EncoderDecoderモデルの一種であるSequence to Sequence(Seq2Seq)に、
Attention Modelを導入し、その実装と検証結果について説明する。
はじめに
前回
http://qiita.com/kenchin110100/items/b34f5106d5a211f4c004
Sequence to Sequence(Seq2Seq)モデルの実装をChainerで行なったが、
今回はそのモデルにAttention Modelを追加しました。
以降では、Attention Model、その実装法、検証結果について説明をします。
Attention Model
Attention Modelとは
LSTMなどのRNN系のネットワークを用いることで、文などの系列データを特徴ベクトルに変換することができます。
しかし初期に入力したデータは、最終的に出力される特徴ベクトルに反映されにくくなります。
つまり、「お母さんが化粧をして、スカートを履いて街に出かけた」という文と、「お父さんが化粧をして、スカートを履いて街に出かけた」という文がほとんど同じ特徴ベクトルになってしまうということです。
初期に入力したデータもちゃんと考慮するようにする仕組みがAttention Modelです。
Sequence to Sequence with Attention Model
前回実装したSeq2Seqモデルの計算の流れを図示すると下のようになります。
| Sequence to Sequence |
|---|
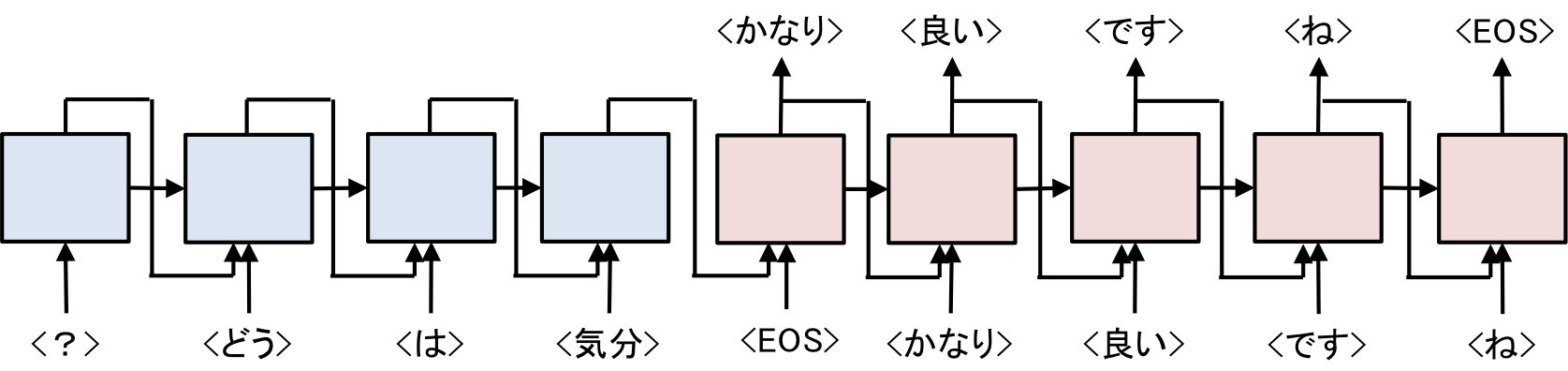 |
| (前回と少し図を変えています) |
青色の部分が発話をベクトル化するEncoder、赤色の部分がベクトルから応答を出力するDecoderです。
