概要
Databricks で Confluent Schema Registry を利用して from_avro 関数と from_protobuf 関数を用いた際に、Kafka 側でスキーマの進化(フィールド追加など)が行われたことを Databricks 側がどのように検知・処理するのかを調査しました。
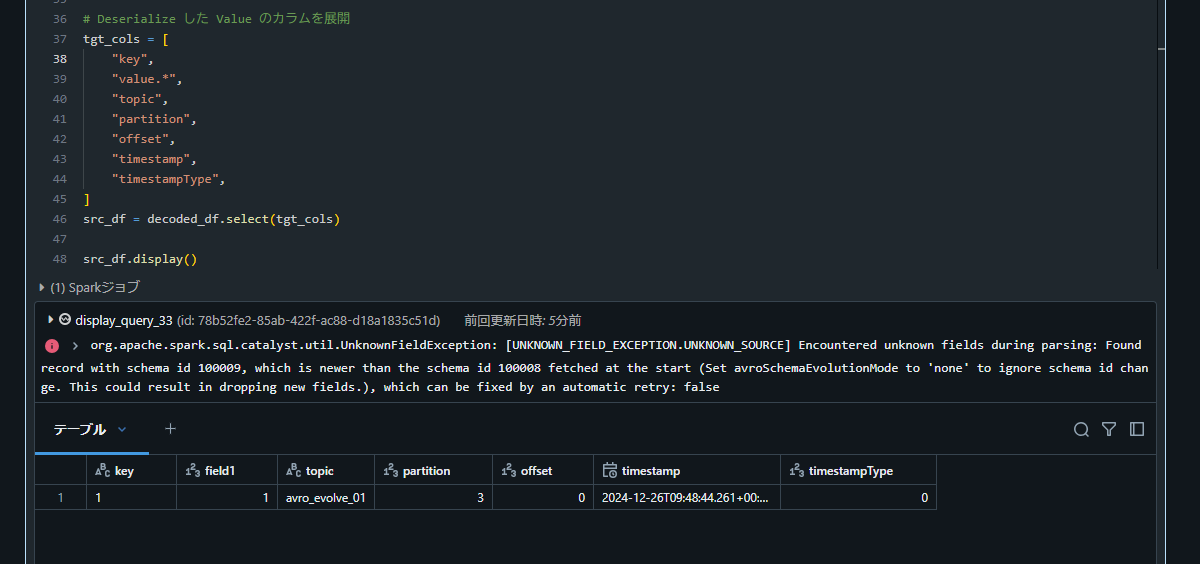
avroSchemaEvolutionModeオプション、あるいは、schema.registry.schema.evolution.modeオプションをrestartに設定した状態で新しいフィールドが追加されると、Databricks の処理が UnknownFieldException` エラーで停止してしまうことを確認しました。本記事では、その検証コードと結果をまとめます。
org.apache.spark.sql.catalyst.util.UnknownFieldException: [UNKNOWN_FIELD_EXCEPTION.UNKNOWN_SOURCE]
Encountered unknown fields during parsing: Found record with schema id 100009, which is newer than
the schema id 100008 fetched at the start (Set avroSchemaEvolutionMode to 'none' to ignore schema
id change. This could result in dropping new fields.), which can be fixed by an automatic retry: false
Kafka をソースにした場合におけるスキーマ展開について
Databricks のドキュメントによると、Kafka 側でスキーマが進化した場合、Avro だけでなく Protobuf でもスキーマ進化に対応するオプションが用意されています。ただし、Avro のデフォルト設定が none である一方、Protobuf のデフォルト設定は restart である点には留意が必要です。本仕様に基づき、ジョブの再起動時にエラーをリトライする仕組みを導入すれば、Kafka 側で新しいフィールドが追加された際にも、自動的に新しいカラムを認識・追加できるようになります。
Databricks Runtime 14.2 以降では from_avro でスキーマ進化モードを使用できます。 スキーマ進化モードを有効にすると、スキーマの進化を検出した後にジョブで UnknownFieldException がスローされます。

