概要
Google Colab の Spark にて Hadoop Catalog の Apache Iceberg の動作検証をした結果を共有します。 Valinlla Spark にて Apache Iceberg を動作させたかっため本検証を実施しました。
検証結果
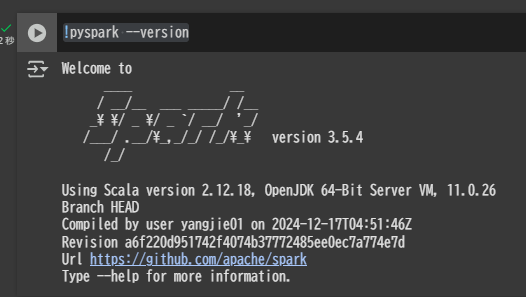
Spark のバージョンを確認
!pyspark --version
SparkSession を定義
Spark のバージョンに応じてspark.jars.packagesで指定するライブラリのバージョンを変更する必要あり。
from pyspark.sql import SparkSession
spark = (SparkSession.builder
.appName("IcebergExample")
.config("spark.jars.packages", "org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.8.0")
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
.config("spark.sql.catalog.spark_catalog", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.spark_catalog.type", "hadoop")
.config("spark.sql.catalog.spark_catalog.warehouse", "/iceberg")
.getOrCreate()
)
spark

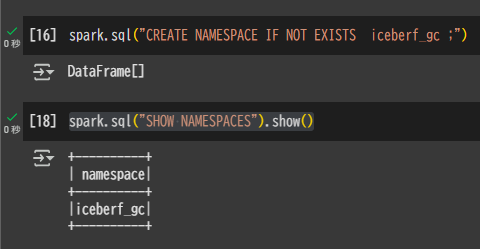
Namespace を作成
spark.sql("CREATE NAMESPACE IF NOT EXISTS iceberf_gc ;")
spark.sql("SHOW NAMESPACES").show()
テーブルを作成
spark.sql("""
CREATE OR REPLACE TABLE iceberf_gc.first_table (
id INT,
name STRING
)
USING iceberg
;""")

テーブルにデータを書き込み
data = [(1, "Alice"), (2, "Bob"), (3, "Charlie")]
columns = ["id", "name"]
df = spark.createDataFrame(data, columns)
display(df.toPandas())
df.write.mode("overwrite").format("iceberg").saveAsTable("iceberf_gc.first_table")

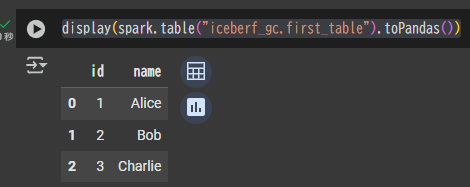
テーブルのデータを確認
display(spark.table("iceberf_gc.first_table").toPandas())
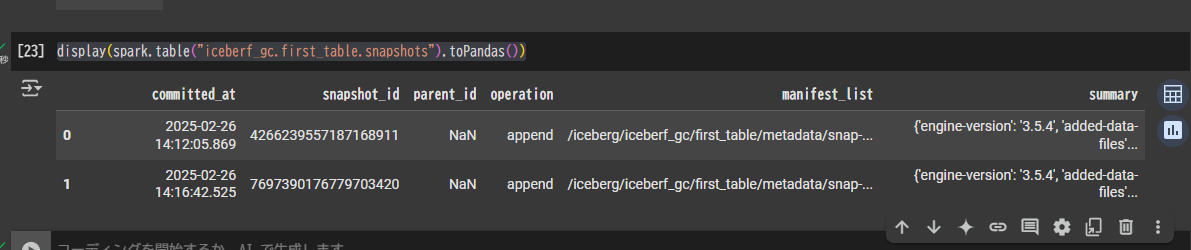
テーブルの snapshots の確認
display(spark.table("iceberf_gc.first_table.snapshots").toPandas())
ストアードプロシージャ(Comapaction)の実施
res_df = spark.sql("CALL spark_catalog.system.rewrite_data_files('spark_catalog.iceberf_gc.first_table')")
display(res_df.toPandas())