これにAttention Modelを加えると以下の図のようになります。
| Sequence to Sequence with Attention model |
|---|
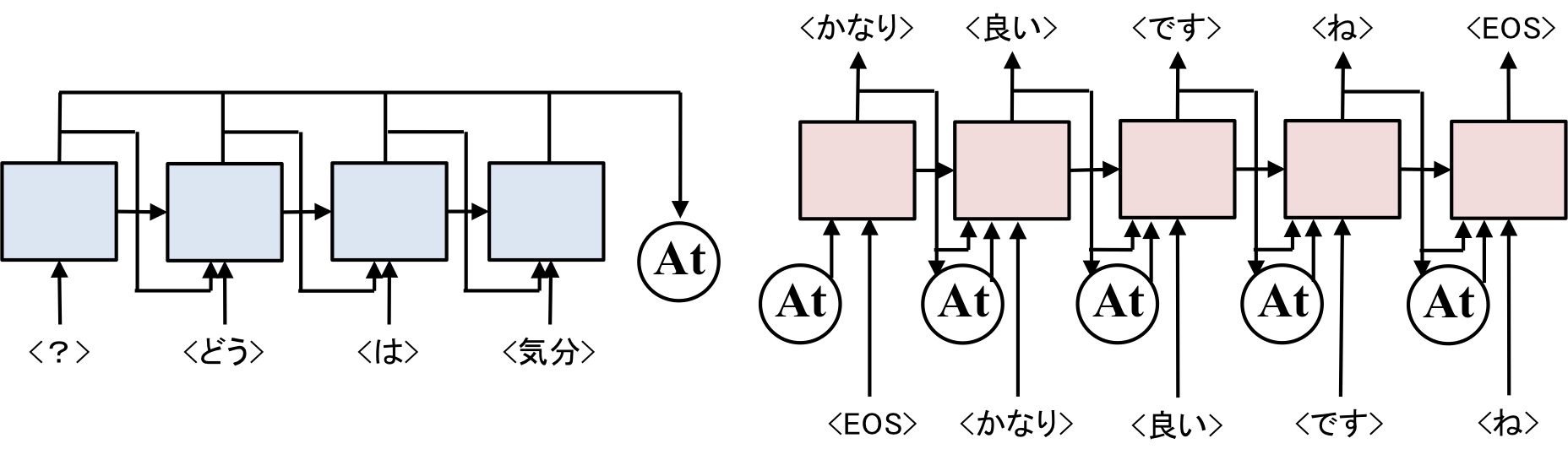 |
少し複雑になりますが、図中の[At]と書いてあるところがAttention Modelとなります。
Encoder側では、毎回出力される中間ベクトルをAttention Modelの中に記憶させていきます。
Decoder側では、1つ前の中間ベクトルをAttention Modelに入力します。
入力されたベクトルを元にAttention ModelがEncoder側で入力された中間ベクトルの加重平均をとってリターンします。
Encoderの中間ベクトルの加重平均をDecoderに入力することで、前にある単語、後ろにある単語、どこでも注目できるようにするのがAttention Modelとなります。
Attention Modelには大きく分けて2種類存在し、Global AttentionとLocal Attentionと呼ばれます。
以降では、Global Attention、Local Attentionの説明を行います。
Global Attention
Global Attentionが提案されたのが、下記の論文になります。
Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. "Neural machine translation by jointly learning to align and translate." arXiv preprint arXiv:1409.0473 (2014).
