概要
本記事では、Snowflake Open Catalog の全体像を把握するための学習コンテンツを紹介します。Snowflake Open Catalog を検証する際には外部サービスとの連携が必要ですが、ここでは主に Google Colab 上で Spark を利用して操作する手順を解説します。本記事を通じて、Snowflake Open Catalog に関する理解が深まれば幸いです。
- 環境構築
- Azure Storage 環境の構築
- Snowflake Open Catalog のアカウントを作成
- Snowflake Open Catalog のカタログ構築
- 内部カタログの作成
- Azure Storage に対する認証設定
- Snowflake Open Catalog におけるロールの作成
- Snowflake Open Catalog における接続情報の作成
- Snowflake Open Catalog に対する権限付与
- Spark による Open Catalog のオブジェクト操作
- Iceberg テーブルに対する REFRESH の実行
- Iceberg テーブルに対する 自動 REFRESH 設定の実施
Snowflake Catalog での学習コンテンツについては、以下の記事をご参照ください。
出所:Snowflake Catalog における Iceberg テーブルの基本的な操作手順 #Spark - Qiita
本記事は「SnowflakeにおけるApache Iceberg機能の完全ガイド」シリーズの一部です。
Apache Iceberg機能の全体像やSnowflake上での活用方法について詳しく知りたい方は、以下の記事をご覧ください。
Snowflake Open Catalog について
Snowflake Open Catalog は、オープンソースのデータカタログ基盤 Apache Polaris をベースにしたマネージドサービスであり、特に Apache Icebergのテーブルカタログとしての役割を担います。
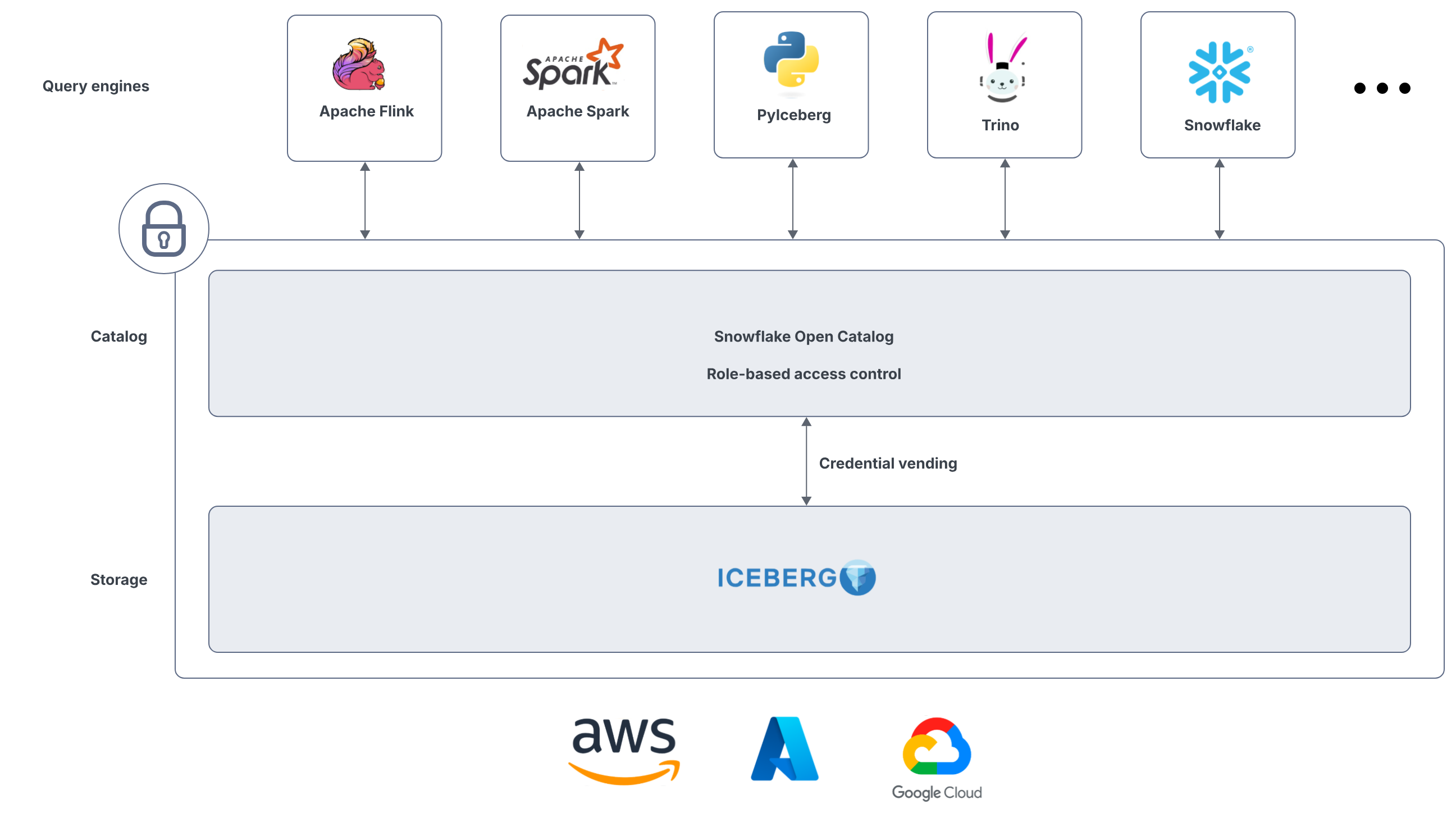
出所:Snowflakeオープンカタログの概要 | Snowflake Documentation
Snowflake で Apache Iceberg 利用する方法としては、Snowflake をカタログとして利用する方法と、Snowflake Open Catalog(マネージド Apache Polaris)を利用する方法があります。本記事では後者をメインに扱います。Snowflake Open Catalog は、Snowflake のアカウントとは別に Snowflake Open Catalog のアカウントを作成して Iceberg のカタログとして利用できる仕組みです。Snowflake Open Catalog 上で管理しているテーブルは、Snowflake 側からも利用可能です。
