概要
Databricks で Apache Iceberg テーブルを作成し、Azure Storage に保存したデータを外部サービス(Google Colab 上の Apache Spark/PyIceberg と Snowflake)から操作した検証結果をまとめました。参考にした公式ドキュメントは次のとおりです。
- Databricks の Apache Iceberg とは? | Databricks Documentation
- Apache Iceberg クライアントから Databricks テーブルにアクセスする | Databricks Documentation
検証で特筆すべきポイントは、Iceberg テーブルを作成すると _iceberg だけでなく _delta_log ディレクトリも生成され、DESC HISTORY など Delta Lake のメタデータ操作が行えることです。Databricks では Apache Iceberg と Delta Lake におけるフォーマット統合の一歩目を踏み出したのかもしれません。


⚠️ セキュリティ上の注意
本記事では検証のために トークン を直接スクリプトに記述しています。実運用では OAuth 認証 を優先し、トークンやストレージキーなどの機密情報は Databricks Secrets に登録してください。

引用元:Apache Spark での Iceberg テーブルの使用 | Databricks Documentation
事前準備
環境準備
- Databricks 環境
- Snowflake 環境
- Google Colab 環境
Azure Storage の作成

Azure Storage を参照する Databricks カタログの作成

Databricks で PAT を取得
Databricks のアクセス トークンではない点に注意してください。
from databricks.sdk import WorkspaceClient
client = WorkspaceClient()
# 有効期限 1 時間の PAT を発行
token_response = client.tokens.create(
lifetime_seconds=3600,
comment="PAT token for API access",
)
pat_token = token_response.token_value
print(pat_token)
spark.createDataFrame([{"token": pat_token}]).display()

Unity Catalog 無効クラスタの作成
ストレージ直下のファイル構造を確認するため、Unity Catalog(UC)が無効のクラスタを用意します。

Databricks でマネージド Apache Iceberg テーブルを作成
スキーマの作成
catalog_name = "icebertg_catalog_01"
schema_name = "schema_01"
spark.sql(f"CREATE SCHEMA IF NOT EXISTS {catalog_name}.{schema_name}")

テーブルの作成
table_name = "iceberg_table_01"
spark.sql(f"""
DROP TABLE IF EXISTS {catalog_name}.{schema_name}.{table_name};
""")
spark.sql(f"""
CREATE TABLE {catalog_name}.{schema_name}.{table_name} (
id BIGINT,
amount DOUBLE,
tx_time TIMESTAMP
)
USING ICEBERG;
""")

カタログ エクスプローラーで タイプ = マネージド、データソース = Iceberg であることを確認します。

続いてテーブルの保存パスを取得します。
df = spark.sql(f"""
DESC EXTENDED {catalog_name}.{schema_name}.{table_name}
""")
# Location 行だけ抽出
location = df.where("col_name = 'Location'").collect()[0][1]
print(location)

ディレクトリ構造を確認(UC 無効クラスタ)
UC 無効クラスタにて、Azure Storage への認証情報を設定します。
storage_account = "icebergtest12345"
container = "iceberg"
key = "d1OcHJi1gfQAx4kthk+MyI/XXXXXXX"
spark.conf.set(
f"fs.azure.account.key.{storage_account}.dfs.core.windows.net",
key
)

取得した location を abfss_path に設定し、ディレクトリを一覧表示します。Iceberg 用の _iceberg と Delta Lake 用の _delta_log が共存しているのがわかります。
abfss_path = "abfss://iceberg@icebergtest12345.dfs.core.windows.net/__unitystorage/catalogs/d695b843-f5f0-4fa3-b5ee-e97257986e91/tables/66265b30-60f9-4b70-baa0-d81aa8251f68"
display(dbutils.fs.ls(abfss_path))
_iceberg/metadata には Iceberg のメタデータ、_delta_log には Delta Lake のトランザクションログが保存されています。
display(dbutils.fs.ls(abfss_path + "/_iceberg"))
display(dbutils.fs.ls(abfss_path + "/_iceberg/metadata/"))

display(dbutils.fs.ls(abfss_path + "/_delta_log"))

データ挿入と再確認
UC 有効クラスタでレコードを挿入してみます。
spark.sql(f"""
INSERT INTO {catalog_name}.{schema_name}.{table_name}
VALUES (1, 100.0, current_timestamp()), (2, 250.5, current_timestamp());
""")
df = spark.table(f"{catalog_name}.{schema_name}.{table_name}")
df.sort("id").display()

