概要
CData Virtuality に対して Databricks (Spark) から jdbc により overwrite する場合に発生する下記のエラーへの対応方法を共有します。その対処方法として、 DELETE の処理を実行してから APPEND する方法を紹介します。
Py4JJavaError: An error occurred while calling o3043.save.
: org.teiid.jdbc.TeiidSQLException: com.datavirtuality.dv.core.replicator.ReplicatorException: In order to create or drop tables (or create a physical index) in the current data source, it is needed to specify the default schema using the data source parameter importer.defaultSchema.
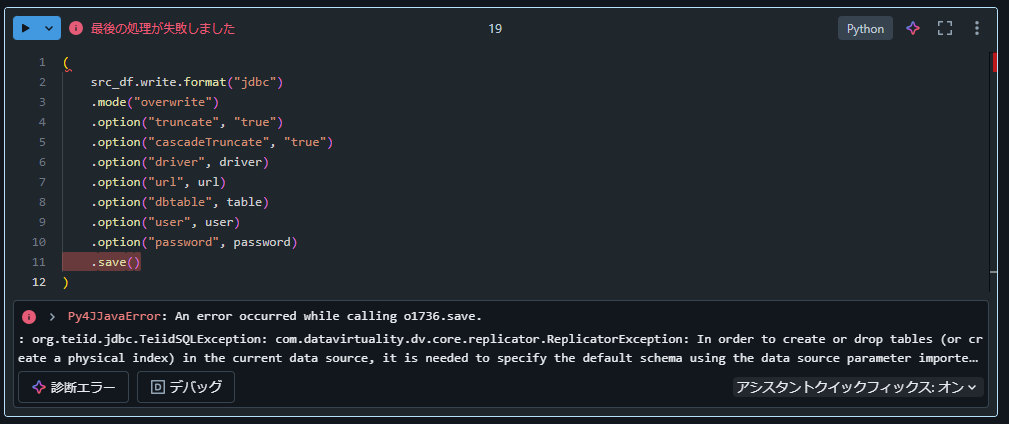
