Introduction how to make a gramar checker that anyone can easily build it.
私たち日本人のようなノンネイティブが書く英文には、必ず文法誤りやスペル誤りといった誤りが含まれています (断定)。
実際、イキって書いた冒頭の英文にも以下のような誤りが含まれてました。
Introduction how to make a grammar grammar checker that anyone can easily build it.
・ 「gramar」はスペル誤り。正しくは「grammar」
・ 「that」が関係代名詞の目的格をとっているため、buildの目的語である「it」は余剰。
このように、私のようにイキって英文を書いときに恥をかかないためにも Grammar Checkerは必須だと言えます。実際、すでに商用のものもいろいろ出ており、例えば Microsoft Wordにはかなり前からspell checker 機能が実装されてますし、最近だと GrammarlyやGingerといったより多様な誤りを訂正してくれるソフトウエアも開発されています。
文法誤り訂正タスクの研究動向
Grammar checker を作る前にまずは関連する研究分野について簡単に整理しておきます。
自然言語処理分野では、上述したような与えられた文に含まれる様々な文法誤りを自動的に訂正するタスクのことを文法誤り訂正(Grammatical Error Correction)タスクと呼ばれ、日々研究が進められています。これまでの研究動向をざっくりと図示したものが以下になります。
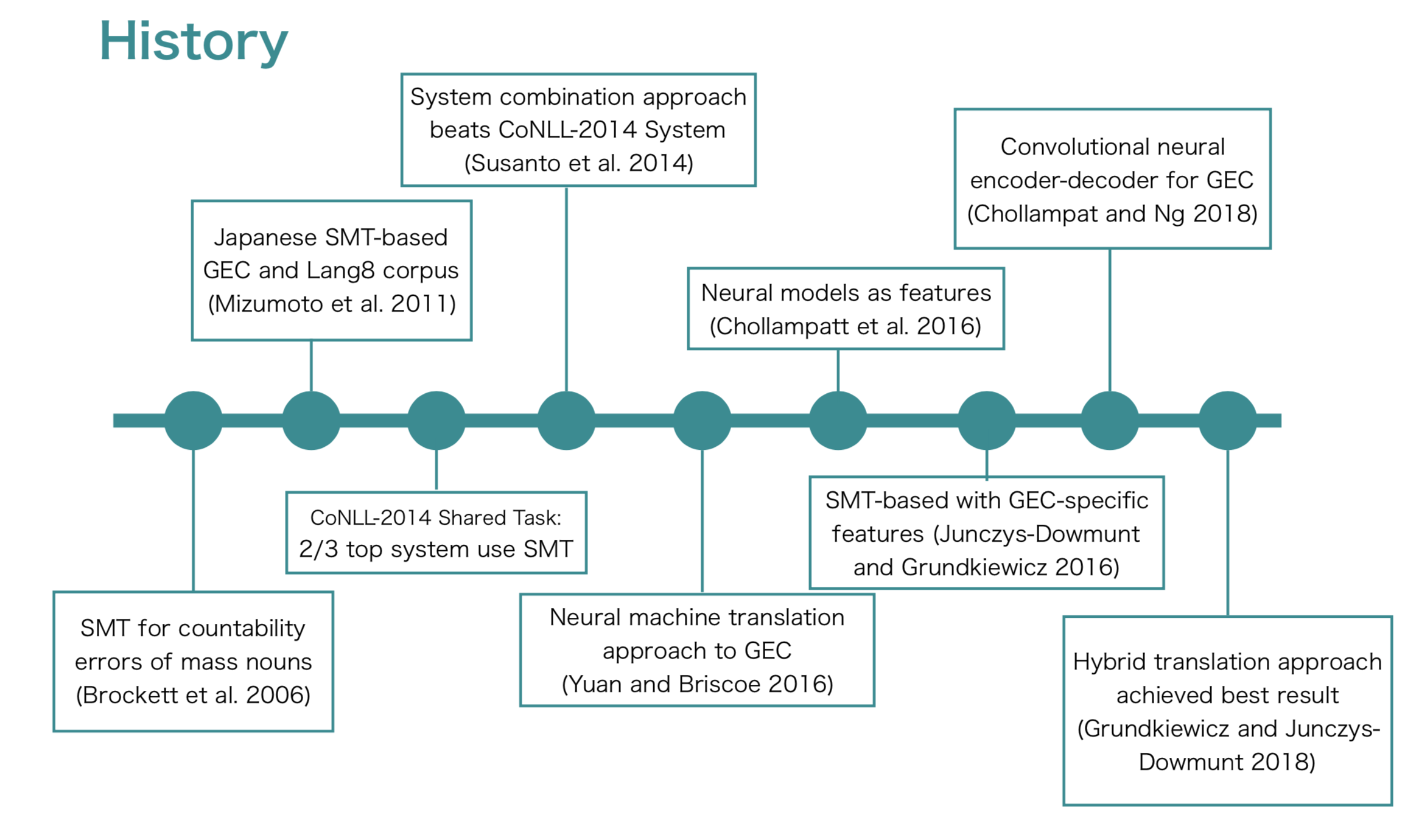
文法誤り訂正分野では、現在 Translation Approachが主流になってます。これは、誤り訂正を bad English → good Englishの翻訳とみなして解こうというアプローチです。上図からもわかる通り、2011年頃に Lang8 Corpus (後述)といった大規模なパラレルデータの登場を皮切りに、統計的機械翻訳(Statistical Machine Translation:SMT)ベースの訂正手法が一気に盛んになりました。
Translation Approach が登場する前までは、誤りタイプごとに分類器を作る Classifier-based なアプローチが主流でしたが、その場合各誤りタイプ(例:冠詞訂正モデル、前置詞訂正モデルなど)ごとにモデルを作る必要がありましたが、Translation Approachを用いることで (基本的には) 全ての誤りを一括で訂正できるモデルを作ることができたのがやはり一番大きなブレークスルーだと思います。他にも Translation Approach のアドバンテージとしては以下のようなものが挙げられるかと思います。
- bad Englishとgood Englishのパラレルデータから訂正モデルを学習することができる
- とてもシンプルで、言語依存ツールが必要ない
- 相互作用する誤り (interacting errors)や多様な誤りを訂正できるようになる
- interacting errosの例:
- (bad) I look forward hear from you.
- (good) I look forward to hearing from you.
- toの挿入と、hearからhearingへの置換操作は相互に作用している
- 個別に対処するClassifer-basedな手法だとこのような誤りを訂正するのは難しい
