概要
Apache Iceberg 用の BigQuery テーブルについて、基本的な動作検証を行った結果を共有します。本記事では、BigQuery 上で Apache Iceberg 用テーブルを操作する方法と、Google Colab(Spark)でデータを参照する方法を紹介します。
BigQuery では、以下の 3 種類の Apache Iceberg テーブルを作成できます。本記事の対象は Apache Iceberg 用の BigQuery テーブルです。
- Apache Iceberg 用の BigLake 外部テーブル(BigLake Iceberg テーブル)
- BigQuery Metastore Iceberg テーブル
- Apache Iceberg 用の BigQuery テーブル(Iceberg マネージド テーブル / BigQuery Iceberg テーブル)
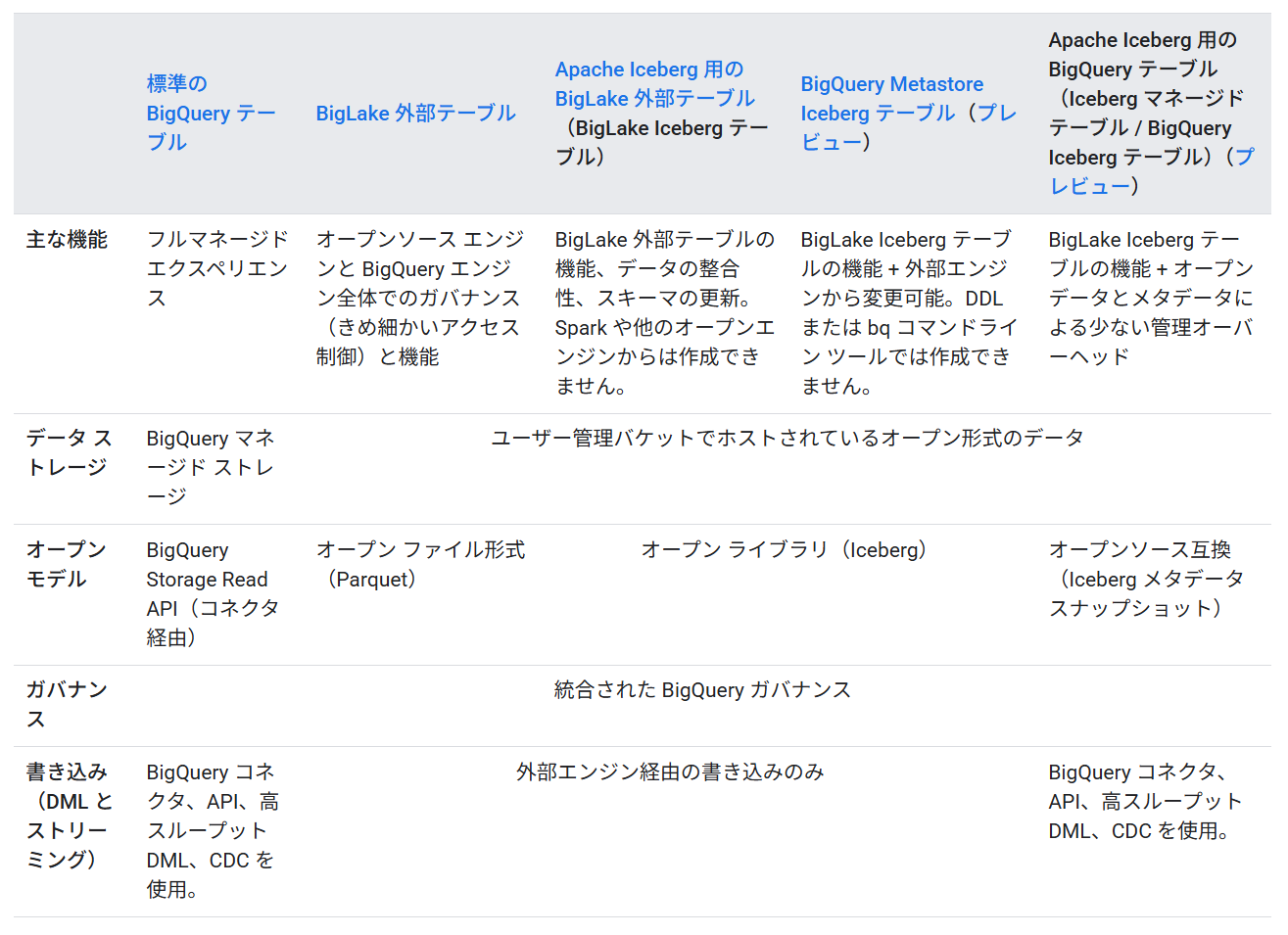
出所:Apache Iceberg 用の BigQuery テーブル | Google Cloud
Apache Iceberg 用の BigQuery テーブルでは、metadata layer のオブジェクトが作成されません。そのため、外部サービスから接続する場合は EXPORT TABLE METADATA SQL ステートメントを実行して、Apache Iceberg のメタデータファイルを出力する必要があります。

