概要
Databricks のサンプルデータセットの1つである TPC-H のデータから、Spark データフレームを作成する方法を共有します。
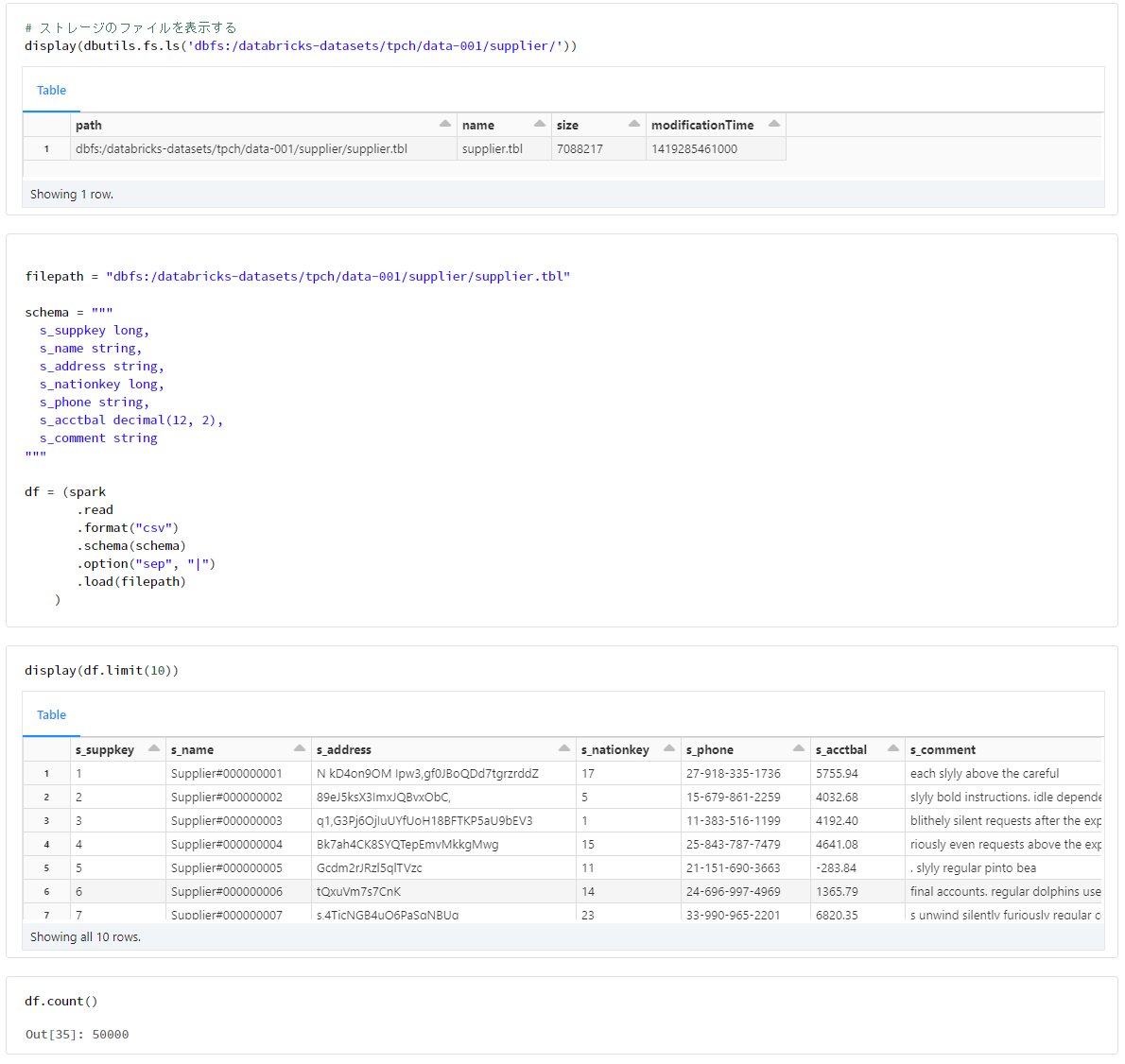
# ストレージのファイルを表示する
display(dbutils.fs.ls('dbfs:/databricks-datasets/tpch/data-001'))
path_to_md = "dbfs:/databricks-datasets/tpch/README.md"
displayHTML("<pre>" + dbutils.fs.head(path_to_md) + "</pre>")
path_to_md = "dbfs:/databricks-datasets/tpch/data-001/README.md"
displayHTML("<pre>" + dbutils.fs.head(path_to_md) + "</pre>")
