概要
dbt(Data Build tool)を、前提知識となるデータエンジニアリングにおける現状を踏まえて、どういったツールであるかを説明します。dbtがデータエンジニアリングのあるべき姿としてデザインされており、共有されることが少ないデータエンジニアリングのナレッジを含むため、dbtを利用しない場合でも本記事の内容は有益な情報となっております。
dbtの概要については、下記の記事で整理しています。
データエンジニアリングの技術背景
ストレージコンピューティングの分離が可能なデータ処理エンジン(Spark、Presto等)がデータ分析基盤のデータストアとして用いられるようになってきています。従来であればデータレイクではデータの管理が困難であったが、レイクハウスフォーマット(Delta Lake、Hudi、Iceberg等)の開発によりデータレイクにACID特性を持たせられるようになり、データ処理エンジンの利用が容易となりました。さらに、クラウドコンピューティングの普及により、データ処理の要求に応じてコンピューティングを柔軟にスケールアップが可能となったことにより、ビッグデータ処理が可能なデータ処理エンジンがデータ分析基盤の中心的な役割を担うようになってきました。Snowflakeにおいても、同様の特性があることから、データ分析基盤として注目されています。
ビッグデータの処理が容易となったこで、Databricks社が提唱しているようなメダリオンアーキテクチャ(ローデータをBronze、一時加工したデータをSilver、データ活用に利用するデータをGoldとして管理する方法)に基づきデータが蓄積されるようなりました。そのアーキテクチャでは、ローデータに対して必要に応じて処理を行うELT(抽出、ロード、変換)が実施されます。
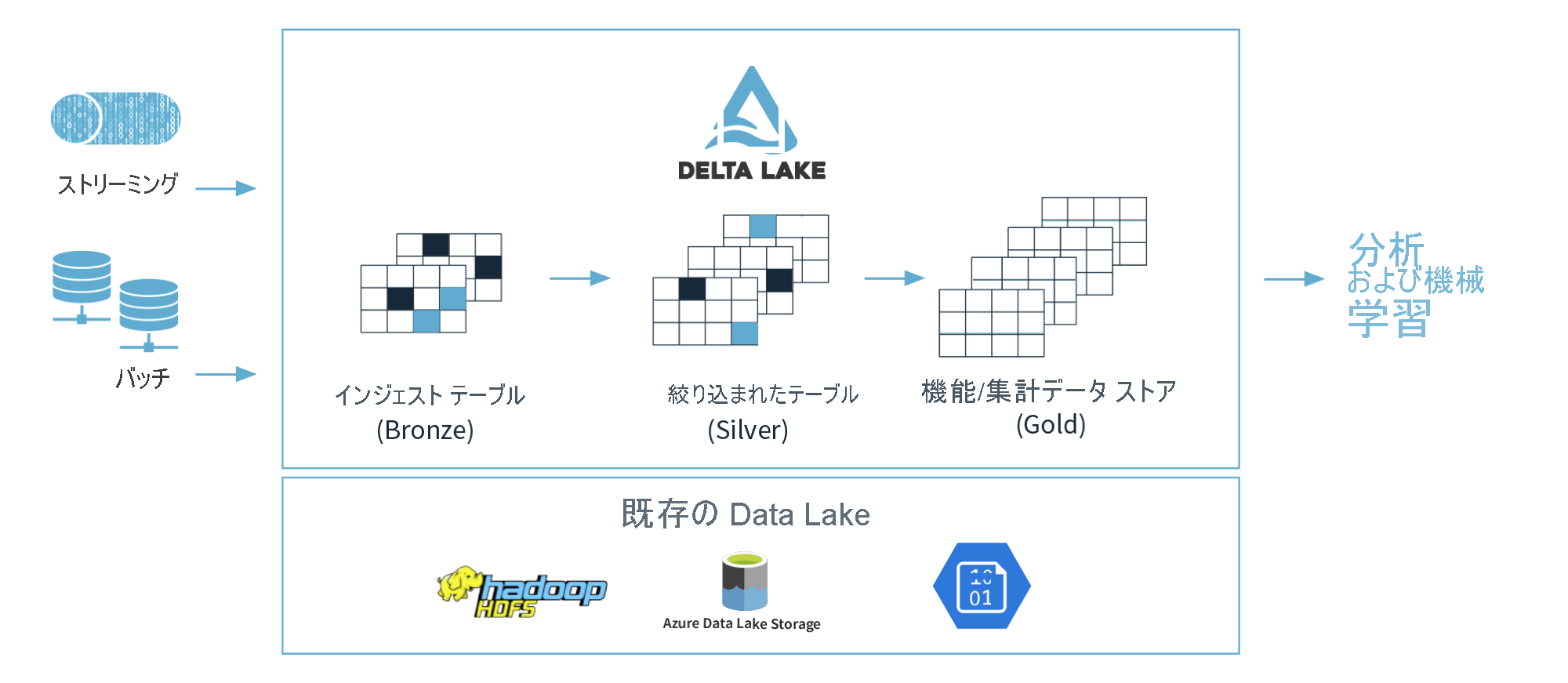
引用元:ブロンズ、シルバー、ゴールドのアーキテクチャについて - Learn | Microsoft Docs
dbtでは、ELTにおけるT(変換)を最適に実施するためのツールとして開発されました。dbtでは、ローデータのテーブルをSourcesとして、また、ローデータのテーブルから派生したテーブルをModelsとしてそれぞれ扱い、それらの抽出元(SQL文におけるFROM句から判断)からテーブルの依存関係をDAG(有向非巡回グラフ)として定義します。DAGに応じて、データのパイプラインを実行することやドキュメントとして可視化することが可能となります。
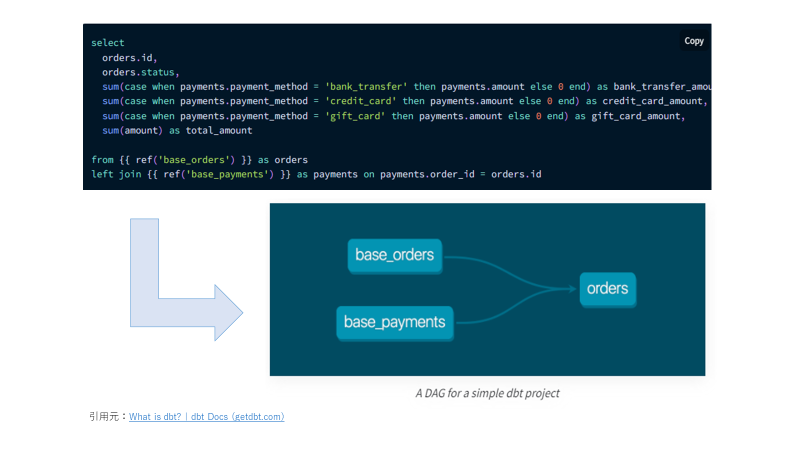
dbtにおける最も重要な設計思想の1つは、データエンジニアリングにDRY原則(Don’t Repeat Your Self)の適用にあるようです。SQLは他言語と比べると、簡単に記述できるが再利用性が低いという特徴があります。特にデータ分析システムでは、コードが長くなることやパフォーマンスを考慮した記述を行うこともあり、再利用性が低いです。ストアードプロシージャにて再利用性を高める試みもありますが、可読性が悪い印象があります。そのような問題への対策として、dbtでは、Macrosやソースへの参照によりSQLのモジュール化が可能です。
データエンジニアリング時にテストの実行も考慮されていることも特徴的です。システムテストを行うというよりは、データに対するテストを実行します。一般的なDWHやデータレイクでは、一意制約等の制約機能を設定できない場合もあり、データエンジニアリングは、システム運用の時間の経過とともにデータの品質が悪くなってしまうことがあります。たとえば、snowflakeでドキュメント(制約の概要 — Snowflake Documentation)では、Snowflakeは、制約の定義と維持をサポートしていますが、常に強制される NOT NULL 制約以外については強制しませんとあり、制約の保証が実施されないようです。dbtでは、一般的な制約(ユニークキー制約、NOT NULL制約、ドメイン制約、外部キー制約)やデータ鮮度の確認がデフォルトで実行であり、SQLでテストを実行でます。
dbtにおけるコンポーネントの全体像
dbtのコンポーネントを、ソース(Source)からデータ活用(Data analytics)のフローに基づいて整理したものが下記図です。フローの観点とコンポーネントの観点でそれぞれ説明します。
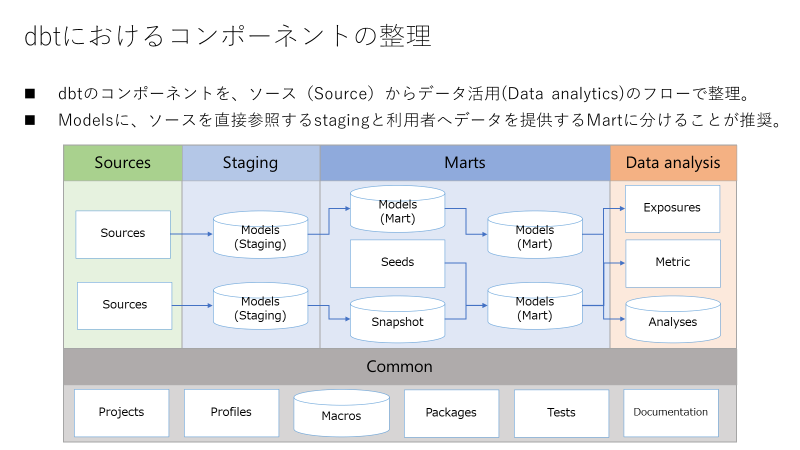
dbtを用いてデータ活用を実施するまでのフロー
フローを下記の4つに分割していますが、1~3はdbtが推奨するModelsの区分けであり、4は私が追加しました。
| # | 分類 | 概要 |
|---|---|---|
| 1 | Sources | 参照元のローデータの定義を実施。 |
| 2 | Staging | ソースに対する1対1関係となるようにモデルの定義を実施。 |
| 3 | Marts | Stagingのモデルに基づき、データ活用に用いるモデルの定義を実施。 |
| 4 | Data Analysis | dbtにて処理したテーブルに対するデータ活用の支援を実施。 |
MartsからSourcesを直接参照させずにStagingを経由する理由としては、dbtのドキュメントに下記のような記載がある通り、ローデータのテーブルの仕様変更への対応を容易にするためやデータ分析システム内での規則に合わせて命名を変更するためです。
