概要
本記事では、Getting started with PyIceberg の内容をベースに、Google Colab 上で Apache Iceberg テーブルの操作を実行しながら、生成されるメタデータファイルなどを確認する方法を紹介します。
Getting started with PyIceberg とは、SQLite をカタログとして利用し、Apache Iceberg の基本操作を行うための手順を示すチュートリアルです。

引用元:PyIceberg
しかし、上記チュートリアルだけでは、以下の画像で示されるような Apache Iceberg 全体の構造を把握する手順が含まれていません。そこで本記事では、テーブル操作時に作成されるメタデータファイルなどを確認する手順を追加しています。

より深く Apache Iceberg を理解したい方は、以下の記事も参考になります。
Getting started with PyIceberg の実施
PyIceberg のインストール
!pip install pyiceberg -q
ディレクトリを作成
!mkdir -p /content/warehouse

SQLCatalog の初期化
from pyiceberg.catalog.sql import SqlCatalog
# warehouse のパス(Colab では /content/warehouse を利用)
warehouse_path = "/content/warehouse"
# SqlCatalog の初期化
catalog = SqlCatalog(
"default",
uri=f":sqlite///{warehouse_path}/pyiceberg_catalog.db",
warehouse=f"file://{warehouse_path}"
)

サンプルデータ取得と Pandas データフレームを作成
!curl https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2023-01.parquet -o /tmp/yellow_tripdata_2023-01.parquet
import pyarrow.parquet as pq
df = pq.read_table("/tmp/yellow_tripdata_2023-01.parquet")

Namespace(スキーマ)とテーブルを作成
# Namespace が存在しないとエラーとなるため追記
try:
catalog.create_namespace("default")
print("Namespace 'default' を作成しました。")
except Exception as e:
print("Namespace 'default' は既に存在するか、作成に失敗しました。エラー内容:", e)
table = catalog.create_table(
"default.taxi_dataset",
schema=df.schema,
)
テーブルにデータを書き込み
table.append(df)
len(table.scan().to_arrow())

カラム追加後にスキーマ進化(Schema Evolution)し、再度データを書き込み
import pyarrow.compute as pc
df = df.append_column("tip_per_mile", pc.divide(df["tip_amount"], df["trip_distance"]))
with table.update_schema() as update_schema:
update_schema.union_by_name(df.schema)
table.overwrite(df)
print(table.scan().to_arrow())

テーブルの件数を表示
df = table.scan(row_filter="tip_per_mile > 0").to_arrow()
len(df)

ディレクトリの表示
!find /content/warehouse

作成されるメタデータファイルなどを確認
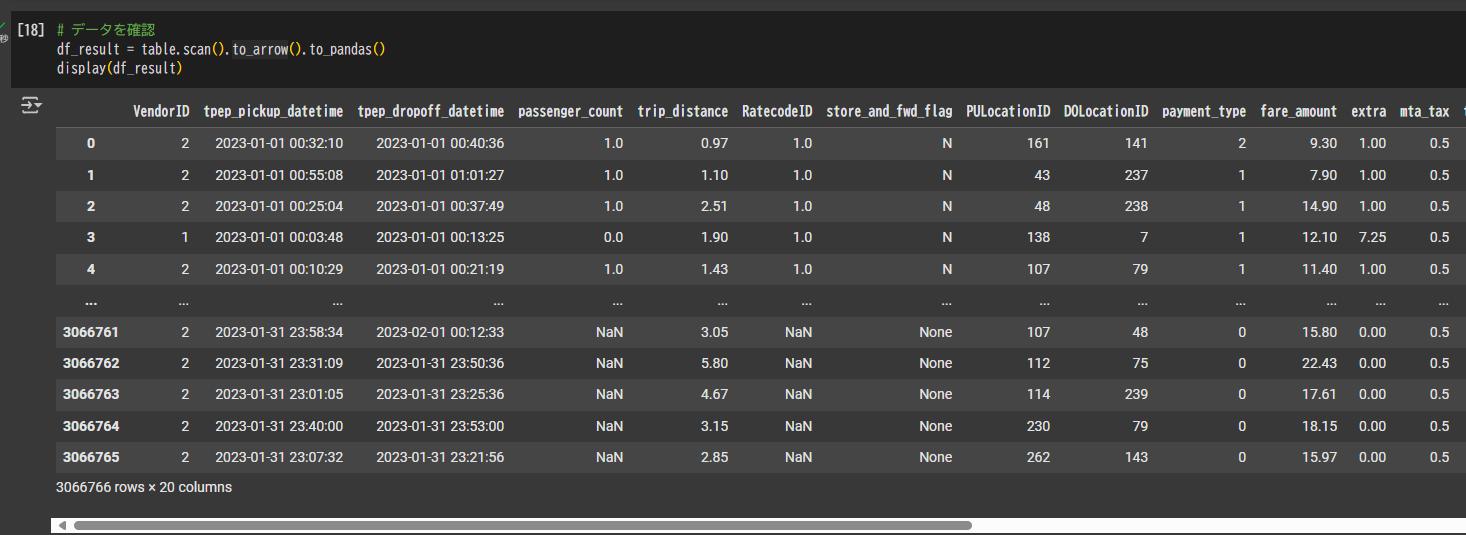
テーブルのデータを表示
# データを確認
df_result = table.scan().to_arrow().to_pandas()
display(df_result)
ディレクトリをツリー形式で表示
# 指定ディレクトリのツリー表示
import os
def print_tree(root, indent=""):
items = sorted(os.listdir(root))
for index, item in enumerate(items):
path = os.path.join(root, item)
connector = "└── " if index == len(items) - 1 else "├── "