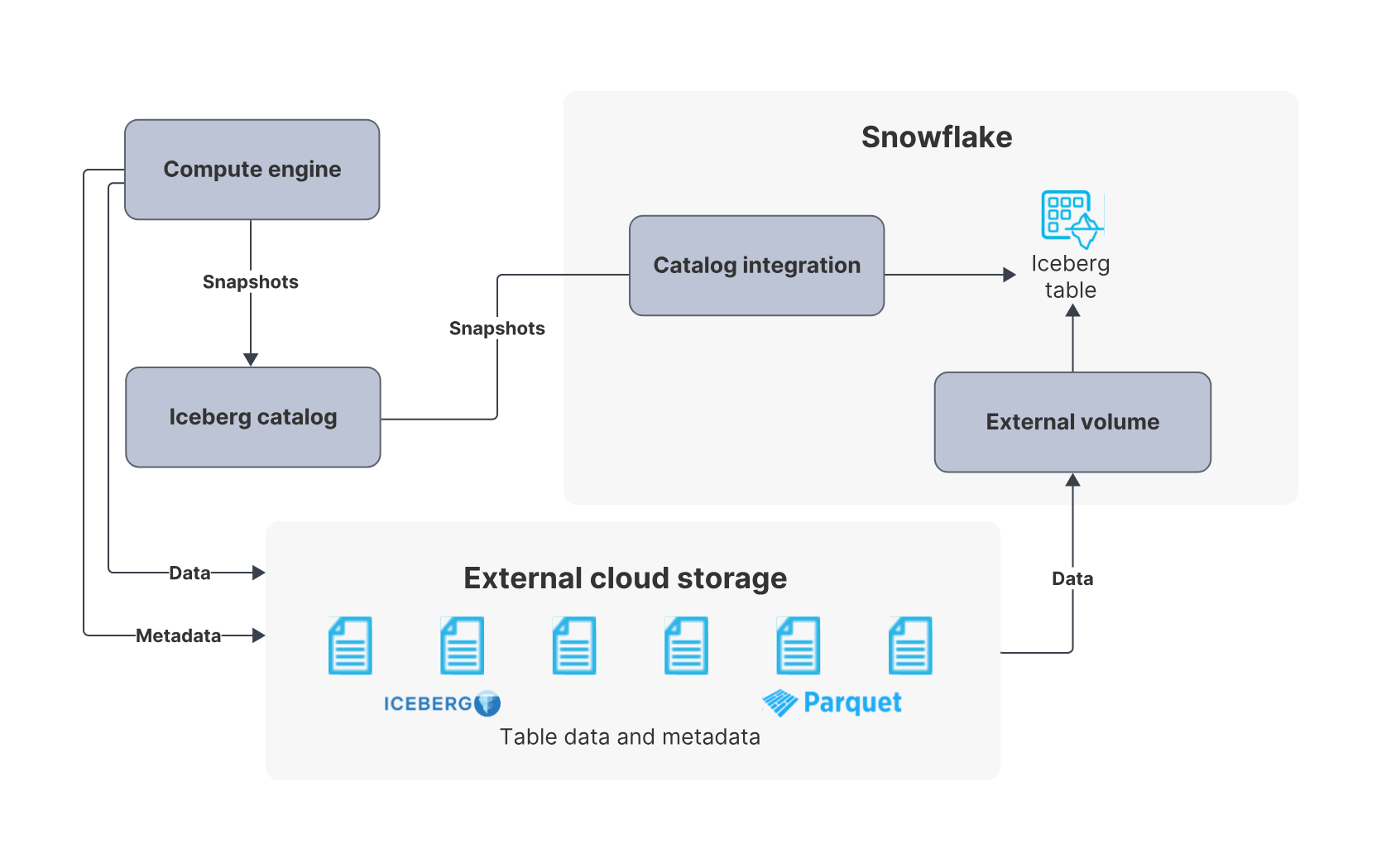
出所:Apache Iceberg™ テーブル | Snowflake Documentation
ドキュメントは、Snowflakeのドキュメントとは別に「Snowflake Open Catalog」の専用タブで表示できます。
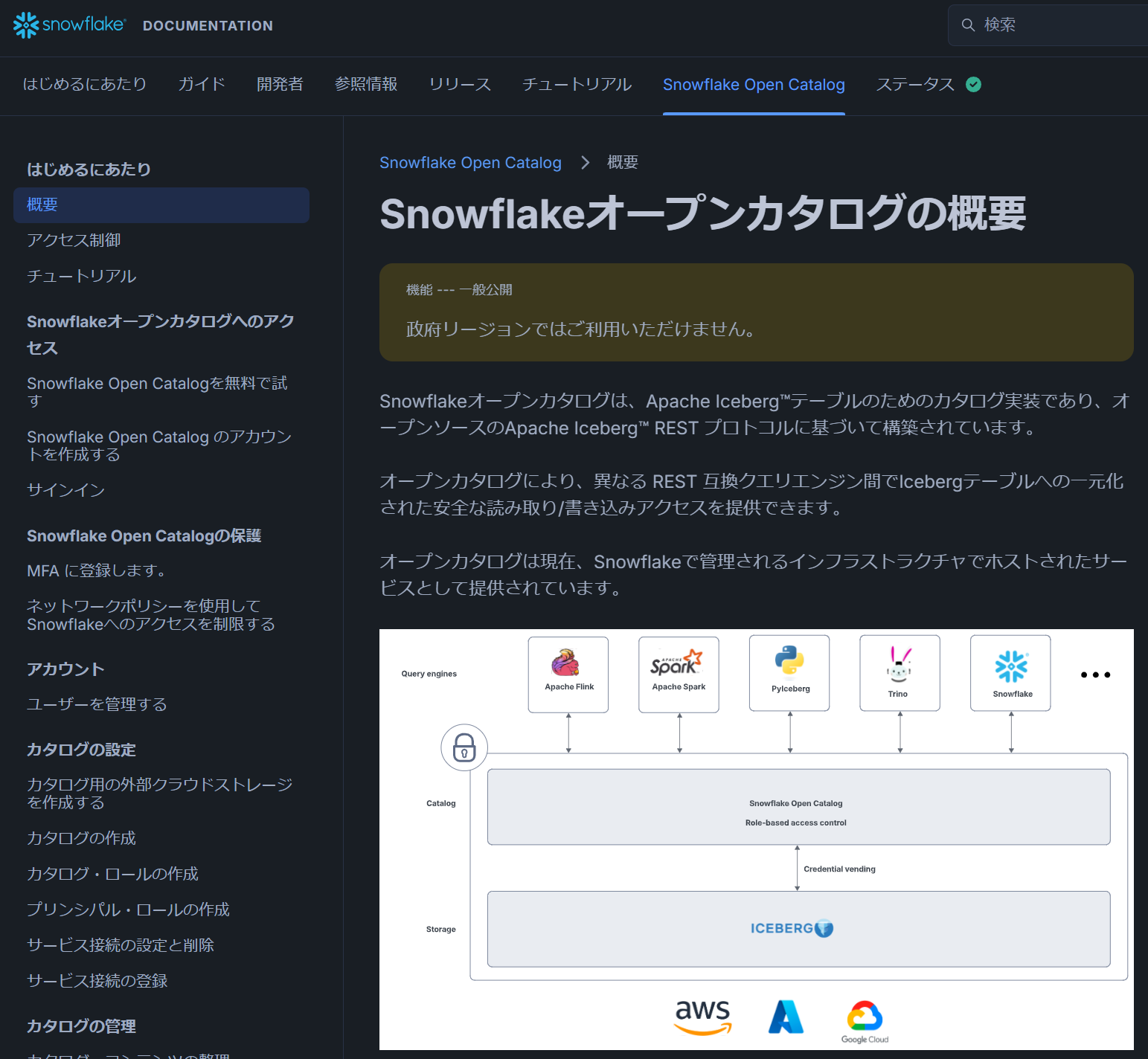
出所:Snowflakeオープンカタログの概要 | Snowflake Documentation
本記事は Snowflake の公式チュートリアルをベースとしています。公式チュートリアルもあわせてご確認ください。
クラウドベンダーごとの手順については、以下のドキュメントに記載されています。
- Azureストレージを使用したカタログの作成 | Snowflake Documentation
- Amazon Simple Storage Service (Amazon S3)を使用したカタログの作成 | Snowflake Documentation
- Googleのクラウドストレージを使用したカタログの作成 | Snowflake Documentation
また、Google Colab 上での Spark の基本的な操作方法については、以下の記事をご参照ください。
環境構築
Azure Storage 環境の構築
まず、Azure Storage アカウントを作成します。
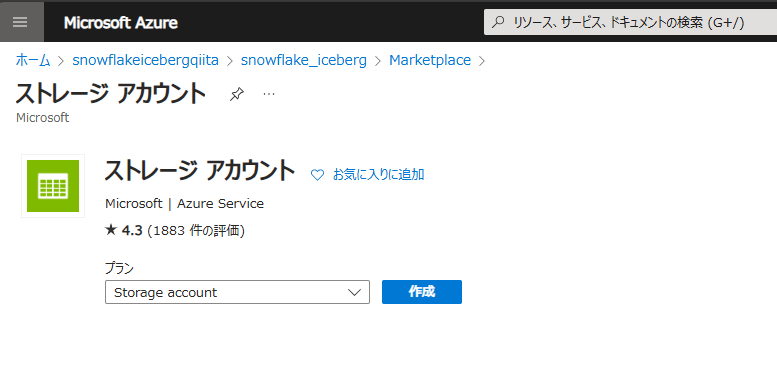
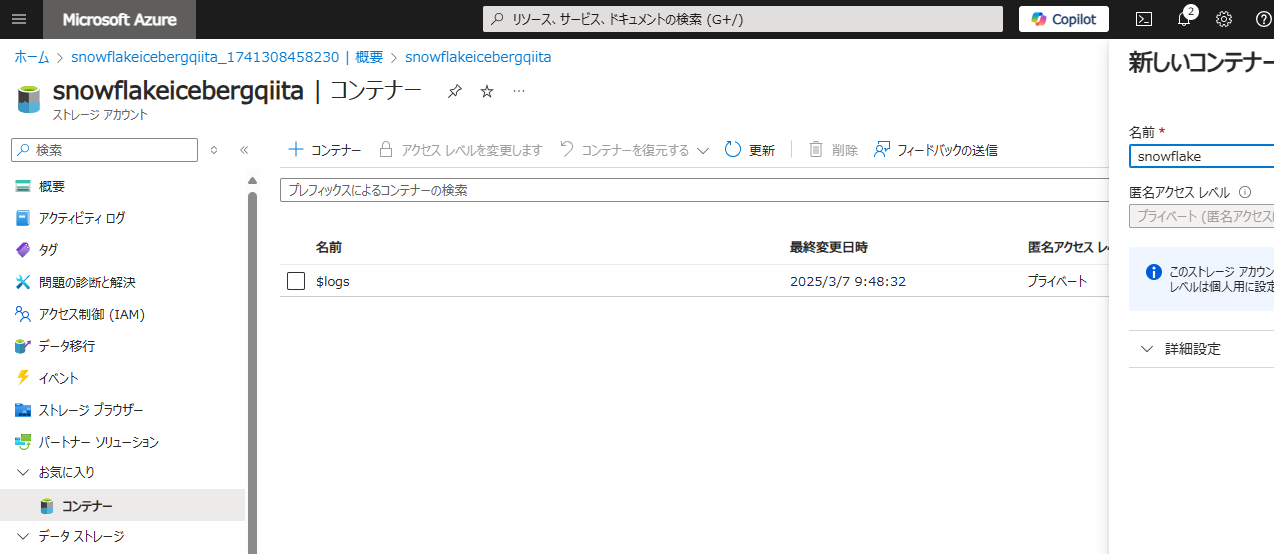
snowflake というコンテナーを作成します。
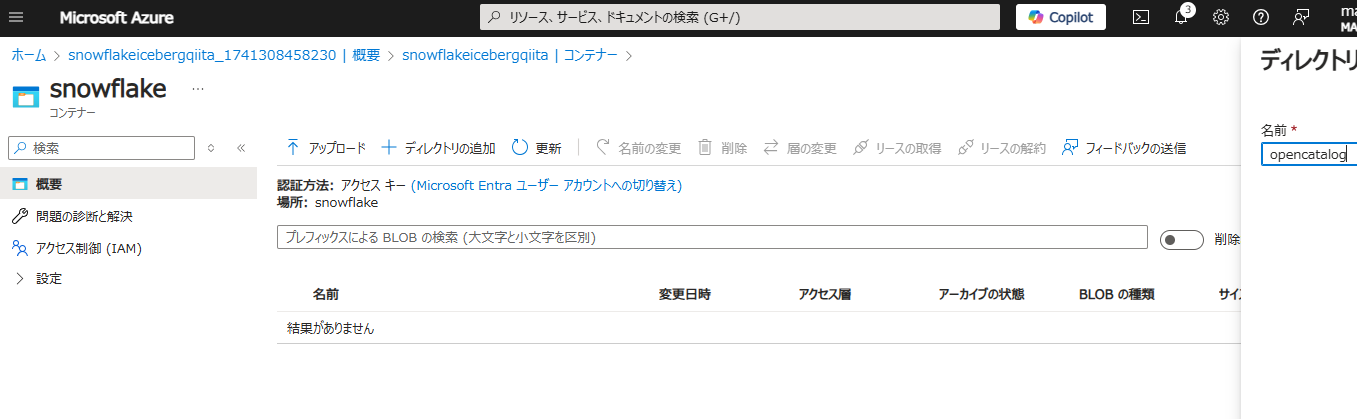
opencatalog というディレクトリを作成します。
Snowflake Open Catalog のアカウントを作成
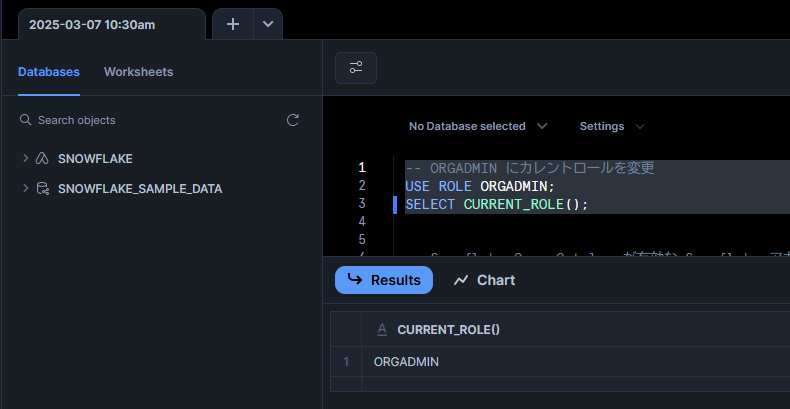
ORGADMIN ロールに切り替えます。
-- ORGADMIN にカレントロールを変更
USE ROLE ORGADMIN;
SELECT CURRENT_ROLE();
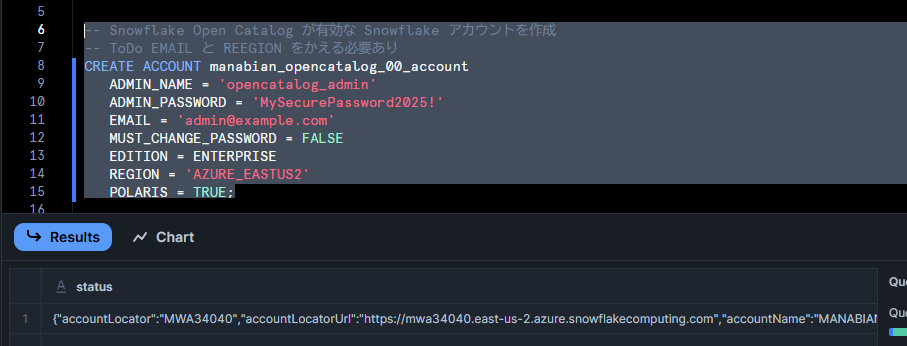
Snowflake Open Catalog が有効な Snowflake アカウントを作成します。
-- Snowflake Open Catalog が有効な Snowflake アカウントを作成
-- ToDo EMAIL と REEGION をかえる必要あり
CREATE ACCOUNT manabian_opencatalog_00_account
ADMIN_NAME = 'opencatalog_admin'
ADMIN_PASSWORD = 'MySecurePassword2025!'