Apache Iceberg 用の BigLake 外部テーブルの操作手順については、以下の記事で紹介しています。
また、Google Colab 上の Spark で Apache Iceberg テーブルを扱う方法は、以下の記事で解説しています。本記事では、あらかじめこの記事の設定が実施済みであることを前提としています。
手順
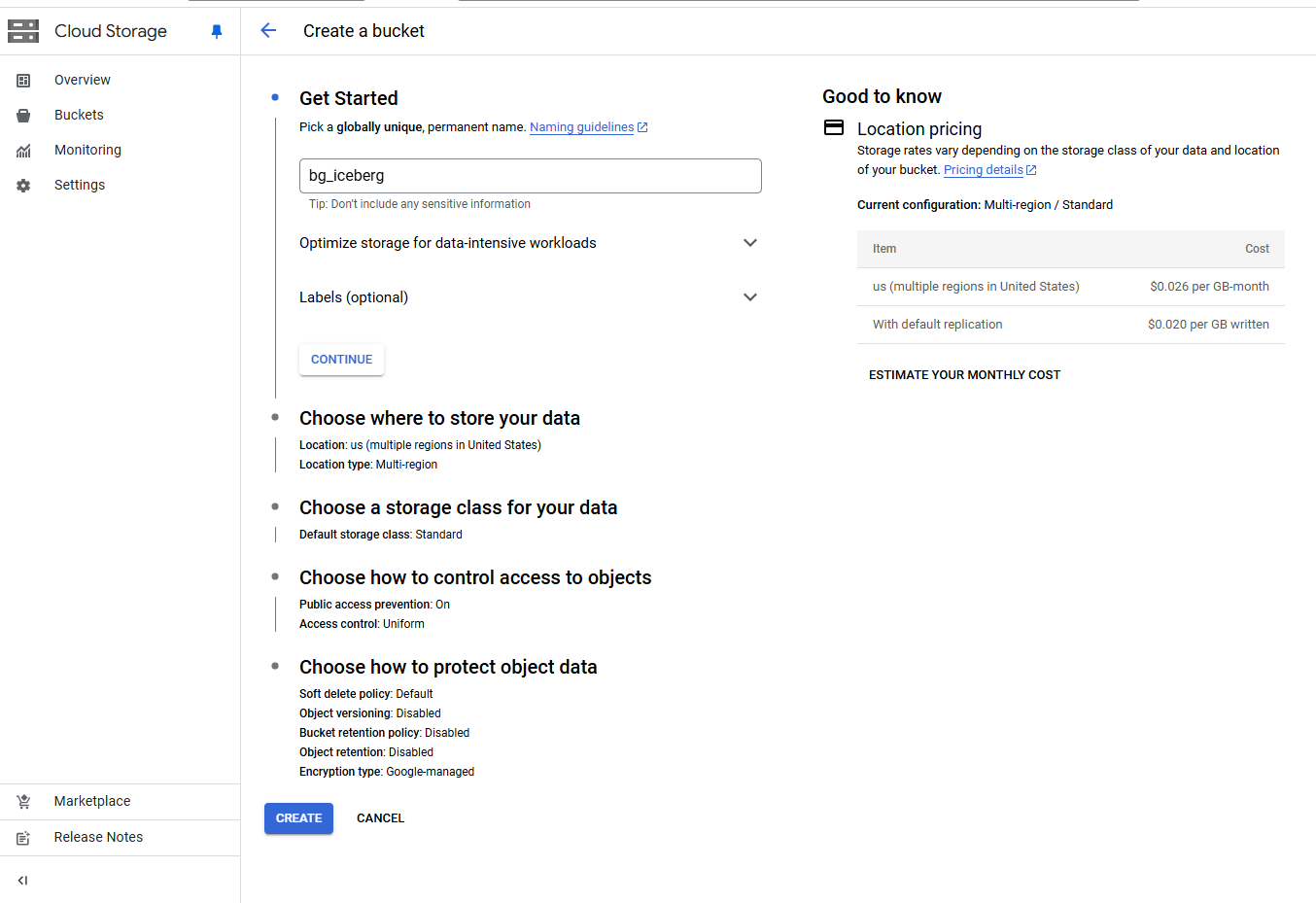
GCS のバケットを作成
BigQuery にて GCS に対する接続を作成
Google Cloud コンソールの BigQuery 画面で + Add をクリックします。
Connections to external data sources を選択します。
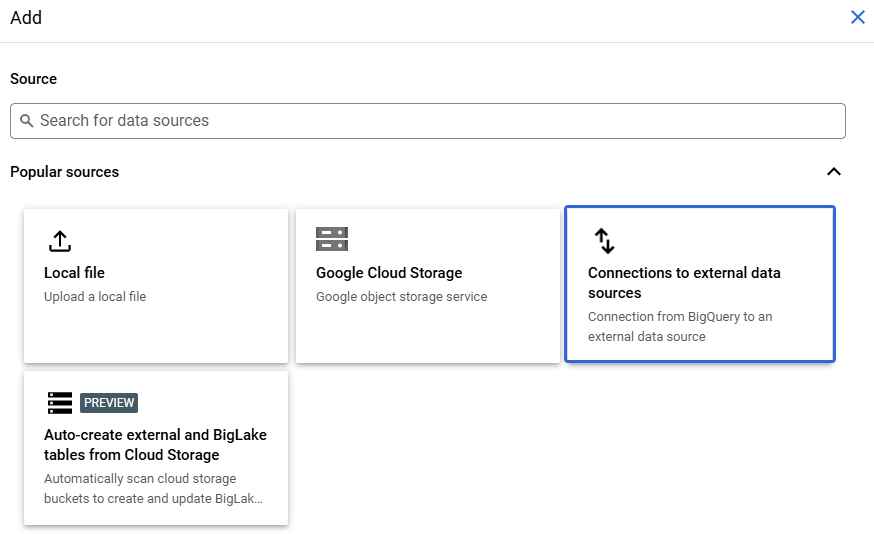
Connection type に Vertex AI remote models, remote functions and BigLake (Cloud Resource) を指定し、Connection ID に任意の名称を設定します。
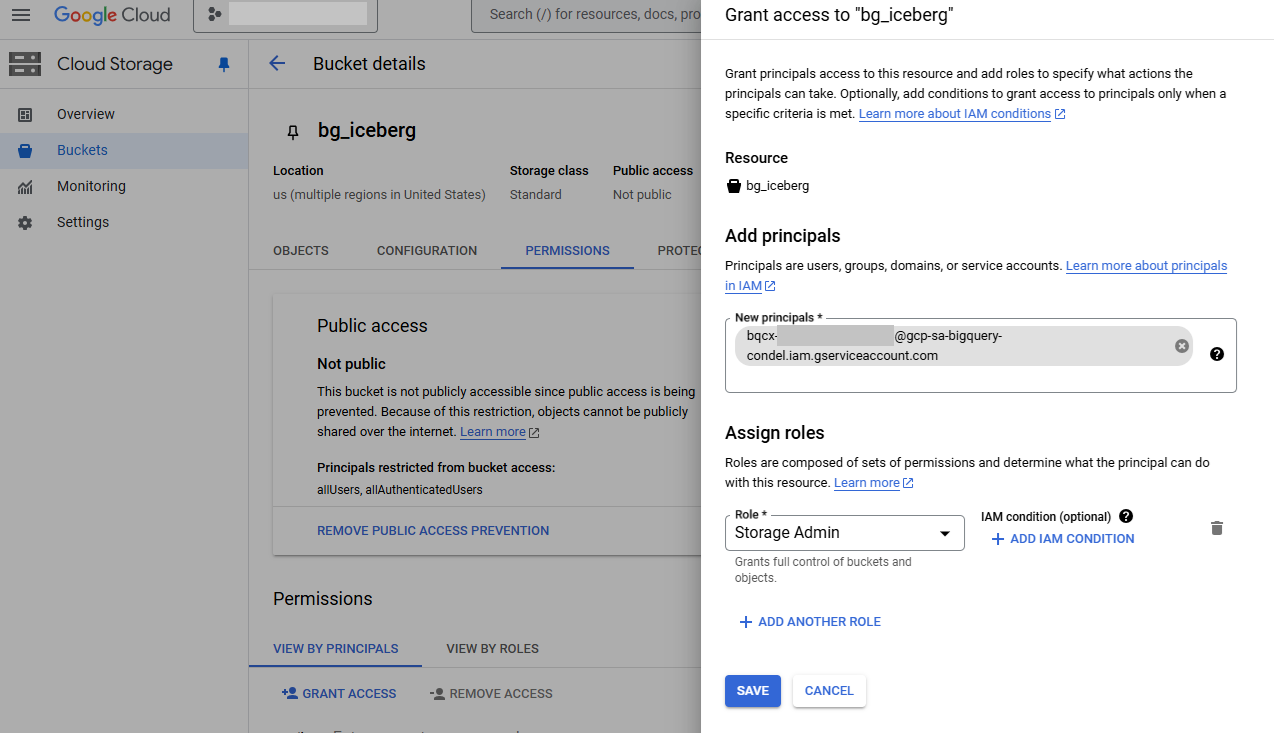
作成した接続の Service account id を確認します。

続いて、GCS バケットの IAM 設定で、上記 Service account id に必要な権限(Storage Admin)を付与します。
