSnowflakeの利用を始めたところです。
SnowflakeにはAIを活用した機能がたくさんありますよね。
直近だと Snowflake Intelligence がGAされて話題になりました。
ちょこちょこ触ってみて「これは便利だなぁ…」と思いつつ、まだ本格的には利用できていない状況です。
今回は、以下の機能について実際に触りながら試してみた内容を記事にしたいと思います。
- Cortex Analyst
- Cortex Data Agent
- Snowflake Intelligence
- Sematic View(Model)
- CortexSearch(チョットダケ)
前提
利用データについて
今回は化粧品業界に関しての株価データ(オープンデータで利用できるもの)とをSnowflakeに突っ込み、いい感じに分析・可視化出来るところまでやってみたいと思います。
※ロールなどの設定に関しては今回は省略します
各種利用サービスについて
詳細は公式のドキュメントを参照した方が早いと思いますが、ざっくり以下のような理解をしています。
| コンポーネント | 役割 |
|---|---|
| Semantic Model | YAML形式でビジネス用語とDB定義をマッピング。ステージに配置 |
| Semantic View | Semantic Modelと同等だがDBオブジェクトとして管理。GRANT可能 |
| Cortex Search | 非構造化データのベクトル検索・RAG |
| Cortex Analyst | 自然言語→SQL変換・実行 |
| Cortex Data Agent | 質問を解析し、Analyst/Searchを適切にルーティング |
| Snowflake Intelligence | チャット、可視化、Explore、履歴管理 |