Since this data is normally loaded by third parties, the structure of it can change over time – tables and columns may be added, removed, or renamed. When this happens, it is easier to update models if raw data is only referenced in one place.
引用元:Best practices | dbt Docs (getdbt.com)
データは通常サードパーティによってロードされるため、データの構造は時間の経過とともに変化する可能性があります。テーブルと列は追加、削除、または名前変更される可能性があります。これが発生した場合、生データが1つの場所でのみ参照されると、モデルを更新するのが簡単になります。
上記引用文の翻訳
Rename and recast fields once
Raw data is generally stored in a source-conformed structure, that is, following the schema and naming conventions that the source defines. Not only will this structure differ between different sources, it is also likely to differ from the naming conventions you wish to use for analytics.
引用元:Best practices | dbt Docs (getdbt.com)
フィールドの名前を変更してキャストし直す
生データは通常、ソースに準拠した構造で保存されます。つまり、ソースが定義するスキーマと命名規則に従います。この構造はソースごとに異なるだけでなく、分析に使用する命名規則とも異なる可能性があります。
上記引用文の翻訳
Data Analysisにあるコンポーネントについては、dbtで処理を実行するものではなく、一時的にクエリを発行する際やドキュメントに記載する際に利用します。dbtの公式オンラインコースであるRefactoring SQL for Modularity(Refactoring SQL for Modularity (getdbt.com))では、リファクタリング前後のコードの実行結果が同一となることを確認する際に、データ比較のSQL文をコンパイルするAnalysesを用いた方法が紹介されています。
dbtにおける主なコンポーネント
dbtにおける主なコンポーネントを下記表に整理します。
| # | 分類 | コンポーネント | 概要 | 定義方法 |
|---|---|---|---|---|
| 1 | Common | Projects | dbtプロジェクトの基本情報を保持。 |
dbt_project.ymlにて定義。 |
| 2 | Common | Profiles | 接続先データストアの接続情報を保持。 |
profiles.ymlにて定義。dbt CLIの場合にのみ定義が必要。 |
| 3 | Source | Sources | 接続先データストアに存在するローデータのテーブル情報を保持。 |
sources直下のYAMLファイルにて定義。 |
| 4 | Staging | Models | マテリアライゼーションするテーブルのSELECT文を保持。 |
models直下のSQLファイルにて定義。必要に応じて、YAMLファイルも定義。 |
| 5 | Marts | Models | マテリアライゼーションするテーブルのSELECT文を保持。 |
models直下のSQLファイルにて定義。必要に応じて、YAMLファイルも定義。 |
| 6 | Marts | Seeds | データストアにロードするデータとテーブルの定義を保持。 |
seeds直下のCSVファイルにて記載。 |
| 7 | Marts | Snapshot | SCD Type2を実施するテーブルの定義を保持。 |
snapshot直下のSQLファイルにて定義。 |
| 8 | Data Analysis | Exposures | dbtで定義したModelsのダウンストリームの利用方法を保持。 |
models直下のYAMLファイルにて定義。 |
| 9 | Data Analysis | Metric | dbtで定義したModelsから集計方法の情報(メトリック、メジャー)を保持。 |
models直下のYAMLファイルにて定義。 |
| 10 | Data Analysis | Analyses | データ活用に用いるSQL文を保持 |
analyses直下のSQLファイルにて定義。 |
| 11 | Common | Macros | Jinjaで記載した再利用可能なロジックを保持。 |
macros直下のSQLファイルにて定義。 |
| 12 | Common | Packages | dbt hub等にて共有されている再利用可能なMacrosのパッケージの取得情報を保持。 |
packages.ymlにて定義。 |
| 13 | Common | Tests | モデルやソースなどに対するテストを定義。 |