print(indent + connector + item)
if os.path.isdir(path):
extension = " " if index == len(items) - 1 else "│ "
print_tree(path, indent + extension)
print_tree(warehouse_path)
├── default.db
│ └── taxi_dataset
│ ├── data
│ │ ├── 00000-0-3f9ae304-2945-44fe-aa50-77ac36b362fd.parquet
│ │ └── 00000-0-6d54f692-e850-4c94-b503-a2ba8ddf604c.parquet
│ └── metadata
│ ├── 00000-a522d21e-4947-4d7a-8b0c-f74a0432b746.metadata.json
│ ├── 00001-358284f0-7856-4662-ac1d-18db786e1139.metadata.json
│ ├── 00002-5b0a7e48-19f3-42ed-839c-14a2101c7d85.metadata.json
│ ├── 00003-85f9a93a-cb11-41fe-9c0b-118077f5f4cb.metadata.json
│ ├── 3f9ae304-2945-44fe-aa50-77ac36b362fd-m0.avro
│ ├── 6d54f692-e850-4c94-b503-a2ba8ddf604c-m0.avro
│ ├── d587fcaf-37d9-41df-ab74-70b8df33d316-m0.avro
│ ├── snap-5208795649190268058-0-6d54f692-e850-4c94-b503-a2ba8ddf604c.avro
│ ├── snap-7008364628208335728-0-d587fcaf-37d9-41df-ab74-70b8df33d316.avro
│ └── snap-8890271881640778471-0-3f9ae304-2945-44fe-aa50-77ac36b362fd.avro
└── pyiceberg_catalog.db

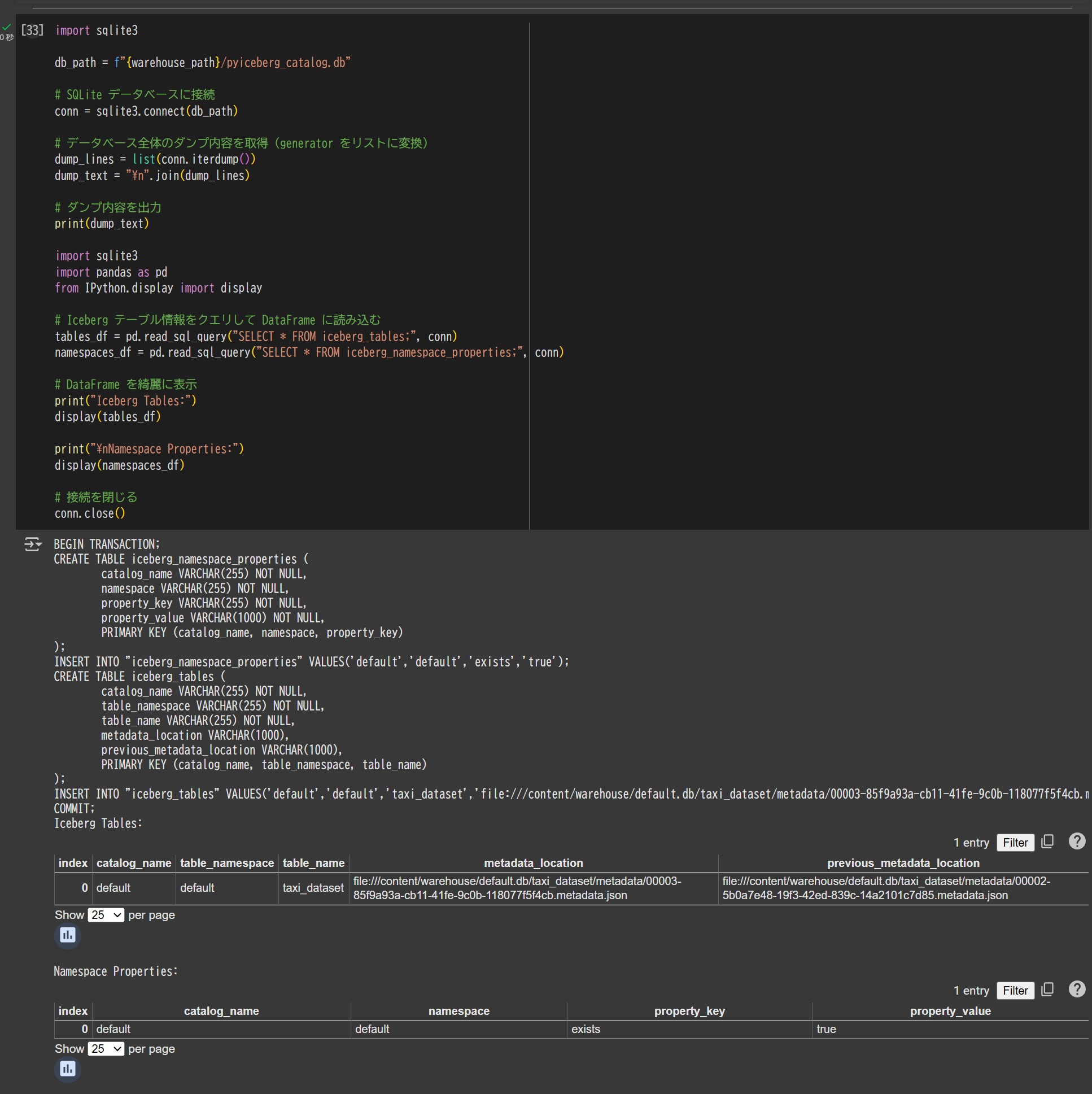
Iceberg Catalog の確認
import sqlite3
db_path = f"{warehouse_path}/pyiceberg_catalog.db"
# SQLite データベースに接続
conn = sqlite3.connect(db_path)
# データベース全体のダンプ内容を取得(generator をリスト化)
dump_lines = list(conn.iterdump())
dump_text = "\n".join(dump_lines)
# ダンプ内容を出力
print(dump_text)
import sqlite3
import pandas as pd
from IPython.display import display
# Iceberg テーブル情報をクエリして DataFrame に読み込む
tables_df = pd.read_sql_query("SELECT * FROM iceberg_tables;", conn)
namespaces_df = pd.read_sql_query("SELECT * FROM iceberg_namespace_properties;", conn)
# DataFrame を整形して表示
print("Iceberg Tables:")
display(tables_df)
print("\nNamespace Properties:")
display(namespaces_df)
# 接続を閉じる
conn.close()
BEGIN TRANSACTION;
CREATE TABLE iceberg_namespace_properties (
catalog_name VARCHAR(255) NOT NULL,
namespace VARCHAR(255) NOT NULL,
property_key VARCHAR(255) NOT NULL,
property_value VARCHAR(1000) NOT NULL,
PRIMARY KEY (catalog_name, namespace, property_key)
);
INSERT INTO "iceberg_namespace_properties" VALUES('default','default','exists','true');
CREATE TABLE iceberg_tables (
catalog_name VARCHAR(255) NOT NULL,