元々は機械翻訳で使われていたんですね。
Global Attentionについて説明した資料は、
https://www.slideshare.net/yutakikuchi927/deep-learning-nlp-attention
がわかりやすいです。
あと英語になりますが、
https://talbaumel.github.io/attention/
もわかりやすいです。
Encoder側で入力された中間ベクトルの加重平均を取る仕組みを図示すると以下のようになります。
| Global Attention |
|---|
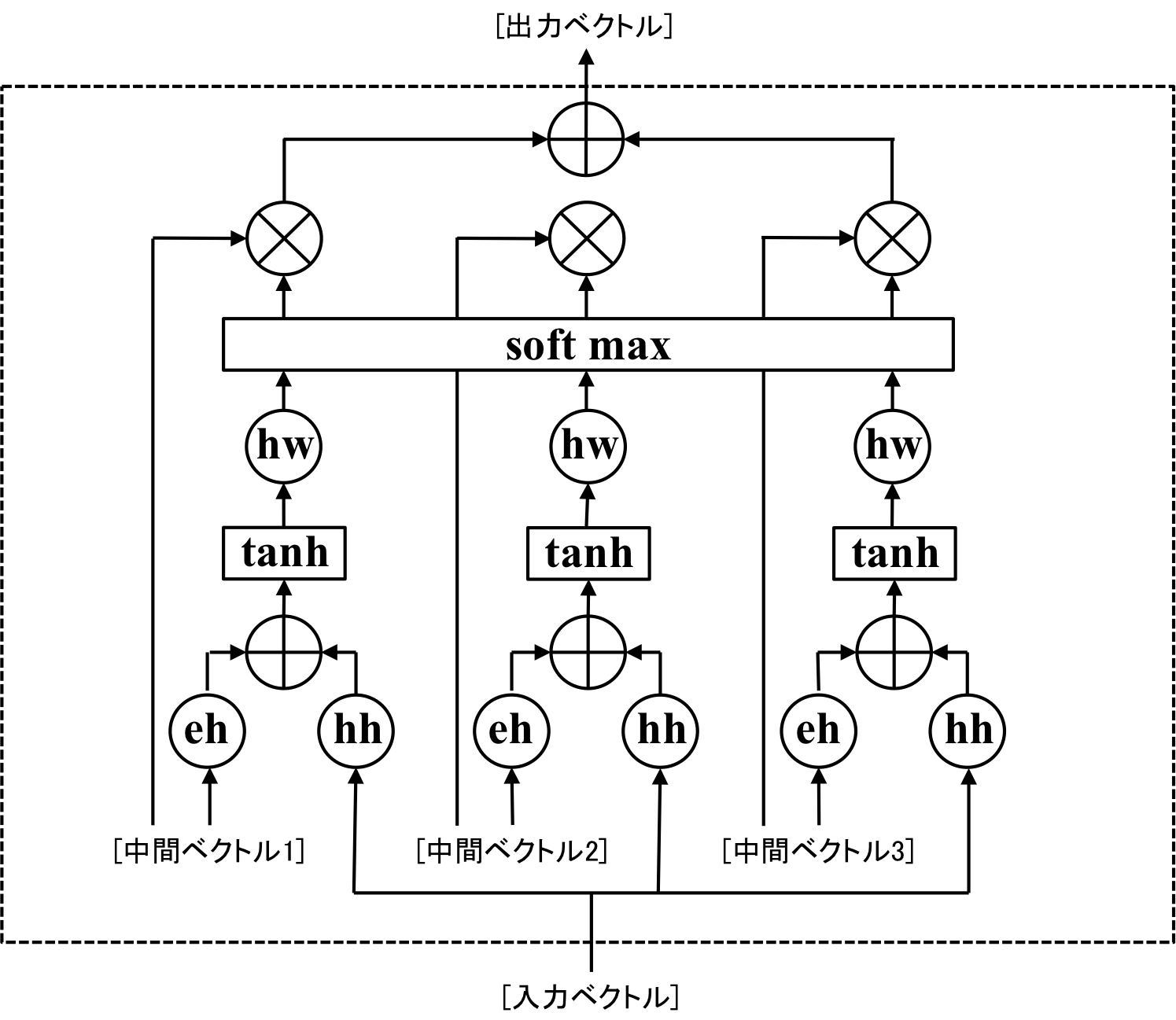 |
図はEncoder側で[中間ベクトル1]、[中間ベクトル2]、[中間ベクトル3]の3つのベクトルが入力されてる状態を考えています。
図中の[eh]、[hh]は隠れ層サイズのベクトルから隠れ層のサイズのベクトルを出力する線形結合層、[+]はベクトルの足し算、[×]はベクトルの要素ごとの掛け算を表しています。
[tanh]はhyperbolic tangentであり、ベクトルの要素を-1から1までのスケールに変換します。
[hw]は隠れ層のサイズからサイズ1のスカラを出力する線形結合層です。
[soft max]はSoftMax関数で、入力された値を和が1になるように正規化します。
[Soft max]によって計算された値を加重平均のウェイトとして、中間ベクトルの加重平均をとった結果を出力します。
これがGlobal Attentionの仕組みです。
Local Attention
Local Attentionが提案された論文は下記のもの
Luong, Minh-Thang, Hieu Pham, and Christopher D. Manning. "Effective approaches to attention-based neural machine translation." arXiv preprint arXiv:1508.04025 (2015).