tests直下のSQLファイル、SourcesのYAMLファイル、あるいは、ModelsのYAMLファイルにて定義。 |
| 14 | Common | Documentation | 各コンポーネントの定義に基づいて、ドキュメントを生成。 | 各コンポーネントで定義。 |
Modelsでは、SELECT文によるSQLファイルに定義を行うだけで、dbtにより変換されたDDL(ビューやテーブルの作成)とDML(データのロード)を行うSQL文がデータストアに実行されます。データストアに対してDDLとDMLを実行することをマテリアライゼーションと呼んでおり、設定に応じた処理が実行されます。SCD Type2を実施したい場合には、Modelsではなく、Snapshotを利用します。マテリアライゼーションにはephemeralという方法もありますが、データストアでの実体化は行わず、dbt内部でのみ利用されます。
| # | 実施内容 | 定義方法 |
|---|---|---|
| 1 | ビューを作成 |
configにてmaterialized='view'を記載 |
| 2 | 全件更新(CTAS) |
configにてmaterialized='table'を記載 |
| 3 | 増分更新 |
configにてmaterialized='incremental'を記載 |
| 4 | 差分更新(Merge、あるいは、Delete+Insert) |
configにてmaterialized='incremental'とunique_keyを記載 |
マテリアライゼーションの仕様を知った際にはビュの作成とテーブルへのロードが同列で扱われていることに違和感を覚えましたが、パフォーマンスに課題をかかえた際にビューからテーブルに切り替えた際にダウンストリームのコードの修正が不要であることがメリットであるとに気付きました。dbtでは、下記のような優先時順位でマテリアライゼーション方法の選択が推奨されています。
- Use views by default
- Use ephemeral models for lightweight transformations that shouldn't be exposed to end-users
- Use tables for models that are queried by BI tools
- Use tables for models that have multiple descendants
- Use incremental models when the build time for table models exceeds an acceptable threshold
引用元:Best practices | dbt Docs (getdbt.com)
- デフォルトでビューを使用
- エンドユーザーに公開すべきでないモデルの場合には、一時的なモデルを仕様
- BIツールによって照会されるモデルの場合には、テーブルを使用
- 複数の子孫を持つモデルの場合には、テーブルを使用
- テーブルモデルのビルド時間が許容可能なしきい値を超える場合には、インクリメンタルモデルを使用
上記引用文の翻訳
私は差分更新を第一の選択肢として考えてしまうのですが、dbtでは差分更新を行うことでシステムが複雑になることで運用コスト増加要因となることから推奨されていないようです。データストアのコンピューティングへの支払いにリソースを割くのか、システムの運用体制にリソースを割くのかを選択する必要があります。それぞれのマテリアライゼーション方法の長所と短所については、マテリアライゼーション| dbtドキュメント (getdbt.com) にまとめられています。
SQLのモジュール化(コンポーネント化)の実践例
概要
SQLをモジュール化する手順を、dbtの公式オンラインコースであるRefactoring SQL for Modularity(Refactoring SQL for Modularity (getdbt.com) にて提示されている既存コードのリファクタリングをベースに紹介します。
モジュール化する手順としては下記の手順を実施します。
- クエリ種類(Import、Logical、Final)に応じてCTEにより分割したSQL文に変更
- ローデータのテーブルをSourcesとして、モデルとして外部で管理する場合にはModelsとして別のファイルで定義
- Sources、あるいは、Modelsの定義を参照するように変更
dbtでは、下記の3つのクエリ種類を別々のCTEで定義して、FinalのCTEに対するSELECT文で記述することが推奨されています。CTEとは、common table expressionの略であり、WITH 句で定義された名前付きサブクエリです。
| # | クエリ種類 | 概要 |
|---|---|---|
| 1 | Import | データを取得するクエリ。 |
| 2 | Logical | データを加工するクエリ。 |
| 3 | Final | 最終的に出力するデータのクエリ。 |
SELECT文の推奨記述方法の例
with
import_orders as (
-- query only non-test orders
select * from {{ source('jaffle_shop', 'orders') }}
where amount > 0
),
import_customers as (
