概要
Databricks(Spark)にてDelta Lake形式とParquet形式における実行計画のデータサイズを比較したところ、Delta Lake形式では約1万分の1のサイズとなりました。Delta Lake形式の利用により、Parquet形式を利用よりも性能の向上が期待できます。
パーティション列を設定したParquet形式のデータセットとDelta Lake形式のデータセットに対してfilterを行う処理の実行計画を比較する検証を実施しました。本記事では、その手順と実行結果を記述します。
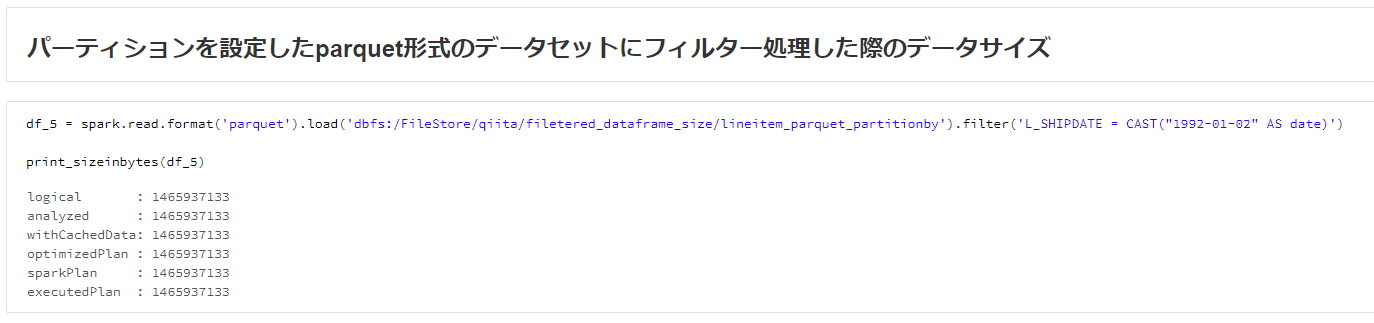
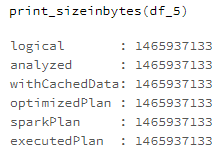
optimizedPlanの実行計画ステージ以降で、Parquet形式ではサイズが変わらないのに対して、Delta Lake形式ではサイズが縮小することが判明しました。
| データフォーマット | 実行計画のデータサイズ |
|---|---|
| Parquet形式 | 1,465,937,133 |
| Delta Lake形式 | 122,624 |
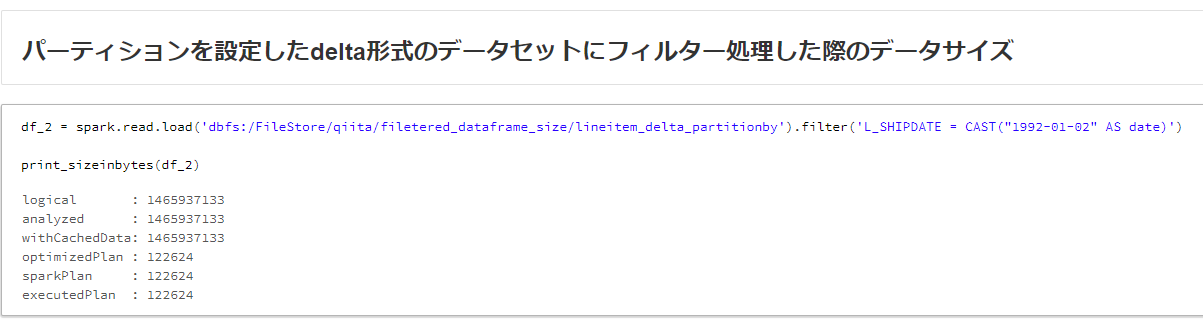
Delta Lake形式の実行計画のデータサイズ

Parquet形式の実行計画のデータサイズ
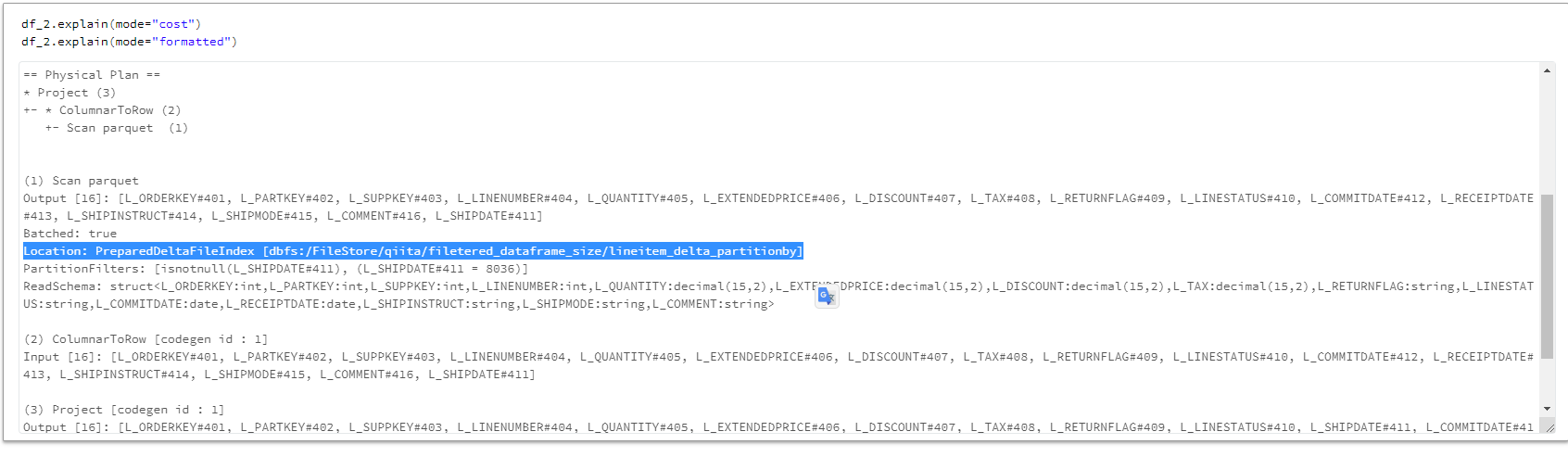
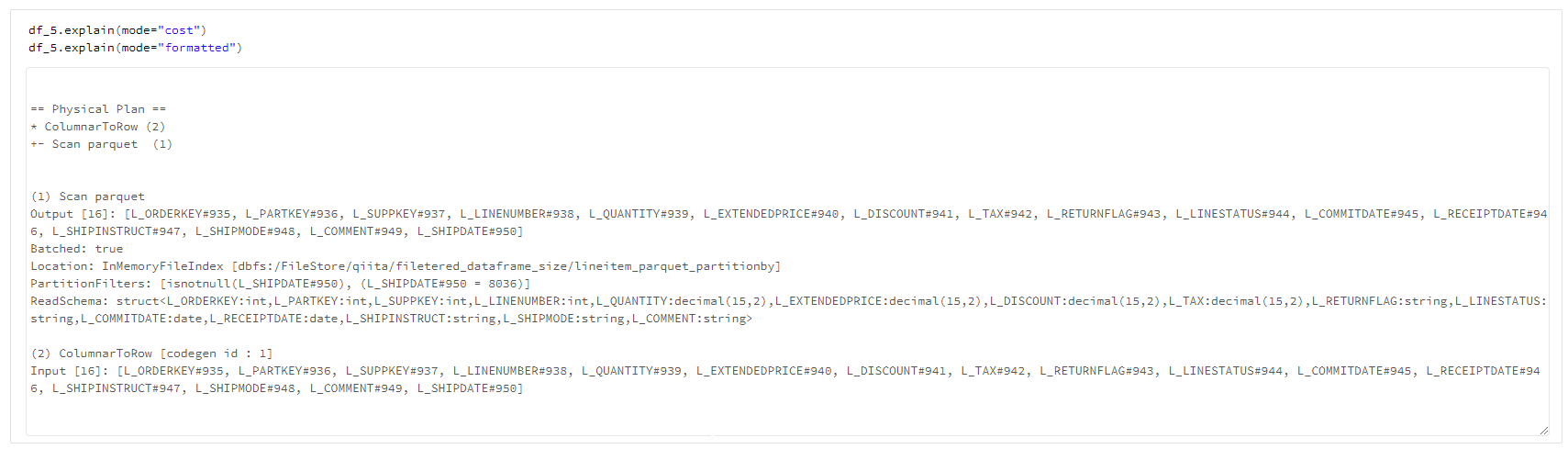
実行計画を比較すると、Delta Lake形式ではPreparedDeltaFileIndexが利用されるなど実行計画が異なりました。
Delta Lake形式の実行計画
Parquet形式の実行計画
詳細は下記のGithub pagesのページをご確認ください。
コードを実行したい方は、下記のdbcファイルを取り込んでください。
https://github.com/manabian-/databricks_tecks_for_qiita/blob/main/tecks/filtered_dataframe_size/dbc/filtered_dataframe_size.dbc
実行環境
databricks runtime: 9.0.x-scala2.12
Python version : 3.8.10
pyspark version : 3.1.2