Spark DataFrame で JDBC を使用してデータを overwrite モードでデフォルトの設定(truncate オプションがfalse )で書き込む場合にはテーブルを DROP してから書き込みを行うため、CData Virtuality に対する処理がエラーとなりました。また、truncate オプションを true に設定しても、ドキュメントの記載通り正常に動作しないことが確認されています。この問題を回避するため、DELETE 文でデータを削除してから APPEND モードでデータを書き込む代替手法を説明します。
MySQLDialect, DB2Dialect, MsSqlServerDialect, DerbyDialect, and OracleDialect supports this while PostgresDialect and default JDBCDirect doesn't.
引用元:JDBC To Other Databases - Spark 3.5.1 Documentation
MySQLDialect、DB2Dialect、MsSqlServerDialect、DerbyDialect、および OracleDialect はこれをサポートしていますが、PostgresDialect とデフォルトの JDBCDirect はサポートしていません。
上記翻訳
事前準備
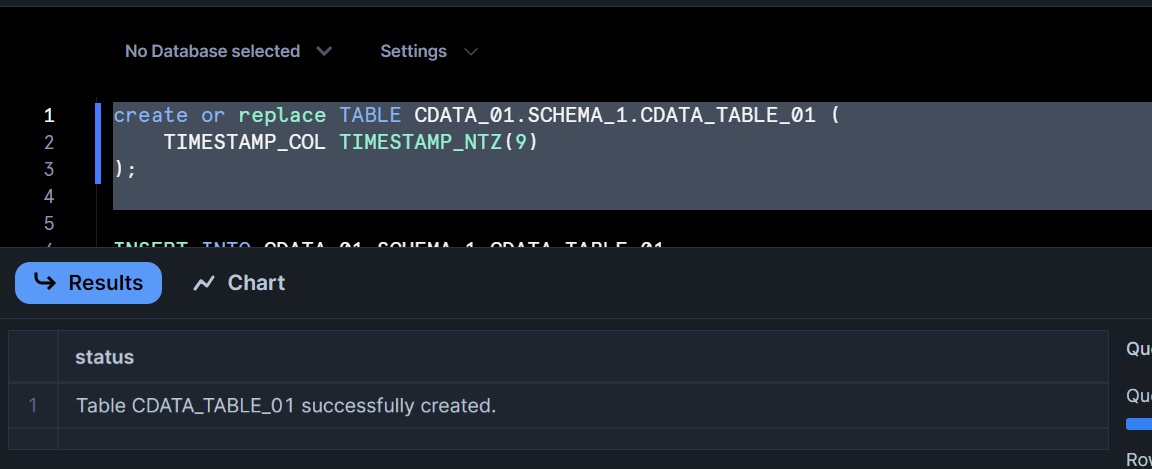
