概要
本記事にて、データ分析基盤の検討の進め方を記載します。データ分析基盤の概念モデルを検討した上で、それにサービスをマッピングを行い選定を行うプロセスを紹介します。

サービスを選定する際には、ガートナーなどの外部期間の評価報告レポートが参考になります。ガートナーは、特定の分野ごとにマジック・クアドラントを発表しており、製品ごとの弱点も記載されているなど参考になる情報が記載されております。最新のトレンドを反映された評価となっていることから、IT投資による優位性を保ちたいのであれば、適切な評価をされているサービスを選定すべきです。ガートナーの報告書は有料コンテンツではありますが、ソフトウェアベンダー(特にその分野でリーダーとなっている会社)が無償で公開していることがあるので探してみてください
製品の選定を行う際には、ソフトウェアベンダーの言葉を鵜呑みにせずに、自分で言葉の定義を行いながら進めることが重要です。単純な比較表を作成するだけでは製品の特徴の理解は難しく、想定シナリオでの性能や使い勝手の評価を行うことで製品に対する理解が深まります。サービス評価を下記の観点で、初期評価・中間評価・最終評価を行うことが有用です。
- 機能(機能を保持しているか)
- 性能(機能がどれぐらいの性能ができるのか)
- 使い勝手(機能を使いやすいか)
- コスト(購入・開発・運用・廃棄のライフサイクル全体のコスト)
データ分析基盤の選定
下記のステップで、データ分析基盤を選定するプロセスを紹介します。
STEP1.データ分析基盤に関する前提知識の獲得
STEP2.データ分析基盤の概念モデルを作成
STEP3.利用コンポーネントの決定
STEP4.論理モデル(利用コンポーネントにサービスをマッピングした図)の検討
STEP5.PoCの実施と機能・性能・使い勝手・コストの観点での最終レポート作成
STEP1.データ分析基盤に関する前提知識の獲得
データ分析基盤の定義を行います。データマネジメントの領域に関する調査を実施する際には、下記の書籍やサイトの情報を探索します。
- DAMA-DMBOK: Data Management Body of Knowledge: 2nd Edition
- データマネジメント知識体系ガイド 第二版
- The DAMA Dictionary of Data Management, 2nd Edition: Over 2,000 Terms Defined for IT and Business Professionals (English Edition)
- Gartner Glossary
データ分析基盤の検討する際には、下記のマイクロソフト様ドキュメントも参考になります。
データ分析基盤を検討する上で、必要となる主な知識は下記です。
- ラムダアーキテクチャ
- SMPとMPP
- ディメンションナルモデリング
- 構造化データ・半構造データ・非構造データの違い
- 列指向フォーマット(ParquetからDelta Lakeへ)
- 同時実行性(一般的なDWHは同時実行性が低く、BIから接続する際の同時実行数に注意)
- データストアの拡張性
- 最近の話題
- データ仮想化
- データプリパレーション
- データカタログ
Qiitaの記事として同僚が参考になる情報を記載しているので、ご一読ください。