BigQuery 上で Apache Iceberg 用の BigQuery テーブルを作成
次に、BigQuery で下記の SQL を実行し、Apache Iceberg 用の BigQuery テーブルを作成します。{connection_id} には先ほど作成した接続の ID を指定してください。
CREATE OR REPLACE TABLE qiita.fist_table (
id INT,
name STRING,
status STRING
)
WITH CONNECTION `{connection_id}`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://bg_iceberg/qiita/fist_table'
);
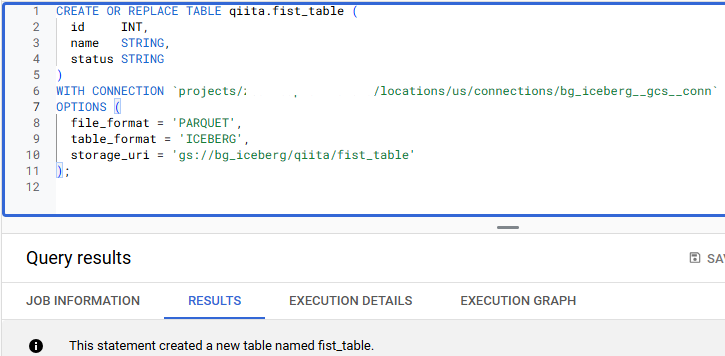
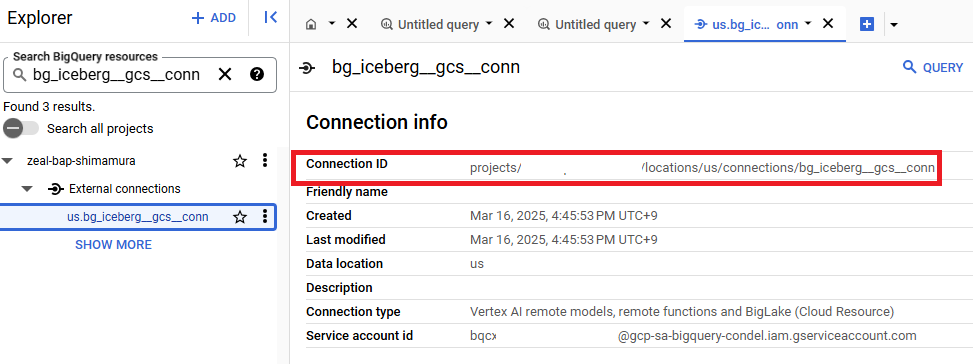
BigQuery Studio 上で接続を表示したときの詳細画面にて、Connection ID を確認できます。
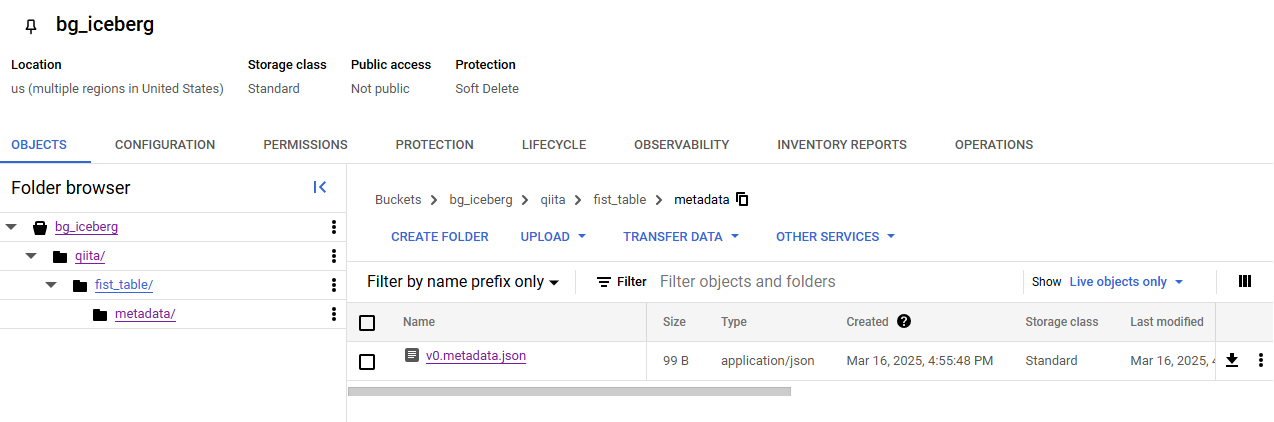
テーブル作成後、GCS のバケットを確認すると v0.metadata.json というファイルが生成されています。ただし、これは通常の Apache Iceberg メタデータファイルとは異なるようです。