1. Snowflake にてテスト用のテーブルを作成
create or replace TABLE CDATA_01.SCHEMA_1.CDATA_TABLE_01 (
TIMESTAMP_COL TIMESTAMP_NTZ(9)
);
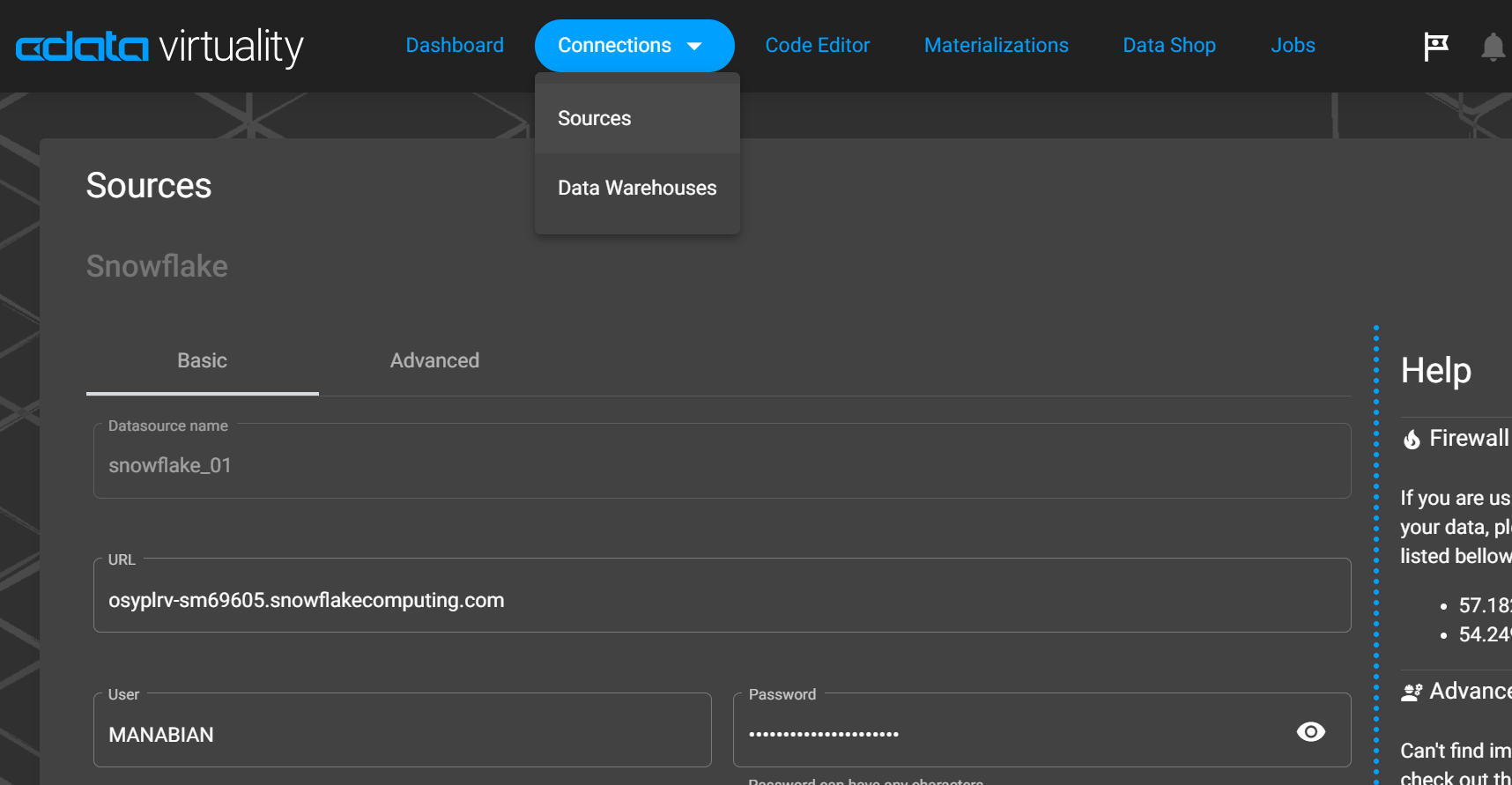
2. CData Virtuality にて Snowflake を Sources に登録
3. CData Virtuality の jdbc を Databricks のクラスターにインストール
エラーの再現方法
1. 書き込み用データを保持したデータフレームを作成
from pyspark.sql.functions import current_timestamp
# 書き込み用データを保持したデータフレームを作成
src_df = spark.createDataFrame([(1,)], ["id"]).withColumn("TIMESTAMP_COL", current_timestamp())
src_df = src_df.drop("id")
src_df.display()
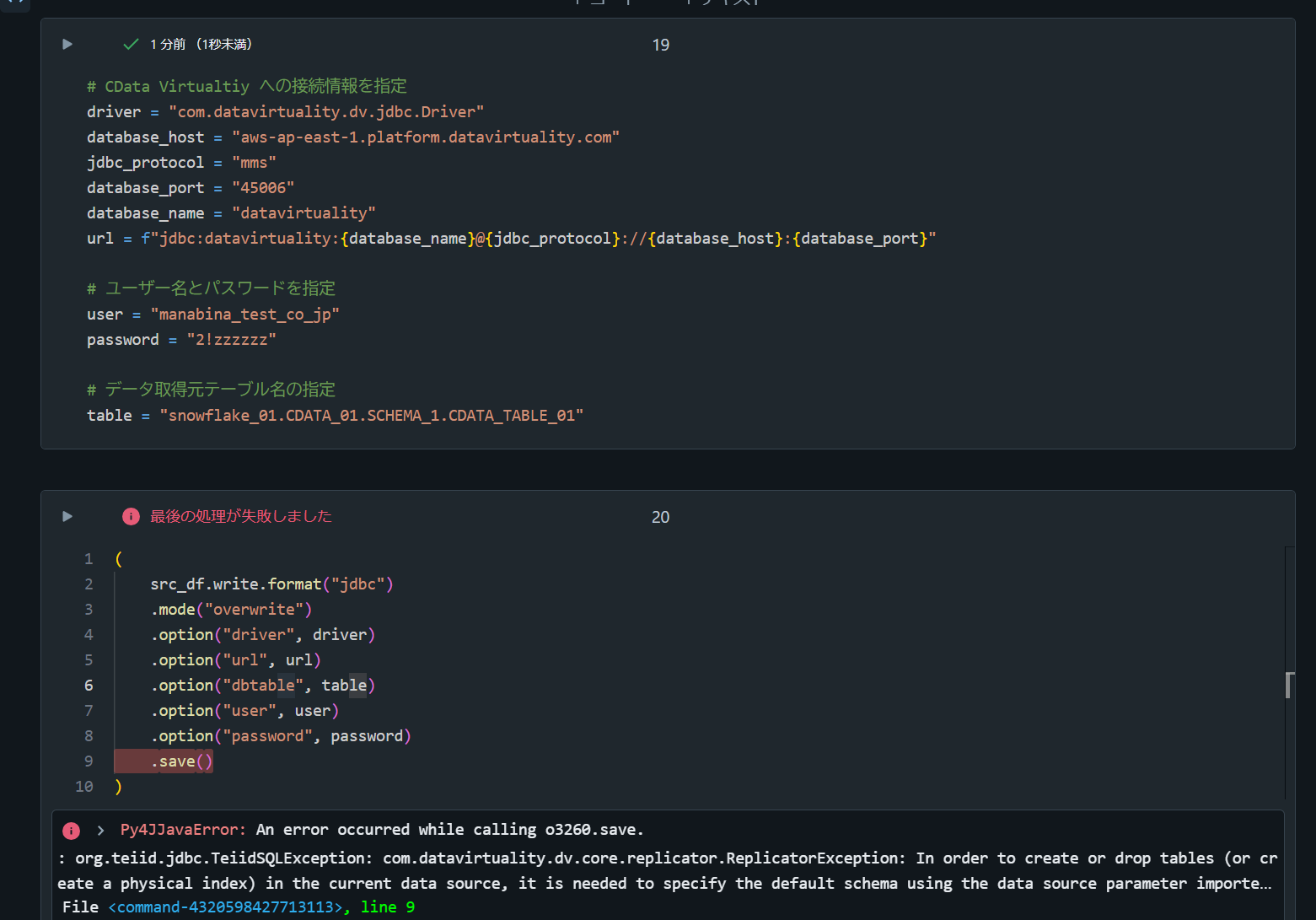
2. overwrite の処理がエラーとなることを確認
