概要
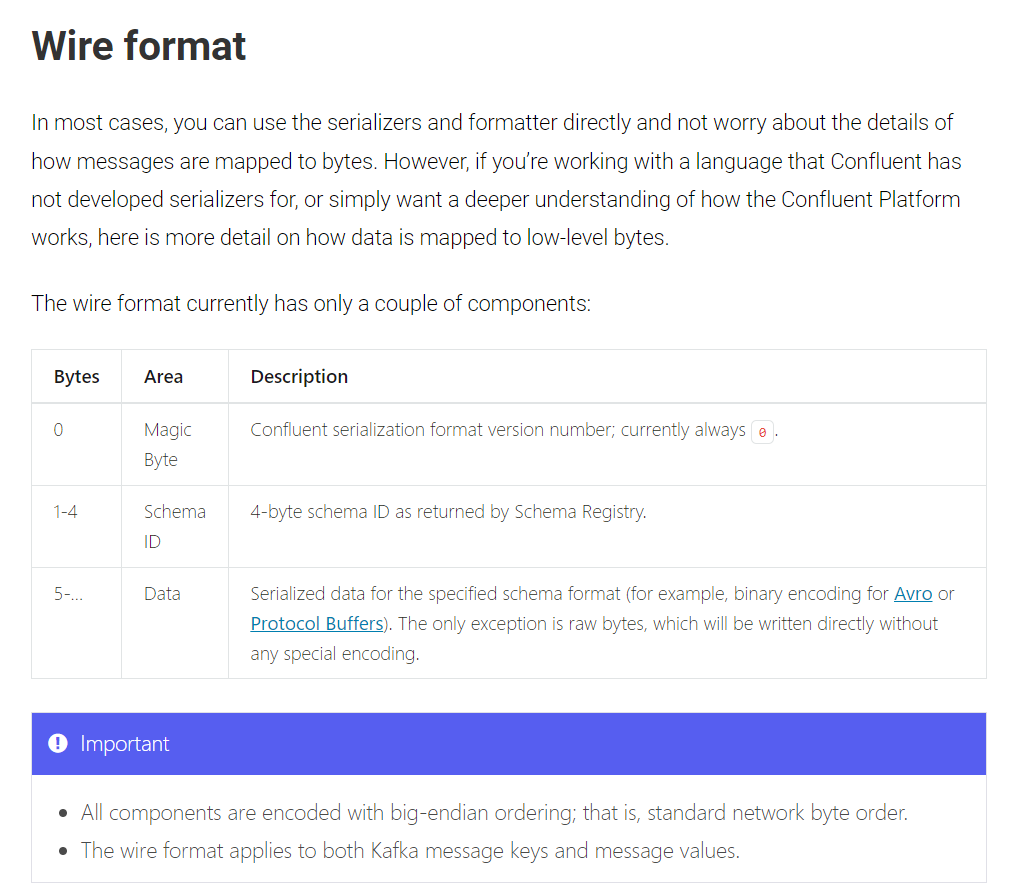
Databricks で Confluent から Avro 形式のデータを読み込む際に発生する MALFORMED_AVRO_MESSAGE エラーへの対処方法を共有します。本エラーはデータ型の不一致だけでなく、Confluent が生成するバイナリ形式の仕様が原因となる場合もあります。Confluent が生成するバイナリは、先頭 5 バイトに Magic Byte と Schema ID が格納されているため、手動でバイナリをデシリアライズする際にはこの 5 バイトを除去する必要があります。本記事では、その具体的な対応手順を解説します。
org.apache.spark.SparkException: [MALFORMED_AVRO_MESSAGE] Malformed Avro messages are detected in message deserialization. Parse Mode: FAILFAST. To process malformed Avro message as null result, try setting the option 'mode' as 'PERMISSIVE'. SQLSTATE: KD000
エラーの再現方法と対応方法
1. 事前準備
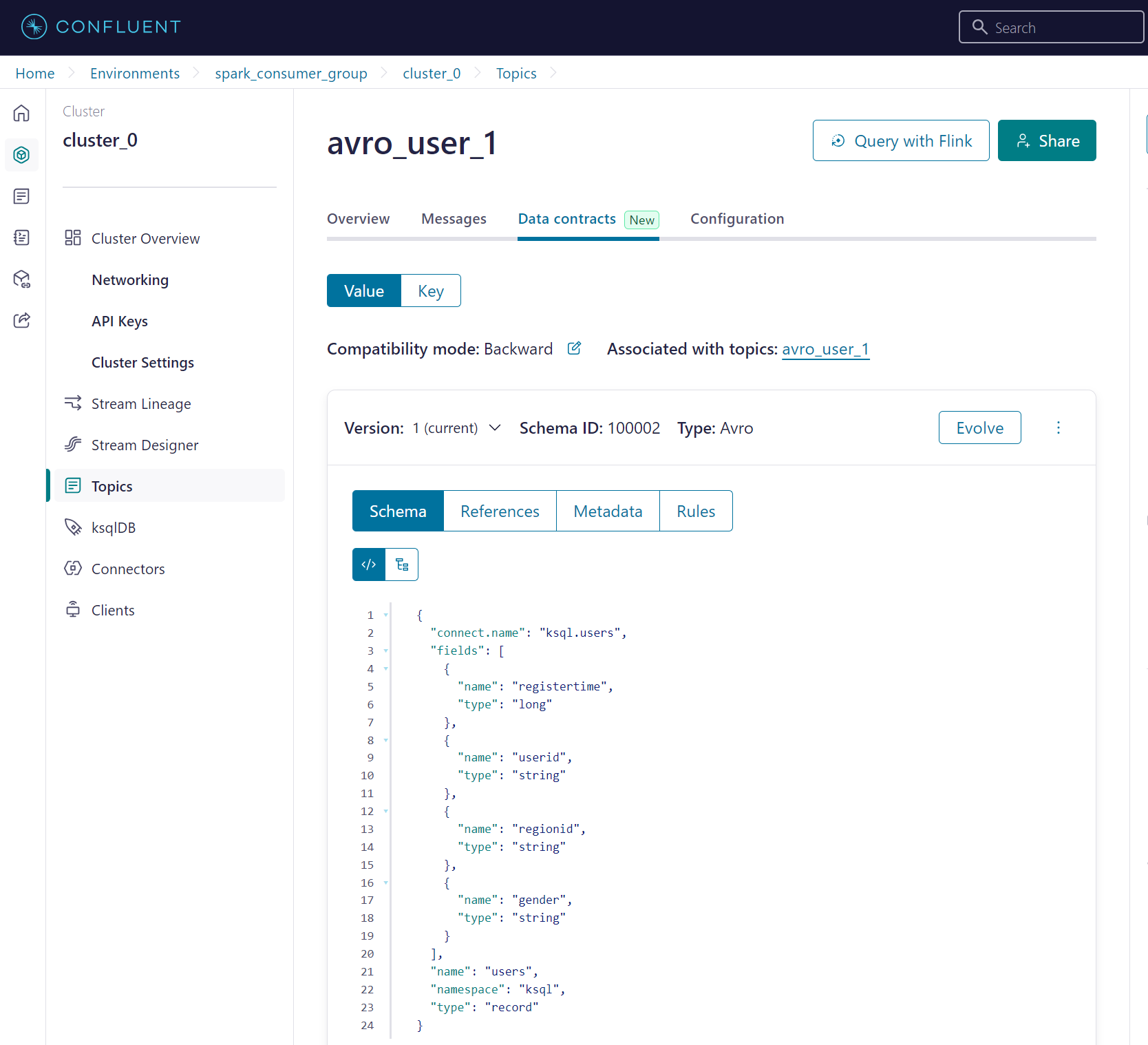
