概要
Google Colab から Google Cloud Storage に Apace Iceberg 形式のデータを書き込む方法を紹介します。
Google Colab の Spark にて Apache Iceberg 形式のデータの基本操作については下記の記事で紹介しています。
- Getting started with PyIceberg と Iceberg で作成されるファイル郡の確認を Google Colab でやってみた #Python - Qiita
- Google Colab の Spark にて Hadoop Catalog の Apache Iceberg の動作検証 #iceberg - Qiita
事前準備
下記の記事を参考にして Google Colab と GCS を接続してください。
Apache Icebeg 形式のデータの操作方法
Service Account のキーファイルをストレージに配置後、Google Drive をマウント
from google.colab import drive
drive.mount('/content/drive')
SparkSession の定義
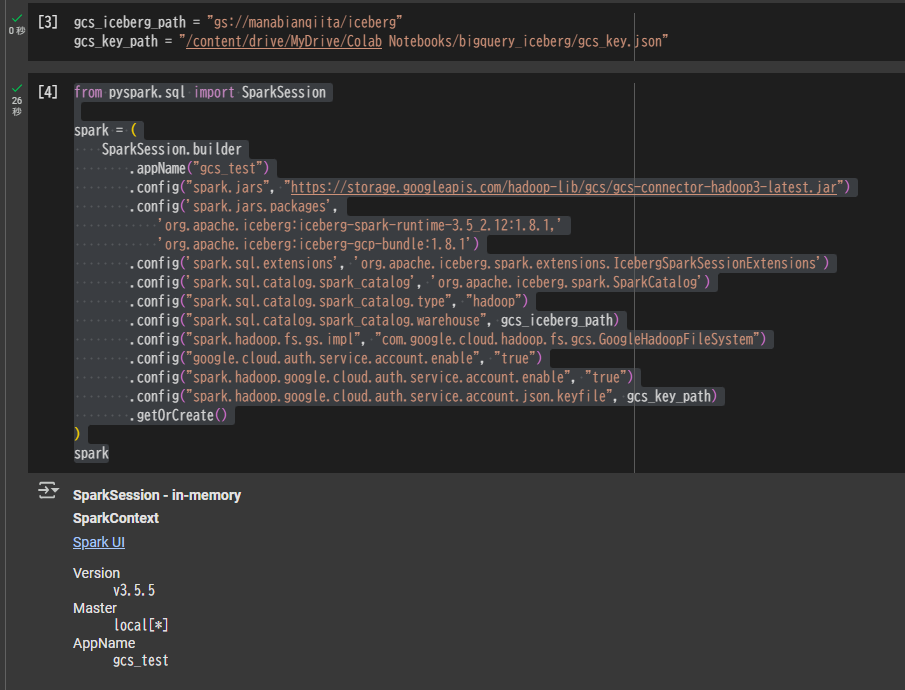
gcs_iceberg_path = "gs://manabianqiita/iceberg"
gcs_key_path = "/content/drive/MyDrive/Colab Notebooks/bigquery_iceberg/gcs_key.json"
from pyspark.sql import SparkSession
spark = (
SparkSession.builder
.appName("gcs_test")
.config("spark.jars", "https://storage.googleapis.com/hadoop-lib/gcs/gcs-connector-hadoop3-latest.jar")
.config('spark.jars.packages',
'org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.8.1,'
'org.apache.iceberg:iceberg-gcp-bundle:1.8.1')
.config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions')
