概要
Databricks(Spark)にてDataFrameReaderのmode機能を用いたエラーレコードの抽出方法を共有します。
mode機能にて_corrupt_record列に基づいて、エラーレコードを出力します。
DataFrameReaderのmode機能については、下記の記事で紹介しております。
詳細は下記のGithub pagesのページをご確認ください。
コードを実行したい方は、下記のdbcファイルを取り込んでください。
実施手順
事前準備
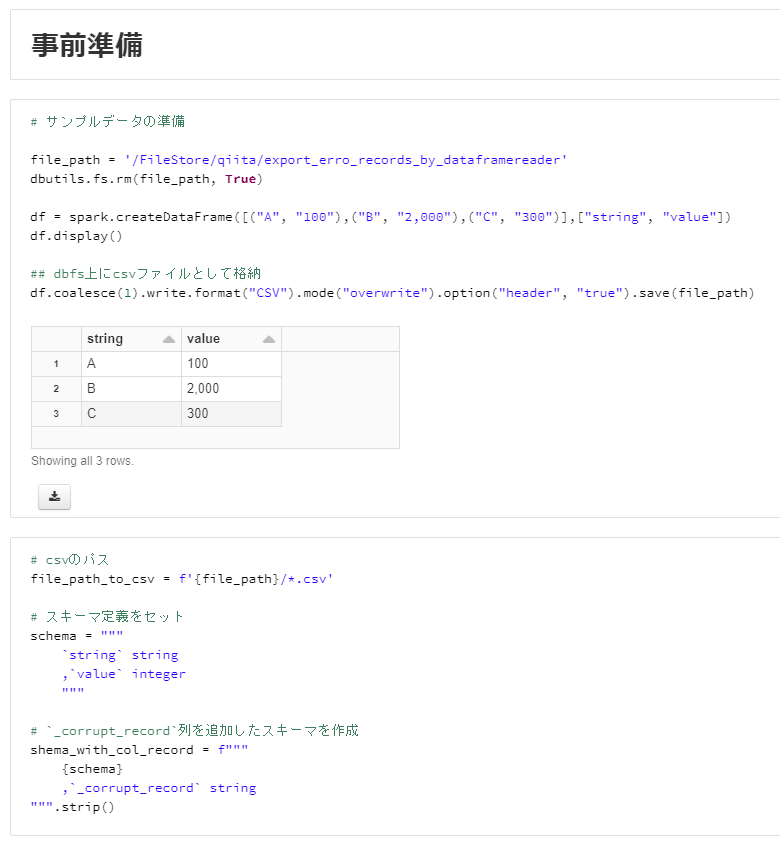
# サンプルデータの準備
file_path = '/FileStore/qiita/export_erro_records_by_dataframereader'
dbutils.fs.rm(file_path, True)
df = spark.createDataFrame([("A", "100"),("B", "2,000"),("C", "300")],["string", "value"])
df.display()
## dbfs上にcsvファイルとして格納
df.coalesce(1).write.format("CSV").mode("overwrite").option("header", "true").save(file_path)
# csvのパス
file_path_to_csv = f'{file_path}/*.csv'
# スキーマ定義をセット
schema = """
`string` string
,`value` integer
"""
# `_corrupt_record`列を追加したスキーマを作成
shema_with_col_record = f"""
{schema}
,`_corrupt_record` string
""".strip()
mode機能を用いたエラーレコードの抽出
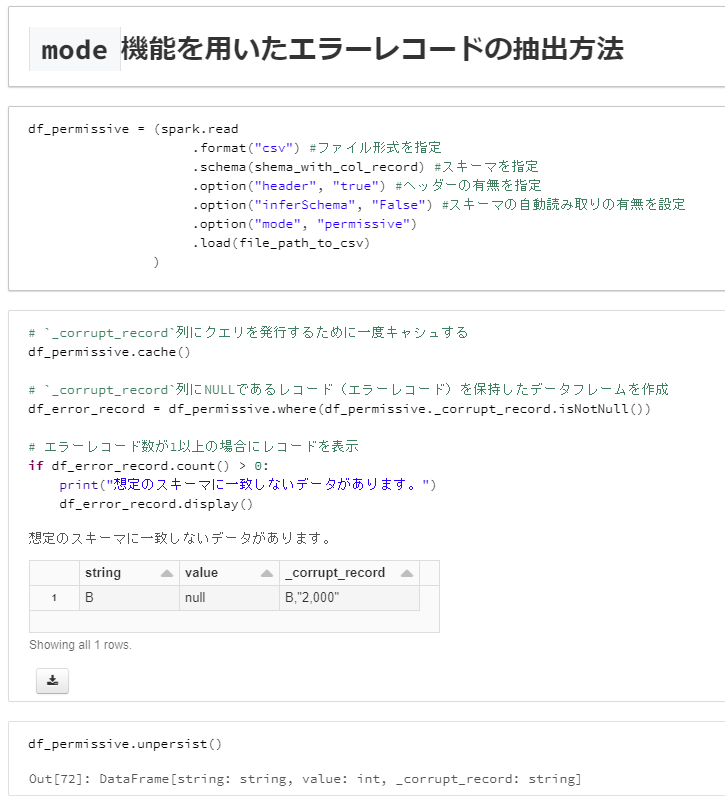
df_permissive = (spark.read
.format("csv") #ファイル形式を指定
.schema(shema_with_col_record) #スキーマを指定
.option("header", "true") #ヘッダーの有無を指定
.option("inferSchema", "False") #スキーマの自動読み取りの有無を設定
.option("mode", "permissive")
.load(file_path_to_csv)
)
# `_corrupt_record`列にクエリを発行するために一度キャシュする
df_permissive.cache()
# `_corrupt_record`列にNULLであるレコード(エラーレコード)を保持したデータフレームを作成
df_error_record = df_permissive.where(df_permissive._corrupt_record.isNotNull())
# エラーレコード数が1以上の場合にレコードを表示
if df_error_record.count() > 0:
print("想定のスキーマに一致しないデータがあります。")
df_error_record.display()
df_permissive.unpersist()

関連記事
ノートブックをGithub Pageによる共有方法
Databricks(Azure Databricks)でGithub経由でノートブックを共有する方法 - Qiita