- interacting errosの例:
特に最近ではこの分野も例外ではなく深層学習の波が押し寄せてきており、従来のSMTベースのアプローチだけでなく、ニューラル機械翻訳(NMT)ベースあるいは、そのハイブリッドといった手法が登場してきています。
お手軽 Grammar Checkerを作ろう
さて、ここから本題に入ってきます。
より高精度な誤り訂正システムに作るには、モデルを工夫する必要がありますが、今回は冒頭でも述べた通り、誰でも手軽に作れるに重きを置いているため、できるだけ既存のオープンソースを使ってかなりベーシックなモデルを作ってみたいと思います。
用意するもの
-
ベースとするモデル
- Encoder-Decoder with attention model
- 今回は通称「出た!本」のサポートページにあがっている以下のモデルを使用
- https://github.com/mlpnlp/mlpnlp-nmt
- Encoder-Decoder with attention model
-
使用するデータ
- 訓練データ: Lang8 Learner Corpora
- 開発データ: CoNLL2013 testset
- 評価データ: CoNLL2014 testset
Sequence to Sequence with Attention Model

今回ベースとして使うモデルは、Encoder-Decoder モデルの一種であるいわゆる Sequence to Sequence (Seq2Seq)モデルに Attention Mechanism を導入した Seq2Seq with Attention Model になります。
文法誤り訂正分野の研究でも多く採用されているモデルで、Encoder/Decoder部分にはRecurrent Neural Network(RNN)を用いられることが主流です。
ここではモデルの詳しい説明は割愛させていただきますので、Seq2Seq with attention model について詳しく知りたい方は以下の記事なんかはわかりやすく紹介してると思うのでご参照ください。
参考:
今更ながらchainerでSeq2Seq(2)〜Attention Model編〜
https://qiita.com/kenchin110100/items/eb70d69d1d65fb451b67
Lang8 Learner Corpora
 http://lang-8.com/
http://lang-8.com/
訓練データには、Lang-8というSNS型添削サービスのデータから収集して作れた Lang8 Leaner Corporaを用います。Lang8 Leaner Corpora は以下のように Json形式でデータを保持しており、学習者が書いた対象言語 (learninng_language)と学習者の母語(native_language)といった情報がアノテートされてます。
DATA FORMAT
===========
The data is in json format. The structure is
["journal_id",
"sentence_id",
"learning_language",
"native_language",
["learner_sentence1","learner_sentence2",...],
[["correction1_to_sentence1","correction2_to_sentence1",...],
["correction1_to_sentence2","correction2_to_sentence2",...],
