はじめに
DWHおよびETLで必要とされる大規模な処理がどういう背景と考え方で実現されているのか"超ざっくり"まとめます。
データ処理技術のトレンド
まずはETL処理に関してです。DWHもそうですが、分散処理がキーワードとなります。
求められるBigdataへの対応
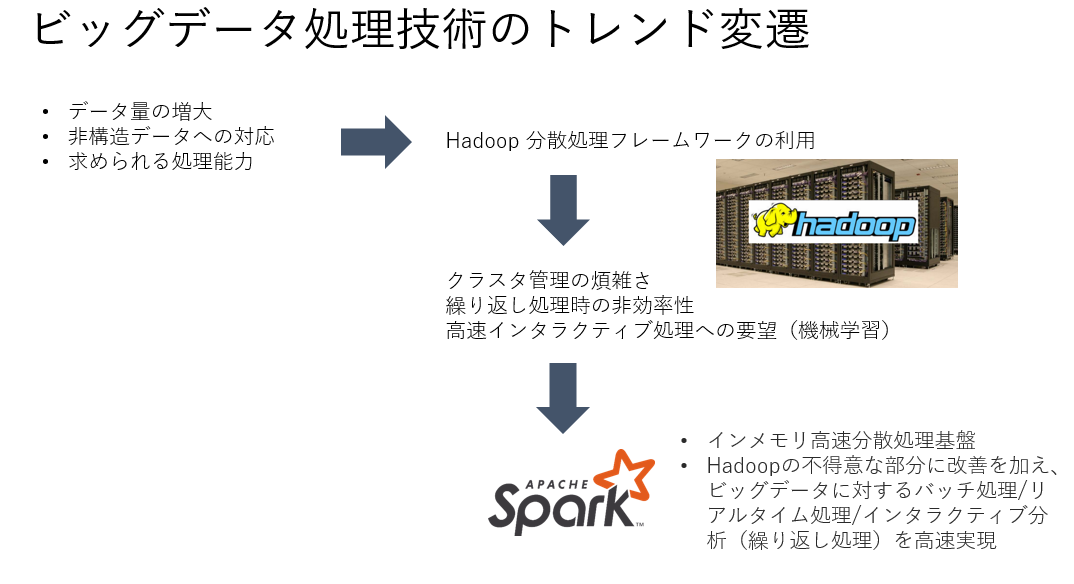
いわゆる3V(Variety,Velocity,Volume)で定義されることの多いBigdataの出現に伴い、それを分析処理するソフトウェアにはまず第一に「大量のデータに対する処理を現実的な時間内で終わらせること」が求められました。
分散処理フレームワークの台頭
大量のデータを効率的に処理させるための対応として、Hadoopと呼ばれるような処理技術が利用されるようになりました。
Hadoopは以下のような仕組みで大量データを効率的に処理することを実現しました。
「データを分割して多数のサーバーで処理」(Map)
「それぞれのデータ処理結果をまとめる」(Reduce)
「MapReduceを効率的に行なう仮想ストレージシステム」(HDFS:Hadoop Distributed File System)
この技術要素はGoogleで発表された論文を元が元になっており、Apache HadoopとしてOSS化されています。
Hadoopへのフラストレーション
現在Hadoopの仕組みなしでは大規模データ処理は語れないほどの位置づけのHadoopですが、完璧なものというわけではありません。
クラスタ準備
