はじめに
Pleasanter(プリザンター)は、柔軟なカスタマイズ性と豊富な集計機能を備えた業務アプリケーション構築プラットフォームです。標準機能でも多様な集計処理が可能ですが、業務要件によっては「月単位の集計」や「複数条件による集計」など、より高度で柔軟な分析が必要になるケースがあります。
しかし、標準UIのみでこれらの集計ロジックを実現しようとすると、設定やデータ加工の工数が増大し、メンテナンス性も低下する恐れがあります。
そこで今回は 集計処理をSQL側(特にView・ストアドプロシージャ)に委譲し、集計結果をPleasanterのテーブルに直接反映させる 手法をご紹介します。
このアプローチにより、
- 集計ロジックの柔軟性向上
- 処理速度の改善(DBエンジンによる集計最適化)
- 開発・運用の効率化
といったメリットが期待できます。
集計要件の背景
今回のサンプルでは、次のような業務要件を想定しています。
- 従業員が日単位で残業時間を申請する「残業申請テーブル」が存在する
- 管理者(上長・経理担当者など)が、月単位で各従業員の残業申請時間を集計して確認したい
残業申請テーブル
| # | 日付 | 従業員 | 残業時間 |
|---|---|---|---|
| 1 | 2025年8月1日 | Aさん | 1 |
| 2 | 2025年8月2日 | Aさん | 2 |
| 3 | 2025年8月3日 | Aさん | 3 |
| 4 | 2025年8月1日 | Bさん | 1 |
| 5 | 2025年8月2日 | Bさん | 1 |
| 6 | 2025年8月3日 | Bさん | 3 |
残業申請テーブル(集計)
今回作りたい集計テーブル となります。
残業申請テーブルからAさん、Bさんの残業時間の合計が分かるテーブルを作成します。
| # | 日付 | 従業員 | 残業時間(合計) |
|---|---|---|---|
| 1 | 2025年8月 | Aさん | 6 |
| 2 | 2025年8月 | Bさん | 5 |
実装の方針
本実装では、以下の構成を採用します。
-
Pleasanter側に2つのテーブルを用意
- 元データ(残業申請テーブル)
- 集計結果テーブル(残業申請の月次集計)
-
SQL Server側で集計Viewを作成
- 元テーブルのデータを月単位で集計
- Pleasanterのテーブル構造に合わせた形式で出力
-
ストアドプロシージャで集計結果を登録
- 既存の集計結果を削除
- 集計Viewの内容を一括登録
テーブル構成
Pleasanterでは、内部的に Results と Items テーブルにデータが格納されます。
今回は、記録テーブル と 記録テーブル(集計) を以下のように設定します。
-
記録テーブル(元データ)
- 分類A:従業員([[Users]]でユーザー一覧を参照)
- 日付A:残業日
- 数値A:残業申請時間
- 数値B:実際の残業時間
-
記録テーブル(集計)
- 分類A:従業員
- 数値A:残業申請時間合計
- 数値B:実際の残業時間合計
- 数値C:年月(例:202508)
サイトID
| テーブル名 | サイトID |
|---|---|
| 記録テーブル | 10199 |
| 記録テーブル(集計) | 10200 |
参考
記録テーブルの構成

記録テーブル(集計)の構成
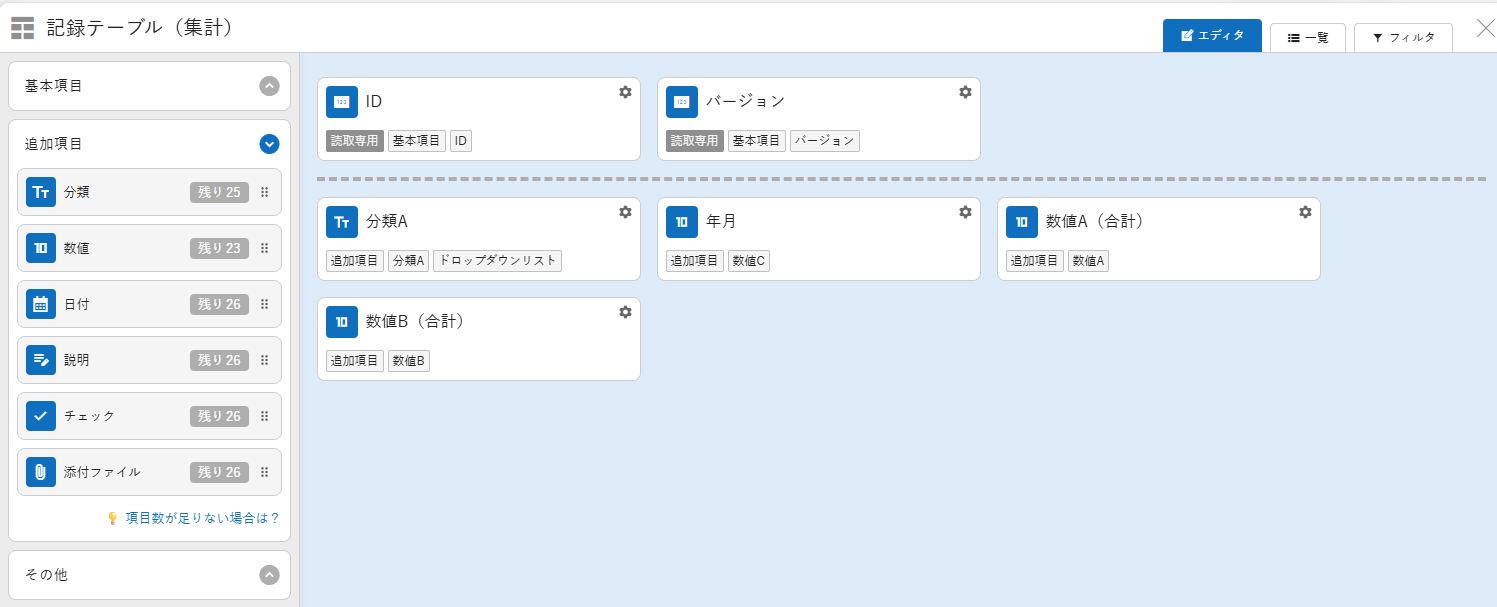
日付A、数値A、数値Bと初期値としているのは後続の ストアドプロシージャ、テーブル列 が列名を一致させたほうがイメージし易いと思い初期値のままとしています。
記録テーブルの分類設定には従業員一覧を表示させたいので [[Users]] を設定してます。

実装
集計クエリの作成
まず、元データを月単位で集計するViewを作成します。
ここでは FORMAT 関数を用いて yyyyMM 形式に変換し、DECIMAL 型で保持します。
CREATE VIEW [dbo].[V_Results_MonthTotal_10199]
AS
SELECT
10200 AS SiteId