引用元:ストリーミング Avro データの読み取りと書き込み - Azure Databricks | Microsoft Learn
restart (既定値): 新しいスキーマ ID が認識されたときに UnknownFieldException をトリガーします。 これにより、クエリが終了します。 Databricks では、スキーマの変更を取得するために、クエリの失敗時に再開するようにジョブを構成することをお勧めします。
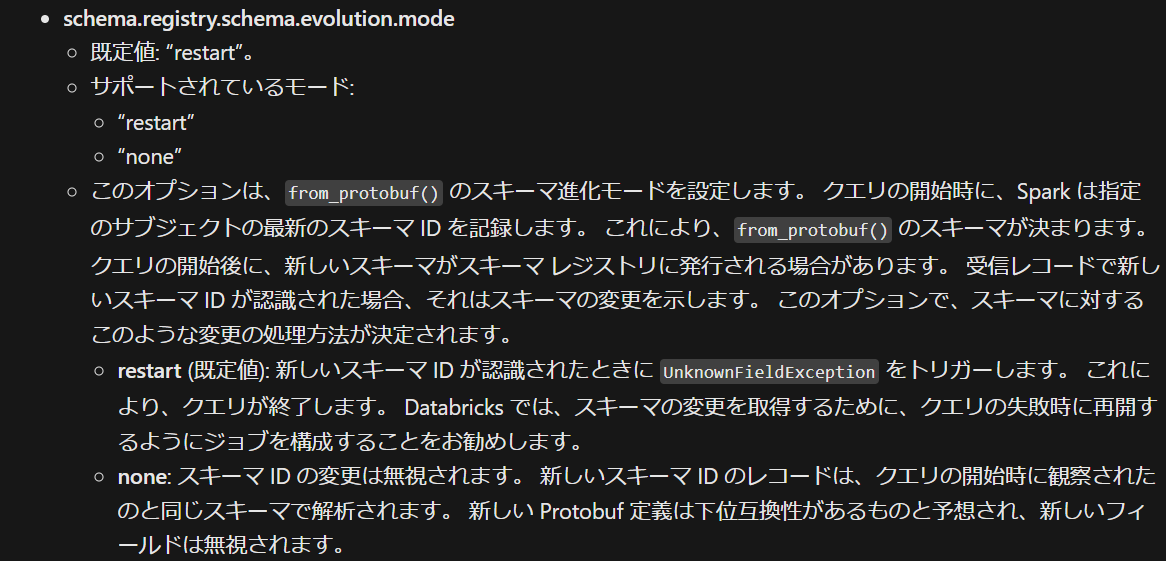
引用元:プロトコル バッファーの読み取りと書き込みを行う - Azure Databricks | Microsoft Learn
事前準備
1. Confluent で API キーを取得

2. Confluent で Schema Registry 用 API キーを取得

3. Databricks に認証情報をセット
# Confluent に対する認証情報をセット
bootstrap_servers = "pkc-92aaa.us-east-2.aws.confluent.cloud:9092"
sasl_username = "NYQNA56RYSHSEAAA"
sasl_password = "g0AwC7hwasWL49Vn5MdBWrZeaQBFpv3DH0QcTWj7Ovh/HE1R2dWUssi0VxBAAAAA"
sr_url = "https://psrc-l6aaa.us-east-2.aws.confluent.cloud"
sr_api_key = "RPHQKLYYQG3HIAAAA"
sr_api_secret = "qRglNE56KGYuTTm2Go1ByfyLxBF9ZALztrmItyxUAGjwIUTiEQwaqAFOaaAAAA"
Avro 形式の Topic におけるスキーマ進化の動作確認
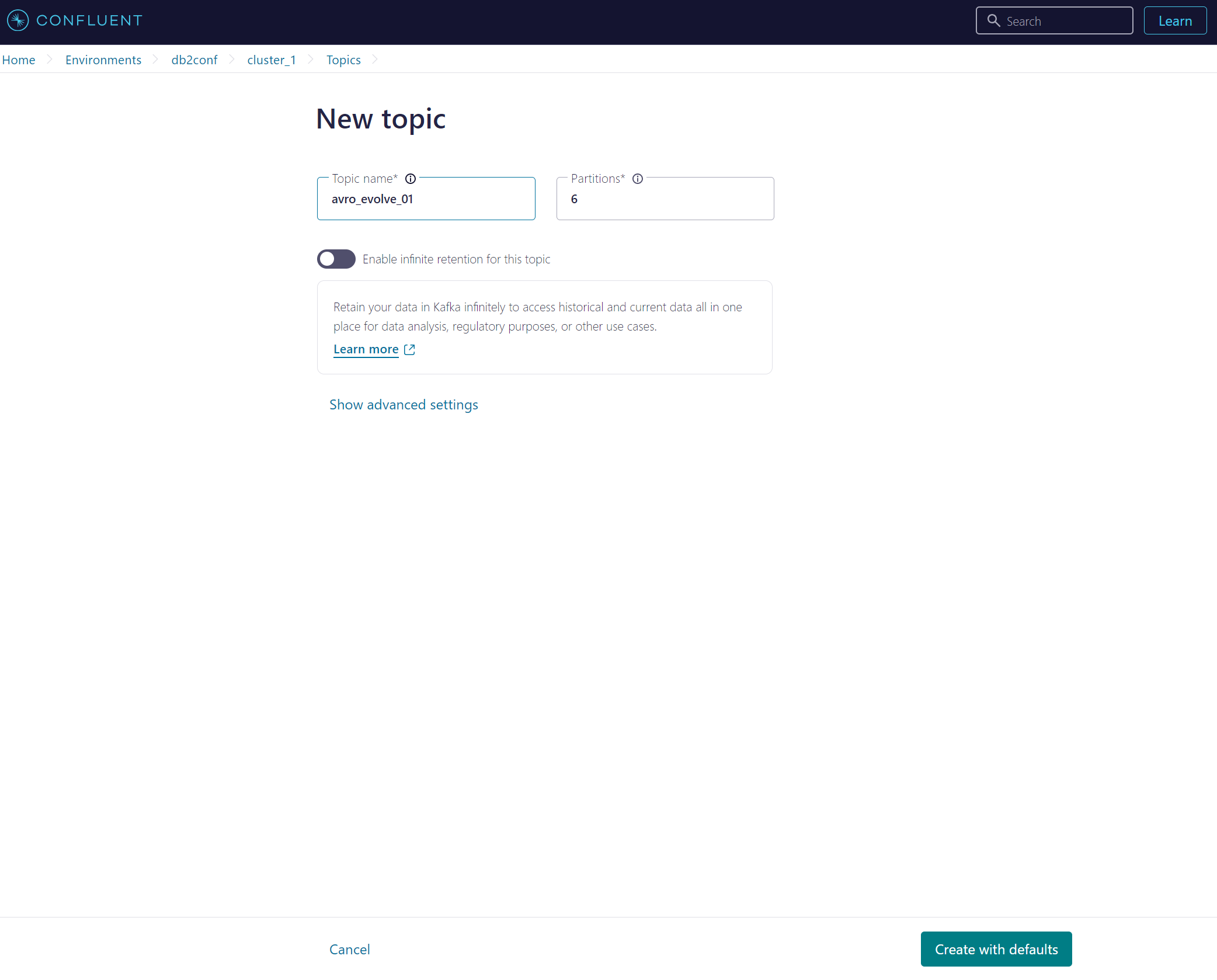
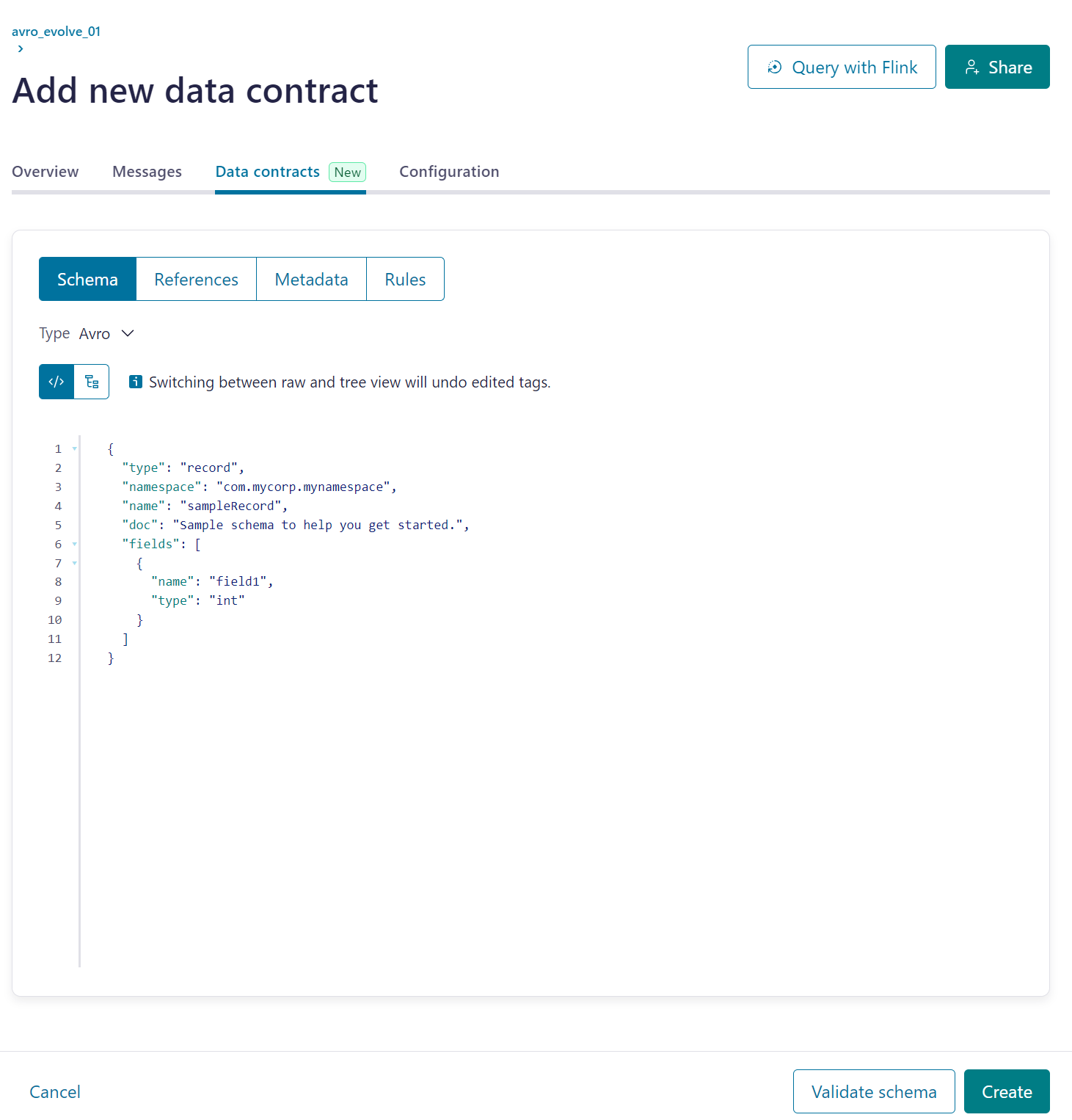
1. Confluent で Topic を作成
2. Confluent で Topic にスキーマを設定
{
"type": "record",
"namespace": "com.mycorp.mynamespace",
"name": "sampleRecord",
"doc": "Sample schema to help you get started.",
