概要
Databricks にて replaceWhere による選択的上書き時におけるソースデータフレームが空の場合に、DELETE のみが実行されるかを検証しました。検証結果としては、DELETE のみが実行されました。DELETE のみを実行したくない場合には、レコードが存在しない場合には書き込み処理をスキップすることで対応できます。本記事では、検証コードとその結果を共有します。
## 対応方法
if df.limit(1).count() > 0:
(
df.write
.mode("overwrite")
.option("replaceWhere", 'datasource in ("bbb.txt","ccc.txt")')
.saveAsTable("replace_test.tbl_01"
)
)
else:
print("ソースデータがないためスキップ")

検証方法と検証結果
次のようなデータをもつテーブルを用意します。
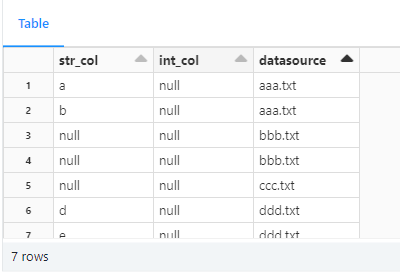
datasource列にてbbb.txtとccc.txtの値のレコードを空のデータフラームで書き込みます。

replaceWhere による選択的上書きを実施したところ、次のようにデータが上書きされました。bbb.txtとccc.txtがなくなっていることを確認できました。

検証コード
1. スキーマを作成
%sql
create schema if not exists replace_test;

2. テーブル作成と初期データの挿入
%sql
create or replace table replace_test.tbl_01
(
str_col string,
int_col int,
datasource string
);
INSERT INTO replace_test.tbl_01
(
str_col,
int_col,
datasource
)
SELECT 'a',NULL,'aaa.txt'
UNION ALL
SELECT 'b',NULL,'aaa.txt'
UNION ALL
SELECT NULL,NULL,'bbb.txt'
UNION ALL
SELECT NULL,NULL,'bbb.txt'
UNION ALL
SELECT NULL,NULL,'ccc.txt'
UNION ALL
SELECT 'd',NULL,'ddd.txt'
UNION ALL
SELECT 'e',NULL,'ddd.txt'
;
select * from replace_test.tbl_01;

3. 上書きデータを保持したデータフレームを作成
# 空のデータフラームを作成
src_d = []
src_s = """
str_col string,
int_col int,
datasource string
"""
df = spark.createDataFrame(src_d,src_s)
df.display()
"""
df = spark.createDataFrame(src_d,src_s)
df.display()

4. replaceWhere による選択的上書きの実施と結果確認
(
df.write
.mode("overwrite")
.option("replaceWhere", 'datasource in ("bbb.txt","ccc.txt")')
.saveAsTable("replace_test.tbl_01"
)
)
spark.table("replace_test.tbl_01").display()

5. リソースの作成
%sql
drop schema replace_test cascade
