はじめに
家計簿や業務ログのように「備考欄」に自由記述テキストが溜まることは多いですが、
内容を分類したいときに Streamlitアプリ として実装すると手軽にGUIベースで可視化できます。
何ができるのか(したいのか?)
表形式のデータをざっくり分類、分析したい。その際にわざわざコードを見なくとも画面上でできるようにしたい。
用語解説(簡単に)
Mecab:日本語用の形態素解析ツール。日本語そのものは単語で区切る文章ではないため、機械は分類しにくいのを、自動的に単語に分けてくれる。
トピック分析:クラスタリングされた分類の代表ワードを元に、ラベリングしてどんな内容が多いかを分析するやり方。今回はあくまでそのための補助ツールですが、代表語をLLMなどでラベルするといいかもです。
この記事では、以下の流れを実現します:
- CSVアップロード
- 対象列を選択(複数可)
- MeCabで形態素解析 → TF-IDFベクトル化
- KMeansでクラスタリング
- クラスタごとの代表語とクラスタ結果を表示・ダウンロード
環境構築
必要環境
- Python 3.9〜3.11
- Windows11(CMDで動作確認済)
ライブラリインストール
pip install streamlit mecab-python3 ipadic neologdn scikit-learn pandas numpy
コード
app.py として保存します。
import streamlit as st # Streamlitライブラリを読み込む → 入力例: なし 出力例: stモジュール利用可能
import pandas as pd # データ処理用ライブラリ → 入力例: pd.DataFrame({"a":[1,2]}) 出力例: a列を持つDataFrame
import numpy as np # 数値計算用ライブラリ → 入力例: np.array([1,2,3]) 出力例: array([1,2,3])
import re # 正規表現処理用 → 入力例: re.sub(r"\d","X","a1b2") 出力例: "aXbX"
import neologdn # 日本語正規化用ライブラリ → 入力例: neologdn.normalize("テスート") 出力例: "テスト"
import MeCab # MeCab形態素解析ライブラリ → 入力例: MeCab.Tagger("-Ochasen") 出力例: Taggerオブジェクト
import ipadic # IPA辞書設定ライブラリ → 入力例: ipadic.MECAB_ARGS 出力例: MeCab初期化引数
from sklearn.feature_extraction.text import TfidfVectorizer # TF-IDFベクトル化 → 入力例: TfidfVectorizer() 出力例: Vectorizerオブジェクト
from sklearn.cluster import KMeans # KMeansクラスタリング → 入力例: KMeans(n_clusters=3) 出力例: KMeansモデル
# MeCab初期化
tagger = MeCab.Tagger(ipadic.MECAB_ARGS) # MeCabをIPA辞書で初期化 → 入力例: "寿司を食べる" 出力例: 形態素解析結果
def normalize(text): # テキスト正規化関数
text = neologdn.normalize(str(text)) # 全角・半角・長音記号を正規化 → 入力例: "テスート" 出力例: "テスト"
text = text.lower() # 小文字化 → 入力例: "ABC" 出力例: "abc"
text = re.sub(r"[0-9]+", " ", text) # 数字を削除 → 入力例: "abc123" 出力例: "abc "
text = re.sub(r"[!-/:-@[\]^_`「」、。・…()[]【】=+*%¥¥,.。「」『』\s]+", " ", text) # 記号を削除 → 入力例: "テスト!" 出力例: "テスト"
return text.strip() # 前後の空白を除去して返す → 入力例: " テスト " 出力例: "テスト"