"fields": [
{
"name": "field1",
"type": "int"
}
]
}
3. データを追加
4. Schema Registry の接続情報を変数にセット(avroSchemaEvolutionModeをrestartに設定)
# Schema Registry の接続情報
schema_registry_options = {
"confluent.schema.registry.basic.auth.credentials.source": "USER_INFO",
"confluent.schema.registry.basic.auth.user.info": f"{sr_api_key}:{sr_api_secret}",
"avroSchemaEvolutionMode": "restart",
}
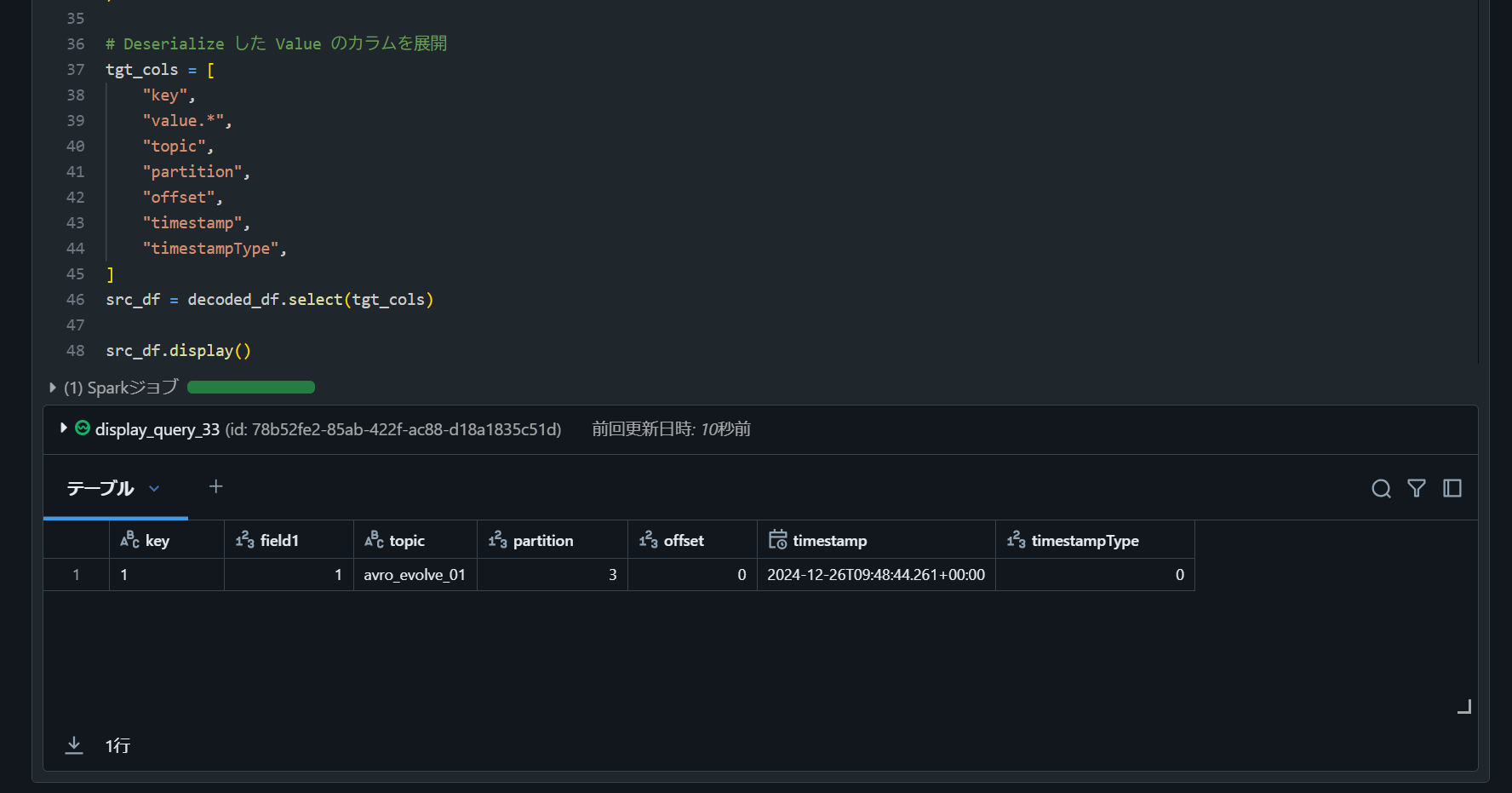
5. Databricks で Confluent からデータを取得
topic_name = "avro_evolve_01"
subject_name = topic_name + "-value"
from pyspark.sql.functions import col, expr
from pyspark.sql.avro.functions import from_avro
# Confluent から読み込み
df = (
spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", bootstrap_servers)
.option("kafka.security.protocol", "SASL_SSL")
.option(
"kafka.sasl.jaas.config",
f'kafkashaded.org.apache.kafka.common.security.plain.PlainLoginModule required username="{sasl_username}" password="{sasl_password}";',
)
.option("kafka.sasl.mechanism", "PLAIN")
.option("subscribe", topic_name)
.option("startingOffsets", "earliest")
.load()
)
# Key を Deserialize
key_des_df = df.withColumn(
"key",
col("Key").cast("string"),
)
