はじめに
本記事は機械学習の知識が0だった人間が、1ヶ月間勉強した成果をまとめた内容になります。
具体的なコードを用いて、1行ずつ「何をやっているのか?」を自分の理解で綴ります。
厳密ではなかったり、間違っていることを書いているかもしれませんがご了承ください。
CNNとは?
Convolutional Neural Networkの略称です。
日本語だと畳み込みニューラルネットワークと呼ばれています。
機械学習と一言で言っても種類は様々です。その中の一つがCNNです。
画像分類でよく用いられるニューラルネットワークです。
Kerasとは?
機械学習にはscikit-learn、Chainer、TensorFlowといった様々なライブラリが存在します。
KerasはGoogleが開発したTensorFlowをベースに利用することが可能なライブラリです。
KerasでCNN
Kerasを使ってCNNで0~9の手書き文字の画像分類をやっていきます。
MNISTと呼ばれる手書き文字のデータセットを利用します。

機械学習のHello worldですね。
早速ですが分類するコードを貼り付けます。
import tensorflow as tf
# 0~9の手書き文字MNISTのデータセットを読み込む
(training_images, training_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data()
# 画像データの形式を変更する
training_images = training_images.reshape(training_images.shape[0], 28, 28, 1)
test_images = test_images.reshape(test_images.shape[0], 28, 28, 1)
# 画像データを正規化する
training_images = training_images / 255.0
test_images = test_images / 255.0
# ラベルデータを1-of-K表現にする
training_labels = tf.keras.utils.to_categorical(training_labels)
test_labels = tf.keras.utils.to_categorical(test_labels)
# CNNのモデルを作成する
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(64, (3,3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
# 任意のオプティマイザと損失関数を設定してモデルをコンパイルする
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# ネットワーク各層の出力内容を確認する
model.summary()
# モデルをトレーニングする
model.fit(training_images, training_labels, epochs=5)
# テストデータで精度を確認する
test_loss = model.evaluate(test_images, test_labels)
以上です。
これだけのコードで画像分類が可能です!
ここからは1行ずつ何をやっているのかを丁寧に見ていこうと思います。
データの前処理
import tensorflow as tf
今回はtf.kerasを利用していくのでtensorflowをインポートします。
(training_images, training_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data()
手書き文字の画像データが存在しないと始まりません。
この1行でトレーニング用画像60000枚とテスト用画像10000枚が手に入ります。
今回は画像に対して答え(ラベル)が存在する教師あり学習になります。
1と書かれている画像にはラベル1、9と書かれている画像にはラベル9、即ち予めその画像が何を意味するかの答えを持っているデータセットになります。

training_images = training_images.reshape(training_images.shape[0], 28, 28, 1)
training_images.shape[0]はトレーニング用画像の数を意味します。
後述する画像データ入力の形状に変形するためreshapeを行なっています。
test_images = test_images.reshape(test_images.shape[0], 28, 28, 1)
テスト用画像データに対しても同じ処理を行います。
training_images = training_images / 255.0
トレーニング用画像データを正規化(Normalization)します。
ここで言うところの正規化とはピクセル値を0〜1の範囲に収める作業になります。
今回の手書き文字画像は**グレースケール(黒から白までの色の変化を0~255の値で表現)**です。
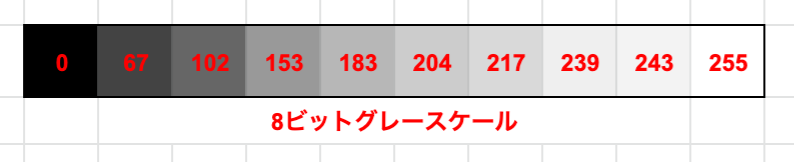
なので、各ピクセル値を255で割ることによって0~1の範囲に収めることができますね。


**左:正規化前(0~255)**右:正規化後(0~1)
正規化(特徴スケーリング)がなぜ必要か?
例えば、年齢と身長を特徴量データとした時に、26歳と168センチというデータを扱うことになると思います。年齢は0~100歳、身長は30センチ〜200センチといったようにデータの取る範囲と値が異なる場合があります。なので、データのスケールを揃えてあげる作業が必要になってくるわけです。
画像分類の場合も0~1の間でスケーリング(今回は正規化)することによって精度が良くなるらしいです。
補足
 因みにグレースケールではなく**RGBの場合**はこんな感じでRとGとBの次元を持っています。
* * *
```python
test_images = test_images / 255.0
```
テスト用画像データに対しても同じ処理を行います。
* * *
```python
training_labels = tf.keras.utils.to_categorical(training_labels)
```
次はトレーニング用ラベルデータを入力する形状に変形します。
取得した直後のラベルデータの中身を見てみましょう。
因みにグレースケールではなく**RGBの場合**はこんな感じでRとGとBの次元を持っています。
* * *
```python
test_images = test_images / 255.0
```
テスト用画像データに対しても同じ処理を行います。
* * *
```python
training_labels = tf.keras.utils.to_categorical(training_labels)
```
次はトレーニング用ラベルデータを入力する形状に変形します。
取得した直後のラベルデータの中身を見てみましょう。
 1番目の画像が5、2番目の画像が0、最後の画像が8ということが一目で分かります。
今回はこれを**to_categorical()**を使って**1-of-K表現**に変換します。
1番目の画像が5、2番目の画像が0、最後の画像が8ということが一目で分かります。
今回はこれを**to_categorical()**を使って**1-of-K表現**に変換します。
 変換後の1番目のラベルデータを見てみましょう。
5だったはずですが、**0と1の長さ10の配列**になっていると思います。
配列の長さは**分類するラベル数(クラス数)**を意味します。
注目すべきは**1の場所**で、**0から数えて5番目だけが1**になっています。
**対象の位置だけを1にして他を0にする**ことで表現するのが1-of-k表現です。
* * *
```python
test_labels = tf.keras.utils.to_categorical(test_labels)
```
テスト用ラベルに対しても同じ処理を行います。
* * *
## モデルの定義
変換後の1番目のラベルデータを見てみましょう。
5だったはずですが、**0と1の長さ10の配列**になっていると思います。
配列の長さは**分類するラベル数(クラス数)**を意味します。
注目すべきは**1の場所**で、**0から数えて5番目だけが1**になっています。
**対象の位置だけを1にして他を0にする**ことで表現するのが1-of-k表現です。
* * *
```python
test_labels = tf.keras.utils.to_categorical(test_labels)
```
テスト用ラベルに対しても同じ処理を行います。
* * *
## モデルの定義
model = tf.keras.models.Sequential
モデルを定義しています。
tf.keras.layers.Conv2D(64, (3,3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
ニューラルネットワークの詳細を見ていきましょう。
1行ずつ見て行く前に大雑把に何をやっているのかを記述します。
入力→畳み込み→プーリング→畳み込み→プーリング→1次元配列化→全結合→出力。
以上です。
基本は畳み込んでプーリングして全結合するだけです。
畳み込み層
tf.keras.layers.Conv2D(64, (3,3), activation='relu', input_shape=(28, 28, 1))
Conv2Dは畳み込みを行うために利用するニューラルネットワークです。
色々引数に取っていますが焦らず1つずつ見ていきましょう。
入力の形状
input_shape=(28, 28, 1)
inputなので入力される画像データの形状が指定されています。
先ほど前処理を行なった画像データの一番最初(確か5でしたよね)の形状を見てみましょう。
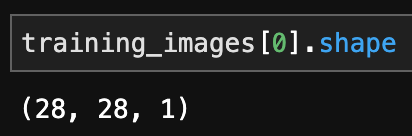
input_shapeと一致しますね!