def tokenize(text): # MeCabでトークン化する関数
text = normalize(text) # 正規化処理 → 入力例: "テスート123" 出力例: "テスト"
node = tagger.parseToNode(text) # MeCabで形態素解析 → 入力例: "冷凍食品" 出力例: ノードオブジェクト
tokens = [] # トークン格納リスト
while node: # ノードがある限り繰り返し
features = node.feature.split(",") # 品詞情報などを分割 → 入力例: "名詞,一般,*,*,*,*,冷凍食品" 出力例: ["名詞","一般",...,"冷凍食品"]
pos = features[0] # 品詞大分類を取得 → 入力例: ["名詞",...] 出力例: "名詞"
base = features[6] if len(features) > 6 else node.surface # 原形を取得(なければ表層形) → 入力例: "冷凍食品" 出力例: "冷凍食品"
if pos in ["名詞", "動詞"] and base != "*": # 名詞・動詞のみを対象
tokens.append(base) # トークンに追加 → 出力例: ["冷凍食品"]
node = node.next # 次のノードへ
return tokens # トークンリストを返す → 出力例: ["冷凍食品","買う"]
st.title("CSVトピック分析ツール") # タイトルを表示 → 出力例: 画面に「CSVトピック分析ツール」と表示
uploaded_file = st.file_uploader("CSVファイルをアップロード", type=["csv"]) # CSVアップロードUIを表示 → 出力例: ファイル選択ボタン
if uploaded_file is not None: # ファイルがアップロードされた場合
df = pd.read_csv(uploaded_file) # CSVをDataFrameとして読み込む → 入力例: sample.csv 出力例: DataFrame
st.subheader("CSVプレビュー") # 小見出しを表示 → 出力例: 「CSVプレビュー」
st.dataframe(df.head()) # CSVの先頭部分を表示 → 出力例: DataFrame先頭5行
# 分類対象列を選択(複数可)
cols = st.multiselect("分類に使う列を選んでください", df.columns.tolist()) # 列選択UI → 入力例: ["備考","カテゴリ"] 出力例: 選択結果
if len(cols) == 0: # 選択が空の場合
st.warning("少なくとも1列を選んでください") # 警告を表示 → 出力例: 黄色い警告メッセージ
else:
# 選択列を結合してテキスト化
notes = df[cols].astype(str).fillna("").agg(" ".join, axis=1) # 選択列を結合 → 入力例: 備考="寿司" カテゴリ="外食" 出力例: "寿司 外食"
# TF-IDFベクトル化
vectorizer = TfidfVectorizer(tokenizer=tokenize, token_pattern=None) # トークン化関数を指定したTF-IDFベクトライザ → 出力例: Vectorizerオブジェクト
X = vectorizer.fit_transform(notes) # TF-IDF行列を生成 → 出力例: (行数×語彙数)の疎行列
feature_names = np.array(vectorizer.get_feature_names_out()) # 語彙リストを取得 → 出力例: ["寿司","ご飯",...]
# クラスタ数をスライダーで選択
k = st.slider("クラスタ数 (k)", min_value=2, max_value=10, value=5) # スライダーUI → 入力例: 5 出力例: k=5