,R.ClassA AS ClassA
,SUM(R.NumA) AS NumA
,SUM(R.NumB) AS NumB
,CONVERT(DECIMAL,FORMAT(R.DateA, 'yyyyMM')) AS NumC
FROM Results R
WHERE R.SiteId = 10199
GROUP BY
R.ClassA
,FORMAT(R.DateA, 'yyyyMM');
GO
ストアドプロシージャの作成
このストアドプロシージャでは、
- 記録テーブル(集計)のサイトID(10200)の情報を削除
- viewから記録テーブル(集計)のデータを登録
という流れで処理します。
CREATE PROCEDURE [dbo].[P_Load_Results_From_V_Results_MonthTotal_10199]
AS
BEGIN
-- 実行時の余計なメッセージ(行数など)を抑制
SET NOCOUNT ON;
-- エラー発生時に即座にトランザクションを中断する設定
SET XACT_ABORT ON;
-- 対象となるサイトID
DECLARE @TargetSiteId bigint = 10200;
-- 実行時の現在日時を保持
DECLARE @Now datetime = GETDATE();
-- 取込用ステージングテーブル
-- メモリ上(テーブル変数)に一時的にデータを格納する
-- rn: 行番号(Itemsとのマッピング用)
DECLARE @Src TABLE(
rn int PRIMARY KEY,
ClassA nvarchar(1024),
NumA decimal(19,4),
NumB decimal(19,4),
NumC decimal(19,4)
);
-- ItemsテーブルとResultsテーブルを紐づけるためのマッピングテーブル
-- rn: ステージング側の行番号
-- ReferenceId: Itemsテーブルの主キー(Results.ResultIdと一致させる)
DECLARE @Map TABLE(
rn int PRIMARY KEY,
ReferenceId bigint NOT NULL
);
BEGIN TRY
BEGIN TRAN; -- 一連の処理をトランザクションとしてまとめる
/* =========================================================
0) 事前削除
---------------------------------------------------------
- 対象SiteIdの既存データを削除
- 再取込の前処理としてクリーンな状態にする
========================================================= */
DELETE FROM dbo.Results
WHERE SiteId = @TargetSiteId;
DELETE FROM dbo.Items
WHERE SiteId = @TargetSiteId
AND ReferenceType = N'Results';
/* =========================================================
1) ビュー取り込み(行番号付与)
---------------------------------------------------------
- 集計ビュー V_Results_MonthTotal_10199 から必要な列を取得
- CASTで数値精度を揃える
- ROW_NUMBERでユニークな行番号を付与し、後続処理のマッピングキーとする
========================================================= */
WITH S AS (
SELECT
V.ClassA
,CAST(V.NumA AS decimal(19,4)) AS NumA
,CAST(V.NumB AS decimal(19,4)) AS NumB