※今回 Cortex Search はメインでは扱いませんが、公開されているIR情報のドキュメントなどを試しに入れてみてIntelligenceに参照させたりしたのでおまけで最後につけています。
データの準備
元となるデータの準備からです。
今回は yfinance を利用してそれらを利用したいと思います。
Yahoo APIを利用してのデータ取得になるので、今回のデモ作成のみに限定して利用します。
※利用規約の確認
https://legal.yahoo.com/us/en/yahoo/terms/product-atos/apiforydn/index.html
https://legal.yahoo.com/us/en/yahoo/terms/otos/index.html
この記事で使っている株価データは、yfinance を使って一度だけ取得したものです。
自動で取得を継続する等、業務システムへの利用はないものとなります。
yfinance は Yahoo! の公式 API ではないため、あくまで 個人的な学習・技術検証の範囲で利用に限定し、記事内で扱うデータは再配布せず、加工後の可視化のみを掲載しています。
データは以下の形式のデータ取り込みます。
company_info
| カラム名 | データ型 | 説明 |
|---|---|---|
| ticker | VARCHAR(10) | 証券コード(例:4911.T) |
| company_name | VARCHAR(100) | 企業名(日本語) |
| long_name | VARCHAR(200) | 正式企業名(英語) |
| sector | VARCHAR(100) | セクター |
| industry | VARCHAR(100) | 業界 |
| market_cap | BIGINT | 時価総額 |
| enterprise_value | BIGINT | 企業価値 |
| employees | INTEGER | 従業員数 |
| website | VARCHAR(500) | ウェブサイトURL |
| business_summary | TEXT | 事業概要 |
| country | VARCHAR(50) | 国 |
| currency | VARCHAR(10) | 通貨 |
| exchange | VARCHAR(50) | 取引所 |
| forward_pe | DECIMAL(8,2) | 予想PER |
| trailing_pe | DECIMAL(8,2) | 実績PER |
| price_to_book | DECIMAL(8,2) | PBR(株価純資産倍率) |
| dividend_yield | DECIMAL(8,6) | 配当利回り |
| payout_ratio | DECIMAL(8,4) | 配当性向 |
| beta | DECIMAL(8,4) | ベータ値 |
| fifty_two_week_high | DECIMAL(10,2) | 52週高値 |
| fifty_two_week_low | DECIMAL(10,2) | 52週安値 |
| created_at | TIMESTAMP | データ作成日時 |
stock_historical_data
| カラム名 | データ型 | 説明 |
|---|---|---|
| ticker | VARCHAR(10) | 証券コード |
| company_name | VARCHAR(100) | 企業名 |
| data_date | DATE | データ日付 |
| open_price | DECIMAL(10,2) | 始値 |
| high_price | DECIMAL(10,2) | 高値 |
| low_price | DECIMAL(10,2) | 安値 |
| close_price | DECIMAL(10,2) | 終値 |
| volume | BIGINT | 出来高 |
| dividends | DECIMAL(8,4) | 配当金 |
| stock_splits | DECIMAL(8,4) | 株式分割比率 |
| price_change | DECIMAL(8,2) | 前日比価格変動 |
| price_change_pct | DECIMAL(8,4) | 前日比変動率(%) |
| volume_ma_5 | DECIMAL(15,2) | 5日移動平均出来高 |
| price_ma_5 | DECIMAL(10,2) | 5日移動平均価格 |
| price_ma_25 | DECIMAL(10,2) | 25日移動平均価格 |
| volatility_20d | DECIMAL(8,4) | 20日ボラティリティ |
| daily_range | DECIMAL(8,2) | 日次価格レンジ(高値-安値) |
| daily_range_pct | DECIMAL(8,4) | 日次価格レンジ率(%) |
| created_at | TIMESTAMP | データ作成日時 |
Sematinc View と Cortex Analyst の準備
まずは Semantic View の定義について。
新しいスキーマレベルオブジェクトである セマンティックビュー に、セマンティックなビジネスコンセプトを直接データベースに格納することができます。ビジネス・メトリクスを定義し、ビジネス・エンティティとその関係をモデリングできます。物理データにビジネス上の意味を付加することで、セマンティックビューはデータ主導の意思決定を強化し、エンタープライズアプリケーション全体で一貫したビジネス定義を提供します。
要するにビジネス用語とデータベースの翻訳レイヤーを定義できる機能で、これを定義することで以下が実現できるものだと認識しています。
- メトリクス計算の一貫性担保(単一の真実)
- LLMが自然言語クエリを理解しやすくなる(Cortex Analyst利用時)
- 物理データが変わっても、一貫したビジネス定義を後続のBI・アプリで利用可能
物理テーブル(raw data)
↓
セマンティックビュー(ビジネス定義層)
↓
各種アプリ・BI・AI
Seamtic View自体の定義には以下の3つの要素が存在しています
| 概念 | 定義 | 具体例 | 集約レベル | 用途 |
|---|---|---|---|---|
| ファクト | 行レベルの数値データ。個別イベントの「いくら」「いくつ」 | 単価、数量、原価、取引金額 | 行単位(集約前) | メトリクス計算の材料 |
| メトリクス | ファクトを集約した KPI。ビジネス成果を測る指標 | 総売上高 SUM(単価×数量)、利益率 (売上-原価)/売上 | 集約後 | 意思決定・レポート |
| ディメンジョン | カテゴリ属性。メトリクスを切り分けるフィルタ軸 | 顧客名、商品カテゴリ、地域、日付 | - | グループ化・フィルタ |
※ファクトは素材、メトリクスは料理、ディメンジョンは切り分け方。
今回のSemantic Viewは以下のような定義を行いました。
(UIからでもそれぞれ追加していけると思いますが、今回は yml ファイルで定義したものをアップロードしています)
以下は実際に定義しているものを少し簡略化したものになります。