table_namespace VARCHAR(255) NOT NULL,
table_name VARCHAR(255) NOT NULL,
metadata_location VARCHAR(1000),
previous_metadata_location VARCHAR(1000),
PRIMARY KEY (catalog_name, table_namespace, table_name)
);
INSERT INTO "iceberg_tables" VALUES('default','default','taxi_dataset','file:///content/warehouse/default.db/taxi_dataset/metadata/00003-85f9a93a-cb11-41fe-9c0b-118077f5f4cb.metadata.json','file:///content/warehouse/default.db/taxi_dataset/metadata/00002-5b0a7e48-19f3-42ed-839c-14a2101c7d85.metadata.json');
COMMIT;
metadata layer の metadata file を確認
import os
import json
from IPython.display import display, Markdown
metadata_dir = f"{warehouse_path}/default.db/taxi_dataset/metadata"
# metadata ディレクトリ内の JSON ファイルを確認
for filename in os.listdir(metadata_dir):
if filename.endswith(".json"):
file_path = os.path.join(metadata_dir, filename)
with open(file_path, "r") as f:
data = json.load(f)
pretty_json = json.dumps(data, indent=4, ensure_ascii=False)
display(Markdown(f"**==== {filename} の内容 ====**"))
display(Markdown(f"```\n{pretty_json}\n```"))
クリックで出力結果を表示可能
```00001-358284f0-7856-4662-ac1d-18db786e1139.metadata.json { "location": "file:///content/warehouse/default.db/taxi_dataset", "table-uuid": "8a37e044-0e1b-4aad-8a72-8ca5c6d51149", "last-updated-ms": 1740447644616, "last-column-id": 19, "schemas": [ { "type": "struct", "fields": [ { "id": 1, "name": "VendorID", "type": "long", "required": false }, { "id": 2, "name": "tpep_pickup_datetime", "type": "timestamp", "required": false }, { "id": 3, "name": "tpep_dropoff_datetime", "type": "timestamp", "required": false }, { "id": 4, "name": "passenger_count", "type": "double", "required": false }, { "id": 5, "name": "trip_distance", "type": "double", "required": false }, { "id": 6, "name": "RatecodeID", "type": "double", "required": false }, { "id": 7, "name": "store_and_fwd_flag", "type": "string", "required": false }, { "id": 8, "name": "PULocationID", "type": "long", "required": false }, { "id": 9, "name": "DOLocationID", "type": "long", "required": false }, { "id": 10, "name": "payment_type", "type": "long", "required": false }, { "id": 11, "name": "fare_amount", "type": "double", "required": false }, { "id": 12, "name": "extra", "type": "double", "required": false }, { "id": 13, "name": "mta_tax", "type": "double", "required": false }, { "id": 14, "name": "tip_amount", "type": "double", "required": false }, { "id": 15, "name": "tolls_amount", "type": "double", "required": false }, { "id": 16, "name": "improvement_surcharge", "type": "double", "required": false }, { "id": 17, "name": "total_amount", "type": "double", "required": false }, { "id": 18, "name": "congestion_surcharge", "type": "double", "required": false }, { "id": 19, "name": "airport_fee", "type": "double", "required": false } ], "schema-id": 0, "identifier-field-ids": [] } ], "current-schema-id": 0, "partition-specs": [ { "spec-id": 0, "fields": [] } ], "default-spec-id": 0, "last-partition-id": 999, "properties": {}, "current-snapshot-id": 8890271881640778471, "snapshots": [ { "snapshot-id": 8890271881640778471, "sequence-number": 1, "timestamp-ms": 1740447644616, "manifest-list": "file:///content/warehouse/default.db/taxi_dataset/metadata/snap-8890271881640778471-0-3f9ae304-2945-44fe-aa50-77ac36b362fd.avro", "summary": { "operation": "append", "added-files-size": "53106652", "added-data-files": "1", "added-records": "3066766", "total-data-files": "1", "total-delete-files": "0", "total-records": "3066766", "total-files-size": "53106652", "total-position-deletes": "0", "total-equality-deletes": "0" }, "schema-id": 0 } ], "snapshot-log": [ { "snapshot-id": 8890271881640778471, "timestamp-ms": 1740447644616 } ], "metadata-log": [ { "metadata-file": "file:///content/warehouse/default.db/taxi_dataset/metadata/00000-a522d21e-4947-4d7a-8b0c-f74a0432b746.metadata.json", "timestamp-ms": 1740447614186 } ], "sort-orders": [ { "order-id": 0, "fields": [] } ], "default-sort-order-id": 0, "refs": { "main": { "snapshot-id": 8890271881640778471, "type": "branch" } }, "format-version": 2, "last-sequence-number": 1 } ```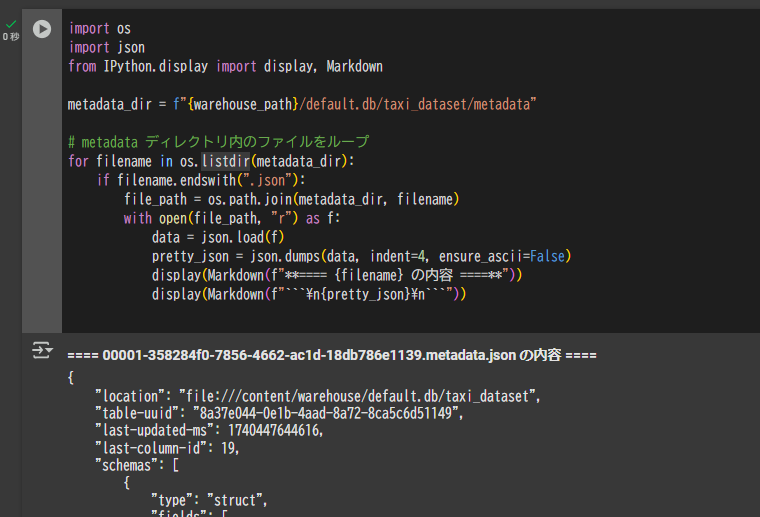
metadata layer の manifest list を確認
!pip install fastavro -q
import os
import json
from fastavro import reader
metadata_dir = f"{warehouse_path}/default.db/taxi_dataset/metadata"
def default_converter(obj):