,CAST(V.NumC AS decimal(19,4)) AS NumC
,ROW_NUMBER() OVER (ORDER BY V.ClassA, V.NumC) AS rn
FROM dbo.V_Results_MonthTotal_10199 AS V
)
INSERT @Src(rn, ClassA, NumA, NumB, NumC)
SELECT rn, ClassA, NumA, NumB, NumC
FROM S;
/* =========================================================
2) MERGEで Items を作成しつつ rn⇔ReferenceId を取得
---------------------------------------------------------
- MERGEのON条件を false(1=0) にして全件INSERT
- OUTPUT句で @Src.rn と挿入された ReferenceId を @Map に格納
- これによりステージングデータとItemsのPKが紐付く
========================================================= */
MERGE dbo.Items AS T
USING @Src AS SRC
ON 1 = 0
WHEN NOT MATCHED THEN
INSERT
(
Ver, ReferenceType, SiteId, Title, FullText,
SearchIndexCreatedTime, Comments, Creator, Updator,
CreatedTime, UpdatedTime
)
VALUES
(
1, N'Results', @TargetSiteId, N'タイトル無し', NULL,
@Now, NULL, 1, 1, @Now, @Now
)
OUTPUT SRC.rn, inserted.ReferenceId
INTO @Map(rn, ReferenceId);
/* =========================================================
3) Items.FullText の更新
---------------------------------------------------------
- UIや検索用に「記録テーブル(集計) {ReferenceId}」という文字列を設定
- UpdatedTime も現在時刻に更新
========================================================= */
UPDATE I
SET I.FullText = N'記録テーブル(集計) ' + CONVERT(nvarchar(32), I.ReferenceId),
I.UpdatedTime = @Now
FROM dbo.Items AS I
JOIN @Map AS M
ON I.ReferenceId = M.ReferenceId;
/* =========================================================
4) ResultsへのINSERT
---------------------------------------------------------
- ResultId = Items.ReferenceId(外部キー的役割)
- Verは既定値1を利用
- 取得した集計データをResultsテーブルに反映
- DateAなど未使用項目はNULLで挿入
========================================================= */
INSERT dbo.Results
(
SiteId
,UpdatedTime
,ResultId
-- Ver は既定値(=1)
,Title, Body, Status, Manager, Owner, Locked
,ClassA