これも機械翻訳の論文ですね。
参考にした資料は
https://www.slideshare.net/yutakikuchi927/deep-learning-nlp-attention
です。
下はLocal Attentionの計算フロー図です。
| Local Attention |
|---|
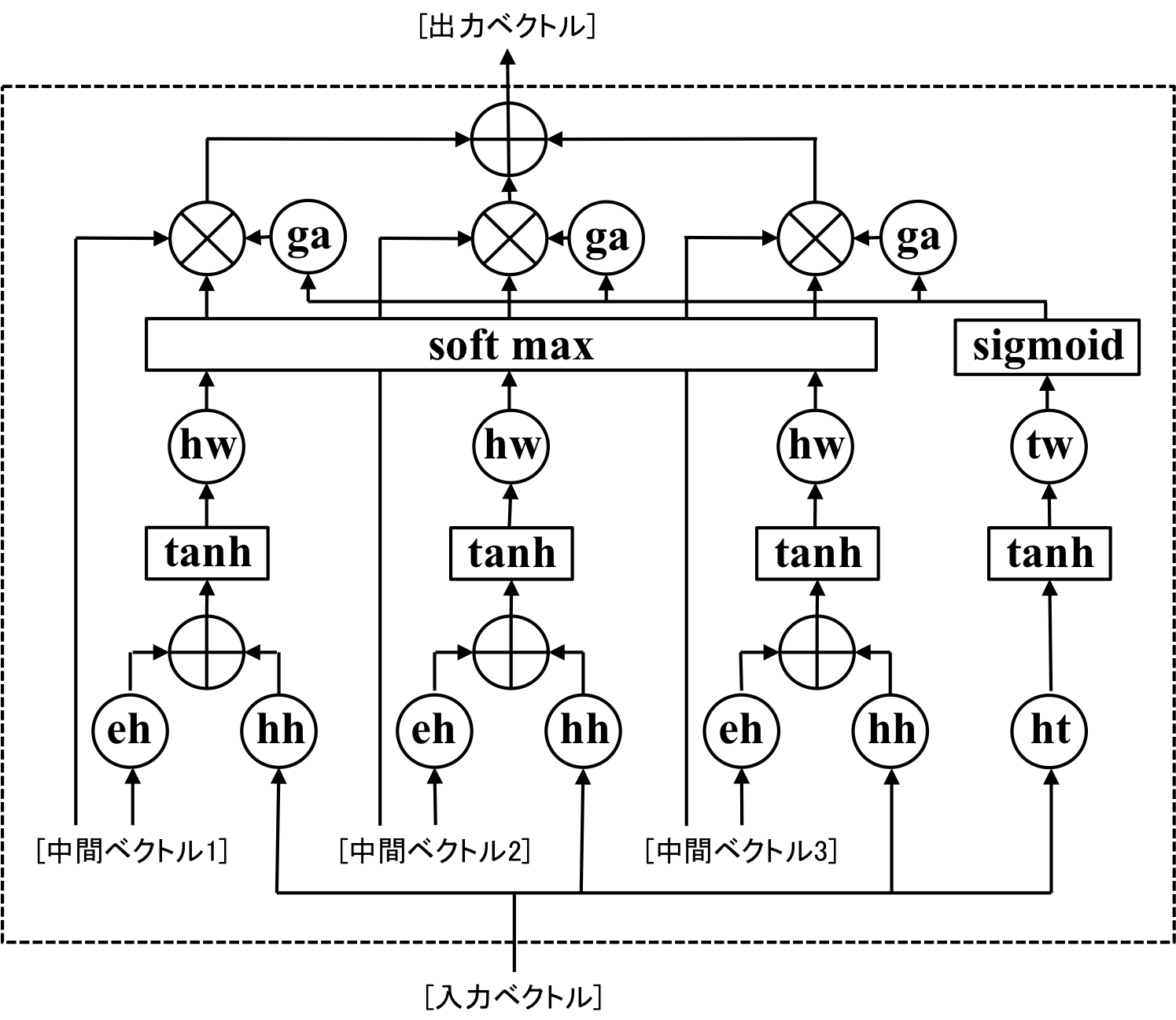 |
Global Attentionにさらにネットワークが追加されています。
主な違いは右側のネットワーク。
[ht]は隠れ層サイズのベクトルから隠れ層のサイズのベクトルを出力する線形結合、[tanh]は先ほどと同じ、ベクトルの要素を-1から1までの範囲にスケーリングする働きをします。
[tw]は隠れ層サイズのベクトルをスカラーに変換する線形結合層であり、[sigmoid]はシグモイド関数で、入力された値を0から1の範囲にスケーリングします。したがって、ここまで入力されたベクトルは、0から1までの範囲のスカラーになります。
次に図中の[ga]で何をしているのかを説明します。gaの計算は以下の式です。
output = \exp\bigl(-\frac{(s - input * Len(S))^2}{\sigma^2}\bigl)
ここで、$input$は0から1の範囲にスケーリングされたスカラー、$Len(S)$はエンコーダーで入力された中間ベクトルの数、$s$は中間層ベクトルの順番([中間ベクトル1]なら1、[中間ベクトル2]なら2)を表してる。
もし仮にsigmoid関数で出力された値が0.1ならば、[ga]は中間ベクトル1の時に大きな値になり、中間ベクトル3の時は小さな値になる。
この出力をGlobal Attentionで計算した重みに掛け合わせることで、よりピンポイントに特定の中間ベクトルに注目することが可能になります。
実装
前回と同じようにchainerで実装しました。Encoder部分はSeq2Seqの時と同じです。
参考にさせていただいたコードはoda様のものです。ありがとうございます。
https://github.com/odashi/chainer_examples
Attention
実装したのはGlobal Attentionです。コードは下記の通り、
class Attention(Chain):
def __init__(self, hidden_size, flag_gpu):
"""
Attentionのインスタンス化
:param hidden_size: 隠れ層のサイズ
:param flag_gpu: GPUを使うかどうか
"""
super(Attention, self).__init__(
# 順向きのEncoderの中間ベクトルを隠れ層サイズのベクトルに変換する線形結合層
fh=links.Linear(hidden_size, hidden_size),
# 逆向きのEncoderの中間ベクトルを隠れ層サイズのベクトルに変換する線形結合層
bh=links.Linear(hidden_size, hidden_size),
# Decoderの中間ベクトルを隠れ層サイズのベクトルに変換する線形結合層
hh=links.Linear(hidden_size, hidden_size),
# 隠れ層サイズのベクトルをスカラーに変換するための線形結合層
hw=links.Linear(hidden_size, 1),
)
# 隠れ層のサイズを記憶
self.hidden_size = hidden_size
# GPUを使う場合はcupyを使わないときはnumpyを使う
if flag_gpu:
self.ARR = cuda.cupy
else:
self.ARR = np
def __call__(self, fs, bs, h):
"""
Attentionの計算
:param fs: 順向きのEncoderの中間ベクトルが記録されたリスト
:param bs: 逆向きのEncoderの中間ベクトルが記録されたリスト
:param h: Decoderで出力された中間ベクトル
:return: 順向きのEncoderの中間ベクトルの加重平均と逆向きのEncoderの中間ベクトルの加重平均
"""