EMAIL = 'admin@example.com'
MUST_CHANGE_PASSWORD = FALSE
EDITION = ENTERPRISE
REGION = 'AZURE_EASTUS2'
POLARIS = TRUE;
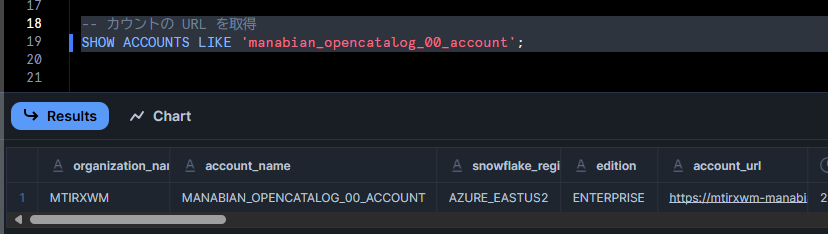
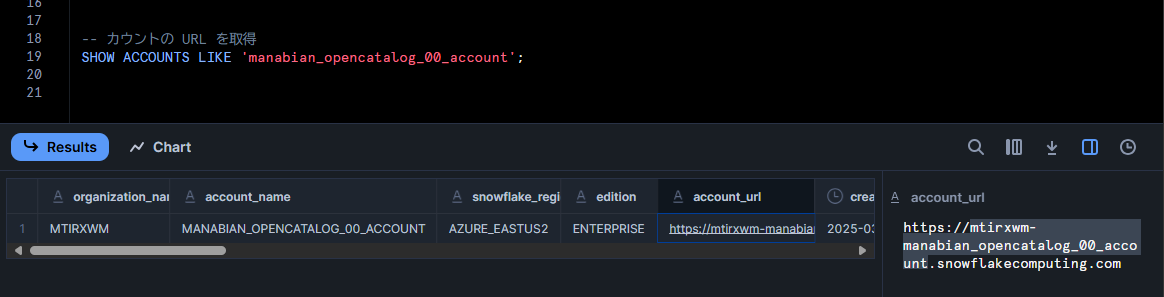
Snowflake Open Catalog が有効な Snowflake アカウントの URL を取得します。
-- カウントの URL を取得
SHOW ACCOUNTS LIKE 'manabian_opencatalog_00_account';
作成直後にアクセスすると 404 エラーが表示される場合があるため、5 分程度待ちます。
ページをリロードし、先ほど設定したアカウントでログインします。
Snowflake Open Catalog のアカウントのウェブインターフェイスに接続できることを確認します。
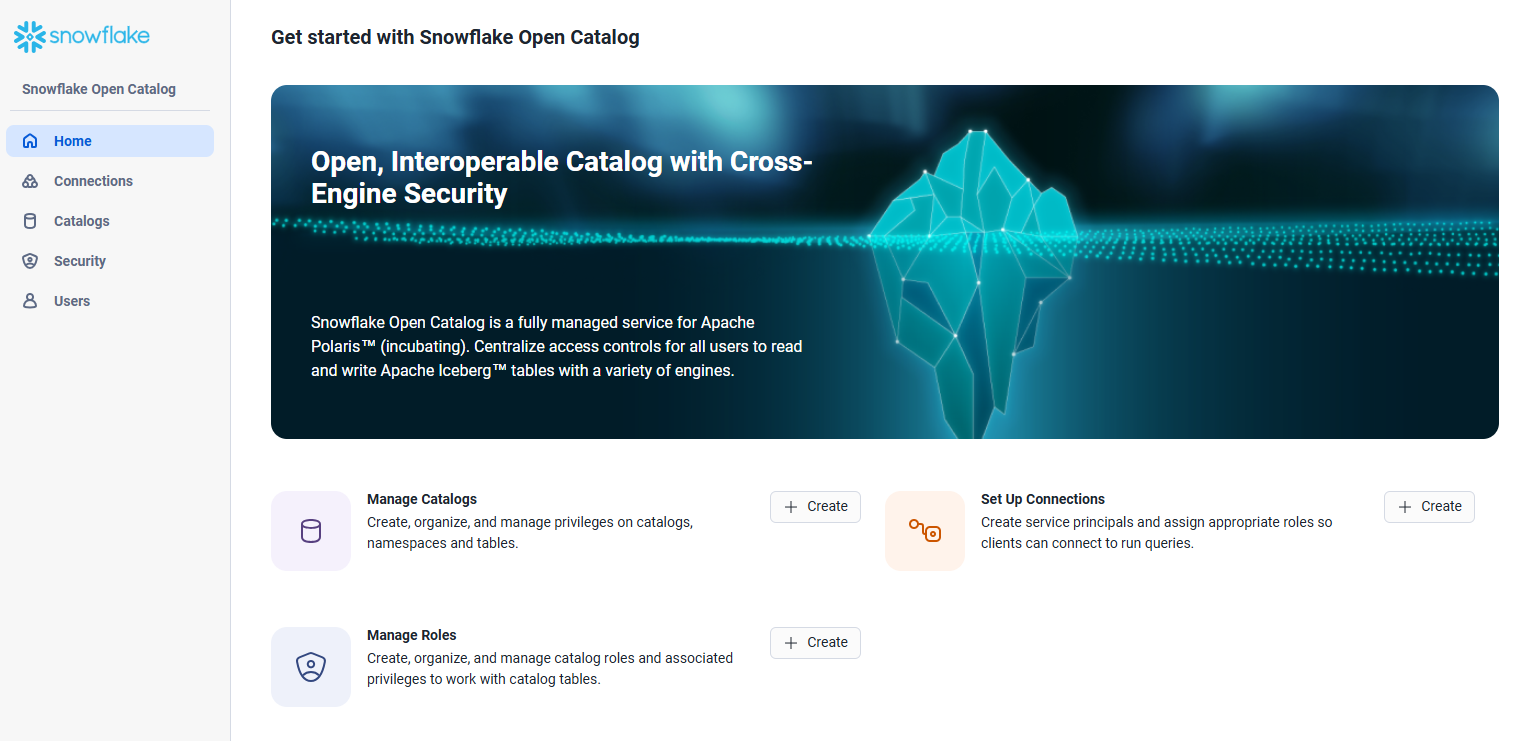
Snowflake Open Catalog のカタログ構築
内部カタログの作成
Catalogsタブ -> + Catalogを選択
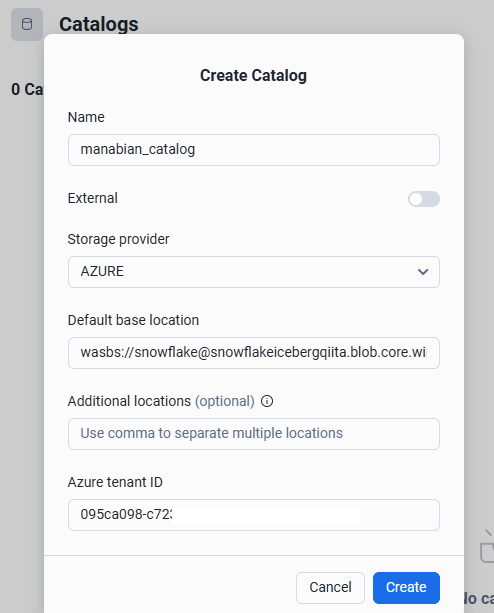
カタログの設定値を入力後にCreateを選択
| # | 項目 | 設定値例 | 備考 |
|---|---|---|---|
| 1 | Name | manabian_catalog | カタログの名称 |
| 2 | External | 非チェック | 外部カタログを利用するかの選択 |
| 3 | Storage provider | Azure | |
| 4 | Default base location | wasbs://snowflake@snowflakeicebergqiita.blob.core.windows.net/opencatalog/ |
Azure プロトコルではなく、 wasbs または abfss を指定 |
| 5 | Additional locations (optional) | 空文字 | |
| 6 | Azure tenant ID | 095ca098-c723-xxxxxx-xxxxxxxxxx | Azure テナント ID |
本記事は Azure 環境向けの手順を示していますが、Snowflake のドキュメントにはクラウドベンダー別の手順が用意されています。
公式ドキュメント上では Blob と ADLS の両方が指定可能となっていますが、ADLS での動作は未検証です。Blob の URI について、公式ドキュメントには「abfss」と記載がありますが、実際には「wasbs」が正しく機能します。
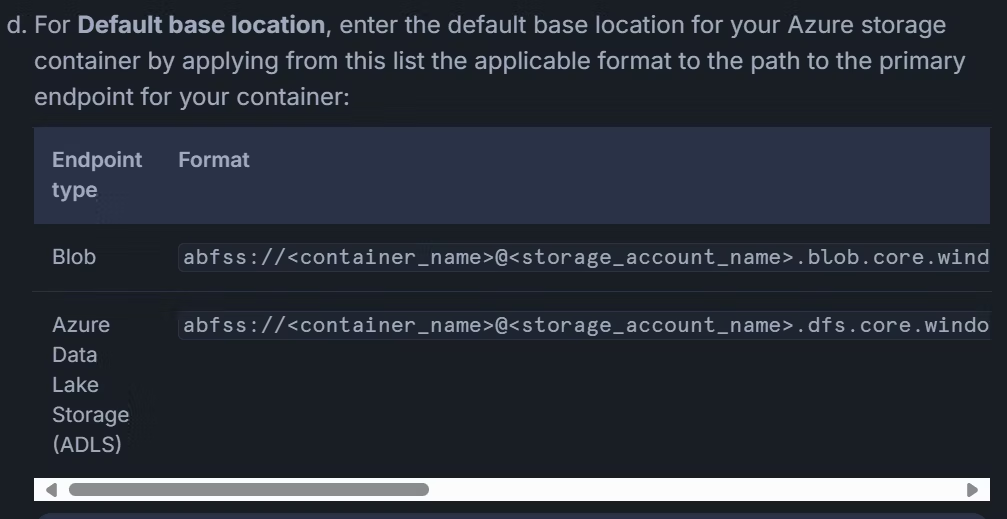
出所:Azureストレージを使用したカタログの作成| Snowflake Documentation
カタログが作成されたことを確認
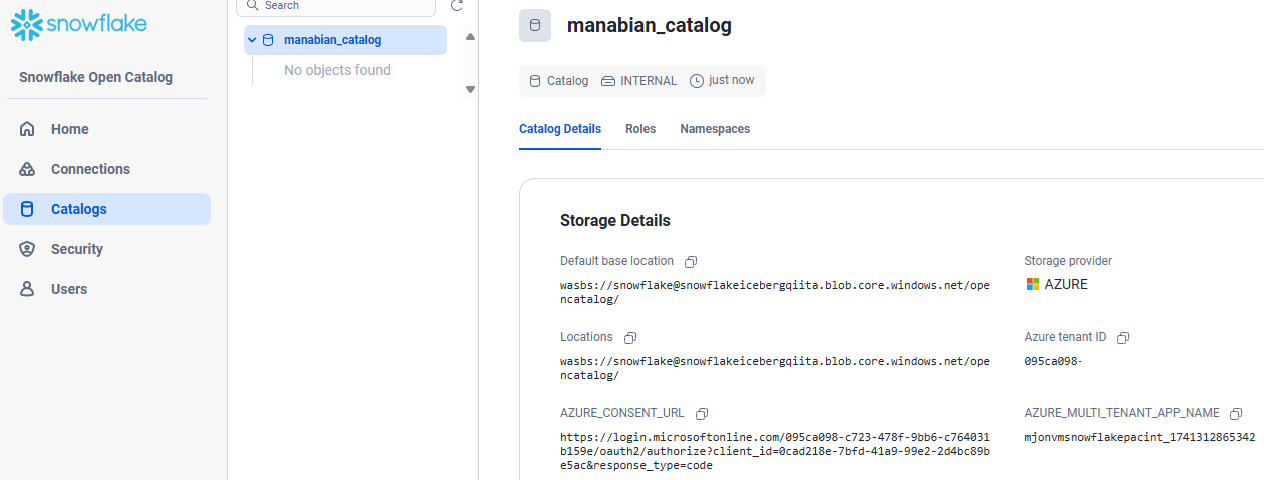
Azure Storage に対する認証設定
カタログの設定を表示後、AZURE_CONSENT_URL の URL を Azure にログインしているブラウザでアクセス
外部アプリケーションへのサインイン許可を求めるページが表示されたら、承諾を選択
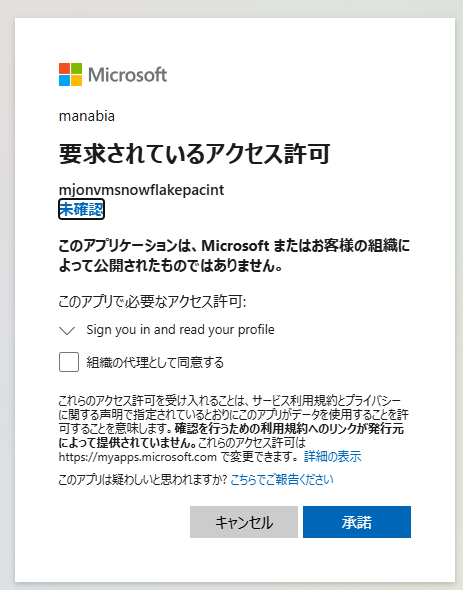
この手順は、以下のドキュメントに示されている Microsoft ID プラットフォームでのアクセス許可と同意の設定に相当します。
Azure ポータルで、作成した Azure Storage のページを表示し、アクセス制御 (IAM) -> + 追加 -> ロールの割り当ての追加を選択