name: COSMETICS_IR_ANALYSIS
description: 化粧品業界4社の株価・IR情報を分析するセマンティックモデル
# ===================
# テーブル定義
# ===================
tables:
# --- 企業情報テーブル ---
- name: COMPANY_INFO
description: 企業基本情報・財務指標
base_table:
database: IR_ANALYSIS
schema: STOCK_DATA
table: COMPANY_INFO
# 分析軸(グループ化・絞り込み用)
dimensions:
- name: COMPANY_NAME
synonyms: [会社名, 企業名, 銘柄名]
description: 企業名
expr: company_name
data_type: VARCHAR(100)
sample_values: [資生堂, 花王, コーセー, ポーラ・オルビスHD]
- name: TICKER
synonyms: [ティッカー, 証券コード]
expr: ticker
data_type: VARCHAR(10)
# 数値項目(集計対象)
facts:
- name: FORWARD_PE
synonyms: [PER, 予想PER, 株価収益率, 割安, 割高]
description: 予想PER。10倍未満=割安、20倍超=割高
expr: forward_pe
data_type: NUMBER(8,2)
default_aggregation: avg
- name: MARKET_CAP
synonyms: [時価総額, 企業価値]
expr: market_cap
data_type: NUMBER(38,0)
default_aggregation: sum
primary_key:
columns: [TICKER]
# --- 株価履歴テーブル ---
- name: STOCK_HISTORICAL_DATA
description: 日次株価データ(OHLCV、移動平均、ボラティリティ)
base_table:
database: IR_ANALYSIS
schema: STOCK_DATA
table: STOCK_HISTORICAL_DATA
dimensions:
- name: COMPANY_NAME
synonyms: [会社名, 企業名]
expr: company_name
data_type: VARCHAR(100)
# 時間軸
time_dimensions:
- name: DATA_DATE
synonyms: [日付, 取引日, いつ]
expr: data_date
data_type: DATE
facts:
- name: CLOSE_PRICE
synonyms: [株価, 終値, 現在価格]
expr: close_price
data_type: NUMBER(10,2)
default_aggregation: avg
- name: VOLUME
synonyms: [出来高, 取引量]
expr: volume
data_type: NUMBER(38,0)
default_aggregation: sum
- name: PRICE_CHANGE_PCT
synonyms: [変動率, パフォーマンス, リターン]
expr: price_change_pct
data_type: NUMBER(8,4)
default_aggregation: avg
# 定義済みフィルター
filters:
- name: recent_30days
synonyms: [直近30日, 過去30日]
expr: data_date >= DATEADD(day, -30, CURRENT_DATE())
- name: current_year
synonyms: [今年, 本年]
expr: YEAR(data_date) = YEAR(CURRENT_DATE())
# 定義済みメトリクス
metrics:
- name: AVG_CLOSE_PRICE
synonyms: [平均株価, 平均価格]
expr: avg(close_price)
- name: TOTAL_VOLUME
synonyms: [合計出来高]
expr: sum(volume)
primary_key:
columns: [TICKER, DATA_DATE]
# ===================
# テーブル間リレーション
# ===================
relationships:
- name: STOCK_TO_COMPANY
left_table: STOCK_HISTORICAL_DATA
right_table: COMPANY_INFO
relationship_columns:
- left_column: TICKER
right_column: TICKER
relationship_type: many_to_one
join_type: left_outer
# ===================
# 検証済みクエリ(精度向上用サンプル)
# ===================
verified_queries:
- name: avg_price_30days
question: 資生堂の直近30日間の平均株価は?
sql: |
SELECT avg(close_price) as avg_price
FROM IR_ANALYSIS.STOCK_DATA.STOCK_HISTORICAL_DATA
WHERE company_name = '資生堂'
AND data_date >= DATEADD(day, -30, CURRENT_DATE())
use_as_onboarding_question: true
- name: volume_ranking
question: 2024年の出来高合計を企業ごとに比較
sql: |
SELECT company_name, sum(volume) as total_volume
FROM IR_ANALYSIS.STOCK_DATA.STOCK_HISTORICAL_DATA
WHERE YEAR(data_date) = 2024
GROUP BY company_name
ORDER BY total_volume DESC
use_as_onboarding_question: true
| 用語 | 説明 |
|---|---|
| dimension | 分析軸。グループ化や絞り込みに使う項目(企業名、地域など) |
| time_dimension | 時間に関する分析軸。期間指定に使用(日付、年月など) |
| fact | 数値項目。集計対象となる値(株価、売上、数量など) |
| filter | 事前定義されたWHERE条件(直近30日、今年など) |
| metric | 事前定義された計算式(平均株価、合計出来高など) |
| synonyms | 同義語。自然言語の揺らぎに対応(「株価」「終値」「現在価格」→同一カラム) |
先ほど作成したSematic ViewのYAMLを利用したCortexAlanystを定義します。