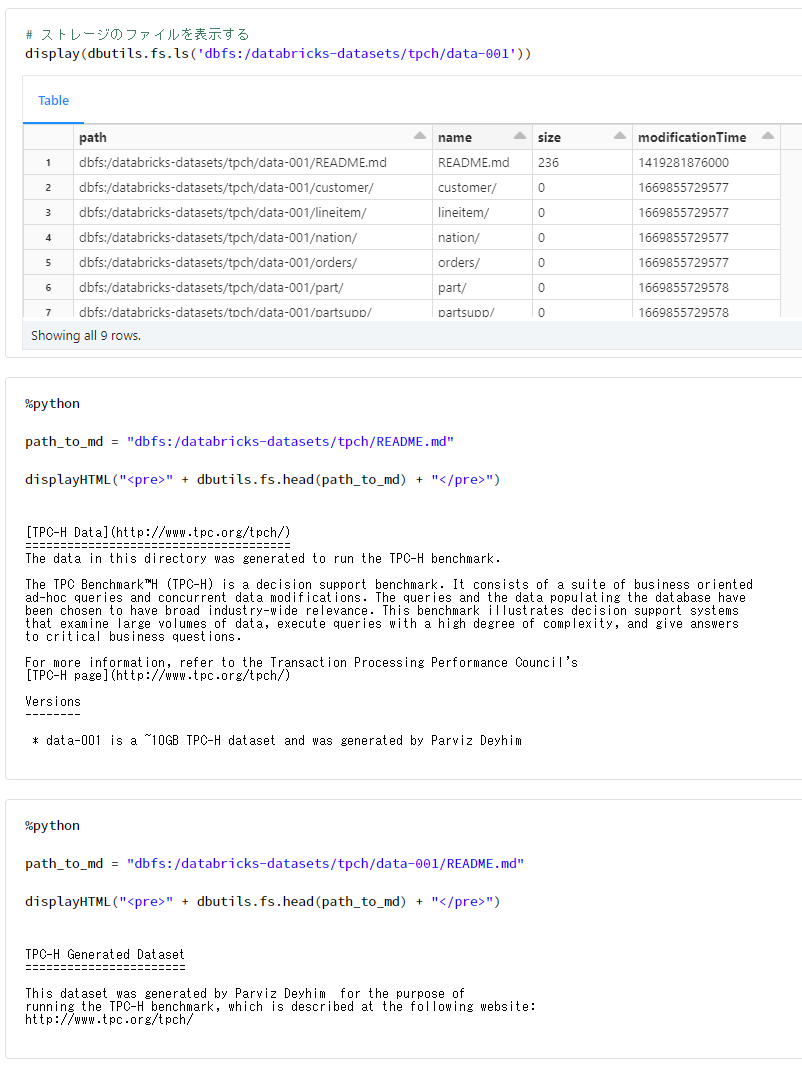
TPC-H がどういったものであるかは、下記の記事で整理しております。
データベースの性能検証に利用されるTPC-HとTPC-DSに関するざっくりとした整理 - Qiita
データフレームの作成方法
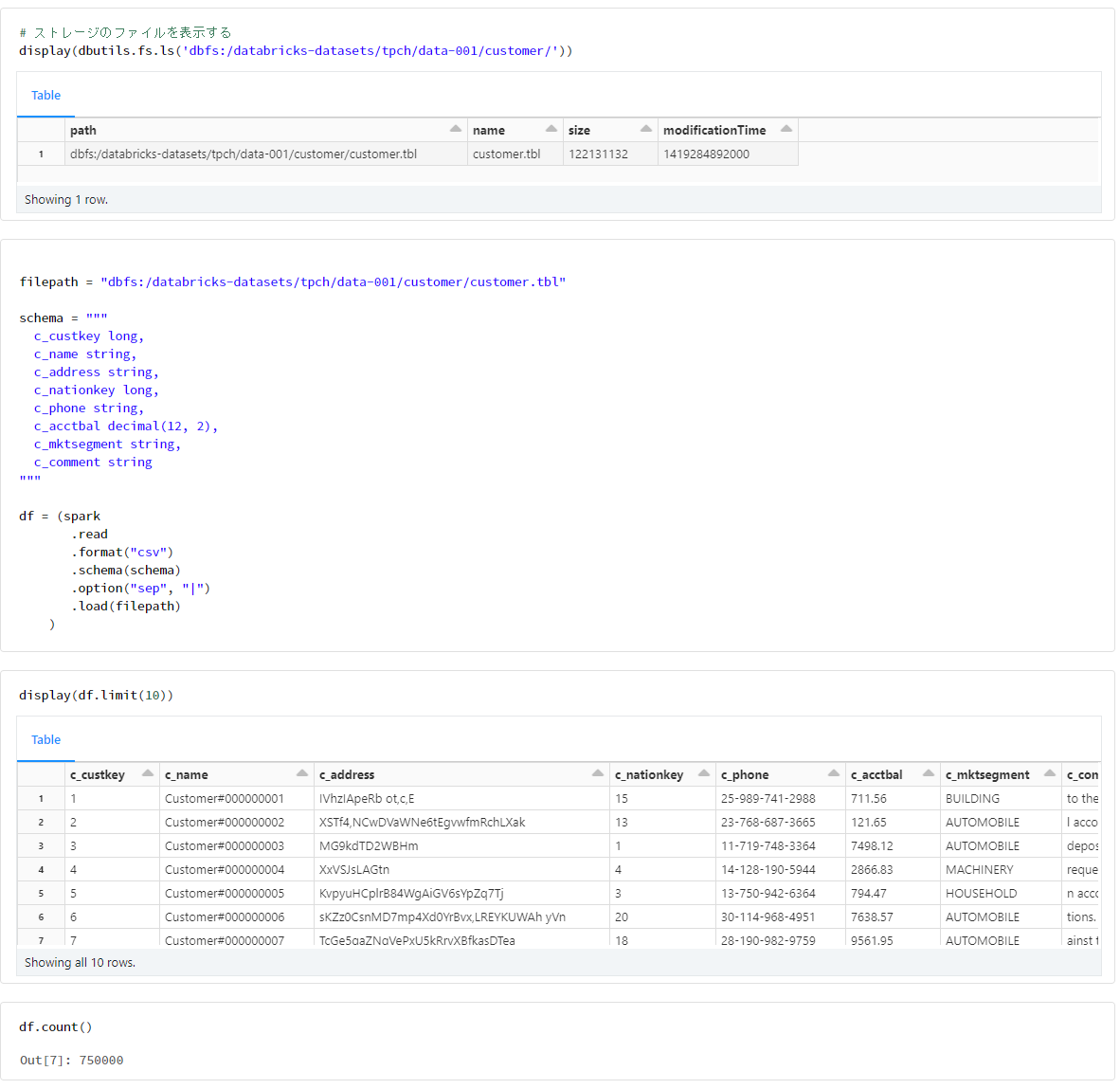
customer
filepath = "dbfs:/databricks-datasets/tpch/data-001/customer/customer.tbl"
schema = """
c_custkey long,
c_name string,
c_address string,
c_nationkey long,
c_phone string,
c_acctbal decimal(12, 2),
c_mktsegment string,
c_comment string
"""
df = (spark