縦が28ピクセル、横が28ピクセル、グレースケールの画像データであることが分かります。
3次元目の1はチャンネル数を意味するので、色の情報を持っていれば**(28, 28, 3)**となります。
フィルタサイズ
(3,3)
・・・これだけじゃ引数に何を取るのか分からないのでドキュメントを見ていきます。
__init__(
filters,
kernel_size,
strides=(1, 1),
padding='valid',
data_format=None,
dilation_rate=(1, 1),
activation=None,
use_bias=True,
kernel_initializer='glorot_uniform',
bias_initializer='zeros',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
**kwargs
)
どうやらkernel_sizeを取るようです。
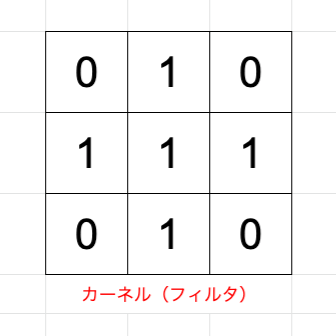
今回は3×3のカーネルサイズを引数に取っているということです。
畳み込みとは?
畳み込みを説明するためにはstridesとpaddingも重要です。
デフォルト値としてstrides=(1, 1)でpadding='valid'であることを把握しておきましょう。
また、カーネルとはフィルタとも呼ばれています。
これで、畳み込みを説明するための材料が揃いました。
ずばり、畳み込みとは
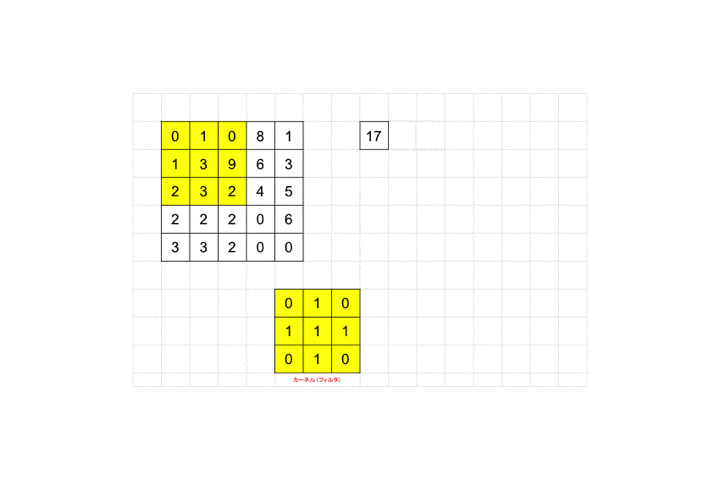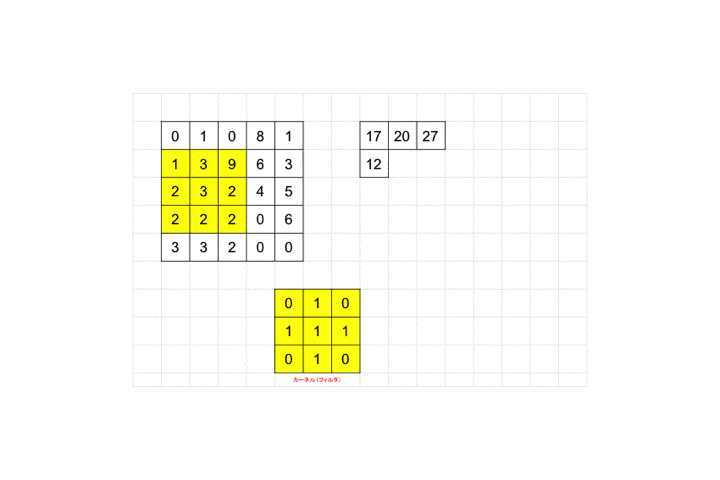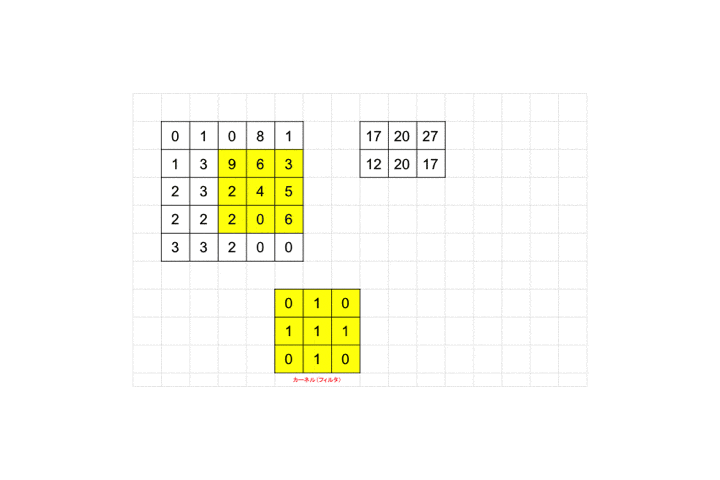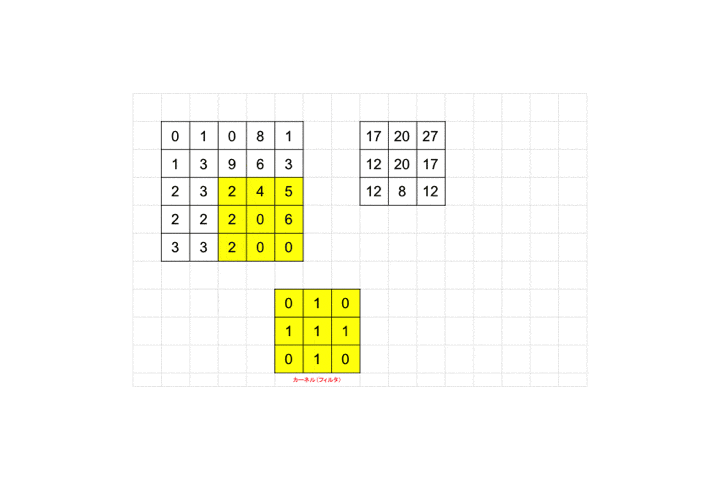
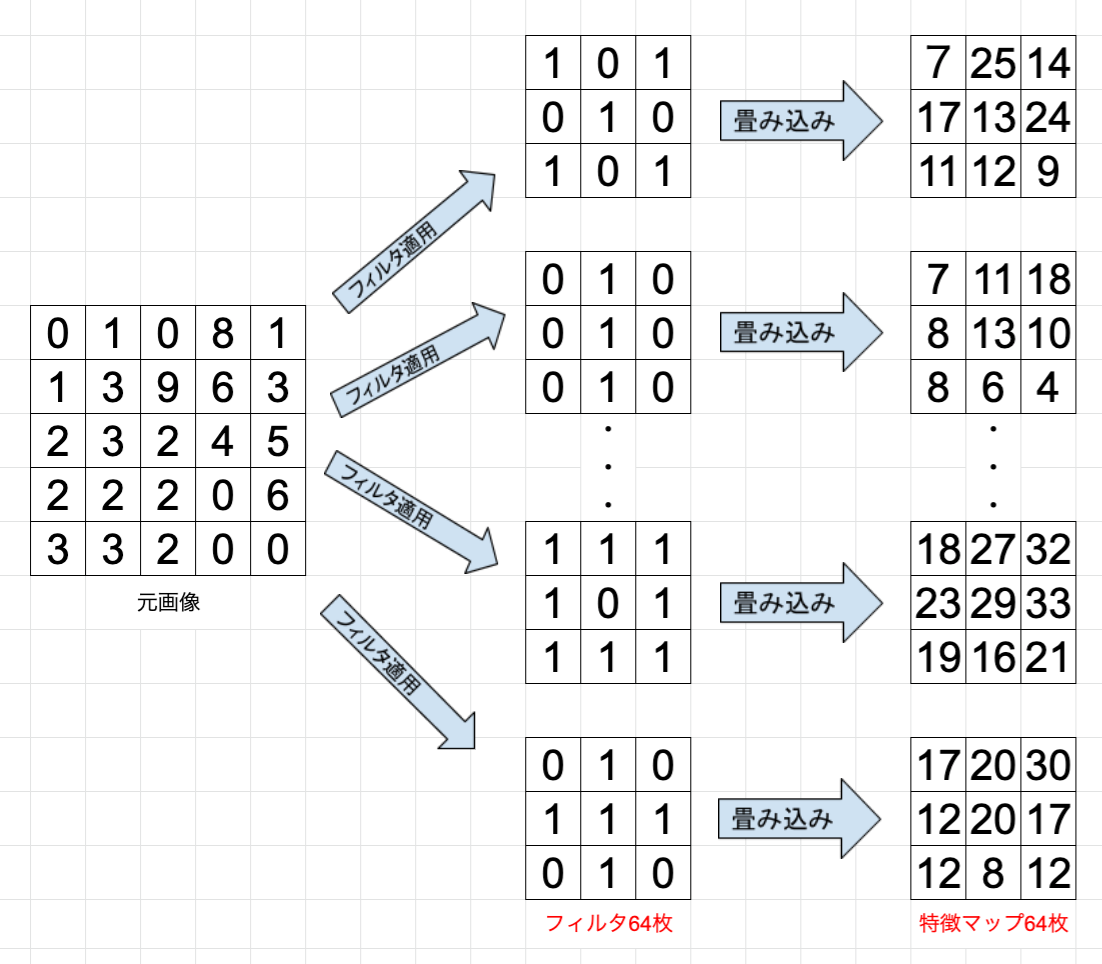