分散処理を行うためにはクラスタ(サーバのかたまり)を用意する必要がありますが、Hadoopのメリットを享受するためには少なくともTB級のデータ処理が必要なことから、一部の限られた企業での利用にとどまりました。
分析ユースケースへの非効率性
Hadoopは仕組み上、処理の度に毎回Diskに書き込むことから、複数の処理ステップを組み合わせるような処理や、繰り返し処理結果を使いまわすような処理では非効率な面が指摘されていました。
開発の難易度
Hadoopの開発にはJavaを扱える人材が必要なため、データ分析ができ、Javaが扱える人材という面で開発のハードルが高く、普及に歯止めをかけていました。
Hadoopの普及と分散処理の進化
クラウドベンダーによるHadoopの民主化
クラスタ管理の観点ではクラウドベンダーがPaaS(もしくはIaaS)を提供することにより、より簡単な利用ができるようになりました。
Sparkの登場
さて、Hadoopの分析ユースケースおよび、開発言語の門戸の狭さからSparkというOSSの分散処理フレームワークが誕生しました。

参考:http://spark.apache.org/talks/overview.pdf
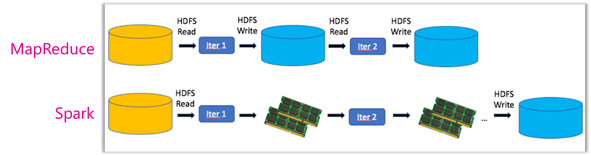
Sparkは従来のHadoopのキー技術となっていたMapReduceを置き換えるものです。
処理ステップのプランを最適化し、Hadoopでは処理の度にDiskに書き込んでいた中間処理結果の保存をメモリ上で行い、Disk I/Oの回数を減らすものです。
また、SparkではJavaベースのScalaだけだなく、Python,R,SQL,.Netでのコーディングが可能となっており、特にPysparkは最近の機械学習ブームで爆発的に増加したPythonユーザとの相性の良さから利用が広がっています。
