概要
Databricks ( Spark ) にて 引用符 ( sep ) 内に 区切り文字 ( lineSep ) が含まれる CSV ファイルを取り込む場合には multiLine を true に設定する必要があるようです。
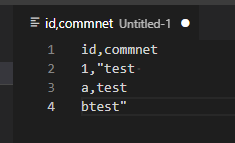
引用符 ( sep ) 内に 区切り文字 ( lineSep ) が含まれる CSV ファイルとは、カラム値が " で囲まれており、その値内で \r が入っているファイルのことです。
id,commnet
1,"test
a,test
btest"
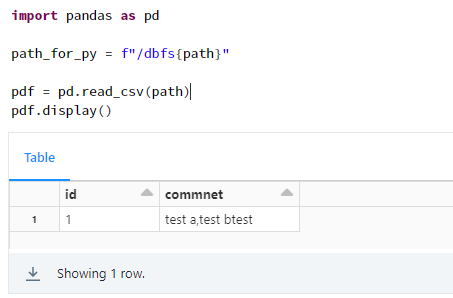
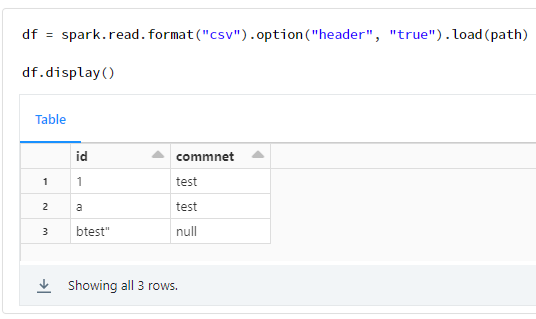
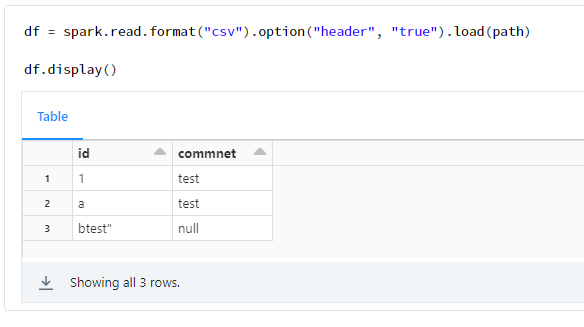
私がさわってきたツールではデフォルトで1つの値として認識してくれることが多かったのですが、Spark では異なるようです。下記に、Pandas での実行例と Spark での実行例を記載しております。Pandas では 1 行のデータフレームとなっておりますが、Spark では 3 行のデータフレームとなっております。
Pandas での実行例
import pandas as pd
path_for_py = f"/dbfs{path}"
pdf = pd.read_csv(path)
pdf.display()
Spark での実行例
df = spark.read.format("csv").option("header", "true").load(path)
df.display()
対応方法としては、multiLineを trueに設定すればいいようです。
Parse one record, which may span multiple lines, per file. CSV built-in functions ignore this option.

引用元:CSV Files - Spark 3.3.1 Documentation (apache.org)
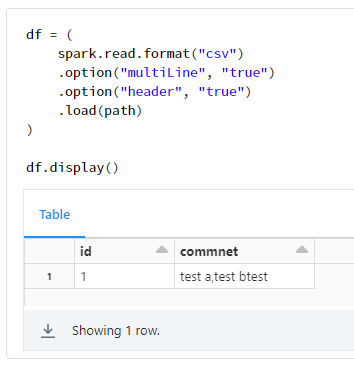
df = (
spark.read.format("csv")
.option("multiLine", "true")
.option("header", "true")
.load(path)
)
df.display()
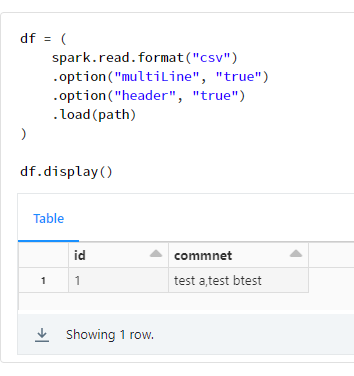
検証コード
1. サンプルファイルを配置
import inspect
from pyspark.sql import DataFrame, SparkSession
from pyspark.dbutils import DBUtils
def put_files_to_storage(
path,
content,
is_overwrite=True,
):
# 最初の行と最後の行を削除
content = inspect.cleandoc(content)
spark = SparkSession.getActiveSession()
dbutils = DBUtils(spark)
return dbutils.fs.put(path, content, is_overwrite)
path = "/test/test.csv"
csv_data_rows = """
id,commnet
1,"test
a,test
btest"
"""
put_files_to_storage(path, csv_data_rows)
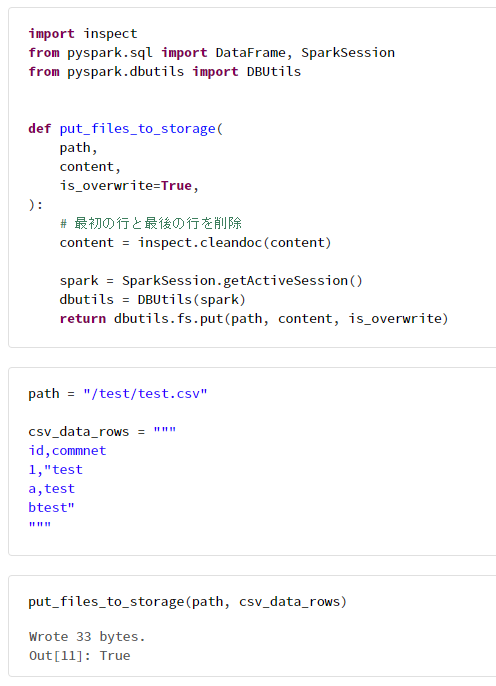
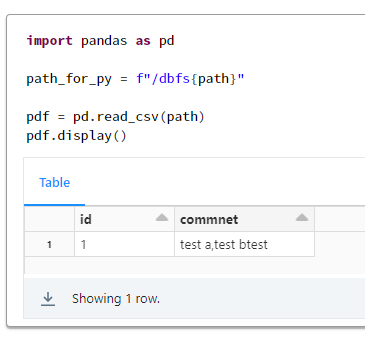
2. Pandas での実行例
import pandas as pd
path_for_py = f"/dbfs{path}"
pdf = pd.read_csv(path)
pdf.display()
3. Spark (デフォルト) での実行例
df = spark.read.format("csv").option("header", "true").load(path)
df.display()
4. Spark (multiLineをtrueに設定) での実行例
df = (
spark.read.format("csv")
.option("multiLine", "true")
.option("header", "true")
.load(path)
)
df.display()
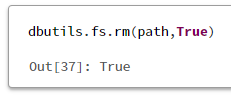
5. リソースを削除
dbutils.fs.rm(path,True)