...],
]
Example:
["772869","227504","English","Spanish",["My prefer color","Hello
people,","Today I didn't know to tell us.","My prefer color is red.","Because
is funny and diferent.","The red can to pretend dangeruis and it's sexy.","The
color red is chosen for people with self-confidence."],[[],[],["Today I didn't
know how to say it this:"],["My favourite color is red."],["Because it is
funny and different."],["Red can pretend to be dangerous and it's
sexy."],["The color red is chosen by people with self confidence."]]]
なお、Lang8 Learner Corpora には英語の他にも日本語、韓国語、スペイン語、フランス語などなどいろいろな言語データが含まれていますが、以下に公開されているツールを使えば、任意の言語を簡単に抽出することができるので便利です。
Lang8-NAIST-extractor
https://github.com/tomo-wb/Lang8-NAIST-extractor
手順
1. データの準備
-
- Lang8 Learner Corpora から対象言語(今回の場合は英語)を抽出
-
- データのクリーニング
- 顔文字や、対象言語以外の言語といったノイズを除去
- 1.で英語を指定して抽出してきても、実際には日本語や中国語などが混じってたりする (生データはノイズだらけ!)
- → Unicodeの範囲指定やLanguage Identificationなどで頑張る...!
- 長さが極端に短かったり長かったりする文対は学習の妨げになるため除去しておく
- → ルールベースや編集距離を使う
-
- データの前処理
- lowercase
- tokenize など
-
- パラレルデータの準備
- クリーニングしたデータを学習者の文(例:lang8-input.org)と訂正済みの文(例:lang8-input.cor)をそれぞれ1行1文形式のファイルとして用意する
以上のような手順で作られた実際のデータはこんな感じです。
(左側の文がorg/右側の文がcor)
this is my second post . this is my second post .
i will appreciate it if you correct my sentences . | i would appreciate it if you could correct my sentences .
the summer weather in japan is not agreeable to me with its h | i find japan 's summer weather disagreeable because of its hi
so , as the winter is coming , i 'm getting to feel better . | so , as the winter is coming , i 'm starting to feel better .