.read
.format("csv")
.schema(schema)
.option("sep", "|")
.load(filepath)
)
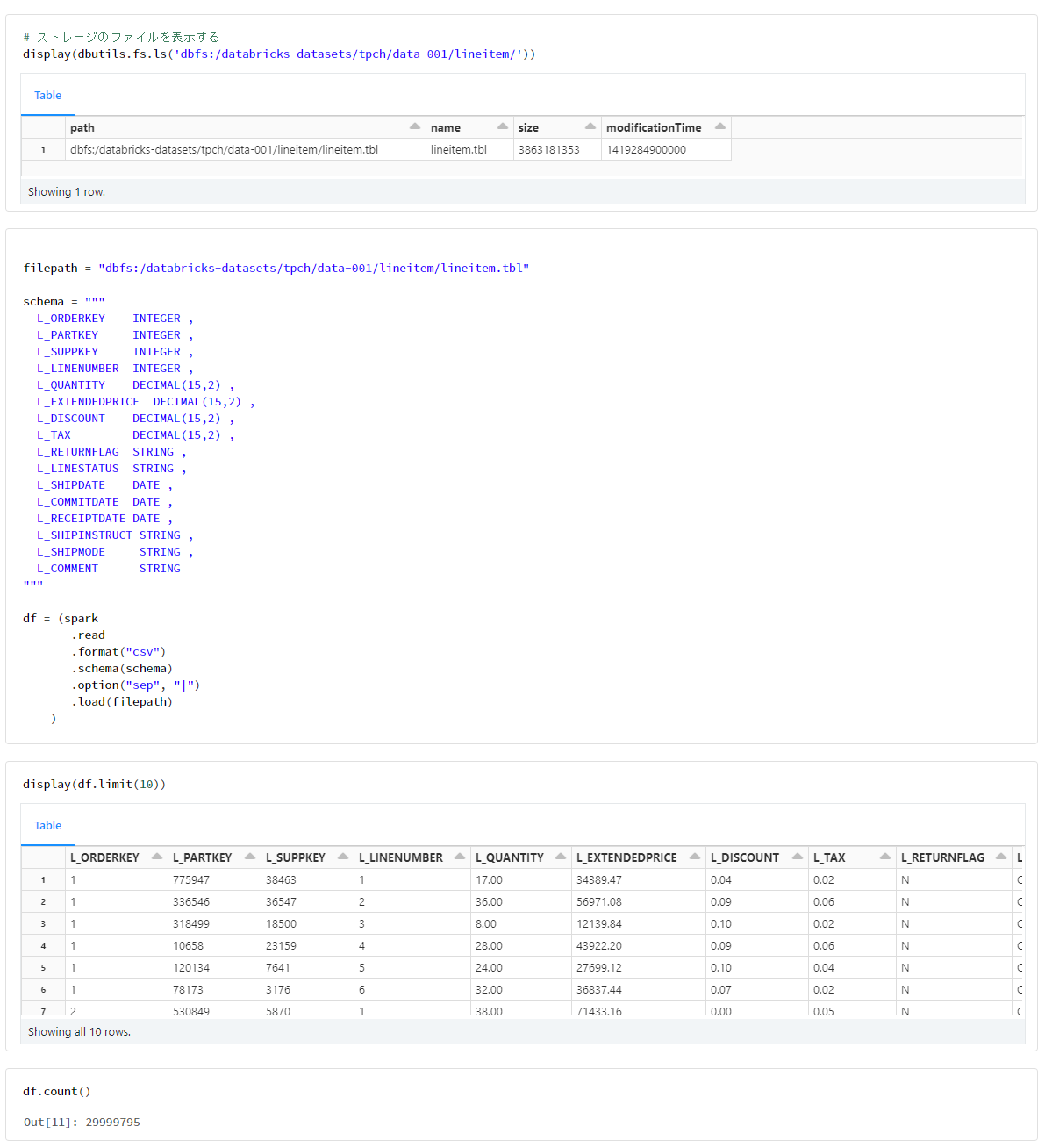
lineitem
filepath = "dbfs:/databricks-datasets/tpch/data-001/lineitem/lineitem.tbl"
schema = """
l_orderkey integer ,
l_partkey integer ,
l_suppkey integer ,
l_linenumber integer ,
l_quantity decimal(15,2) ,
l_extendedprice decimal(15,2) ,
l_discount decimal(15,2) ,
l_tax decimal(15,2) ,
l_returnflag string ,