Confluent にて Avro 形式の Topic を準備
{
"connect.name": "ksql.users",
"fields": [
{
"name": "registertime",
"type": "long"
},
{
"name": "userid",
"type": "string"
},
{
"name": "regionid",
"type": "string"
},
{
"name": "gender",
"type": "string"
}
],
"name": "users",
"namespace": "ksql",
"type": "record"
}
Databricks にて Confluent に対する認証情報をセット
# Confluent に対する認証情報をセット
bootstrap_servers = "pkc-921aa.us-east-2.aws.confluent.cloud:9092"
sasl_username = "U4BML4OPRCaaaa"
sasl_password = "zzEjUzyUwYYJneNE240L7jgPVrHAtRBANo6wnnzCgKlGIJ9OxJqaJZWRvaaaaa"

Databricks にて Topic とスキーマをセット
topic_name = "avro_user_1"
schema = """
{
"connect.name": "ksql.users",
"fields": [
{
"name": "registertime",
"type": "long"
},
{
"name": "userid",
"type": "string"
},
{
"name": "regionid",
"type": "string"
},
{
"name": "gender",
"type": "string"
}
],
"name": "users",
"namespace": "ksql",
"type": "record"
}
"""

Confluent を参照したデータフレームを定義
# Confluetn から読み込み
df = (
spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", bootstrap_servers)
.option("kafka.security.protocol", "SASL_SSL")
.option(
"kafka.sasl.jaas.config",
f'kafkashaded.org.apache.kafka.common.security.plain.PlainLoginModule required username="{sasl_username}" password="{sasl_password}";',
)
.option("kafka.sasl.mechanism", "PLAIN")
.option("subscribe", topic_name)