if isinstance(obj, bytes):
try:
return obj.decode("utf-8")
except UnicodeDecodeError:
return str(obj)
raise TypeError(f"Object of type {obj.__class__.__name__} is not JSON serializable")

# Manifest List の表示 (ファイル名が "snap-" で始まる)
print("==== Manifest List Files ====")
for filename in os.listdir(metadata_dir):
if filename.startswith("snap-") and filename.endswith(".avro"):
file_path = os.path.join(metadata_dir, filename)
print(f"---- {filename} の内容 ----")
with open(file_path, "rb") as fo:
avro_reader = reader(fo)
for record in avro_reader:
print(json.dumps(record, indent=4, ensure_ascii=False, default=default_converter))
print("-" * 40)
snap-8890271881640778471-0-3f9ae304-2945-44fe-aa50-77ac36b362fd.avro
{
"manifest_path": "file:///content/warehouse/default.db/taxi_dataset/metadata/3f9ae304-2945-44fe-aa50-77ac36b362fd-m0.avro",
"manifest_length": 6010,
"partition_spec_id": 0,
"content": 0,
"sequence_number": 1,
"min_sequence_number": 1,
"added_snapshot_id": 8890271881640778471,
"added_files_count": 1,
"existing_files_count": 0,
"deleted_files_count": 0,
"added_rows_count": 3066766,
"existing_rows_count": 0,
"deleted_rows_count": 0,
"partitions": [],
"key_metadata": null
}

metadata layer の manifest file を確認
print("==== Manifest Files ====")
for filename in os.listdir(metadata_dir):
if not filename.startswith("snap-") and filename.endswith(".avro"):
file_path = os.path.join(metadata_dir, filename)
print(f"---- {filename} の内容 ----")
with open(file_path, "rb") as fo:
avro_reader = reader(fo)
for record in avro_reader:
print(json.dumps(record, indent=4, ensure_ascii=False, default=default_converter))
print("-" * 40)
クリックで出力結果を表示可能
3f9ae304-2945-44fe-aa50-77ac36b362fd-m0.avro
{
"status": 1,
"snapshot_id": 8890271881640778471,
"sequence_number": null,
"file_sequence_number": null,
"data_file": {
"content": 0,
"file_path": "file:///content/warehouse/default.db/taxi_dataset/data/00000-0-3f9ae304-2945-44fe-aa50-77ac36b362fd.parquet",
"file_format": "PARQUET",
"partition": {},
"record_count": 3066766,
"file_size_in_bytes": 53106652,
"column_sizes": [
{
"key": 1,
"value": 354603
},
{
"key": 2,
"value": 13992882
},
{
"key": 3,
"value": 14141081
},
{
"key": 4,
