注意事項
調査中ですが、意見を募集したいため記事を投稿します。
記事内容を更新する可能性があります。
概要
Databricksにて外部Hive Metastoreを構築する方法の検証を整理します。
下記の表が外部Hive Metastoreを構築する方法の概要、それぞれの検証結果の詳細を後述します。
| # | 方法 | 実施可否 | 問題・課題 |
|---|---|---|---|
| 1 | Databricksのドキュメント通りにSpark Configにより構築する方法 | 〇 | spark.conf.getにより接続情報を取得できてしまうこと。 |
| 2 | セッションスコープでSpark Configを変更 | × | 設定を変更できないこと。 |
| 3 | Hive Metastoreへの接続情報ファイル(hive-site.xml)を置き換える方法 | × | ファイル置き換え前のデータベースに接続してしまうこと。 |
| 4 | Hive Metastoreへの接続情報ファイルに対する参照パスの環境変数(CONF_HIVE_CONF_DIR)を置き換える方法 | × | 外部メタストアデータベースへ接続できず、データベースを作成しても永続化されないこと。 |
Databricksではデフォルトで内部のHive Metastoreデータベースを参照する仕様であり、Azure Databricksではリージョンごとに共通のAzure Database for Mysqlを利用するようになっているようです。Hive Metastoreデータベースへの接続情報の取得方法としては下記のドキュメントで紹介されております。
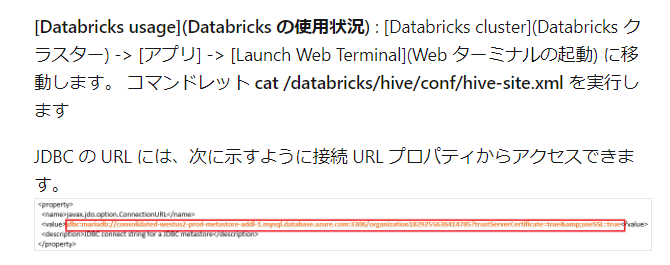
引用元:Azure Purview で Hive メタストア データベースを登録してスキャンを設定する - Azure Purview | Microsoft Docs
参考になる情報としてDatabricksのドキュメントがありますが、AWS版DatabricksとAzure Databricksでは記載内容が異なり、どちらも参考になります。
- 外部Apache Hiveメタストア - Azure Databricks - Workspace | Microsoft Docs
- External Apache Hive metastore | Databricks on AWS
SparkにおけるHive Metastoreの動作を概要を利用するには、GMOインターネットグループ様のブログ記事がとても参考になります。
1. Databricksのドキュメント通りにSpark Configにより構築する方法
構築方法
下記の記事に記載しております。
- Databricksにおける外部Hive MetastoreをMySQL(Azure Database for MySQL)にてローカルモードでSpark Configにて構築する方法 - Qiita
- Databricksにおける外部Hive MetastoreをAzure SQL DatabaseにてローカルモードでSpark Configにて構築する方法 - Qiita
課題
課題1-1. spark.conf.getにより接続情報を取得できてしまうこと
Databricksシークレットに格納することで値を表示しないようにできてしまうが、jdbc経由でHive Metastoreデータベースに接続できてしまうという課題がある。

2. セッションスコープでSpark Configを変更
構築方法
Spark Cofigをセッション中に変更
spark.conf.set("spark.hadoop.javax.jdo.option.ConnectionDriverName", "<driver>")
spark.conf.set("spark.hadoop.javax.jdo.option.ConnectionURL","<url>")
spark.conf.set("spark.hadoop.javax.jdo.option.ConnectionUserName","<usernaem>)
spark.conf.set("spark.hadoop.javax.jdo.option.ConnectionPassword","<password>")
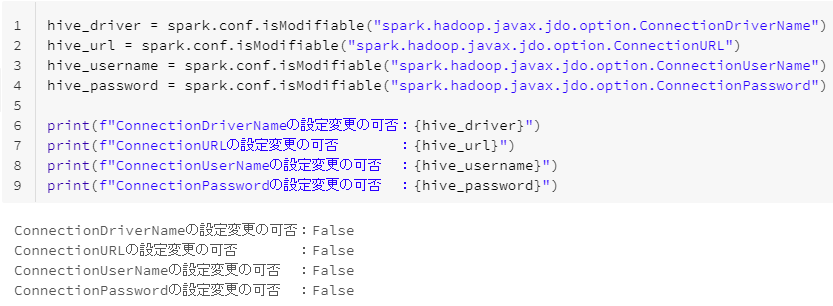
課題2-1. Spark Configの設定を変更できないこと。
spark.conf.isModifiableにより変更可否を確認できるが、いずれの設定もFalseである。
hive_driver = spark.conf.isModifiable("spark.hadoop.javax.jdo.option.ConnectionDriverName")
hive_url = spark.conf.isModifiable("spark.hadoop.javax.jdo.option.ConnectionURL")
hive_username = spark.conf.isModifiable("spark.hadoop.javax.jdo.option.ConnectionUserName")
hive_password = spark.conf.isModifiable("spark.hadoop.javax.jdo.option.ConnectionPassword")
print(f"ConnectionDriverNameの設定変更の可否:{hive_driver}")
print(f"ConnectionURLの設定変更の可否 :{hive_url}")
print(f"ConnectionUserNameの設定変更の可否 :{hive_username}")
print(f"ConnectionPasswordの設定変更の可否 :{hive_password}")
参考情報
3. Hive Metastoreへの接続情報ファイル(hive-site.xml)を置き換える方法
構築方法
下記のコードを実行してhive-site.xmlを置き換えます。
contents = """
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:sqlserver://{databaseへの接続情報}</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.microsoft.sqlserver.jdbc.SQLServerDriver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>{ユーザー}</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>{パスワード}</value>
<description>Password to use against metastore database</description>
</property>
<!-- If the following two properties are not set correctly, the metastore will