l_linestatus string ,
l_shipdate date ,
l_commitdate date ,
l_receiptdate date ,
l_shipinstruct string ,
l_shipmode string ,
l_comment string
"""
df = (spark
.read
.format("csv")
.schema(schema)
.option("sep", "|")
.load(filepath)
)
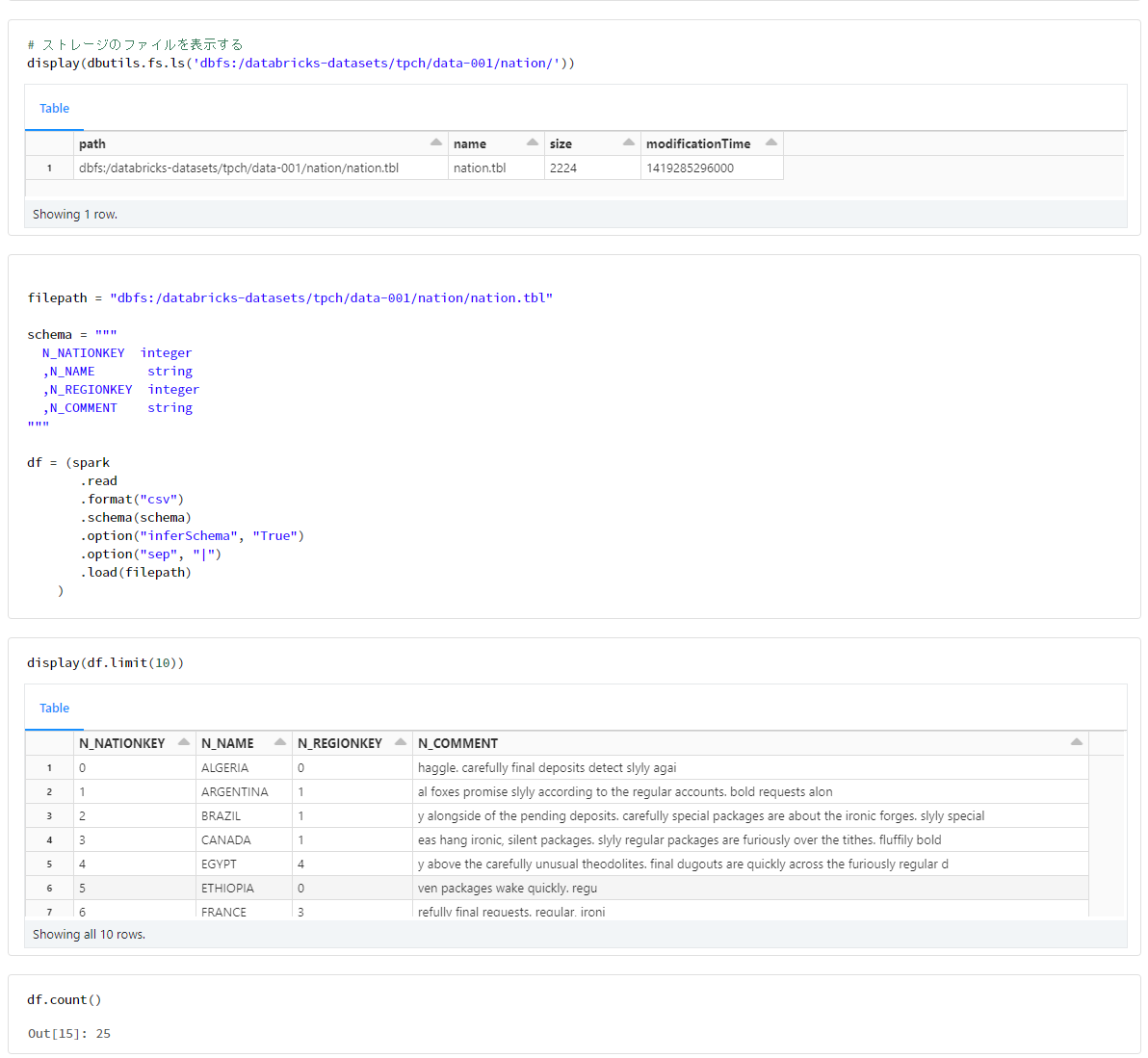
nation
filepath = "dbfs:/databricks-datasets/tpch/data-001/nation/nation.tbl"
schema = """
n_nationkey integer
,n_name string
,n_regionkey integer
,n_comment string
"""