.config('spark.sql.catalog.spark_catalog', 'org.apache.iceberg.spark.SparkCatalog')
.config("spark.sql.catalog.spark_catalog.type", "hadoop")
.config("spark.sql.catalog.spark_catalog.warehouse", gcs_iceberg_path)
.config("spark.hadoop.fs.gs.impl", "com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem")
.config("google.cloud.auth.service.account.enable", "true")
.config("spark.hadoop.google.cloud.auth.service.account.enable", "true")
.config("spark.hadoop.google.cloud.auth.service.account.json.keyfile", gcs_key_path)
.getOrCreate()
)
spark
SpakSession を定義済みの場合には、ランタイムを接続解除して削除を選択して最初からやり直してください。

Apache Iceberg テーブルを作成
spark.sql(f"""
CREATE OR REPLACE TABLE default.first_table(
id INT,
name STRING,
status STRING
)
USING iceberg;
""")

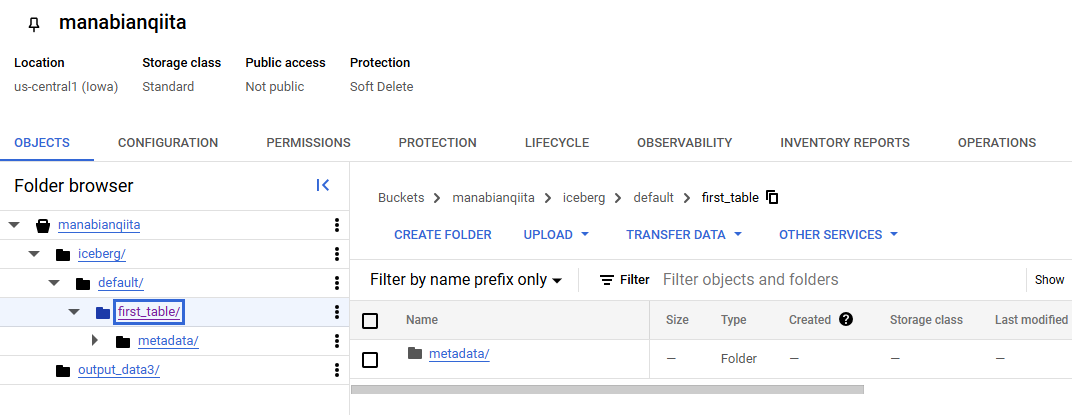
GCS 上にテーブルのディレクトリが作成されていることを確認します。
テーブルにデータを挿入
spark.sql("""
INSERT INTO
default.first_table (id, name, status)
VALUES
(1, 'Alice', 'active'),
(2, 'Bob', 'active'),
(3, 'Charlie', 'active'),
(4, 'Daisy', 'active'),
(5, 'Ethan', 'active');
""").show()
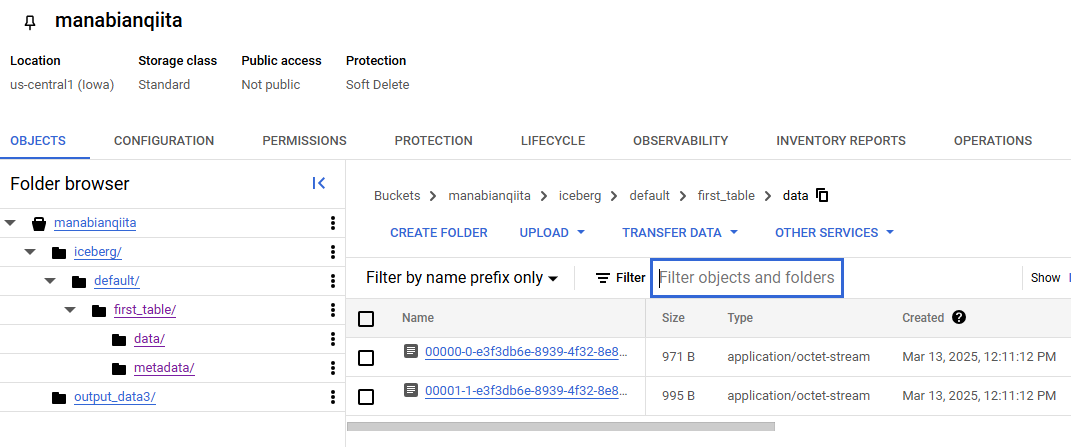
GCS 上にテーブルのディレクトリ内に parquet ファイルが書き込まれていることを確認します。
テーブルのデータを取得
spark.table("default.first_table").show()