今回はYAMLファイルで作成したのでアップロードするだけで完了となります。
※何かしら定義間違いなどがあった場合はこちらの画面でエラーが表示されます。
この時点で画面の右側に Playground が表示されて実際に試してみることができるようになっていますね。
せっかくなのでやってみましょう。
Q:どんなデータが利用できますか?

Q:各社の直近30日の平均終値はいくらですか?

このように Cortex Analyst に対して自然言語でデータに対して問い合わせが可能になっています。
この時点でもかなり使えそうな印象がありますが、ここからさらに Snowflake Intelligence を用いた設定を行ってみましょう。
Snowflake Intelligence の設定
Snowflake Intelligenceの設定については公式のドキュメントを参考に実施します。
-- データベースの作成
CREATE DATABASE IF NOT EXISTS snowflake_intelligence;
GRANT USAGE ON DATABASE snowflake_intelligence TO ROLE PUBLIC;
-- Agent格納用のスキーマの作成
CREATE SCHEMA IF NOT EXISTS snowflake_intelligence.agents;
GRANT USAGE ON SCHEMA snowflake_intelligence.agents TO ROLE PUBLIC;
-- Agent作成の権限付与
GRANT CREATE AGENT ON SCHEMA snowflake_intelligence.agents TO ROLE <role>;
今回は一般ナレッジエージェントではなく、Cortex Analystのセマンティックビューを利用するエージェントを作成します。
https://docs.snowflake.com/ja/user-guide/snowflake-cortex/snowflake-intelligence#create-an-agent-that-uses-a-semantic-view-in-cortex-analyst

ここからエージェントの各種設定を行います。
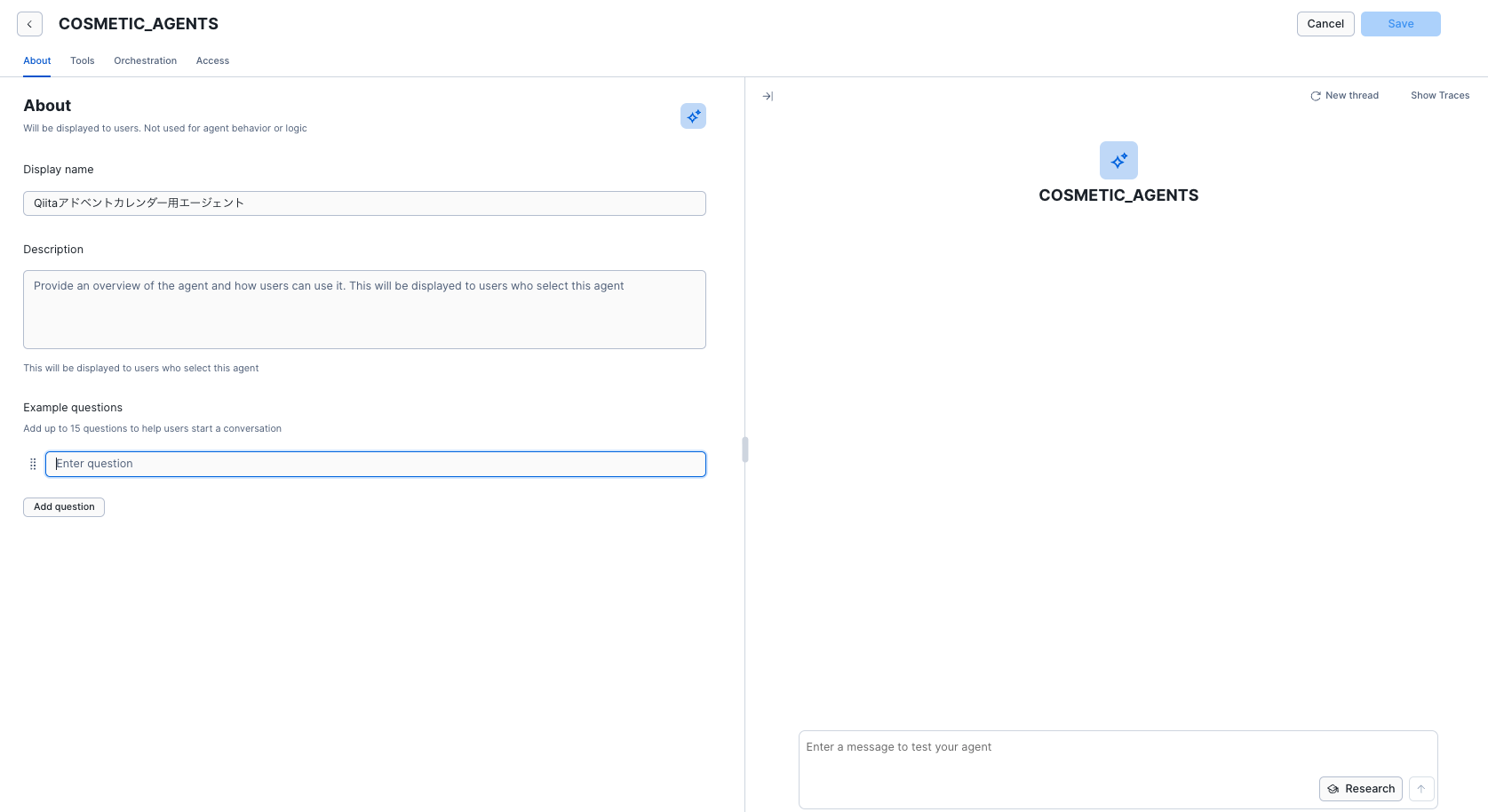
About 部分
こちらは基本的なエージェントの説明とサンプル質問などを登録できるので以下のように設定しています。