df = (spark
.read
.format("csv")
.schema(schema)
.option("inferSchema", "True")
.option("sep", "|")
.load(filepath)
)
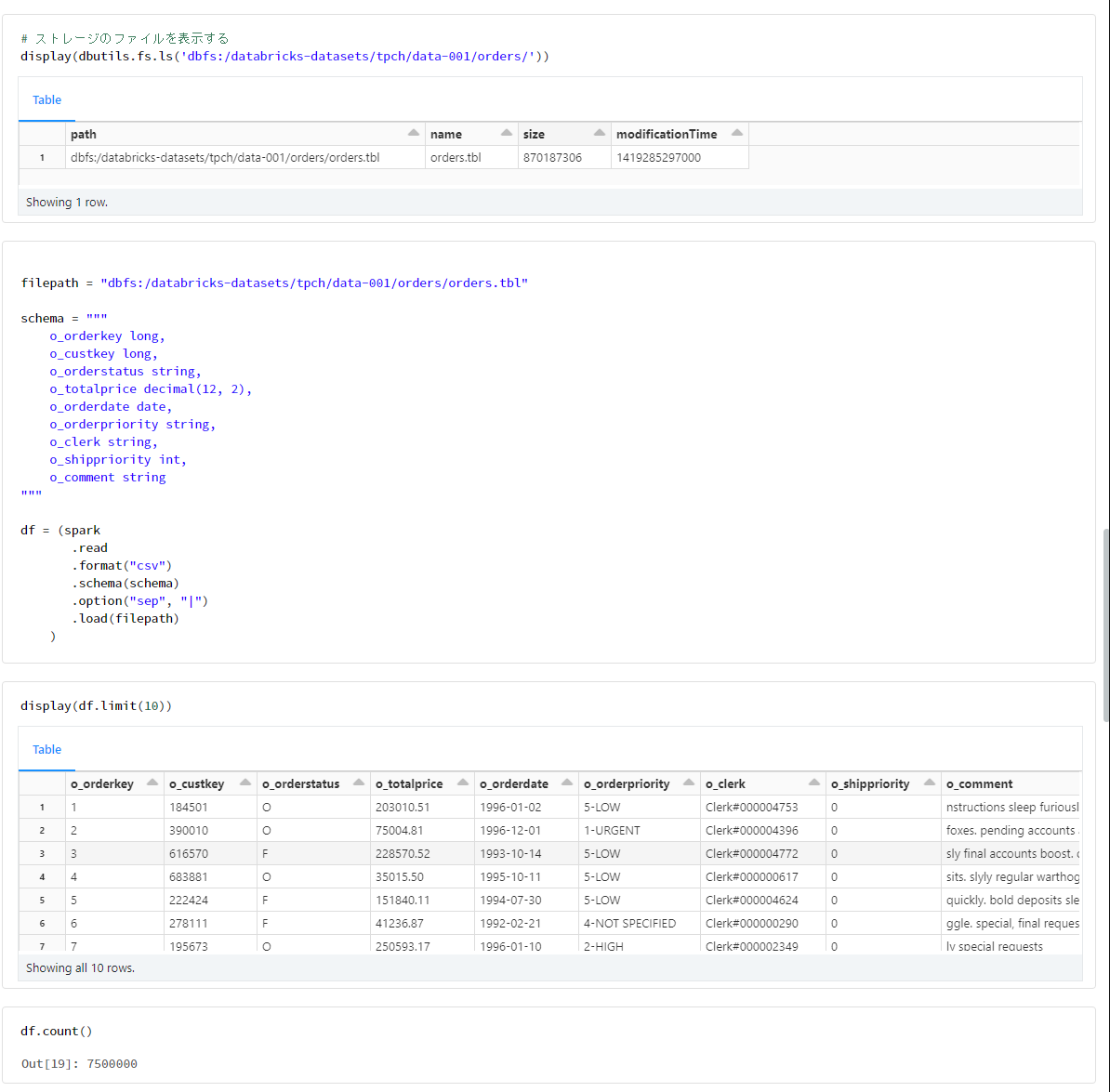
orders
filepath = "dbfs:/databricks-datasets/tpch/data-001/orders/orders.tbl"
schema = """
o_orderkey long,
o_custkey long,
o_orderstatus string,
o_totalprice decimal(12, 2),
o_orderdate date,
o_orderpriority string,
o_clerk string,
o_shippriority int,
o_comment string
"""
df = (spark