# CData Virtualtiy への接続情報を指定
driver = "com.datavirtuality.dv.jdbc.Driver"
database_host = "aws-ap-east-1.platform.datavirtuality.com"
jdbc_protocol = "mms"
database_port = "45006"
database_name = "datavirtuality"
url = f"jdbc:datavirtuality:{database_name}@{jdbc_protocol}://{database_host}:{database_port}"
# ユーザー名とパスワードを指定
user = "manabina_test_co_jp"
password = "2!zzzzzz"
# データ取得元テーブル名の指定
table = "snowflake_01.CDATA_01.SCHEMA_1.CDATA_TABLE_01"
(
src_df.write.format("jdbc")
.mode("overwrite")
.option("driver", driver)
.option("url", url)
.option("dbtable", table)
.option("user", user)
.option("password", password)
.save()
)
Py4JJavaError: An error occurred while calling o3043.save.
: org.teiid.jdbc.TeiidSQLException: com.datavirtuality.dv.core.replicator.ReplicatorException: In order to create or drop tables (or create a physical index) in the current data source, it is needed to specify the default schema using the data source parameter importer.defaultSchema.
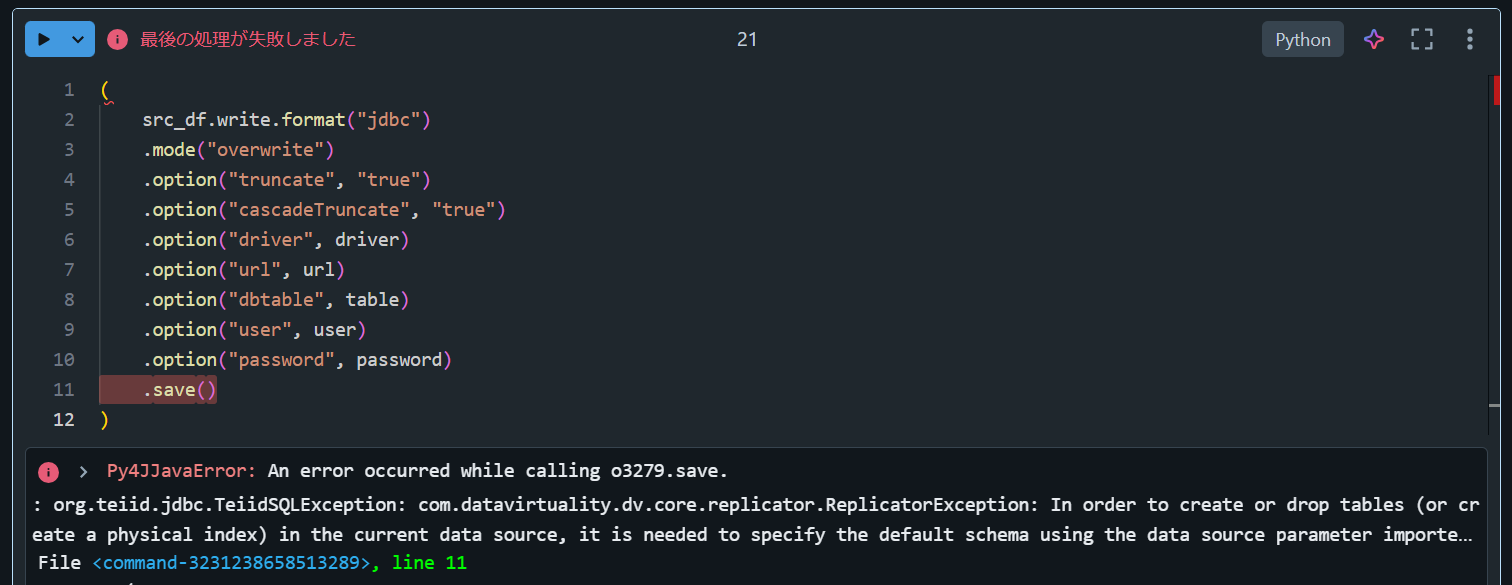
3. truncateをtrueに設定してもエラーとなることを確認
(
src_df.write.format("jdbc")
.mode("overwrite")
.option("truncate", "true")
.option("cascadeTruncate", "true")
.option("driver", driver)
.option("url", url)