Tool部分

Description部分については、 Generate with Cortex を利用して自動生成されたものを設定しています。
どういった設定になった?(日本語訳)
テーブル1: COMPANY_INFO
データベース: IR_ANALYSIS、スキーマ: STOCK_DATA
日本の大手化粧品企業4社(資生堂、花王、コーセー、ポーラ・オルビスホールディングス)の基礎的な財務指標および企業情報を格納。
企業プロファイルとバリュエーション指標のマスターリファレンスとして機能する。
化粧品業界セクターにおける比較財務分析、バリュエーション評価、投資意思決定に必要なデータを提供。
カラム一覧: TICKER(証券コード)、COMPANY_NAME(企業名)、INDUSTRY(業種分類)、SECTOR(市場セクター)、BETA(市場感応度リスク指標)、DIVIDEND_YIELD(年間配当利回り)、FORWARD_PE(予想PER)、MARKET_CAP(時価総額)、PRICE_TO_BOOK(PBR)、TRAILING_PE(実績PER)
テーブル2: STOCK_HISTORICAL_DATA
データベース: IR_ANALYSIS、スキーマ: STOCK_DATA
OHLC価格、出来高、テクニカル指標、算出指標を含む包括的な日次取引データを格納。
過去の株価パフォーマンス分析用。市場の動きと取引パターンを時系列で記録。
化粧品4社における移動平均線やリスク指標を通じたトレンド分析、パフォーマンス比較、ボラティリティ評価、テクニカル分析を可能にする。
カラム一覧: TICKER(証券コード - COMPANY_INFOと連携)、DATA_DATE(取引日)、COMPANY_NAME(企業名)、MONTH(月)、QUARTER(四半期)、YEAR(年)、CLOSE_PRICE(終値)、DAILY_RANGE(日中値幅)、DAILY_RANGE_PCT(日中値幅率)、HIGH_PRICE(高値)、LOW_PRICE(安値)、OPEN_PRICE(始値)、PRICE_CHANGE(価格変動)、PRICE_CHANGE_PCT(騰落率)、PRICE_MA_25(25日移動平均)、PRICE_MA_5(5日移動平均)、VOLATILITY_20D(20日ボラティリティ)、VOLUME(出来高)
設計理由:
このセマンティックビューは、日本の化粧品業界に対する包括的な分析機能を提供するため、
基礎的な企業データと過去の株価パフォーマンスを統合している。
COMPANY_INFOテーブルは基礎的な財務指標と企業プロファイルを提供し
STOCK_HISTORICAL_DATAは詳細な取引データとテクニカル指標を提供する。
TICKERカラムを介したテーブル間の関連付けにより
ファンダメンタルのバリュエーション指標と市場パフォーマンストレンドのクロス分析が可能となる。
この構造は、化粧品大手4社における比較バリュエーション分析
パフォーマンスベンチマーキング、リスク評価、投資意思決定などの多様な分析ユースケースをサポートする。
説明:
COSMETICS_ANALYSISセマンティックビューは
IR_ANALYSISデータベース内で日本の化粧品大手4社(資生堂、花王、コーセー、ポーラ・オルビスホールディングス)の
株式市場および財務分析を統合的に提供する。
COMPANY_INFOの基礎的財務指標とSTOCK_HISTORICAL_DATAの包括的な過去取引データを組み合わせ
バリュエーション指標、市場パフォーマンス、リスク指標の比較分析を可能にする。
株価トレンド、ボラティリティ分析、配当利回り比較、テクニカル指標評価など様々な分析クエリをサポート。
ユーザーは、基礎的な企業データと詳細な日次取引情報の両方を統合したデータセットを通じて
企業間ベンチマーキング、投資機会評価、市場行動パターン分析を実行できる。
ここの具体的な挙動 ( generate with cortex ) についてはAgentsやCortexAnalystのページから見つけることができず...(私の探し方が悪い気もするのですが)
ただ、Snowflake Horizon Catalog などでは以下に記載がありました。
今回でいえば Semantic View を設定しているのでそちらを内容をベースに推論した結果を出してくれているのかなと勝手に思っています ![]()
Orchestration
こちらでは 利用する Model や Orchestration instructions、Response instructions などの設定が可能です(Budgetについての設定も可能ですが今回は割愛)
公式ドキュメントの例として
https://docs.snowflake.com/en/user-guide/snowflake-cortex/cortex-agents-rest-api
response は
"You will respond in a friendly but concise manner"
orchestration は
"For any query related to revenue we should use Analyst; For all policy questions we should use Search"
などを定義するようです。
今回は以下のように設定しています。