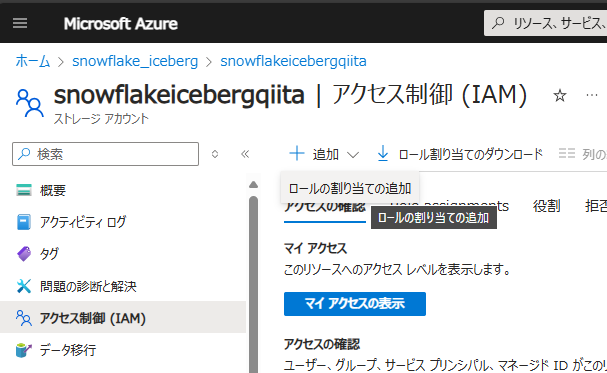
ストレージ BLOB データ共同作成者を選択して 次へ をクリック
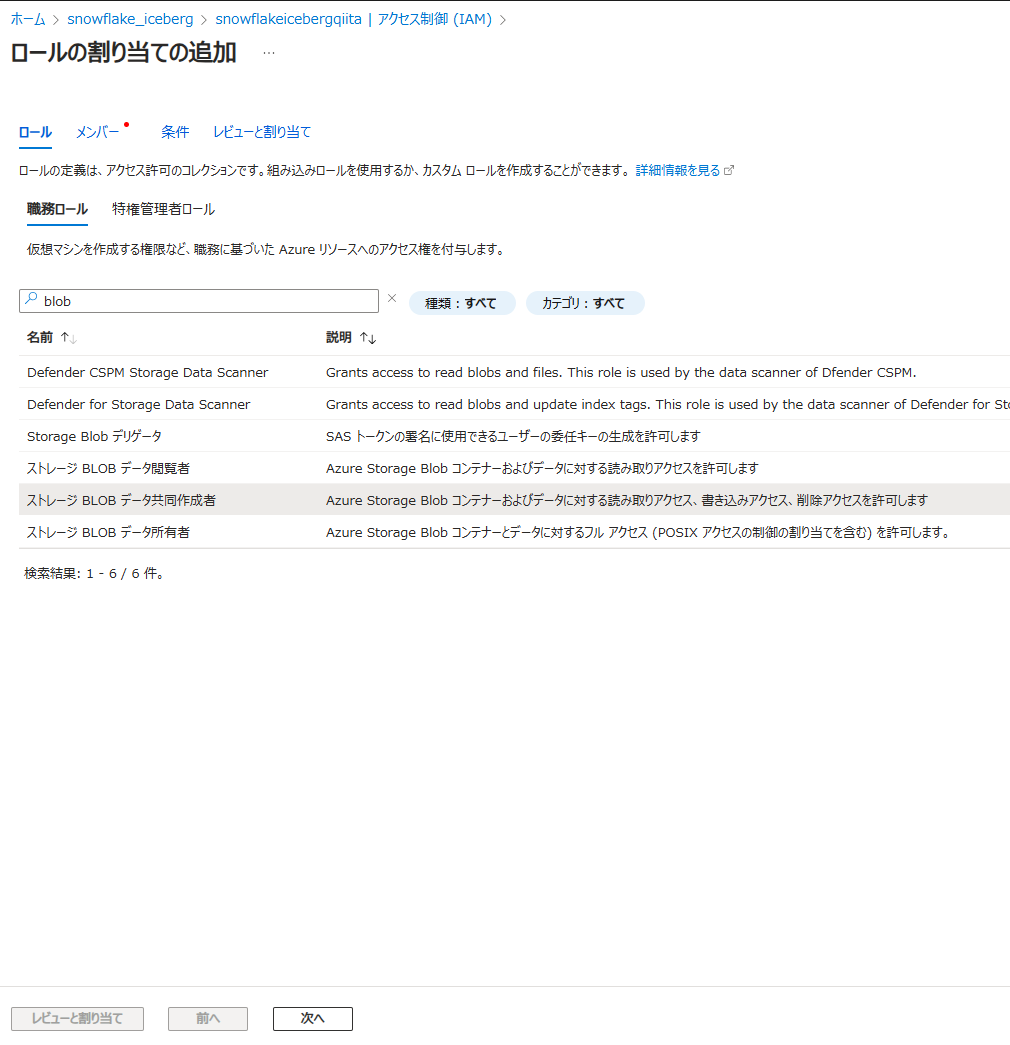
Snowflake Open Catalog のカタログ設定に表示されている AZURE_MULTI_TENANT_APP_NAME(例:mjonvmsnowflakepacint_1741312865342)のうち、アンダーバーより前の名称(例:mjonvmsnowflakepacint)のアプリケーションを選択し、選択 -> レビューと割り当て をクリック
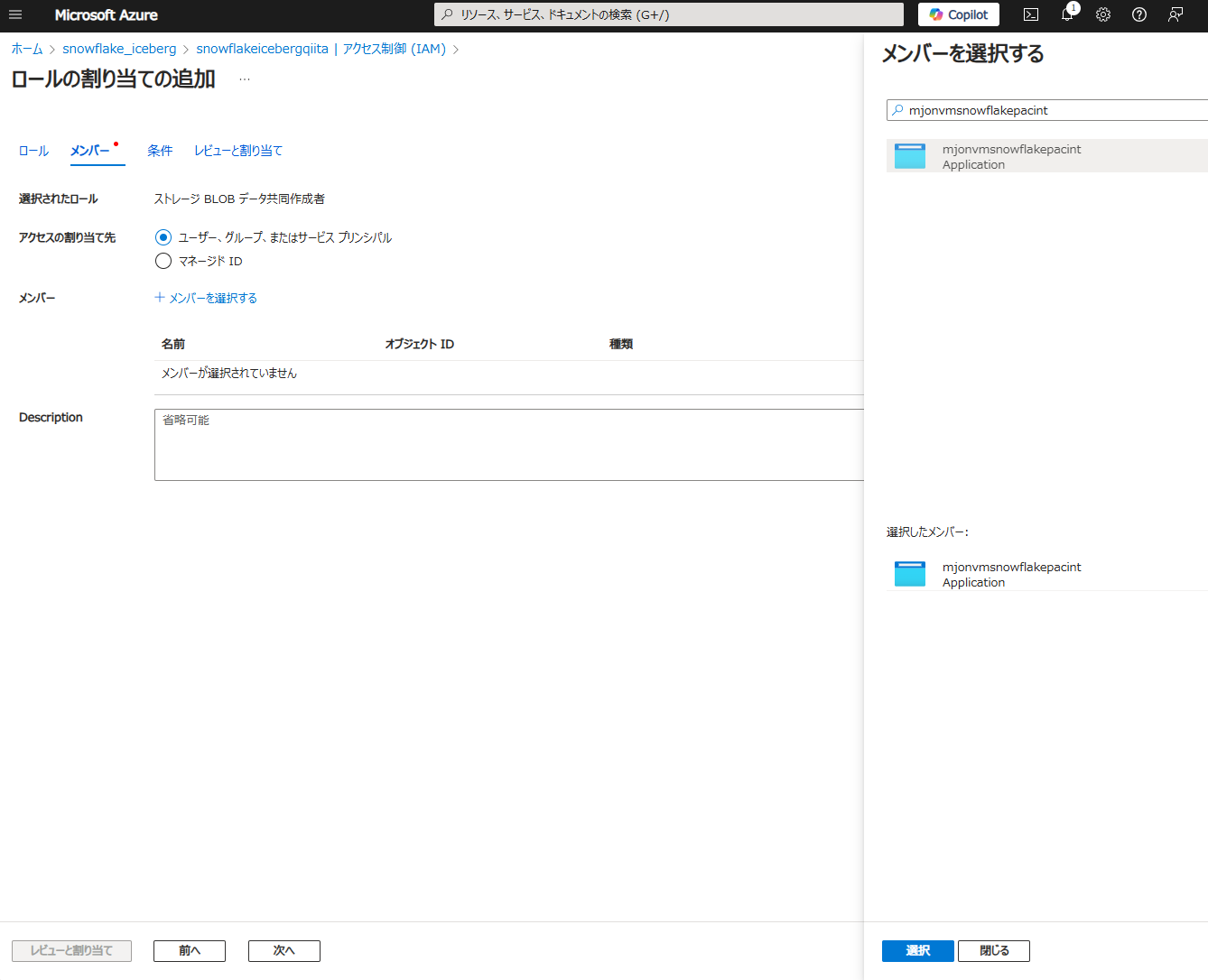
Snowflake Open Catalog のカタログ設定に記載されている AZURE_MULTI_TENANT_APP_NAME の値を参照します。
レビューと割り当てをクリック
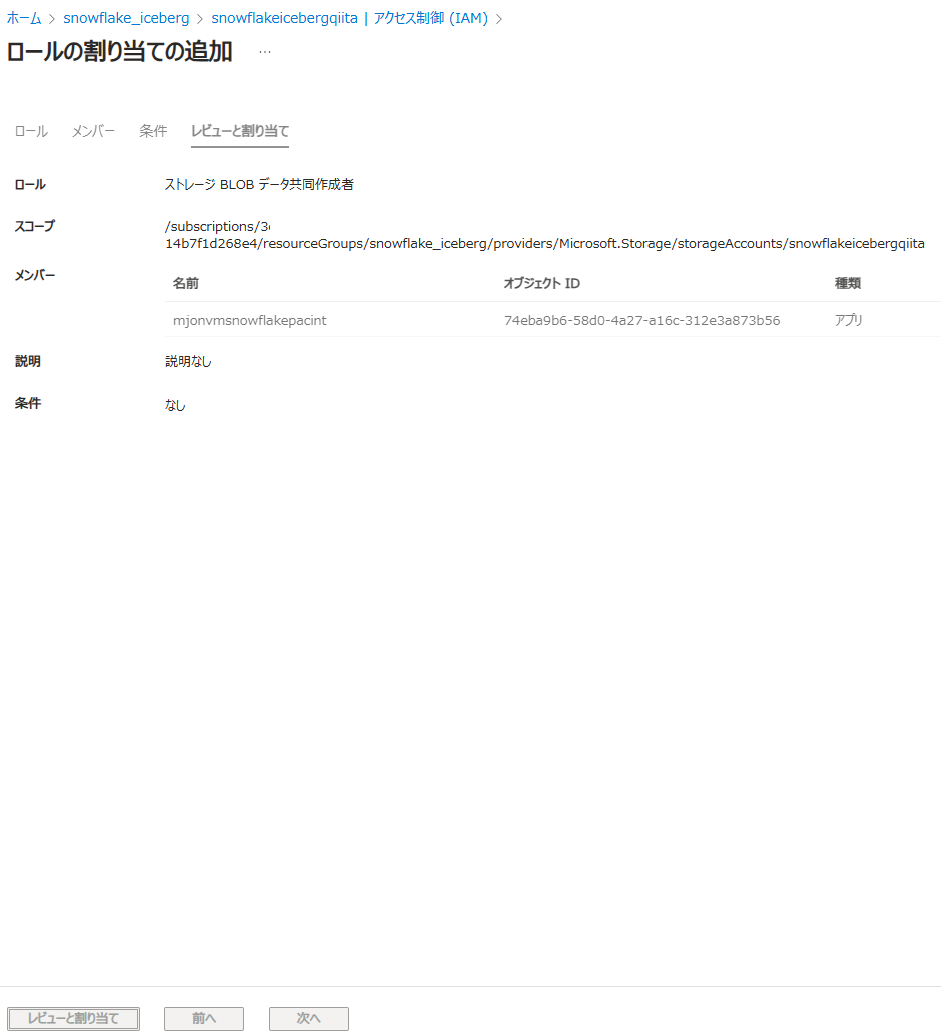
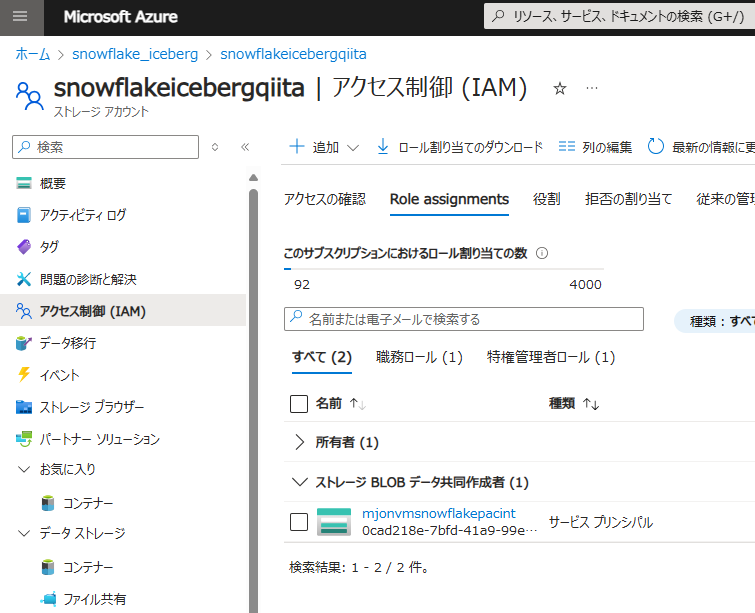
Role assignments タブで割り当てが追加されていることを確認
Snowflake Open Catalog におけるロールの作成
Snowflake Open Catalog で Connections タブ -> Roles タブ -> + Principal Role を選択
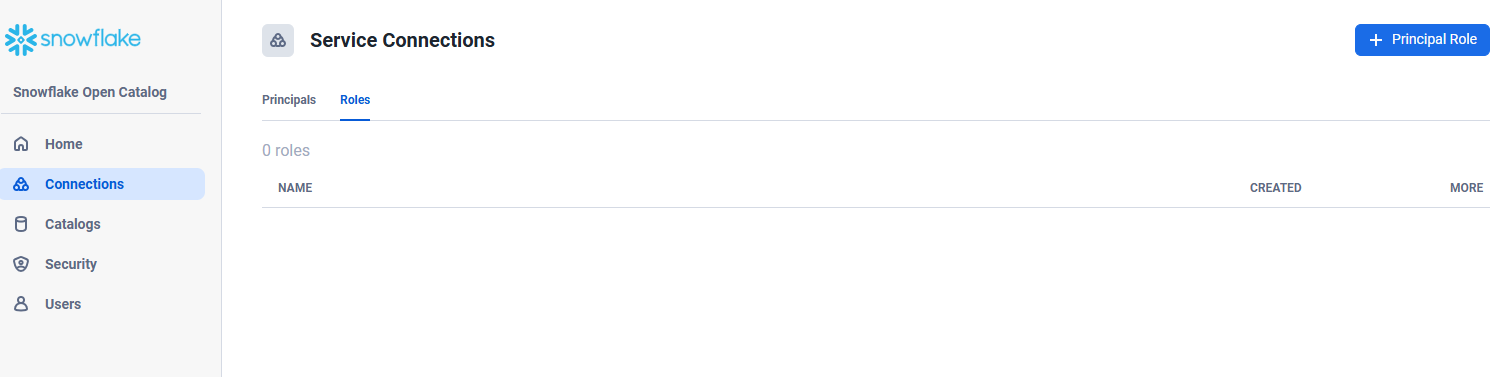
Name に spark_role と入力し、Create をクリック
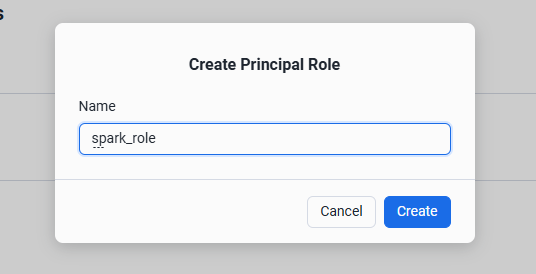
Snowflake Open Catalog における接続情報の作成
Snowflake Open Catalog で Connections タブ -> Principal タブ -> + Connection を選択
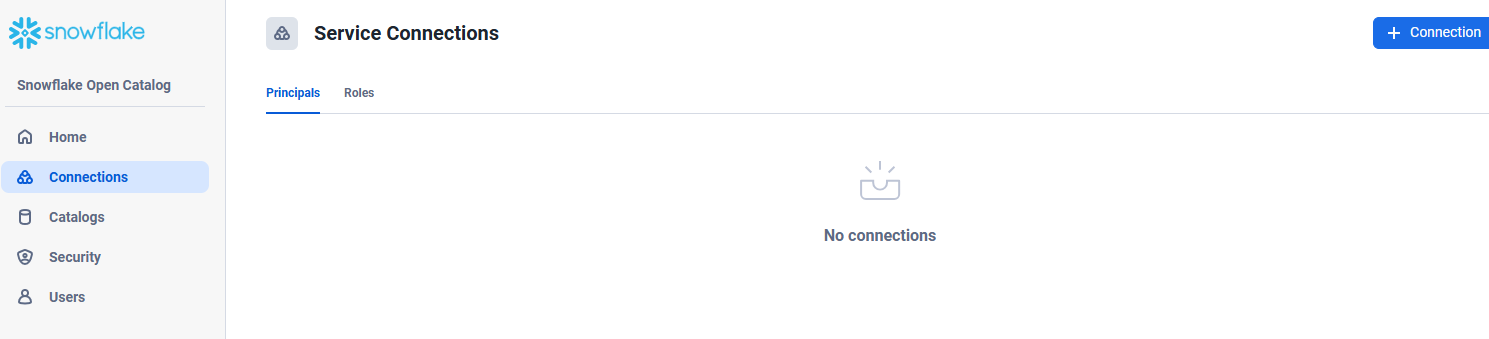
項目に値を設定して Create をクリック
| # | 項目 | 設定値例 |
|---|---|---|
| 1 | Name | google_colab |
| 2 | Query Engine | Apache Spark |
| 3 | Principal Role | spark_role |
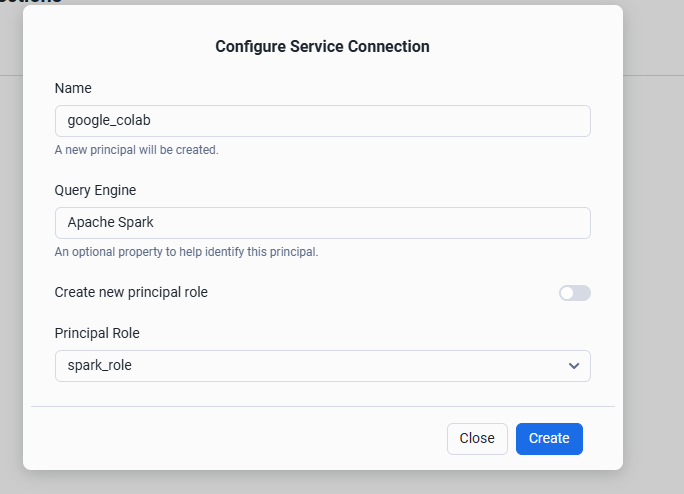
Spark からアクセスする際に利用する Client ID と Client Secret を取得
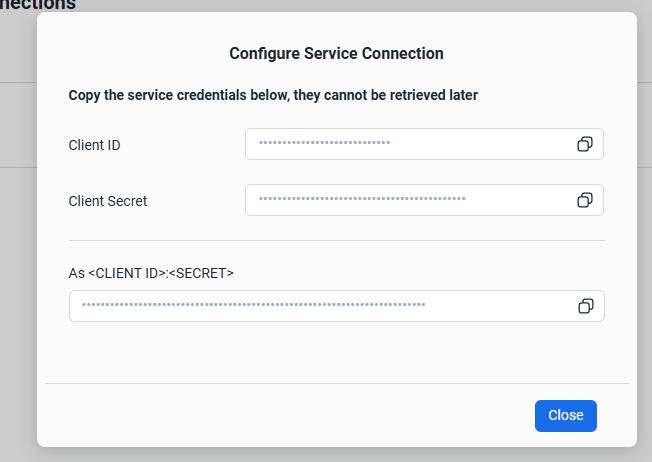
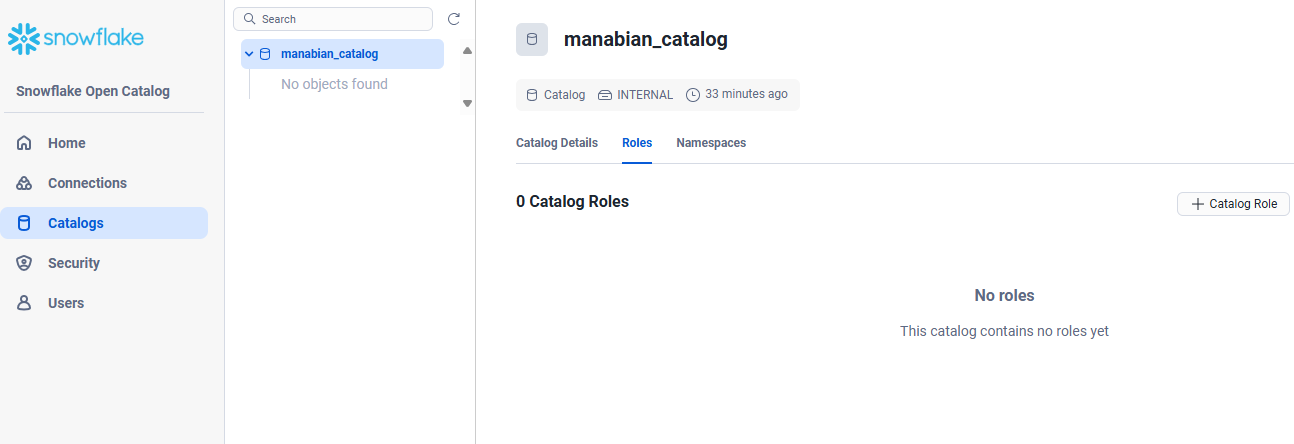
Snowflake Open Catalog に対する権限付与
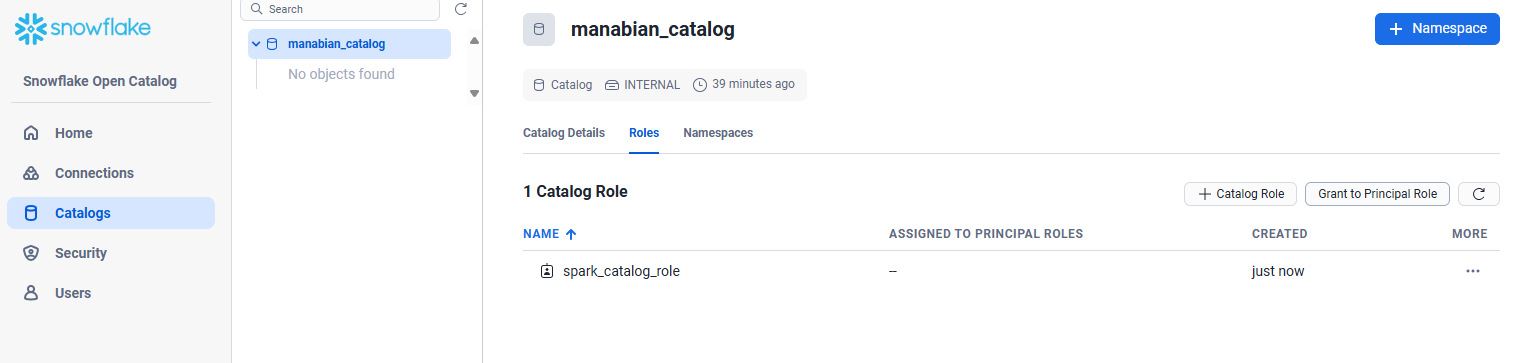
Catalogs -> 作成済みのカタログ -> Roles -> + Catalog Role を選択
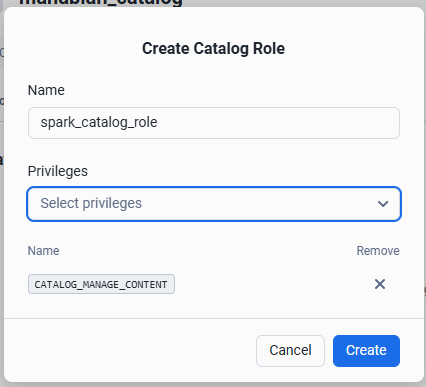
項目に値を設定して Create をクリック
| # | 項目 | 設定値例 |
|---|---|---|
| 1 | Name | spark_catalog_role |
| 2 | Privileges | CATALOG_MANAGE_CONTENT |
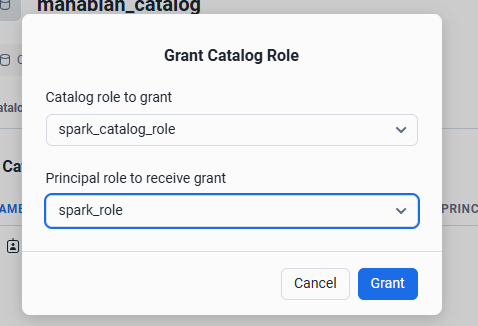
Grant to Principal Role を選択
項目を設定して Grant をクリック
| # | 項目 | 設定値例 |
|---|---|---|