.option("startingOffsets", "earliest")
.load()
)

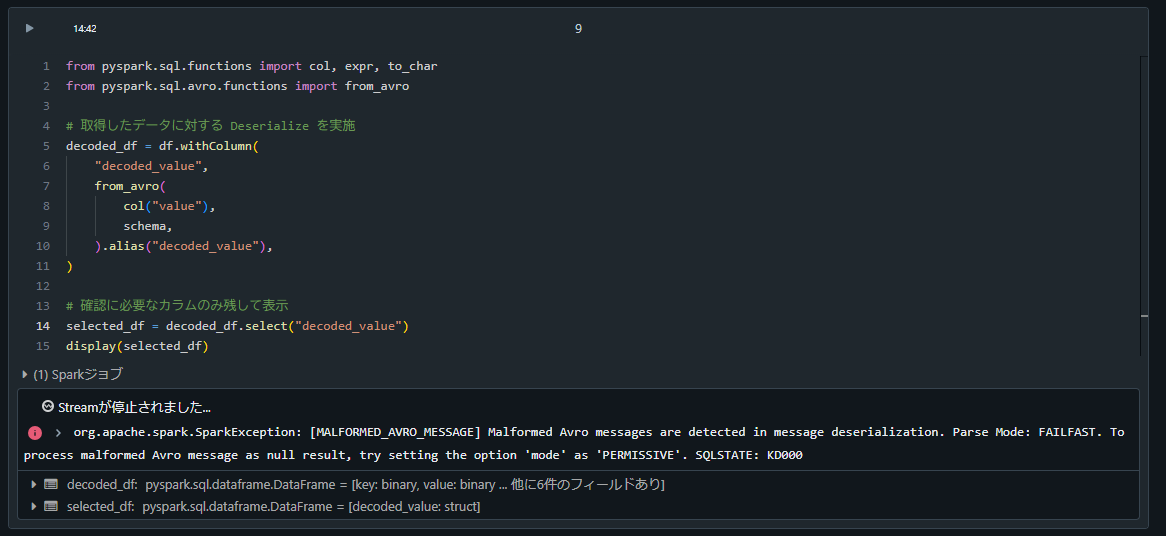
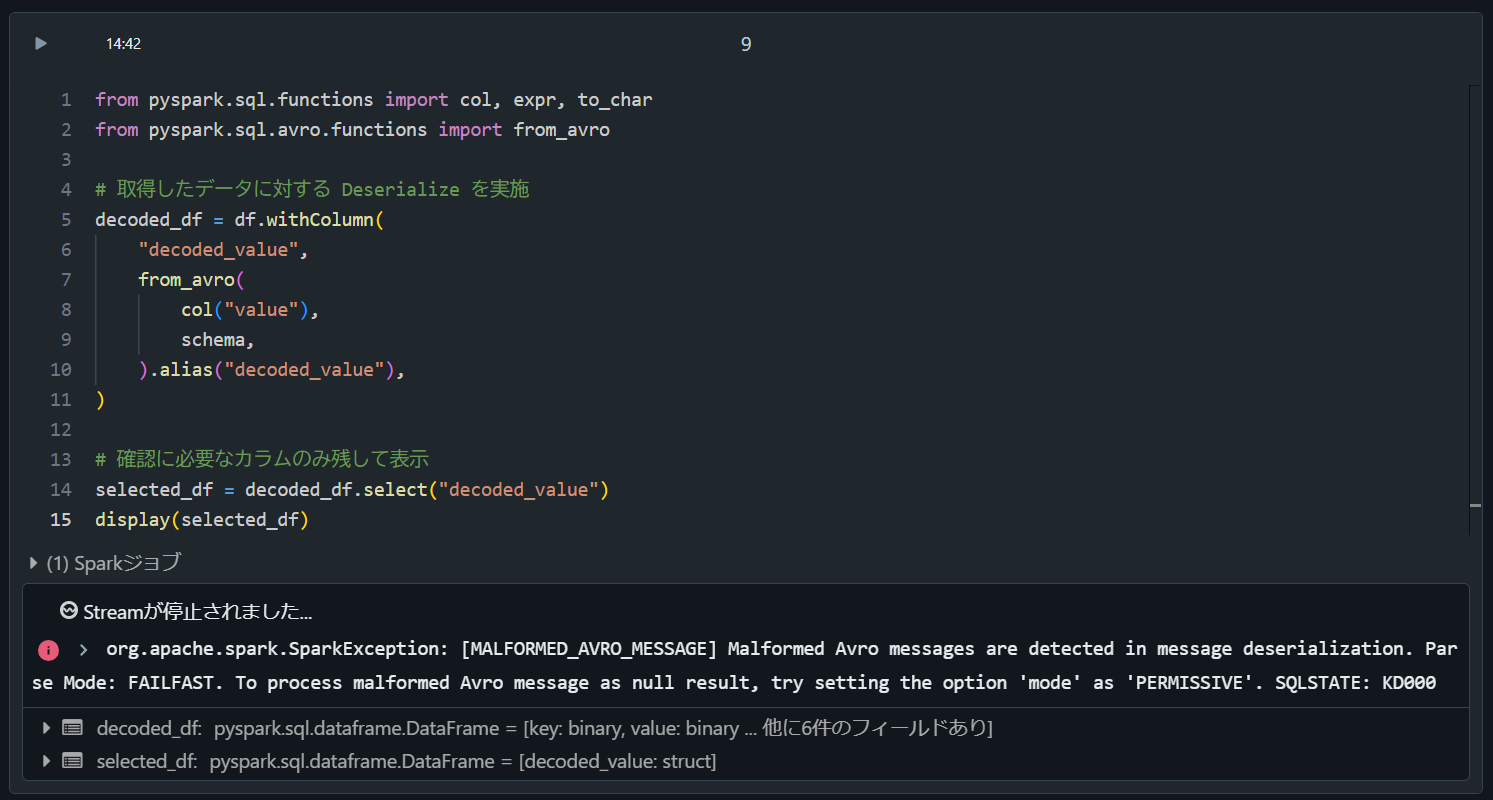
エラーの再現方法
from pyspark.sql.functions import col, expr, to_char
from pyspark.sql.avro.functions import from_avro
# 取得したデータに対する Deserialize を実施
decoded_df = df.withColumn(
"value",
from_avro(
col("value_no_magic"),
schema,
).alias("decoded_value"),
)
# 確認に必要なカラムのみ残して表示
selected_df = decoded_df.select("decoded_value")
display(selected_df)
org.apache.spark.SparkException: [MALFORMED_AVRO_MESSAGE] Malformed Avro messages are detected in message deserialization. Parse Mode: FAILFAST. To process malformed Avro message as null result, try setting the option 'mode' as 'PERMISSIVE'. SQLSTATE: KD000
