はじめに
この記事は、データ分析のトレーニングのために、kaggleのKernelを写経し、自分なりに解説・理解していく記事です。間違いなどありましたら、ご指摘頂けると幸いです。
本日のコンペとKernel
コンペは前回に引き続きタイタニック。コードはこちらの内容を写経していきます。
流れとポイント
- 学習用データ、検証用データの両方を使い、欠損値の補完を行う。
- 年齢の欠損値は、決定木で予測する。
コード
ライブラリーの読み込み
library("rpart")
library("rpart.plot")
rpartは決定木を用いた分析を行うためのライブラリーです。
決定木に関しては@RINDOさんの機械学習初心者が決定木を作ってみるの記事にかかれている、
要は
if - elseを大量に作る。 ってことです。
の説明がとてもわかりやすいと感じました。
非常に雑な例えですが、
もし体重が60kg以下なら(if!!)、肥満ではない。
60kg以上の場合(else!!)、身長が170cm以上なら肥満ではない。
それ以外は肥満。
といったように、最も正しそうな分け方を作り、それを何度も繰り返していく、といった感じです。
rpart.plotは、上記の分岐を図として作成してくれるライブラリーです。図はこの記事の最後の方で作成して掲載します。
データの読み込み
train <- read.csv("../input/train.csv")
test <- read.csv("../input/test.csv")
test$Survived <- 0
read.csv()を使って、学習用データ(train)と、検証用データ(test)を読み込みます。
test$Survived <- 0とありますが、この段階で検証用データ内に、目的変数となるSurvived列を追加しています。
これは、この後の手順でrbindを用いて学習用データと検証用データをバインドするのですが、その際列が一致していないとエラーが発生し、バインド出来ないからです。
ちなみに、dplyr::bind_rowsを利用すると、列が一致していなくてもバインド出来ます。ただし、一致しなかった列(足りなかった列)の値はNAになってしまいます。
前処理
combi <- rbind(train, test)
combi$Name <- as.character(combi$Name)
combi <- rbind(train, test)
学習用データとテスト用データをバインドし、一つのデータフレームにします。
combi$Name <- as.character(combi$Name)
乗客の名前が記載されているName列がfactor型になっているので、それをcharacter型に変えます。
strsplit(combi$Name[1], split='[,.]')
# [[1]]
# [1] "Braund" " Mr" " Owen Harris"
strsplit(combi$Name[1], split='[,.]')[[1]]
# [1] "Braund" " Mr" " Owen Harris"
strsplit(combi$Name[1], split='[,.]')[[1]][2]
# [1] " Mr"
この3行は特に何かの処理を行うためのものではなく、処理結果の例示を行い、この後のコードの理解をより深めるためのものだと思われます。
(コメントとして、出力結果も記載しています)
また、strsplit()は、文字列をsplitでマッチした部分で分割する関数です。
[]は正規表現で、[]内に入力された文字のいずれかと一致、という意味です。今回は.か,のいずれかと一致したら、そこで分割するになります。
combi$Title <- sapply(combi$Name, FUN=function(x) {strsplit(x, split='[,.]')[[1]][2]})
combi$Title <- sub(' ', '', combi$Title)
先程例示した中の3番目を利用して、Name列からMr、Masterといった敬称を抜き出し、新しいTitle列に代入しています。sapplyは、ベクトルやデータフレームに対して、ある関数を適用させる関数。これによって、Name列の各行に対して敬称を抜き出すことが出来ています。
sub()は文字列の置換を行う関数です。第一引数の文字を、第二引数の文字に置換します。第三引数は適用する文字ベクトルです。今回はTitle列からスペースを除去するのに利用しています。
combi$Title[combi$PassengerId == 797] <- 'Mrs' # female doctor
combi$Title[combi$Title %in% c('Lady', 'the Countess', 'Mlle', 'Mee', 'Ms')] <- 'Miss'
combi$Title[combi$Title %in% c('Capt', 'Don', 'Major', 'Sir', 'Col', 'Jonkheer', 'Rev', 'Dr', 'Master')] <- 'Mr'
combi$Title[combi$Title %in% c('Dona')] <- 'Mrs'
combi$Title <- factor(combi$Title)
**いきなり何してるんだ!?**って感じですが、Title列に含まれる敬称以外の文字を置換しています。置換前のデータを一応見てみましょう。
table(combi$Title)
Capt Col Don Dona Dr Jonkheer Lady Major Master
1 4 1 1 8 1 1 2 61
Miss Mlle Mme Mr Mrs Ms Rev Sir the Countess