| 1 | Catalog role to grant | spark_catalog_role |
| 2 | Catalog role to grant | spark_role |
Spark による Open Catalog のオブジェクト操作
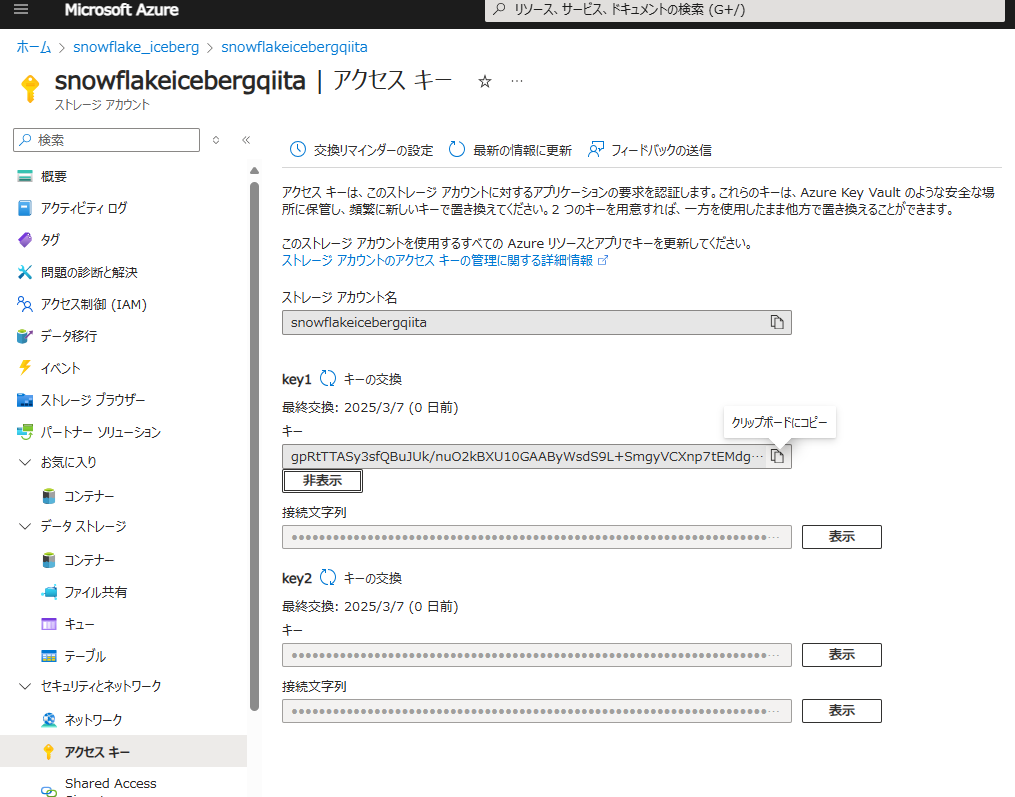
Azure Storage で アクセスキー タブにある key1 の値を取得
Google Colab のノートブックを作成
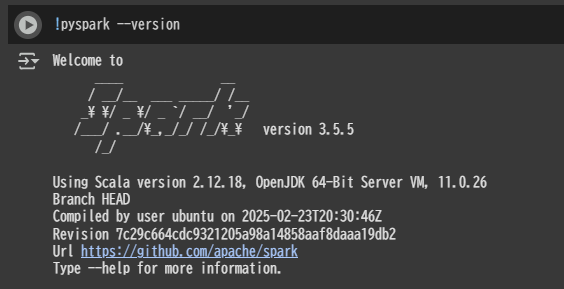
Spark のバージョンを確認
!pyspark --version
Snowflake Open Catalog の account_identifier を変数にセット
open_catalog_account_identifier = "mtirxwm-manabian_opencatalog_00_account"

account_identifier は管理画面の URL から確認できます。
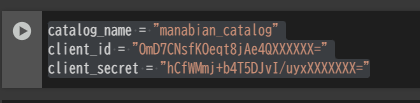
カタログ名と認証情報を変数にセット
catalog_name = "manabian_catalog"
client_id = "OmD7CNsfKOeqt8jAe4QXXXXXX="
client_secret = "hCfWMmj+b4T5DJvI/uyxXXXXXXX="
Azure Storage の名称とキーを変数にセット
# Azure Storage に関する情報をセット
azure_storage_account_name = "snowflakeicebergqiita"
azure_storage_account_key = "cBGfLSEInUgJ+e6w/bx7x4yewwOqDIIGE7sjPUMttki9CzXXXXXXXX=="

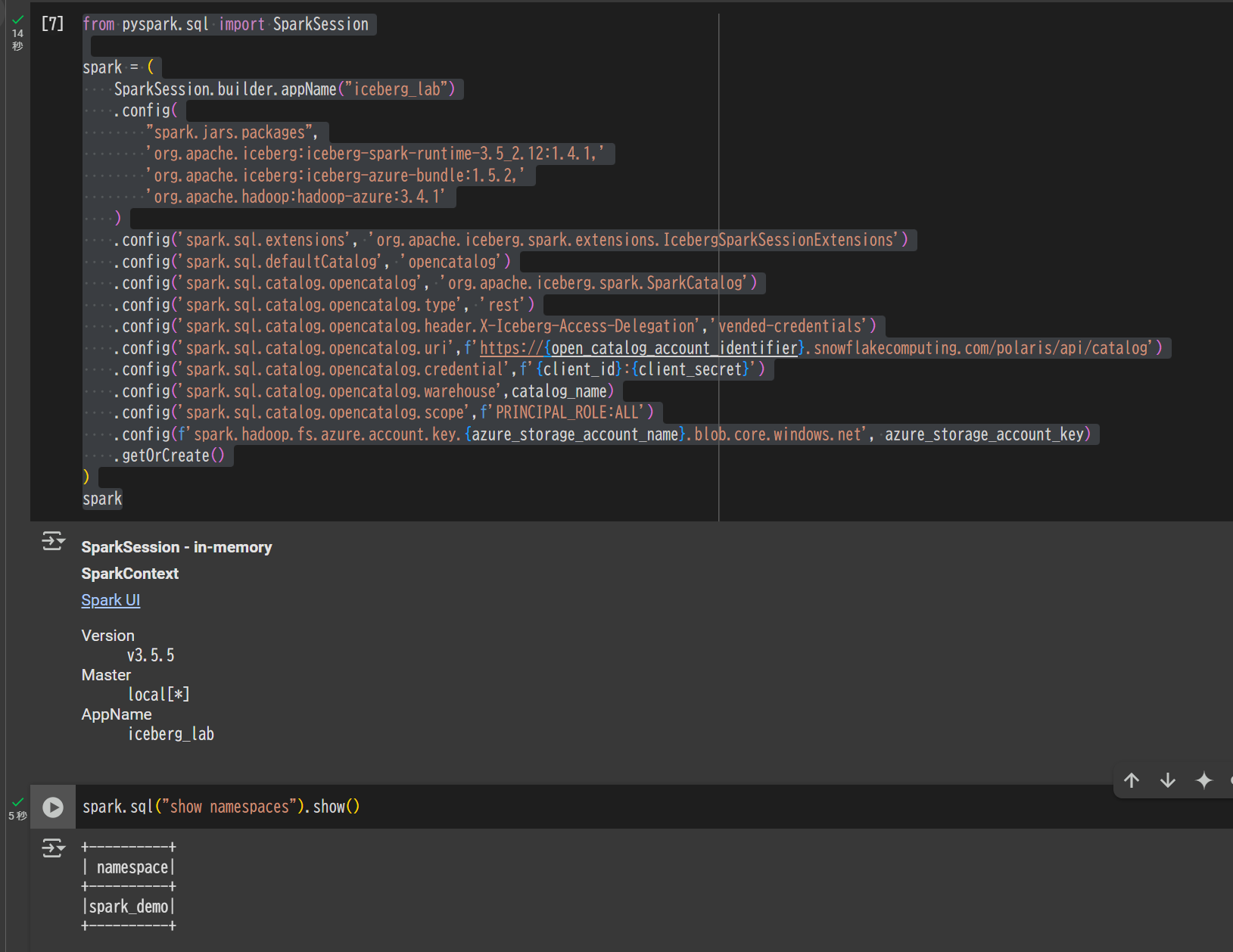
SparkSession の定義と疎通確認
from pyspark.sql import SparkSession
spark = (
SparkSession.builder.appName("iceberg_lab")
.config(
"spark.jars.packages",
'org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.1,'
'org.apache.iceberg:iceberg-azure-bundle:1.5.2,'
'org.apache.hadoop:hadoop-azure:3.4.1'
)
.config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions')
.config('spark.sql.defaultCatalog', 'opencatalog')
.config('spark.sql.catalog.opencatalog', 'org.apache.iceberg.spark.SparkCatalog')
.config('spark.sql.catalog.opencatalog.type', 'rest')
.config('spark.sql.catalog.opencatalog.header.X-Iceberg-Access-Delegation','vended-credentials')
.config('spark.sql.catalog.opencatalog.uri',f'https://{open_catalog_account_identifier}.snowflakecomputing.com/polaris/api/catalog')