# ミニバッチのサイズを記憶
batch_size = h.data.shape[0]
# ウェイトを記録するためのリストの初期化
ws = []
# ウェイトの合計値を計算するための値を初期化
sum_w = Variable(self.ARR.zeros((batch_size, 1), dtype='float32'))
# Encoderの中間ベクトルとDecoderの中間ベクトルを使ってウェイトの計算
for f, b in zip(fs, bs):
# 順向きEncoderの中間ベクトル、逆向きEncoderの中間ベクトル、Decoderの中間ベクトルを使ってウェイトの計算
w = functions.tanh(self.fh(f)+self.bh(b)+self.hh(h))
# softmax関数を使って正規化する
w = functions.exp(self.hw(w))
# 計算したウェイトを記録
ws.append(w)
sum_w += w
# 出力する加重平均ベクトルの初期化
att_f = Variable(self.ARR.zeros((batch_size, self.hidden_size), dtype='float32'))
att_b = Variable(self.ARR.zeros((batch_size, self.hidden_size), dtype='float32'))
for f, b, w in zip(fs, bs, ws):
# ウェイトの和が1になるように正規化
w /= sum_w
# ウェイト * Encoderの中間ベクトルを出力するベクトルに足していく
att_f += functions.reshape(functions.batch_matmul(f, w), (batch_size, self.hidden_size))
att_b += functions.reshape(functions.batch_matmul(b, w), (batch_size, self.hidden_size))
return att_f, att_b
説明では、Encoderは1つしか使わなかったですが、実はAttention Modelでは順向きのEncoderと逆向きのEncoderの2種類を使うことが一般的です。
なのでAttentionの計算をする時に、順向きのEncoderが計算した中間ベクトルのリスト、逆向きのEncoderが計算した中間ベクトルのリストの2つを渡しています。
Decoder
Decoderで入力する値は、Seq2Seqの時と異なり、単語ベクトル、Decoderが計算した中間ベクトル、Encoderの中間ベクトルの加重平均の3つになりました。そこでDecoderの実装を書き換えています。
class Att_LSTM_Decoder(Chain):
def __init__(self, vocab_size, embed_size, hidden_size):
"""
Attention ModelのためのDecoderのインスタンス化
:param vocab_size: 語彙数
:param embed_size: 単語ベクトルのサイズ
:param hidden_size: 隠れ層のサイズ
"""
super(Att_LSTM_Decoder, self).__init__(
# 単語を単語ベクトルに変換する層
ye=links.EmbedID(vocab_size, embed_size, ignore_label=-1),
# 単語ベクトルを隠れ層の4倍のサイズのベクトルに変換する層
eh=links.Linear(embed_size, 4 * hidden_size),
# Decoderの中間ベクトルを隠れ層の4倍のサイズのベクトルに変換する層
hh=links.Linear(hidden_size, 4 * hidden_size),
# 順向きEncoderの中間ベクトルの加重平均を隠れ層の4倍のサイズのベクトルに変換する層
fh=links.Linear(hidden_size, 4 * hidden_size),
# 順向きEncoderの中間ベクトルの加重平均を隠れ層の4倍のサイズのベクトルに変換する層
bh=links.Linear(hidden_size, 4 * hidden_size),