select * from {{ source('jaffle_shop', 'customers') }}
),
logical_cte_1 as (
-- perform some math on import_orders
),
logical_cte_2 as (
-- perform some math on import_customers
),
final_cte as (
-- join together logical_cte_1 and logical_cte_2
)
select * from final_cte
引用元:Refactoring legacy SQL to dbt SQL | dbt Docs (getdbt.com)
本記事では下記のSQL文のコンポーネント化を実施します。
with
paid_orders as (
select orders.id as order_id,
orders.user_id as customer_id,
orders.order_date as order_placed_at,
orders.status as order_status,
p.total_amount_paid,
p.payment_finalized_date,
c.first_name as customer_first_name,
c.last_name as customer_last_name
from {{ source('jaffle_shop', 'orders') }} as orders
left join (
select
orderid as order_id,
max(created) as payment_finalized_date,
sum(amount) / 100.0 as total_amount_paid
from {{ source('stripe', 'payment') }} as payments
where status <> 'fail'
group by 1
) p on orders.id = p.order_id
left join {{ source('jaffle_shop', 'customers') }} as c on orders.user_id = c.id ),
customer_orders as (
select
c.id as customer_id
, min(order_date) as first_order_date
, max(order_date) as most_recent_order_date
, count(orders.id) as number_of_orders
from {{ source('jaffle_shop', 'customers') }} c
left join {{ source('jaffle_shop', 'orders') }} as orders on orders.user_id = c.id
group by 1
)
select
p.*,
row_number() over (order by p.order_id) as transaction_seq,
row_number() over (partition by customer_id order by p.order_id) as customer_sales_seq,
case when c.first_order_date = p.order_placed_at
then 'new'
else 'return' end as nvsr,
x.clv_bad as customer_lifetime_value,
c.first_order_date as fdos
from paid_orders p
left join customer_orders as c using (customer_id)
left outer join
(
select
p.order_id,
sum(t2.total_amount_paid) as clv_bad
from paid_orders p
left join paid_orders t2 on p.customer_id = t2.customer_id and p.order_id >= t2.order_id
group by 1
order by p.order_id
) x on x.order_id = p.order_id
order by order_id
1.クエリ種類(Import、Logical、Final)に応じてCTEにより分割したSQL文に変更
データ取得元のテーブルを特定して、ImportのCTEを作成します。
下記のテーブルが参照されております。
- raw.jaffle_shop.orders
- raw.jaffle_shop.customers
- raw.stripe.payment
データを取得するシンプルなSELECT文をテーブル別にCTEで定義します。
with
-- Import CTEs
customers as (
select * from raw.jaffle_shop.orders
),
orders as (
select * from raw.jaffle_shop.customers
),
payments as (
select * from raw.stripe.payment
),