.config('spark.sql.catalog.opencatalog.credential',f'{client_id}:{client_secret}')
.config('spark.sql.catalog.opencatalog.warehouse',catalog_name)
.config('spark.sql.catalog.opencatalog.scope',f'PRINCIPAL_ROLE:ALL')
.config(f'spark.hadoop.fs.azure.account.key.{azure_storage_account_name}.blob.core.windows.net', azure_storage_account_key)
.getOrCreate()
)
spark
spark.sql("show namespaces").show()
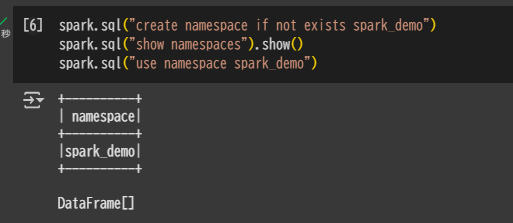
Namespace を作成
spark.sql("create namespace if not exists spark_demo")
spark.sql("show namespaces").show()
spark.sql("use namespace spark_demo")
Snowflake Open Catalog のウェブインターフェースにて、Namespace が作成されていることを確認します。
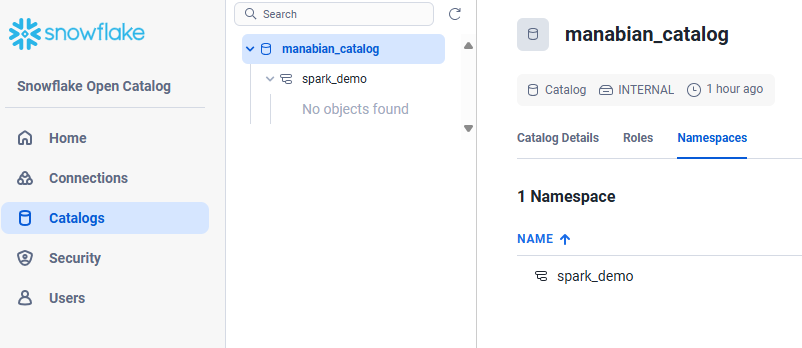
テーブルを作成
spark.sql("create or replace table test_table (col1 int) using iceberg");
spark.sql("show tables").show()
Snowflake Open Catalog のウェブインターフェースにて、テーブルが作成されていることを確認します。
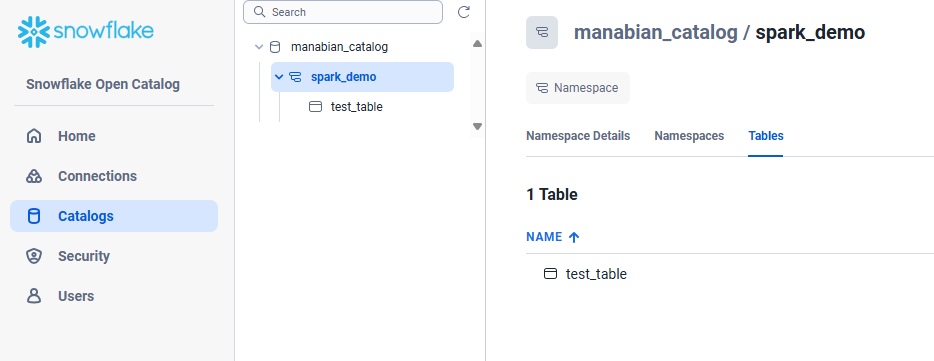
spark.sql("insert into test_table values (1)");

もしこの手順でエラーになる場合は、以下の記事を参考にしてください。
spark.table("test_table").show();
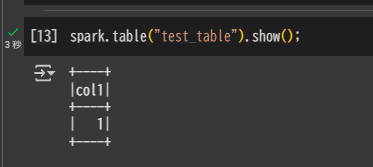
Snowflake アカウントへのテーブルの手動同期
Snowflake Open Catalog のカタログ統合を作成
-- 各値を変数としてセット
SET open_catalog_account_identifier = 'mtirxwm-manabian_opencatalog_00_account';
SET catalog_name = 'manabian_catalog';
SET namespace_name = 'spark_demo';
SET client_id = 'OmD7CNsfKOeqt8jAe4QXXXXXX=';
SET client_secret = 'hCfWMmj+b4T5DJvI/uyxXXXXXXX=';
-- 連結した URL は変数に事前に設定
SET full_catalog_uri = 'https://' || $open_catalog_account_identifier || '.snowflakecomputing.com/polaris/api/catalog';
-- 変数を利用してカタログ統合を作成
CREATE OR REPLACE CATALOG INTEGRATION demo_open_catalog_int
CATALOG_SOURCE = POLARIS
TABLE_FORMAT = ICEBERG
CATALOG_NAMESPACE = $namespace_name
REST_CONFIG = (