入力画像のピクセル範囲に対してフィルタを適用して行く作業になります。
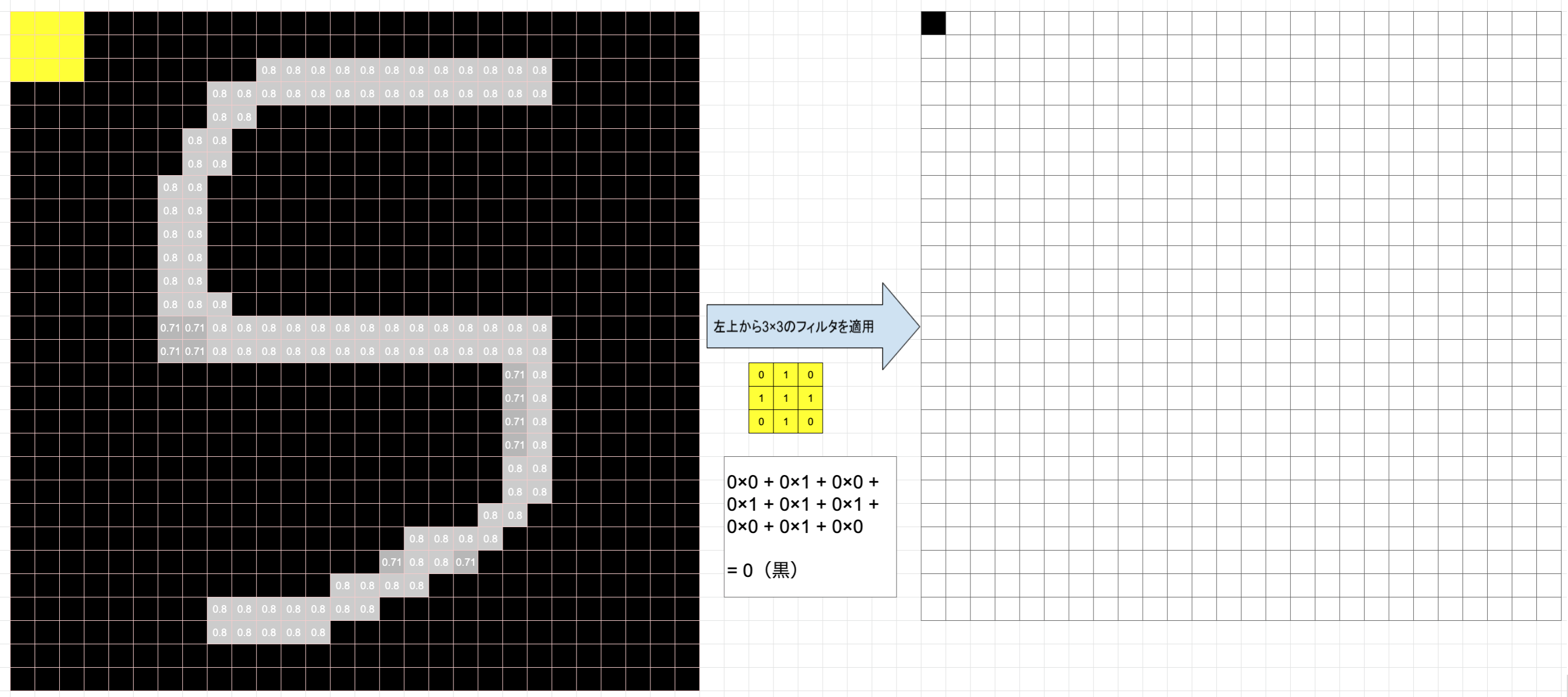
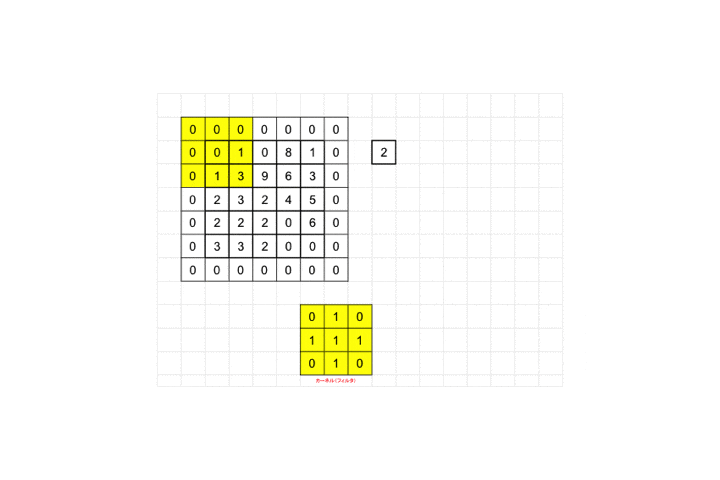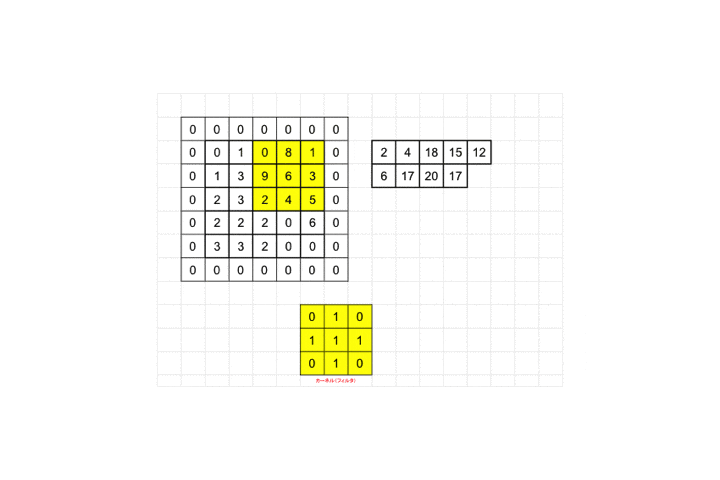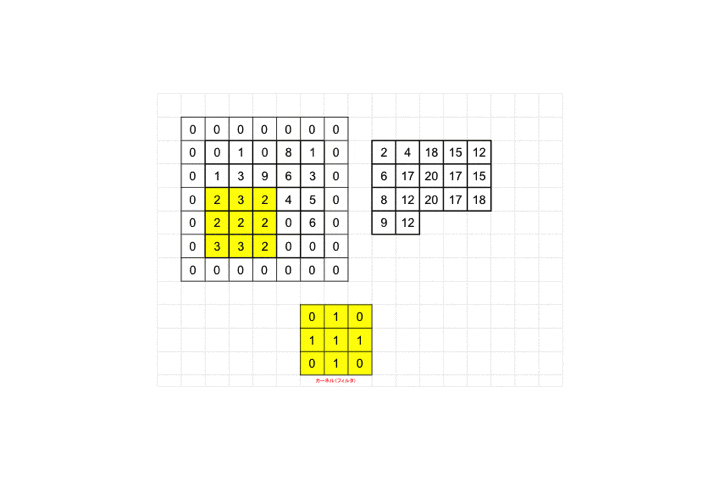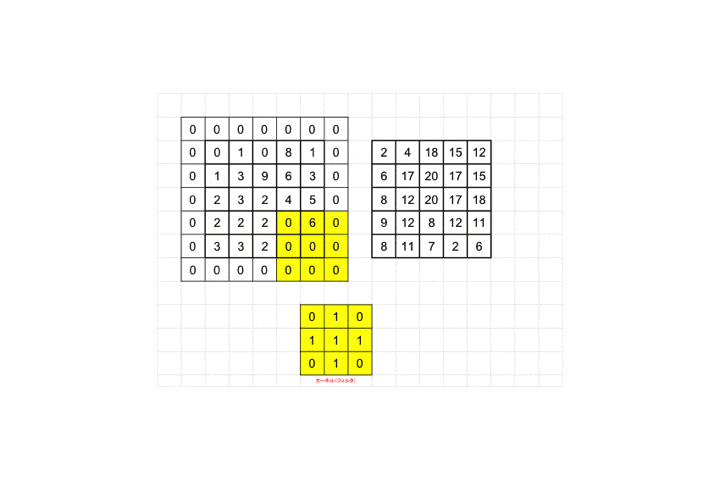
上記図を見ながら説明していきます。
黄色い枠が3×3のカーネル、すなわちフィルタになります。
それを画像ピクセルの左上から適用し、画像ピクセル値と対応するフィルタのピクセル値を掛け合わせ算出された値を足し合わせます。図の例だと画像ピクセル値が全て0なので結果も0となります。適用後のピクセルサイズを見てみましょう。
3×3が1×1のピクセルサイズに畳み込まれていますね。
最後までフィルタを適用していくと全体として28×28の画像が26×26に畳み込まれます。
大きするので、5×5の画像に3×3のフィルタを適用する動きを可視化してみましょう。
サイズを変えないで畳み込むことも可能です。
これを指定するのが先ほど確認したpaddingになります。
デフォルト値は**padding='valid'が指定されており、これは画像そのものにフィルタを適用していくことになります。
padding='same'を指定すると、画像の周りを0パディングすることによってサイズを変えず端の特徴もより捉えることができるようになります。
フィルタを間引くことも可能です。
今はstrides=(1, 1)によって横に1ピクセル縦に1ピクセルずつフィルタを適用していました。