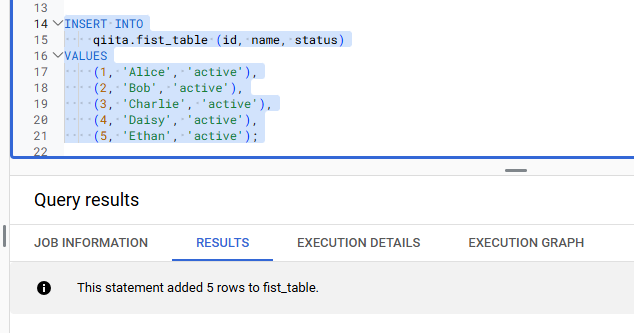
データの挿入確認
次に、下記の SQL でテーブルにデータを挿入します。
INSERT INTO
qiita.fist_table (id, name, status)
VALUES
(1, 'Alice', 'active'),
(2, 'Bob', 'active'),
(3, 'Charlie', 'active'),
(4, 'Daisy', 'active'),
(5, 'Ethan', 'active');
クエリを実行すると、正常にデータを取得できます。
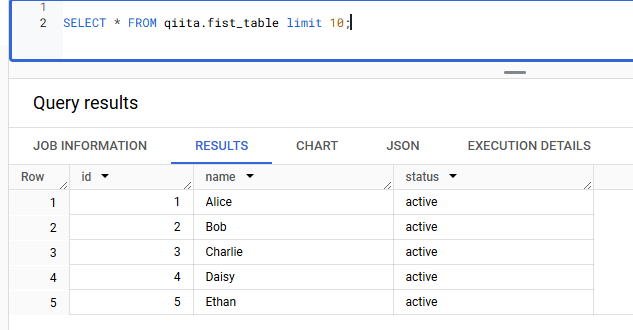
GCS のバケットを再度確認すると、data ディレクトリが作成され、その中に Parquet ファイルが生成されていることがわかります。

ただし、metadata ディレクトリにある v0.metadata.json の内容は変化していません。
Google Colab から Apache Iceberg 用の BigQuery テーブルを参照
まず、Spark のバージョンを確認します。
!pyspark --version
Google Drive をマウントします。
from google.colab import drive
drive.mount('/content/drive')
続いて、SparkSession を定義します。