"value": 586825
},
{
"key": 5,
"value": 4212146
},
{
"key": 6,
"value": 233063
},
{
"key": 7,
"value": 32330
},
{
"key": 8,
"value": 2176673
},
{
"key": 9,
"value": 3062159
},
{
"key": 10,
"value": 414539
},
{
"key": 11,
"value": 3218715
},
{
"key": 12,
"value": 849762
},
{
"key": 13,
"value": 91291
},
{
"key": 14,
"value": 3665991
},
{
"key": 15,
"value": 410140
},
{
"key": 16,
"value": 60799
},
{
"key": 17,
"value": 5078675
},
{
"key": 18,
"value": 258837
},
{
"key": 19,
"value": 249306
}
],
"value_counts": [
{
"key": 1,
"value": 3066766
},
{
"key": 2,
"value": 3066766
},
{
"key": 3,
"value": 3066766
},
{
"key": 4,
"value": 3066766
},
{
"key": 5,
"value": 3066766
},
{
"key": 6,
"value": 3066766
},
{
"key": 7,
"value": 3066766
},
{
"key": 8,
"value": 3066766
},
{
"key": 9,
"value": 3066766
},
{
"key": 10,
"value": 3066766
},
{
"key": 11,
"value": 3066766
},
{
"key": 12,
"value": 3066766
},
{
"key": 13,
"value": 3066766
},
{
"key": 14,
"value": 3066766
},
{
"key": 15,
"value": 3066766
},
{
"key": 16,
"value": 3066766
},
{
"key": 17,
"value": 3066766
},
{
"key": 18,
"value": 3066766
},
{
"key": 19,
"value": 3066766
}
],
"null_value_counts": [
{
"key": 1,
"value": 0
},
{
"key": 2,
"value": 0
},
{
"key": 3,
"value": 0
},
{
"key": 4,
"value": 71743
},
{
"key": 5,
"value": 0
},
{
"key": 6,
"value": 71743
},
{
"key": 7,
"value": 71743
},
{
"key": 8,
"value": 0
},
{
"key": 9,
"value": 0
},
{
"key": 10,
"value": 0
},
{
"key": 11,
"value": 0
},
{
"key": 12,
"value": 0
},
{
"key": 13,
"value": 0
},
{
"key": 14,
"value": 0
},
{
"key": 15,
"value": 0
},
{
"key": 16,
"value": 0
},
{
"key": 17,
"value": 0
},
{
"key": 18,
"value": 71743
},
{
"key": 19,
"value": 71743
}
],
"nan_value_counts": [],
"lower_bounds": [
{
"key": 1,
"value": "\u0001\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
},
{
"key": 2,
"value": "b'\\x80\\xa1\\xf1\\xb0__\\x04\\x00'"
},
{
"key": 3,
"value": "b'\\xc0\\xfb\\xe1\\xa5l_\\x04\\x00'"
},
{
"key": 4,
"value": "b'\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x80'"
},
{
"key": 5,
"value": "b'\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x80'"
},
{
"key": 6,
"value": "b'\\x00\\x00\\x00\\x00\\x00\\x00\\xf0?'"