これをstrides=(2, 2)**にするとどうでしょう?可視化すれば一目瞭然だと思います。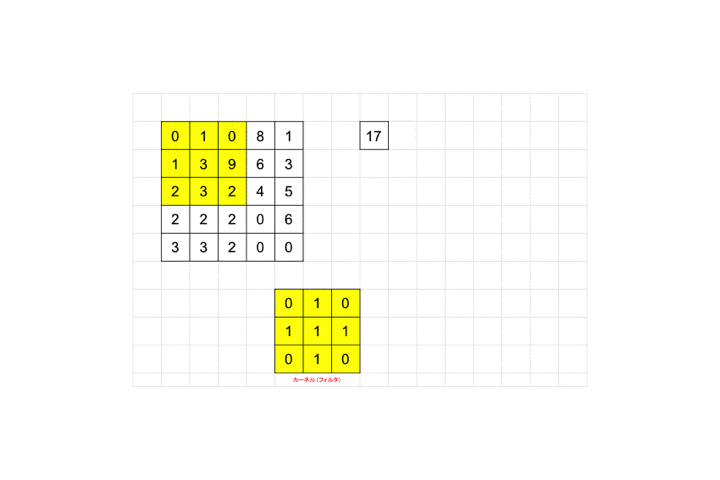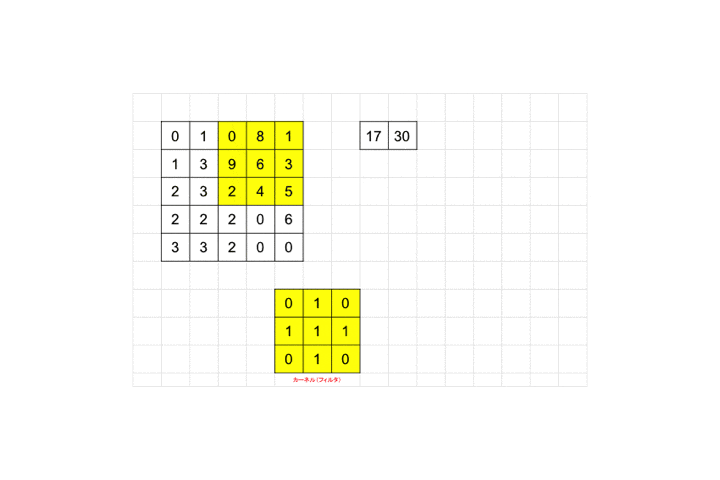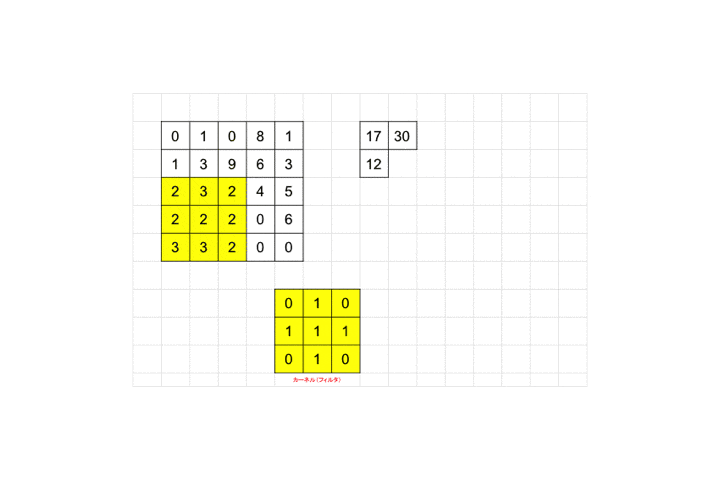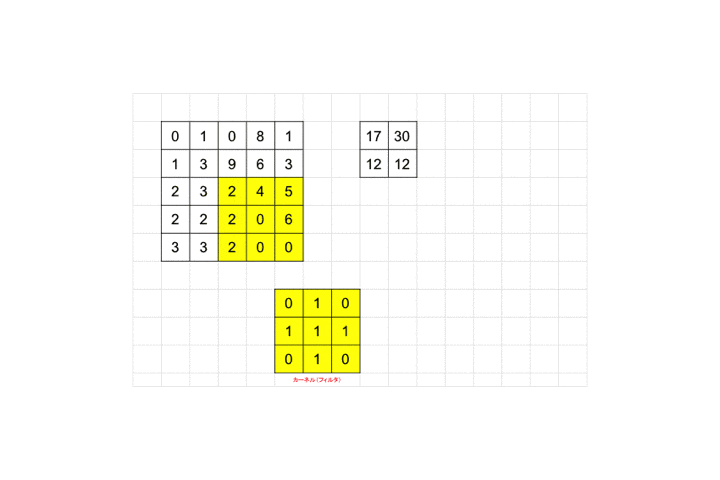
フィルタ適用開始位置が2ピクセル分飛んでフィルタを適用している感じになります。
フィルタ数
64
・・・これだけじゃ引数に何を取るのか分からないので再びドキュメントを見ていきます。
どうやらをfiltersを取るようです。
今回は64枚のフィルタを使っているということです。
今までの例だと1枚のフィルタを適用して1枚の畳み込まれた画像が出力されていることを確認しましたが、実際には64枚のフィルタを使い、64パターンの特徴マップが出力されることになります。
活性化関数
もう一踏ん張りです。最後の引数を見ていきましょう。
activation='relu'
活性化関数に使う関数名を指定しています。
今回は**ReLU関数(ランプ関数)**を利用しています。
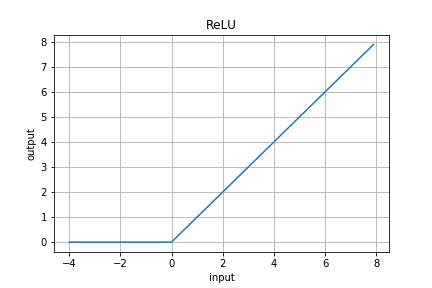
横軸を入力、縦軸を出力と見ると、正の値の場合はそのまま出力し、負の値の場合は0を出力するという関数になります。先ほどのフィルタの例だと全て正の値になっていたのでそのまま出力していましたが、実際には負の値も取ります。
最後にはReLUという活性化関数が適用され、出力される値(特徴マップ)が決まるというわけです。
畳み込み層のまとめ
- 入力画像に対して**カーネル(フィルタ)**を適用する
- フィルタを適用していく**ストライド(移動幅)**を設定する
- フィルタ数を決める
- パディングが必要かどうかを考える
- 最後に活性化関数ReLUを適用する
フィルタサイズやストライド、フィルタ数に関してはハイパーパラメータなので、値を色々変えて学習の変化を試してみると面白いかもしれません。
プーリング層
tf.keras.layers.MaxPooling2D(2,2)