,NumA, NumB, NumC
,DateA
,Creator, Updator
,CreatedTime
)
SELECT
@TargetSiteId
,@Now
,M.ReferenceId
,NULL, NULL, NULL, NULL, NULL, NULL
,S.ClassA
,S.NumA, S.NumB, S.NumC
,NULL
,1, 1
,@Now
FROM @Src AS S
JOIN @Map AS M
ON M.rn = S.rn
ORDER BY S.rn; -- データの順序を維持
COMMIT TRAN; -- 正常終了時に確定
END TRY
BEGIN CATCH
-- エラー時はトランザクションをロールバックして再スロー
IF XACT_STATE() <> 0 ROLLBACK TRAN;
THROW;
END CATCH
END
GO
実行する
ストアドプロシージャを実行すると 記録テーブル(集計) に集計されたデータが作成せれます。
記録テーブル
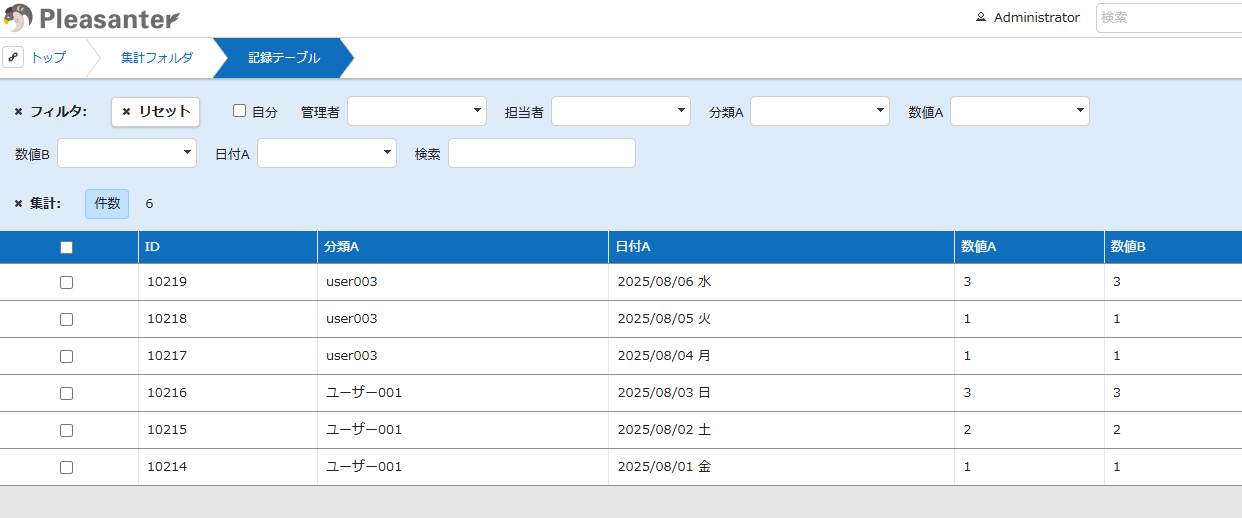
記録テーブル(集計)

終わりに
今回ご紹介した手法は、Pleasanterの標準的な集計機能ではカバーしきれない複雑な集計要件を、SQL Server側に集計ロジックを移譲することで柔軟かつ効率的に実現する手法としてご紹介させていただきました。
Pleasanterはローコード開発ツールとして非常に優れた柔軟性を持ちますが、UI設定のみで複雑な集計を構築しようとすると、条件式やフィルタの組み合わせが増え、管理が煩雑になる傾向があります。特に月単位・年度単位といった期間集計や、複数の数値項目を集約するケースでは、データベースエンジンが持つ集計関数やグルーピング機能を直接活用する方が、処理性能や可読性の面で優位です。
本記事の実装例では、Viewによる集計ロジックの定義 と ストアドプロシージャによるデータ登録処理 を組み合わせることで、以下のような利点を実現しました。
-
処理の高速化
集計処理をSQL Serverの内部で完結させることで、Pleasanter側での逐次計算やフィルタリングが不要になり、表示速度や応答性が向上します。特にデータ件数が多い場合や複数ユーザーが同時利用する環境では効果が顕著です。 -
ロジックの一元管理
集計条件や加工方法をView内に定義することで、業務ルールの変更が発生した際も、UI設定を複数修正する必要がなく、SQLの単一点修正で全体に反映できます。これにより保守性と再利用性が向上します。 -
柔軟な拡張性
今回は残業時間集計を例としましたが、同様の仕組みは売上分析、在庫推移、顧客行動データ分析など、あらゆる集計系業務に応用可能です。期間条件やグルーピング単位をパラメータ化することで、異なる分析ニーズにも対応できます。 -
データ品質の担保
集計処理前に不要データを削除し、必要な形式に正規化してから登録するため、表示データの整合性を確保できます。加えて、トランザクション制御により、途中エラー時も不完全なデータが反映されることを防止できます。
一方で、このアプローチを運用する上では以下のような注意点もあります。
- SQL Serverの知識が必須となるため、開発者がSQL構文・パフォーマンスチューニングに習熟している必要があります。
- Pleasanterのアップデートやスキーマ変更時には、Viewやストアドプロシージャが影響を受ける可能性があるため、定期的な検証が必要です。
- データ件数や更新頻度によっては、ストアドプロシージャ実行のタイミングやバッチ処理の計画が重要になります。
総じて、本手法は「UI設定での集計限界を超えたい場合」「パフォーマンスと柔軟性を両立したい場合」に非常に有効です。SQLによる集計とPleasanterの表示機能を適切に組み合わせることで、現場のニーズに即した集計画面を短期間で構築でき、業務効率の向上とデータ活用の高度化を同時に実現できます。
今回の事例が、読者の皆さまが自社のPleasanter活用をより戦略的かつ高効率に進める一助となれば幸いです。