# Magic Byte と Schema ID を取り除いた Value を Deserialize
decoded_df = key_des_df.withColumn(
"value",
from_avro(
col("value"),
options=schema_registry_options,
subject=subject_name,
schemaRegistryAddress=sr_url,
),
)
# Deserialize した Value のカラムを展開
tgt_cols = [
"key",
"value.*",
"topic",
"partition",
"offset",
"timestamp",
"timestampType",
]
src_df = decoded_df.select(tgt_cols)
src_df.display()
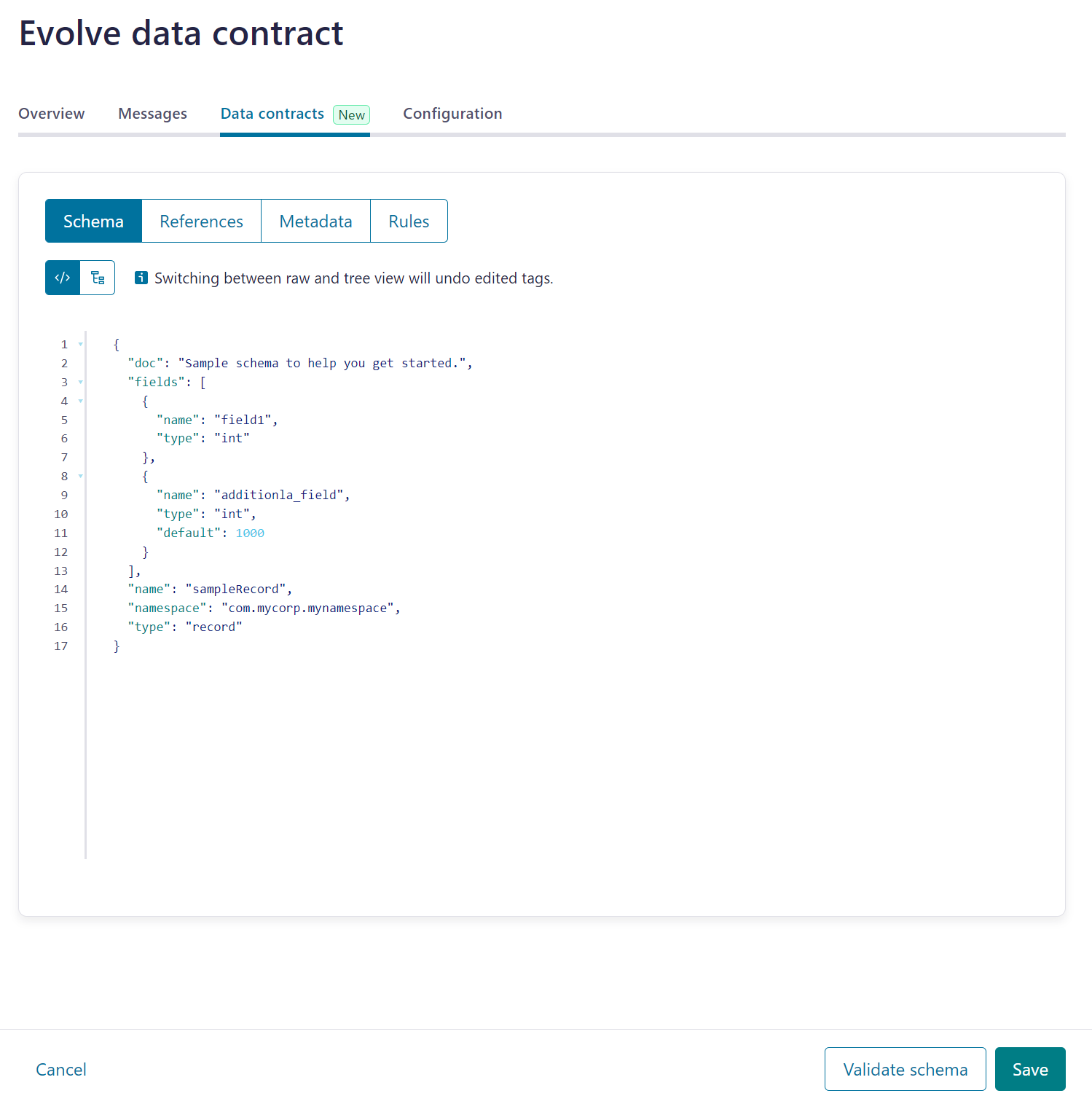
6. フィールドを追加
{
"doc": "Sample schema to help you get started.",
"fields": [
{
"name": "field1",
"type": "int"
- }
+ },
+ {
+ "name": "additional_field",
+ "type": "int",
+ "default": 1000
+ }
],
"name": "sampleRecord",
"namespace": "com.mycorp.mynamespace",
"type": "record"
}
7. フィールド追加のみでは Databricks 側がエラーとならないことを確認
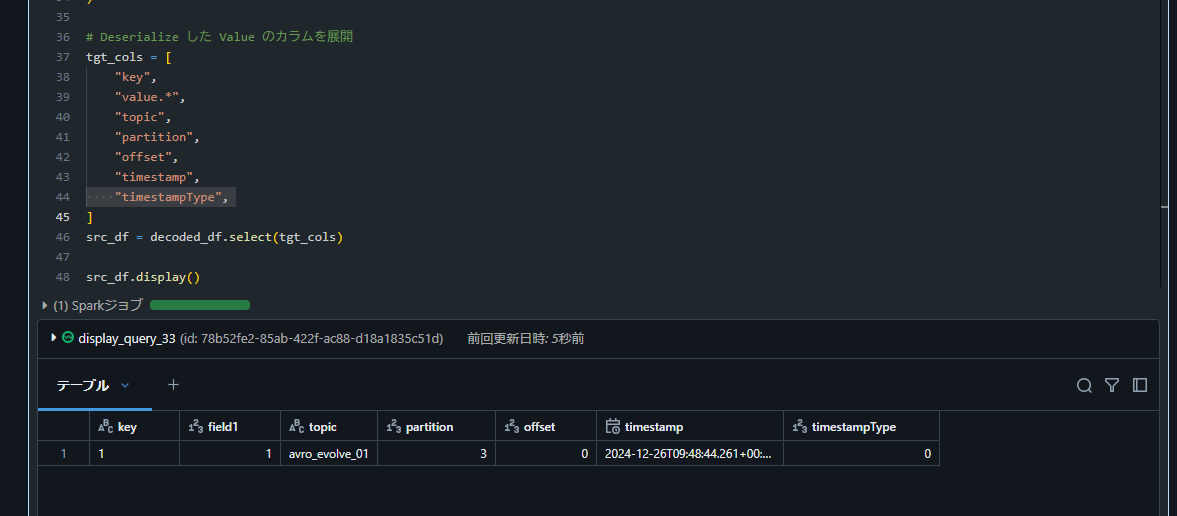
8. Confluent で Topic にデータを追加
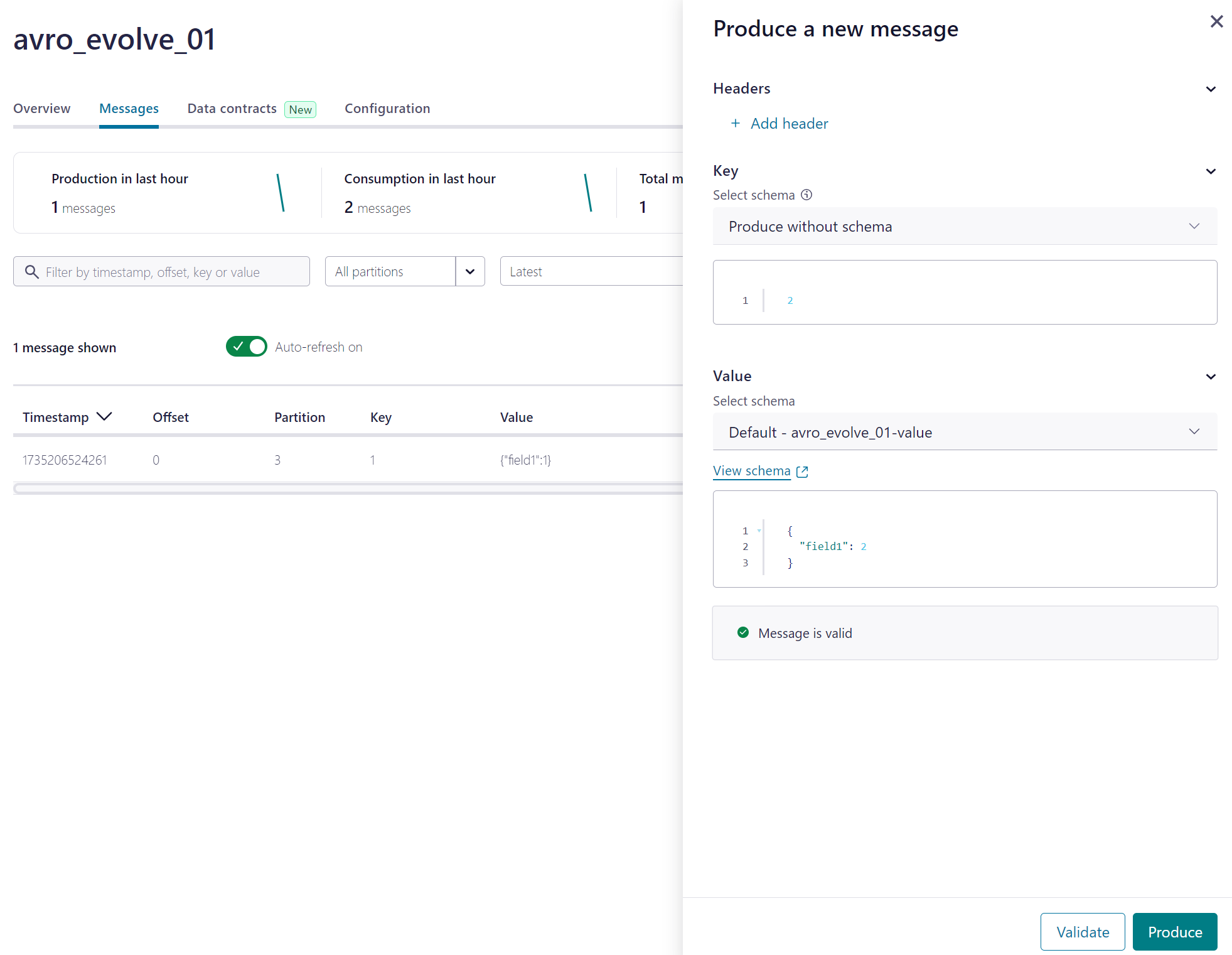
9. Databricks での処理がエラーになることを確認
org.apache.spark.sql.catalyst.util.UnknownFieldException: [UNKNOWN_FIELD_EXCEPTION.UNKNOWN_SOURCE] Encountered unknown fields during parsing: Found record with schema id 100009, which is newer than the schema id 100008 fetched at the start (Set avroSchemaEvolutionMode to 'none' to ignore schema id change. This could result in dropping new fields.), which can be fixed by an automatic retry: false
