概要
この記事では、Azure Data Factory を使用して、下記のような改行(\n)を含む区切りテキスト形式のファイルを Databricks Delta Lake コネクターを介して Databricks に書き込む方法を共有します。Spark Dataframe では、カラム内に改行が含まれている場合、multiLineをTrueに設定することで想定通りに読み取ることができます。同様の設定は Azure Data Factory でも必要です。
id,text
"1","abc"
"2","あいう
"
"3","123"

Azure Data Factory でデフォルトの設定で書き込む場合、エラーが発生します。この問題を解決するために、Azure Data Factory におけるパイプライン定義の json に additionalFormatOptions を直接追記する方法を採用します。
以下はエラーメッセージの例です。
ErrorCode=AzureDatabricksCommandError,Hit an error when running the command in Azure Databricks. Error details: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 6.0 failed 4 times, most recent failure: Lost task 0.3 in stage 6.0 (TID 9) (10.139.64.10 executor 0): org.apache.spark.SparkException: [TASK_WRITE_FAILED] Task failed while writing rows to dbfs:/user/hive/warehouse/multi_line_test.db/test.
Caused by: com.databricks.sql.io.FileReadException: Error while reading file wasbs:REDACTED_LOCAL_PART@{storage_name}.blob.core.windows.net/multiline/source.txt.
Caused by: org.apache.spark.SparkException: [MALFORMED_RECORD_IN_PARSING.WITHOUT_SUGGESTION] Malformed records are detected in record parsing: [
Caused by: org.apache.spark.sql.catalyst.util.BadRecordException: org.apache.spark.SparkRuntimeException: [MALFORMED_CSV_RECORD] Malformed CSV record: "
Caused by: org.apache.spark.SparkRuntimeException: [MALFORMED_CSV_RECORD] Malformed CSV record: "
Caused by: org.apache.spark.SparkException: [TASK_WRITE_FAILED] Task failed while writing rows to dbfs:/user/hive/warehouse/multi_line_test.db/test.
Caused by: com.databricks.sql.io.FileReadException: Error while reading file wasbs:REDACTED_LOCAL_PART@{storage_name}.blob.core.windows.net/multiline/source.txt.
Caused by: org.apache.spark.SparkException: [MALFORMED_RECORD_IN_PARSING.WITHOUT_SUGGESTION] Malformed records are detected in record parsing: [
Caused by: org.apache.spark.sql.catalyst.util.BadRecordException: org.apache.spark.SparkRuntimeException: [MALFORMED_CSV_RECORD] Malformed CSV record: "
Caused by: org.apache.spark.SparkRuntimeException: [MALFORMED_CSV_RECORD] Malformed CSV record: ".

``
Databricks におけるmultiLineについて、下記の記事において紹介しています。
エラーとなるコードと対応策
事前準備
改行を含む区切りテキストファイルを Azure Storage に配置します。
id,text
"1","abc"
"2","あいう
"
"3","123"

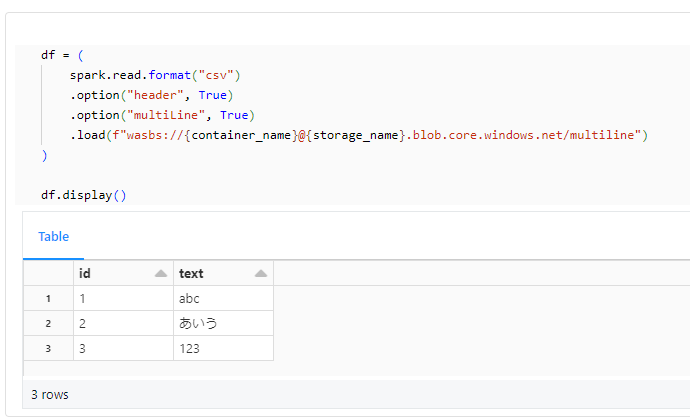
Databricks からストレージのファイルを想定通りに参照できることを確認します。
storage_name = "" # Azure Storage名
container_name = "" # Azure Storage のコンテナー名
df = (
spark.read.format("csv")
.option("header", True)
.option("multiLine", True)
.load(f"wasbs://{container_name}@{storage_name}.blob.core.windows.net/multiline")
)
df.display()
Databricks で書き込み先の Hive metastore のテーブルを作成します。
%sql
CREATE SCHEMA IF NOT EXISTS multi_line_test;
CREATE OR REPLACE TABLE multi_line_test.test (
id string,
text string
);