and also , around the new year 's holidays , we will have a l and also , around the new year 's holidays , we will have a l
mostly with delicious foods , drinks , and good conversations mostly with delicious foods , drinks , and good conversations
2. vocabファイルの作成
ターミナル上で以下のコマンドを実行し、vocabファイルを作成します。
for f in sample_data/lang8-input.{org,cor} ;do \
echo ${f} ; \
cat ${f} | sed '/^$/d' | perl -pe 's/^\s+//; s/\s+\n$/\n/; s/ +/\n/g' | \
LC_ALL=C sort | LC_ALL=C uniq -c | LC_ALL=C sort -r -g -k1 | \
perl -pe 's/^\s+//; ($a1,$a2)=split;
if( $a1 >= 3 ){ $_="$a2\t$a1\n" }else{ $_="" } ' > ${f}.vocab_t3_tab ;
done
上記を実行すると、org/corファイルともに以下のような 1行にtokenと頻度がtab区切りになった vocabファイルが作成されます。
. 1861168
i 1417468
, 1180262
the 966446
to 890581
a 612142
and 587223
in 485203
is 470394
of 459406
my 413616
it 403189
that 266874
for 256843
was 235074
have 216078
you 214480
but 202303
so 194290
this 193364
3. 学習
ターミナル上で以下のコマンドを実行し、モデルを学習させます。
SLAN=org; TLAN=cor; GPU=-1; EP=10 ; \
MODEL=GEC.model ; \
python -u ./src/LSTMEncDecAttn.py -V2 \
-T train \
--gpu-enc ${GPU} \
--gpu-dec ${GPU} \
--enc-vocab-file sample_data/lang8-input.${SLAN}.vocab_t3_tab \
--dec-vocab-file sample_data/lang8-input.${TLAN}.vocab_t3_tab \
--enc-data-file sample_data/lang8-input.${SLAN} \
--dec-data-file sample_data/lang8-input-w5.${TLAN} \
--enc-devel-data-file sample_data/conll13.${SLAN} \
--dec-devel-data-file sample_data/conll13.${TLAN} \
-D 512 \
-H 512 \
-N 2 \
--optimizer SGD \
--lrate 1.0 \
--batch-size 32 \
--out-each 0 \
--epoch ${EP} \
--eval-accuracy 0 \
--dropout-rate 0.3 \
--attention-mode 1 \