10. Databricks で再度データ取得処理を実行し、カラムが追加されたことを確認
from pyspark.sql.functions import col, expr
from pyspark.sql.avro.functions import from_avro
# Magic Byte と Schema ID を取り除いた Value を Deserialize
decoded_df = key_des_df.withColumn(
"value",
from_avro(
col("value"),
options=schema_registry_options,
subject=subject_name,
schemaRegistryAddress=sr_url,
),
)
# Confluent から読み込み
df = (
spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", bootstrap_servers)
.option("kafka.security.protocol", "SASL_SSL")
.option(
"kafka.sasl.jaas.config",
f'kafkashaded.org.apache.kafka.common.security.plain.PlainLoginModule required username="{sasl_username}" password="{sasl_password}";',
)
.option("kafka.sasl.mechanism", "PLAIN")
.option("subscribe", topic_name)
.option("startingOffsets", "earliest")
.load()
)
# Key を Deserialize
key_des_df = df.withColumn(
"key",
col("Key").cast("string"),
)
# Magic Byte と Schema ID を取り除いた Value を Deserialize
decoded_df = key_des_df.withColumn(
"value",
from_avro(
col("value"),
options=schema_registry_options,
subject=subject_name,
schemaRegistryAddress=sr_url,
),
)
# Deserialize した Value のカラムを展開
tgt_cols = [
"key",
"value.*",
"topic",
"partition",
"offset",
"timestamp",
"timestampType",
]
src_df = decoded_df.select(tgt_cols)
src_df.display()
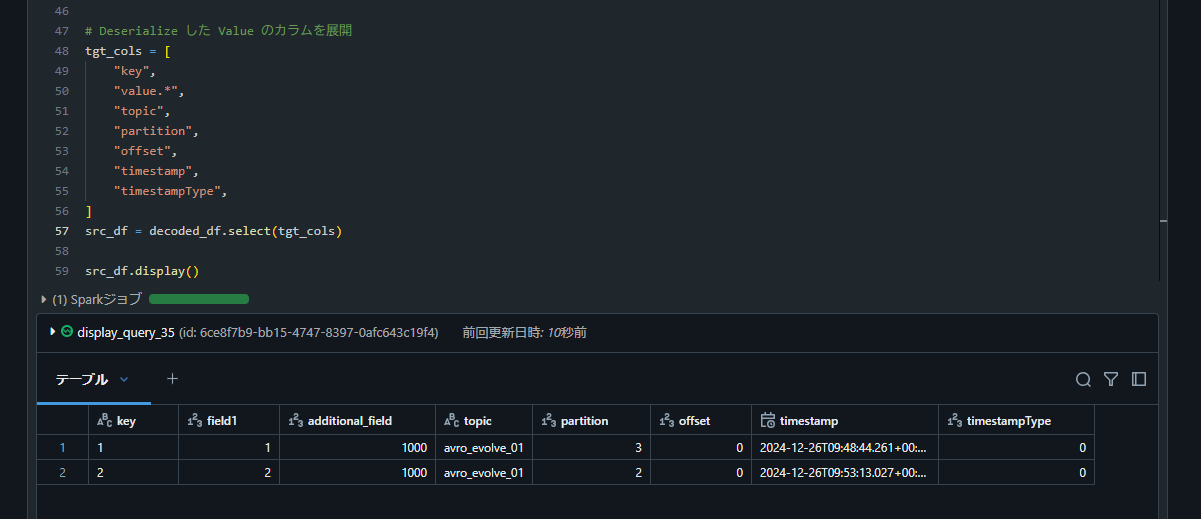
Protobuf 形式の Topic におけるスキーマ展開の検証
Protobuf 形式の場合も、Kafka でフィールドを追加した際に Avro と同様のエラーが発生し、ジョブの再実行で新規カラムが反映されることを確認しました。ここでは概要のみを示します。
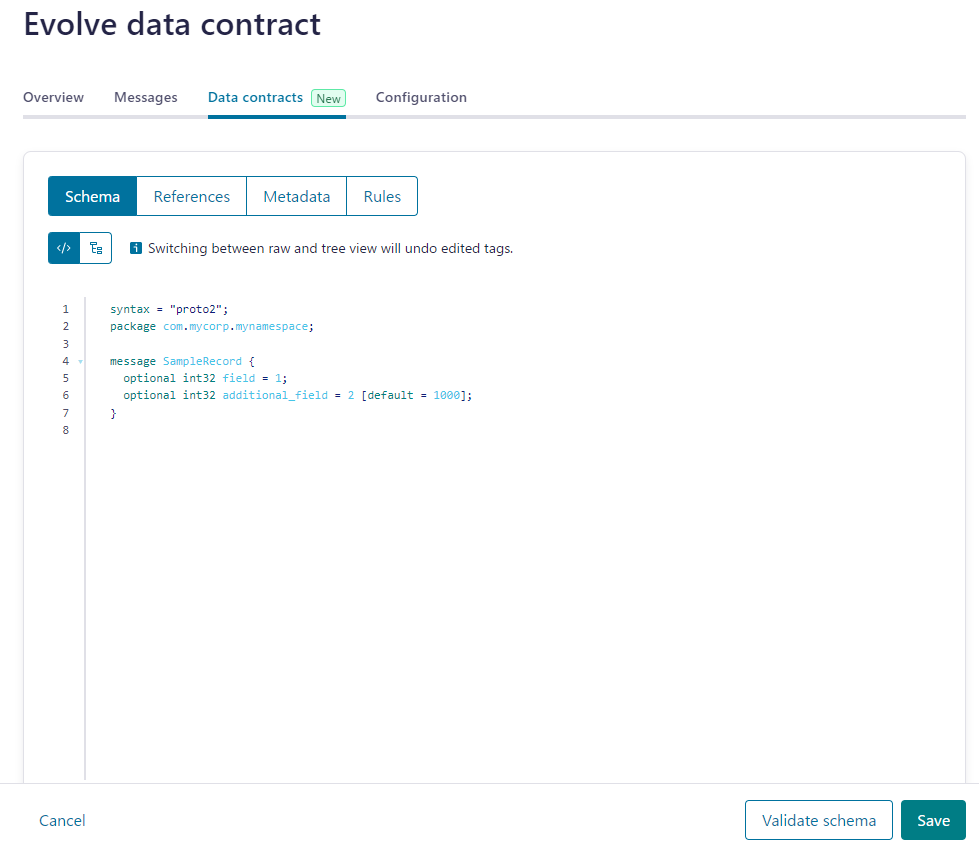
下記のスキーマのオブジェクトに変更後に、 Databricks 側の処理がエラーとなりました。
syntax = "proto2";
package com.mycorp.mynamespace;
message SampleRecord {
optional int32 field = 1;
optional int32 additional_field = 2 [default = 1000];
}
org.apache.spark.sql.catalyst.util.UnknownFieldException: [UNKNOWN_FIELD_EXCEPTION.UNKNOWN_SOURCE] Encountered unknown fields during parsing: Found record with schema id 100012, which is newer than the schema id 100011 fetched at the start (Set schema.registry.schema.evolution.mode to 'none' to ignore schema id change. This could result in dropping new fields.), which can be fixed by an automatic retry: false
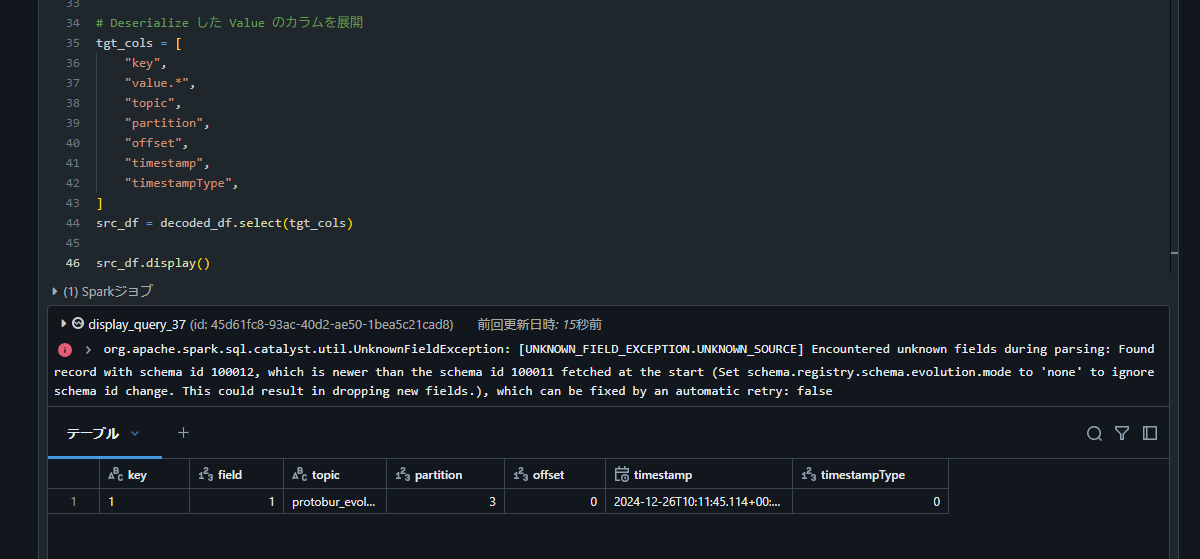
Avro と同様、再実行で新規フィールドが追加されたことが確認できました。