attempt to initialize its schema upon startup
-->
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>false</value>
</property>
<property>
<name>datanucleus.autoCreateSchema</name>
<value>false</value>
</property>
<property>
<name>datanucleus.fixedDatastore</name>
<value>true</value>
</property>
<property>
<name>datanucleus.connectionPool.minPoolSize</name>
<value>0</value>
</property>
<property>
<name>datanucleus.connectionPool.initialPoolSize</name>
<value>0</value>
</property>
<property>
<name>datanucleus.connectionPool.maxPoolSize</name>
<value>1</value>
</property>
<property>
<name>hive.stats.autogather</name>
<value>false</value>
</property>
<property>
<name>mapred.reduce.tasks</name>
<value>100</value>
</property>
<!-- To mitigate the problem of PROD-4498 and per HIVE-7140, we need to bump the timeout.
Since the default value of this property used by Impala is 3600 seconds, we will use this value for
actual deployment
(http://www.cloudera.com/content/cloudera/en/documentation/core/latest/topics/cm_props_cdh530_impala.html).
-->
<property>
<name>hive.metastore.client.socket.timeout</name>
<value>3600</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/local_disk0/tmp</value>
</property>
<property>
<name>hive.metastore.client.connect.retry.delay</name>
<value>10</value>
</property>
<property>
<name>hive.metastore.failure.retries</name>
<value>30</value>
</property>
</configuration>
"""
dbutils.fs.put(
file = "file:/databricks/hive/conf/hive-site.xml",
contents = contents,
overwrite = True,
)
課題
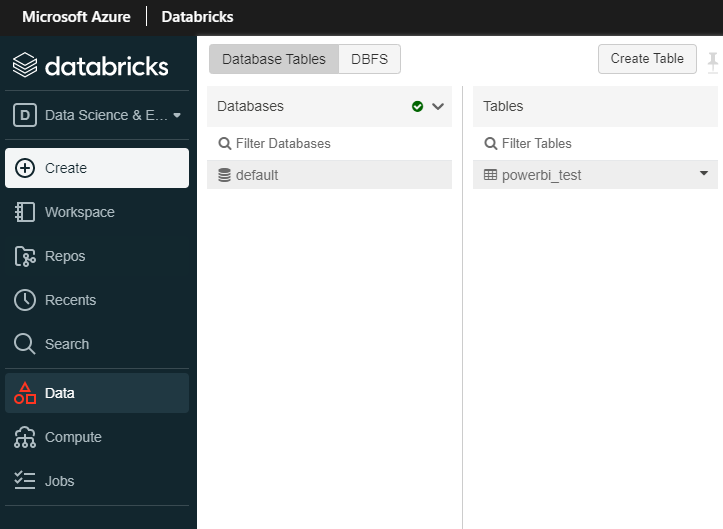
課題3-1. ファイル置き換え前のデータベースに接続してしまうこと
ファイルを置き換えてもデータベースは切り替わらず、クラスターを再起動するとhive-site.xmlが初期化されてしまいます。
hive-site.xml置き換え前のデータベース
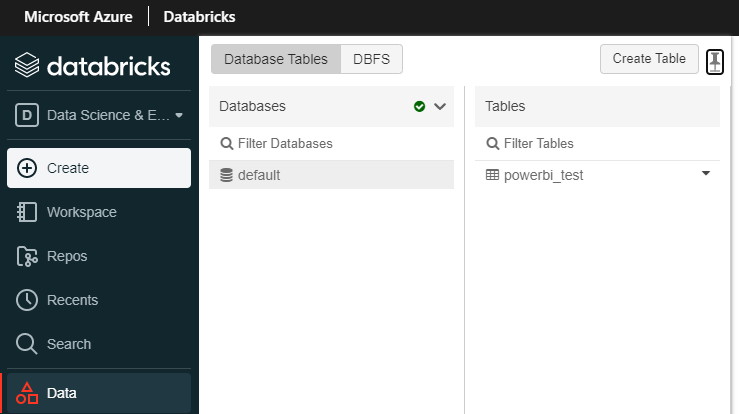
hive-site.xml置き換え後のデータベース
4. Hive Metastoreへの接続情報ファイルに対する参照パスの環境変数(CONF_HIVE_CONF_DIR)を置き換える方法
構築方法
下記のコードにより、dbfs上にhive-site.xmlを配置します。。
contents = """
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:sqlserver://{databaseへの接続情報}</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.microsoft.sqlserver.jdbc.SQLServerDriver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>{ユーザーID}</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>{パスワード}</value>
<description>Password to use against metastore database</description>
</property>
<!-- If the following two properties are not set correctly, the metastore will
attempt to initialize its schema upon startup
-->
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>false</value>
</property>
<property>
<name>datanucleus.autoCreateSchema</name>
<value>false</value>
</property>
<property>
<name>datanucleus.fixedDatastore</name>
<value>true</value>
</property>
<property>
<name>datanucleus.connectionPool.minPoolSize</name>
<value>0</value>
</property>
<property>
<name>datanucleus.connectionPool.initialPoolSize</name>
<value>0</value>
</property>
<property>
<name>datanucleus.connectionPool.maxPoolSize</name>
<value>1</value>
</property>
<property>
<name>hive.stats.autogather</name>
<value>false</value>
</property>
<property>
<name>mapred.reduce.tasks</name>
<value>100</value>
</property>
<!-- To mitigate the problem of PROD-4498 and per HIVE-7140, we need to bump the timeout.