MPP型DWHの登場
次にDWH製品の仕組みに関してです。こちらでも分散処理がキーワードとなります。
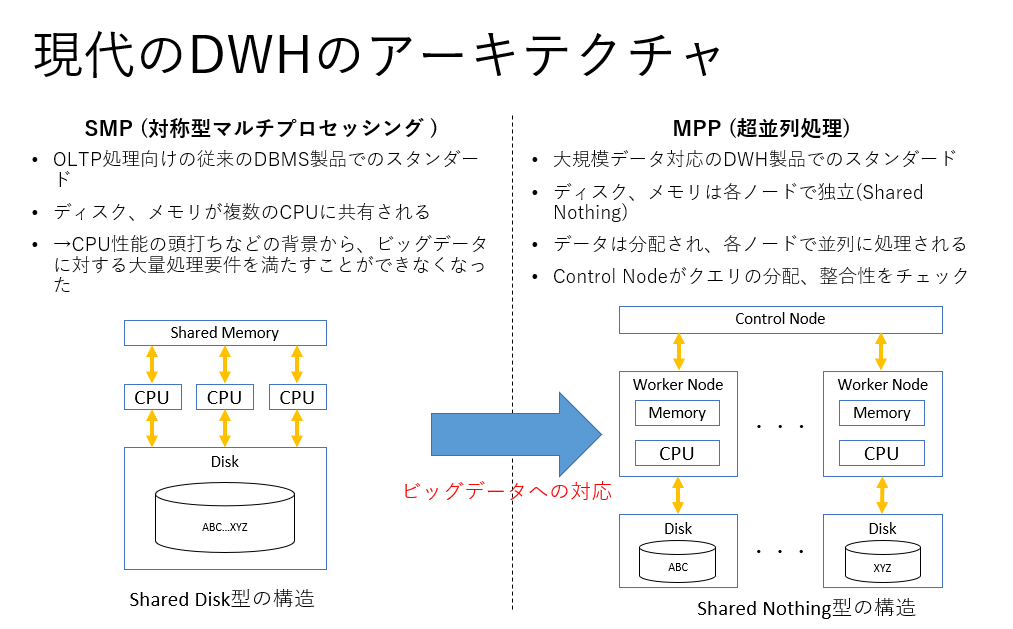
SMP:Symmetric Multi Processing
SMP型の処理は従来の単一サーバで完結するOLTP向けのDBに多く、近年のDWH製品はMPP型での処理が前提となっています。
MPP:Massively Parallel Processing
超並列処理とも言います。
MPP型のDWHは、Hadoopと同様の発想で、大量のデータを分割し、それぞれのノードで処理することで、大規模データ処理に対応します。
Shared EverythingからShared Nothingへ
MPPを実現するうえで、Shared Nothing型が多く採用されていました。
最近ではその枠組みを超えて、ストレージ層、コンピュート層、アプリケーション層といった形で、ハイブリッドな構成をとるDWHも多く登場しています。
補足 Shared Nothing のスケールアウトの課題
Shared Nothing ではストレージとコンピュートが一体化しているがために、コンピュートの増加の際にはストレージのリバランス処理が発生し、スケールアウトに時間がかかるなどの問題があります。
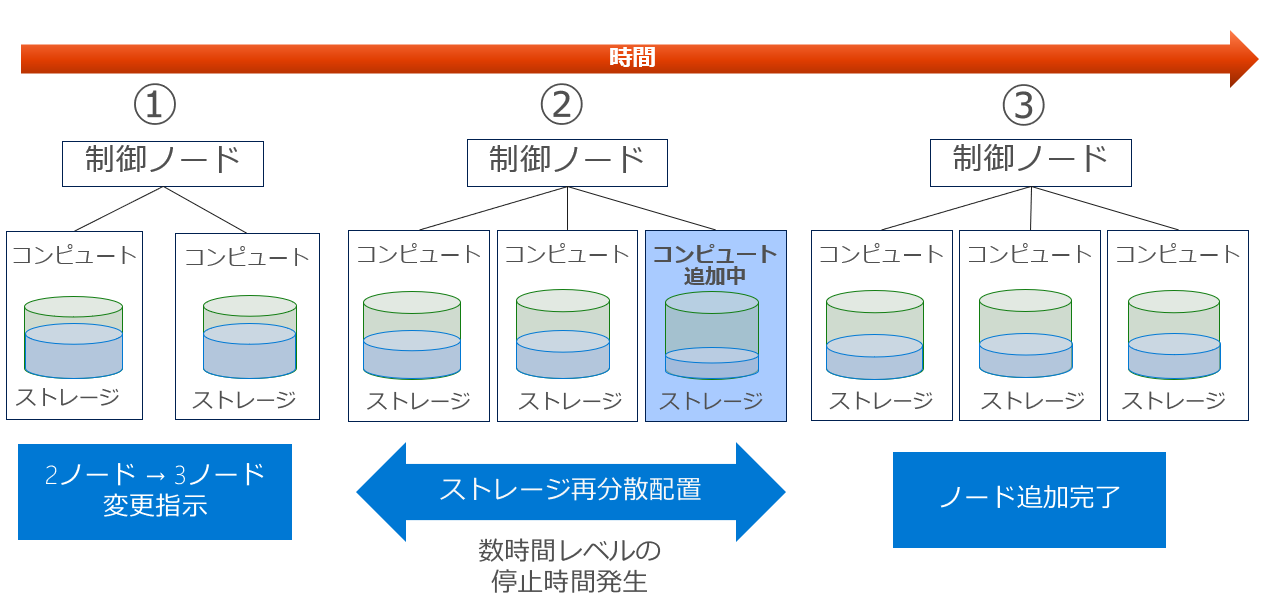
Shared Nothingだが、ストレージはコンピュート増加とは関連しないように層を形成するなど各社のDWHそれぞれで対策がされています。