CATALOG_URI = $full_catalog_uri
WAREHOUSE = $catalog_name
)
REST_AUTHENTICATION = (
TYPE = OAUTH
OAUTH_CLIENT_ID = $client_id
OAUTH_CLIENT_SECRET = $client_secret
OAUTH_ALLOWED_SCOPES = ('PRINCIPAL_ROLE:ALL')
)
ENABLED = true;
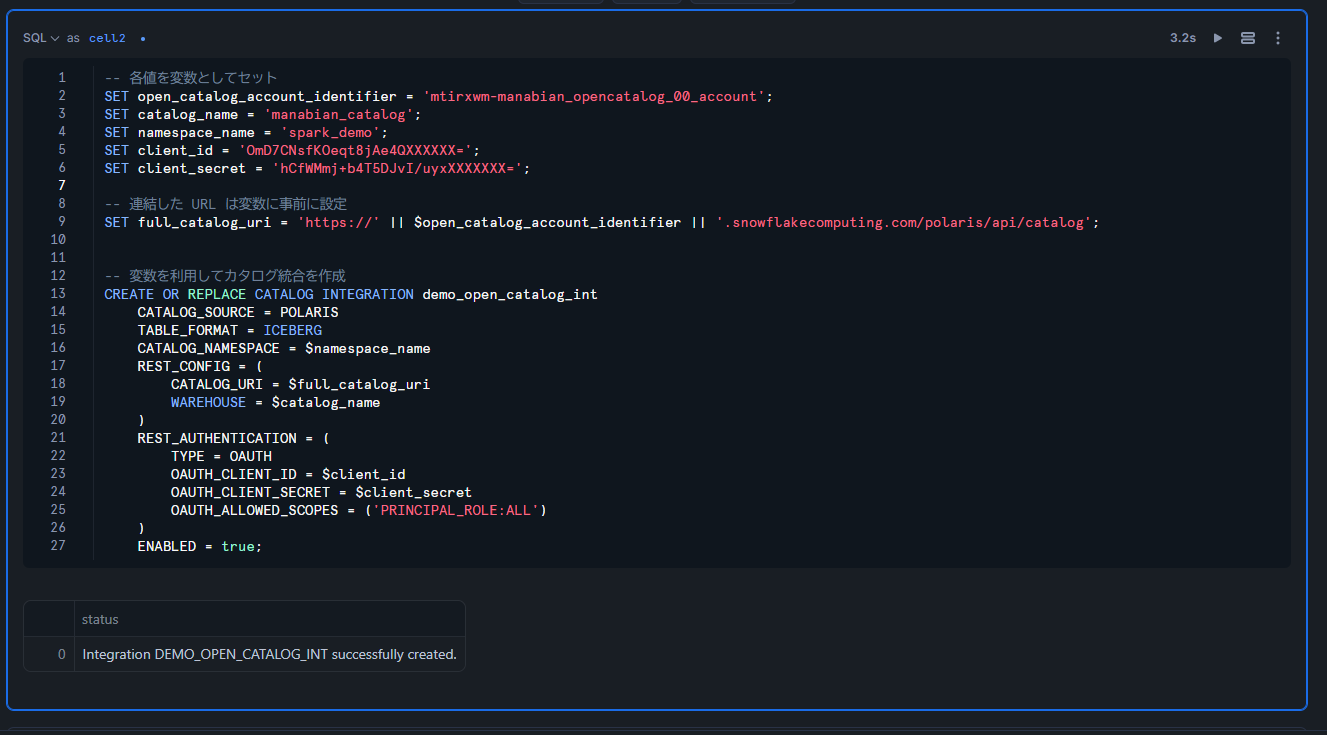
作成されたら確認します。
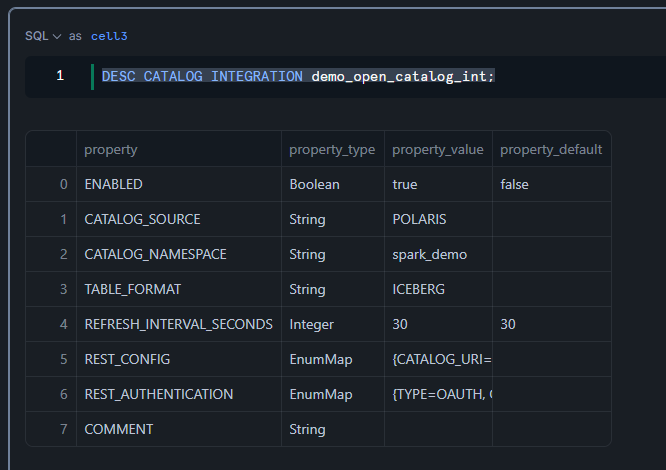
DESC CATALOG INTEGRATION demo_open_catalog_int;
外部 Volume を作成
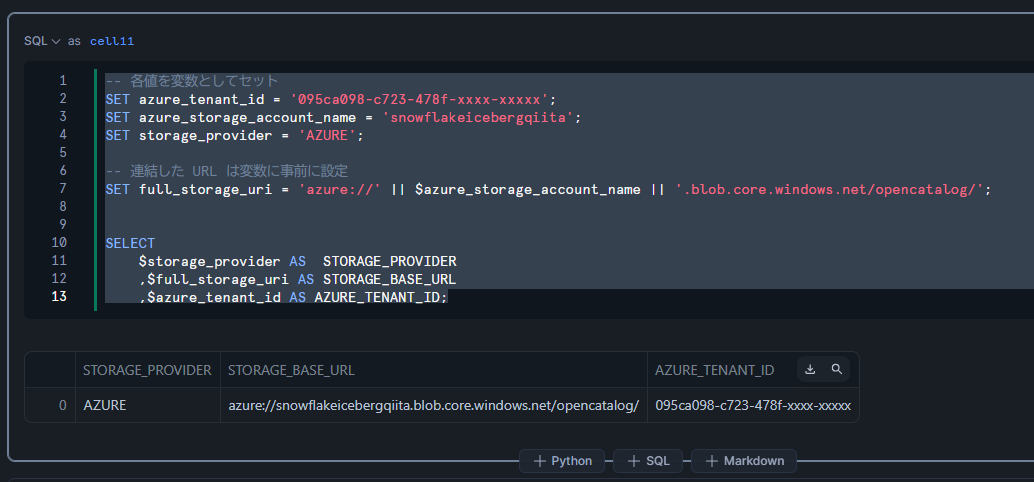
CREATE EXTERNAL VOLUME 文に変数を指定できないため、設定値を生成してコピー&ペーストする方法をとります。まずは必要な値を生成します。
-- 各値を変数としてセット
SET azure_tenant_id = '095ca098-c723-478f-xxxx-xxxxx';
SET azure_storage_account_name = 'snowflakeicebergqiita';
SET storage_provider = 'AZURE';
-- 連結した URL は変数に事前に設定
SET full_storage_uri = 'azure://' || $azure_storage_account_name || '.blob.core.windows.net/snowflake/opencatalog/';
SELECT
$storage_provider AS STORAGE_PROVIDER
,$full_storage_uri AS STORAGE_BASE_URL
,$azure_tenant_id AS AZURE_TENANT_ID;
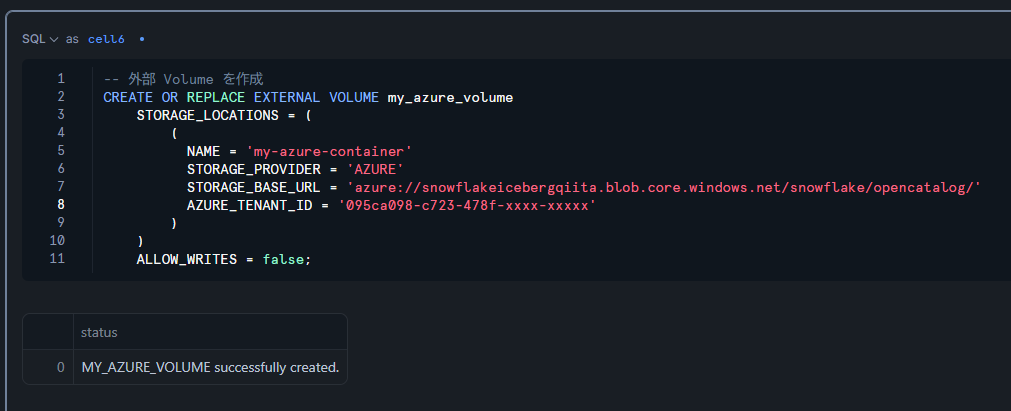
上記で取得した値を参考にしながら、以下の CREATE EXTERNAL VOLUME 文をコピー&ペーストして実行します。
-- 外部 Volume を作成
CREATE OR REPLACE EXTERNAL VOLUME my_azure_volume
STORAGE_LOCATIONS = (
(
NAME = 'my-azure-container'
STORAGE_PROVIDER = 'AZURE'
STORAGE_BASE_URL = 'azure://snowflakeicebergqiita.blob.core.windows.net/snowflake/opencatalog/'
AZURE_TENANT_ID = '095ca098-c723-478f-xxxx-xxxxx'
)
)
ALLOW_WRITES = false;
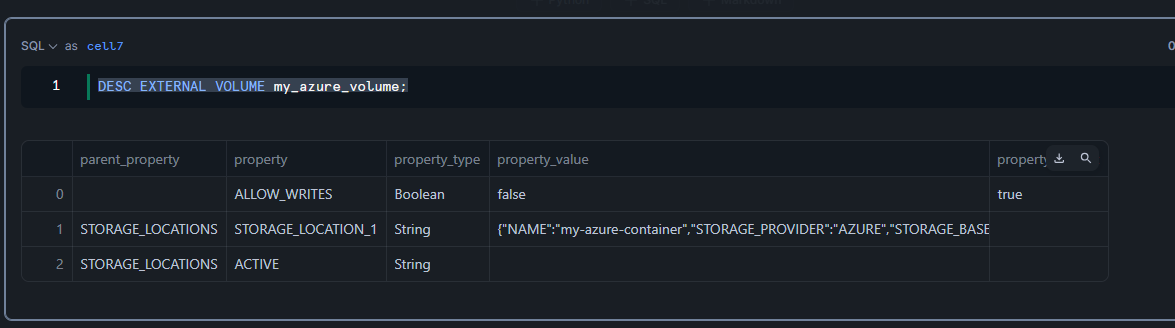
作成を確認します。
DESC EXTERNAL VOLUME my_azure_volume;
外部 Volume に対する権限の付与
AZURE_CONSENT_URL の URL を Azure にログインしているブラウザでアクセスします。
DESC EXTERNAL VOLUME my_azure_volume;
SELECT
PARSE_JSON($4):AZURE_MULTI_TENANT_APP_NAME::string AS AZURE_MULTI_TENANT_APP_NAME,
PARSE_JSON($4):AZURE_CONSENT_URL::string AS AZURE_CONSENT_URL