Since the default value of this property used by Impala is 3600 seconds, we will use this value for
actual deployment
(http://www.cloudera.com/content/cloudera/en/documentation/core/latest/topics/cm_props_cdh530_impala.html).
-->
<property>
<name>hive.metastore.client.socket.timeout</name>
<value>3600</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/local_disk0/tmp</value>
</property>
<property>
<name>hive.metastore.client.connect.retry.delay</name>
<value>10</value>
</property>
<property>
<name>hive.metastore.failure.retries</name>
<value>30</value>
</property>
</configuration>
"""
dbutils.fs.put(
file = "dbfs:/FileStore/hive/conf/hive-site.xml",
contents = contents,
overwrite = True,
)
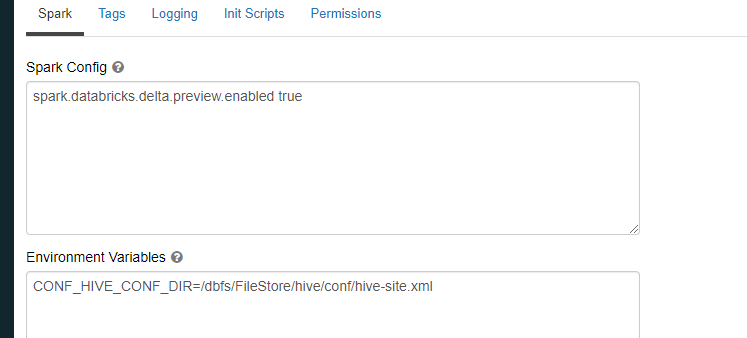
Environment Variablesにて下記の値を設定。
CONF_HIVE_CONF_DIR=/dbfs/FileStore/hive/conf/hive-site.xml
課題
課題4-1. 外部メタストアデータベースへ接続できず、データベースを作成しても永続化されないこと
データベース作成することは可能ですが、Hive Metastoreデータベースにもデータが書き込まれておりませんでした。
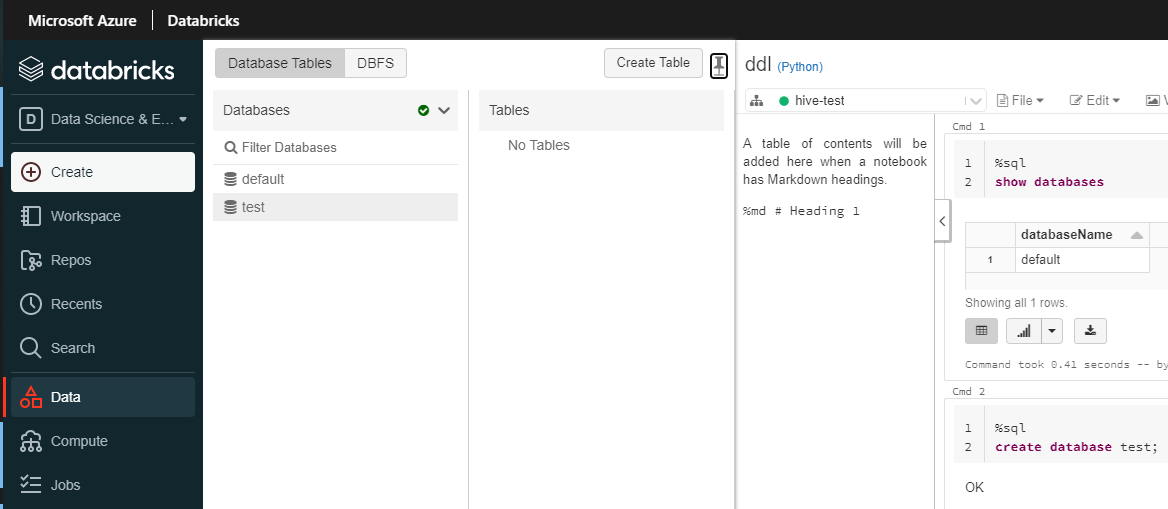
クラスターを再起動すると、データベースが初期化されてしまいます。