STEP2.データ分析基盤の概念モデルを作成
2020年10月14日時点で、私が考えるデータ分析基盤の概念モデルは下記図であり、下記の箇条書きの観点でモデル化しております。最近のデータ分析基盤のトレンドを反映することで網羅的に記載しておりますので、参考にしてください。
- ビックデータの3V(Volume、Variety、Velocity)に対応できる拡張性のあるアーキテクチャとすること
- データ分析レイヤーにて、可視化・統計解析(AI)シミュレーションの3つに分けて、それぞれのツールを選定できるようにすること
- データ仮想化サービス、データレプリケーションサービス、データプリパレーション(データ連携サービス)などのサービスの位置付けの明確化を行うこと
詳細の記事については、下記の記事をご確認ください。
| 番号 | 記事 | 詳細記事リンク |
|---|---|---|
| 1 | データ分析基盤における概念モデルとは | リンク |
| 2 | ソースレイヤーとは | リンク |
| 3 | インタフェースレイヤーとは | リンク |
| 4 | バッチレイヤーとは | リンク |
| 5 | スピードレイヤーとは | リンク |
| 6 | サービスレイヤーとは | リンク |
| 7 | データ利活用レイヤーとは | リンク |
| 8 | データカタログとは | リンク |
| 9 | オーケストレーションとは | リンク |
| 10 | DevOpsとは | リンク |
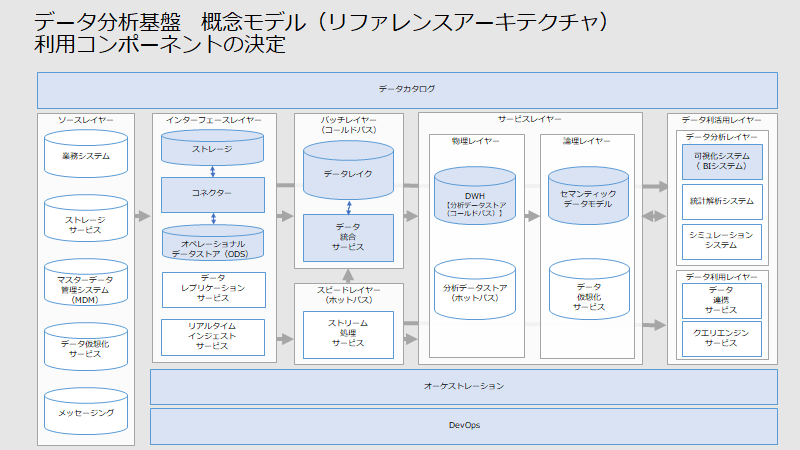
STEP3.利用コンポーネントの決定
概念モデルに基づき、スコープの対象とするコンポーネントを決定します。下記の前提をもとに、概念モデルの図にて利用するコンポーネントを塗りつぶし、利用しないコンポーネントを塗りつぶしなしにします。
- BI(ビジネス・インテリジェンス)システムを導入すること
- データレイクに格納する前に、ODSにてデータの品質確認を行うこと
- リアルタイム分析・統計解析・シミュレーション・データ利用レイヤーは実装しないこと
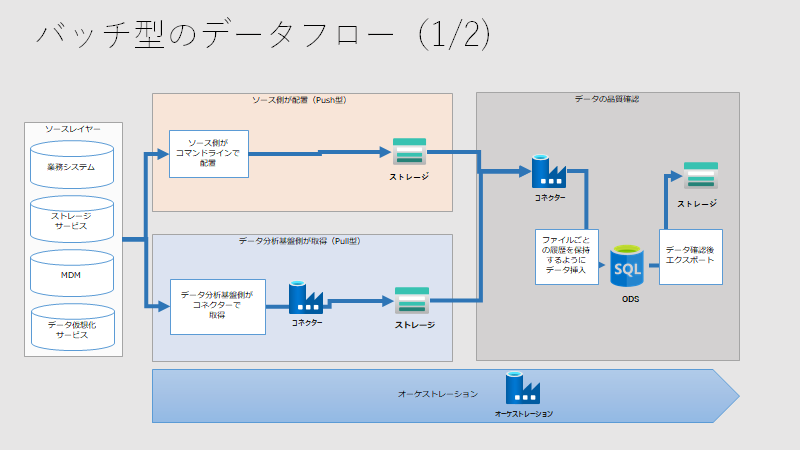
STEP4.論理モデル(利用コンポーネントにサービスをマッピングした図)の検討
利用コンポーネントを整理した概念モデル図に、実際のサービスをマッピングします。下記の前提で、概念モデル図の上にサービスを配置します。
- Azureで実装すること
- データカタログとして、Informatica社のデータカタログを検討すること
- サービス間の連携を疎結合をするためにAzure Storageで連携を行うこと

データフローの検討も必要です。サービス間の関係性を下記のように整理します。
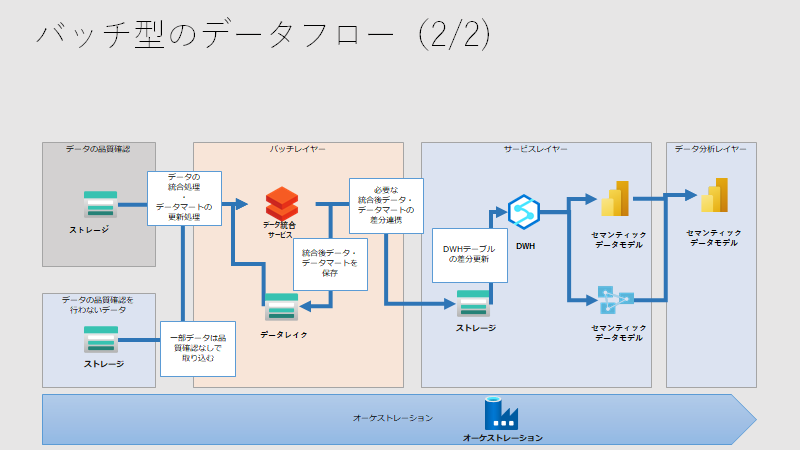
バッチレイヤーにて集計ロジックを集中させ、サービスレイヤーでは単純な差分連携のみを行うことを示すために、下記のように整理します。
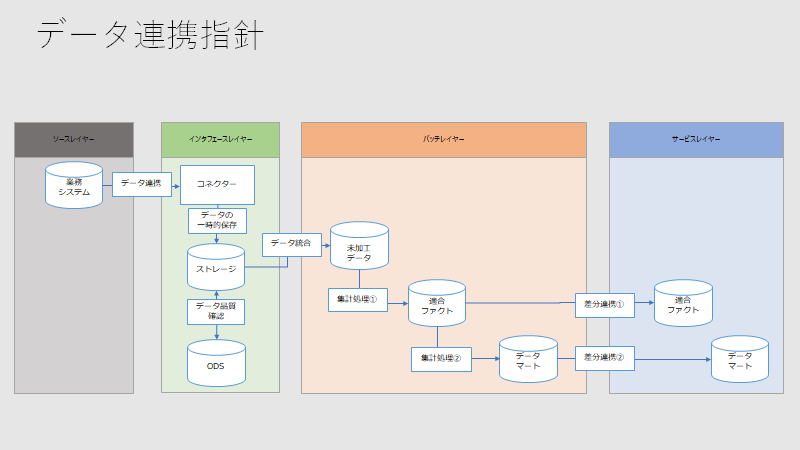
そして、データレイクにどのようなファイル形式として保存するのか、また、サービス間でどのようなファイル形式で連携するのかに関する指針をきめます。