.option("dbtable", table)
.option("user", user)
.option("password", password)
.save()
)
エラーへの対応方法
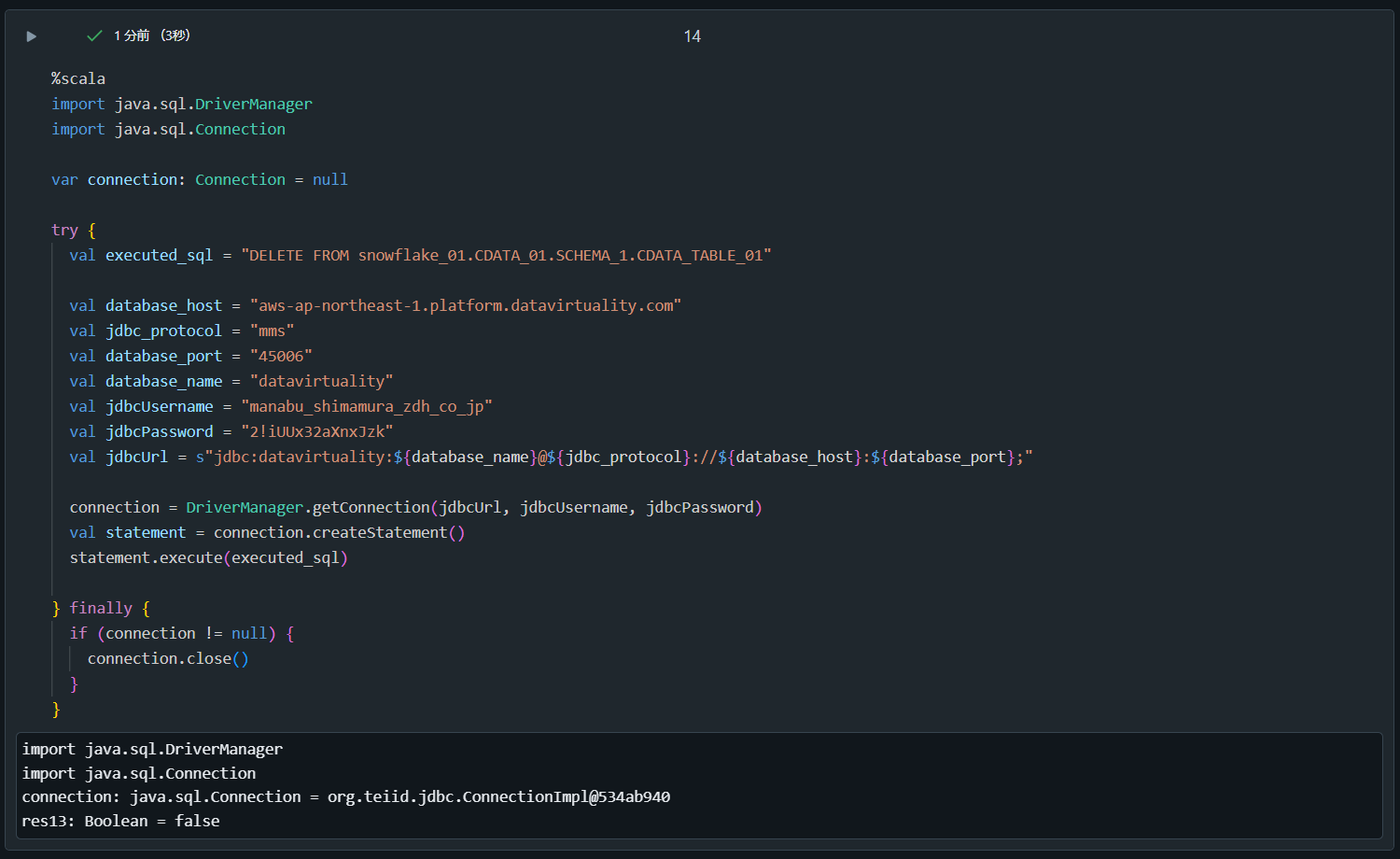
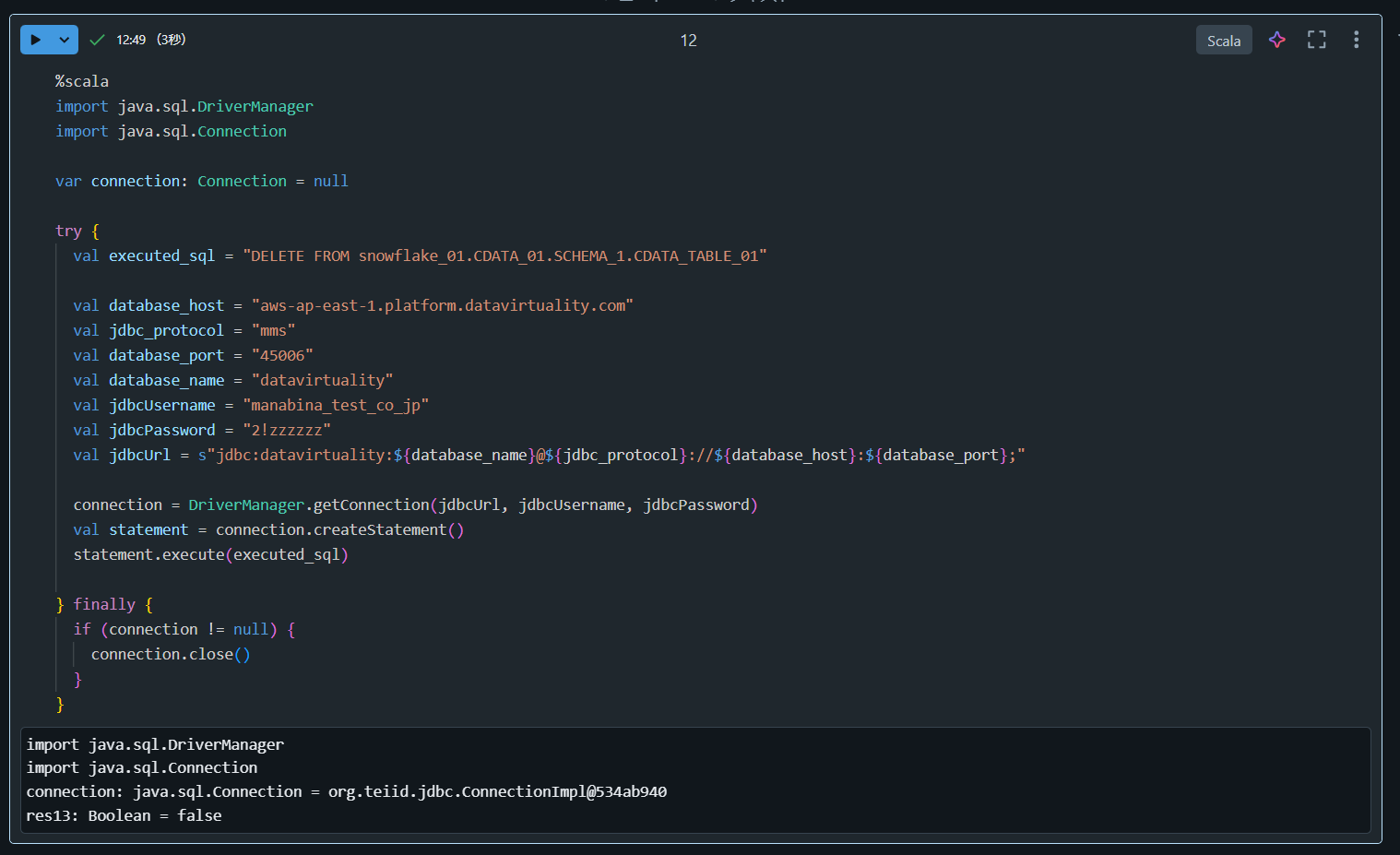
1. テーブルに対する DELETE 処理を実行
%scala
import java.sql.DriverManager
import java.sql.Connection
var connection: Connection = null
try {
val executed_sql = "DELETE FROM snowflake_01.CDATA_01.SCHEMA_1.CDATA_TABLE_01"
val database_host = "aws-ap-east-1.platform.datavirtuality.com"
val jdbc_protocol = "mms"
val database_port = "45006"
val database_name = "datavirtuality"
val jdbcUsername = "manabina_test_co_jp"