再度 UC 無効クラスタでディレクトリを確認すると、新たに 00/ フォルダが作成され、その下に Zstandard 圧縮 Parquet ファイルが配置されているのがわかります(フォルダ名は実行タイミングにより変わります)。
display(dbutils.fs.ls(abfss_path))

display(dbutils.fs.ls(abfss_path + "/_iceberg/metadata/"))

display(dbutils.fs.ls(abfss_path + "/_delta_log"))

display(dbutils.fs.ls(abfss_path + "/00"))

Delta Lake の API で読み込み可能なことも確認済みです。
spark.read.format("delta").load(abfss_path).display()

テーブルの履歴を確認
_delta_log があるため、Iceberg テーブルに対しても DESC HISTORY が利用できます。
df = spark.sql(f"""
DESC HISTORY {catalog_name}.{schema_name}.{table_name}
""")
df.display()
一方、Spark Extensions を使った Iceberg 標準の history テーブルは現時点ではサポートされていません。
df = spark.table(f"{catalog_name}.schema_01.iceberg_table_01.history")
display(df.toPandas())



Google Colab(Apache Spark)から Iceberg テーブルを操作
事前準備
Google Colab でノートブックを開き、Spark が利用可能であることを確認します。
!pyspark --version

Databricks の URL、カタログ名、トークンを設定します。
workspace_url = "https://adb-327XXXXX.19.azuredatabricks.net/"
unity_catalog_name = "icebertg_catalog_01"
token = "dkea6bcaa1490a3XXXX"

SparkSession を作成します。
from pyspark.sql import SparkSession
spark = (
SparkSession.builder
.config(
"spark.jars.packages",
"org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.9.2,"
"org.apache.iceberg:iceberg-azure-bundle:1.9.2"
)
.config("spark.sql.extensions",
"org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
.config("spark.sql.catalog.spark_catalog", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.spark_catalog.type", "rest")
.config("spark.sql.catalog.spark_catalog.uri",
f"{workspace_url}/api/2.1/unity-catalog/iceberg-rest")
.config("spark.sql.catalog.spark_catalog.token", token)
.config("spark.sql.catalog.spark_catalog.warehouse", unity_catalog_name)
.getOrCreate()
)

スキーマとテーブルが表示されることを確認します。
spark.sql("SHOW SCHEMAS").show()
spark.sql("SHOW TABLES IN schema_01").show()

データ参照
df = spark.table("schema_01.iceberg_table_01")
display(df.toPandas())

データ書き込み
spark.sql("""
INSERT INTO schema_01.iceberg_table_01
VALUES (3, 300.0, current_timestamp());
""")

Databricks でも書き込まれたことを確認。
df = spark.table(f"{catalog_name}.{schema_name}.{table_name}")
df.sort(df.id.desc()).display()

Google Colab(PyIceberg)から Iceberg テーブルを操作
事前準備
Azure Storage へアクセスするため adlfs も合わせてインストールします。
!pip install pyiceberg adlfs -q

パラメータ設定は先ほどと同様です。
workspace_url = "https://adb-327XXXXX.19.azuredatabricks.net/"
unity_catalog_name = "icebertg_catalog_01"
token = "dkea6bcaa1490a3XXXX"
RestCatalog をインスタンス化。
from pyiceberg.catalog.rest import RestCatalog
catalog = RestCatalog(
name="unity_catalog",
uri=f"{workspace_url}/api/2.1/unity-catalog/iceberg-rest",
warehouse=unity_catalog_name,
token=token,
)

データ参照
table = catalog.load_table("schema_01.iceberg_table_01")
pdf = table.scan().to_pandas()
display(pdf)

データ書き込み
import pyarrow as pa
from datetime import datetime, timezone
# 追加用データ
row = pa.table({
"id": [4],
"amount": [400.0],
"tx_time":[datetime.now(timezone.utc)]
})
table.append(row)

Databricks 側でも挿入を確認。

Snowflake から Iceberg テーブルを操作
事前準備
CREATE EXTERNAL VOLUME は変数展開ができないため、先に必要な値を生成してコピー&ペーストします。
-- 各値を変数としてセット
SET azure_tenant_id = '095ca098-c723-478f-xxxx-xxxxx';
SET azure_storage_account_name = 'icebergtest12345';
SET azure_storage_container_name = 'iceberg';
SET storage_provider = 'AZURE';
-- 結合した URL を変数に事前設定
SET full_storage_uri = 'azure://' || $azure_storage_account_name || '.blob.core.windows.net/' || $azure_storage_container_name;
SELECT
$storage_provider AS STORAGE_PROVIDER,
$full_storage_uri AS STORAGE_BASE_URL,
$azure_tenant_id AS AZURE_TENANT_ID;