260 2 1 757 197 2 8 1 1
Captやら、Jonkheerやら、敬称ではないものが多く含まれています。これらを、Mrsや、Mrという値に置換しています。
combi$Embarked[c(62, 830)] <- 'S'
combi$Embarked <- factor(combi$Embarked)
62,830行目のEmbarked列(乗船した港)が空欄のため、共にSを入れています。多くの乗客がS(サザンプトン港)から乗船したので、そうしているようです。
その後、Embared列をfactor型に変えます。
combi$Fare[1044] <- median(combi$Fare, na.rm=TRUE)
1044行目のFare列(運賃)は空欄になっています。ここを補完するために、NAを除いたFareの中央値を利用しています。
combi$family_size <- combi$SibSp + combi$Parch + 1
新たな列family_seizeを作成。計算は同乗している兄弟/配偶者の数 + 同乗している親/子供の数になっています。
家族がいると、「その人を守りながらorその人と行動を共にしながら、脱出を行う」ということが想像できるので、説明変数として加えているのだと思います。
predicted_age <- rpart(Age ~ Pclass + Sex + SibSp + Parch + Fare + Title + family_size,
data = combi[!is.na(combi$Age),],
method = 'anova')
combi$Age[is.na(combi$Age)] <- predict(predicted_age, combi[is.na(combi$Age),])
Age列の欠損を補完するために、決定木でAgeを予測しています。
rpart()内のAgeが目的変数、Pclass + Sex + SibSp + Parch + Fare + Title + family_sizeが説明変数になっています。
data = combi[!is.na(combi$Age),]で、利用するデータはcombiデータ内Age列がNAではないものを指定しています。
method =は、目的変数によって使い分けるようで、anova、poisson、class、expのいずれかを選択することが出来ます。おそらく、目的変数が「量的変数」の場合anovaを指定するみたいです。「質的変数」時は、class。その他、目的変数が「サバイバルオブジェクト」「生起を表す2カラム」などの時、指定を変えるようですが、よくわかりませんでした。。。(参考)
predict()は、作成した予測モデルを元に、実際に値を予測する関数。第一引数に予測モデル、第二引数に予測する値を入れます。
生存予測モデルの作成
ここまでの手順でデータの前処理が終わりました。ここから、実際に生存したかどうかの予測を行っていきます。
train_new <- combi[1:891,]
test_new <- combi[892:1309,]
test_new$Survived <- NULL
前処理の段階で、学習用・検証用データを結合していたので、それを再度分割します。
元々検証用データにはSurvived列は存在していなかったので、そこも忘れずに消します。
train_new$Cabin <- substr(train_new$Cabin, 1, 1)
train_new$Cabin[train_new$Cabin == ''] <- 'H'
train_new$Cabin[train_new$Cabin == 'T'] <- 'H'
test_new$Cabin <- substr(test_new$Cabin, 1, 1)
test_new$Cabin[test_new$Cabin == ''] <- 'H'
train_new$Cabin <- factor(train_new$Cabin)
test_new$Cabin <- factor(test_new$Cabin)
A11といった形式のキャビン番号を、先頭のアルファベット一文字にします。今回は部屋の番号までは予測に利用しない方針のようです。欠損値、及びTは一律Hにします。なぜHかは不明。おそらく、既存のアルファベットと重複させずに区別したかったのかな、と思っています。
加えて、これは分割前にやっても良かったのではないかという疑問もありますが、スルーします。
上記の処理を学習用・検証用データそれぞれに対して行い、factor型に変更します。
str(train_new)
str(test_new)
作成した学習用データ、検証用データの中身を確認。みなさん各々確認しましょー!
my_tree <- rpart(Survived ~ Age + Sex + Pclass + family_size,
data = train_new,
method = 'class',
control = rpart.control(cp = 0.0001))
summary(my_tree)
いよいよ予測モデルを作成します。目的変数はSurvived、説明変数はAge、Sex、Pclass、family_sizeの4つにしています。元のコードではコメントアウトさせた状態で、説明変数を変えた式も記述されていました。3つの中で、これが一番予測精度が高かったのでしょうか。
method =はclassを選択。
control =は詳細制御オプションのことで、cpは"明らかに価値のない分割を切り捨てることによって計算時間を節約することです。(グーグル翻訳)ということみたいで、指定しておくと良い(のかな?)。
summary()で予測モデルの確認をしていますが、見方がほとんどわかりませんでした...