| 番号 | フォーマット | 説明 | データ分析基盤での利用推奨 |
|---|---|---|---|
| 1 | 区切り型テキストファイル(CSV、TSV) | カンマ区切り、あるいは、タブ区切りによりデータを保持したファイルフォーマットであり、容易に利用できる。データストアに取り込む際には、最も高速に取り込むことができることが多い。 | データレイク:× 業務システム:〇 バッチレイヤーへの連携時:〇 サービスレイヤーへの連携時:◎ リアルタイム処理時:〇 データ連携サービス:〇 クエリエンジン:× |
| 2 | json | システムで利用されるデータ形式。 | × |
| 3 | xml | システムで利用されるデータ形式。 | × |
| 4 | Apache Parquet | 列指向のデータ形式。スキーマの自動読み込みが可能。 | データレイク:〇 業務システム:× バッチレイヤーへの連携時:〇 サービスレイヤーへの連携時:× リアルタイム処理時:× データ連携サービス:〇 クエリエンジン:◎ |
| 5 | Delta Lake | ACID特性などを保持させなどのParquetを拡張させたデータ形式。データレイクにおけるスタンダードとなりそうなファイル形式。ただし、利用するサービスで対応しているか確認する必要がある。 | データレイク:◎ 業務システム:× バッチレイヤーへの連携時:× サービスレイヤーへの連携時:× リアルタイム処理時:〇 データ連携サービス:〇 クエリエンジン:〇 |
| 6 | Apache Avro | スキーマ情報を保持しており、システム間でデータ交換を行うための行指向のデータ形式。 | データレイク:× 業務システム:× バッチレイヤーへの連携時:◎ サービスレイヤーへの連携時:× リアルタイム処理時:◎ データ連携サービス:× クエリエンジン:× |
| 7 | ORC | Hiveの処理に最適化された列指向のデータ形式。 | × |
| 8 | Common Data Model | 標準の共通データ モデル形式のスキーマ化されたデータとして保存するデータ形式。 | データレイク:× 業務システム:◎ バッチレイヤーへの連携時:× サービスレイヤーへの連携時:× リアルタイム処理時:× データ連携サービス:〇 クエリエンジン:× |
引用元:データ分析基盤におけるデータレイクでの保持ファイル形式、および、インターフェースファイルの形式について
STEP5.PoCの実施と機能・性能・使い勝手・コストの観点での最終レポート作成
機能要件・非機能要件に基づいて詳細なアーキテクチャ(物理モデル)を定義をし、それに対するPoCの実施を行った上で、機能・性能・使い勝手・コストの観点での最終レポートを作成します。
Q&A
アジャイル的にデータ分析基盤を検討してよいのか?
アジャイル的にデータ分析基盤を拡張していくことは有効ですが、捨てる覚悟をもつべきです。システムを初期構築時には手探りの状態で進めることがよくありますが、初期のシステムとして構築したもののなかには技術的負債が多く残ってしまうことがあります。アジャイル的に進めるのであれば、実装済みのシステムのスクラップの検討を行うべきであり、その意識がないのであれば考えることを放棄しているだけです。