},
{
"key": 7,
"value": "N"
},
{
"key": 8,
"value": "\u0001\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
},
{
"key": 9,
"value": "\u0001\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
},
{
"key": 10,
"value": "\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
},
{
"key": 11,
"value": "b'\\x00\\x00\\x00\\x00\\x00 \\x8c\\xc0'"
},
{
"key": 12,
"value": "b'\\x00\\x00\\x00\\x00\\x00\\x00\\x1e\\xc0'"
},
{
"key": 13,
"value": "b'\\x00\\x00\\x00\\x00\\x00\\x00\\xe0\\xbf'"
},
{
"key": 14,
"value": "b'\\xaeG\\xe1z\\x14\\x0eX\\xc0'"
},
{
"key": 15,
"value": "b'\\x00\\x00\\x00\\x00\\x00@P\\xc0'"
},
{
"key": 16,
"value": "b'\\x00\\x00\\x00\\x00\\x00\\x00\\xf0\\xbf'"
},
{
"key": 17,
"value": "b'\\x00\\x00\\x00\\x00\\x00x\\x87\\xc0'"
},
{
"key": 18,
"value": "b'\\x00\\x00\\x00\\x00\\x00\\x00\\x04\\xc0'"
},
{
"key": 19,
"value": "b'\\x00\\x00\\x00\\x00\\x00\\x00\\xf4\\xbf'"
}
],
"upper_bounds": [
{
"key": 1,
"value": "\u0002\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
},
{
"key": 2,
"value": "b'@\\x1f\\x90\\xec\\x98\\xf3\\x05\\x00'"
},
{
"key": 3,
"value": "b'\\xc0\\xf1\\x191\\xb4\\xf3\\x05\\x00'"
},
{
"key": 4,
"value": "\u0000\u0000\u0000\u0000\u0000\u0000\"@"
},
{
"key": 5,
"value": "b'3333\\x81\\x9b\\x0fA'"
},
{
"key": 6,
"value": "b'\\x00\\x00\\x00\\x00\\x00\\xc0X@'"
},
{
"key": 7,
"value": "Y"
},
{
"key": 8,
"value": "\t\u0001\u0000\u0000\u0000\u0000\u0000\u0000"
},
{
"key": 9,
"value": "\t\u0001\u0000\u0000\u0000\u0000\u0000\u0000"
},
{
"key": 10,
"value": "\u0004\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
},
{
"key": 11,
"value": "b'fffff \\x92@'"
},
{
"key": 12,
"value": "\u0000\u0000\u0000\u0000\u0000\u0000)@"
},
{
"key": 13,
"value": "b'\\x14\\xaeG\\xe1z\\x94J@'"
},
{
"key": 14,
"value": "b'\\xcd\\xcc\\xcc\\xcc\\xcc\\xccw@'"
},
{
"key": 15,
"value": "b'H\\xe1z\\x14\\xae\\x9fh@'"
},
{
"key": 16,
"value": "b'\\x00\\x00\\x00\\x00\\x00\\x00\\xf0?'"
},
{
"key": 17,
"value": "b'\\x9a\\x99\\x99\\x99\\x99E\\x92@'"
},
{
"key": 18,
"value": "\u0000\u0000\u0000\u0000\u0000\u0000\u0004@"
},
{
"key": 19,
"value": "b'\\x00\\x00\\x00\\x00\\x00\\x00\\xf4?'"
}
],
"key_metadata": null,
"split_offsets": [
4,
18179359,
36107340
],
"equality_ids": null,
"sort_order_id": null
}
}
まとめ
以上の手順を通じて、Apache Iceberg テーブルの作成やスキーマ進化といった操作の流れを Google Colab 上で実行し、その際に生成されるメタデータファイルの中身を確認できます。Apache Iceberg の構造やメタデータの管理方法を理解する上でも、ぜひ試してみてください。