畳み込んだ画像データに対して次はプーリングという作業を行います。
平均値を取るプーリングもありますが、今回は最大値を取るプーリングを行なっていきます。
(2,2)
・・・・ドキュメントを見てきましょう。
__init__(
pool_size,
strides,
padding='valid',
data_format='channels_last',
name=None,
**kwargs
)
どうやらpool_sizeを取るようです。
今回は2×2のプールサイズを引数に取っているということです。
2×2に含まれるピクセルの中で最大の数値を採用するのがMaxPooling2Dです。
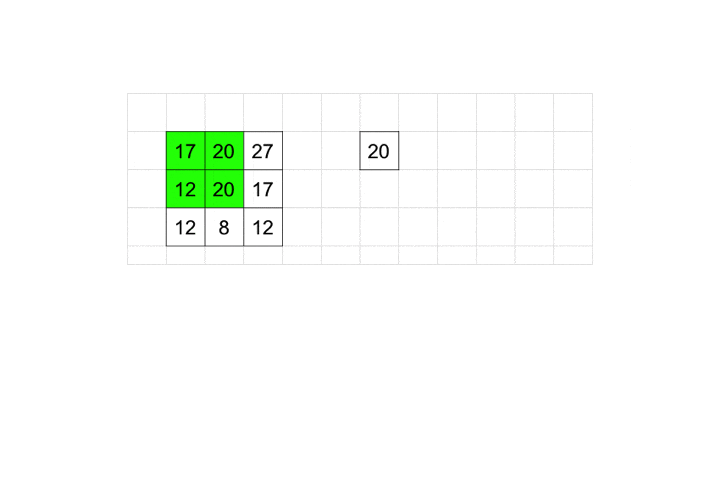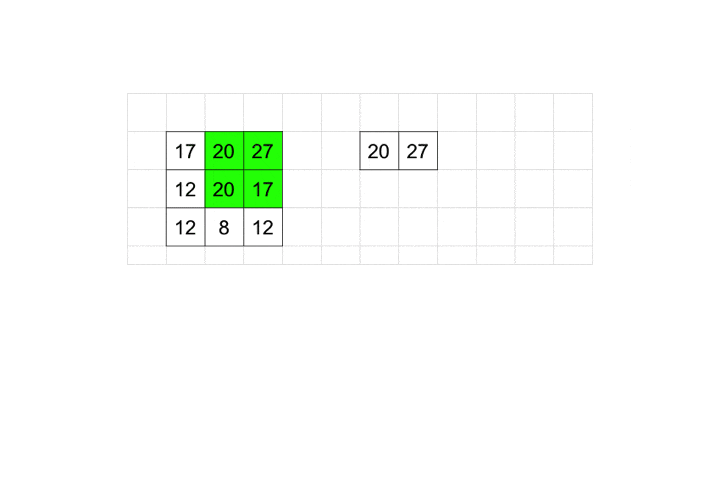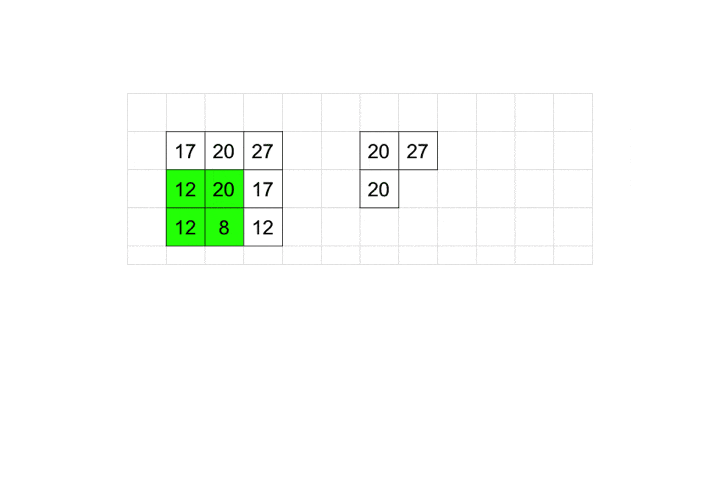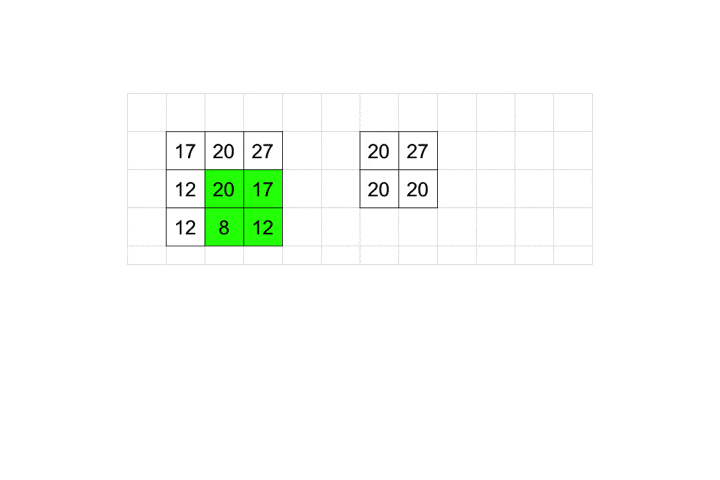
プーリングも畳み込み同様stridesとpaddingを取ることができます。
今回はデフォルト値を利用しているので、動きとしては図のようになります。
プーリングはこれだけです。
層を深くする
1度だけの畳み込み・プーリングだけでも精度は出ると思います。
層を深くすることによって精度が上がるかもしれません。
tf.keras.layers.Conv2D(32, (3,3), activation='relu')
プーリングしたデータに対して今度は32個のフィルタを使って3×3のフィルタを適用します。
tf.keras.layers.MaxPooling2D(2,2)
先ほどと同様に2×2のプーリングを行います。
2回の畳み込みとプーリング後
 2回目のプーリングを終えた時点で、28×28あった画像データが**5×5に圧縮**されたことがわかると思います。