.read
.format("csv")
.schema(schema)
.option("sep", "|")
.load(filepath)
)
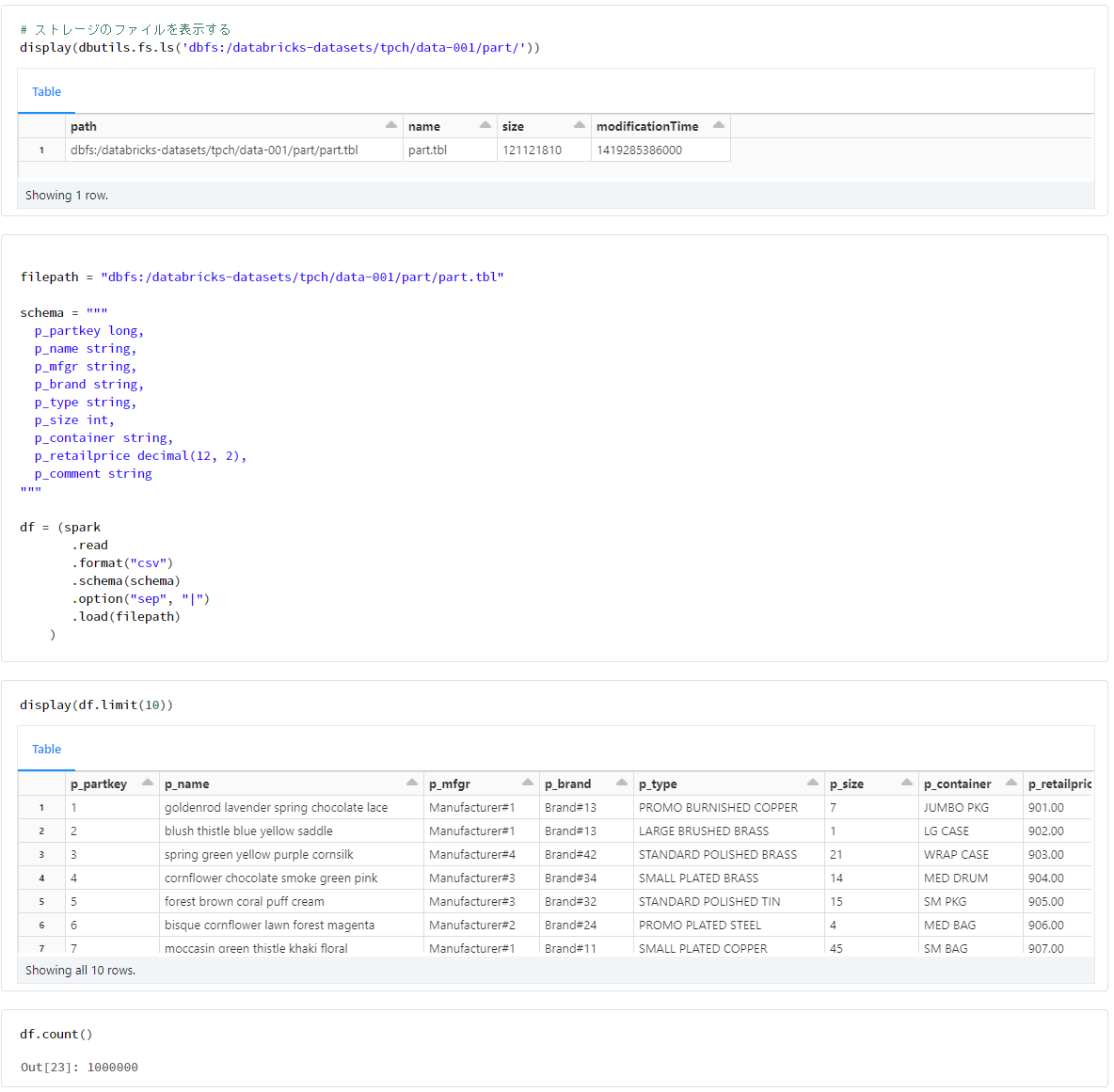
part
filepath = "dbfs:/databricks-datasets/tpch/data-001/part/part.tbl"
schema = """
p_partkey long,
p_name string,
p_mfgr string,
p_brand string,
p_type string,
p_size int,
p_container string,
p_retailprice decimal(12, 2),
p_comment string
"""
df = (spark
.read
.format("csv")
.schema(schema)
.option("sep", "|")
.load(filepath)