model = KMeans(n_clusters=k, random_state=42) # KMeansモデルを定義 → 出力例: KMeansオブジェクト
labels = model.fit_predict(X) # 学習+クラスタ予測 → 出力例: [0,1,2,...]
df["cluster"] = labels # DataFrameにクラスタ番号を追加 → 出力例: 備考ごとのクラスタIDが入る
# クラスタごとの代表語抽出
def get_top_terms_per_cluster(X, labels, feature_names, topn=5): # 代表語抽出関数
result = {} # 結果格納用
for c in range(max(labels) + 1): # 各クラスタをループ
idx = np.where(labels == c)[0] # クラスタcに属するインデックスを取得 → 出力例: [0,2,5]
if len(idx) == 0:
continue # 空クラスタはスキップ
centroid = X[idx].mean(axis=0).A1 # クラスタ内平均ベクトルを計算
top_idx = centroid.argsort()[::-1][:topn] # 上位topn単語のインデックスを取得
result[c] = feature_names[top_idx].tolist() # インデックスを語彙に変換 → 出力例: ["寿司","ご飯"]
return result # 出力例: {0:["寿司","ご飯"],1:["洗剤","日用品"]}
top_terms = get_top_terms_per_cluster(X, labels, feature_names, topn=5) # クラスタ代表語を取得
st.subheader("クラスタごとの代表語") # 小見出しを表示
for c, terms in top_terms.items(): # 各クラスタの代表語をループ表示
st.write(f"Cluster {c}: {', '.join(terms)}") # 出力例: "Cluster 0: 寿司, ご飯"
st.subheader("クラスタ結果プレビュー") # 小見出しを表示
st.dataframe(df[cols + ["cluster"]].head(20)) # 選択列とクラスタ番号を先頭20件表示 → 出力例: DataFrame
# ダウンロードボタン
csv_out = df.to_csv(index=False, encoding="utf-8-sig") # DataFrameをCSV文字列に変換 → 出力例: CSVデータ
st.download_button("結果をCSVでダウンロード", csv_out, file_name="clustered.csv", mime="text/csv") # ダウンロードボタンを表示 → 出力例: CSV保存
起動方法
-
作業用フォルダを作成(例:
C:\topic_app) -
app.pyを保存 -
CMDで移動:
cd C:\topic_app -
Streamlitアプリを起動:
streamlit run app.py -
ブラウザが開き、
http://localhost:8501で利用可能
実行例
1. CSVアップロード画面
CSVをアップロードすると、プレビューが表示されます。
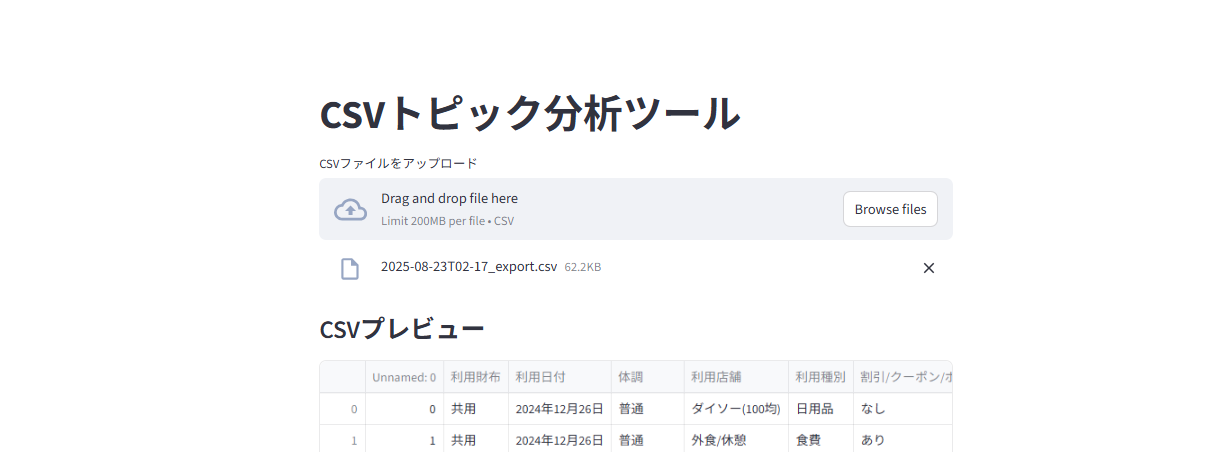
2. 列選択
分析対象にしたい列(単数でも複数でもOK)を選択します。
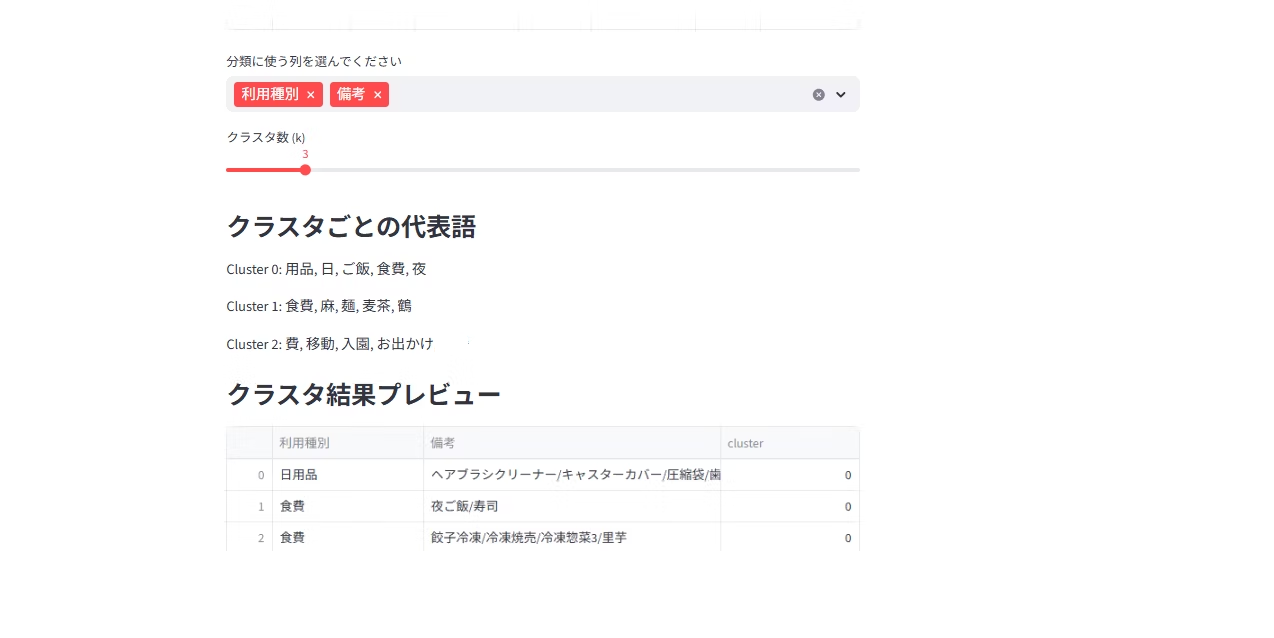
3. クラスタリング結果
- 各クラスタの代表語が表示される(クラスタ数によって粒度を変更可能)
- DataFrameにクラスタ番号が追加される
- 結果はCSVとしてダウンロード可能
まとめ
- MeCab × TF-IDF × KMeans で簡易的なトピック分析が可能
- Streamlitに組み込むと、誰でもCSVをアップロードして試せるツールになる
- 列選択を柔軟にできるため、家計簿や業務ログなど様々なフォーマットに対応可能
残課題
- 代表語リストの抽出精度を向上させて、分析への貢献値を上げたい。