val jdbcPassword = "2!zzzzzz"
val jdbcUrl = s"jdbc:datavirtuality:${database_name}@${jdbc_protocol}://${database_host}:${database_port};"
connection = DriverManager.getConnection(jdbcUrl, jdbcUsername, jdbcPassword)
val statement = connection.createStatement()
statement.execute(executed_sql)
} finally {
if (connection != null) {
connection.close()
}
}
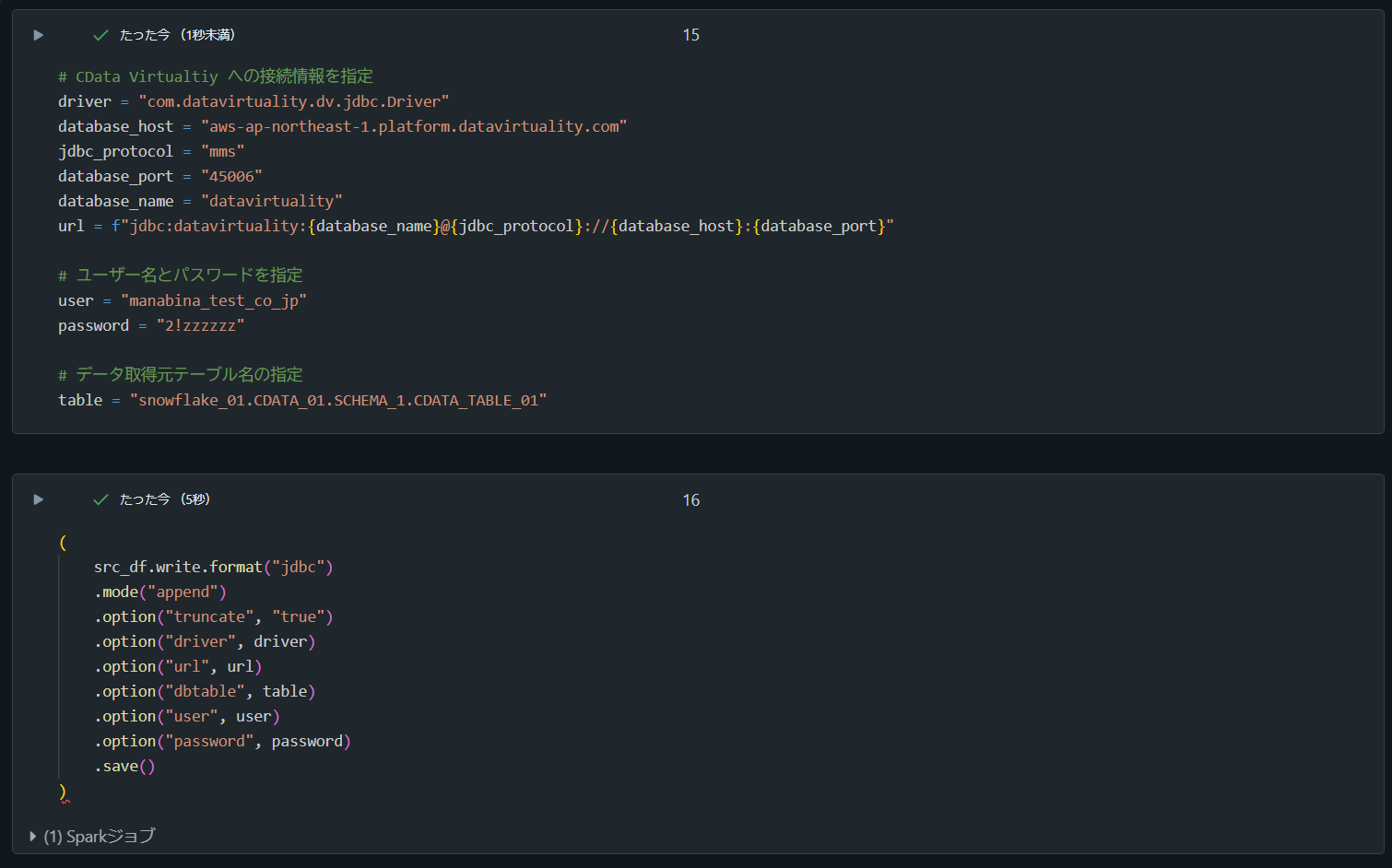
2. append により書き込み処理
# CData Virtualtiy への接続情報を指定
driver = "com.datavirtuality.dv.jdbc.Driver"
database_host = "aws-ap-northeast-1.platform.datavirtuality.com"
jdbc_protocol = "mms"
database_port = "45006"
database_name = "datavirtuality"
url = f"jdbc:datavirtuality:{database_name}@{jdbc_protocol}://{database_host}:{database_port}"
# ユーザー名とパスワードを指定
user = "manabina_test_co_jp"
password = "2!zzzzzz"
# データ取得元テーブル名の指定
table = "snowflake_01.CDATA_01.SCHEMA_1.CDATA_TABLE_01"
(
src_df.write.format("jdbc")
.mode("append")
.option("truncate", "true")
.option("driver", driver)
.option("url", url)
.option("dbtable", table)
.option("user", user)
.option("password", password)
.save()
)
3. CData Virtuality にてデータが書き込まれたことを確認
SELECT
"TIMESTAMP_COL"
FROM
"snowflake_01.CDATA_01.SCHEMA_1.CDATA_TABLE_01";;