次に、データの変換のロジックが含まれるクエリを特定して、ImportのCTEを作成します。
下記の箇所が該当します。
- paid_ordersのCTE
- customer_ordersのCTE
- 最後のSELECT文
Import CTEsを参照するように、CTEで定義します。
-- Logical CTEs
completed_payments as (
select
orderid as order_id,
max(created) as payment_finalized_date,
sum(amount) / 100.0 as total_amount_paid
from payments
where status <> 'fail'
group by 1
),
paid_orders as (
select orders.id as order_id,
orders.user_id as customer_id,
orders.order_date as order_placed_at,
orders.status as order_status,
p.total_amount_paid,
p.payment_finalized_date,
c.first_name as customer_first_name,
c.last_name as customer_last_name
from orders
left join completed_payments as p
on orders.id = p.order_id
left join customers as c
on orders.user_id = c.id ),
customer_orders as (
select
c.id as customer_id
, min(order_date) as first_order_date
, max(order_date) as most_recent_order_date
, count(orders.id) as number_of_orders
from customers as c
left join orders
on orders.user_id = c.id
group by 1
),
x as (
select
p.order_id,
sum(t2.total_amount_paid) as clv_bad
from paid_orders p
left join paid_orders t2
on p.customer_id = t2.customer_id
and p.order_id >= t2.order_id
group by 1
order by p.order_id
),
次に、データの変換のロジックが含まれるクエリを特定して、FinalのCTEを作成します。
残りのSQL文が該当します。
final as (
select
p.*,
row_number() over (order by p.order_id) as transaction_seq,
row_number() over (partition by customer_id order by p.order_id) as customer_sales_seq,
case when c.first_order_date = p.order_placed_at
then 'new'
else 'return' end as nvsr,
x.clv_bad as customer_lifetime_value,
c.first_order_date as fdos
from paid_orders p
left join customer_orders as c
using (customer_id)
left join x
on x.order_id = p.order_id
order by order_id
)
次にFinal CTEを参照するselect文を定義します。
-- Simple Select Statment
select * from final
現時点でのクエリは下記です。
with
-- Import CTEs
customers as (
select * from raw.jaffle_shop.orders
),
orders as (
select * from raw.jaffle_shop.customers
),
payments as (
select * from raw.stripe.payment
),
-- Logical CTEs
completed_payments as (
select
orderid as order_id,
max(created) as payment_finalized_date,
sum(amount) / 100.0 as total_amount_paid
from payments
where status <> 'fail'
group by 1
),
paid_orders as (
select orders.id as order_id,
orders.user_id as customer_id,
orders.order_date as order_placed_at,
orders.status as order_status,
p.total_amount_paid,
p.payment_finalized_date,
c.first_name as customer_first_name,