gcs_iceberg_path = "gs://bg_iceberg/"
gcs_key_path = "/content/drive/MyDrive/Colab Notebooks/bigquery_iceberg/gcs_key.json"
from pyspark.sql import SparkSession
spark = (
SparkSession.builder
.appName("gcs_test")
.config("spark.jars", "https://storage.googleapis.com/hadoop-lib/gcs/gcs-connector-hadoop3-latest.jar")
.config('spark.jars.packages',
'org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.8.1,'
'org.apache.iceberg:iceberg-gcp-bundle:1.8.1')
.config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions')
.config('spark.sql.catalog.spark_catalog', 'org.apache.iceberg.spark.SparkCatalog')
.config("spark.sql.catalog.spark_catalog.type", "hadoop")
.config("spark.sql.catalog.spark_catalog.warehouse", gcs_iceberg_path)
.config("spark.hadoop.fs.gs.impl", "com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem")
.config("google.cloud.auth.service.account.enable", "true")
.config("spark.hadoop.google.cloud.auth.service.account.enable", "true")
.config("spark.hadoop.google.cloud.auth.service.account.json.keyfile", gcs_key_path)
.getOrCreate()
)
spark

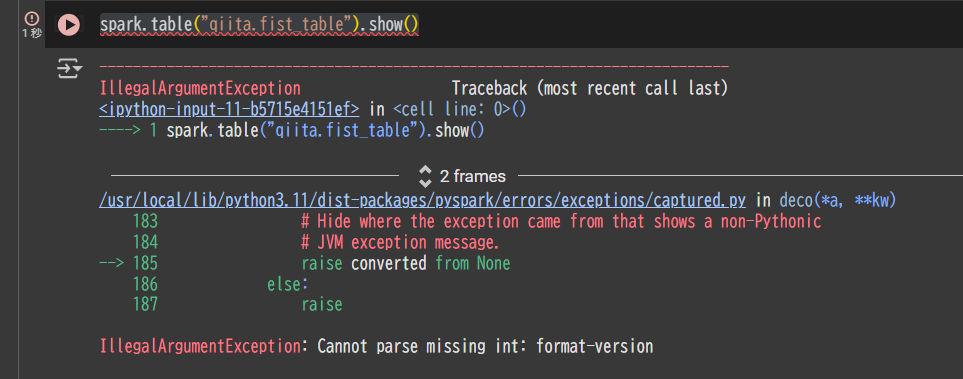
上記の設定が完了したうえでテーブルを参照すると、以下のエラーが発生します。これは、Apache Iceberg が必要とするメタデータファイル(metadata layer)が存在していないためです。
spark.table("qiita.fist_table").show()
IllegalArgumentException: Cannot parse missing int: format-version