schema_registry_options = {
"schema.registry.address": sr_url,
"confluent.schema.registry.basic.auth.credentials.source": "USER_INFO",
"confluent.schema.registry.basic.auth.user.info": f"{sr_api_key}:{sr_api_secret}",
}
topic_name = "protobur_evolve"
value_subject_name = "protobur_evolve-value"
schema_registry_options["schema.registry.subject"] = value_subject_name
from pyspark.sql.functions import col, expr
from pyspark.sql.protobuf.functions import from_protobuf
# Confluent から読み込み
df = (
spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", bootstrap_servers)
.option("kafka.security.protocol", "SASL_SSL")
.option(
"kafka.sasl.jaas.config",
f'kafkashaded.org.apache.kafka.common.security.plain.PlainLoginModule required username="{sasl_username}" password="{sasl_password}";',
)
.option("kafka.sasl.mechanism", "PLAIN")
.option("subscribe", topic_name)
.option("startingOffsets", "earliest")
.load()
)
# Key を Deserialize
key_des_df = df.withColumn(
"key",
col("Key").cast("string"),
)
# Magic Byte と Schema ID を取り除いた Value を Deserialize
decoded_df = key_des_df.withColumn(
"value",
from_protobuf(
col("value"),
options=schema_registry_options,
),
)
# Deserialize した Value のカラムを展開
tgt_cols = [
"key",
"value.*",
"topic",
"partition",
"offset",
"timestamp",
"timestampType",
]
src_df = decoded_df.select(tgt_cols)
src_df.display()
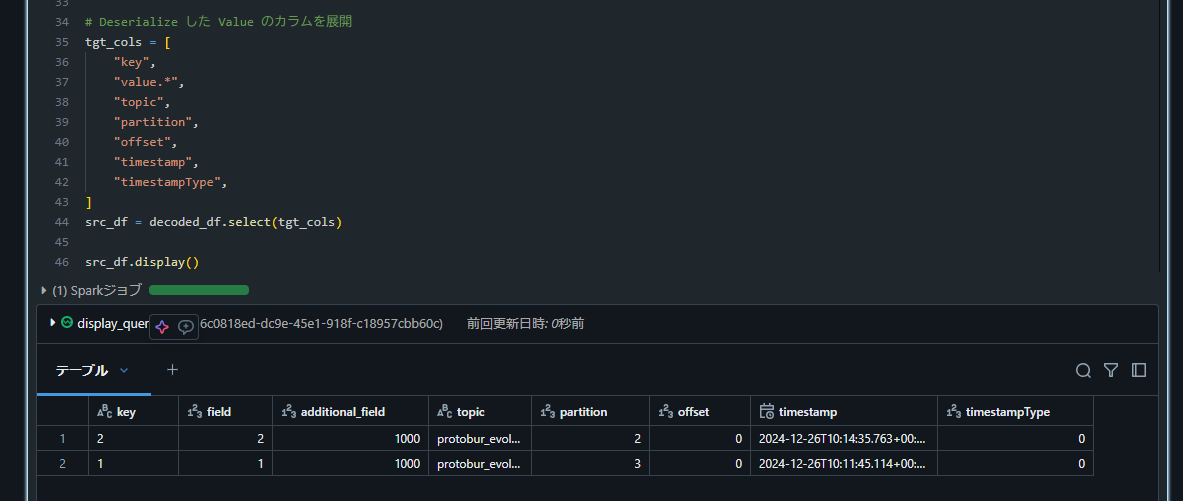
まとめ
まとめ
本記事では、Databricks 上で Confluent Schema Registry を利用した場合に、Kafka 側のスキーマ進化がどのように検知され、どのような振る舞いをするかを調査しました。結論としては、Avro 形式と Protobuf 形式いずれの場合も、スキーマ進化(新規フィールド追加など)があると Databricks 側でいったん UnknownFieldException を発生させた後、再度ジョブを実行することで、追加されたフィールドを認識できることがわかりました。
特に以下のポイントが重要です。
-
avroSchemaEvolutionModeまたは Protobuf 用schema.registry.schema.evolution.modeの設定-
"restart"設定の場合、Kafka にてスキーマ ID が更新されるとUnknownFieldExceptionでクエリが停止しますが、その後の再起動(リトライ)で新しいスキーマを取得し、カラムを自動で追加できます。
-
-
再起動(リトライ)によるスキーマの反映
- クエリやタスクの再起動時に新しいスキーマを正しく読み込むため、Databricks の処理にて
ジョブ失敗時に自動再実行などの仕組みを用いることが推奨されます。
- クエリやタスクの再起動時に新しいスキーマを正しく読み込むため、Databricks の処理にて
-
Avro / Protobuf どちらでも同様に動作
- Avro と Protobuf はそれぞれ別の形式ですが、Databricks + Confluent Schema Registry によるスキーマ進化検知の挙動は非常に似ています。いずれも新しいスキーマを一度検知するとエラーになり、再起動の後にスキーマを再取得するフローをたどります。
今後、スキーマ変更が見込まれる Kafka Topic を Databricks で取り扱う場合は、今回の手順をもとに設定やエラー発生時のリトライ機構を構築しておくと、停止時間を最小限に抑え、柔軟なスキーマ進化に対応できるようになります。