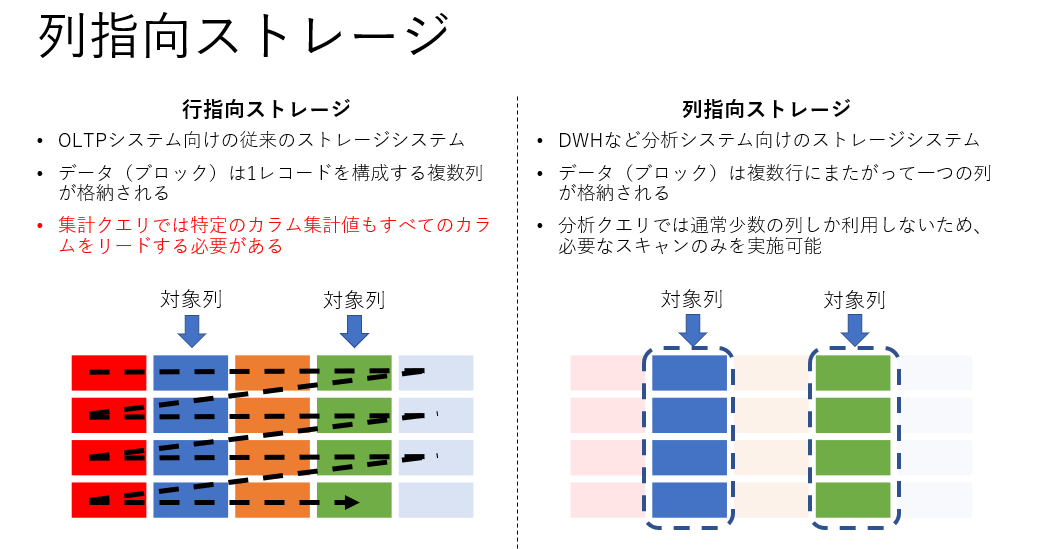
列指向ストレージによる集計処理の効率化
特に集計処理において重要になるのが列指向ストレージの存在です。
参考:https://www.slideshare.net/nttdata-tech/bigdata-storage-layer-software-nttdata
行指向ストレージ
csvなどを単純にファイルに置いた場合や、OLTP向けDBではこの形式でデータが保持されます。
列指向ストレージ
DWH製品では主にこちらが利用されます。カラムナーストレージなどという表記がある場合このことを言っています。
ファイルフォーマットではparquetが代表的な仕組みです。
データブロックを列ごとにもつことで、「集計処理の高速化」と「圧縮の効率化」が図れます。
列指向ストレージのメリット
集計処理の高速化
特に集計処理では以下のようなクエリが多用されますが、利用列はレコード全体の列数から考えると少なく、列指向ストレージのメリットが発揮されます。
SELECT
顧客ID
,SUM(金額) AS 集計金額
FROM
売上テーブル
GROUP BY
顧客ID
圧縮の効率化
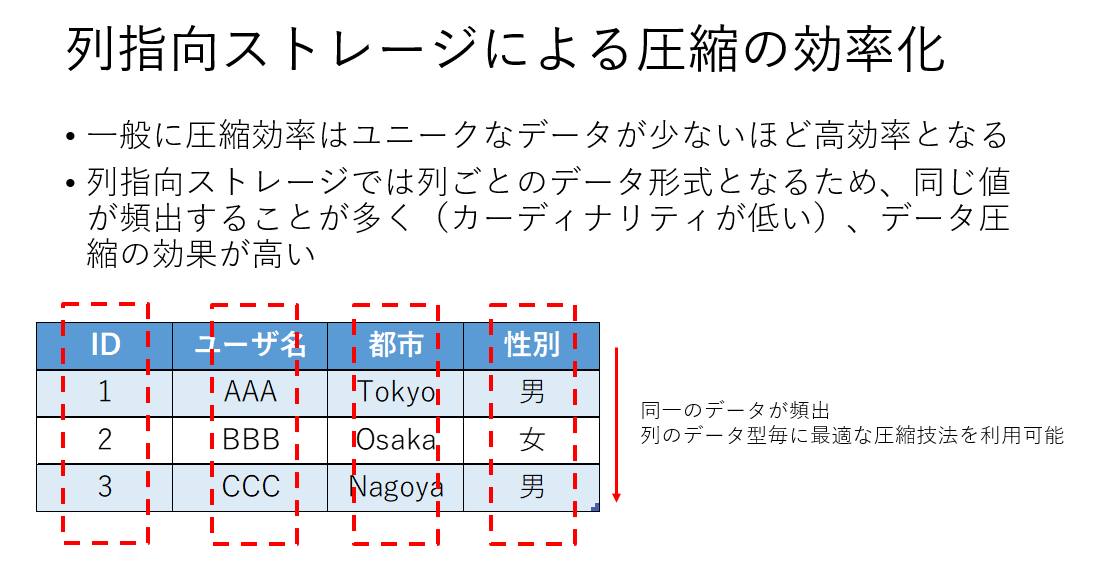
行指向のデータではデータブロック内に前列のデータが入ることに対して、列指向のデータでは同一のデータブロック内では同一のカラムが扱われるので、同一なデータが頻出し、圧縮効率が高くなるケースが増えます。
終わり
様々なDWH製品、ETLツールがありますが、背景となる仕組みや技術の理解を深めることで、製品評価の一助になれば幸いです。