--gradient-clipping 5 \
--initializer-scale 0.1 \
--initializer-type uniform \
--merge-encoder-fwbw 0 \
--use-encoder-bos-eos 0 \
--use-decoder-inputfeed 1 \
-O ${MODEL} \
4. 評価
上記 3. で学習し作成されたモデルファイル (例:GEC.model) を用いて、以下のコマンドを実行して、テストしてみましょう。テストセットには 今回は CoNLL-2014 testsetを用いてます。
SLAN=org; GPU=-1; EP=10 ; BEAM=5 ; \
MODEL=GEC.model ; \
python -u ./src/LSTMEncDecAttn.py \
-T test \
--gpu-enc ${GPU} \
--gpu-dec ${GPU} \
--enc-data-file sample_data/conll14-preproc.${SLAN} \
--init-model ${MODEL}.epoch${EP} \
--setting ${MODEL}.setting \
--beam-size ${BEAM} \
--max-length 150 \
> ${MODEL}.epoch${EP}.decode_MAX${MAXLEN}_BEAM${BEAM}.txt
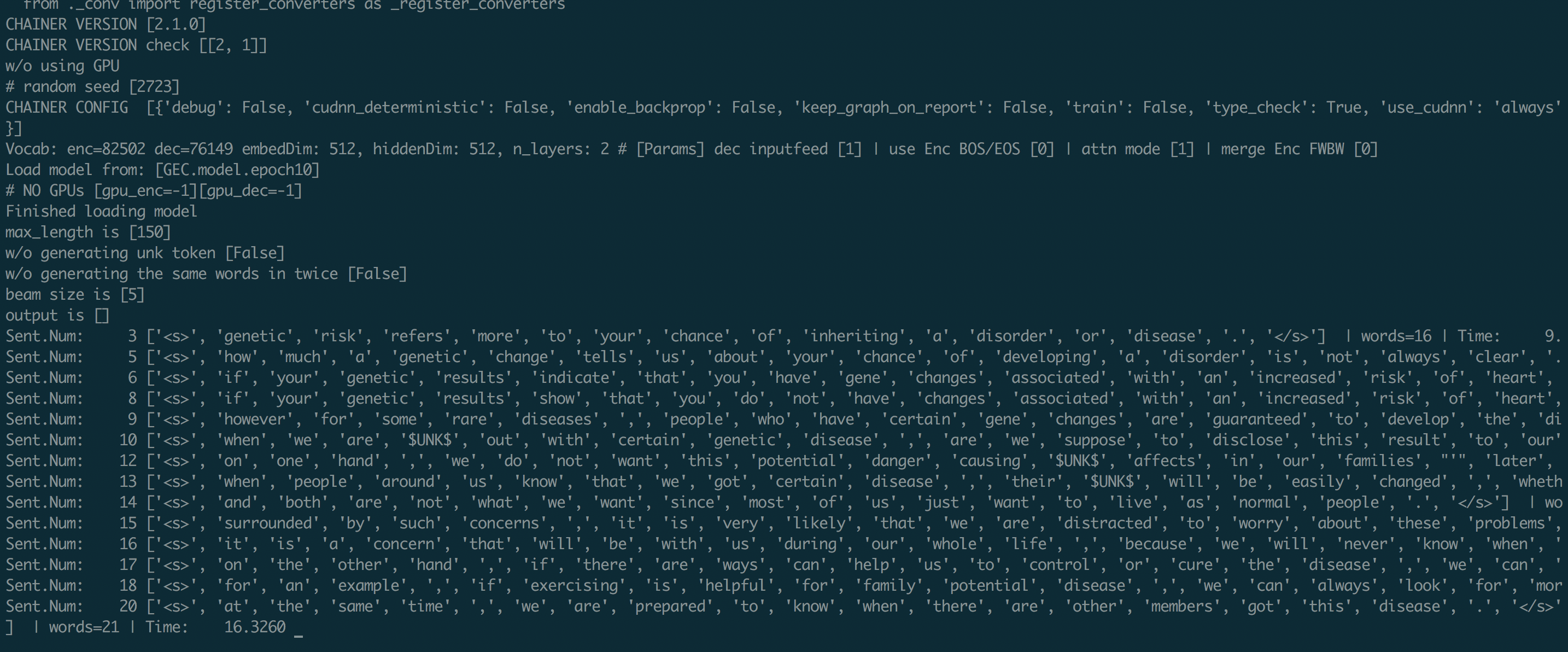
ターミナル上で上記のコマンドを実行すると、以下のようにDecodingが開始されます。
Decoding の様子
より良いモデルを求めて・・・
今回は「さくっと誤り訂正システムを作って動かしてみる」ことが主旨だったため、非常にナイーブなモデルになっていますが、実際にはこれだけだとあまり訂正性能は高くありません。
もしこの記事を読んで**より訂正性能の高いモデルを作りたい!**と興味を持っていただいた場合、例えば以下のポイントに着目してより高性能な自分だけの Grammar Checkerにしてみてください!
-
低頻度語問題への対処
- 上記の Decoding の様子のところでも
$UNK$となっている箇所がありますが、これは訓練データ中に登場しなかった低頻度語になります。現在は、この低頻度語問題の対処方法もいろいろ報告されています。
- 上記の Decoding の様子のところでも
-
データ量を増やす
- 今回は訓練データに Lang8 Leaner Corpora しか使用しませんでしたが、他にも例えば以下のようなParrallel Corpora や English Copora があります。データ量を増やすことで精度向上に繋がるかもしれません。
- Parallel Corpora: NUCLE
- English Corpora: Wikipedia, CommonCrawl
- 今回は訓練データに Lang8 Leaner Corpora しか使用しませんでしたが、他にも例えば以下のようなParrallel Corpora や English Copora があります。データ量を増やすことで精度向上に繋がるかもしれません。
-
多様な学習者への適応
- 学習者によって犯しやすい誤りは様々です。例えば、TOEIC 500点台の学習者が犯す誤りとTOEIC900点台の学習者が犯す誤りでは誤りの事前分布は異なるはずと容易に想像できます。そのため、そのような学習者の誤り分布をうまくモデルに適応させることが精度向上のカギになるかもしれません。