エラーの対応方法
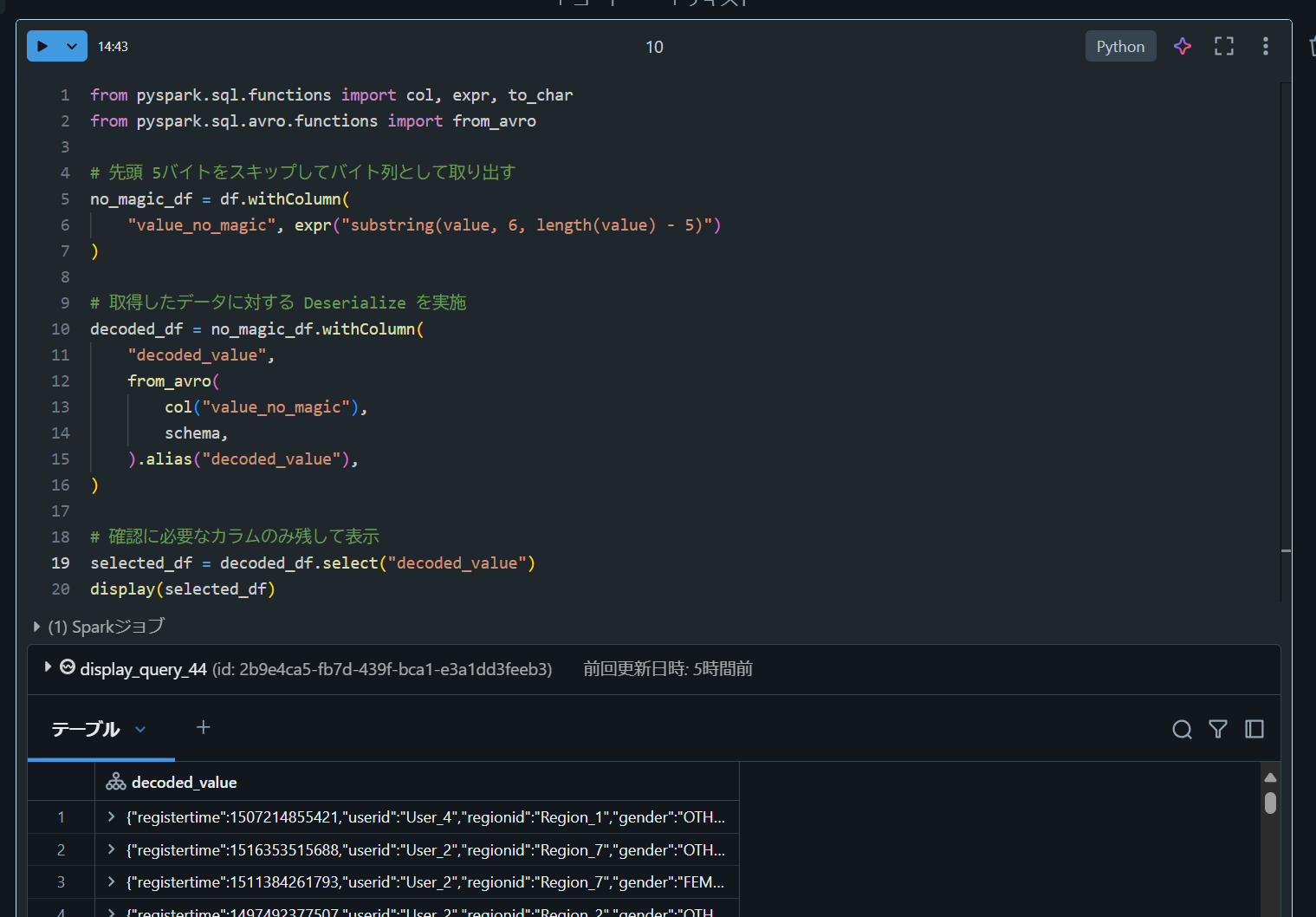
デシリアライズする前に 5 バイトを除去してから実行することを確認できます。
from pyspark.sql.functions import col, expr, to_char
from pyspark.sql.avro.functions import from_avro
# 先頭 5バイトをスキップしてバイト列として取り出す
no_magic_df = df.withColumn(
"value_no_magic", expr("substring(value, 6, length(value) - 5)")
)
# 取得したデータに対する Deserialize を実施
decoded_df = no_magic_df.withColumn(
"decoded_value",
from_avro(
col("value_no_magic"),
schema,
).alias("decoded_value"),
)
# 確認に必要なカラムのみ残して表示
selected_df = decoded_df.select("decoded_value")
display(selected_df)