エラー事象を確認
Azure Storage から Databricks へ書き込むパイプラインを作成して実行します。すると、下記のようなエラーが発生します。
ErrorCode=AzureDatabricksCommandError,Hit an error when running the command in Azure Databricks. Error details: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 6.0 failed 4 times, most recent failure: Lost task 0.3 in stage 6.0 (TID 9) (10.139.64.10 executor 0): org.apache.spark.SparkException: [TASK_WRITE_FAILED] Task failed while writing rows to dbfs:/user/hive/warehouse/multi_line_test.db/test.
Caused by: com.databricks.sql.io.FileReadException: Error while reading file wasbs:REDACTED_LOCAL_PART@{storage_name}.blob.core.windows.net/multiline/source.txt.
Caused by: org.apache.spark.SparkException: [MALFORMED_RECORD_IN_PARSING.WITHOUT_SUGGESTION] Malformed records are detected in record parsing: [
Caused by: org.apache.spark.sql.catalyst.util.BadRecordException: org.apache.spark.SparkRuntimeException: [MALFORMED_CSV_RECORD] Malformed CSV record: "
Caused by: org.apache.spark.SparkRuntimeException: [MALFORMED_CSV_RECORD] Malformed CSV record: "
Caused by: org.apache.spark.SparkException: [TASK_WRITE_FAILED] Task failed while writing rows to dbfs:/user/hive/warehouse/multi_line_test.db/test.
Caused by: com.databricks.sql.io.FileReadException: Error while reading file wasbs:REDACTED_LOCAL_PART@{storage_name}.blob.core.windows.net/multiline/source.txt.
Caused by: org.apache.spark.SparkException: [MALFORMED_RECORD_IN_PARSING.WITHOUT_SUGGESTION] Malformed records are detected in record parsing: [
Caused by: org.apache.spark.sql.catalyst.util.BadRecordException: org.apache.spark.SparkRuntimeException: [MALFORMED_CSV_RECORD] Malformed CSV record: "
Caused by: org.apache.spark.SparkRuntimeException: [MALFORMED_CSV_RECORD] Malformed CSV record: ".
エラーへの対応策を実施
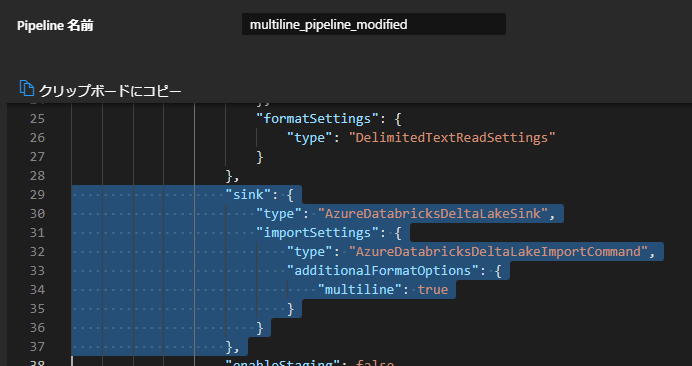
Azure Data Factory にて、パイプライン右上に表示されているこのソースの json コード表現を表示するをクリックして、定義の json を表示します。
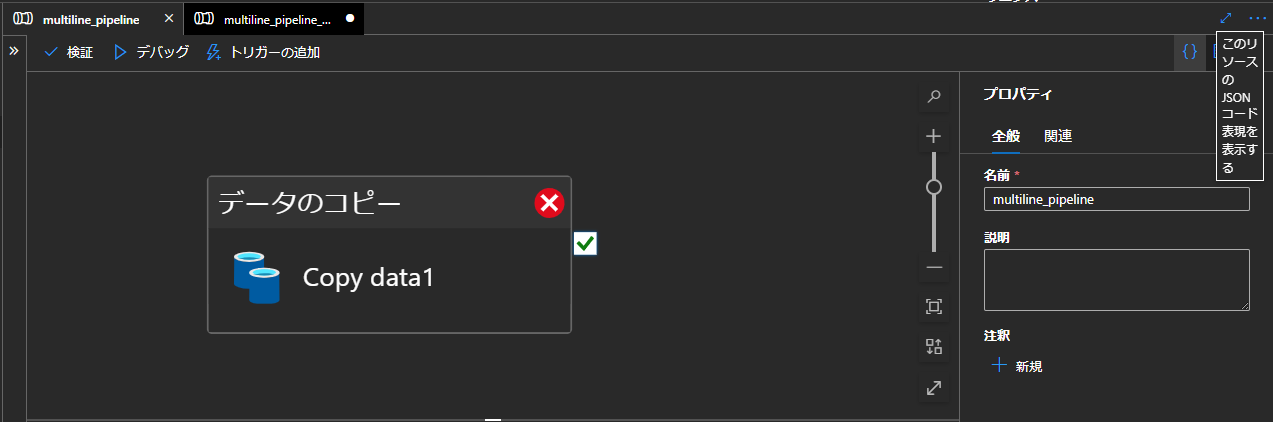
次に、sink の項目を探し、importSettings に additionalFormatOptions を追加します。
"additionalFormatOptions": {
"multiline": true
}