検証手順
事前準備
filepath = "dbfs:/databricks-datasets/tpch/data-001/lineitem/"
schema = """
L_ORDERKEY INTEGER ,
L_PARTKEY INTEGER ,
L_SUPPKEY INTEGER ,
L_LINENUMBER INTEGER ,
L_QUANTITY DECIMAL(15,2) ,
L_EXTENDEDPRICE DECIMAL(15,2) ,
L_DISCOUNT DECIMAL(15,2) ,
L_TAX DECIMAL(15,2) ,
L_RETURNFLAG STRING ,
L_LINESTATUS STRING ,
L_SHIPDATE DATE ,
L_COMMITDATE DATE ,
L_RECEIPTDATE DATE ,
L_SHIPINSTRUCT STRING ,
L_SHIPMODE STRING ,
L_COMMENT STRING
"""
df = (spark
.read
.format("csv")
.schema(schema)
.option("sep", "|")
.load(filepath)
)
dbutils.fs.rm('dbfs:/FileStore/qiita/filtered_dataframe_size', True)
# パーティションを設定したdelta形式のデータセットを準備
df.write.mode('overwrite').format('delta').partitionBy('L_SHIPDATE').save('dbfs:/FileStore/qiita/filetered_dataframe_size/lineitem_delta_partitionby')
# パーティションを設定したparquet形式のデータセットを準備
df.write.mode('overwrite').format('parquet').partitionBy('L_SHIPDATE').save('dbfs:/FileStore/qiita/filetered_dataframe_size/lineitem_parquet_partitionby')
実行計画のステージごとのサイズを表示
# 関数を定義
def print_sizeinbytes(df):
"""複数の実行計画から取得できるデータのサイズを表示
"""