# 隠れ層サイズのベクトルを単語ベクトルのサイズに変換する層
he=links.Linear(hidden_size, embed_size),
# 単語ベクトルを語彙数サイズのベクトルに変換する層
ey=links.Linear(embed_size, vocab_size)
)
def __call__(self, y, c, h, f, b):
"""
Decoderの計算
:param y: Decoderに入力する単語
:param c: 内部メモリ
:param h: Decoderの中間ベクトル
:param f: Attention Modelで計算された順向きEncoderの加重平均
:param b: Attention Modelで計算された逆向きEncoderの加重平均
:return: 語彙数サイズのベクトル、更新された内部メモリ、更新された中間ベクトル
"""
# 単語を単語ベクトルに変換
e = functions.tanh(self.ye(y))
# 単語ベクトル、Decoderの中間ベクトル、順向きEncoderのAttention、逆向きEncoderのAttentionを使ってLSTM
c, h = functions.lstm(c, self.eh(e) + self.hh(h) + self.fh(f) + self.bh(b))
# LSTMから出力された中間ベクトルを語彙数サイズのベクトルに変換する
t = self.ey(functions.tanh(self.he(h)))
return t, c, h
隠れ層の4倍のサイズのベクトルを使うのは、前回説明した理由と同様です。
Attentionにより計算されたEncoderの中間ベクトルの加重平均を使うために、[fh]と[bh]という層を追加していますが、それ以外は同じです。
Seq2Seq with Attention
Encoder、Decoder、Attentionを組み合わせたモデルが以下のようになります。
class Att_Seq2Seq(Chain):
def __init__(self, vocab_size, embed_size, hidden_size, batch_size, flag_gpu=True):
"""
Seq2Seq + Attentionのインスタンス化
:param vocab_size: 語彙数のサイズ
:param embed_size: 単語ベクトルのサイズ
:param hidden_size: 隠れ層のサイズ
:param batch_size: ミニバッチのサイズ
:param flag_gpu: GPUを使うかどうか
"""
super(Att_Seq2Seq, self).__init__(
# 順向きのEncoder
f_encoder = LSTM_Encoder(vocab_size, embed_size, hidden_size),
# 逆向きのEncoder
b_encoder = LSTM_Encoder(vocab_size, embed_size, hidden_size),
# Attention Model
attention = Attention(hidden_size, flag_gpu),
# Decoder
decoder = Att_LSTM_Decoder(vocab_size, embed_size, hidden_size)
)
self.vocab_size = vocab_size
self.embed_size = embed_size
self.hidden_size = hidden_size
self.batch_size = batch_size
# GPUを使うときはcupy、使わないときはnumpy
if flag_gpu:
self.ARR = cuda.cupy
else:
self.ARR = np
# 順向きのEncoderの中間ベクトル、逆向きのEncoderの中間ベクトルを保存するためのリストを初期化
self.fs = []
self.bs = []
def encode(self, words):
"""