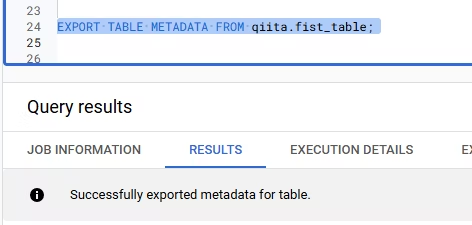
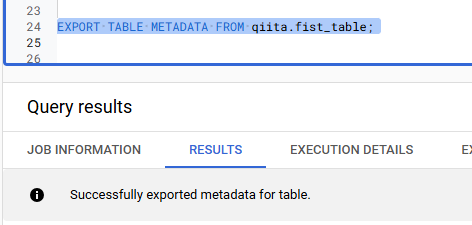
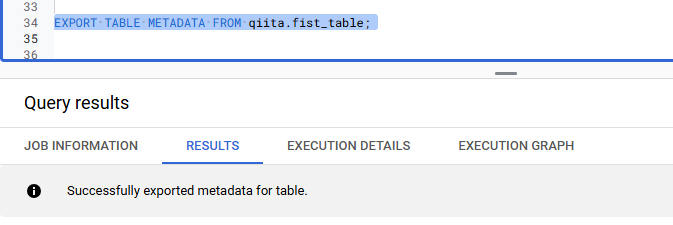
BigQuery Studio に戻り、以下の SQL でメタデータファイルを出力します。
EXPORT TABLE METADATA FROM qiita.fist_table;
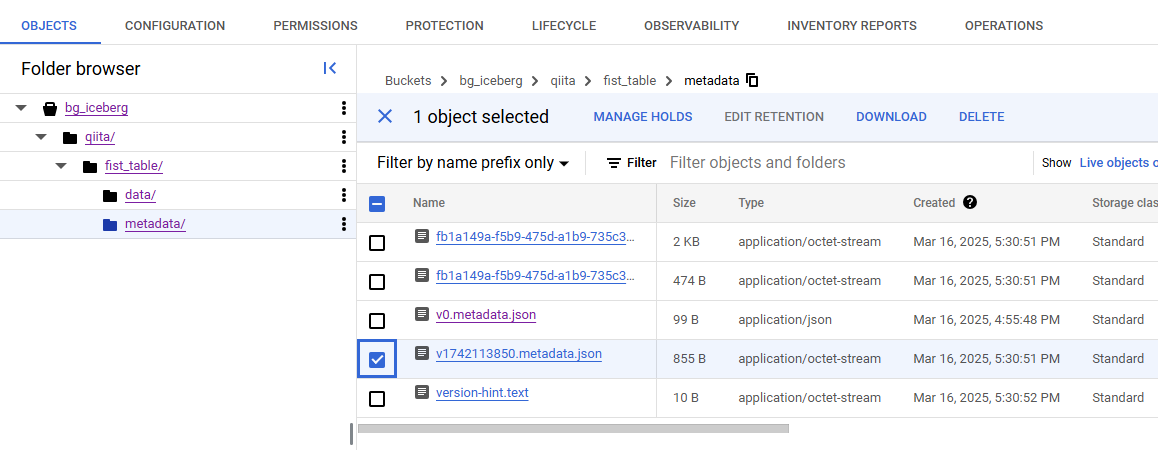
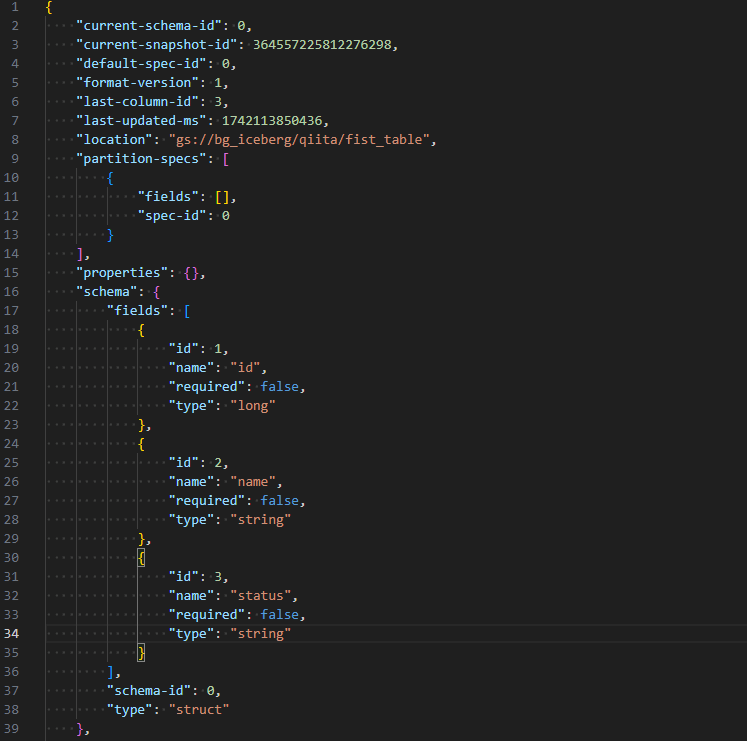
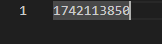
実行後、v1742113850.metadata.json と version-hint.text が生成されます。v1742113850.metadata.json には Apache Iceberg のメタデータが、version-hint.text には最新のメタデータファイル バージョンが記載されています。ここで表示される 1742113850 は、おそらく Unix Timestamp なので、実行時期によって値は異なります。
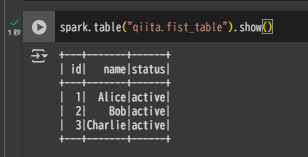
再度 Google Colab でテーブルのデータを取得すると、メタデータが生成されたため問題なく参照できます。