漠然としたオリジナルの画像情報からその画像の特徴だけを振るい落として圧縮した、そんなイメージの理解です。
2回目のプーリングを終えた時点で、28×28あった画像データが**5×5に圧縮**されたことがわかると思います。
漠然としたオリジナルの画像情報からその画像の特徴だけを振るい落として圧縮した、そんなイメージの理解です。
全結合層
tf.keras.layers.Flatten()
各フィルタによって細かく特徴が分割されていたと思いますが、これを一つにまとめます。
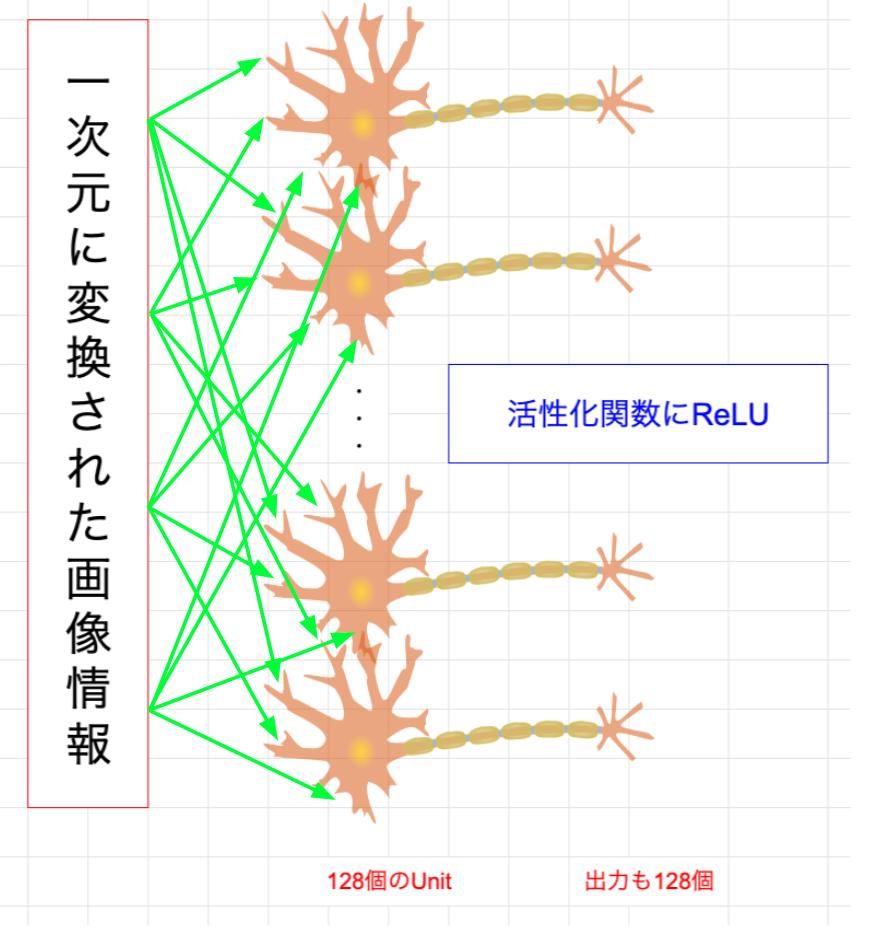
5×5の32枚の特徴マップを1次元に変換します。
(5, 5, 32) → (800)
tf.keras.layers.Dense(128, activation='relu')
128
・・・ドキュメントを見ていきましょう。
どうやらunitsを取るようです。
いきなりですが、ニューロンの話をします。
ニューロンというのは人間の脳で情報を伝播させるために利用される神経細胞です。
もともとニューラルネットワークはこのニューロンをヒントに考案されているので、ここでの理解もその概念が役に立ちます。
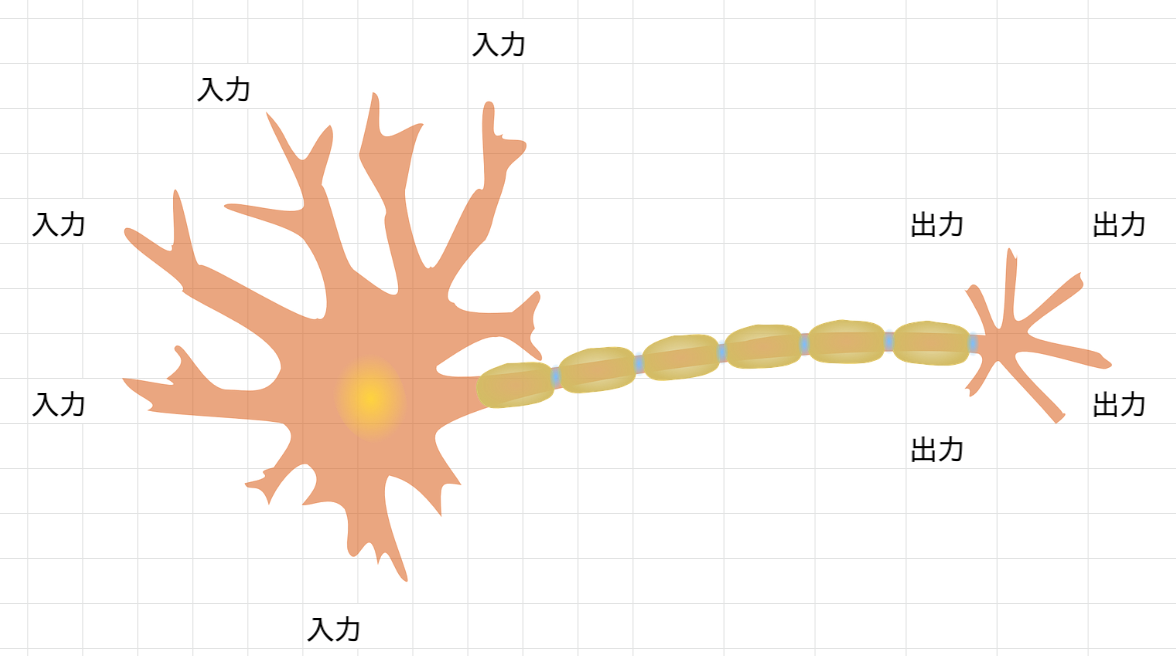
ここの画像を使わせていただきました。
Unitというのはまさにニューロンを意味します。
今回はこのニューロンが128個用意されているというわけです。
1次元に変換された値が全て1個のニューロンに入力され、内部で値を全て結合し、一つの値を出力します。
ここでも活性化関数にReLUを使い、出力するかしないかを決定します。
出力層
tf.keras.layers.Dense(10, activation='softmax')
呼んでいる関数は先ほどと同じDenseになります。
つまり、最後は10個のニューロンを利用して出力を得るということになります。
活性化関数にはsoftmaxを利用します。