FROM TABLE(RESULT_SCAN(LAST_QUERY_ID()))
WHERE $2 = 'STORAGE_LOCATION_1';
承諾を選択します。
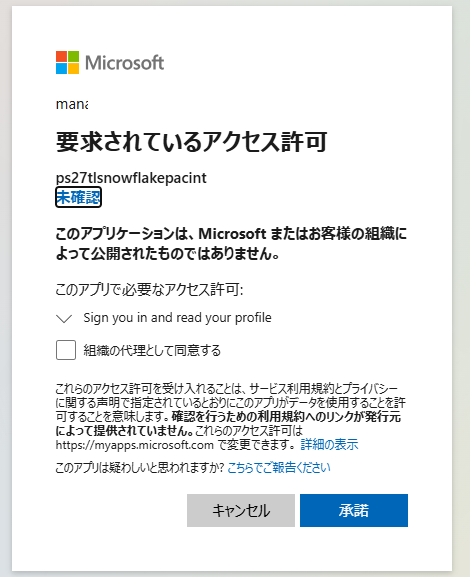
Azure Storage 側で、AZURE_MULTI_TENANT_APP_NAME のアンダーバーより前のアプリケーション(例:ps27tlsnowflakepacint)に対して権限を付与します。
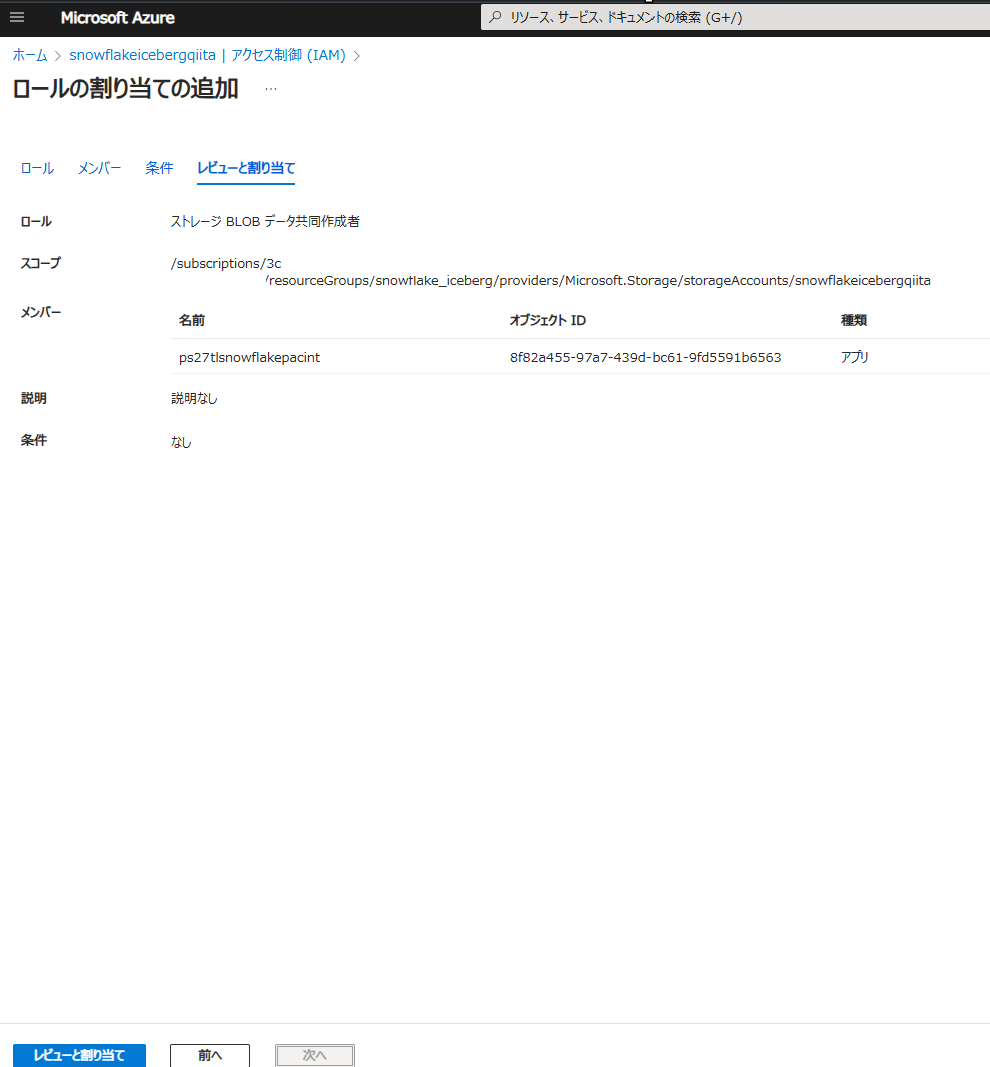
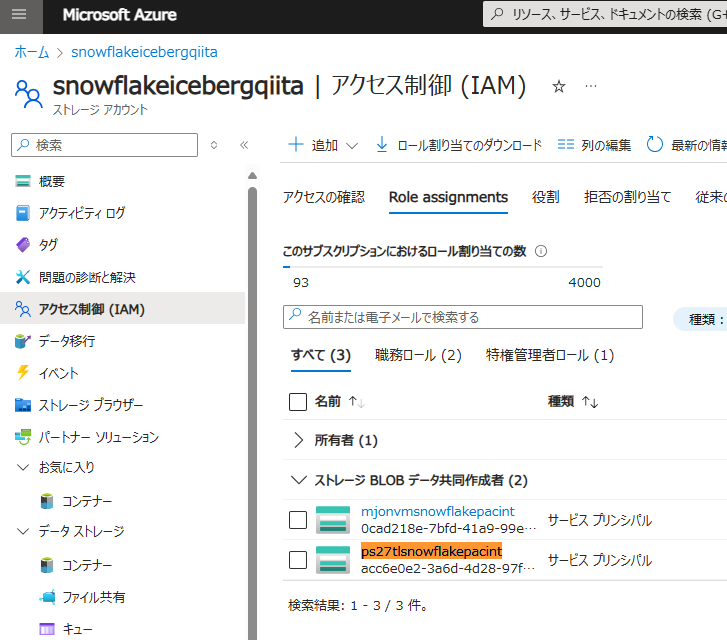
検証用のデータベースを作成
CREATE OR REPLACE DATABASE OPEN_CATALOG_TUTORIAL_DB;
USE DATABASE OPEN_CATALOG_TUTORIAL_DB;
5 分程度待機してから Iceberg テーブルを作成
create or replace iceberg table test_table
catalog = 'demo_open_catalog_int'
external_volume = 'my_azure_volume'
catalog_table_name = 'test_table';
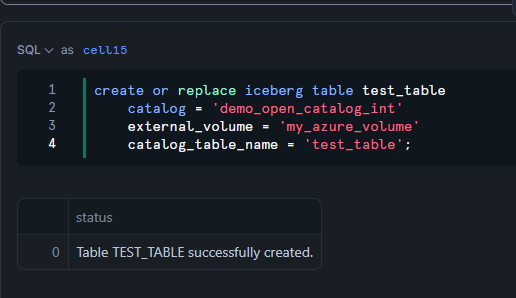
Iceberg テーブルに対するクエリを実行
SELECT
*
FROM
test_table;
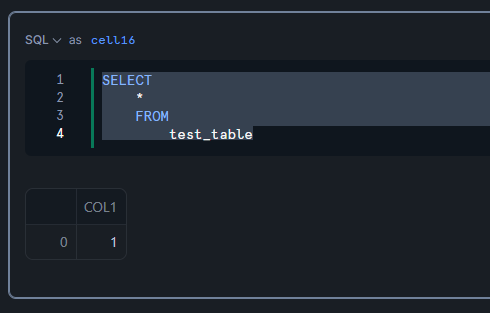
Iceberg テーブルに対する REFRESH の実行
Spark(Google Colab)から書き込みを実行します。
spark.sql("use namespace spark_demo")
spark.sql("insert into test_table values (2)");
spark.table("test_table").show();
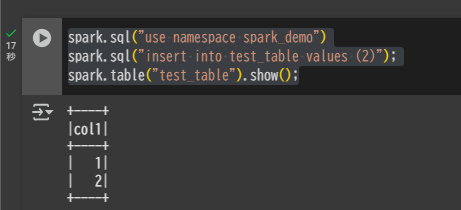
Snowflake 側ではすぐには新しいデータが反映されません。これはメタデータの情報がまだ同期されていないためです。
SELECT
*
FROM
test_table;
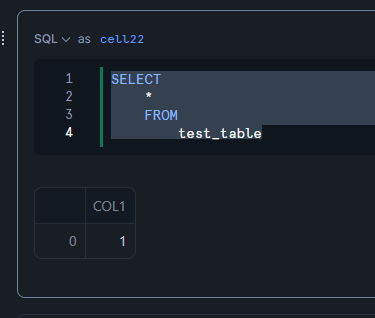
テーブルに対して REFRESH を実行し、データが更新されることを確認します。
ALTER ICEBERG TABLE test_table REFRESH;
SELECT
*
FROM
test_table;
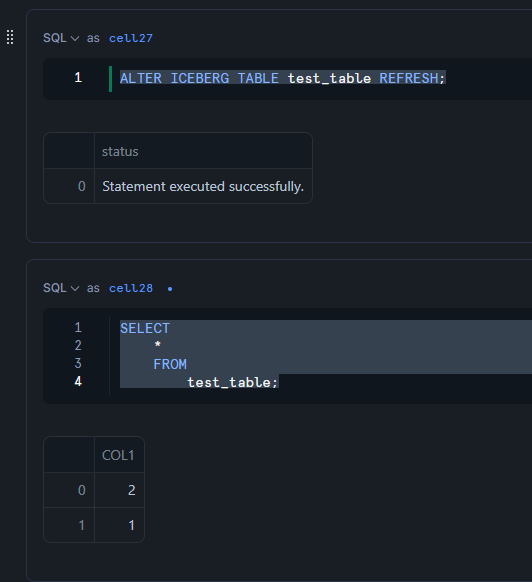
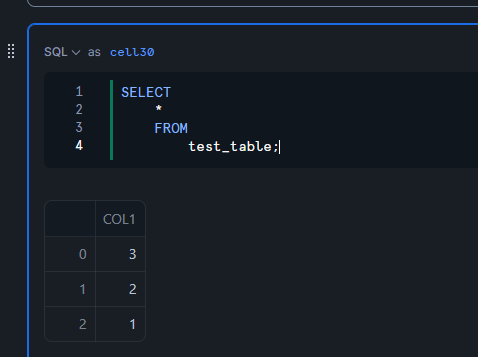
Iceberg テーブルに対する 自動 REFRESH 設定の実施
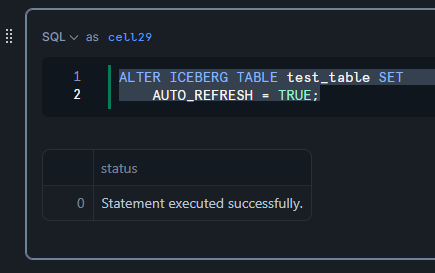
Iceberg テーブルの AUTO_REFRESH オプションを TRUE に設定します。
ALTER ICEBERG TABLE test_table SET
AUTO_REFRESH = TRUE;
Spark(Google Colab)からデータの書き込みを再度実行します。
spark.sql("use namespace spark_demo")
spark.sql("insert into test_table values (3)");
spark.table("test_table").show();
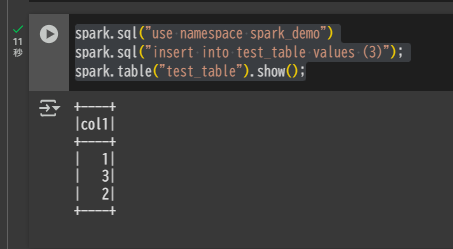
Snowflake 側でクエリを実行すると、自動で 3 のレコードが反映されていることを確認できます。
SELECT
*
FROM
test_table;