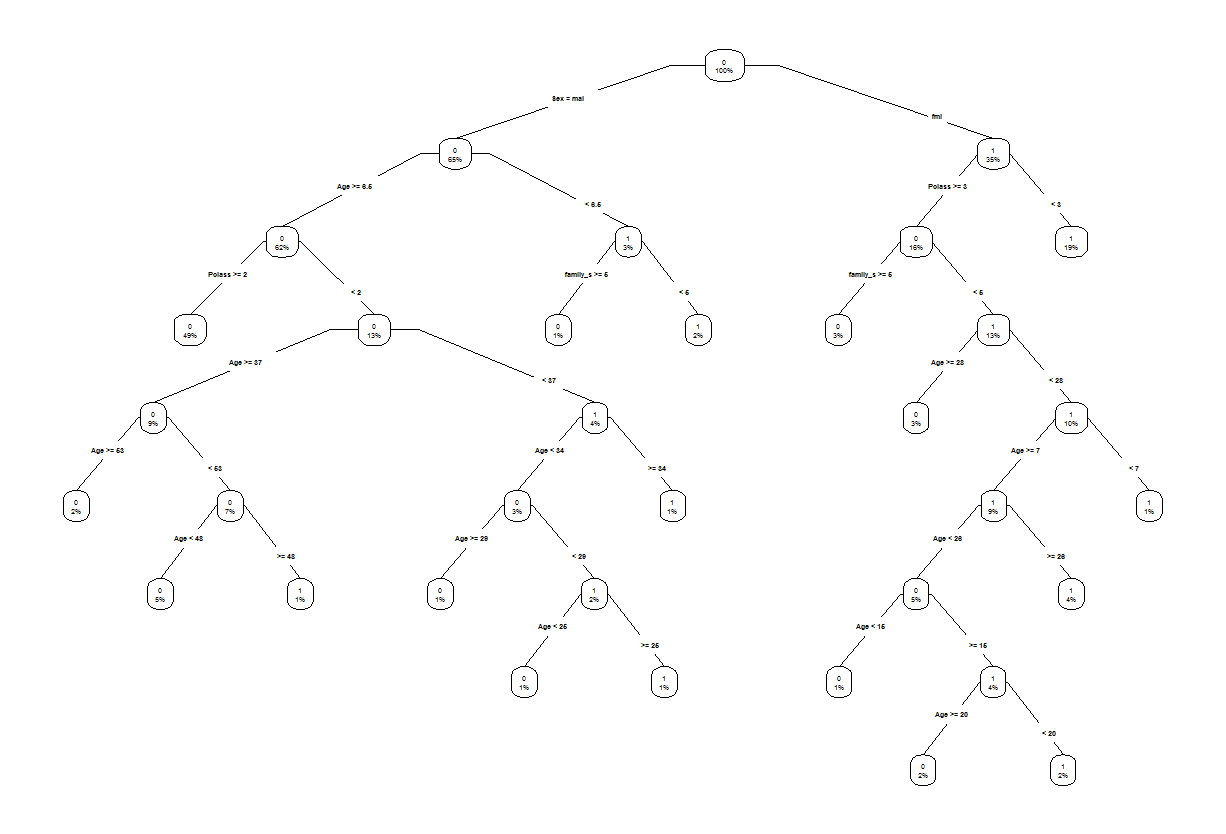
prp(my_tree, type = 4, extra = 100)
prp()で、作成した決定木のビジュアル化をします。
type =で、ビジュアル化した際のデザインを変えられます。引数は0~5まで。
extra =で、ビジュアル化した際に表示させる値(割合等)を指定できます。引数は0~11+100。
作成したものは下図(小さくて見にくい...!!)
my_prediction <- predict(my_tree, test_new, type = 'class')
head(my_prediction)
predict()を使い、作成した予測モデルを元に生存予測を行います。
第一引数は予測モデル、第二引数に予測するデータを指定します。
type =はclassを指定しています(予測対象が2値の質的変数だから、だと思われる...)
vector_passengerid <- test_new$PassengerId
my_solution <- data.frame(passengerId = vector_passengerid, Survived = my_prediction)
head(my_solution)
write.csv(my_solution, file = "my_solution.csv",row.names=FALSE)
最後に、kaggleに提出するためにデータを作成します。
test_new$PassengerIdで、検証用データから乗客のID部分のみ取得します。
取得した乗客のIDと、予測した値を1つのデータフレームにし、csvとして出力しています。
以上!
所感とか
- 欠損値を補完するには、データへの深い理解も、センスも必要だなと感じる。今回、
Ageの補完で決定木を用いているが、その説明変数として新たにTitle列を作成している。確かに、既婚・未婚と言った情報は、年齢の予測には役立ちそうに思える。 - まだまだわからないことが多い。「多分こうかな...?」が多すぎる。日々勉強が必要。
というわけで今日は以上でした。ばいばーい!