)
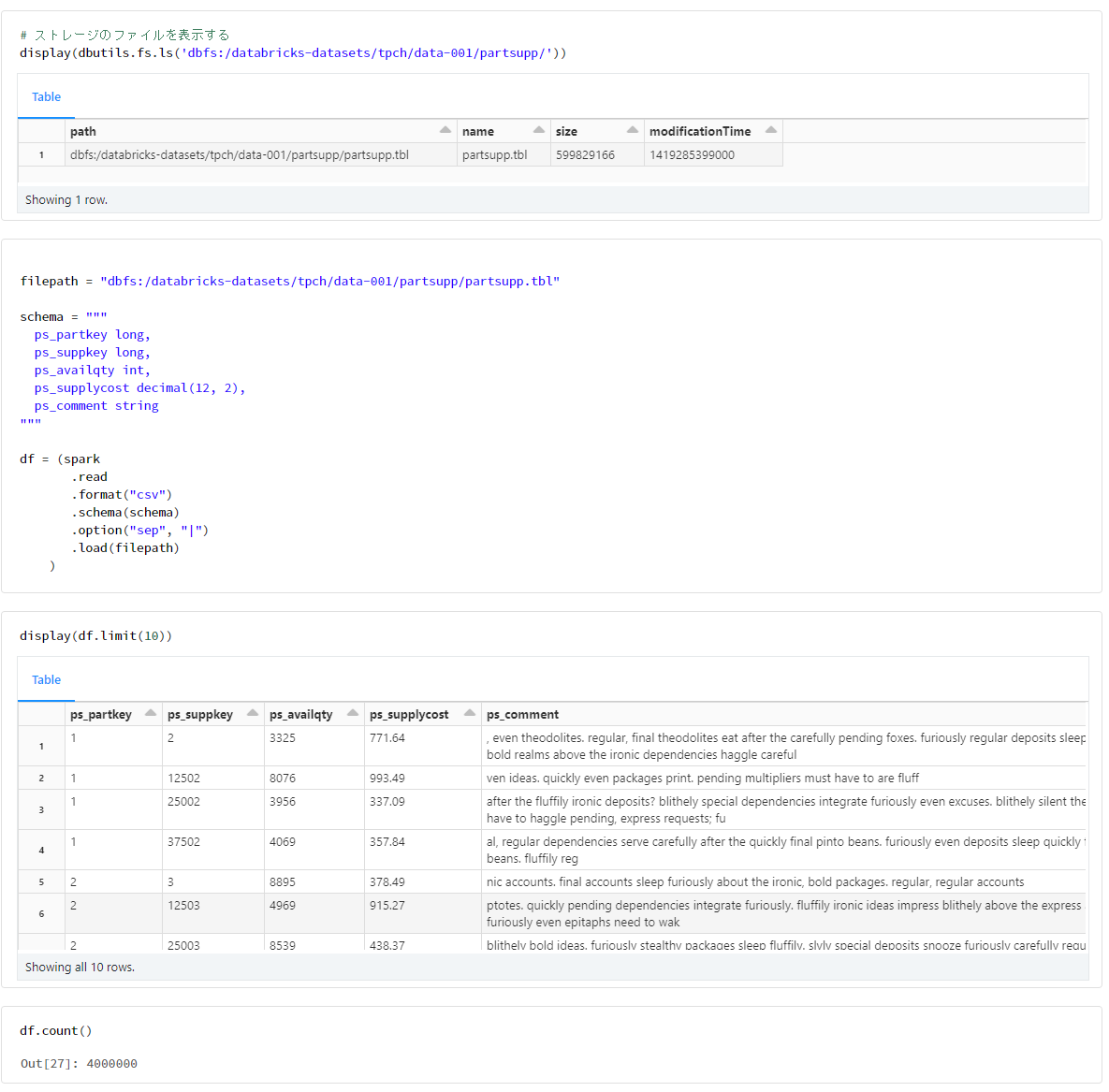
partsupp
filepath = "dbfs:/databricks-datasets/tpch/data-001/partsupp/partsupp.tbl"
schema = """
ps_partkey long,
ps_suppkey long,
ps_availqty int,
ps_supplycost decimal(12, 2),
ps_comment string
"""
df = (spark
.read
.format("csv")
.schema(schema)
.option("sep", "|")
.load(filepath)
)
region
filepath = "dbfs:/databricks-datasets/tpch/data-001/region/region.tbl"
schema = """
r_regionkey long,
r_name string,
r_comment string
"""
df = (spark
.read
.format("csv")
.schema(schema)
.option("sep", "|")
.load(filepath)
)
supplier
filepath = "dbfs:/databricks-datasets/tpch/data-001/supplier/supplier.tbl"
schema = """
s_suppkey long,
s_name string,
s_address string,
s_nationkey long,
s_phone string,
s_acctbal decimal(12, 2),
s_comment string
"""
df = (spark
.read
.format("csv")
.schema(schema)
.option("sep", "|")
.load(filepath)
)