設定前後を比較すると、次のようになります。
"sink": {
"type": "AzureDatabricksDeltaLakeSink",
"importSettings": {
"type": "AzureDatabricksDeltaLakeImportCommand"
}
},

"sink": {
"type": "AzureDatabricksDeltaLakeSink",
"importSettings": {
"type": "AzureDatabricksDeltaLakeImportCommand",
"additionalFormatOptions": {
"multiline": true
}
}
},

パイプラインを実行し、正常終了することを確認します。
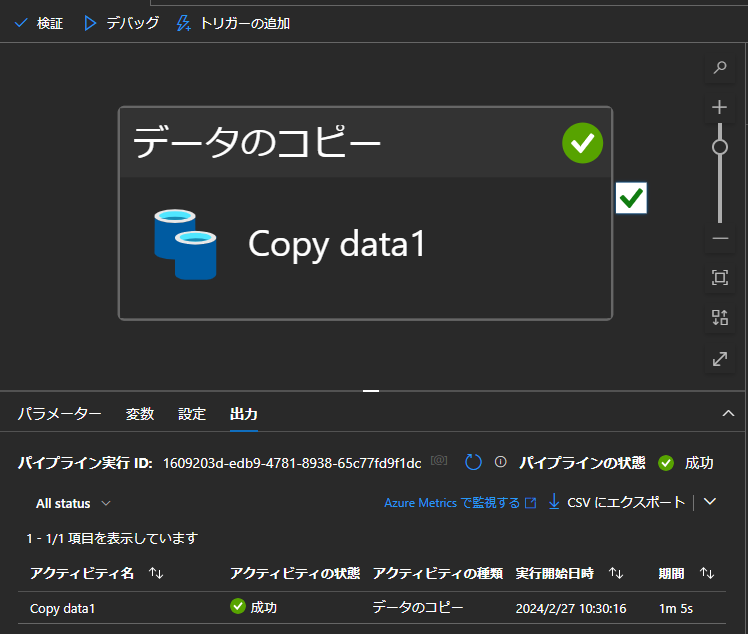
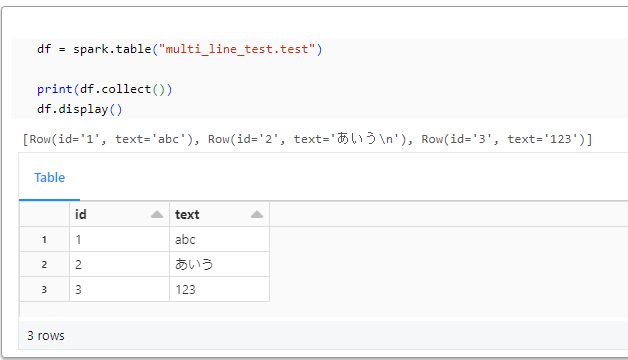
最後に、Databricks でテーブルに書き込まれていることを確認します。
df = spark.table("multi_line_test.test")
print(df.collect())
df.display()
[
Row(id="1", text="abc"),
Row(id="2", text="あいう\n"),
Row(id="3", text="123"),
]