c.last_name as customer_last_name
from orders
left join completed_payments as p
on orders.id = p.order_id
left join customers as c
on orders.user_id = c.id ),
customer_orders as (
select
c.id as customer_id
, min(order_date) as first_order_date
, max(order_date) as most_recent_order_date
, count(orders.id) as number_of_orders
from customers as c
left join orders
on orders.user_id = c.id
group by 1
),
x as (
select
p.order_id,
sum(t2.total_amount_paid) as clv_bad
from paid_orders p
left join paid_orders t2
on p.customer_id = t2.customer_id
and p.order_id >= t2.order_id
group by 1
order by p.order_id
),
final as (
select
p.*,
row_number() over (order by p.order_id) as transaction_seq,
row_number() over (partition by customer_id order by p.order_id) as customer_sales_seq,
case when c.first_order_date = p.order_placed_at
then 'new'
else 'return' end as nvsr,
x.clv_bad as customer_lifetime_value,
c.first_order_date as fdos
from paid_orders p
left join customer_orders as c
using (customer_id)
left join x
on x.order_id = p.order_id
order by order_id
)
-- Simple Select Statment
select * from final
2.ローデータのテーブルをSourcesとして、モデルとして外部で管理する場合にはModelsとして別のファイルで定義
今回は下記のテーブルを参照しているため、それらをSoucesとして別の定義します。
- raw.jaffle_shop.orders
- raw.jaffle_shop.customers
- raw.stripe.payment
Sourcesは、YAML形式のファイルとして下記のように定義します。
version: 2
sources:
- name: jaffle_shop
database: raw
tables:
- name: customers
- name: orders
version: 2
sources:
- name: stripe
database: raw
tables:
- name: payment
3. その定義を参照するように変更
Import CTEsの個所を修正します。
with
-- Import CTEs
customers as (
select * from {{ source('jaffle_shop', 'customers') }}
),
orders as (
select * from {{ source('jaffle_shop', 'orders') }}
),
payments as (
select * from {{ source('stripe', 'payment') }}
),
最終的には下記のようなクエリとなります。
with
-- Import CTEs
customers as (
select * from {{ source('jaffle_shop', 'customers') }}
),
orders as (
select * from {{ source('jaffle_shop', 'orders') }}
),
payments as (
select * from {{ source('stripe', 'payment') }}
),
-- Logical CTEs
completed_payments as (
select
orderid as order_id,
max(created) as payment_finalized_date,
sum(amount) / 100.0 as total_amount_paid
from payments
where status <> 'fail'
group by 1
),
paid_orders as (
select orders.id as order_id,
orders.user_id as customer_id,
orders.order_date as order_placed_at,
orders.status as order_status,
p.total_amount_paid,