Encoderの計算
:param words: 入力で使用する単語記録されたリスト
:return:
"""
# 内部メモリ、中間ベクトルの初期化
c = Variable(self.ARR.zeros((self.batch_size, self.hidden_size), dtype='float32'))
h = Variable(self.ARR.zeros((self.batch_size, self.hidden_size), dtype='float32'))
# 先ずは順向きのEncoderの計算
for w in words:
c, h = self.f_encoder(w, c, h)
# 計算された中間ベクトルを記録
self.fs.append(h)
# 内部メモリ、中間ベクトルの初期化
c = Variable(self.ARR.zeros((self.batch_size, self.hidden_size), dtype='float32'))
h = Variable(self.ARR.zeros((self.batch_size, self.hidden_size), dtype='float32'))
# 逆向きのEncoderの計算
for w in reversed(words):
c, h = self.b_encoder(w, c, h)
# 計算された中間ベクトルを記録
self.bs.insert(0, h)
# 内部メモリ、中間ベクトルの初期化
self.c = Variable(self.ARR.zeros((self.batch_size, self.hidden_size), dtype='float32'))
self.h = Variable(self.ARR.zeros((self.batch_size, self.hidden_size), dtype='float32'))
def decode(self, w):
"""
Decoderの計算
:param w: Decoderで入力する単語
:return: 予測単語
"""
# Attention Modelを使ってEncoderの中間層の加重平均を計算
att_f, att_b = self.attention(self.fs, self.bs, self.h)
# Decoderの中間ベクトル、順向きのAttention、逆向きのAttentionを使って
# 次の中間ベクトル、内部メモリ、予測単語の計算
t, self.c, self.h = self.decoder(w, self.c, self.h, att_f, att_b)
return t
def reset(self):
"""
インスタンス変数を初期化する
:return:
"""
# 内部メモリ、中間ベクトルの初期化
self.c = Variable(self.ARR.zeros((self.batch_size, self.hidden_size), dtype='float32'))
self.h = Variable(self.ARR.zeros((self.batch_size, self.hidden_size), dtype='float32'))
# Encoderの中間ベクトルを記録するリストの初期化
self.fs = []
self.bs = []
# 勾配の初期化
self.zerograds()
順向きのEncoder、逆向きのEncoder、Decoderと全部で3つのLSTMを使っています。
forwardの計算やtrainの計算はSeq2Seqの時と同じです。
作成したコードは
https://github.com/kenchin110100/machine_learning/blob/master/sampleAttSeq2Seq.py
にあります。
実験
コーパス
前回と同じように対話破綻コーパスを使用しました。
https://sites.google.com/site/dialoguebreakdowndetection/chat-dialogue-corpus
実験結果
発話内容も前回と同じように4種類
- token1 = 'おはよう'
- token2 = '調子はどうですか?'