使ってみよう
これで大枠の設定が完了したので、実際に Intelligence の画面で実行してみましょう。

まずは株価データについての簡単な可視化を依頼してみます。

いい感じに可視化してくれていますね!
今回、裏でIR資料についてのドキュメントも Cortex Search で参照できるように登録してみたので、そちらも合わせて実施できないか依頼してみましょう。

こちらも Agent が Cortex Search を利用してデータを取得してくれていますね。
また実行後のグラフ化されたデータについては、元となるデータのテーブル表示や、 Explore を実行することで、SQLなども提示されているので、特に非エンジニアの方には使い勝手が良さそうだなと感じています。

まとめ
良かった点
Semantic View さえ整備すれば、非エンジニアでもチャットで質問→可視化→SQL確認という流れを実現できます。
「SQLは詳しくないけどデータは見たい」という層に対して、大きな価値を提供できると感じました。
課題
YAML を書く作業自体は難しくありませんが、本質的なハードルは、その前提となる「ビジネス用語の統一」や「メトリクス定義の合意形成」が大変そうと感じています。
特に弊社のようなHD体制では、事業会社ごとに同じ言葉でも定義や粒度が異なるケースも多く、この合意形成には時間がかかりそうです。
ただ、これはデータガバナンス上いずれ向き合うべき課題です。Semantic View を作る過程でそれが明文化・可視化されると考えれば、むしろ良い機会とも捉えています。
また、現状の Snowflake の機能としてのLLM利用は基本的にクロスリージョンでの利用となる認識でいます。
会社や利用するデータによってはガバナンスなどの問題でこのあたりの機能の利用が難しいパターンもあると考えています。
今後の検討事項
- 実際の社内データでの欠損・表記揺れへの対応
- 複雑な集計やJOINが絡むクエリでの精度検証
- verified_queries の充実による精度向上
- etc...
これらの課題はありつつも、Snowflake の AI 機能を活用したデータ利活用は積極的に推進していきたいと考えています!!