p.payment_finalized_date,
c.first_name as customer_first_name,
c.last_name as customer_last_name
from orders
left join completed_payments as p
on orders.id = p.order_id
left join customers as c
on orders.user_id = c.id ),
customer_orders as (
select
c.id as customer_id
, min(order_date) as first_order_date
, max(order_date) as most_recent_order_date
, count(orders.id) as number_of_orders
from customers as c
left join orders
on orders.user_id = c.id
group by 1
),
x as (
select
p.order_id,
sum(t2.total_amount_paid) as clv_bad
from paid_orders p
left join paid_orders t2
on p.customer_id = t2.customer_id
and p.order_id >= t2.order_id
group by 1
order by p.order_id
),
-- Final CTE
final as (
select
p.*,
row_number() over (order by p.order_id) as transaction_seq,
row_number() over (partition by customer_id order by p.order_id) as customer_sales_seq,
case when c.first_order_date = p.order_placed_at
then 'new'
else 'return' end as nvsr,
x.clv_bad as customer_lifetime_value,
c.first_order_date as fdos
from paid_orders p
left join customer_orders as c
using (customer_id)
left join x
on x.order_id = p.order_id
order by order_id
)
-- Simple Select Statment
select * from final
4. ドキュメントとリネージの確認
次のようなドキュメントやリネージを作成できるようになります。
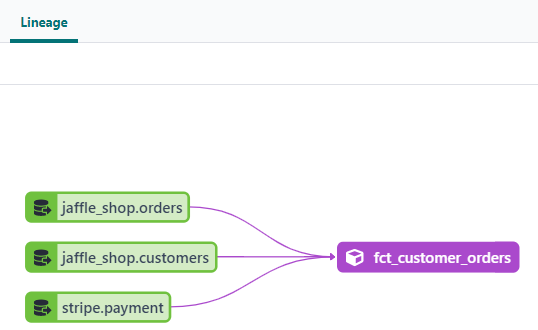
データに対するテストの実施例
dbtでは、テストの設定に応じて、SQLに変換してデータのテストを実行します。一般的な制約(ユニークキー制約、NOT NULL制約、ドメイン制約、外部キー制約)やデータ鮮度を実施するにはYAMLファイル内でテーブルのカラムごとに設定を行い、その他のデータチェックを行いたい場合にはSQLで記述します。下記のSQLによるテストの例では、order_idごとの集計値が負の値にならないことを確認しております。
一般的な制約(ユニークキー制約、NOT NULL制約、ドメイン制約、外部キー制約)の例
version: 2
models:
- name: orders
columns:
- name: order_id
tests:
- unique
- not_null
- name: status
tests:
- accepted_values:
values: ['placed', 'shipped', 'completed', 'returned']
- name: customer_id
tests:
- relationships:
to: ref('customers')
field: id
引用元:Best practices | dbt Docs (getdbt.com)
データ鮮度の例
version: 2
sources:
- name: jaffle_shop
database: raw
freshness: # default freshness
warn_after: {count: 12, period: hour}
error_after: {count: 24, period: hour}
引用元:freshness | dbt Docs (getdbt.com)
SQLによるテストの例
-- Refunds have a negative amount, so the total amount should always be >= 0.
-- Therefore return records where this isn't true to make the test fail
select
order_id,
sum(amount) as total_amount
from {{ ref('fct_payments' )}}
group by 1
having not(total_amount >= 0)
引用元:Tests | dbt Docs (getdbt.com)
以上がdbtに対する少し深い説明です。