table_size = df._jdf.queryExecution().logical().stats().sizeInBytes()
print(f"logical : {table_size}")
table_size = df._jdf.queryExecution().analyzed().stats().sizeInBytes()
print(f"analyzed : {table_size}")
table_size = df._jdf.queryExecution().withCachedData().stats().sizeInBytes()
print(f"withCachedData: {table_size}")
table_size = df._jdf.queryExecution().optimizedPlan().stats().sizeInBytes()
print(f"optimizedPlan : {table_size}")
table_size = df._jdf.queryExecution().sparkPlan().stats().sizeInBytes()
print(f"sparkPlan : {table_size}")
table_size = df._jdf.queryExecution().executedPlan().stats().sizeInBytes()
print(f"executedPlan : {table_size}")
# パーティションを設定したdelta形式のデータセットにフィルター処理した際のデータサイズ
df_2 = spark.read.load('dbfs:/FileStore/qiita/filetered_dataframe_size/lineitem_delta_partitionby').filter('L_SHIPDATE = CAST("1992-01-02" AS date)')
print_sizeinbytes(df_2)
df_5 = spark.read.format('parquet').load('dbfs:/FileStore/qiita/filetered_dataframe_size/lineitem_parquet_partitionby').filter('L_SHIPDATE = CAST("1992-01-02" AS date)')
print_sizeinbytes(df_5)