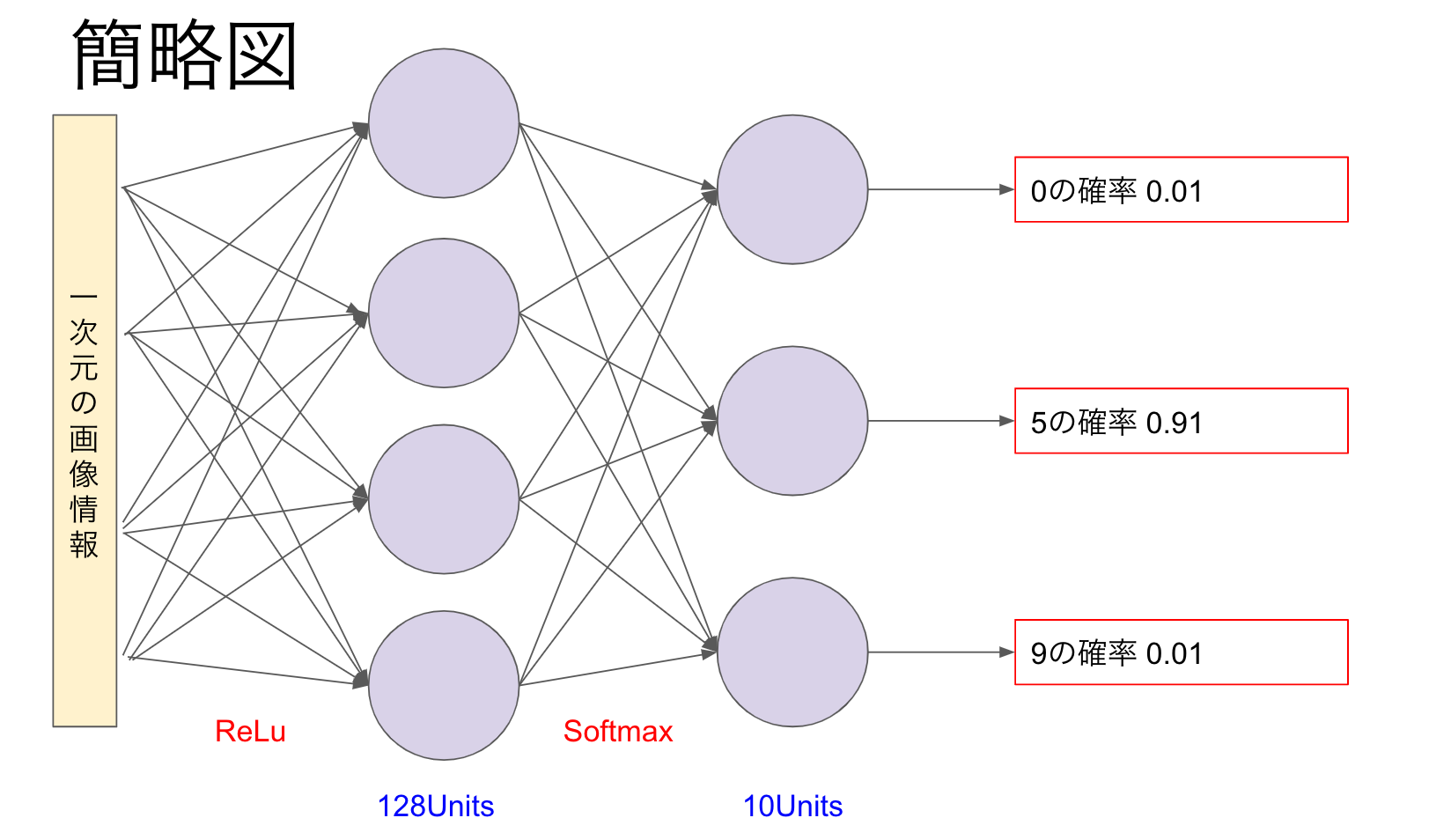
Softmax関数
総和が1となるように予測確率を算出してくれる関数です。
今回の画像分類だと、次のような出力が得られます(イメージです)。

モデルのコンパイル
オプティマイザと損失関数を設定してモデルをコンパイルします。
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
-
オプティマイザ(optimizer)
- トレーニングを最適化する手法を設定する
- 今回はAdamを採用している
- 他にもMomentum SGD、AdaGrad等が存在する
- ここを実装することはないのであるものを使えば良いと思います
- トレーニングを最適化する手法を設定する
-
損失関数(loss)
- ラベルデータと実際の出力がどれだけ誤差があるかを計算する関数
- 今回はcategorical_crossentropyを採用している
- 実はラベルを1-of-K表現に変形せずともsparse_categorical_crossentropyを使えばそのままの形状で渡すことが可能です
- ラベルデータと実際の出力がどれだけ誤差があるかを計算する関数
初学者のうちは、ここら辺はあるものを使っていく感じで大丈夫だと思います。
ひとまずは**「loss使って誤差出してoptimizerでいい感じに重みの更新とか計算してくれてんだろうな〜」**程度の理解しかしてません。間違ってるかもしれません。でも最初のうちはそれでいいんだと思います。(投げやり)
model.summary()
Kerasのモデルは**summary()**が実装されています。
これはネットワークの各層の出力が見れるので大変便利です。
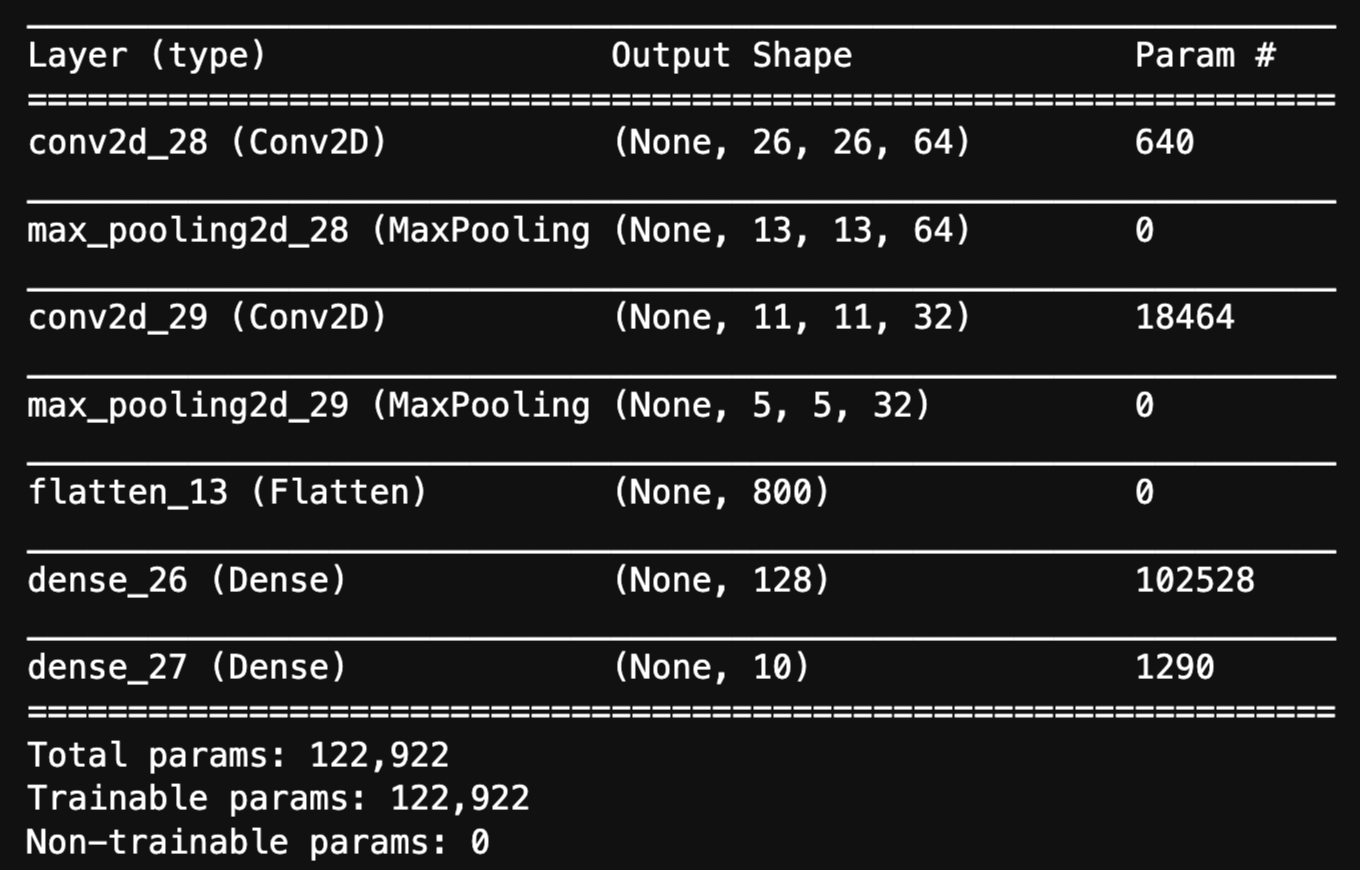
今まで確認してきた各層の内容が一目瞭然ですね。
モデルのトレーニング
いよいよ学習していきます。