spark.table("qiita.fist_table").show()

Apache Iceberg 用の BigQuery テーブルに対する DELETE 実行と Google Colab での参照
BigQuery Studio で、以下の DELETE 文を実行します。
DELETE FROM
qiita.fist_table
WHERE
id > 3;
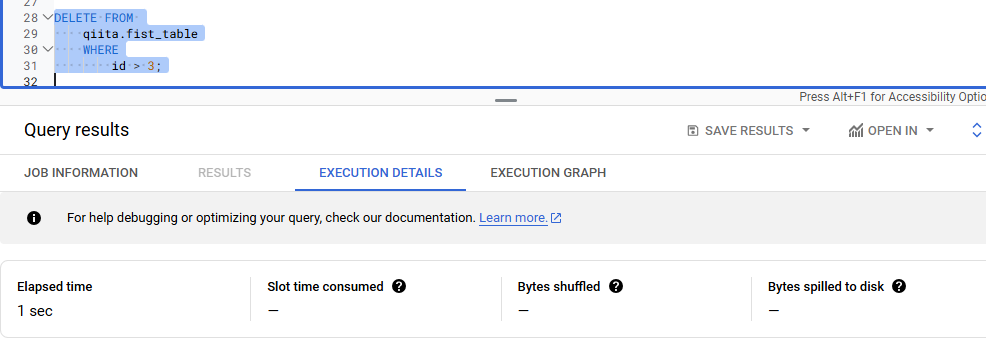
GCS のバケットを確認しても、ファイルに変化はありません。
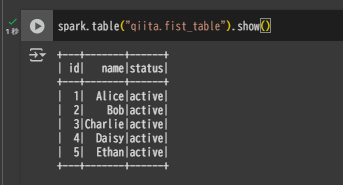
Google Colab からテーブルを参照してみると、まだ DELETE は反映されていません。
そこで、再度 BigQuery Studio に戻り、下記の SQL を実行して最新のメタデータを出力します。
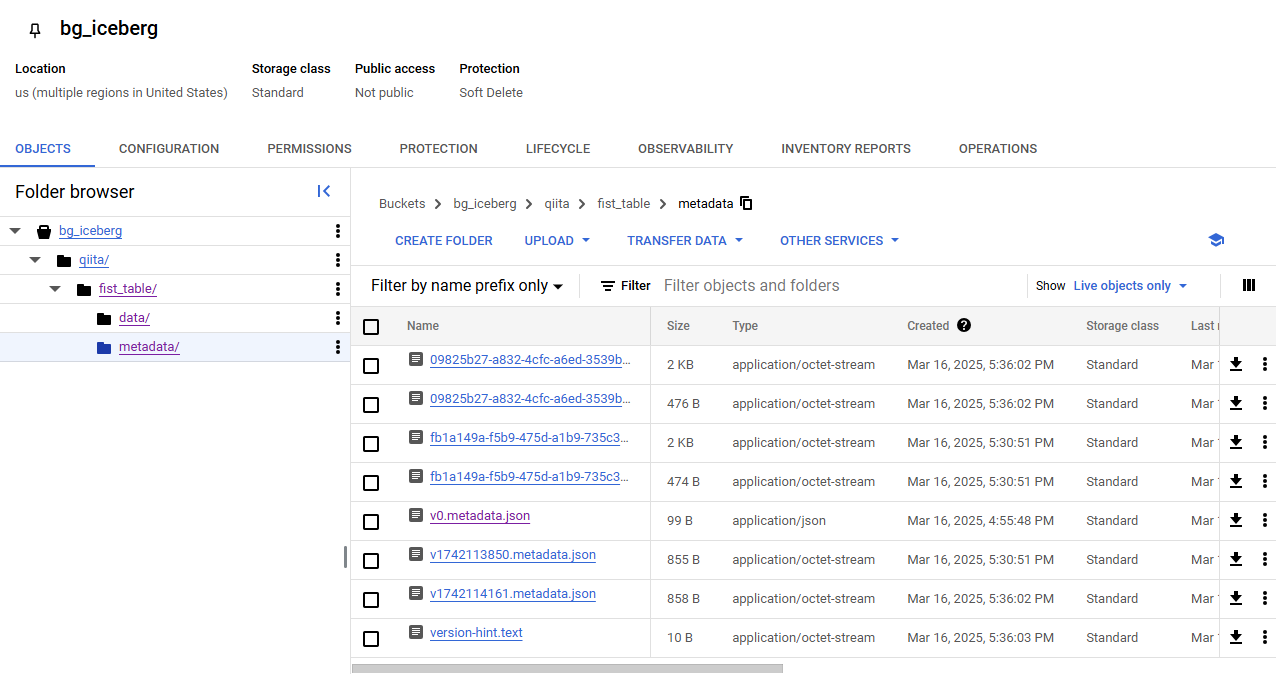
EXPORT TABLE METADATA FROM qiita.fist_table;
v1742114161.metadata.json という新しいファイルが生成されたことを確認できます。
この後、Google Colab から再びテーブルを参照すると、DELETE が反映された状態のデータを確認できます。
spark.table("qiita.fist_table").show()