上記結果をもとに CREATE EXTERNAL VOLUME を実行します。
CREATE OR REPLACE EXTERNAL VOLUME my_azure_sf_volume
STORAGE_LOCATIONS = (
(
NAME = 'my-azure-sf-container'
STORAGE_PROVIDER = 'AZURE'
STORAGE_BASE_URL = 'azure://icebergtest12345.blob.core.windows.net/iceberg'
AZURE_TENANT_ID = '095ca098-c723-478f-xxxx-xxxxx'
)
)
ALLOW_WRITES = true;

作成した Volume を確認。
DESC EXTERNAL VOLUME my_azure_sf_volume;

次に AZURE_CONSENT_URL をブラウザで開き、Snowflake からのアクセスを許可します。
DESC EXTERNAL VOLUME my_azure_sf_volume;
SELECT
PARSE_JSON($4):AZURE_MULTI_TENANT_APP_NAME::string AS AZURE_MULTI_TENANT_APP_NAME,
PARSE_JSON($4):AZURE_CONSENT_URL::string AS AZURE_CONSENT_URL
FROM TABLE(RESULT_SCAN(LAST_QUERY_ID()))
WHERE $2 = 'STORAGE_LOCATION_1';
承諾をクリック。
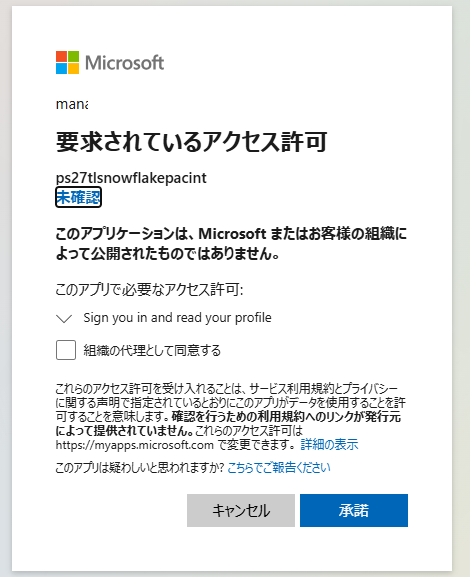
Azure Portal で AZURE_MULTI_TENANT_APP_NAME を検索し、適切なロールを付与します。

:::note info
Snowflake 公式にはクラウド別の手順も用意されています。
外部 Volume の検証が成功することを確認。
SELECT SYSTEM$VERIFY_EXTERNAL_VOLUME('my_azure_sf_volume');

カタログ統合を作成します。
-- 各値を変数としてセット
SET workspace_url = 'https://adb-3274846341828059.19.azuredatabricks.net';
SET unity_catalog_name = 'icebertg_catalog_01';
SET unity_schema_name = 'schema_01';
SET token = 'dapi782363847cXXXXX';
SET catalog_uri = $workspace_url || '/api/2.1/unity-catalog/iceberg-rest';
CREATE OR REPLACE CATALOG INTEGRATION DATABRICKS_ICEBERG_01_DB
CATALOG_SOURCE = ICEBERG_REST
TABLE_FORMAT = ICEBERG
CATALOG_NAMESPACE = $unity_schema_name
REST_CONFIG = (
CATALOG_URI = $catalog_uri
WAREHOUSE = $unity_catalog_name
)
REST_AUTHENTICATION = (
TYPE = BEARER
BEARER_TOKEN = $token
)
ENABLED = TRUE
REFRESH_INTERVAL_SECONDS = 30;

カタログ統合から Snowflake データベースを作成します。
CREATE OR REPLACE DATABASE DATABRICKS_UC_DB
LINKED_CATALOG = (
CATALOG = DATABRICKS_ICEBERG_01_DB
BLOCKED_NAMESPACES = ('information_schema')
)
EXTERNAL_VOLUME = my_azure_sf_volume;

SELECT SYSTEM$CATALOG_LINK_STATUS('DATABRICKS_UC_DB');

SHOW SCHEMAS IN DATABASE DATABRICKS_UC_DB;
SHOW TABLES IN SCHEMA DATABRICKS_UC_DB."schema_01";

データ参照
SELECT * FROM DATABRICKS_UC_DB."schema_01"."iceberg_table_01" ORDER BY 1;

まとめ
- Iceberg テーブル作成時に
_delta_logも生成され、Delta Lake の操作が可能。 - Google Colab(Spark/PyIceberg)、Snowflake からも Iceberg テーブルを共通の REST API で扱える。
- 検証用に PAT を使用したが、実運用では OAuth + Databricks Secrets を推奨。
- ストレージには Iceberg と Delta Lake のメタデータが混在するため、ガバナンスやバックアップ設計時は両方を考慮すること。