model.fit(training_images, training_labels, epochs=5)
modelの**fit()**を呼ぶだけです。
epochs=5
学習を行う回数になります。
今回は60000枚の画像データそれぞれに対して5回学習を行います。
学習し過ぎるとOverfitting(過学習)という問題も発生してくるので注意です。
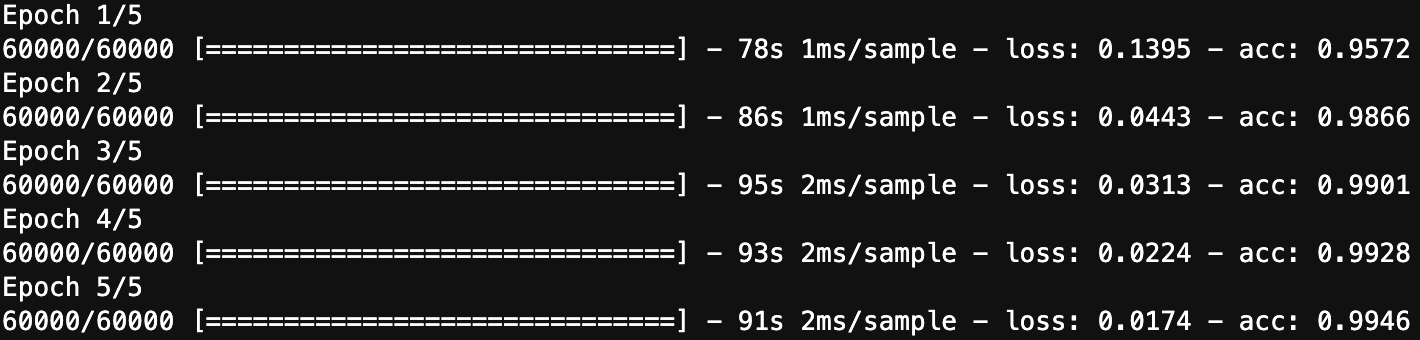
1回目の学習でも95%の精度を出してますね!
5回目の学習が終わった時点で99%の精度です!
補足
ニューラルネットワークの世界は複雑で、トレーニングデータに対しては精度を出せるけど、テストデータといった未知のデータに対しては極端に精度が出なくなってしまう過学習という現象が度々見られます。
過学習を抑えるのに**Dropout(ドロップアウト)**という手法があります。
いくつかのノードを無効化しながら学習を繰り返します。
今回は利用していません。
test_loss = model.evaluate(test_images, test_labels)
最後は学習に利用していない10000枚のテストデータを使って精度を確認していきます。

99%の正答率ですね!すごい!
お疲れ様でした!
おわりに
今回は手書き文字の画像データを扱いましたが、同じ手法で別の画像データ(犬の画像、猫の画像、アイドルの画像、etc...)も学習させることが可能です!
今回のMNISTから無限の可能性を切り開けたと思います!(言い過ぎですね)
「よし!今日からゲームの画像分類をCNNで書くぞ!」
「・・・画像データどうする?そもそもデータセットの作り方は?」
そうなんです。
MNISTから始めた初学者が次にぶち当たる壁としてデータ収集とデータセット作成が待ち構えています。
結局はデータがないと何もできないんですよね・・・。
次回は少ない画像データでも精度が出せる(かもしれない)優秀なモデルをベースとした転移学習についてまとめていきたいです。