- token3 = 'お腹が空きました'
- token4 = '今日は暑いです'
Epochごとに応答を見ていきましょう。
まず1Epoch
発話: おはよう => 応答: ['そう', 'です', 'ね', '</s>']
発話: 調子はどうですか? => 応答: ['はい', '、', '何', 'を', '見', 'て', 'ます', 'か', '?', '</s>']
発話: お腹が空きました => 応答: ['はい', '</s>']
発話: 今日は暑いです => 応答: ['はい', '、', '何', 'を', '見', 'て', 'ます', 'か', '?', '</s>']
そんなに、いやらしい目つきをしていましたか・・・
3Epoch
発話: おはよう => 応答: ['こんにちは。', '</s>']
発話: 調子はどうですか? => 応答: ['そう', 'です', '</s>']
発話: お腹が空きました => 応答: ['熱中症', 'に', '気', 'を', 'つけ', 'て', 'ます', 'か', '?', '</s>']
発話: 今日は暑いです => 応答: ['熱中症', 'に', '気', 'を', 'つけ', 'ない', 'ん', 'です', 'か', '?', '</s>']
5Epoch
発話: おはよう => 応答: ['ありがとう', '</s>']
発話: 調子はどうですか? => 応答: ['スイカ', 'は', '好き', 'です', 'ね', '</s>']
発話: お腹が空きました => 応答: ['熱中症', 'に', '気', 'を', 'つけ', 'て', 'たい', 'です', 'か', '?', '</s>']
発話: 今日は暑いです => 応答: ['熱中症', 'に', '気', 'を', 'つけ', 'て', 'たい', 'です', 'か', '?', '</s>']
熱中症はもうわかったから・・・
7Epoch
発話: おはよう => 応答: ['こんばんは', '</s>']
発話: 調子はどうですか? => 応答: ['スイカ', 'は', '大好き', 'です', 'ね', '</s>']
発話: お腹が空きました => 応答: ['ばい', 'ばい', '</s>']
発話: 今日は暑いです => 応答: ['熱中症', 'に', '気', 'を', 'つけ', 'ない', 'ん', 'です', 'か', '?', '</s>']
おはよう => こんばんわ は、ひどいですね・・・
なんかSeq2Seqの時よりも精度が悪くなった気が・・・
「調子はどうですか?」という発話に対してはSeq2Seqの時と共通してうまく返せてないですね。
おそらく「調子」という単語がコーパスの中で使われていなかったのだと思います。
元が対話破綻コーパスなので破綻した結果が返ってきている、つまりこれでうまく学習できているのかも・・・
損失の合計値の推移や計算時間の比較は最後にまとめて行います。
結論
chainerを使ってSeq2Seq + Attention Modelの計算を行いました。
Seq2Seqだけの時と比較して計算時間がものすごく長くなったように感じました。
その辺の比較はいずれ・・・
次回はCopyNetの実装を行います・・・行いたいです。